目錄
一、Redis概述
二、Redis類型及編碼
三、Redis對象的編碼
1. 類型&編碼的對應關系
2. string類型常用命令
(1)string類型內部實現——int編碼
(2)string類型內部實現——embstr編碼
?編輯
?(3)string類型內部實現——raw編碼?
3. list類型常用命令
(1)列表常用操作
(2)list類型內部實現——ziplist編碼
?(3)list類型內部實現——linkedlist編碼
4. set類型常用命令
(1)set類型內部實現——intset編碼
(2)set類型內部實現——hashtable編碼?
5. zset類型常用命令
(1)zset類型內部實現——ziplist編碼
(2)zset類型內部實現——skiplist編碼?
6. hash類型常用命令
(1)hash類型內部實現——ziplist編碼
四、Redis數據結構
1. SDS簡單動態字符串
2. 為什么Redis使用SDS而不是C字符串?
(1)SDS空間預分配
(2)SDS惰性空間釋放
3.?list雙向鏈表
(1)list雙向鏈表源碼部分
(2)list雙向鏈表數據結構及特點
4. 哈希表
(1)哈希表源碼部分
(2)哈希表數據結構
5. dict字典
(1)dict字典源碼部分
(2)Dict字典數據結構
6. skiplist跳躍表
(1)skiplist跳躍表源碼部分
(2)跳表的數據結構
五、Redis持久化
1. RDB概述
2. RDB的備份與恢復
3. AOF概述
4. appendfsync配置詳解
5.?什么叫寫入?什么叫同步?有什么區別呢?
6. AOF加載流程
7. AOF重寫
六、三種特殊數據類型
1. geospatial地理位置
2. hyperloglog預估集合的基數
3. bitmap位圖
七、事務管理
事務中異常的處理
八、發布訂閱
1.?Redis針對發布訂閱相關指令?
九、主從復制
1. 主從復制的用處?
2. 主從復制實現原理
?3. psync指令
4. 復制偏移量
5. 復制積壓緩沖區&節點ID
十、Redis哨兵
1. 多哨兵模式
2. 環境搭建(3哨兵 1主2從)
3. INFO指令獲得最新節點拓撲圖
4.?哨兵監測集群狀態方法
5. 選舉流程
十一、Redis Cluster
1. 分片方式
(1)哈希取模
(2)一致性哈希
(3)虛擬節點 + 一致性哈希
2. 集群搭建
十二、面試
1. 緩存穿透(查不到數據)
2. 緩存擊穿(高并發查詢某數據,且緩存過期)
3. 緩存雪崩(緩存大批量失效或Redis宕機)
4. 布隆過濾器
面:
數據結構:String、hash、set、zset、list
什么是RDB?RDB和AOF的區別:
一、Redis概述
Redis就是緩存,Redis基于內存,將大量訪問的數據放到緩存,而不是數據庫,這樣不會訪問數據庫,如果都放到內存,內存是jvm中的,無法保證多線程共享同一份內存,所以使用Redis。
數據存在內存中,但是可以對其進行持久化,這樣內存宕機之后,數據也不會丟失。
Redis是開源的(BSD許可),數據結構存儲于內存中,被用來作為數據庫,緩存和消息代理。 它支持多種數據結構,例如:字符串(string),哈希(hash),列表(list),集合(set), 帶范圍查詢的排序集合(zset),位圖(bitmap),hyperloglog,帶有半徑查詢和流的地理 空間索引(geospatial)。 Redis具有內置的復制,Lua腳本,事務和不同級別的磁盤持久性, 并通過Redis Sentinel(負責主從情況下選主)和Redis Cluster自動分區提供高可用性。
安裝Redis
官網 :Downloads - Redis
- 啟動redis服務端:src/redis-server --daemonize yes
- 開啟redis客戶端:src/redis-cli
Redis Sentinel
二、Redis類型及編碼
5種基本數據類型:String、hash、set、zset、list
Redis是key-value鍵值對,key肯定是string類型的,value是RedisObject類型的,包括多種類型。
- OBJECT encoding key:可以查看key對應的value的encoding類型。
三、Redis對象的編碼
| encoding常量 | 編碼所對應的底層數據結構 |
| REDIS_ENCODING_INT | long類型的整數 |
| REDIS_ENCODING_EMBSTR | embstr編碼的簡單動態字符串 |
| REDIS ENCODING_RAW | 簡單動態字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 雙向鏈表 |
| REDIS_ENCODING_ZIPLIST | 壓縮列表 |
| REDIS_ENCODING_INTSET | 整數集合 |
| REDIS_ENCODING_SKIPLIST | 跳表和字典 |
跳表的概念重要:因為可以快速查詢,比樹結構好維護,查詢效率也不會差多少?
1. 類型&編碼的對應關系
| 對象類型(type) | 對象編碼(encoding) |
| REDIS_STRING | REDIS_ENCODING_INT |
| REDIS_ENCODING_EMBSTR | |
| REDIS_ENCODING_RAW | |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_LINKEDLIST | |
| REDIS_SET | REDIS_ENCODING_INTSET |
| REDIS_ENCODING_HT | |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_SKIPLIST | |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_HT |
(能記住最好)
2. string類型常用命令
| 命令行 | 含義 |
| set key value | 賦值key的值為value |
| get key / del key | 獲取key的value值 / 刪除key |
| expire key seconds | 設置key在seconds秒后過期 |
| setex key seconds value | SET + EXPIRE的組合指令 |
| ttl key | 查看key還有多久過期 |
| setnx key value | 如果key不存在,才新增key和value |
| strlen key | 計算指定key的值的長度 |
| incr key value | 值加1 |
| incrby key numbers | 指定增加值,numbers可以是負值 |
| mset key1 value1 key2 value2 … | 批量添加 |
| mget key1 key2 key3 … | 批量獲取 |
用JSON的形式將對象存到value中,擴容規則:當value<=1M時翻倍擴容,當>1M時,每次擴容1M。字符串的長度不能超過512M
setex key time value :在設置key-value對象的同時設置了過期時間,
string類型的三種編碼:
| REDIS_ENCODING_INT |
| REDIS_ENCODING_EMBSTR |
| REDIS_ENCODING_RAW |
int:long長度范圍內的純數字,超過long長度范圍的話就是embstr
embstr:長度小于40位的數字+字符。一次內存分配,RedisObject和sdshdr是連續的。
raw:>=40位的數字加字符。兩次內存分配,靠指針連接RedisObject和sdshdr。訪問速度比embstr慢,但是因為不連續使得內存要求不高。
(1)string類型內部實現——int編碼
如果保存的value值,可以用long類型表示(-9223372036854775808 ~ 9223372036854775807),那么encoding就是int編碼,如果超過了long類型的長度,則會轉換為embstr編碼。
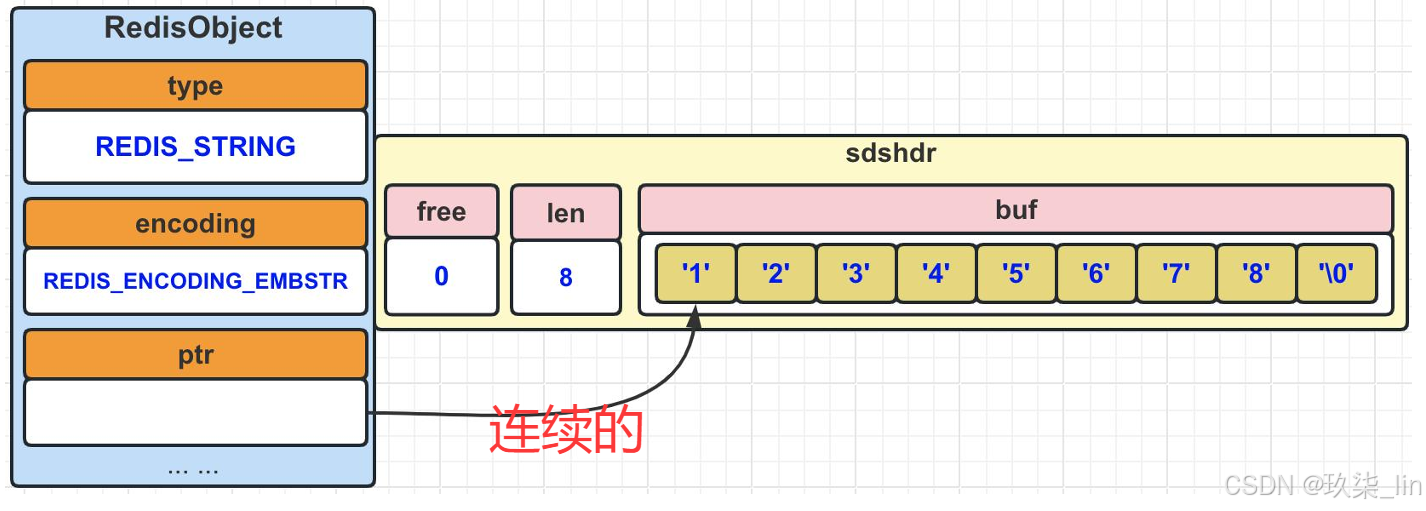
(2)string類型內部實現——embstr編碼
value值的長度如果小于40,則使用embstr,它可以保存數字類型和字符類型的值。embstr編碼是專門用于保存短字符串的一種優化編碼方式。
Redis沒有為embstr編碼的字符串對象提供修改功能,所以embstr是只讀的。如果我們對其進行修改,其實是先轉換成raw,再執行修改命令。所以,修改后embstr就會變為raw編碼的字符串對象了。
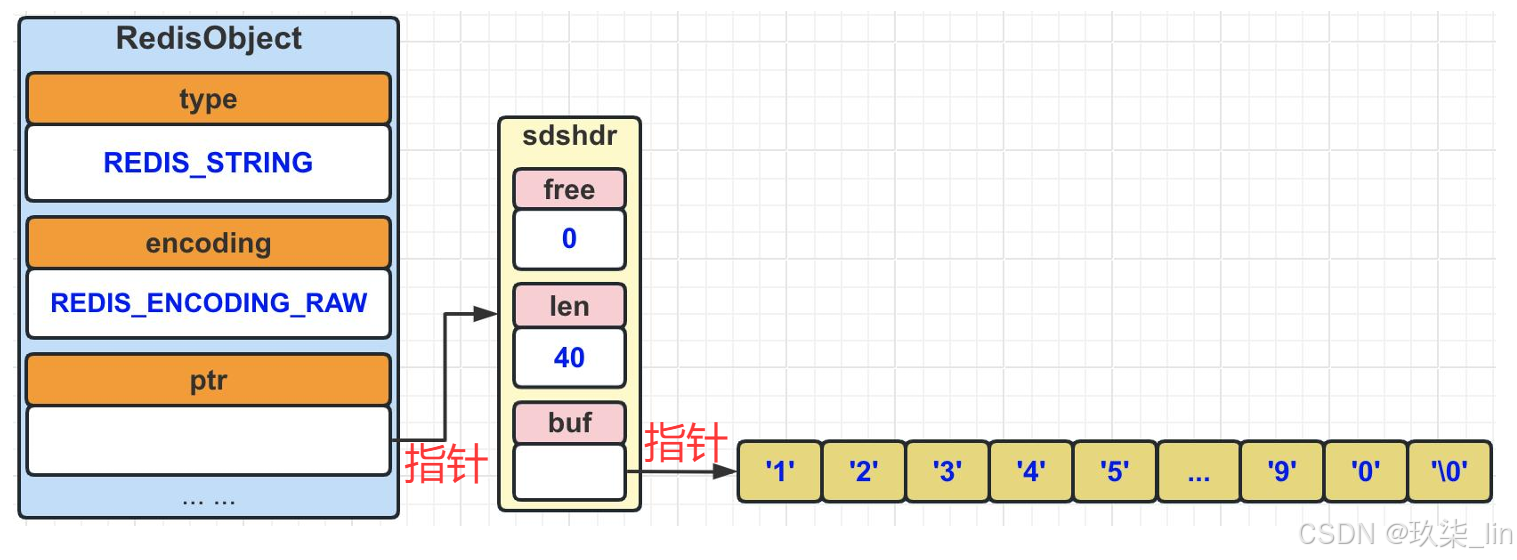
?(3)string類型內部實現——raw編碼?
當value值的長度如果大于等于40時,則使用raw編碼。
如果將原本保存的整數轉換為字符串,那么字符串對象的編碼也將從int變為raw。
3. list類型常用命令
| 命令行 | 含義 |
| lpush key value1 value2 | 左側插入value |
| rpush key value1 value2 | 右側插入value |
| lpop key | 左側彈出value |
| rpop key | 右側彈出value |
| llen key | 查看key的長度 |
| lindex key index | 查看列表中某個index對應的value值 |
| lrange key startIndex endIndex | 查看指定元素,下標從0開始,-1為倒數第一個 |
| ltrm key startIndex endIndex | 僅保留某區間的列表,其余元素全被刪除 |
ltrm key start end中是去掉start之前和end之后的,保留start到end的閉區間的。ltrm key 1 0是刪除所有元素。
(1)列表常用操作
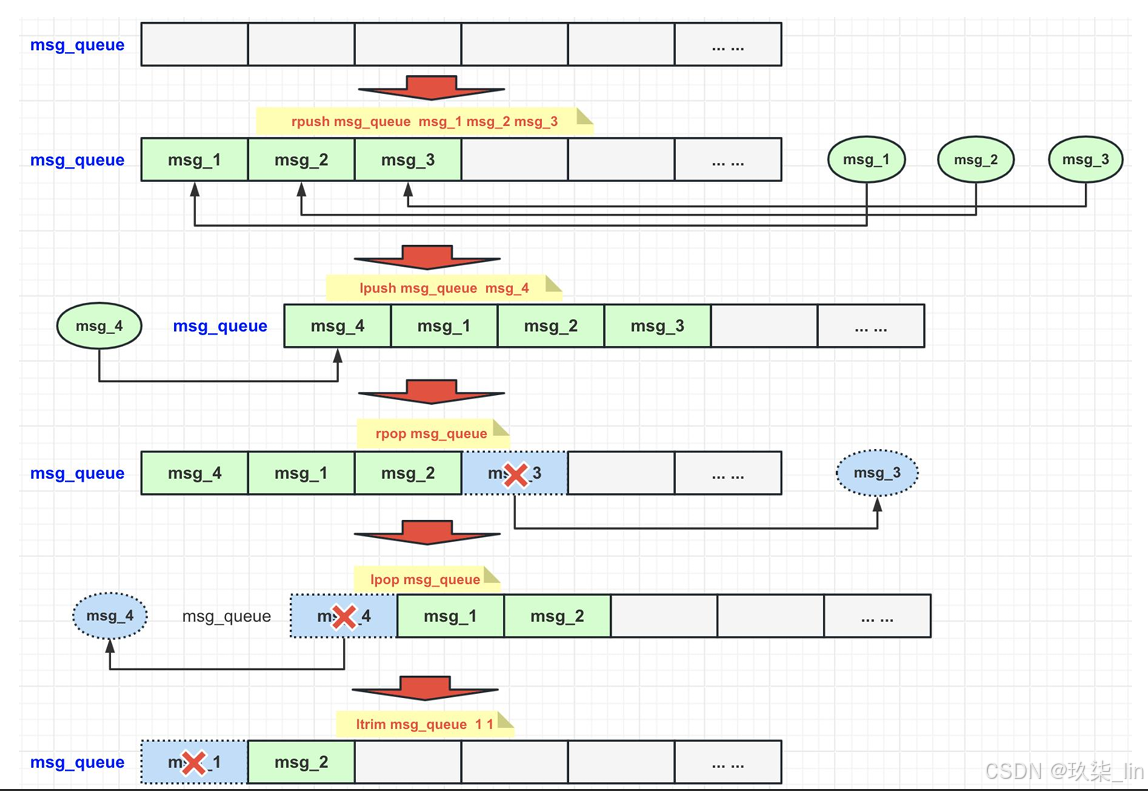
list類型的兩種編碼:?
| REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_LINKEDLIST |
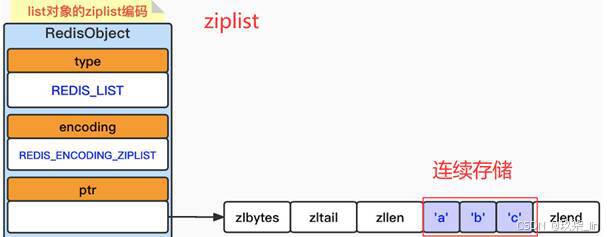
(2)list類型內部實現——ziplist編碼
ziplist編碼列表對象,采用壓縮列表實現。每個列表節點保存一個列表中的元素。當我們執行RPUSH testlist a b c之后,其數據結構如下:
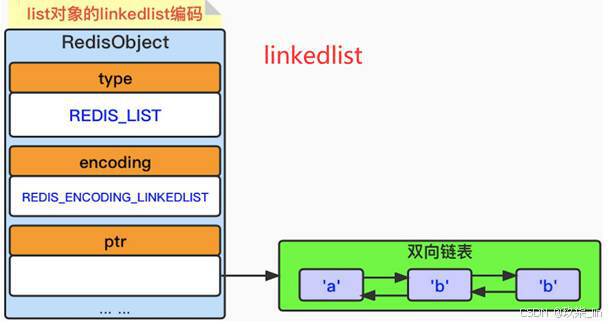
?(3)list類型內部實現——linkedlist編碼
linkedlist編碼列表對象,采用雙向鏈表作為底層實現,每個節點保存一個元素。數據結構如下:
如果滿足所有元素長度小于65字節 并且 列表中元素的個數小于512個是ziplist類型,否則是linkedlist類型;連續存儲,內存連續時訪問速度是最快的
4. set類型常用命令
Set類型:主要目的是去重
| 命令行 | 含義 |
| sadd key value1 value2 | 添加元素到集合中 |
| smembers key | 查看集合中的所有元素 |
| sismember key value | 查看value是否在集合中 |
| scard key | 查詢集合的長度 |
| spop key | 取出集合中的一個元素 |
| del key | 刪除集合 |
set類型的兩種編碼:
| REDIS_ENCODING_INTSET |
| REDIS_ENCODING_HT |
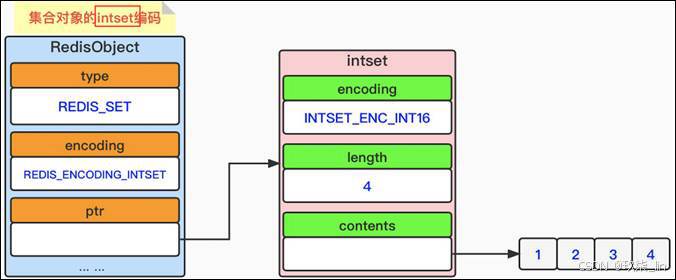
(1)set類型內部實現——intset編碼
intset編碼集合對象使用整數集合作為底層實現,集合對象包含的所有元素都被保存在整數 集合里面。數據結構如下所示:
(2)set類型內部實現——hashtable編碼?
