目錄
一. PySpark前言介紹
二.基礎準備
三.數據輸入
四.數據計算
1.數據計算-map方法
2.數據計算-flatMap算子
3.數據計算-reduceByKey方法
4.數據計算-filter方法
5.數據計算-distinct方法
6.數據計算-sortBy方法
五.數據輸出
1.輸出Python對象
(1)collect算子
(2)reduce算子
(3)take算子
(4)count算子
2.輸出到文件中
六.分布式集群運行(作者談感受)
此章節主要講解PySpark技術其中內容分為:前言介紹、基礎準備、數據輸入、數據計算、數據輸出、分布式集群運行。
基礎準備主要是:“安裝PySpark”和PySpark執行環境入口對象,理解PySpark的編程模型。
分布式集群運行這一章,作者并未學到liunx還有專門的大數據因此無法演示。
一. PySpark前言介紹
Spark的定義:Apache Spark是用于大規模數據(large-scala data)處理的統一(unified)分析引擎

簡單來說,Spark是一款分布式的計算框架,用于調度成百上千的服務器集群,計算TB、PB乃至EB級別的海量數據

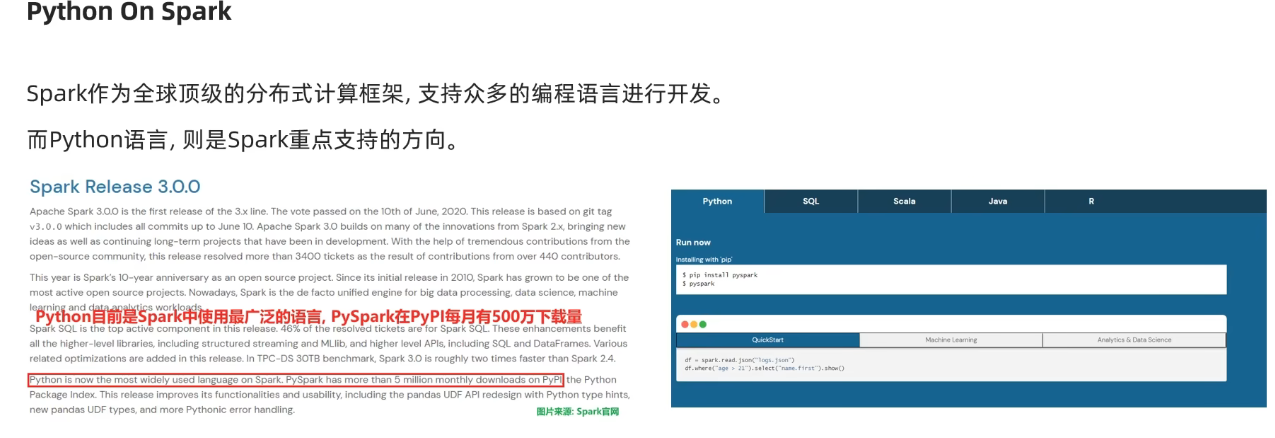
