目錄
HTTP 請求(Request)
認識 URL
URL 基本格式
關于 URL encode
認識方法(method)
1. GET 方法
2. POST 方法
認識請求“報頭”(header)
Host
Content-Length? ?Content-Type
User-Agent(簡稱 UA)
Referer
Cookie
認識請求“正文”(body)
完!
HTTP 請求(Request)
認識 URL
URL 基本格式
URL 不僅僅是在 HTTP 中使用,回憶想想,我們之前在 JDBC 也使用過 URL:jdbc:mysql://127.0.0.1:3306/java110?characterEncoding=utf8&useSSL=false
平時我們俗稱的“網址”,其實說的就是 URL(Uniform Resource Locator 統一資源定位符),描述一個互聯網上的資源位置,即互聯網上的每個文件都有一個唯一的 URL,它包含的信息指出文件的位置以及瀏覽器應該怎么處理它。(URL 的詳細規則由因特網表述 RFC1738 進行約定~~)
我們上面的:https://www.baidu.com/?
這是一個最簡單的 URL,https 是協議的名稱,www.baidu.com 是域名
我們如果抓一個百度里面的搜索內容請求如下:
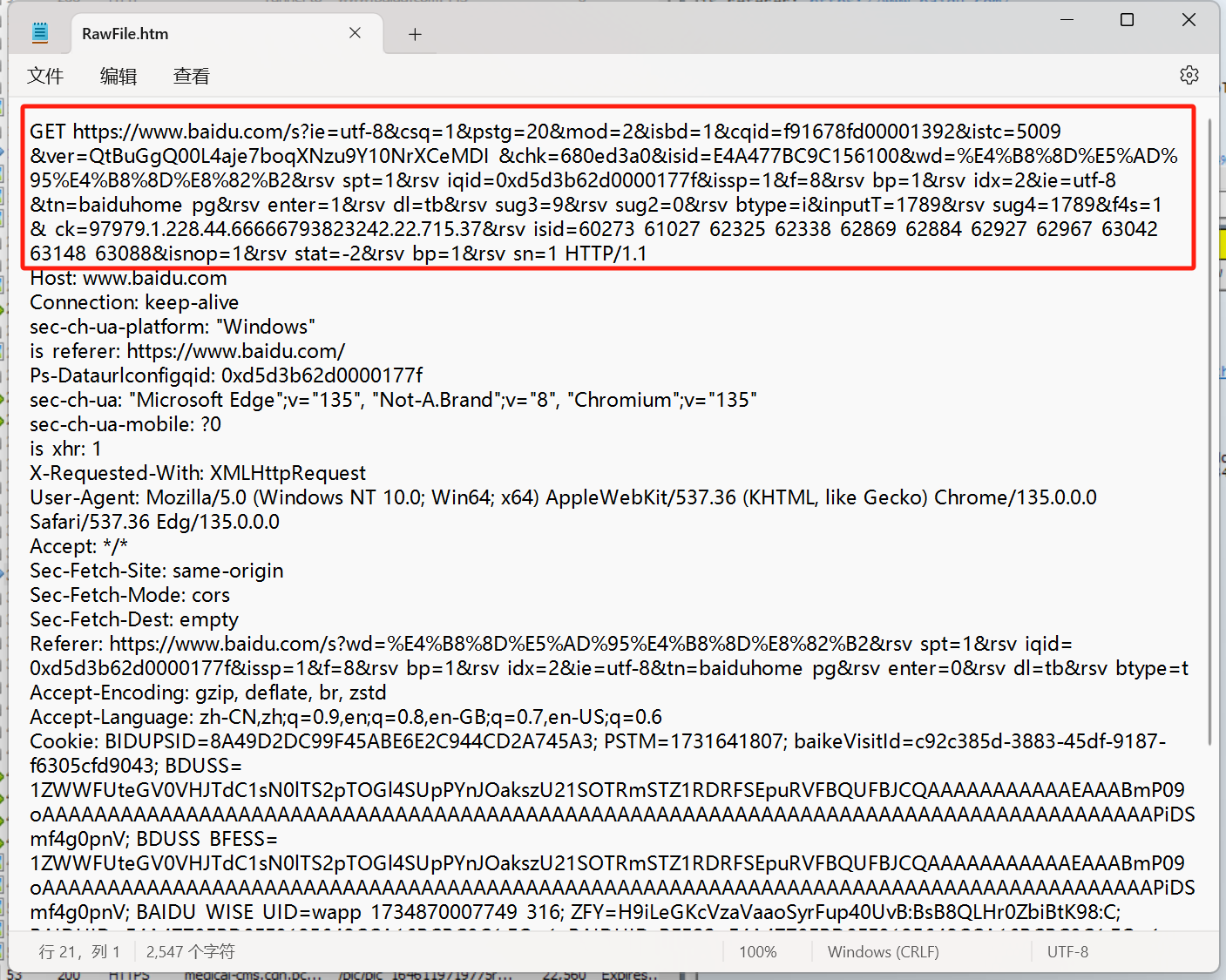
此時的 URL 就不是上面那么簡單了:在協議的名稱,域名的后面,還跟了一長串字符~~ 稱為查詢字符串(query string),查詢字符串中表達的意思,作為外人是無從得知的,這里面的內容就是寫這個代碼的程序員定義的~~
我們可以看到,在查詢字符串中,也是鍵值對的格式。但此處的鍵值對,是使用 & 分割鍵值對,使用 = 來分割鍵和值~~
一個完整的 URL 結構如下:
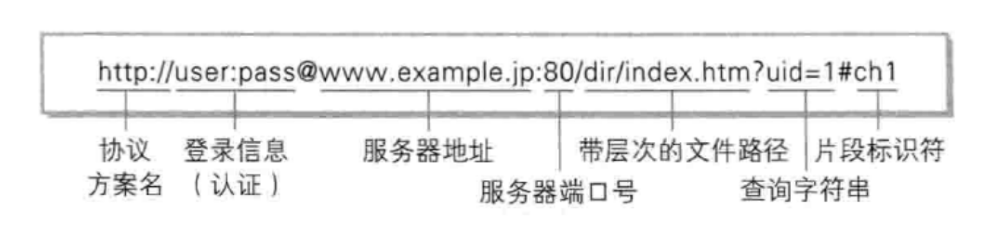
http:協議方案名,常見的有 http 和 https,也有其他的類型(我們前面訪問 mysql 的時候使用 jdbc:mysql)(可以省略,省略后默認為 http://)
user:pass:登錄信息,之前是直接會把相關認證信息直接在 URL 中展示的,后來發現實在是不太安全~~ 現在都是通過單獨的登陸頁面來完成身份驗證~~
www.example.jp:80:服務器地址,服務器端口號,這里的域名,也可以是 IP 地址,后面帶有端口號,可以表示我們要訪問服務器那個端口,如果 URL 中不帶端口號,瀏覽器就會自動給一個默認的端口(這里的服務器端口,不是客戶端中系統隨機分配的那個),此處用什么端口作為默認值,取決于我們的協議是什么:http -- 80? ? https -- 443
dir/index.html:帶有層次的文件路徑
uid=1:查詢字符串,是客戶端給服務器傳遞信息的重要途徑,這里的組織方式是按照鍵值對來組織的,這里面的鍵值對內容,是程序員自定義的~~
ch1:片段標識符,主要用于頁面跳轉,常用于通過不同的片段表示跳轉到文檔的不同章節
結合上述的 IP 地址,端口號,帶層次的文件路徑,查詢字符串,就可以描述出一個網絡資源了:
http://中北大學文韜餐廳:20/手抓餅/番茄手抓餅/?辣椒=少放&香菜=多放
關于 URL encode
在 query string 中都是程序員自定義的鍵值對,但在 URL 中,本身有些特殊符號具有特特定的含義: /? ?:? ??? @? .....
如果 URL 中的 query string 中也包含同樣的符號,怎么辦呢??? ==》 如果直接寫進 query string 中,就可能會使服務器 / 瀏覽器解析失敗!!