當使用字典作為底層實現,每個鍵都是一個字符串對象,每個字符串對象包含了一個集合 元素,而字典的值則全部被設置為NULL。數據結構如下所示:
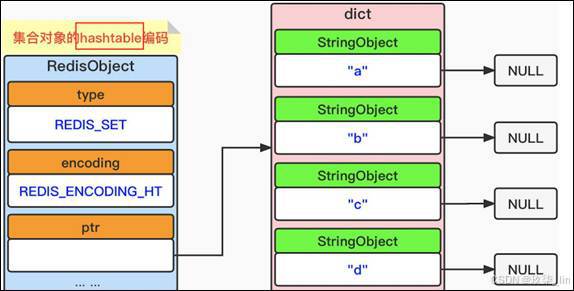
如果填加的是字符類型的,輸出的就是亂序的。如果填加的是純數字類型的話,輸出就是升序的。
當集合對象同時滿足以下 兩個條件時,使用intset 編碼,否則使用 hashtable編碼:
- ① 集合對象保存的所有元 素都是整數值。
- ② 集合對象保存的元素數 量不超過512個。
Intset -->?hashtable:
- 1. 存入幾個數字是intset,再存入字符類型的變成hashtable;
- 2. 存入了512個數字是intset,再存入一個數字也會變成hashtable。
5. zset類型常用命令
| 命令行 | 含義 |
| zadd key score1 value1 value2 score2 | 添加元素到有序集合中 |
| zscore key value | 查看key的score值,輸出score>=負無窮, score<=正無窮的所有元素 |
| zrange key 0 -1 | 正序輸出 |
| zrangebyscore key -inf +inf | 正序輸出 |
| zrevrange key 0 -1 | 倒序輸出 |
| zcard key | 查看key中的元素個數 |
| zrangebyscore key indexStart endStart | 獲得key中score>=indexStart 且 score<=endStart的元素,正序排列 |
| zrevrangebyscore key indexStart endStart | 同上,倒序排列 |
| zrem key value | 刪除key中的元素value |
| zrangebyscore key indexStart endStart | 獲得key中score>=indexStart 且 score<=endStart的元素,正序排列 |
相當于閉區間,如果想要開區間,則zrangebyscore key (indexStart endStart.
zset類型的兩種編碼:
| REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_SKIPLIST |
(1)zset類型內部實現——ziplist編碼
ziplist使用壓縮列表作為底層實現,每個集合元素使用兩個緊挨在一起的壓縮列表節點來保 存,第一個節點保存元素的成員(member),而第二個節點則保存元素的分值(score)。 壓縮列表內的集合元素按分值(score)從小到大進行排序。
當有序集合對象可以同時滿足以下兩個條件時,使用ziplist編碼,否則使用skiplist編碼:
- ① 有序集合保存的元素數量小于等于128個。
- ② 有序集合保存的所有元素長度都小于64字節。
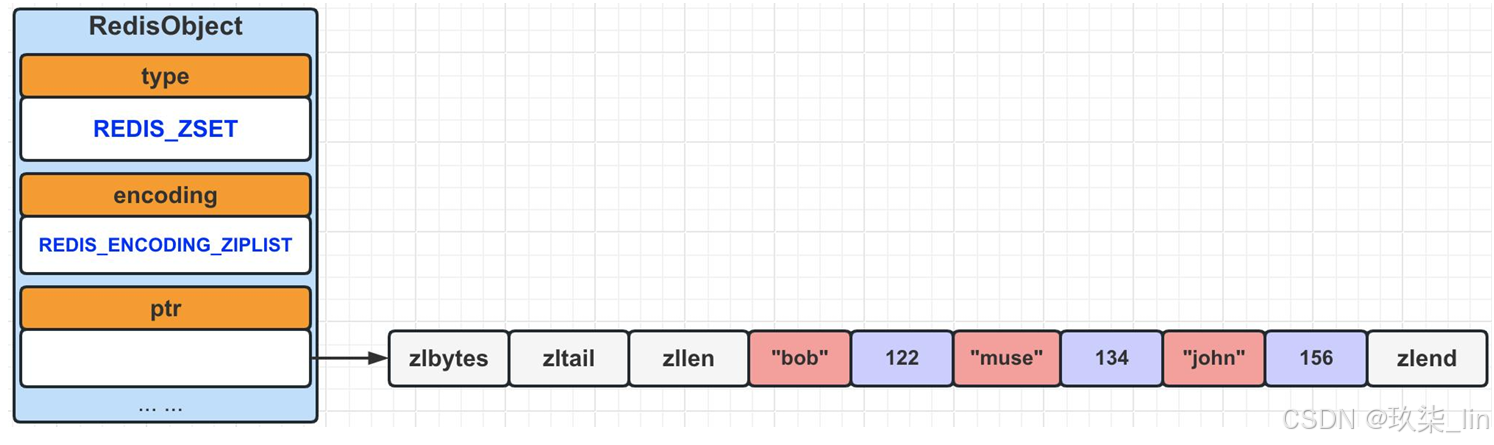
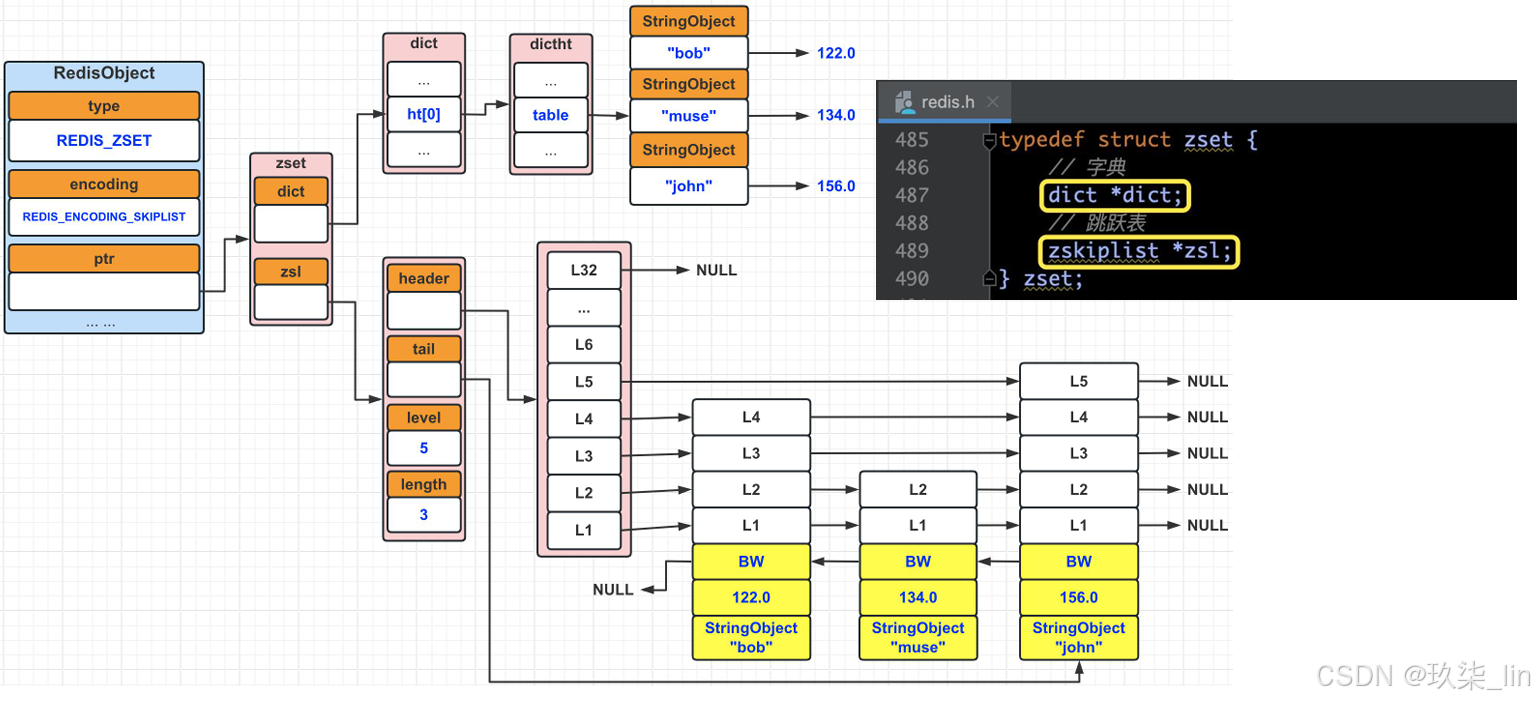
(2)zset類型內部實現——skiplist編碼?
skiplist編碼的有序集合采用zset結構作為底層實現,一個zset同時包含一個字典dict和一個跳躍表zskiplist。?
6. hash類型常用命令
| 命令行 | 含義 |
| hset key name value | 添加屬性元素name和value到key中 |
| hget key name | 查看key的name值 |
| hmset key name1 value1 name2 value2 | 批量添加key的屬性元素 |
| hmget key name1 name2 | 批量獲取key的屬性元素 |
| hlen key | 獲得key的屬性元素個數 |
| hgetall key | 查詢key中的所有元素 |
hash類型的兩種編碼:
| REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_HT |
(1)hash類型內部實現——ziplist編碼
ziplist編碼底層使用壓縮列表實現,當有新的鍵值對要加入到哈希對象時,會先將key值從 隊尾推入壓縮列表中,再將這個key對應的value值從隊尾推入壓縮列表中;所以,同一鍵 值對的兩個節點總是緊挨在一起的——key在前,value在后。

(2)hash類型內部實現——hashtable編碼
同時滿足兩個條件時是ziplist編碼類型,否則為hashtable編碼類型
- ① 哈希對象中所有鍵值對中,key和value的長度均小于等于64字節。
- ② 哈希對象中鍵值對的個數小于512個。
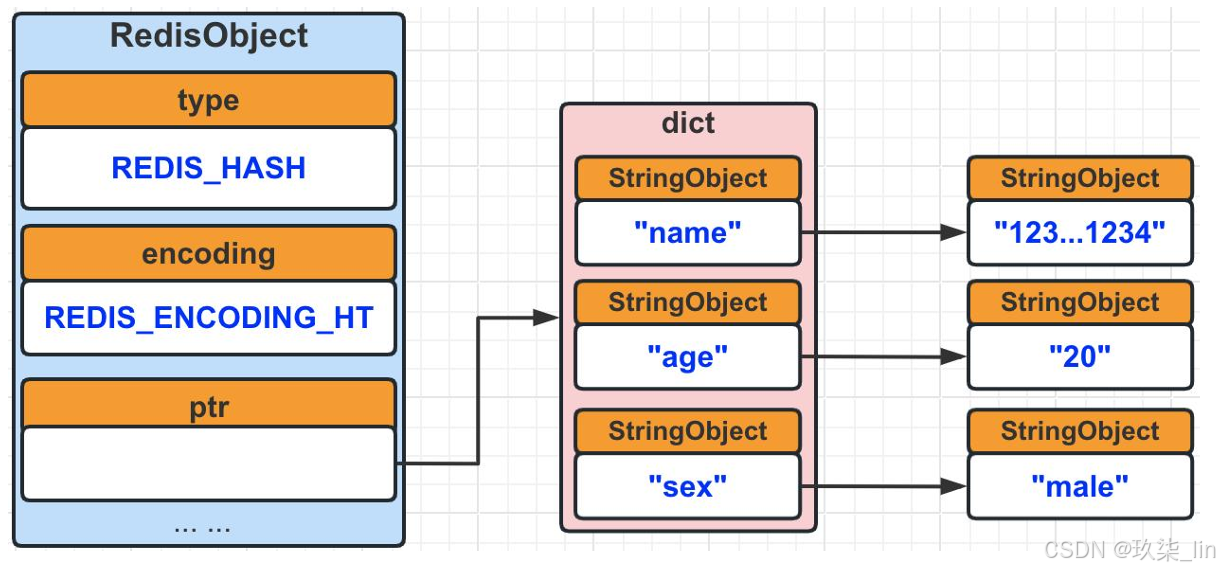
四、Redis數據結構
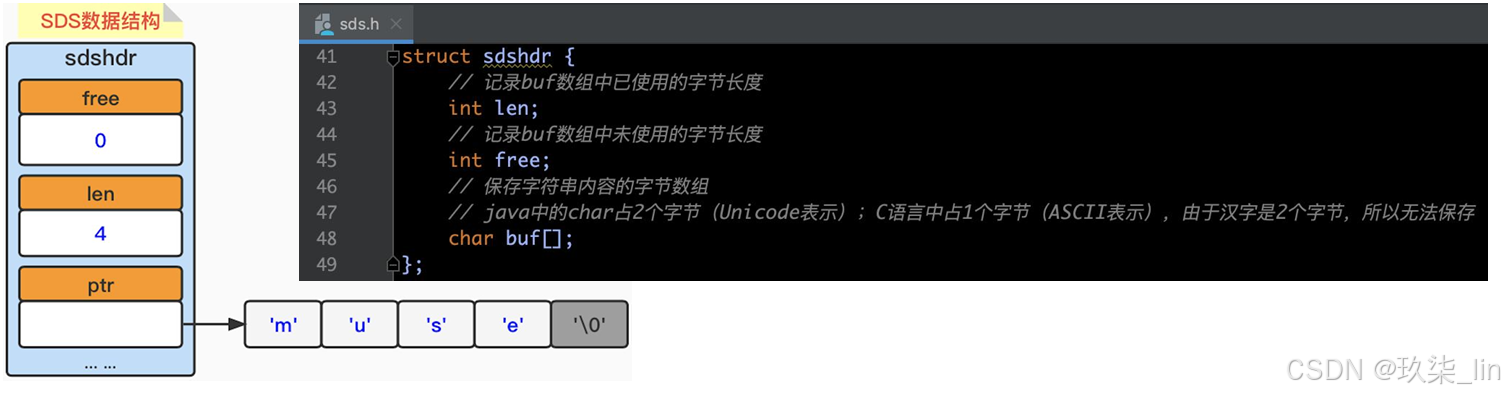
1. SDS簡單動態字符串
SDS(simple dynamic string),簡單動態字符串。是由Redis自己創建的一種表示字符串 的抽象類型。與C語言不同的是,C語言字符串是不可被修改的。但是SDS是動態可以被修 改的。
最后一位遵循C字符串的空字符('\0')結尾的規則,目的是可以直接使用C字符串的函數。 其中:len計數不包含‘\0’。
2. 為什么Redis使用SDS而不是C字符串?
第1點:C語言沒有字符串的類型,關于字符串長度的計算。C字符串沒有記錄字符個數,每次都需要遍歷,所以復雜度為 O(n)。SDS的len記錄了當前字符串的長度,所以獲取字符串長度的復雜度為O(1)。(C語言沒有字符串的類型,只能用數組表示。只能存儲數據,沒有數據計算的能力。Sdshdr中存儲了字符串的長度,當需要查詢長度的時候直接從sdshdr中獲取即可,時間復雜度O(1),而如果是C語言數組的話要去計算每個字符串的長度,時間復雜度是O(N)?)