學習PySpark技術的目的:由于Python應用場景和就業方向是十分豐富的,其中,最為亮點的方向為:“大數據開發”和“人工智能”

總結:
1.什么是Spark、什么是PySpark
- Spark是Apache基金會旗下的頂級開源項目,用于對海量數據進行大規模分布式計算。
- PySpark是Spark的Python實現,是Spark為Python開發者提供的編程入口,用于以Python代碼完成Spark任務的開發
- PySpark不僅可以作為Python第三方庫使用,也可以將程序提交的Spark集群環境中,調度大規模集群進行執行。
二.基礎準備
PySpark庫的安裝
同其它的Python第三方庫一樣,PySpark同樣可以使用pip程序進行安裝。
在”CMD”命令提示符程序內,輸入:
pip install pyspark
或使用國內代理鏡像網站(清華大學源)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
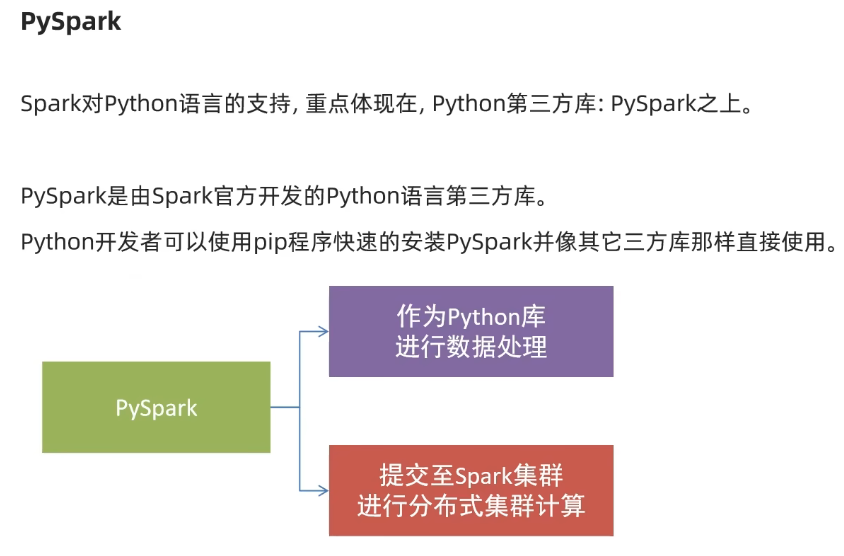
構建PySpark執行環境入口對象
想要使用PySpark庫完成數據處理,首先需要構建一個執行環境入口對象。
PySpark的執行環境入口對象是:類SparkContext 的類對象

以下是示例代碼如下:
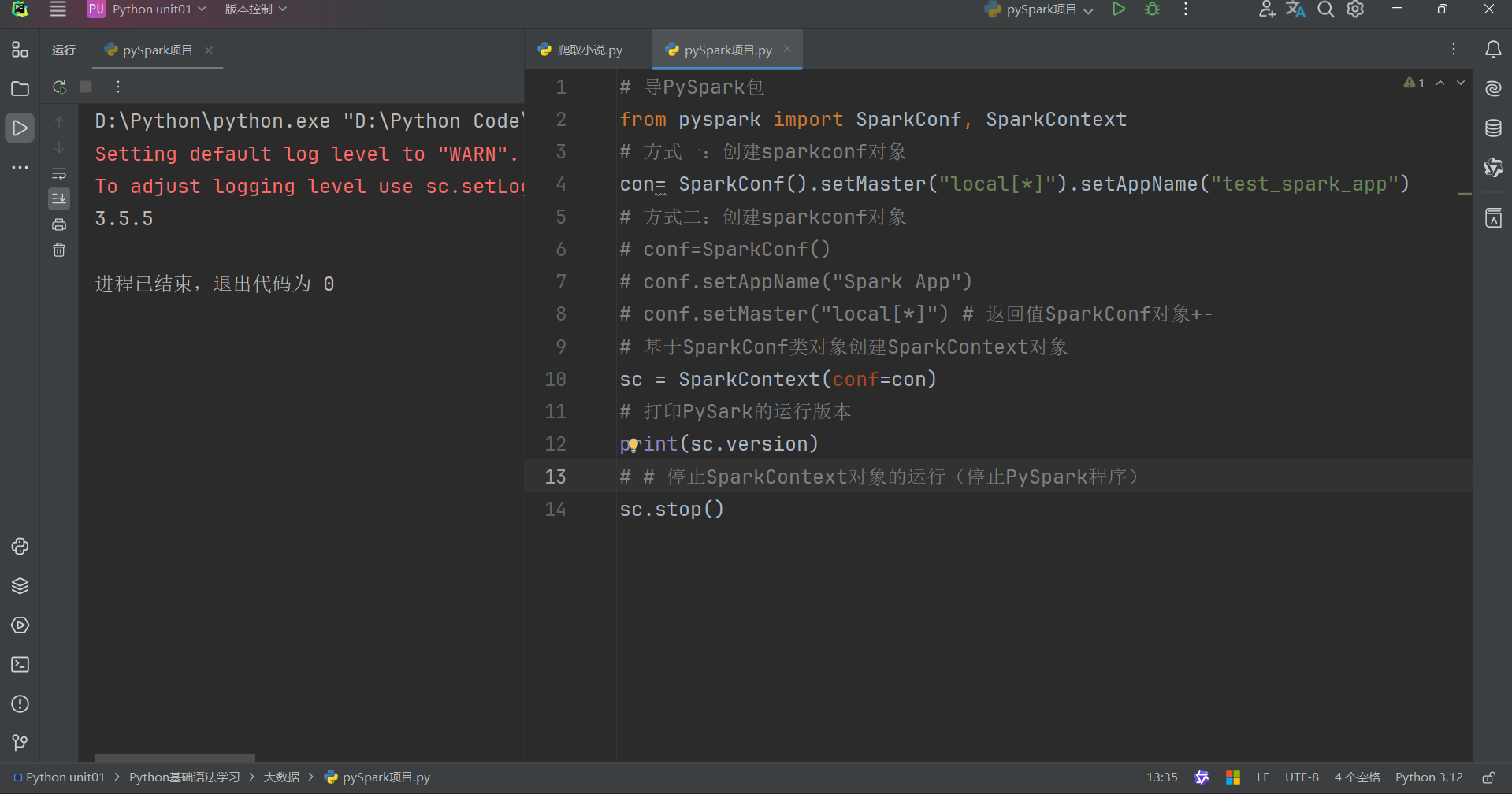