一個靠譜的辦法,我們前面已經在代碼中使用過了:對上述符號進行“轉義”。包括中文字符或者是其他由 UTF-8 或者 GBK 這樣的編碼方式構成的字符,雖然在 URL 中沒有特殊含義,但瀏覽器可能會把編碼中的某個字節當作 URL 中的特殊符號,也需要進行轉義~~
轉義的規則如下:將需要轉碼的字符的轉為 16 進制表示,前面加上 % 即可
比如我們搜索 C++:
 可以看到,query string 中顯示的是 C%2B%2B
可以看到,query string 中顯示的是 C%2B%2B
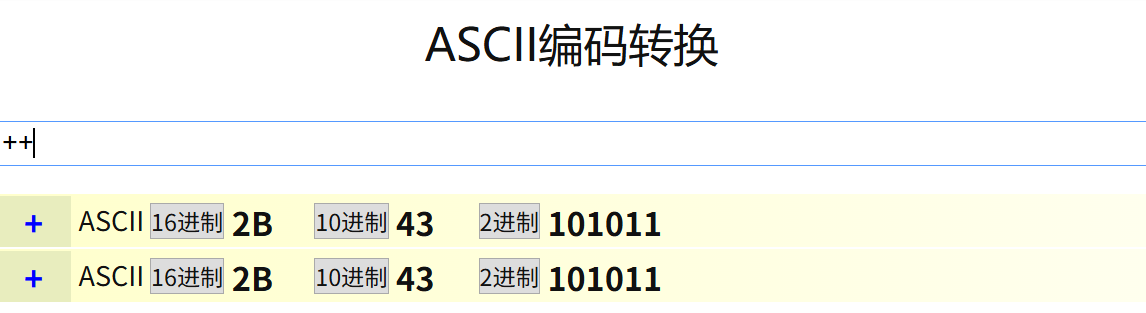
我們可以通過 ASCII 碼表發現,+ 的十六進度是 2B,則對應了 C++ ==》 C%2B%2B
我們也可以搜索一個女神

在上面雖然顯示的 query string 直接是女神,是瀏覽器自動進行了解析,我們可以復制粘貼出來到文本文檔就顯示出來了:

我們“女神”進行 utf-8 編碼:
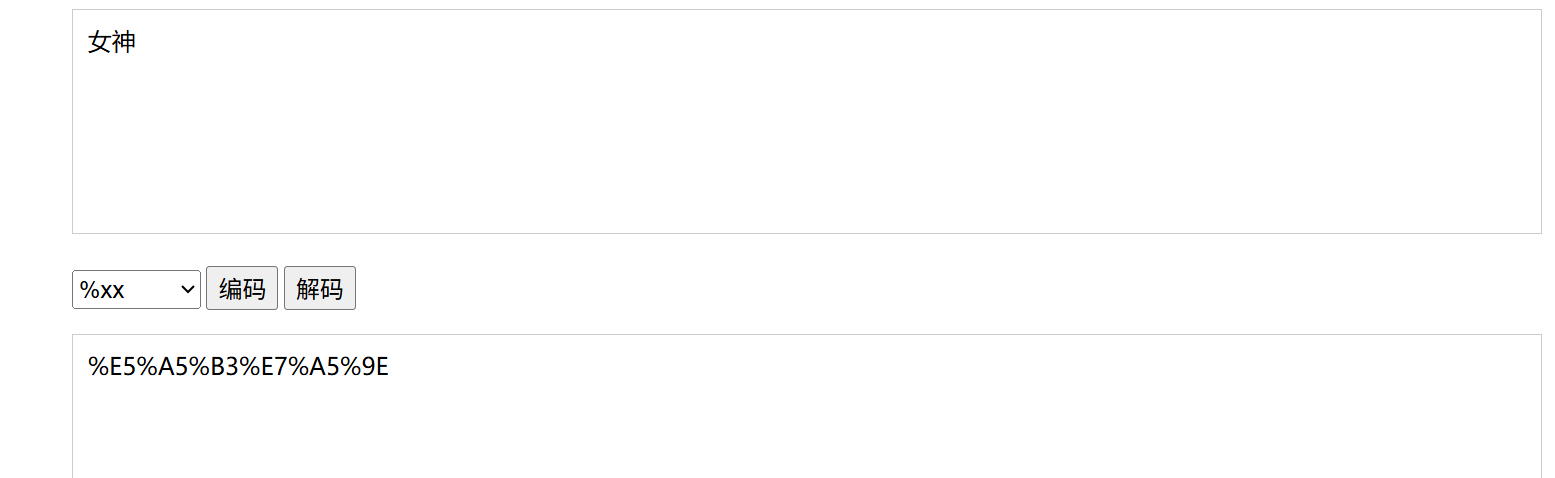
結果相符~~
我們這里的 urlencode 編碼是非常非常重要的~~ 在實際開發中,當我們要構造一個 URL 的時候,尤其是 URL 的 query string 中要包含中文的時候,務必要進行編碼!!
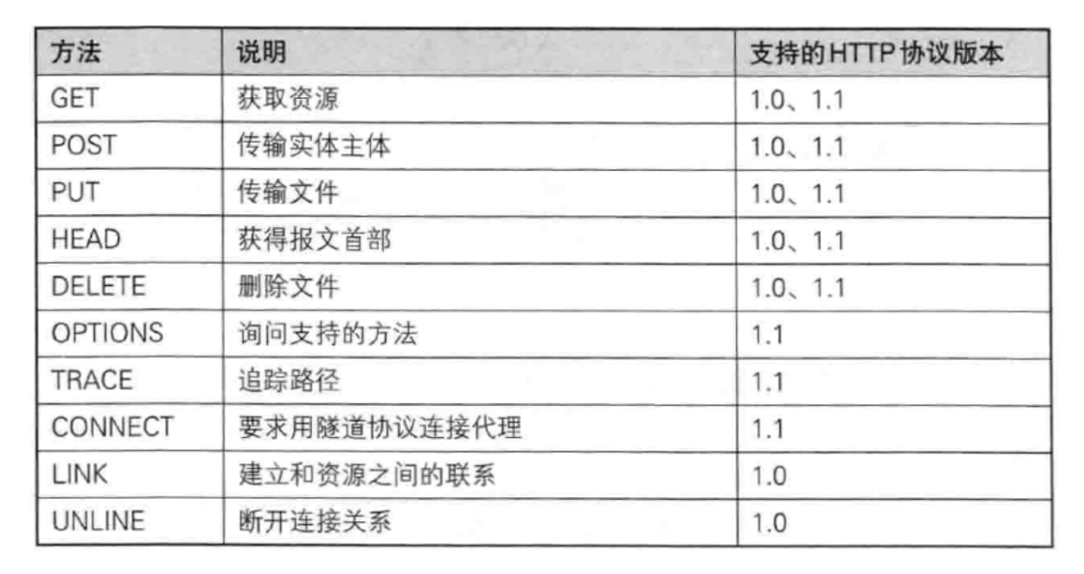
認識方法(method)
請求的首行中,包括了 方法 URL 版本號
方法就描述了這次請求,想干啥(目的)
1. GET 方法
GET 是最常用的 HTTP 方法,常用于獲取服務器上的某個資源(讀操作)。在瀏覽器中直接輸入 URL,此時瀏覽器就會發送出一個 GET 請求。另外,HTML 中的 link,img,script 等標簽,也會觸發 GET 請求。
使用 Fiddler 觀察 GET 請求:
在瀏覽器訪問百度主頁,觀察抓包結果:
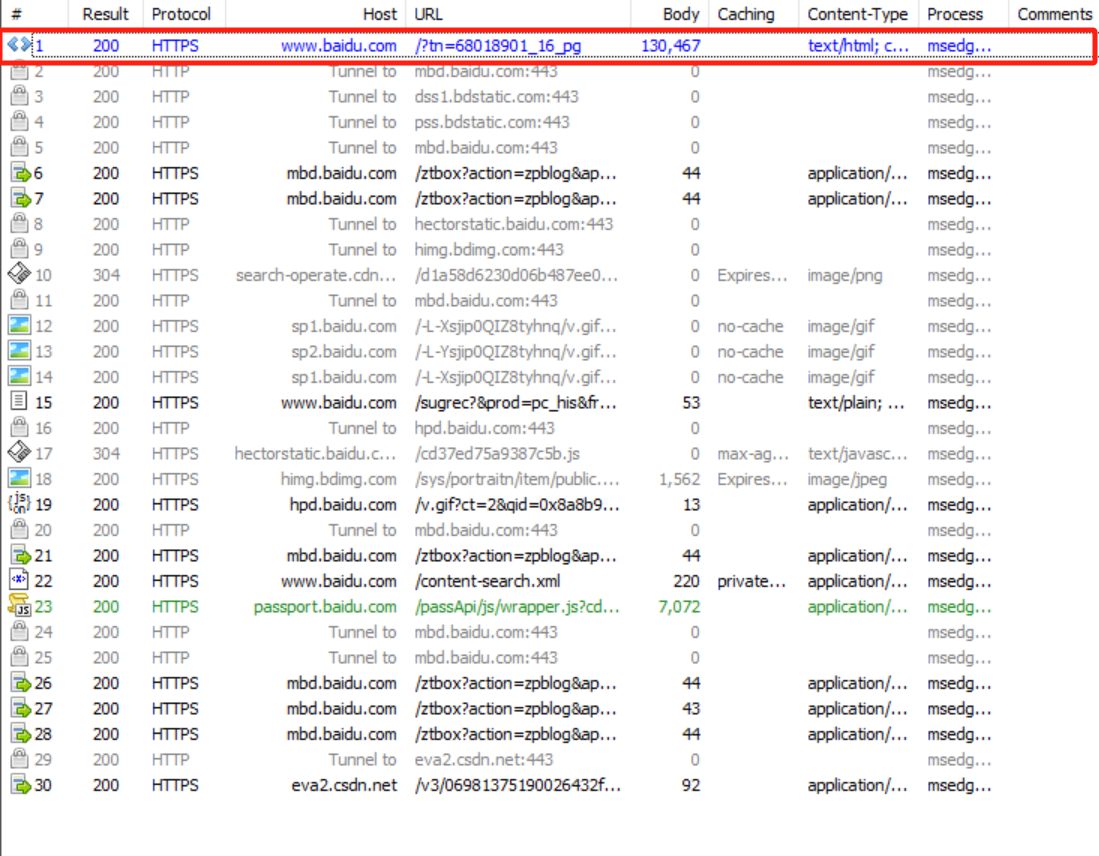
我們可以看到,最上面藍色的,是通過瀏覽器地址發送的 GET 請求,下面的
下面的一個寫 baidu 域名相關的請求,有些是通過 HTML 中的 link/script/img 標簽產生的。有些是通過 ajax 方式產生的。
我們選中第一條,觀察請求的詳細結果:
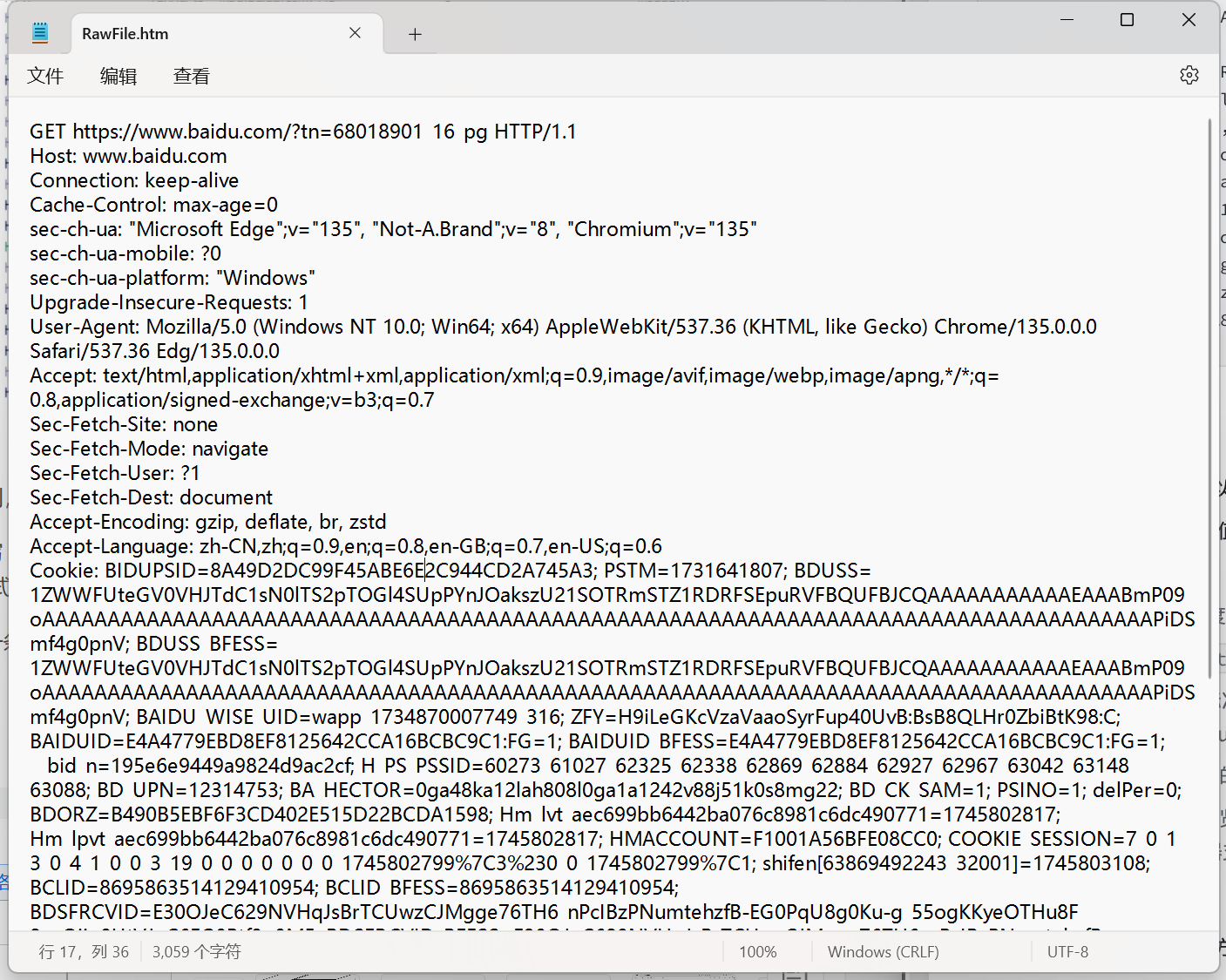
GET 請求的特點:
首行的第一部分為 GET
URL 的 query string 可以為空,也可以不為空
header 部分有若干個鍵值對結構
body 部分為空
2. POST 方法
POST 方法也是一種常見的方法,多用于提交用戶輸入的數據給服務器(例如登錄頁面)
我們可以登錄 gitee 來進行一下抓包~
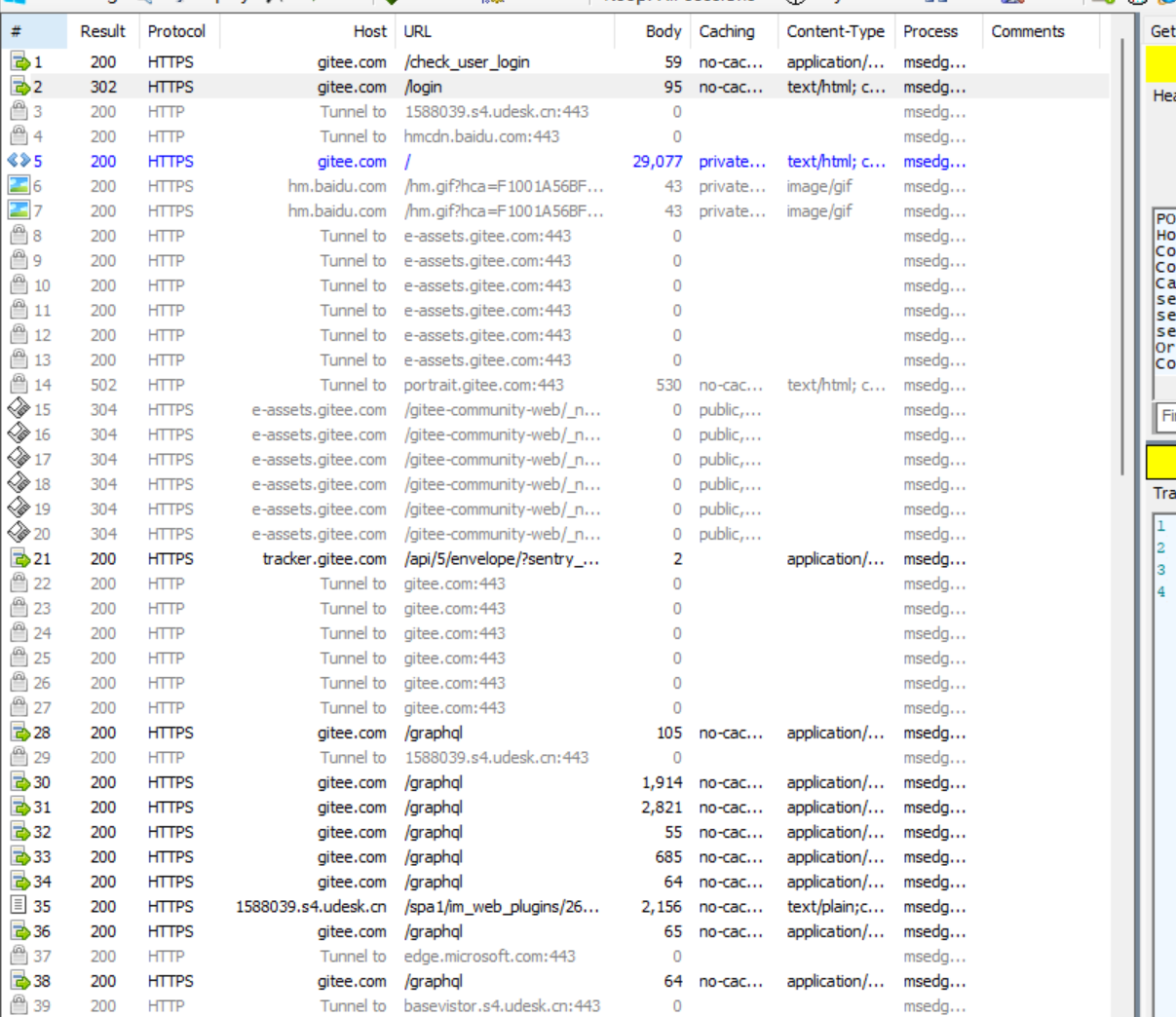