第2點:關于緩沖區溢出。C字符串無法杜絕緩沖區溢出。比如執行strcat函數時,如果 沒有指定足夠的內存,那么拼接后會造成緩沖區溢出。SDS在進行修改時,會先查看空 間是否足夠,如果不夠了,那么它的API會自動的進行空間擴展。用name1的muse去拼接John的時候,之前的bob就會被沖掉。具體情況如下所示:
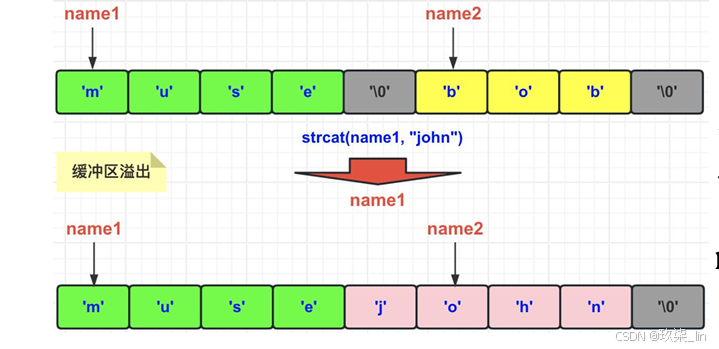
比如:之前name1是muse,name2是bob, 然后忘記在執行strcat操作之前為s1分配足夠 空間了,name1變成了musejohn,那么, name2的內容就被修改了。
第3點:SDS采用了空間預分配&惰性空間釋放來減少性能消耗。空間預分配:SDS會提前多申請一些空間(如下圖)。惰性空間釋放:當刪除了一些字符,空出來一些空間,這些空間不會被釋放,無需跟操作系統交流。而是在sdshdr中更改free記錄的空余空間數,當有新的字符串需要這些空間時,直接使用空余的空間,不需要重新請求空間。
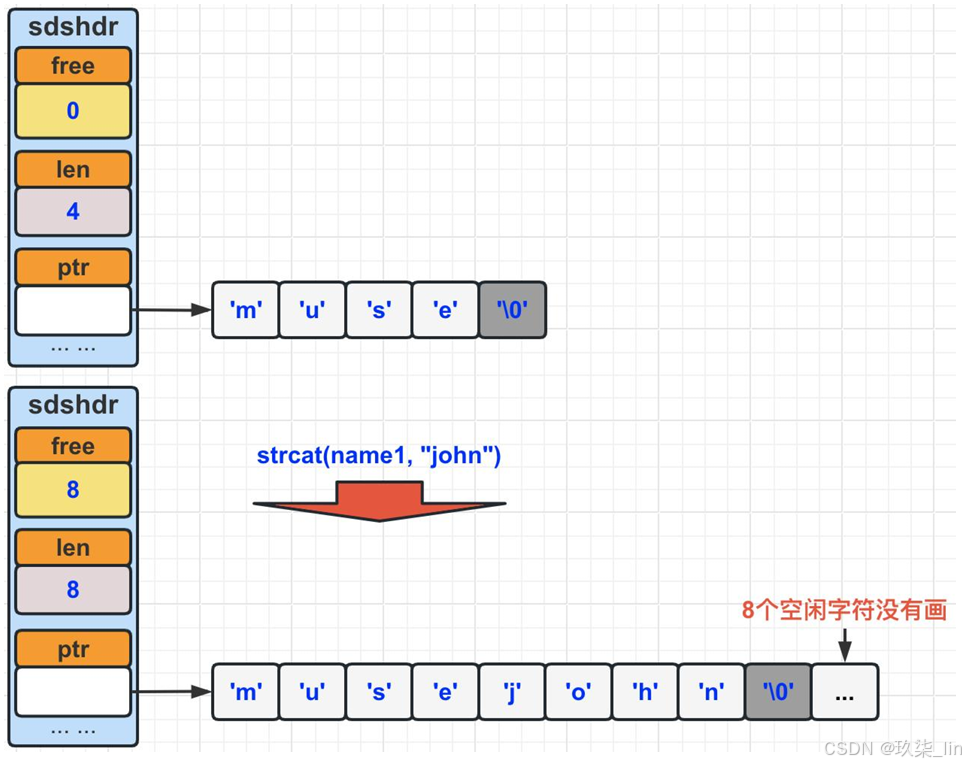
(1)SDS空間預分配
如果對SDS進行修改后,SDS的 長度(len的長度)小于1MB的 時候,那么程序分配和len屬性同樣大小的未使用空間 (free)。如果大于1MB,那么程序會分配1MB的未使用空 間(free)。
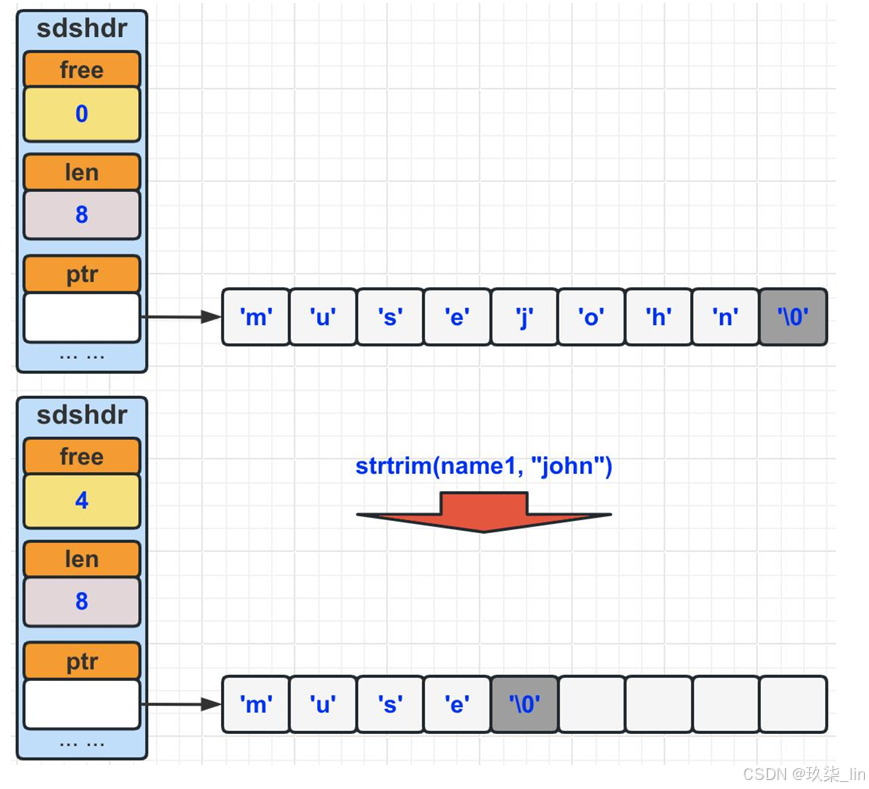
(2)SDS惰性空間釋放
當有縮短SDS字符串操作時,程序并不立即把空閑出來的字節釋放掉,而是使用free屬性將這個空閑的字節記錄起 來,等待將來使用。如右圖所示:
3.?list雙向鏈表
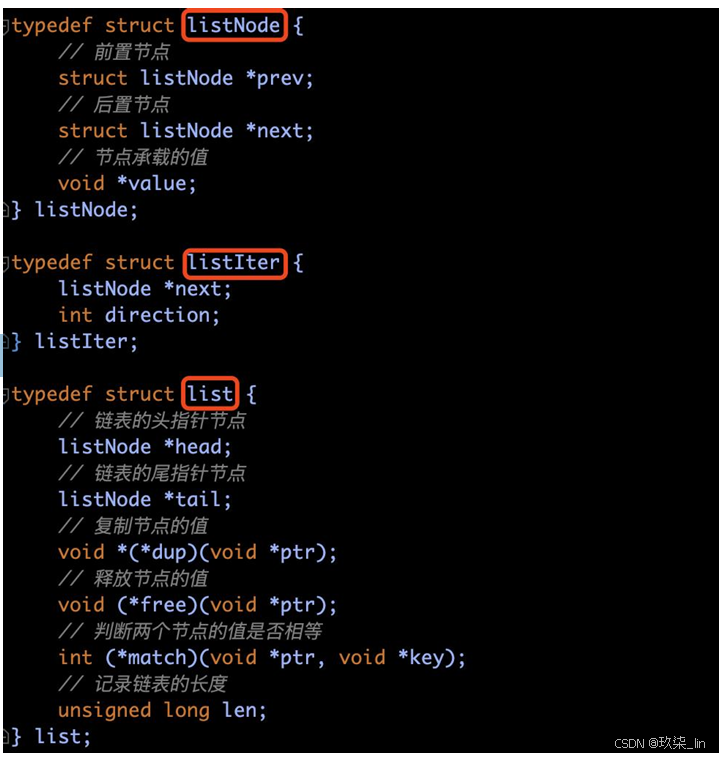
(1)list雙向鏈表源碼部分
鏈表的特點是高效的刪除和新增節點來靈活地調整鏈表中的元素順序。
由于C語言沒有內置鏈表,所以Redis自己構建 了鏈表的實現。
Redis基本數據結構中的REDIS_LIST,底層的實 現之一就采用的鏈表。即:當包含了很多元素, 或者元素中有比較長的字符串時,就會采用鏈 表作為REDIS_LIST的底層實現。
(2)list雙向鏈表數據結構及特點
雙端:具有prev和next指針,獲取某個節點的前置/后置節點的復雜度為O(1)。
無環:頭節點的prev=NULL,尾節點的next=NULL,對鏈表的訪問以NULL為終點。
帶表頭/表尾指針:list結構中包含head指針和tail指針,所以獲得鏈表頭節點/尾節點的復雜 度為O(1)。
多態性:可以通過設置dup、free、match這三個不同類型特定函數,保存各種不同類型的 節點值。
List雙向鏈表數據結構:
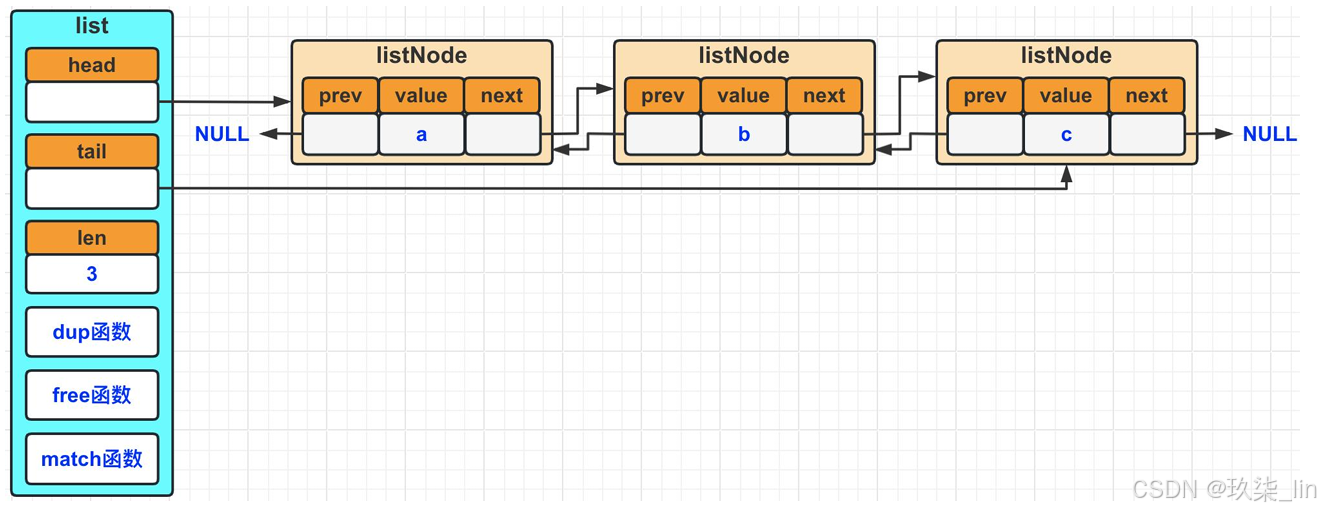
Head指向鏈表頭,tail指向鏈表尾,len記錄了鏈表的長度,當鏈表中新增或刪除節點后,len記錄的值會相應變化。如果想要獲得鏈表的長度時,直接返回len記錄的值即可,無需每次都去計算鏈表的長度。
4. 哈希表
(1)哈希表源碼部分
字典又被稱為符號表、關聯數組、 映射(map)。是一種用于保存 鍵值對的抽象數據結構。
C語音并沒有內置這種數據結構, 因此Redis構建了自己的字典實 現。
字典是哈希鍵的底層實現之一, 當一個哈希鍵包含的鍵值對比較 多,又或者鍵值對中的元素都是 比較長的字符串時,Redis就會 使用字典作為哈希鍵的底層實現。
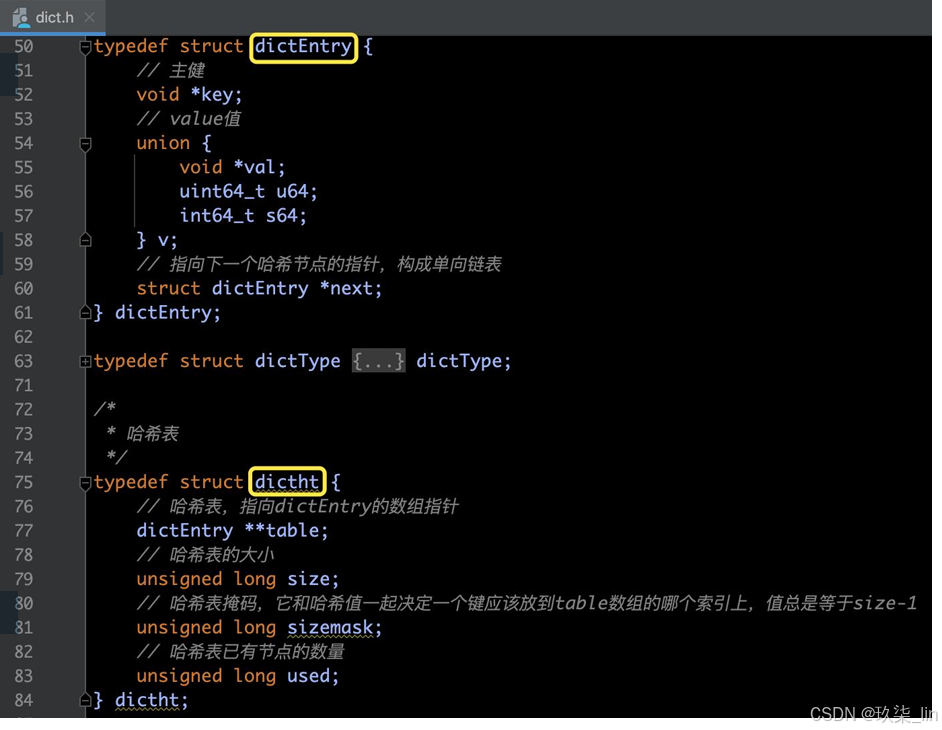
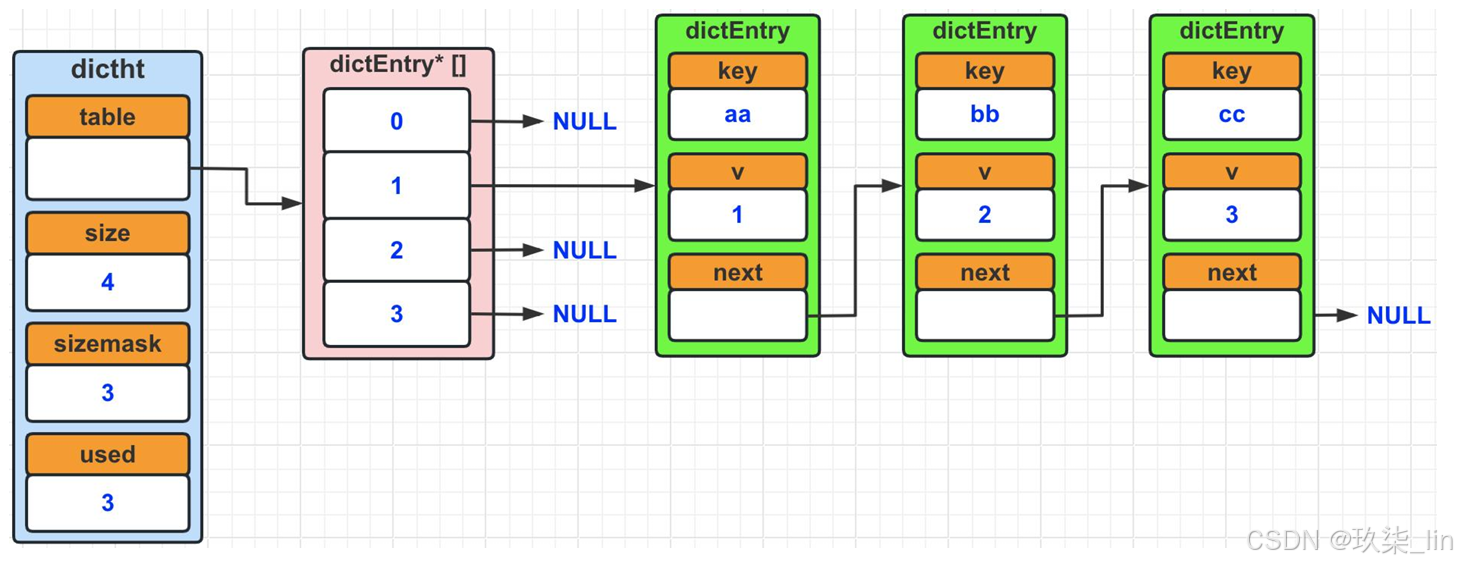
(2)哈希表數據結構
類似于hashtable,數組+鏈表的形式。
5. dict字典
(1)dict字典源碼部分
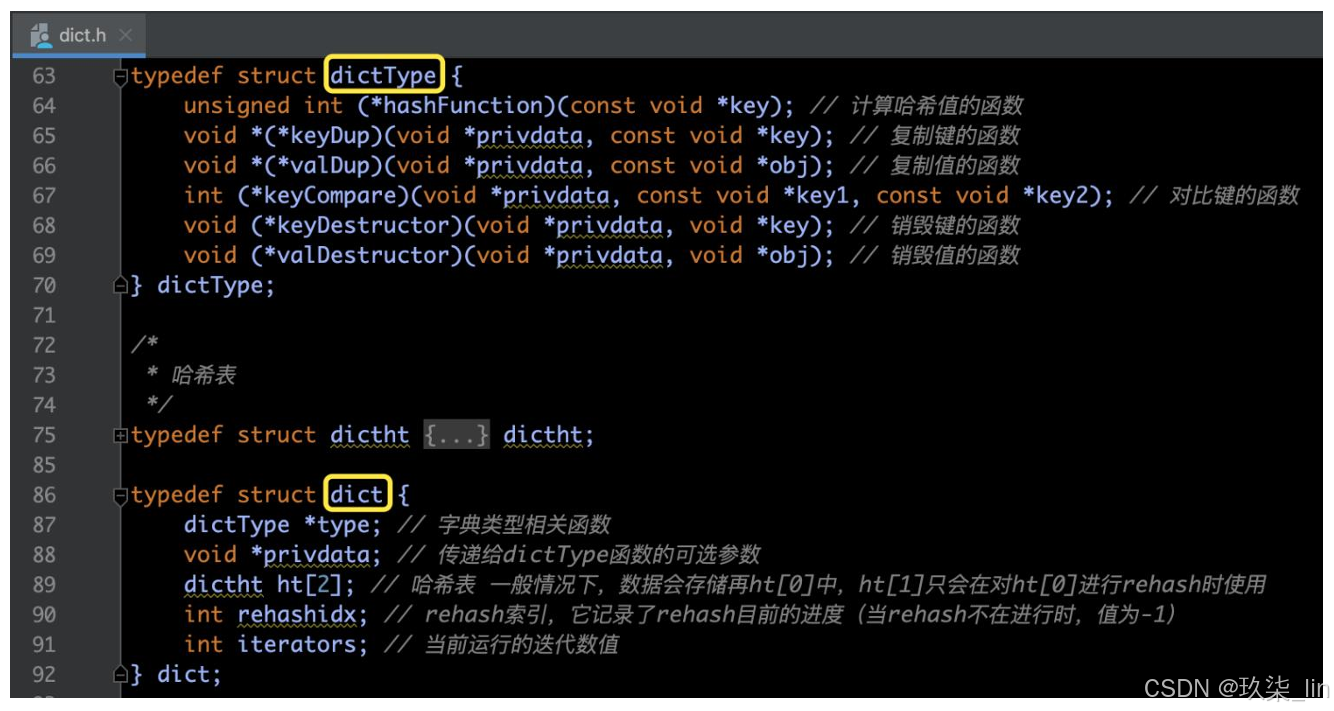
(2)Dict字典數據結構
更復雜的hashtable
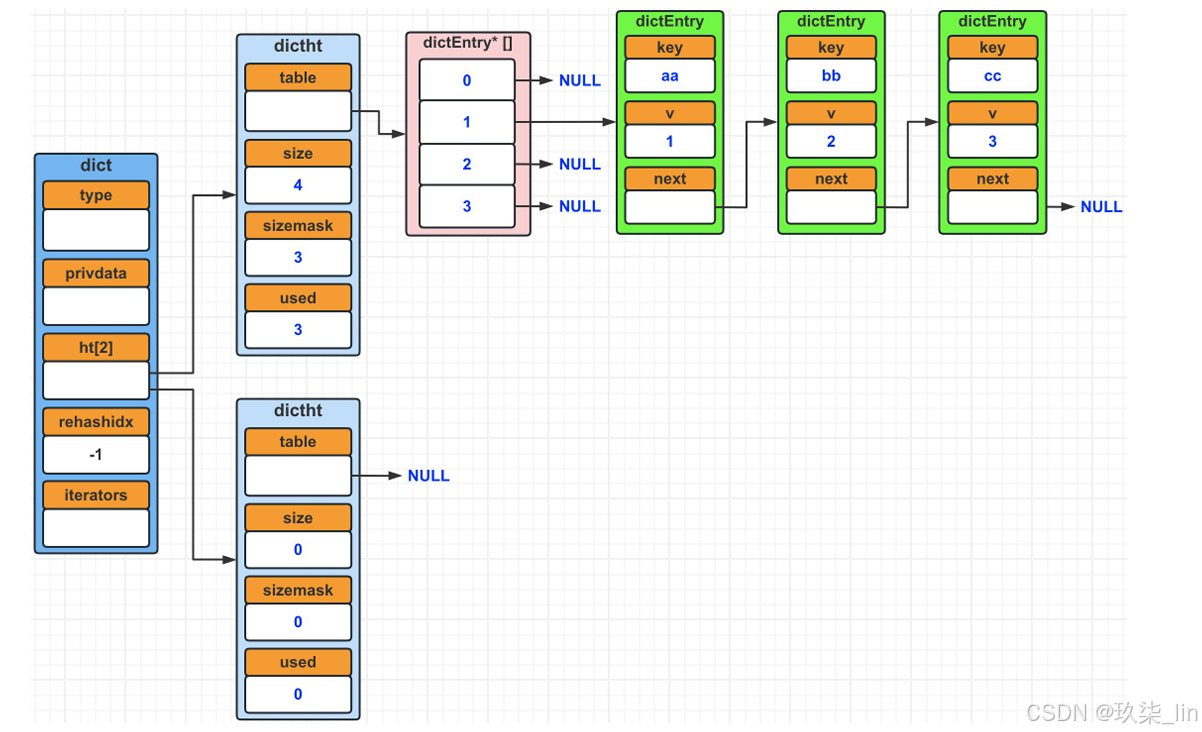
6. skiplist跳躍表
(1)skiplist跳躍表源碼部分
?跳躍表是一種有序數據結構。
Redis使用跳躍表作為有序集合鍵的底層實 現之一,如果一個有序集合包含的元素數 量比較多,或者有序集合中元素的成員是 比較長的字符串時,Redis就會使用跳表來 作為有序集合的底層實現。
Redis只在兩個地方用到了跳躍表: ① 實現有序集合鍵。 ② 在集群節點中用作內部數據結構。
