從看一篇論文開始:Performance Evaluation of TCP BBRv3 in Networks with Multiple Round Trip Times,結論比較悲觀:
- 雖然 BBRv2/3 試圖解決 BBRv1 的公平性問題,但結果依舊不夠理想,BBR 的迭代依舊任重而道遠。
BBR 即使到了 v3 也依然不能論證穩定收斂,也因此它沒辦法成為默認擁塞控制算法。工程界和學界雖越發成為熟人社會卷得厲害,以前也不入流的東西最后可能通過類似 “送禮”,“互捧”,“交易” 的途徑就能標準化,但下限至少是能基本論證穩定和收斂,BBR 目前還差點。
總體而言,此文觀點很明確且有用,比提出個優化點,實驗室用 mininet,ns3,tc 模擬仿真一下吊打原生算法幾十個百分點,然后水一篇論文強很多,說實話那些東西也只是像我這樣沒事寫篇隨筆發個朋友圈的水準。也許稍微好一點,也許還不如我,誰知道呢。
本文剩下的部分主要談 BBR 內部公平性,展示它的難度,最后以描述外部公平性同樣難甚至更難結尾。
作為常識,公平性必須靠 buffer 動力學驅動,在 buffer 擠兌中獲得,遺憾的是,BBR 的 Probe 行為不但沒有利用 buffer 制造多流收斂,反而放大了差異,傾向于利好 RTT 偏大的流,這是不公平性的根源。就好像一個胖子一點點把瘦子擠到邊邊一樣,在不斷接觸中,一次挪一點。
來看看 Why。
此前我分析過,若不是 ProbeRTT 主動清空 buffer 堆積,實踐中的 BBR 將占 buffer 越來越多(雖然在理論分析中,BBR 從不堆積 buffer 制造隊列),這事實即使不看 draft 和代碼,稍微想一下就能明白。這里我再重復講一次(不啰嗦這些,本文也不剩啥了)。
只要 BBR 多流共存,任意一條當前 pacing rate 為 B1 的流只要 Probe 就一定能獲得更大的 buffer 占比,從而一定能擠占出哪怕一丁點帶寬 B2,且 B2 > B1 作為新的 maxbw 被 max-filter 記住,它隨后的 Drain phase 僅能 drain 掉 inflight 中比 B2 · minrtt 多出來的那部分,剩下的 B2 · minrtt - B1 · minrtt 的部分就留在了 buffer 中。
現在用控制變量法,讓其它流不進行 Probe,由于已經完成 Probe 的流擠出了更大的 B2,剩下的流即使保持各自當前 pacing rate,buffer 占用仍會增加,一直到這些流的 maxbw 紛紛過期,buffer 才停止增長。現在釋放控制變量,讓其自由 Probe,不等式傳遞原理,這種真實情況下一定比假設的情況占用更多 buffer。如此反復,隨著 BBR 流持續,buffer 占用將越來越大。
Probe 停止,maxbw 會過期并跌落,buffer 會停漲,但它不會自動清空,只是維持。類似河流經過已經填滿的湖泊,除非枯水不會自動排空湖泊一樣。更何況,Probe 不會停止,因此 buffer 會一直漲下去:
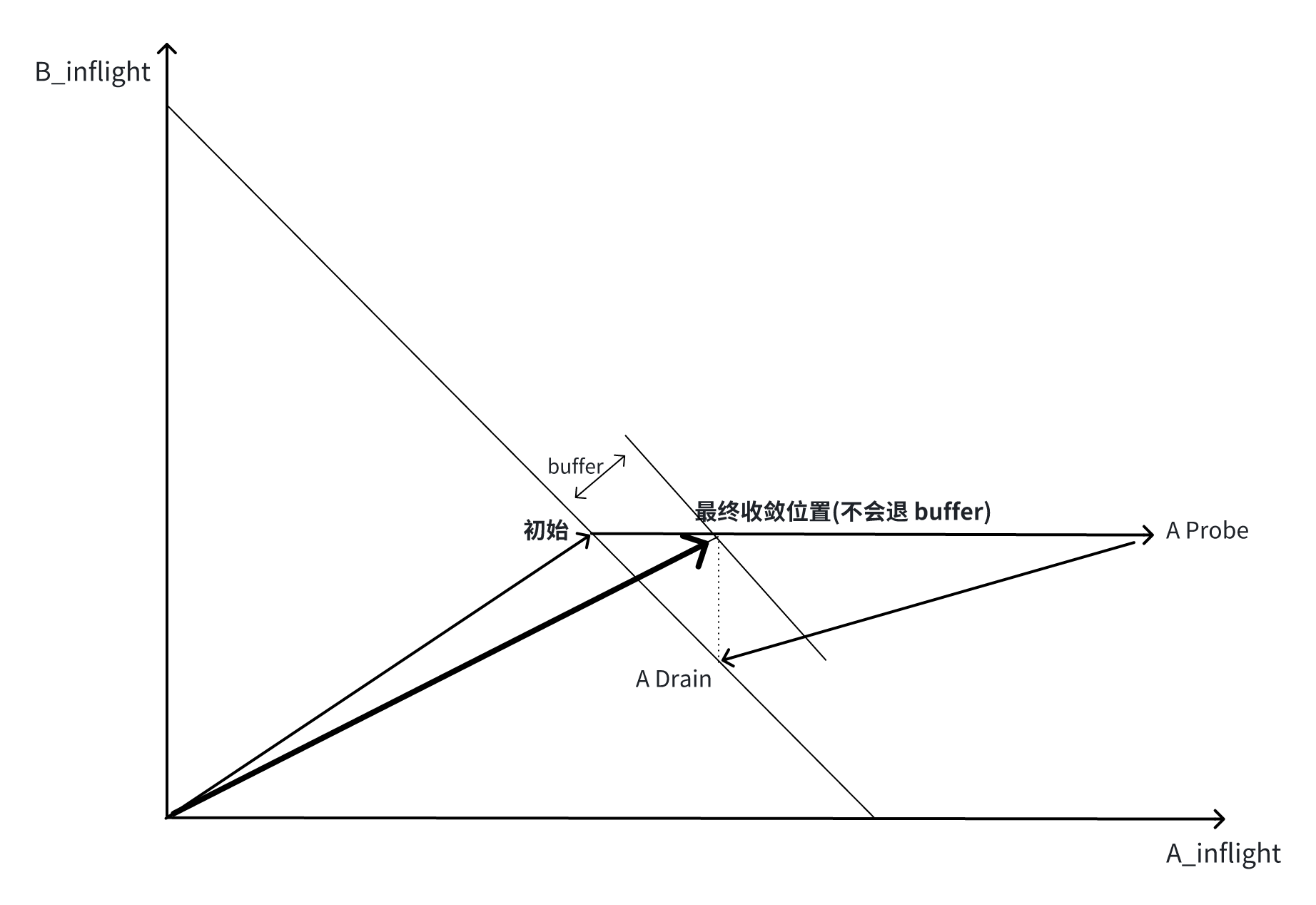
若沒有 ProbeRTT,buffer 將類似上圖指示,從終點不斷堆積下去。但在 ProbeRTT 之前,還得先看下 cwnd gain 對 inflight 的約束。
不知是有意還是無意(也許 Google BBR 團隊從最開始真的就沒意識到這個問題),BBR 增加了 cwnd_gain 作為約束,限制 inflight 最大只能到 2 · BDP,以限制 buffer 的瘋漲,但這個限制讓 RTT 更小的流的處境更加雪上加霜。