對第一個請求,點擊查看詳情
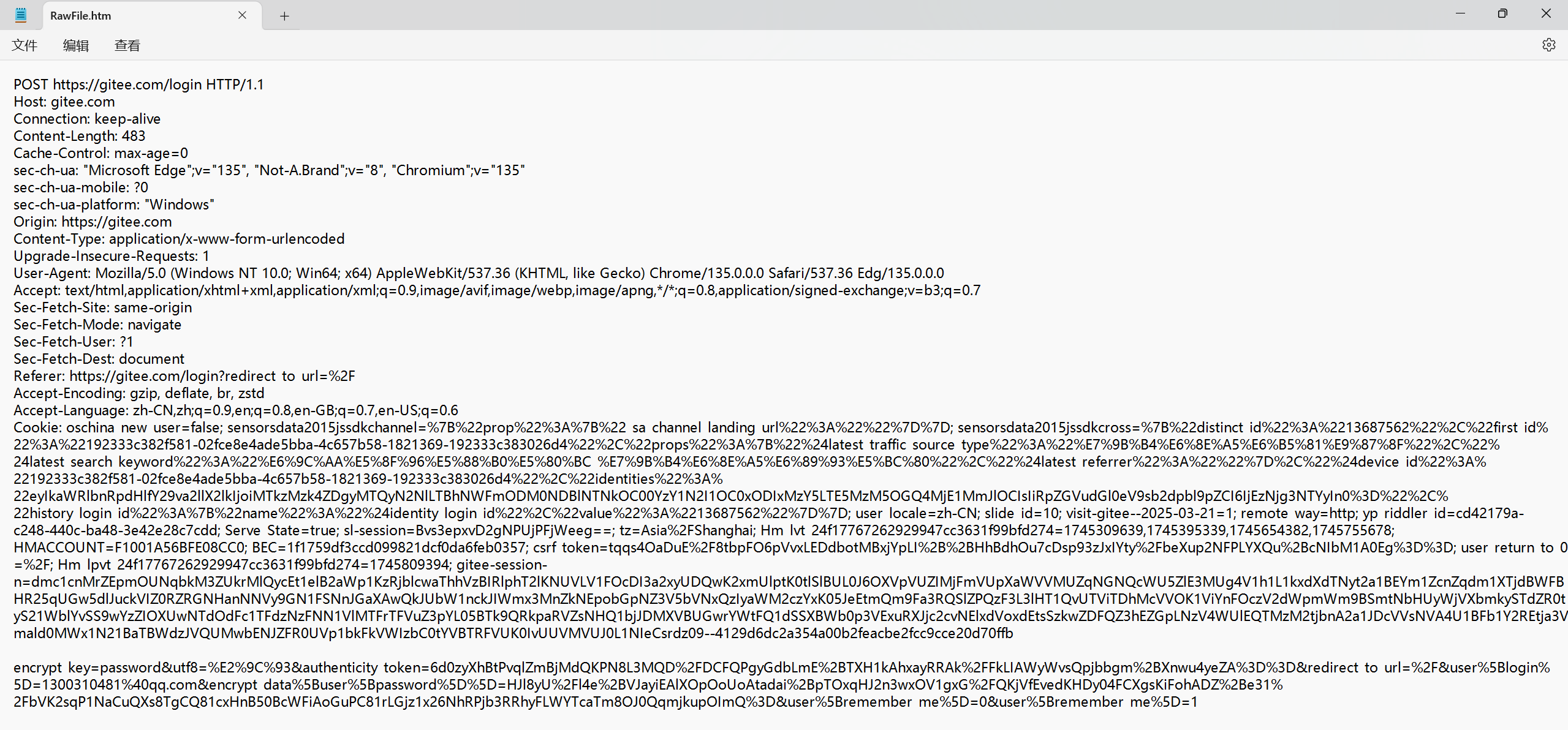
POST 請求的特點:
首行的第一部分為 POST
URL 的 query string 一般為空(可以不為空)
header 部分有若干個鍵值對結構
body 部分一般不為空,body 內的數據格式通過 header 中的 Content - Type 指定。body 的長度由 header 中的 Content - Length 指定~~
面試題:POST 和 GET 的區別:
先蓋棺定論:GET 和 POST 沒有本質區別。使用 GET 的場景,也可以替換成 POST,使用 POST 的場景,也能替換成 GET(這里主要是取決于程序員代碼是怎么寫的,尤其是服務器和客戶端都是同一個程序員實現的情況~~)(部分服務器 / 部分瀏覽器,在某些情況下 GET 和 POST 不能完美替換,但是大部分情況下,相互替換問題一般不大~~)
但是 GET 和 POST 還是在使用習慣上有一些區別的~~
1. GET 習慣于把數據放到 URL 的 query string 中。POST 習慣于把數據放到 body 中。
(GET 也可以把數據放到 body,POST 也可以把數據放到 query string -- 有些可能不支持,絕大部分都支持)
2. 語義上的區別。在標準文檔中,GET 的語義是用來獲取數據的,POST 的語義是給服務器傳輸數據的。(實際使用,當然還是程序員自己說了算~~)
3. 關于冪等性,在標準文檔中,建議 GET 請求實現冪等的,POST 無要求。
(冪等:是一種數學術語,在計算機中也很常見~~ 即每次輸入的內容一定,輸出的結果也一定,就稱為是冪等的,如果每次輸入的內容一定,輸出的結果不一定,就不是冪等的)
(GET 在實際開發中,也不一定非要實現冪等,標準是這么建議的,但我們可以不聽標準的建議~~)
網上的一些不太準確的相關說法:
1. POST 比 GET 更加安全~~
論據:登錄的時候,如果使用 GET,用戶密碼就會顯示在 URL 中,此時會被別人看到,就不安全...
如今用戶密碼都會有一個單獨的登錄頁面了,不會直接在 URL 中,即使是 POST ,即使沒有顯示子啊 URL 中,也是可以被黑客進行抓包獲取的...真正保證安全性的關鍵在于加密!!
2. GET 傳輸的數據量小(存在上限),POST 傳輸的數據量更大
這句話描述的是以前的情況,以前是以前,現在是現在~~
實際上,HTTP 標準文檔上明確說了,對于 GET,URL 的長度是不進行限制的,只不過是之前老版本的 IE 瀏覽器在實現的時候,URL 的長度有限制(現在已經沒有了~~)
3. GET 只能攜帶文本數據,POST 可以攜帶二進制數據
這個說法,并不是完全錯誤,只是有一些局限性~~
URL 通過 query string 來攜帶數據