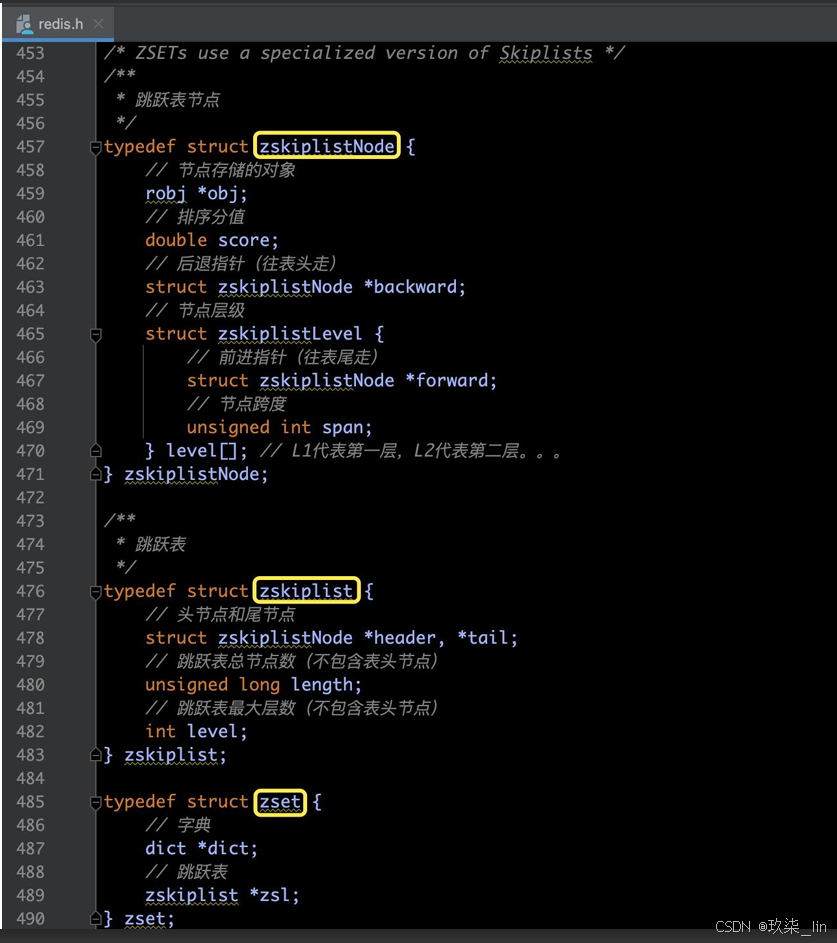
(2)跳表的數據結構
空間換時間的解決方案。層數越多,查詢效率越高,類似于查字典。默認有32層。查找的時候是同層查找,span是跨度,也就是同層跨越幾個節點。Forward是向后查找,如果找不到,要backward去一一查找
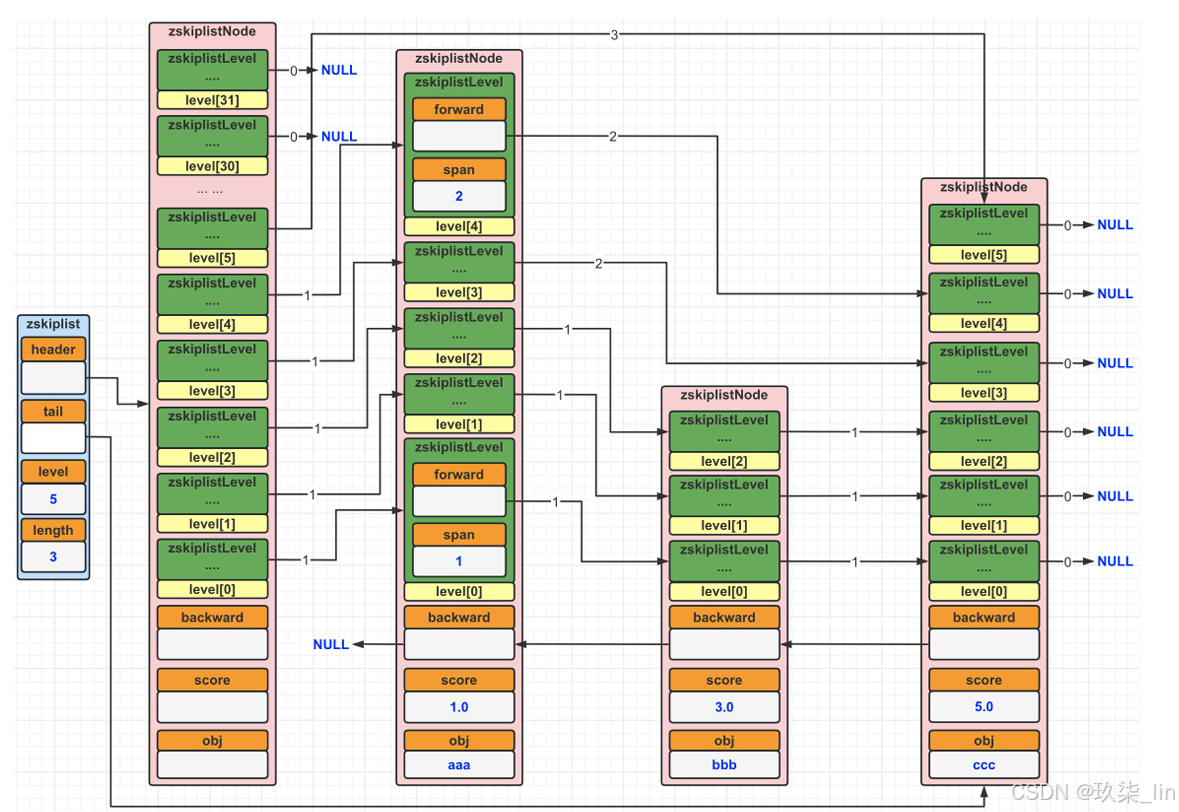
表結構包含了層級信息和節點信息
(3)skiplist跳躍表的使用
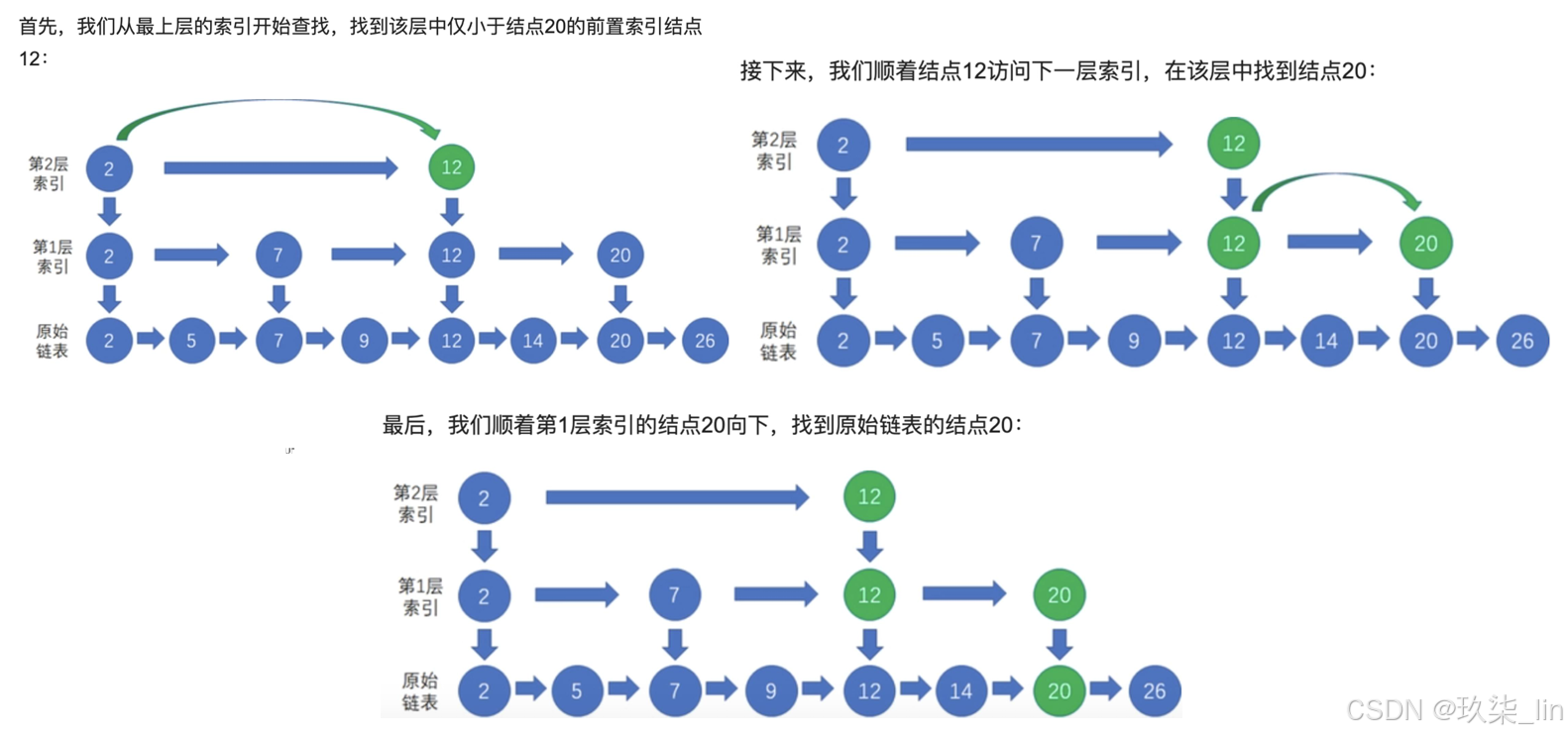
作用:快速查找到要找的元素。
五、Redis持久化
(面)
1. RDB概述
RDB持久化支持手工執行和服務器定期執行,RDB持久化產生的文件是一個經過壓縮的二進 制文件,對應文件為dump.rdb,因為它保存在磁盤上,所以可以用它來還原Redis數據庫中的數據。宕機重啟后,通過讀取二進制文件dump.rdb,將數據還原回來。
保存手工執行RDB保存有兩個命令:SAVE命令和BGSAVE命令。
SAVE命令會阻塞Redis服務器進程,直到RDB文件生成完畢都會一直處于阻塞狀態,不能處理任何的Redis命令請求;BGSAVE命令會fork一個子進程來生成RDB文件,Redis 服務器進程不受影響,可以繼續處理命令請求。
當服務器啟動的時候,RDB自動執行加載,沒有專門的命令來加載RDB文件。只要Redis啟 動時檢測到RDB文件的存在,那么就會自動載入RDB文件。加載過程中,會一直處于阻塞狀 態,直到加載完畢為止。由于AOF文件的更新頻率一般比RDB文件的更新頻率高,所以,如 果服務期開啟了AOF持久化功能,那么就優先加載AOF文件,否則,加載RDB文件。
RDB(Redis database) & AOF(Append Only File):
Redis的數據存儲在內存中,如果宕機了,不作持久化的話,數據就會丟失。
2. RDB的備份與恢復
BGSAVE執行條件檢測器——serverCron
serverCron默認每100毫秒執行一次條 件驗證,如果符合保存條件,則執行 BGSAVE命令。
它會通過dirty和lastsave(間隔時間= 當前時間-lastsave時間)這兩個參數, 來判斷是否執行BGSAVE命令。
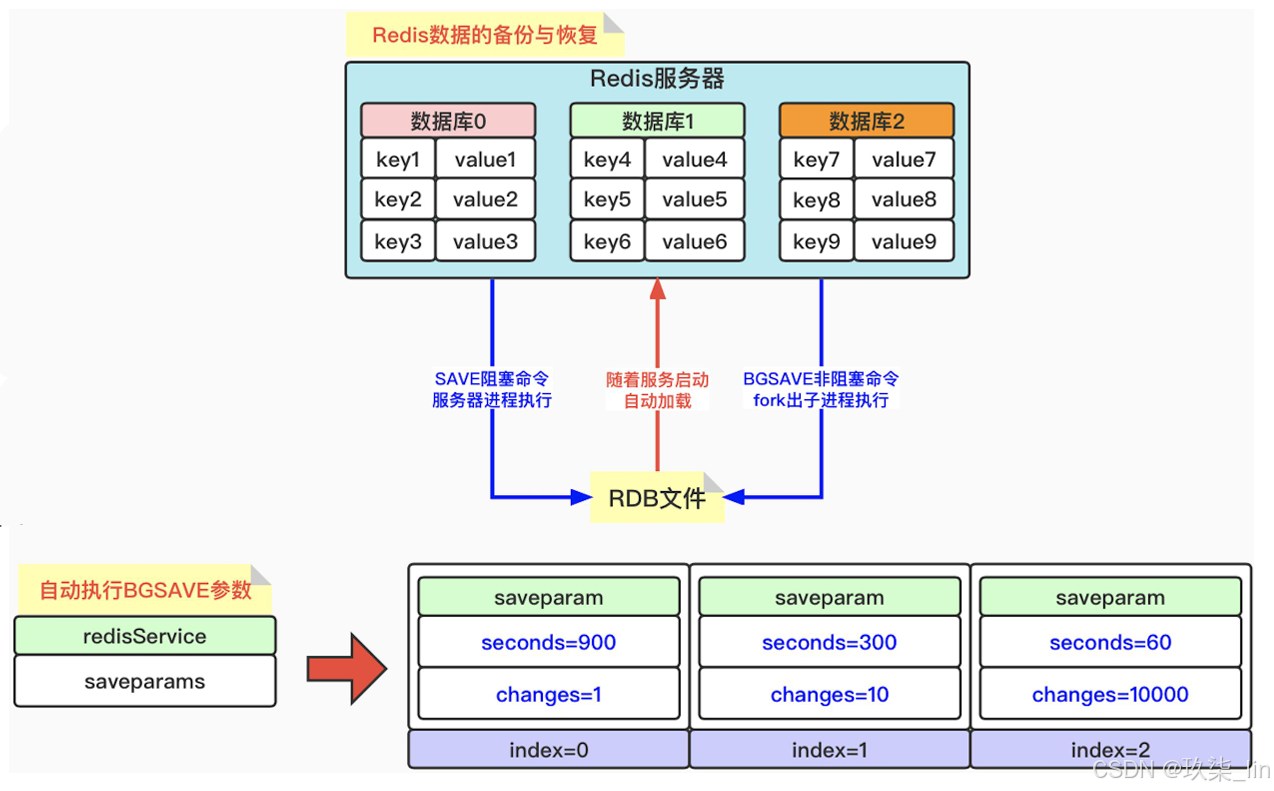
SAVE和BGSAVE生成RDB文件,隨著服務啟動自動加載進內存中(圖片右上角)。
Cron表達式:定期去執行。
RDB和AOF的區別:
BGSAVE將數據保存到庫里邊,AOF是將對應的指令保存到文件里。
3. AOF概述
AOF(Append Only File)持久化,它是通過保存Redis執行命令來記錄數據庫數據變更。 持久化流程如下所示:

如何開啟AOF和配置AOF路徑——redis.conf文件:

AOF的持久化分為三步:命令追加——>文件寫入——>文件同步,如果打開AOF后,每 次執行完一個寫命令之后,都會把寫命令以請求協議格式保存到aof_buf緩沖區的末尾。
AOF是對指令進行備份,先將數據持久化到數據庫,然后再將改變寫入AOF文件中。
寫入和同步都是OS級別的,調用write函數時,將數據放入操作系統的緩存中,在一定時間范圍內,將緩存中的數據刷到磁盤上,寫入是寫到緩存?緩沖中,同步是將緩存?緩沖中的數據刷到真正的磁盤上。
AOF怎么使用:在一個客戶端輸入操作命令,例如“set name muse”,然后打開AOF文件:“BGREWRITEAOF”,再打開另一個客戶端,cd redis/src? cat appendonly.aof,可以從.aof文件中看到前一個客戶端中所做的Redis操作命令。在讀取.aof文件時,將其中記錄的指令再執行一次,達到恢復數據庫操作的目的。
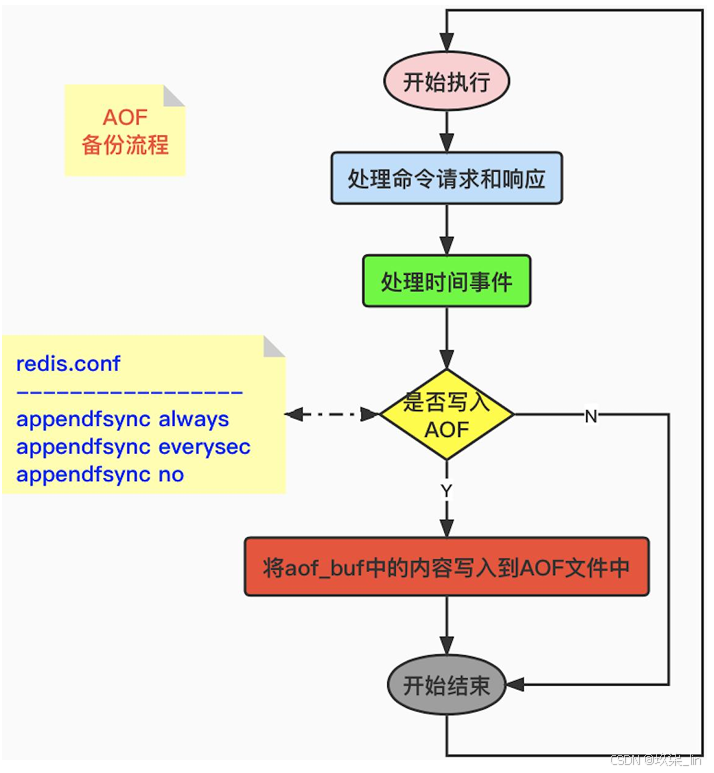
Redis的服務器進程就是一個事件循環,在這個循環中:
- 文件事件負責接收客戶端的命令請求和發 送給客戶端執行結果回復。
- 時間事件負責執行如serverCron這種需要 定時運行的函數。
- 當每次一個事件循環結束之前,都會調用 flushAppendOnlyFile函數,來判斷是否需要 將aof_buf緩沖區中的內容寫入和同步到 AOF文件中。
- 其中,flushAppendOnlyFile函數的行為由 appendfsync配置決定(redis.conf文件中)
4. appendfsync配置詳解

5.?什么叫寫入?什么叫同步?有什么區別呢?