注:
若輸出結果是cmd? �����?����?���??���?����е?��� ���������?���
Java gateway process exited before sending its port number
則需要你去環境變量添加JDK和在path中添加“C:\Windows\System32”即可,作者親測有效。后面可能還需要hadoop的配置,可自行b站,作者也是找半天配半天,甚至這個問題也是靠了我們CSDN大佬的各種解決方法得出來,我只能說CSDN是國內最好用的平臺。
PySpark的編程模型
SparkContext類對象,是PySpark編程中一切功能的入口。
PySpark的編程,主要分為如下三大步驟:

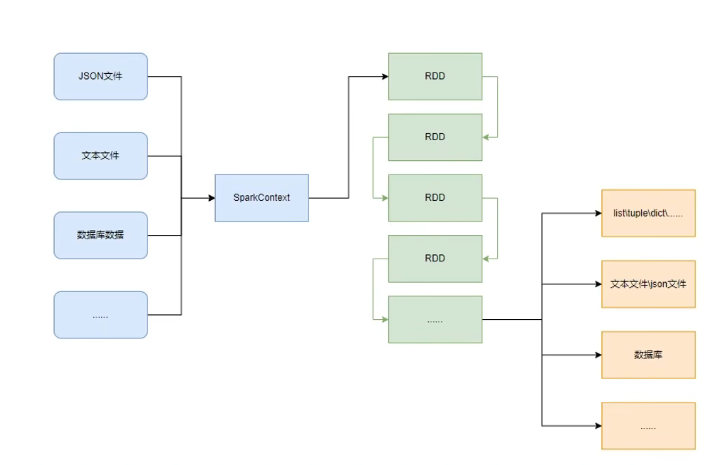
- 通過SparkContext對象,完成數據輸入
- 輸入數據后得到RDD對象,對RDD對象進行迭代計算
- 最終通過RDD對象的成員方法,完成數據輸出工作
總結:
1.如何安裝PySpark庫
pip install pyspark
2.為什么要構建SparkContext對象作為執行入口
PySpark的功能都是從SparkContext對象作為開始
3.PySpark的編程模型是?