query string 是只能包含文本的,是對二進制數據進行 urlencode 了,自然就成為文本了。到了服務器再進行 urldecode,就能把數據還原成二進制。
POST 請求中,bodu 中雖然可以攜帶二進制數據,但也不是經常攜帶的,很多時候是對二進制數據進行 urlencode / base64 等等方式進行轉碼的~~
其他方法使用較少~~
認識請求“報頭”(header)
header 的整體格式也是“鍵值對”結構
每個鍵值對占一行,鍵和值之間使用分號進行分割~
Host
表示服務器主機的地址和端口
(URL 中已經有 Host 了,這里的 Host 和 URL 中的 IP 地址 端口什么的,絕大部分情況下都是一樣的~~)
Content-Length? ?Content-Type
Content-Length 表示 body 中的數據長度。
Content-Type 表示請求的 body 中的數據格式。
(和 body 密切相關,如果當前數據包沒有 body,也就不會有這兩個字段)
如果沒有這兩個字段,body 的請求/響應,就會直接使用空行作為分隔符了,如果有 body,空行就不是結束標志了,從空行開始來讀取 body,body 要讀多長就取決于 Content-Length,讀完之后,這個包就結束了
Content - Type 中的常見選項:
請求中:
1)?application/json:body 中的數據為 json 格式,形如:
{"username":"123456789","password":"xxx","code":"aaa","uuuid":"d110a05ccde65da13"}
2)?application/x-www-form-urlencode:稱為 form 表單,通過 HTML 中的 form 標簽構造出來的一種格式,這種格式的特點是,把 query string 放到 body 中了
3)?multipart/form-data:當需要在表單中上傳文件,或者包含二進制數據的時候使用。在 HTML 的 form 標簽中需要設置 enctype=“multipart/form=data“。
例如:

使用 boundary(邊界標識符,如 ---------WebKitFormBoundaryrGKCBY7qhFd3TrwA)來分割不同表單數據部分。每個部分包含自身的元數據(如 Content-Disposition 指定數據類型和名稱,Content-Type 指定具體的數據類型)。
響應中:
1)?text/plain 純文本
2) text/html? ?html 頁面
3) text/css? css 頁面
4) application/javascript js
5) application/json
6) image/png
7) image/jpg
.....................