為了提高文件的寫入效率,在現代操作系統中,當用戶調用write函數時,將一些數據寫 入到文件的時候,操作系統通常會將寫入數據暫時保存在一個內存緩沖區里面,等到緩沖 區的空間被填滿、或者超過了指定的時限之后,才真正地將緩沖區中的數據寫入到磁盤里 面。
這種做法雖然提高了效率,但也為寫入數據帶來了安全問題,因為如果計算機發生停機, 那么保存在內存緩沖區里面的寫入數據將會丟失。
為此,操作系統提供了fsync和fdatasync兩個同步函數,它們可以強制讓操作系統立即將 緩沖區中的數據寫入到磁盤里,從而確保寫入數據的安全性。

6. AOF加載流程
當Redis服務啟動并讀取AOF,即可恢復關閉前的數據狀態。加載流程如下:

Fack Client(偽客戶端)的執行命令效果與帶網絡的效果完全一樣。由于載入AOF時, 命令來源于AOF文件,而不是網絡連接傳遞過來的命令,所以,建立了一個沒有網絡連接 的偽客戶端。
Redis服務啟動的時候,如果檢測到了AOF,就會先加載AOF,如果AOF是關閉的或者檢測不到,就以RDB為主。
偽客戶端的作用:執行指令,恢復數據。執行完畢,自動關閉偽客戶端。
7. AOF重寫
(面)
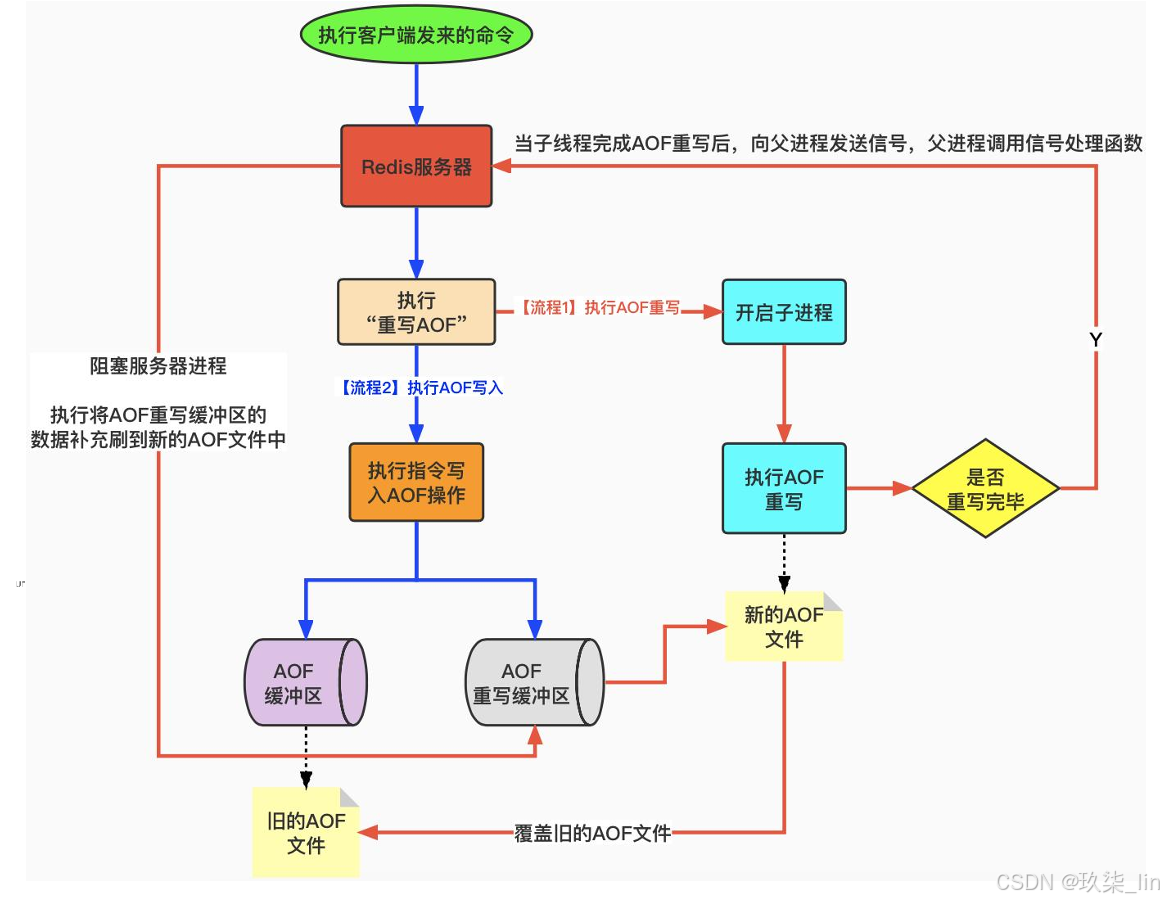
AOF重寫:基于數據重新生成一份AOF,實現AOF瘦身(對指令進行備份)。當重寫的時候,Redis不能再做別的操作,防止造成數據不一致的問題,但是當操作數據頻繁時,AOF重寫不方便,于是創建AOF的時候,開啟一個子進程,在子進程中進行重寫操作。
Redis.conf文件中:
Auto-aof-rewrite-percentage 100:比上一次重寫的大小增多了100%時,會自動觸發重寫(體積)
Auto-aof-rewrite-min-size 64mb:AOF文件超過了64M的時候,觸發一次重寫。
流程圖中:
【執行“重寫AOF”】如果不滿足(當不需要重寫的時候),則執行【執行指令寫入AOF操作】,然后進入【AOF緩沖區】步驟,當需要重寫的時候(redis.conf文件中判斷),執行【開啟子進程】,重寫是基于當前的數據快照寫入的,如果在3:00到3:05分執行重寫操作,那么在這5分鐘的時間內對于數據庫進行的新操作,會寫進【AOF重寫緩沖區】,該緩沖區與重寫操作同步開啟。在3:05重寫完成后,精簡后的操作步驟寫入【新的AOF文件】,重寫完成后【向父進程發送信號,父進程調用信號處理函數】,然后【阻塞服務器進程】,該位置的阻塞是為了將【AOF重寫緩沖區】中的數據補充到【新的AOF文件】中,因為時間比較短,【AOF緩沖區】中的指令也不會很多,通過將redis停止掉,將額外的數據補充到【新的AOF文件】,這個過程速度很快,然后用【新的AOF文件】【覆蓋舊的AOF文件】,覆蓋完成后,再將進程放開,就可以正常地對外提供服務了。
六、三種特殊數據類型
1. geospatial地理位置
快遞,外賣等使用場景
可以用于基于地理位置的業務場景。比如:查詢兩地之間的距離,方圓幾里存在的地理 位置等等。經緯度查詢https://jingweidu.bmcx.com。
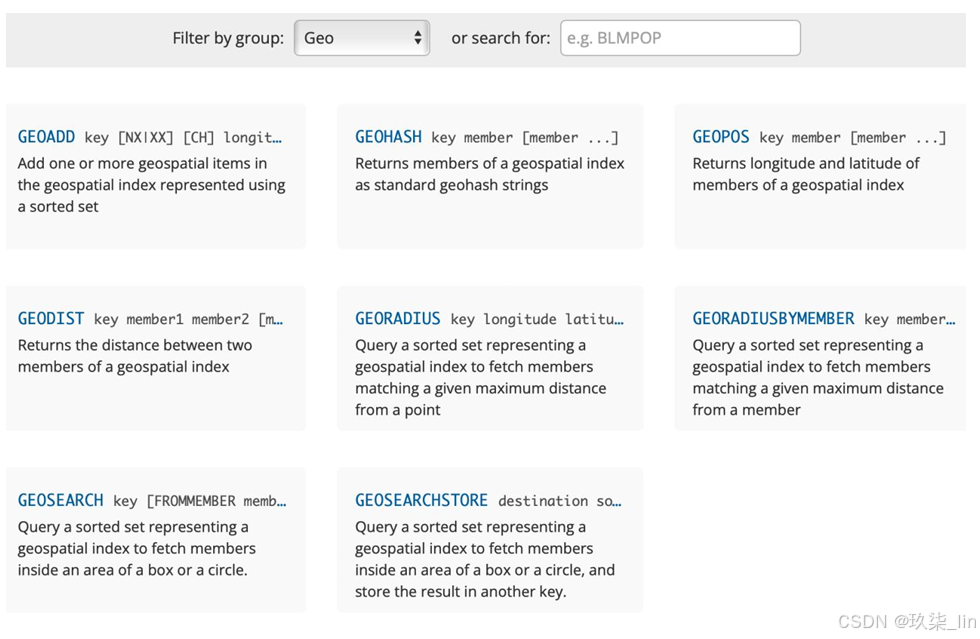
(1)創建數據集:
GEOADD key(city) 經度 緯度 cityname
(2)查詢兩地之間的距離
GEODIST city beijing shanghai km
(3)GEOHASH:52位長度的編碼,通過hash可以表示經度和緯度
GEOHASH city beijing shanghai haerbin (返回的是三個位置的hash編碼)
(4)獲得某個位置的經緯度:
GEOPOS city Beijing
(5)查看所有的city
ZRANGE city 0 -1
(6)雷達圈尋,查找指定坐標在某個半徑范圍內包含的所有位置
GEORADIUS city 116 40 1500 km WITHCOORD WITHDIST ASC
查詢在以(116,40)為圓心,1500km為半徑的圓圈范圍內的所有地址,以升序返回【地址名稱】【距離圓心的長度】【該位置的經度和緯度】
(7)雷達圈尋,查找指定city在某個半徑范圍內包含的所有位置
GEORADIUSBYMEMBER city beijing 1500 km WITHCOORD WITHDIST ASC
2. hyperloglog預估集合的基數
不精準但是快,適用于量大但是對具體數據要求不敏感的,例如對接口的訪問量級,看柱狀圖的數據
hyperloglog常用的使用場景,一般是非精準性的統計計數。比如:統計訪問網站的UV 數,商品評論數或點擊量等等。
HyperLogLog 是一種用于計算唯一事物的概率數據結構(從技術上講,這稱為預估集合 的基數)
它占用的空間很小,只需要12KB的內存,可以存儲2^64不同的元素數量。但是它的統 計是有小于1%的誤差,所以并不適合精準統計使用場景。
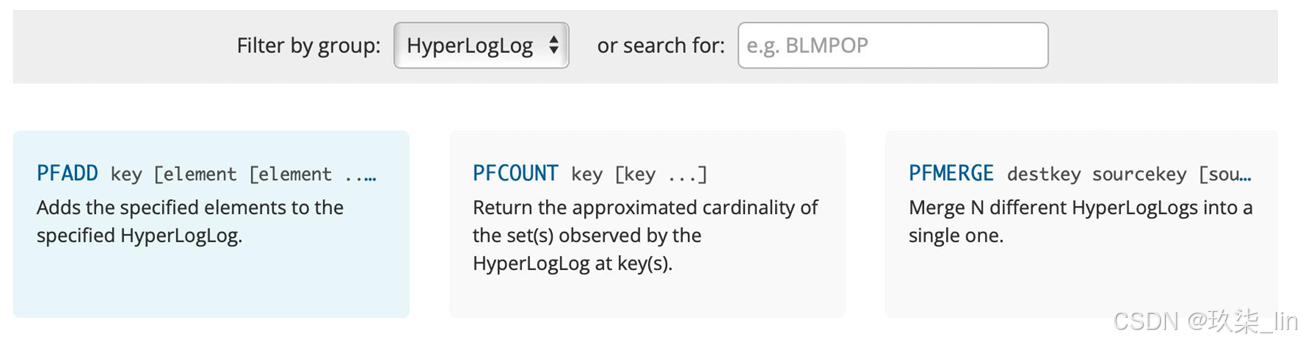
?(1)?? ?新建數據集并向內新增元素
PFADD user muse bob tom tony muse
(2)?? ?計數
PFCOUNT user
返回 4 。有去重的作用
(3)?? ?兩個數據集合并
PFADD vip james muse cartern (創建另一個數據集vip)
PFMERGE alluser user vip ?(合并user和vip數據集)
PFCOUNT alluser ? (去重計數)
返回6
3. bitmap位圖
不占空間,效率較高。Hyperloglog和bitmap適用于大數據量,用來看統計結果,而不是明細的場景。
可以利用bitmap指定其二進制位是0或1,來實現類似“是”or“否”的相關操作。它的 特點也是占用內存空間特別的小。比如,我們要記錄每個用戶當天是否活躍(即:是否 登錄過系統),那么如果我們要記錄他一年的是否登錄的記錄,只需要365個bit即可存 儲。
七、事務管理
半事務,保證語句的原子性,不能保證其他
事務管理:用于保證指令的原子性,功能沒有很強大。
事務的本質,其實就是一組命令的集合。一個事務中的所有命令都會按照命令的順序去 執行,而中間不會被其他命令加塞。沒有隔離性
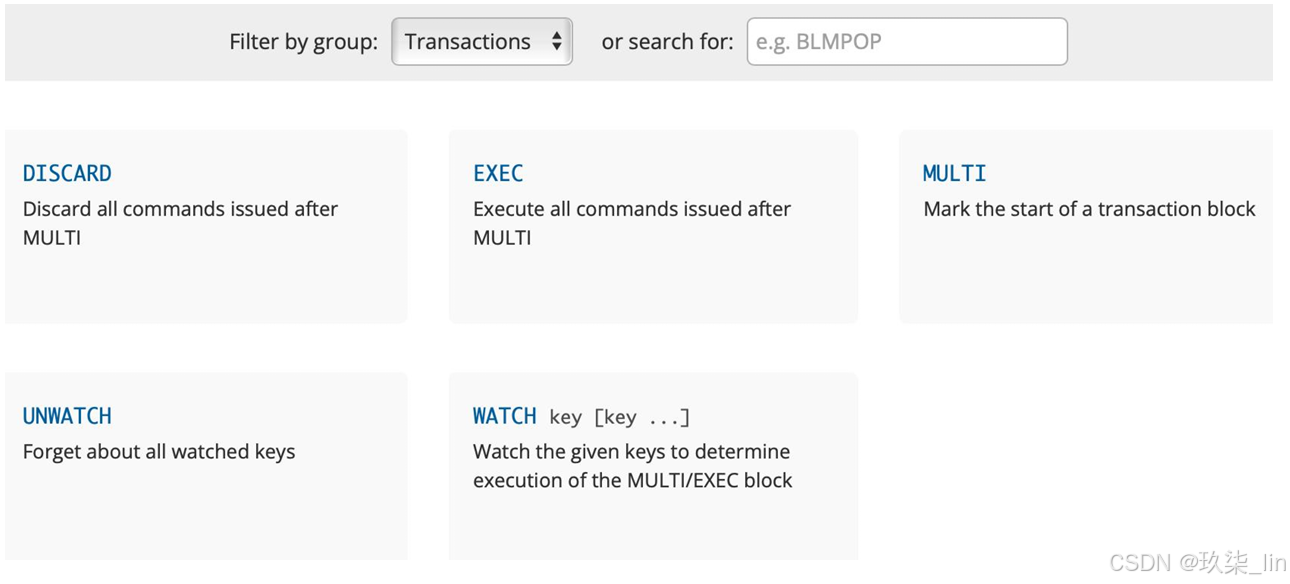
DISCARD:放棄事務的執行
EXEC:執行事務(提交事務)
MULTI:開啟對應的事務?