BDP = bw · RTT,先看 bw,BBR 流的 bw 通過 Qp = 1.25 · maxbw · minrtt 的 Probe 量在 buffer 擠占出來, 可見 minrtt 越小,Qp 越小,再看 RTT,由于 buffer 占用持續增長,RTT = RTprop + RTwait 持續增長,管道容量增加,inflight = maxbw · (minrtt + RTwait) > 2 · maxbw · minrtt 更容易首先滿足 minrtt 小的流,因此 minrtt 小的流首先被 cwnd 限制。
不光如此,這個 cwnd-limited 問題甚至限制 Probe,越是被壓制的流越是被繼續壓制。由于 minrtt 更小流的 BDP 組分中 RTwait 占比很大,即使它的 Probe 加速比更高,其 bw 增量也不足以彌補 RTwait,maxbw 漲太慢,RTwait 值太大,BDP = maxbw · (minrtt + RTwait) 很快遭遇它的上限 2 · maxbw2 · minrtt。BBR 團隊和討論組早就發現這個問題,BBRv3 進行了修正,Probe 期間的 cwnd_gain 從 2 提升到了 2.25,但并沒解決本質問題。
所以,BBR 高度依賴 ProbeRTT,但主動突然排空 buffer 的行為讓 BBR 的 ProbeBW 狀態被中斷,buffer 隊列沒了,但只是把隊列轉到了 sender 的發送緩沖區,在端到端的數據生成處看來,數據只是 bufferbloat 在了尚未進入網絡協議棧的第 0 跳,ProbeRTT 遠沒有解決問題,只是轉移了問題。
核心問題還是要讓算法自動感知 RTT 的升高,無論是 RTwait 的升高還是 minrtt 本來就高,這兩種情況下,算法都要傾向于抑制 Probe,無論是縮短 Probe 時間,還是降低 pacing gain。
再一次,第一個想到的還得是靠 sigmoid 做激發函數,不過這次先簡單點,直接用兩個 sigmoid 來線性疊加,背后的意思是提供兩個負反饋:
- 隊列越長,即 RTT - minrtt 越大,越傾向于抑制 Probe;
- RTprop 越長,越傾向于抑制 Probe;
- 用 sigmoid 函數去量綱,歸一。
操作如下:
S i g m o i d ( x , α , β , γ ) = α 1 + e β ? x + γ \mathrm{Sigmoid}(x,\alpha,\beta,\gamma)=\dfrac{\alpha}{1+e^{\beta\cdot x}}+\gamma Sigmoid(x,α,β,γ)=1+eβ?xα?+γ
A = B = 1 A=B=1 A=B=1
K = A ? S i g m o i d ( R T T ? R T p r o p , α 1 , β 1 , γ 1 ) + B ? S i g m o i d ( R T p r o p , α 2 , β 2 , γ 2 ) K=A\cdot\mathrm{Sigmoid}(\mathrm{RTT-RTprop},\alpha_1,\beta_1,\gamma_1)+B\cdot\mathrm{Sigmoid}(\mathrm{RTprop},\alpha_2,\beta_2,\gamma_2) K=A?Sigmoid(RTT?RTprop,α1?,β1?,γ1?)+B?Sigmoid(RTprop,α2?,β2?,γ2?)