補充:

我們后面自己寫服務器程序返回網頁,如果發現網頁亂碼,就可以檢查一下是否是這里的編碼方式沒有設置或者是設置的不對~
User-Agent(簡稱 UA)
表示瀏覽器/操作系統的屬性,描述了用戶使用什么樣的設備上網
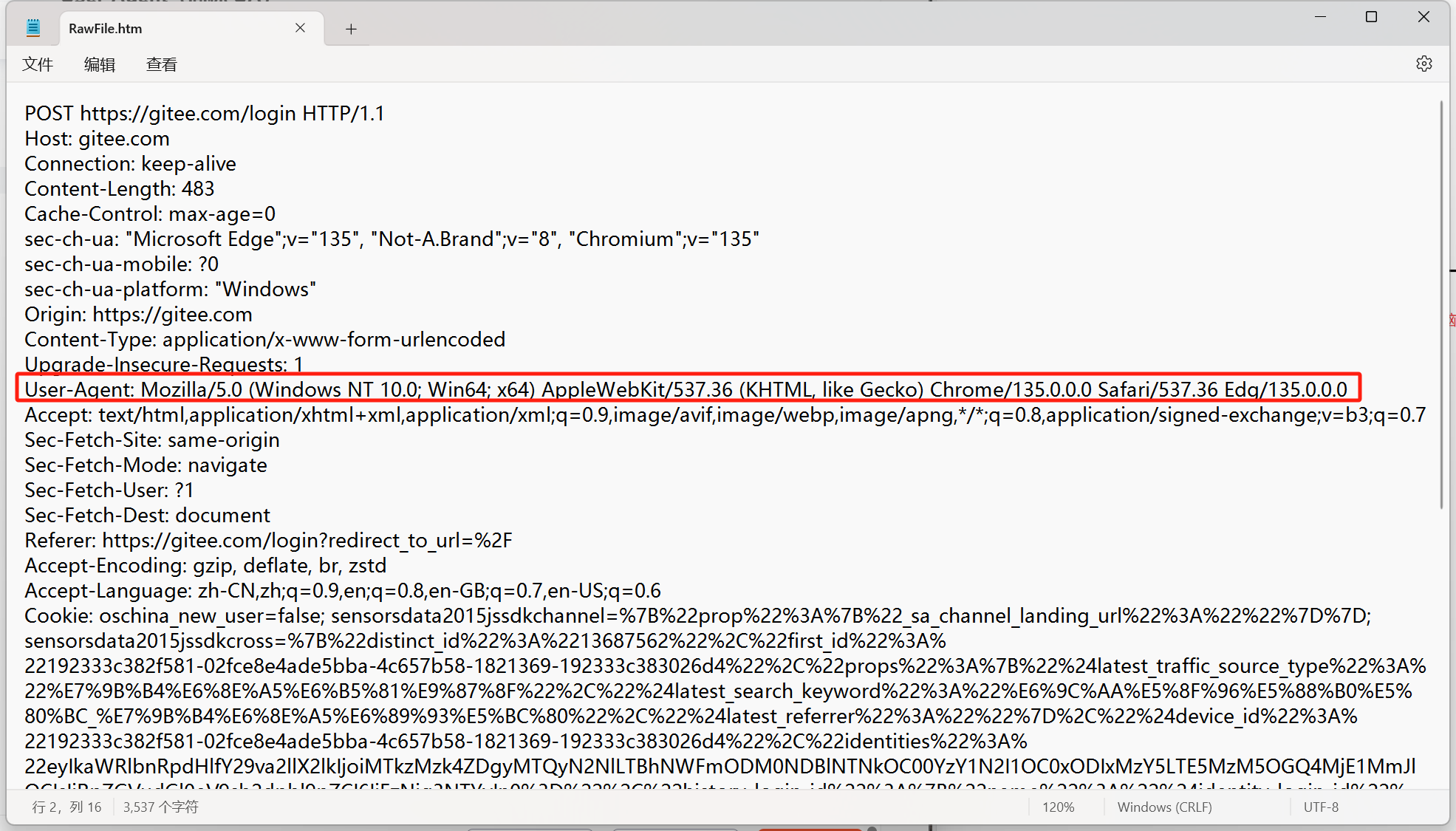
Windows NT 10.0 Win64; x64 ==> 操作系統信息
Chrome/121.0.0.0 Safari/537.36 Edg/135.0.0.0 ==》 瀏覽器信息~~
上古時期,UA 是非常關鍵的內容,由于計算機發展迅速,不同用戶使用的上網設備,差異很大,UA 就可以表明該用戶上網的設備具體是什么信息,如何用戶使用的是比較老的設備,返回的頁面就不含新特性,確保這個頁面可以正確的訪問出來。如果用戶使用的是新設備,返回的頁面就包含新的特性,確保這個頁面體驗感足夠好~~
隨著時間推移,瀏覽器現在都差不多了~~ 但 UA 仍然很有用,很多網站在 PC 端和手機端,由于其設備的大小區別,返回的頁面布局也會有所差異,這就是通過 UA 來進行控制的~~
Referer
表示這個頁面是從那個頁面跳轉過來的。在瀏覽器中,直接輸入 URL 或者點擊收藏夾打開的網頁,此時是沒有 Refere 的
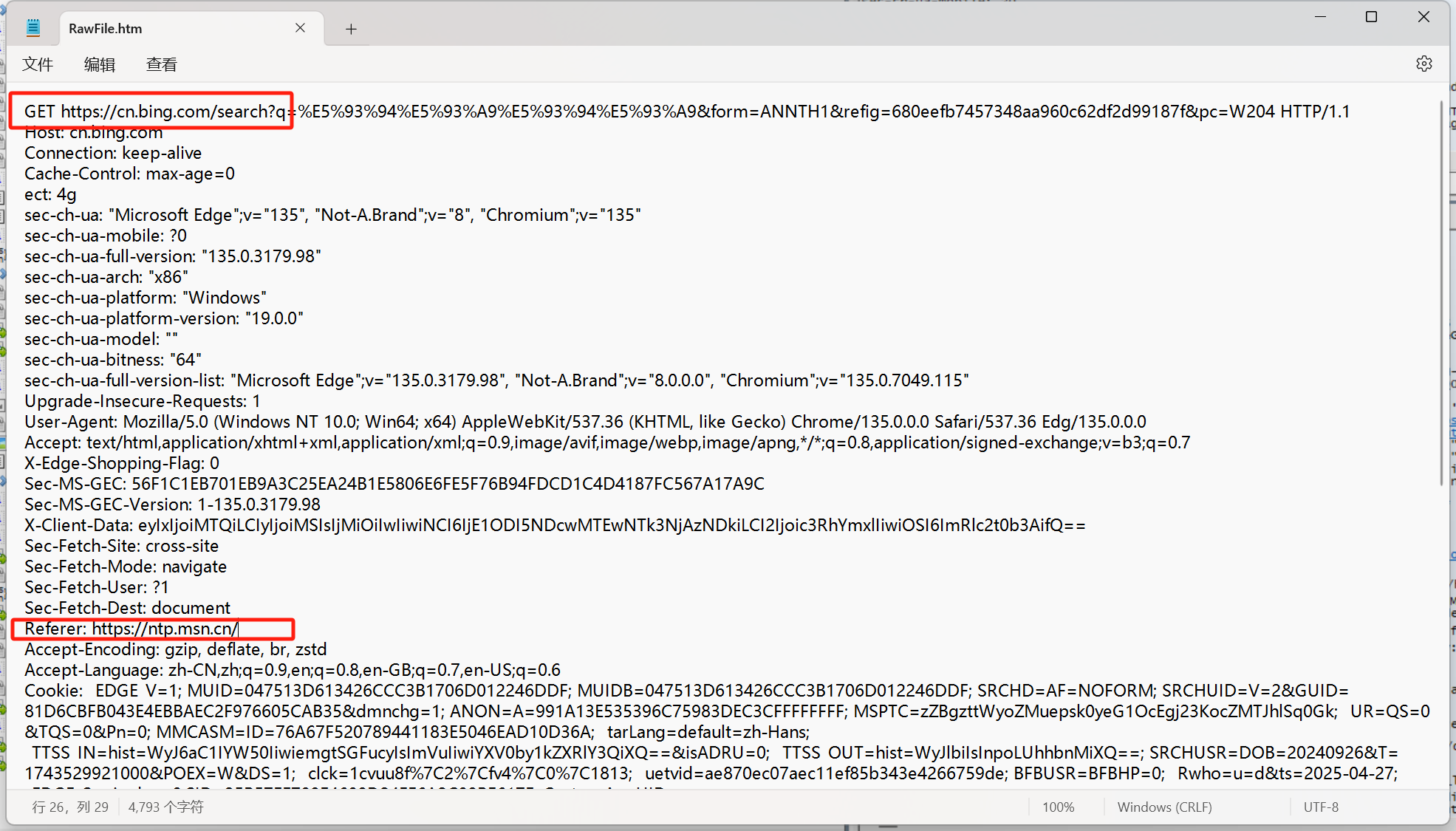
舉例:
我有個朋友~~~當年做的是廣告頁面~~~搜索廣告中,都是按照點擊計費的,用戶每次點擊廣告,負責的企業都能賺錢,所以必須要記錄某個廣告在某個時間段內被點擊多少次。
比如說在百度中搜索“腎虛”,當我們用戶點擊一下,百度就能到賬 money~~
這個點擊次數,百度和廣告主都要進行統計~~
百度中,用戶點擊就會把請求發送到百度的計費服務臺,通過記錄日志就知道了~~
廣告主中,就在他的服務器上記錄日志,但一個廣告,一般不會僅僅就找一家平臺,他會找 360,搜狗等等~他怎么知道那些請求是百度的廣告引流過來的呢??? ==》借助 referer 即可~~
問題來了 referer 是否會被篡改呢??? ==》 很有可能!!