UNWATCH:解除監控
WATCH:監控
示例:同一IP和端口開啟兩個客戶端用作測試
客戶端1:set account 1000
客戶端1和2:get account ,返回結果均為1000
客戶端1:開啟對應的事務: MULTI
客戶端1:進行一系列的操作
????????set account 2000
????????set account 800
????????set account 500
以上三條指令將操作加入到隊列,其實還沒有真正執行。在客戶端2查不到這三條指令所做的更改。如果要真正地執行,需要EXEC,這是依次執行以上三條指令,中間不能再插入其他指令(單進程執行)。
客戶端1:EXEC
這時再get account返回的是500
客戶端1:MULTI 開啟事務
????????set account 2000
????????set account 800
客戶端1:DISVARD 放棄執行事務
????????get account
?? 返回的是500,設置為2000和800的兩條指令不會操作。
事務監控功能:
客戶端1:WATCH account
客戶端1:MULTI
客戶端1:set account 1000
客戶端1:set account 1500
客戶端1:set account 700
客戶端2:get account 返回5? ? ?00
客戶端2:set account 5000
客戶端2:get account 返回5000
客戶端1:EXEC
客戶端1:get account 返回的不是700,而是5000.
以上結果的原因是:客戶端1開啟事務之前開啟了WATCH監控功能,此時可以發現在客戶端2對account進行了修改,于是在客戶端1隊列中的事務操作就會放棄執行。
如果不開啟WATCH監控功能:(現在賬戶是5000)
客戶端1:MULTI 開啟實物功能
客戶端1:set account 1000
??????????? Set account 700
客戶端2:set account 500
客戶端2:get account 返回500
客戶端1:EXEC 執行成功
客戶端1:get account 返回700
因為沒有開啟WATCH監控功能,所以客戶端2進行了更改之后,再去執行事務操作,依舊可以成功。
事務管理需要注意的兩點:
- 每次需要監控,都要在開啟事務之前開啟監控功能
- 針對命令語法錯誤,會導致整個事務執行被中斷;針對執行中的運行操作錯誤(異常),只會導致該條指令的執行失敗,不會影響事務中的其他指令。(示例如下)
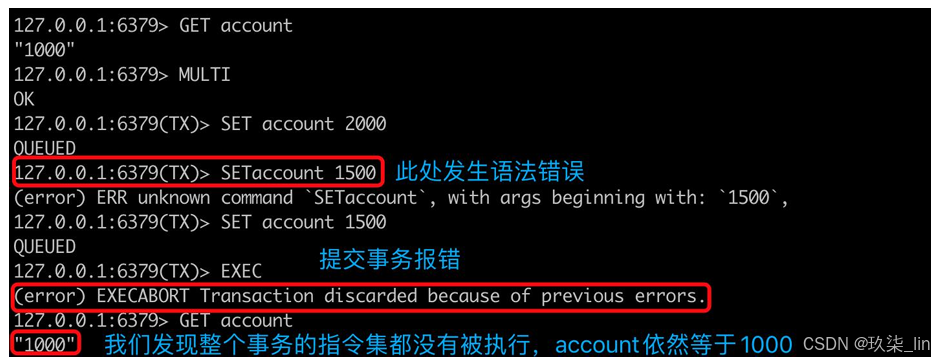
針對命令語法錯誤:
本來account中是700;
客戶端1:MULTI
客戶端1:set account 2000
客戶端1:setaccount 1500? 執行時會報錯(語法錯誤)
客戶端1:set account 1500
客戶端1:EXEC??? 執行時報錯
客戶端1:get account? 返回700,即事務中的指令都不會執行
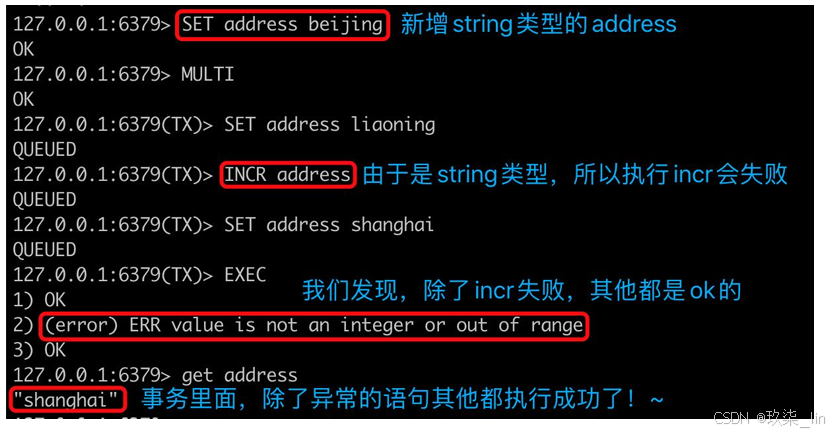
針對執行中的運行異常:
本來address中存的是beijing;
客戶端1:MULTI? 開啟事務
客戶端1:set address liaoning
客戶端1:INCR address
客戶端1:set address shanghai
客戶端1:EXEC? 此時回車顯示語句1和3執行成功,語句2執行失敗
客戶端1:get address? 返回“shanghai”
事務中異常的處理
命令語法錯誤:針對語法錯誤,會導致整個事務 執行被中斷
?運行操作錯誤:針對執行中的異常,只會導致該 條指令的執行失敗,而不會影響事務 中其他的指令
八、發布訂閱
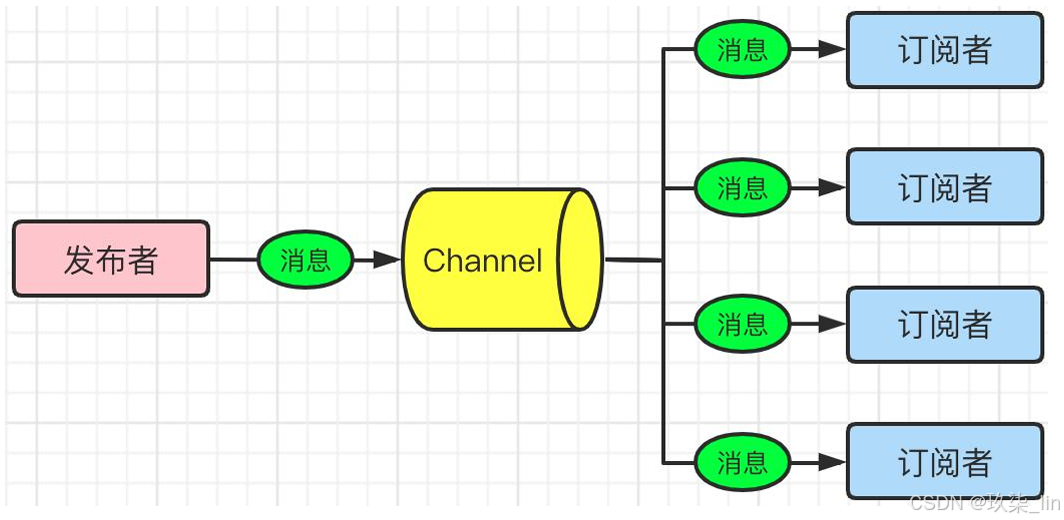
如果熟悉消息中間件,那么對發布訂閱一定不陌生。發布者Publish一條消息,消息發送 到Channel通道中,然后所有訂閱了這個通道的訂閱者Subscriber都會接收到這條消息。 如下圖所示:
1.?Redis針對發布訂閱相關指令?
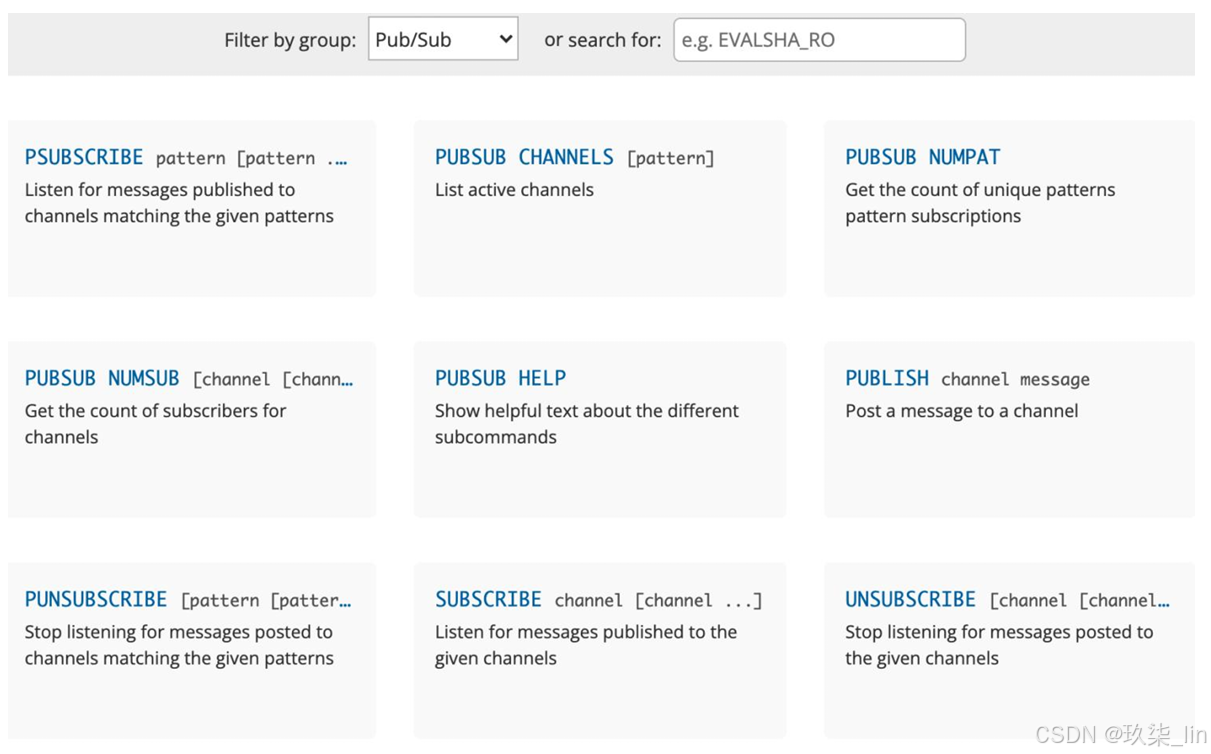
示例:
(1)基礎
客戶端1:SUBSCRIBE muse
客戶端2:PUBLISH muse hello? 此時客戶端1的控制臺會輸出message:“hello”
(2)匹配模式pattern
客戶端1:PSUBSCRIBE h[ae]llo
客戶端2:PUBLISH hallo 1111? ??客戶端1可以接收到1111
客戶端2:PUBLISH hello 1111? ??客戶端1可以接收到1111
客戶端2:PUBLISH hillo 1111? ???客戶端1接收不到1111
(3)訂閱通道PUBSUB,無法基于pattern
客戶端1:SUBSCRIBE muse???? (這里如果設置的是PSUBSCRIBE m*se,下邊第二條也不能訂閱成功,因為不基于pattern)
客戶端2:PUBSUB CHANNELS muse? 客戶端2可以訂閱成功
客戶端2:PUBSUB CHANNELS m1se? 客戶端2訂閱不成功
(4)查看訂閱數量 PUBSUB NUMPAT
客戶端2:PUBSUB NUMPAT? 返回訂閱者的數量
客戶端2:PUBSUB NUMSUB muse 返回非pattern模式訂閱者的數量。
九、主從復制
主從復制,是指將一臺Redis服務器的數據復制到其他的Redis服務器。前者稱為主節點 (Master/Leader),后者稱為從節點(Slave/Follower);數據是從主節點復制到從節點的。其中,主節點負責寫數據(當然有讀的權限),從節點負責讀數據(它沒有寫數 據的權限)。默認的配置下,每個Redis都是主節點。
一個主節點可以有多個從節點,但是一個從節點只能有一個主節點,即:主從節點是1對N的關系。(問題:不能自動選主)

1. 主從復制的用處?