數據輸入:通過5parkContext完成數據讀取
數據計算:讀取到的數據轉換為RDD對象,調用RDD的成員方法完成
計算
數據輸出:調用RDD的數據輸出相關成員方法,將結果輸出到list、元組、字典、文本文件、數據庫等
三.數據輸入
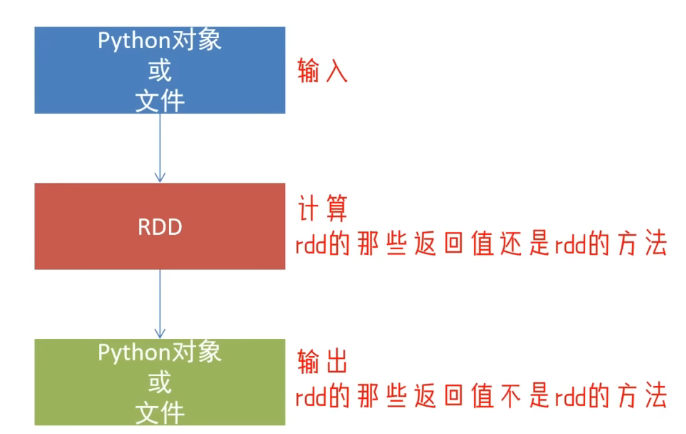
RDD對象
如圖可見,PySpark支持多種數據的輸入,在輸入完成后,都會得到一個:RDD類的對象
RDD全稱為:彈性分布式數據集(ResilientDistributed Datasets)
PySpark針對數據的處理,都是以RDD對象作為載體,即:
- 數據存儲在RDD內
- 各類數據的計算方法,也都是RDD的成員方法
- RDD的數據計算方法,返回值依舊是RDD對象
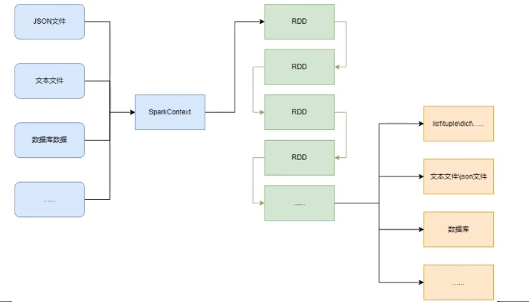