因此就有了 HTTPS 的出現~~ 這個 S 其實是 SSL(網絡中用于加密的協議~~)
加密就能把 header 和 body 都進行加密,網絡上傳輸的就是密文了~~
其他人要想修改,就得先進行破解,就算能破解,也無法篡改,一旦進行修改操作,用戶的瀏覽器就能感知到了~~~
Cookie
Cookie 本質上是一個瀏覽器這邊本地持久化存儲數據的機制。
瀏覽器作為電腦上的一個程序,是可以直接讀寫本地磁盤文件的,系統提供了一個 API 操作文件。注意的是,瀏覽器上運行的網頁,理論上也是可以通過瀏覽器提供的 API 來讀寫本地的磁盤文件,但是瀏覽器禁止了這種做法(瀏覽器并沒有給網頁提供這樣的 API) (不安全~~ 萬一黑客通過網頁,直接把我們 C 盤中的學習資料刪了怎么辦??? /哭 /哭 ~~)
但話又說回來,有些網站,是需要把一些信息保存到瀏覽器這邊的,比如當前登錄的用戶身份信息~~ 瀏覽器退而求其次,給網頁提供了 API,但這個 API 只能是有限度的存儲數據,而不能隨意的訪問文件系統~~
HTTP 請求中的 Cookie 字段,就是把本地存儲的 Cookie 信息發送到服務器這邊。
HTTP 響應中會有一個 Set-Cookie 字段,就算服務器告訴瀏覽器你要在本地保存那些信息。
上述的請求和響應字段,都是以鍵值對的形式進行的(程序員可以自定義~~)
Cookie 中存儲了一個字符串,這個數據可能是客戶端(網頁)自行通過 JavaScript 寫入的,也可能是來自于服務器(服務器在 HTTP 響應的 header 中通過 Set-Cookie 字段給瀏覽器返回數據)
一般可以通過這個字段來實現“身份標識”的功能。(每個不同的域名下都可以有不同的 Cookie,不同網站之間的 Cookie 并不沖突~)
舉個例子:
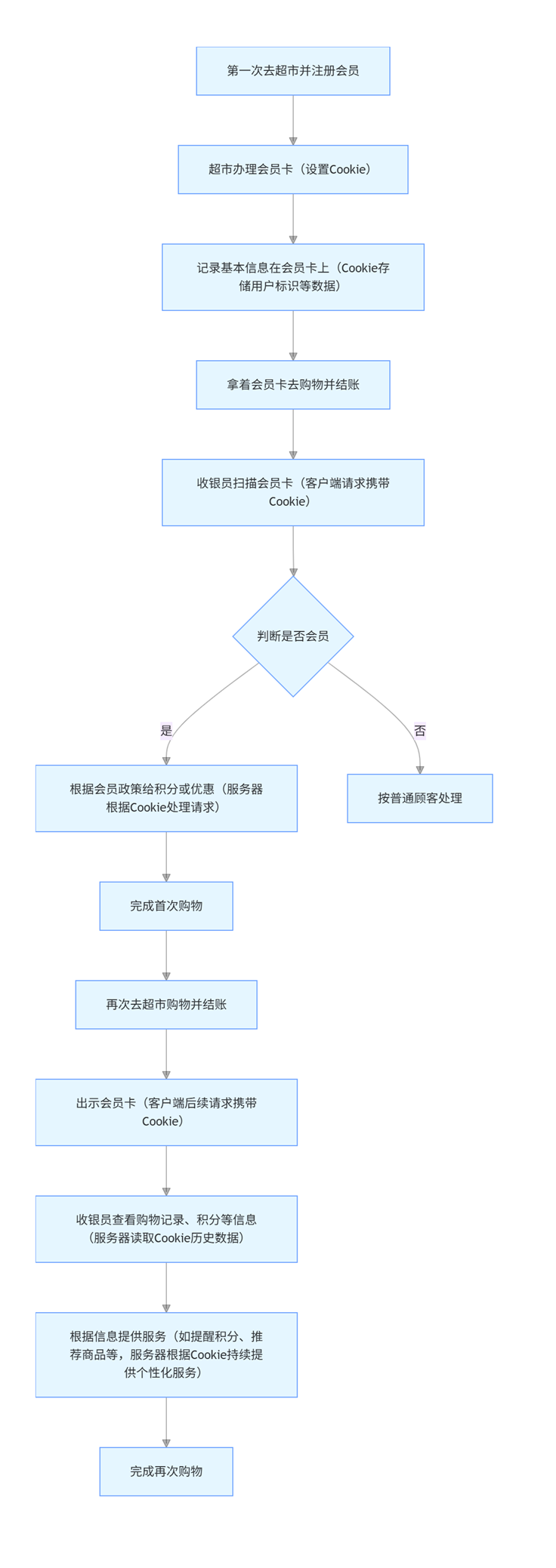
Cookie 的作用,非常類似于超市買東西時候的購物卡流程~~
1. 注冊會員(初始設置 Cookie)
當我們第一次去超市,注冊稱為會員之后,超市會給我們辦一張會員卡,這就類比是服務器給客戶端設置 Cookie。會員卡上記錄了我們的信息,比如姓名,會員卡號,積分等等,這些信息就如同 Cookie 里面存儲的用戶標識等基礎數據