數據冗余:主從復制實現了數據的備份,實際上提供了數據冗余的實現方式。實現高可用性
故障恢復:當主節點出現異常時,可以由從節點提供服務,實現快速的故障恢復,實際上提供了服 務冗余的實現方式。主節點出現故障,從節點用來提供服務,這時主節點可以用來故障恢復。
負載均衡:在主從復制的基礎上,配合讀寫分離,可以由主節點提供寫服務,由從節點提供讀服務, 分擔服務器的負載; 在寫少讀多的業務場景下,通過多個從節點分擔讀負載,可以大大提高 Redis服務器是并發量。
高可用:哨兵配合主從復制,可以實現Redis集群的高可用。當主節點掛掉之后,由哨兵從從節點中選擇一個節點作為主節點。
主機宕機之后,從節點依舊無法成為主節點,還是只能提供讀操作。
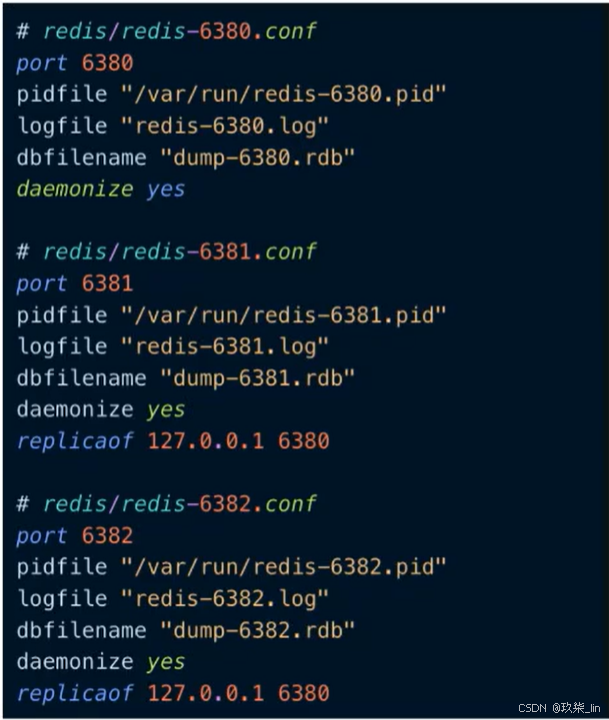
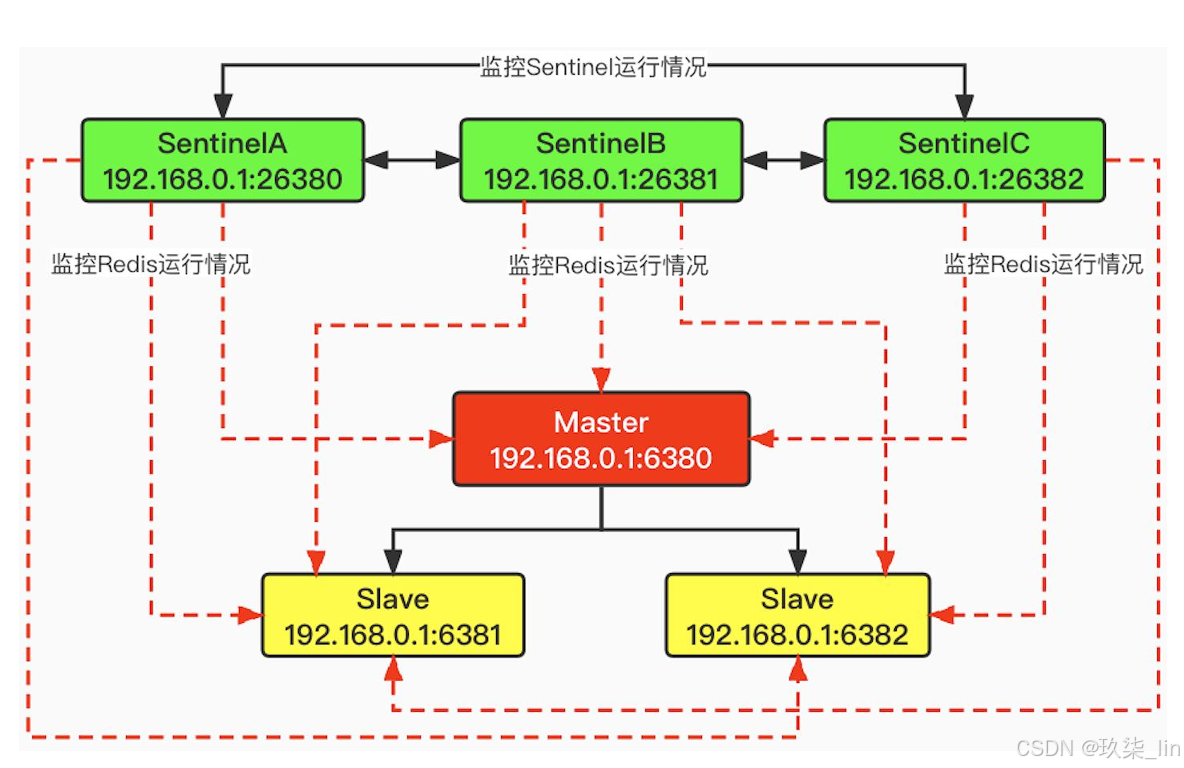
環境搭建:6380為主節點,6381和6382為從節點。
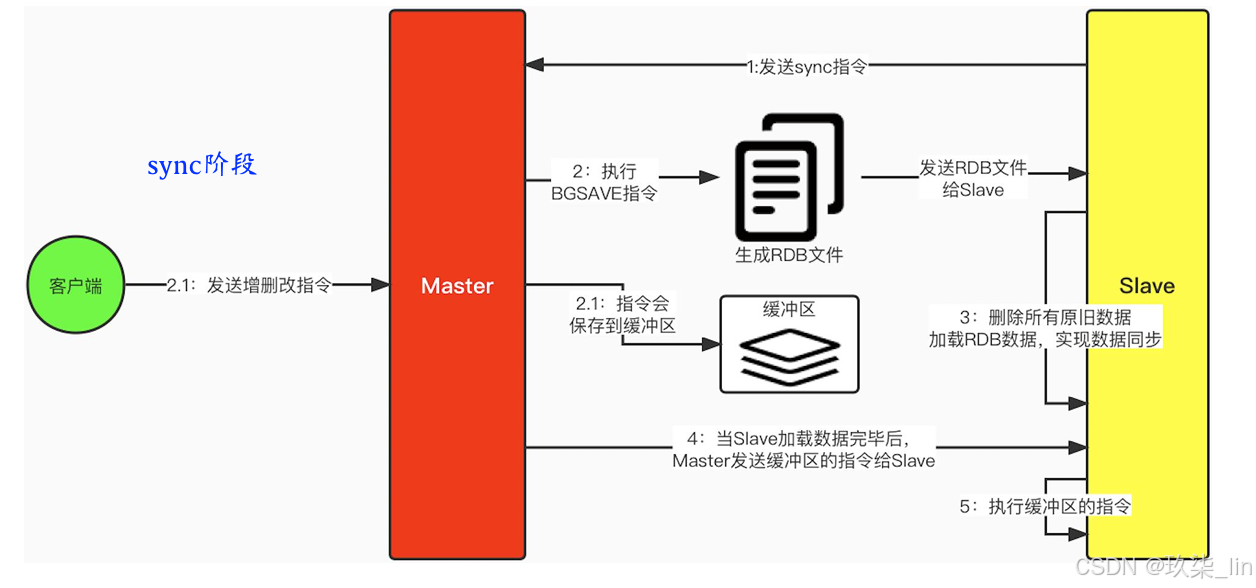
2. 主從復制實現原理
Redis的主從復制可以分為兩個階段:sync階段和command propagate階段。當從節點啟 動后,會發送sync指令給主節點,要求全量同步數據,此為sync階段;那么,如果后續 Master節點接收到新的增刪改操作,也需要Slave節點接收同步的更新,這就是command propagate階段;
?3. psync指令
當主從節點都正在運行的時候,出現了網絡抖動,造成連接斷開,那么當網絡恢復,兩個 節點再次建立起連接的時候。從節點發送sync指令后,主節點依然需要重新生成RDB,并 對從節點進行全量數據的同步造成。那么這中間的耗時是非常嚴重的,并且傳輸備份文件 也會對網絡帶寬造成很大的消耗。那么為了解決這個問題,從Redis 2.8開始,引入了 psync指令來代替sync指令。psync指令會根據不同的情況,來確定執行全量重同步還是部 分重同步。
全量重同步:當從節點是第一次與主節點建立連接的時候(或者兩次同步之間數據差異量非常大:大的程度由部分重同步判斷),那么就會執行全量重同步,這個同步過程 與上面我們介紹的sync階段+command propagate階段一樣。
部分重同步:從節點的復制偏移量無法在復制積壓緩沖區中找相應待同步的數據 并且 主節點與從節點不是第一次同步(根據判斷)
4. 復制偏移量
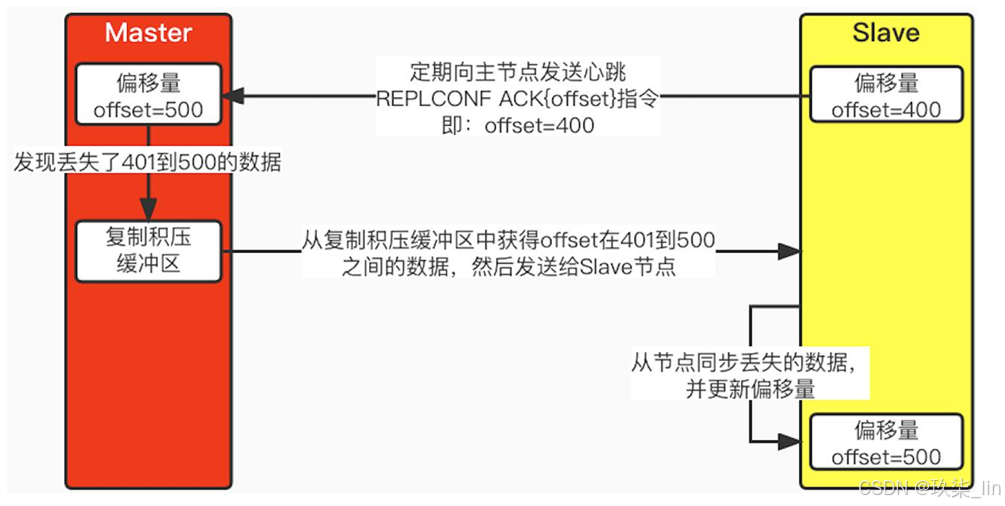
Master節點和Slave節點都保存著一份復制偏移量。當Master節點每次向Slave節點發送n 字節數據的時候,就會在Master節點偏移量加上n;而Slave節點每次接收到n個字節的 時候,也會在Slave節點偏移量上加n。在命令傳播階段,Slave節點會定期的發送心跳 REPLCONF ACK{offset}指令,這里的offset就是Slave節點的offset。當Master節點接 收到這個心跳指令后,會對比自己的offset和命令里的offset,如果發現有數據丟失,那 么Master節點就會推送丟失的那段數據給Slave節點。如下圖所示:
5. 復制積壓緩沖區&節點ID
什么是復制積壓緩沖區?
復制積壓緩沖區是由主節點維護的一個固定長度(默認1MB)的隊列。它存儲了每個字節值與對應的復制偏移量。因為復制積壓緩沖區的大小是固定的,所以它保存的是主節點近 期執行的寫命令。當從節點將offset發送給主節點后,主節點便會根據offset與復制積壓緩 沖區的大小來決定是否可以使用部分重同步。如果offset之后的數據仍然在復制積壓緩沖區 內,則執行部分重同步;否則還是執行全量重同步。
節點ID:
Redis節點服務啟動之后,就會產生一個用來唯一標識Redis節點的ID。當Master節點與 Salve節點進行第一次連接同步的時候,Master節點會將ID發送給Slave節點,Slave節點接收 到會對其進行保存。那么當主從服務之間發生了中斷重連的時候,Slave服務器會將這個ID 發送給Master服務器,Master服務器會拿自己的ID進行對比,如果相同,則說明主從之前是 連接過的。否則,則說明是第一次建立的連接。那么,就需要全量去同步數據了。
十、Redis哨兵
我們介紹主從復制的時候發現,主節點掛掉從節點不會自動變為主節點,需要人工的去 配置主節點才可以。但是這種做法費時費力,怎樣能讓Redis在主節點掛掉的情況下,自 己從從節點中選擇新的主節點呢?這時候,就需要使用Sentinel哨兵了。
哨兵本質就是一個Redis實例節點。哨兵模式是一種特殊的模式,它能夠后臺監控主機是 否故障,如果故障了,則根據投票數自動將Slave節點轉換為新的Master節點。 首先 Redis提供了哨兵的命令,哨兵是一個獨立的進程,會獨立的運行。它的原理是:哨兵通過發送命令,等待Redis服務器響應,從而監控運行的多個Redis實例。如下圖所示:
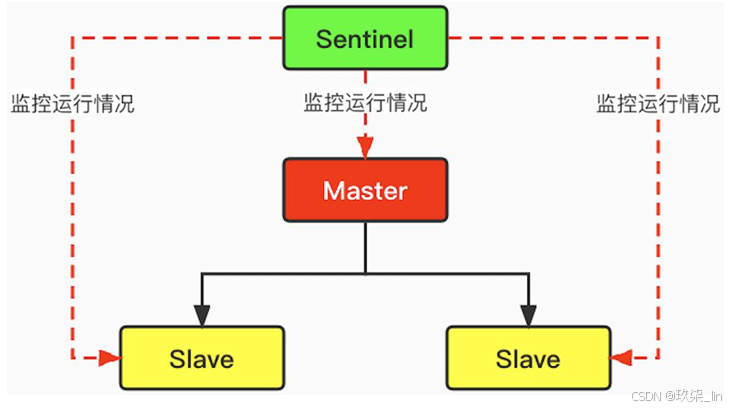
主節點宕機后,推選出新的主節點,這時當重啟后,原來的主節點下沉為從節點。這個過程由Sentinel完成,不需要手動去做。是如何做點:重寫redis.command文件,在該文件中可以指定主節點是哪一個,重啟的時候根據配置文件中設置的主從節點的拓撲圖。
多個Sentinel之間不存在主從的概念,是平行角色,會相互監控,多個Sentinel投票選擇一個slave作為master。如果Sentinel只剩了一個,就沒有了選主的能力。
1. 多哨兵模式
然而一個哨兵進程對Redis服務器進行監控,可能會出現問題。因此,我們可以使用多哨 兵進行監控。各個哨兵之間還會進行監控,這樣就形成了多哨兵模式。
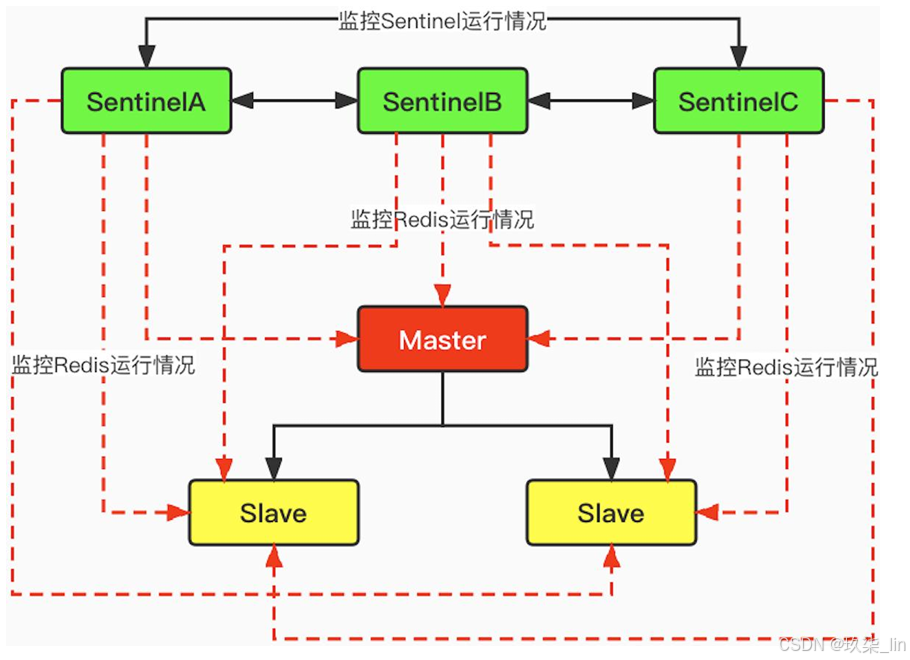
主觀節點下線:SentinelA等待master的相應,在規定時間內沒有響應,則為主觀master下線。
客觀節點下線:多個Sentinel對master節點進行的判斷。半數以上認為下線則認為master下線。再去根據投票結果選擇slave升級為master。
2. 環境搭建(3哨兵 1主2從)
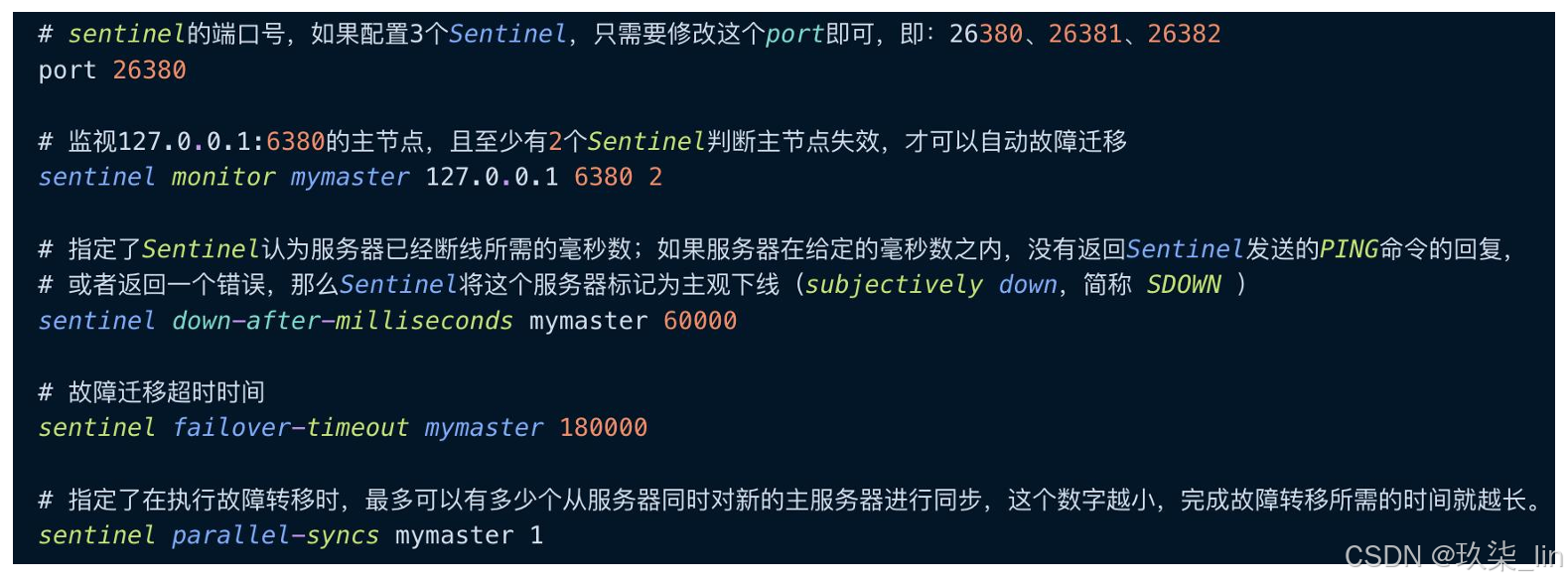
哨兵配置文件sentinel.conf
 ?Sentinel是redis的一個進程。只剩一個Sentinel之后無法進行master選舉了。
?Sentinel是redis的一個進程。只剩一個Sentinel之后無法進行master選舉了。
啟動:
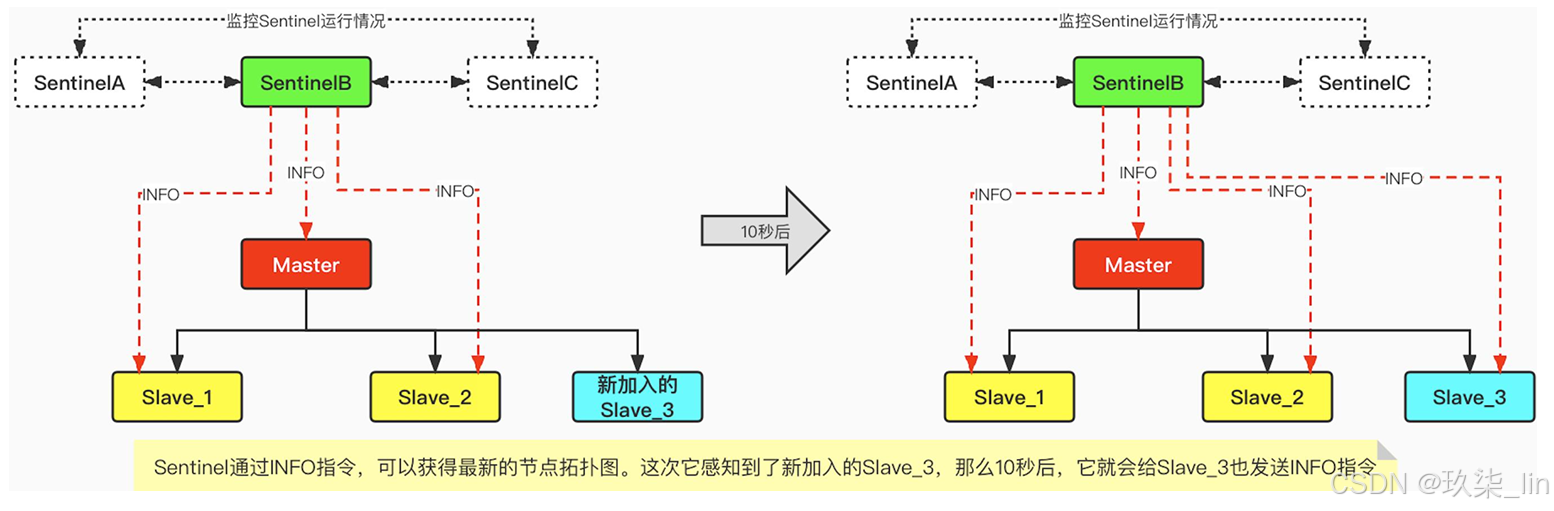
3. INFO指令獲得最新節點拓撲圖
每個Sentinel每隔10秒就會向主從節點中發送INFO指令,通過該指令可以獲得整個redis的節 點拓撲圖。那么這時候,如果有新的節點加入或者有節點退出集群,那么Sentinel就可以很 快的感知到拓撲圖的變化。如下圖所示:
4.?哨兵監測集群狀態方法
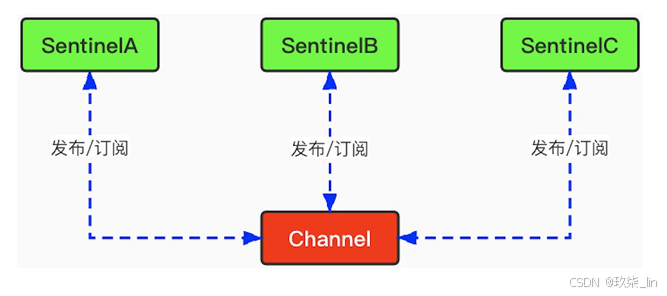
每個Sentinel每隔2秒會向指定頻道上發布自己 對Master節點是否正常的判斷以及當前 Sentinel節點的信息,并且通過訂閱這個頻道, 可以獲得其他Sentinel節點的信息和對Master 節點是否存活的判斷。如圖所示:
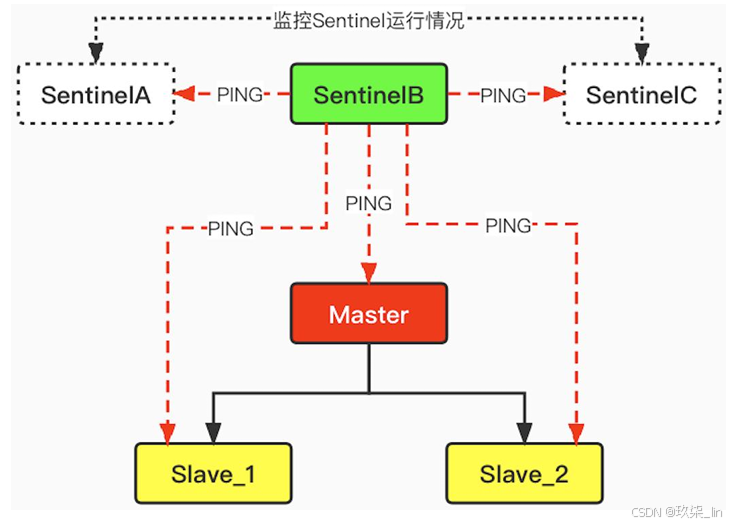
每個Sentinel每隔1秒會向所有節點 (Sentinel節點、Master節點、Slave節點) 發送PING指令來進行心跳檢測。如圖所示:
5. 選舉流程
當一個Sentinel判斷主節點不可用的時候,會首先進行“主觀下線”,此時,這個Sentinel 通過sentinel is-masterdown-by-addr指令獲取其他哨兵節點對主節點的判斷,如果當 前哨兵節點對主節點主觀下線的票數超過了我們定義的quorum值,則主節點被判定為 “客觀下線”。
Leader Sentinel 節點會從原主節點的從節點中選出一個新的主節點,選舉流程如下:
- ① 首先,過濾掉所有主觀下線的節點。