G a i n = S i g m o i d ( K , α , β , γ ) \mathrm{Gain}=\mathrm{Sigmoid}(K,\alpha,\beta,\gamma) Gain=Sigmoid(K,α,β,γ)
用實際現網數據訓練,求出最佳擬合的幾個 α,β,γ 就可以了。那句廢話 A = B = 1 旨在表明一個點,兩個并列的 Sigmoid 函數沒必要加權,也許你會覺得 “單純 RTprop 大” 和 “單純 RTwait 大” 需要區別對待,其實不必,因為 Sigmoid 有個激發特性,只要 RTprop 和 RTwait 沒有一起大,它們和的 Sigmoid 函數就可以很小,只需調整 α2,β2,γ2 讓其向右偏,這意味著 RTprop 的作用力比 RTwait 更大,反之向左偏就傾向于 RTwait 的作用力更大。
如果不想實現復雜函數(特別是內核中),可分析現網數據后直接用 python 生成一張算好的表,將其粘貼在代碼里,代碼里查表大概就跟我一個函數幾千個 if 分支差不多的意思了。
為了能抵抗并容忍 minrtt 噪聲,前幾天剛發明一個 minrtt 采集算法,參考 BBR minrtt 的采集,兩個算法疊加,讓人不明覺厲,可以水一篇論文了。
但且慢,這些啟發式把戲難道不是我一直嗤之以鼻的嗎,我一再強調 RTT 的不準確性,算不準就別算,所以除卻這些可能適合論文或蒙騙經理的把戲,還有一個更加實用的方法。
參考 L4S & TCP Prague,TCP Prague 的 draft 提到一種 極簡主義算法 來去除 RTT 相關性,從而解決 AIMD 場景的 RTT 不公平性。模仿該思想,一個正確實用的算法就來了:
P r o b e Q u o t a = M a x B W ? R T p r o p + 0.25 ? min ? ( R T p r o p , δ ) \mathrm{ProbeQuota}=\mathrm{MaxBW}\cdot \mathrm{RTprop}+0.25\cdot\min(\mathrm{RTprop},\delta) ProbeQuota=MaxBW?RTprop+0.25?min(RTprop,δ)
其中 δ 為一個經驗的,統計意義上的 RTprop 中位數或其它的典型值,在不同網絡中有不同的典型值。
修改下面的函數即可:
static void bbr_update_cycle_phase(struct sock *sk,const struct rate_sample *rs,struct bbr_context *ctx)
{...case BBR_BW_PROBE_UP:
總之,BBR 的公平性之路還有很長的路要走,不僅僅是 BBR 內部的公平性,還有與 cubic 等 AIMD 算法共存時的外部公平性。
外部公平性,這很大程度上是因為存量 TCP 多數使用久經考驗和論證的 cubic 等 AIMD 算法,想當年 Reno AIMD 算法上線時,它是一個從零到一的過程,并不需要考慮外部公平性,而內部公平性非常好論證,隨后的 bic,cubic 也只是簡單迭代,可一旦涉及完全不同的機制,比如 Vegas,考慮到部署后的公平性,基本就是胎死腹中。看,BBR 為了外部公平性,又回到了老路,哪怕只是為了兼容,可能它必須兼容。
浙江溫州皮鞋濕,下雨進水不會胖。

)




:超詳細繼承知識點)





 -- 圖形界面)




RestAPI 毛子(外部導入打卡/游標分頁/Refit/Http resilience/批量提交/Quartz后臺任務/Hateoas Driven))