2. 首次購物(第一次請求攜帶 Cookie)
當我們再收銀臺結賬的時候,收銀員會掃描我們的會員卡。這就類似于客戶端向服務器發起請求的時候帶上了 Cookie。收銀員通過會員卡,就可以知道我們是會員,會根據會員的政策給我們積分或者相關的優惠,就像服務器根據 Cookie 里面的信息,來識別出用戶,并作出響應的處理,比如提供個性化的頁面展示或服務~~
3. 再次購物(后續請求攜帶 Cookie)
之后我們再去超市購物,結賬的時候每次都出示會員卡。收銀員每次都能夠通過會員卡來了解到我們之前的購物記錄,積分情況等,然后根據這些信息為我們提供服務~~比如提醒我們,積分快能兌換禮品了,或者根據我們的購物偏好,來推薦一些商品。這就如同客戶端后續每次向服務器發送請求時,Cookie 持續發揮作用,讓服務器可以基于之前的交互歷史,持續為用戶提供連貫,個性化的服務~~
流程圖如下:
關于 Cookie 的幾個重要結論:
1. Cookie 從哪里來???
服務器返回給瀏覽器的。通常都是首次訪問/登錄成功之后。
2. Cookie 到哪里去???
Cookie 會存儲在瀏覽器本地主機的硬盤上。后續每次訪問服務器都會帶上 Cookie。不同的客戶端,保存的 Cookie 是不同的,即使是同一個主機,使用不同的瀏覽器,Cookie 大概率也不同。
3. Cookie 中存儲什么???
Cookie 以鍵值對的形式對數據進行存儲。這里的內容都是程序員自定義的,和 query string 一樣,外人無從理解~ 不同的網站的 Cookie 是不同的~
4. Cookie 在瀏覽器這邊如何組織???
在硬盤本地保存,是按照不同的域名為維度,分別進行存儲。
5. Cookie 的用途是什么???
用來在客戶端保存數據,其中最主要的就是保存用戶的身份標識,使得服務器可以通過標識來區分用戶了,一般其他的業務不會存在 Cookie 中~~
我們可以通過抓包來觀察一下頁面登錄的過程(以 gitee 為例):
1) 清除之前的 Cookie
2) 登錄操作:
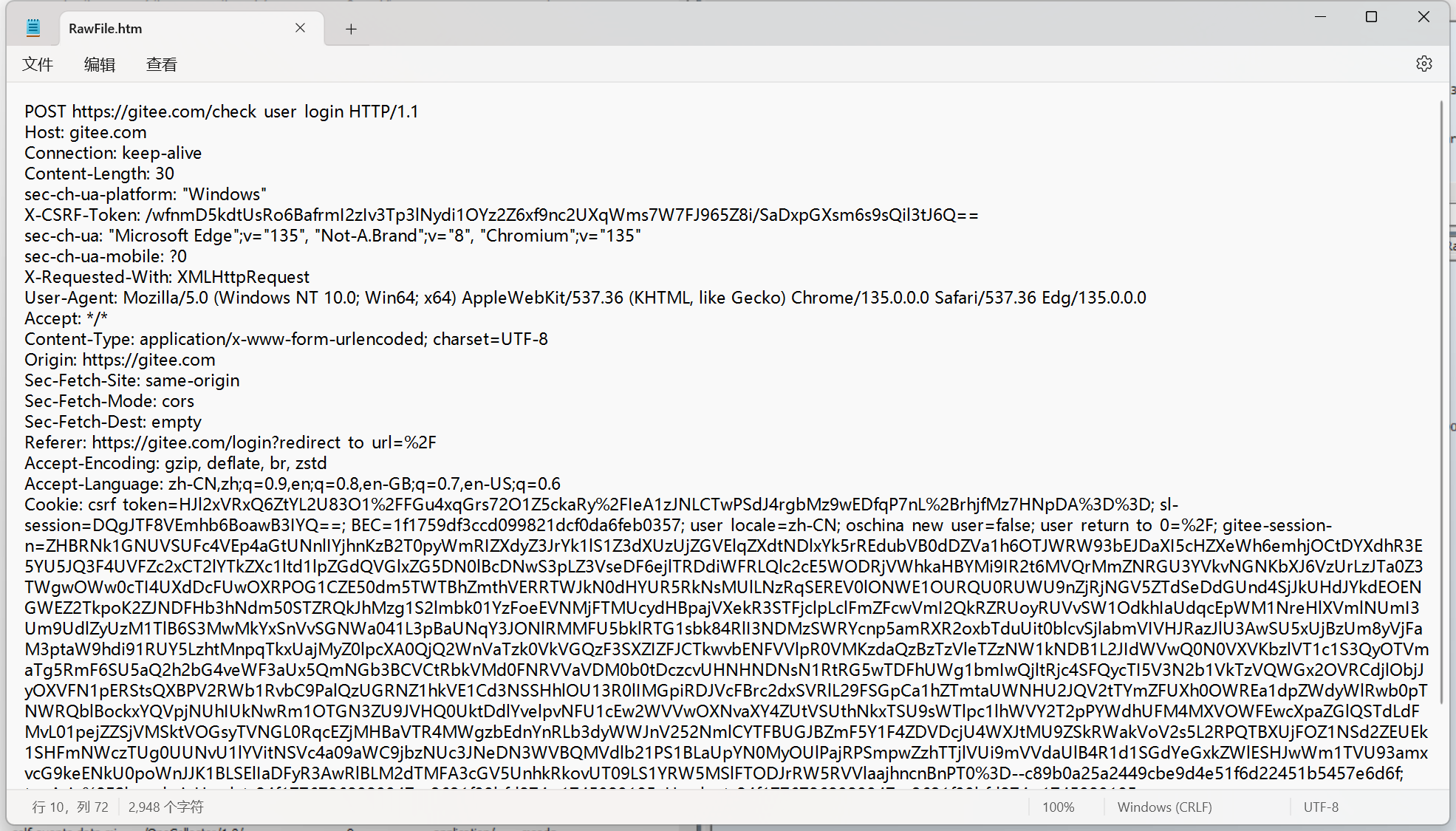