- ② 然后,選擇slave-priority最高的 節點,如果有則返回,沒有就繼續下面的流程。
- ③ 選擇出復制偏移量offset最大的節點,如果有則返回,沒有就繼續下面的流程。
- ④ 選擇run_id最小的節點,其中,run_id表示服務器運行ID(run_id越小,啟動越早)。
- ⑤ 在選擇完畢后,Leader Sentinel節點會通過SLAVEOF NO ONE命令讓選擇出來的從節 點成為主節點,然后通過SLAVEOF命令讓其他的節點成為該節點的從節點。
十一、Redis Cluster
Redis3.0開始引入了去中心化(沒有主從)分片集群Redis Cluster。
傳統的Redis集群是基于主從復制+哨兵的方式來實現的。但是集群中都只有一個主節點 提供寫服務。
Redis Cluster則采用多主多從的方式,支持開啟多個主節點,每個主節點上可以掛載多 個從節點。
Cluster會將數據進行分片,將數據分散到多個主節點上,而每個主節點都可以對外提供 讀寫服務。這種做法使得Redis突破了單機內存大小限制,擴展了集群的存儲容量。并且 Redis Cluster也具備高可用性,因為每個主節點上都至少有一個從節點,當主節點掛掉 時,Redis Cluster 的故障轉移機制會將某個從節點切換為主節點。
Redis Cluster是一個去中心化的集群,每個節點都會與其他節點保持互連,使用gossip協 議來交換彼此的信息,以及探測新加入的節點信息。并且Redis Cluster無需任何代理, 客戶端會直接與集群中的節點直連。
1. 分片方式
(1)哈希取模
這種方式就類似我們使用HashMap時選址的方式,只要hash計算出來的值夠散列(rehash),那么 每個key都可以均勻的分散到N個節點上。 但是它存在的問題就是,如果要擴容或縮容,會導致key重新計算存儲位置,從而導致緩 存失效。
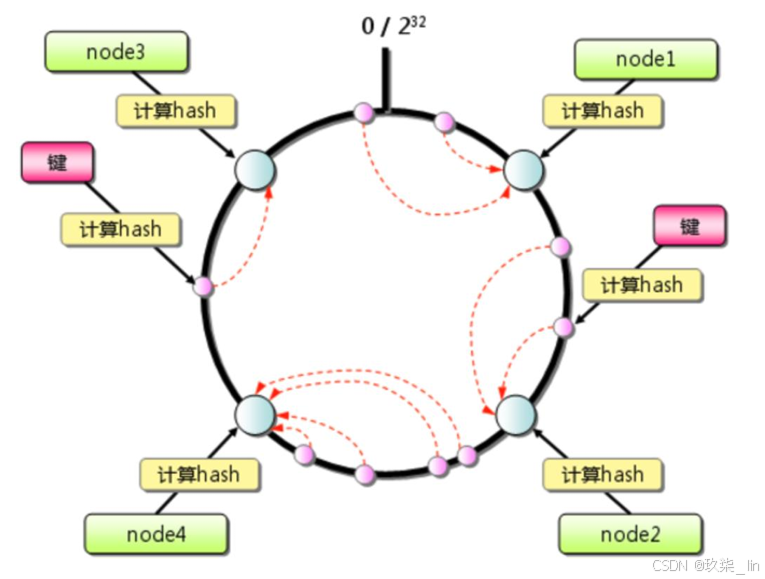
(2)一致性哈希(面)
一致性哈希算法將整個哈希值空間組織 成一個虛擬的圓環,其范圍為0 ~ 2^32-1, 如圖所示。 我們會先對Key計算它的hash值,從而確 定它在環上的位置。然后從該位置沿著環順指針地走,找到的第一個節點,便是這個 Key應該存放的服務器節點的位置。(容易造成雪崩的問題)
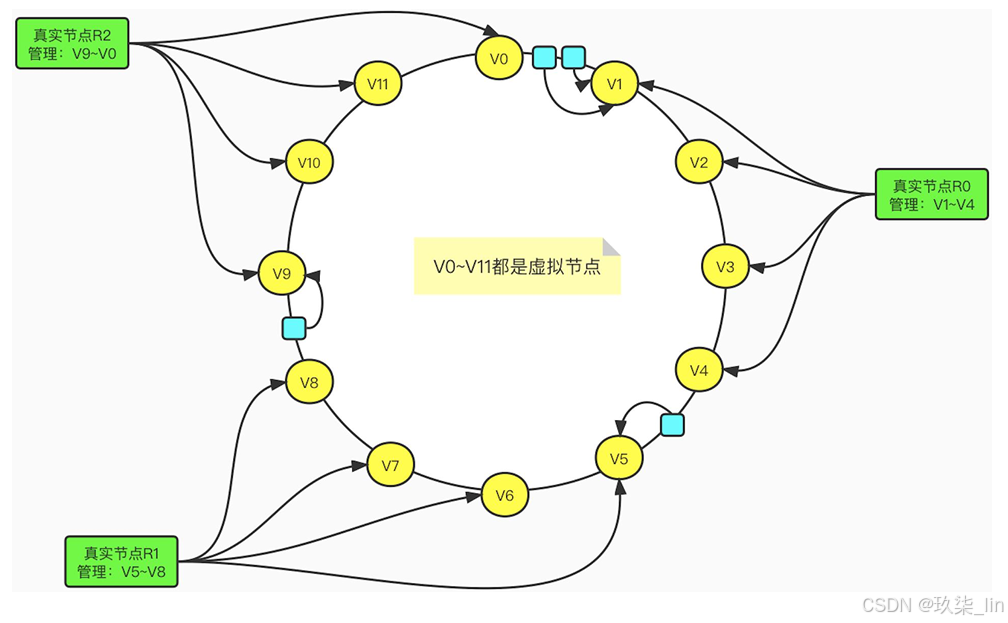
(3)虛擬節點 + 一致性哈希
該方案在一致性哈希的基礎上,引入了虛擬節點這一概念。原本是由實際節點來“搶占” 哈希環的位置,現在則是將虛擬節點分配給實際節點,然后由虛擬節點來搶占。如圖所示:
在引入了虛擬節點這一概念后,數據 到實際節點的映射關系就變成了數據 到虛擬節點,再由虛擬節點到實際節 點了。Redis集群便是采用了這種方 案。一個集群包含16384個哈希槽 (hash slot)也就是16384個虛擬節 點。譬如,我們的集群有三個節點, 那么:
- Master1節點負責處理0~5460號 slot
- Master2節點負責處理5461~ 10922號slot
- Master3節點負責處理10923~ 16383號slot
2. 集群搭建
?由于Redis Cluster要求必須要至少6個節點,所以我們就以配置3主3從為例。修改redis 6390.conf ~ redis-6395.conf配置文件
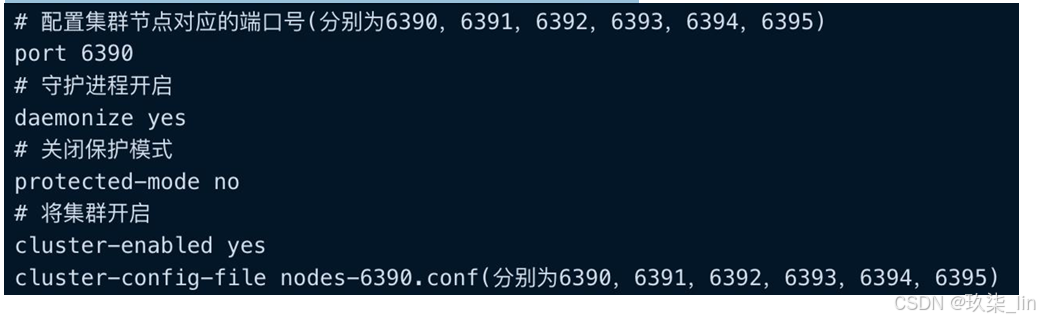
分配主從(--cluster-replicas 1:表示創建1主1從)
- ./redis-cli --cluster create 127.0.0.1:6390 127.0.0.1:6391 127.0.0.1:6392 127.0.0.1:6393 127.0.0.1:6394 127.0.0.1:6395 --cluster-replicas 1
配置完集群后,可能會報錯——16384個槽位沒有分配完。我們通過如下指令就可以進行檢查和修復
- redis-cli --cluster check 172.17.0.2:6379
- redis-cli --cluster fix 172.17.0.2:6379 #官方修復功能
十二、面試
1. 緩存穿透(查不到數據)
當用戶想要查詢一個數據,發現Redis中不存在,也就是所謂的緩存沒有命中,于是這個 數據請求就會打到數據庫中。結果數據庫中也不存在這條數據,那么結果就是什么都沒 查詢出來。那么當用戶很多時候的查詢,緩存中都沒有數據,請求直接打到數據庫中, 這樣就會給數據庫造成很大的壓力,緩存的作用也就幾近于失效了,那么這種情況就叫 做緩存穿透。
解決方案: ① 當數據庫中也查詢不到數據時,那么將返回的空對象也緩存起來,同時設置一個過期時間,之后再訪問這個數據將會從緩存中獲取, 從而起到保護數據庫的作用。 ② 添加布隆過濾器。如圖所示:
布隆過濾器:如果查不到,是真的查不到,如果查到了,不一定是真的查到了。所以通過布隆過濾器查不到,直接返回即可
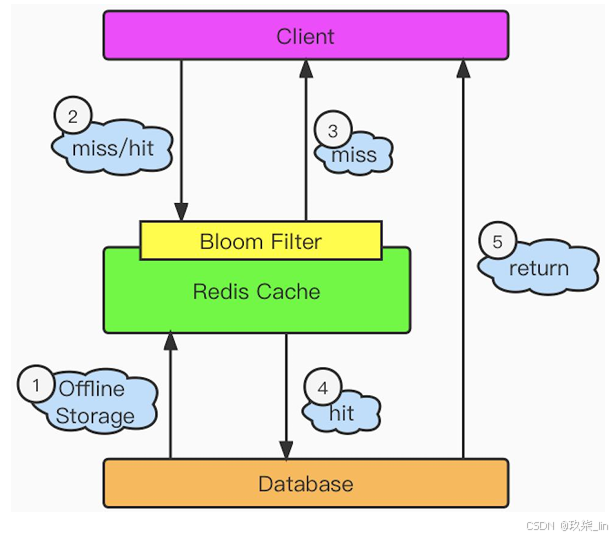
緩存穿透:查不到數據,穿透的是redis。因為redis緩存中沒有數據,所以擊穿redis訪問數據庫。
2. 緩存擊穿(高并發查詢某數據,且緩存過期)
指一個非常熱點的key,在不停的高并發請求著,那么當這個key在緩存中失效的一瞬間, 持續對這個key的高并發就擊穿了緩存,直接請求到了數據庫,就像在一個屏障上早開了 一個洞。當熱點key過期失效的一瞬間,高并發突然融入,會對數據庫突然造成巨大的壓 力,嚴重的情況甚至會造成數據庫宕機。
解決方案:
① 方案一:設置熱點數據永不過期 從緩存層面來看,沒有設置過期時間,所以不會出現熱點key過期后所產生的緩存擊穿問題。
② 方案二:加互斥鎖?在數據庫的前面一層加分布式鎖,當緩存數據過期后,保證對每個熱點key同時只有一個線程去查詢后端 服務,并將熱點數據添加到緩存。
3. 緩存雪崩(緩存大批量失效或Redis宕機)
指在某一個時間段,緩存集中過期失效,或Redis宕機,導致針對這批數據的查詢都落到 了數據庫上,對于數據庫而言,就會產生周期性的壓力波峰。于是所有的請求都會達到 存儲層,存儲層的調用量會暴增,造成存儲層也會掛掉的情況。其實緩存集中過期,倒 不是最致命的,比較致命的是Redis發生節點宕機或斷網。因為緩存集中過期后,數據庫 壓力增大,但是隨著緩存的創建,壓力也會逐漸變小。針對Redis服務節點宕機,對數據 庫服務器造成的壓力是不可預知的,很有可能是持續壓力而最終造成數據庫宕機。
解決方案 :
① 方案一:配置Redis集群
通過配置Redis集群,提升高可用性,那么即使掛掉幾個Redis節點,集群內的其他Redis 節點依然可以繼續對外提供服務。
② 方案二:限流降級
緩存失效后,通過加鎖或隊列來控制讀取數據庫且寫入緩存的線程數量。常用的緩存降級是MQ。
③ 方案三:數據預熱分散過期時間
在正式部署之前,先把可能被高頻訪問的數據預先訪問一遍,這樣大部分熱點數據就加 載到緩存中了,并且通過設置不同的過期時間,讓緩存失效的時間盡量均勻,防止同一時刻 大批量緩存失效
4. 布隆過濾器
布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進制向量 和一系列隨機映射函數。布隆過濾器可以用于檢索一個元素是否在一個集合中。它的優 點是空間效率和查詢時間都比一般的算法要好的多,缺點是有一定的誤識別率和刪除困 難。
布隆過濾器的特征是:它可以判斷某個數據一定不存在,但是無法判斷一定存在。(確實有點拗口,但當我們介紹完它的原理,就很容易明白了)
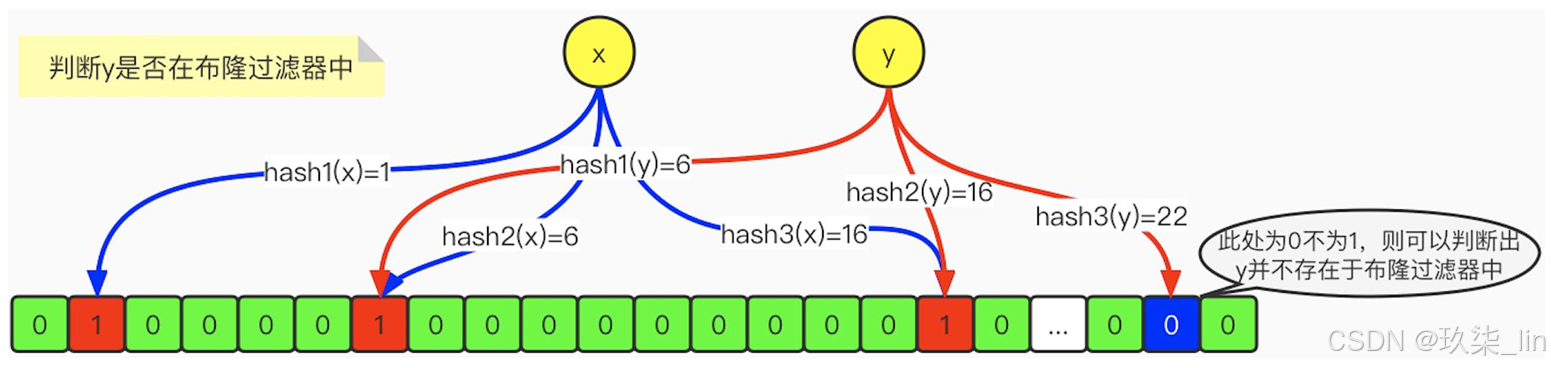
布隆過濾器:判斷不存在則一定不存在,判斷存在也不一定存在。
- ?把數據庫中的數據以離線的方式存到redis緩存中。
- ?Client發請求,首先布隆過濾器判斷,如果不存在,則返回miss ③
- 如果布隆過濾器判斷存在,則請求redis,再將數據返回給client
刪除困難:不提供刪除能力
數據一致性不能完全被解決。












)
Linux的歷史與環境搭建)





教程)