登錄請求:
登錄響應:
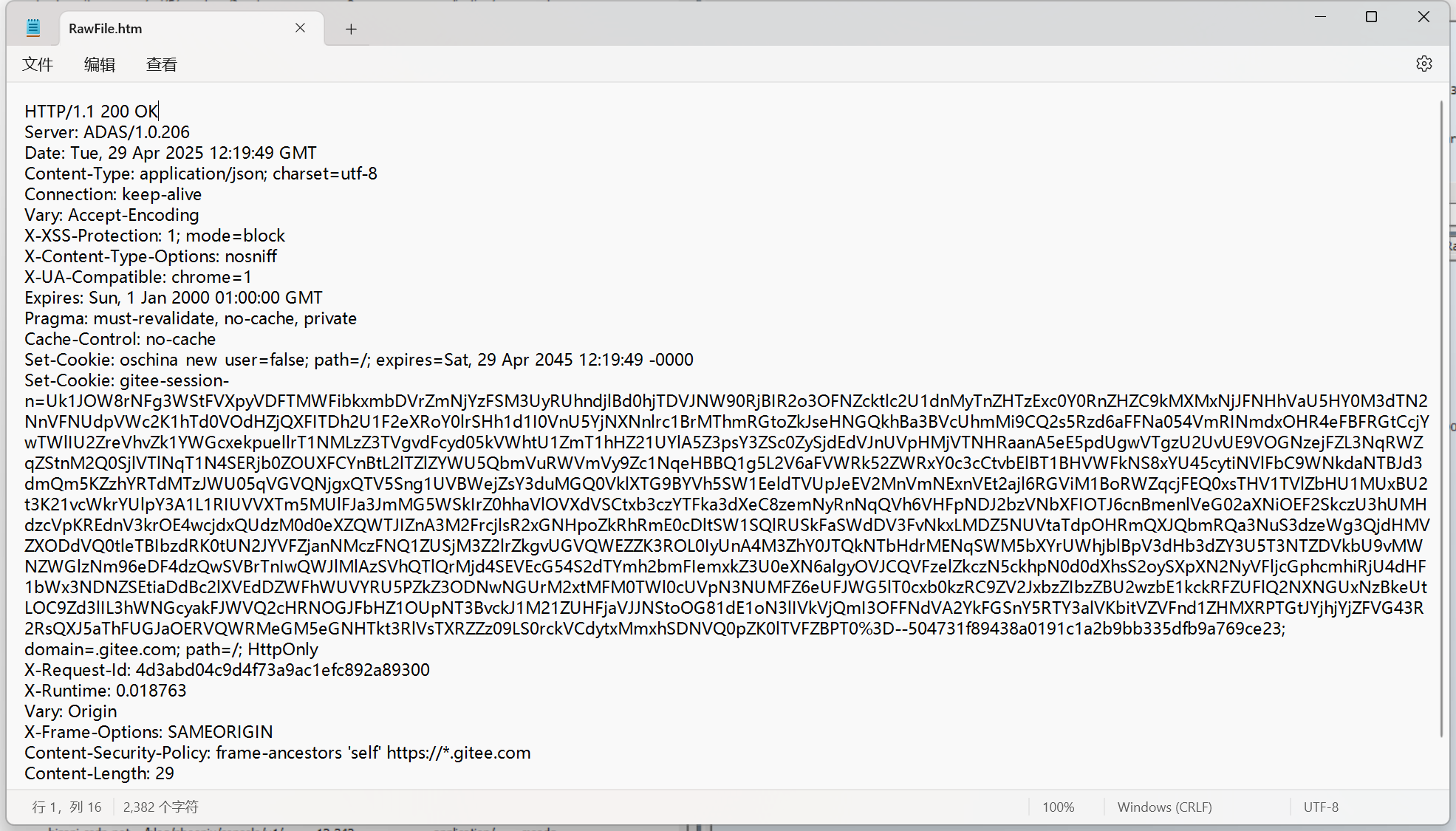 可以看到,響應中包含了 Set-Cookie 屬性
可以看到,響應中包含了 Set-Cookie 屬性
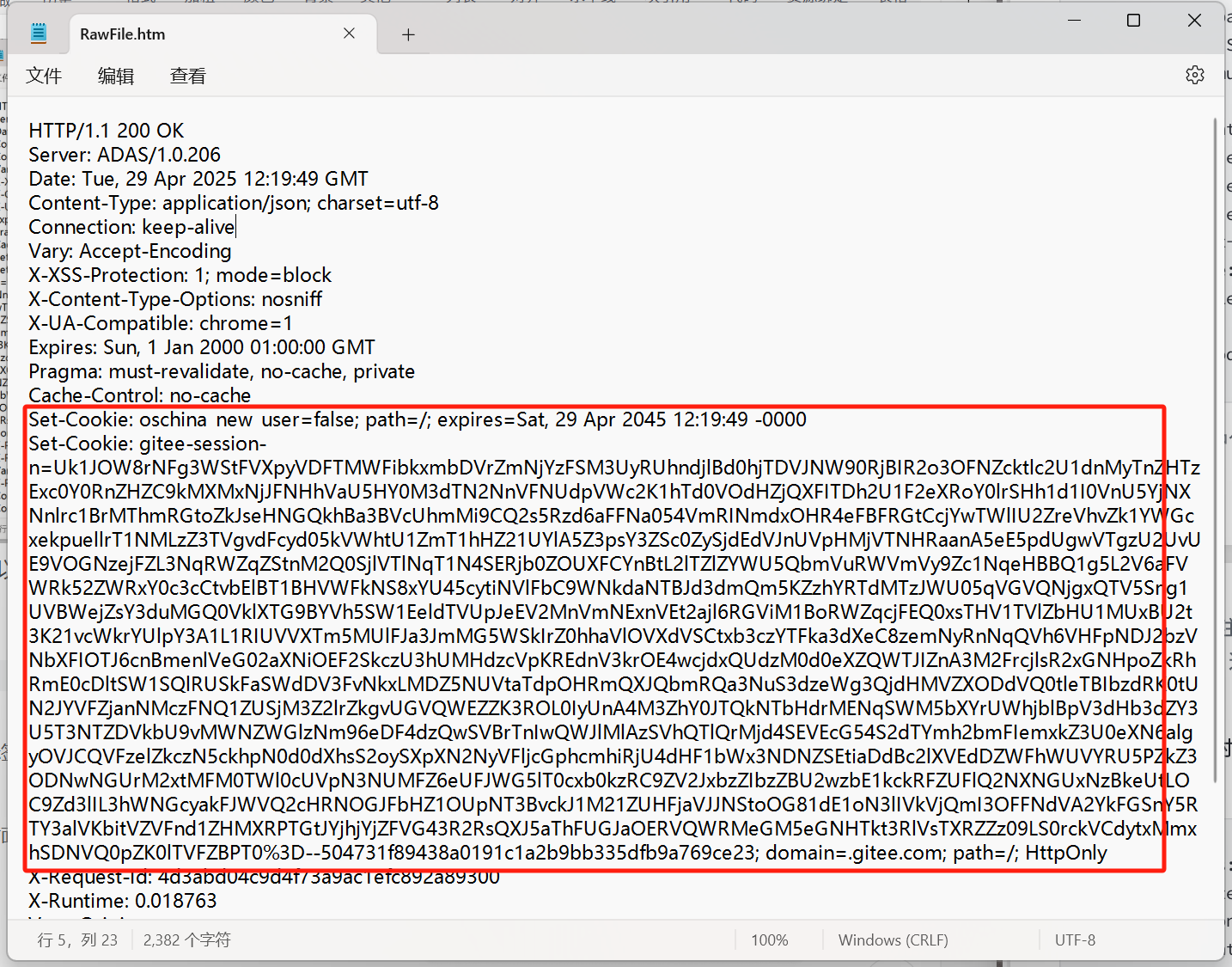
其中我們重點看一下第二個,里面包含了一個 gitee-session-n 這樣的屬性,屬性值是一串很長的加密之后的信息。這個信息就是用戶當前登錄的身份標識,也稱為“令牌(token)”。
3) 訪問其他頁面
當我們登錄成功之后,此時訪問碼云中的其他頁面(比如個人主頁),請求中就會帶著剛剛獲取到的 Cookie 信息。
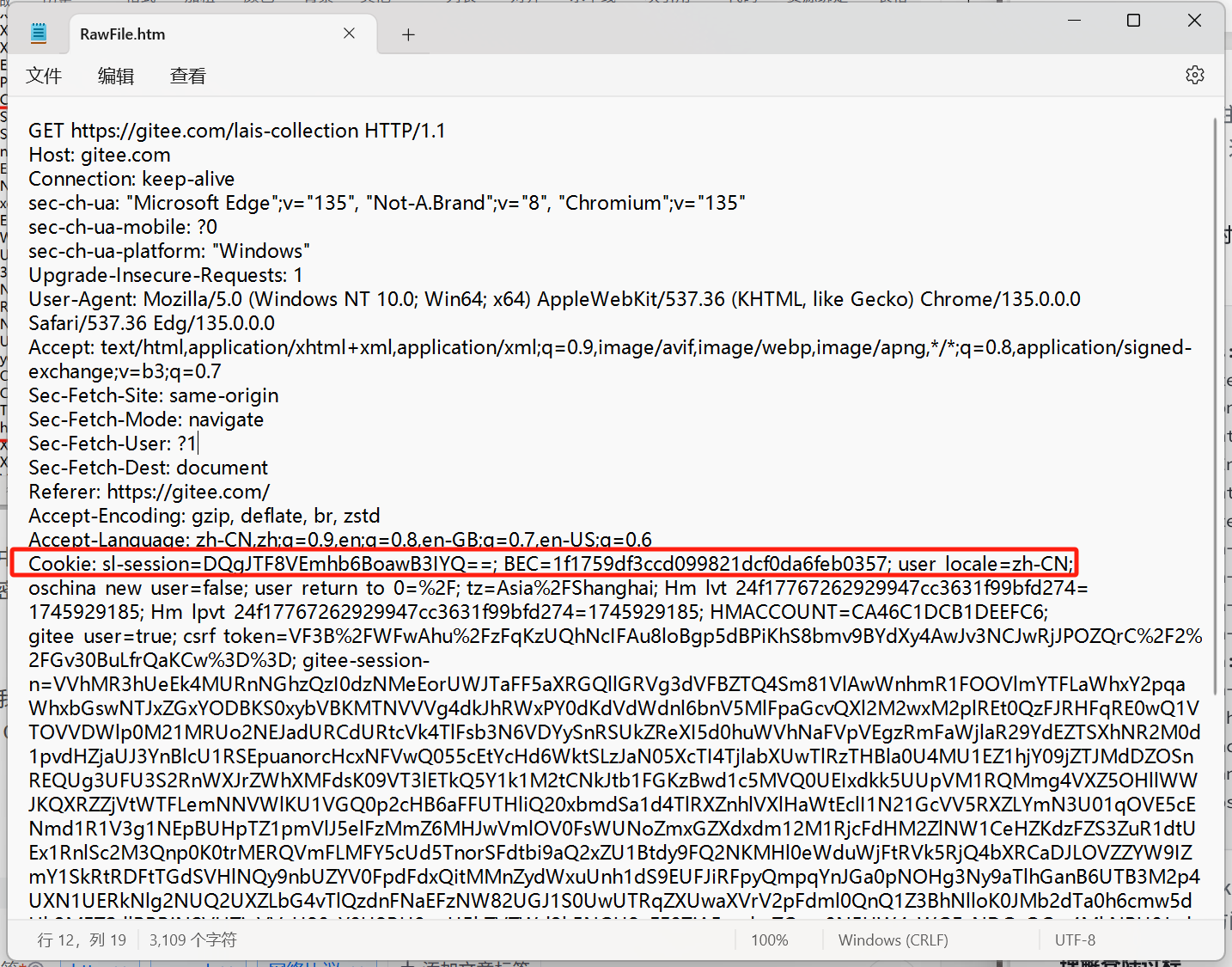
我們的請求中的 Cookie 字段也包含了一個 gitee-session-n 屬性,里面的值和剛才服務器返回的值相同,后續只要訪問 gitee 這個網站,就會一直帶著這個令牌,直到令牌過期/下次重新登錄~~
比如我們此時再訪問一個“我的星選集”,此時請求中的 Cookie 還是和之前一樣的~~
理解登錄過程:
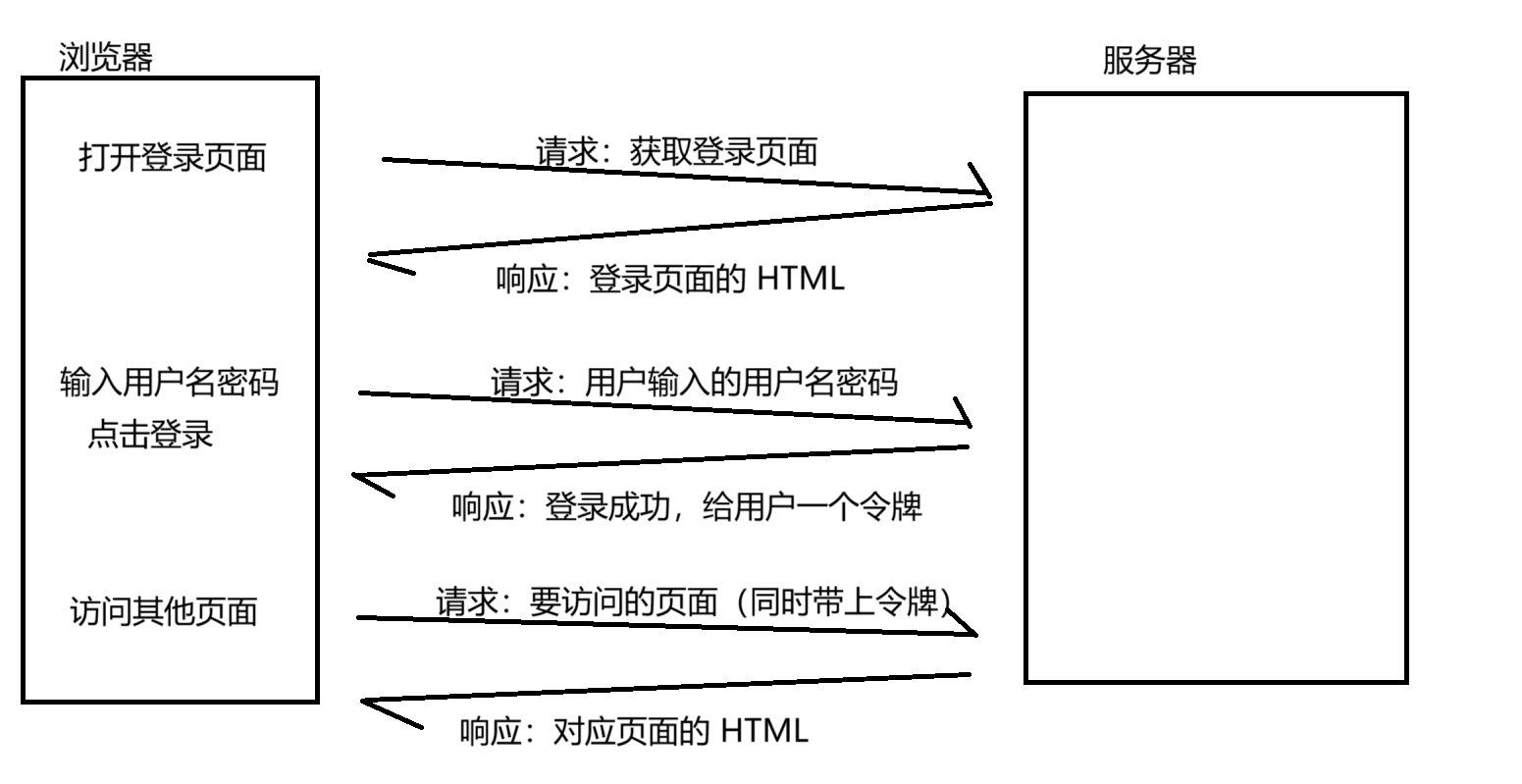
這個過程再結合我們前面去超市買東西例子:
首次進入超市后,就是打開登錄頁面。當我們第一次結賬提供手機號信息辦會員卡的時候,就是輸入用戶名密碼,點擊登錄,此時就得到了一張“會員卡”,這張會員卡就相當于是我們的“令牌”。
此后再去超市進行購物,積分兌換獎品等等操作,就不需要再提供手機號了,只需要憑會員卡就可以識別出我們的身份了。
當我們要搬家的時候,不想要會員卡了,就可以注銷這個卡,此時我們的身份就和會員卡的關聯就銷毀了(類似于網站的退出登錄操作)
當我們之后再搬回來,又想在超市買東西,就可以再辦一張會員卡,此時就得到了一個新的令牌~~
認識請求“正文”(body)

正文中常見的就是我們上面 Content - Type 中的一些格式內容~~



)







)


:深入剖析synchronized關鍵字的底層原理)