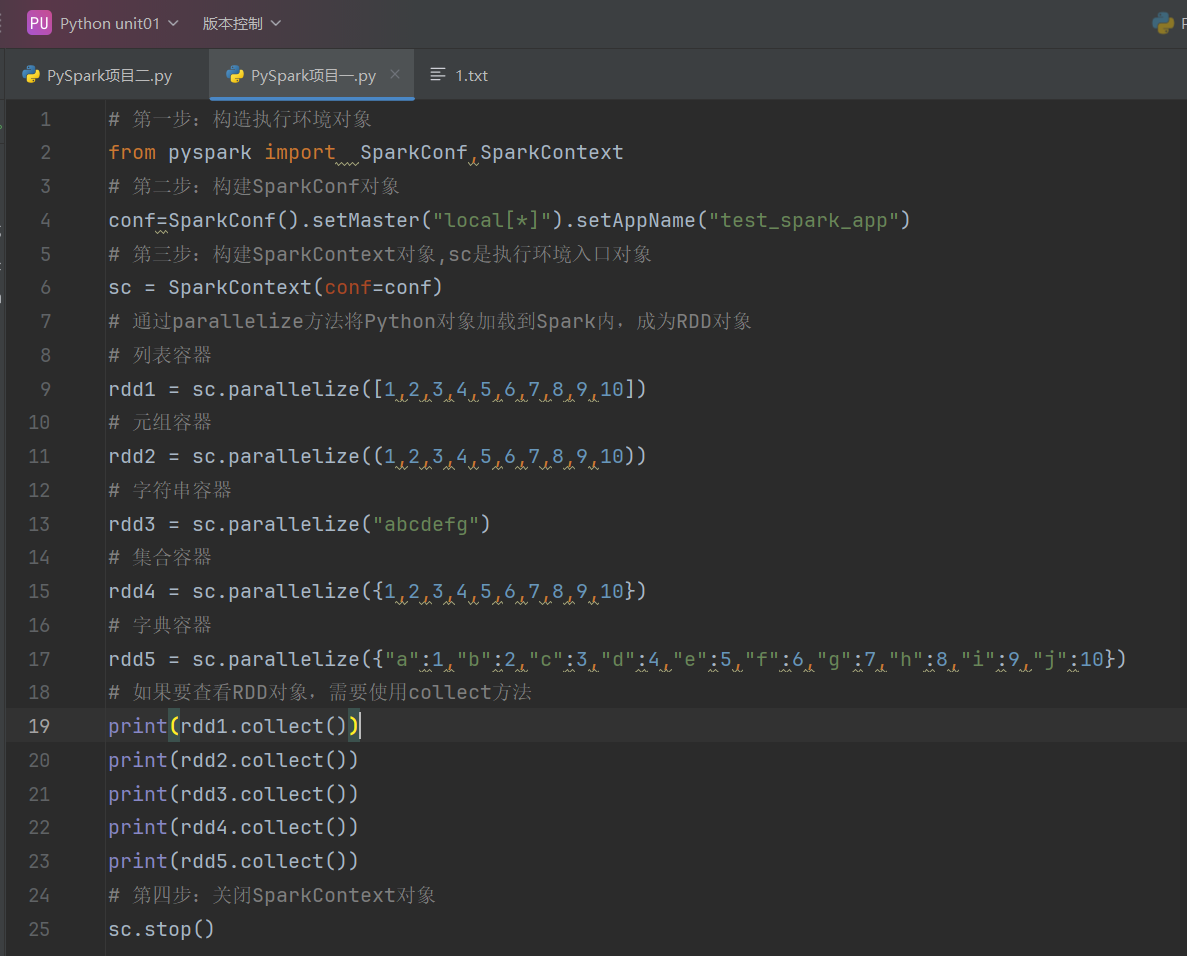
PySpark支持通過SparkContext對象的parallelize成員方法,將:
- list
- tuple
- set
- dict
- str
轉換為PySpark的RDD對象

注意:
- 字符串會被拆分出1個個的字符,存入RDD對象
- 字典僅有key會被存入RDD對象
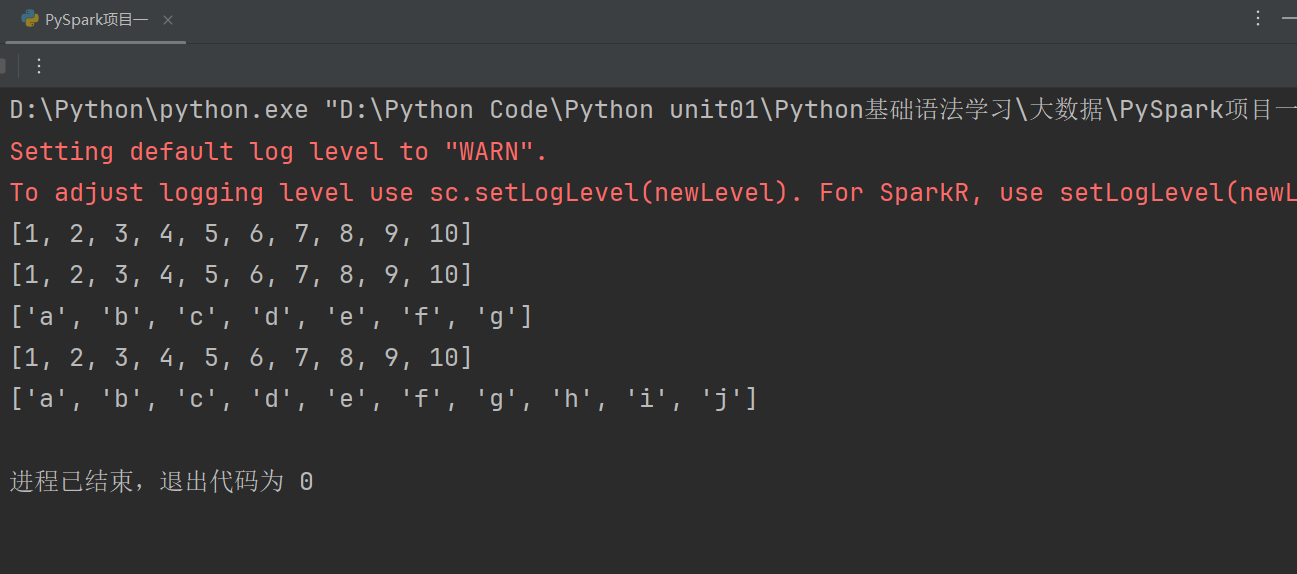
代碼示例如下:
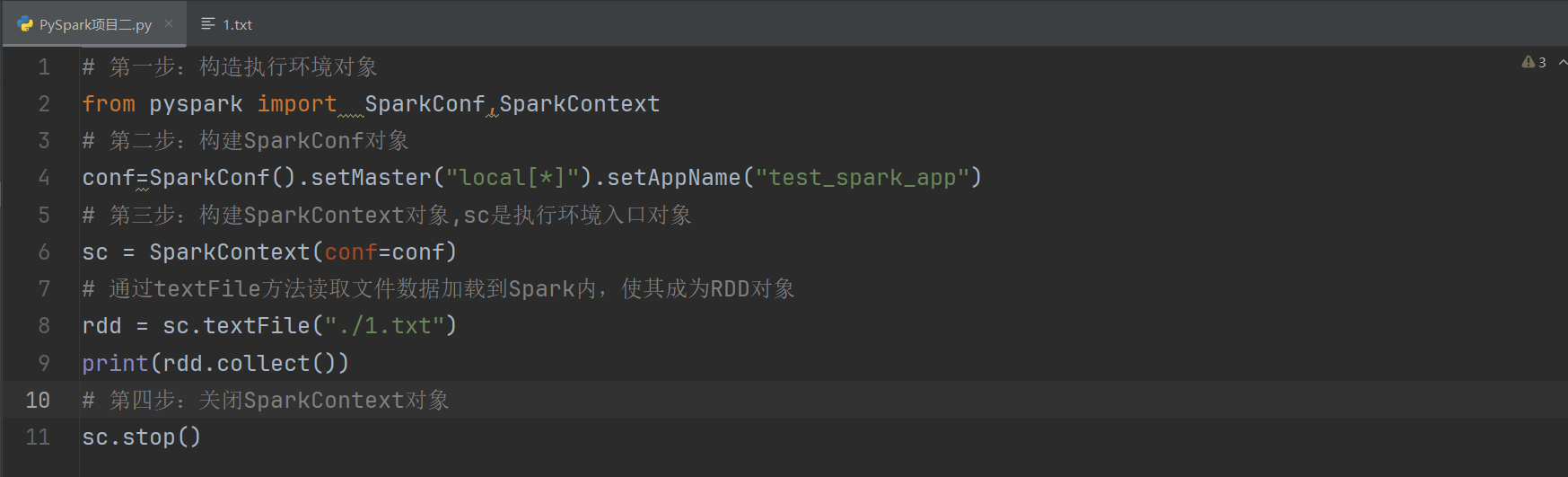
讀取文件轉RDD對象
PySpark也支持通過SparkContext入口對象,來讀取文件,來構建出RDD對象。

代碼演示如下:

總結:
1.RDD對象是什么?為什么要使用它?
RDD對象稱之為分布式彈性數據集,是PySpark中數據計算的載體,它可以:
- 提供數據存儲
- 提供數據計算的各類方法
- 數據計算的方法,返回值依舊是RDD(RDD選代計算)
后續對數據進行各類計算,都是基于RDD對象進行
2.如何輸入數據到Spark(即得到RDD對象)
- 通過SparkContext的parallelize成員方法,將Python數據容器轉換為RDD對象
- 通過SparkContext的textFile成員方法,讀取文本文件得到RDD對象
四.數據計算
此小節分為:map方法、flatMap方法、reduceByKey方法、filter方法、distinct方法、sortBy方法。
1.數據計算-map方法
PySpark的數據計算,都是基于RDD對象來進行的,那么如何進行呢?
自然是依賴,RDD對象內置豐富的:成員方法(算子)
map算子
功能: map算子,是將RDD的數據 一條條處理( 處理的邏輯 基于map算子中接收的處理函數),返回新的RDD
語法:

示例代碼演示如下:
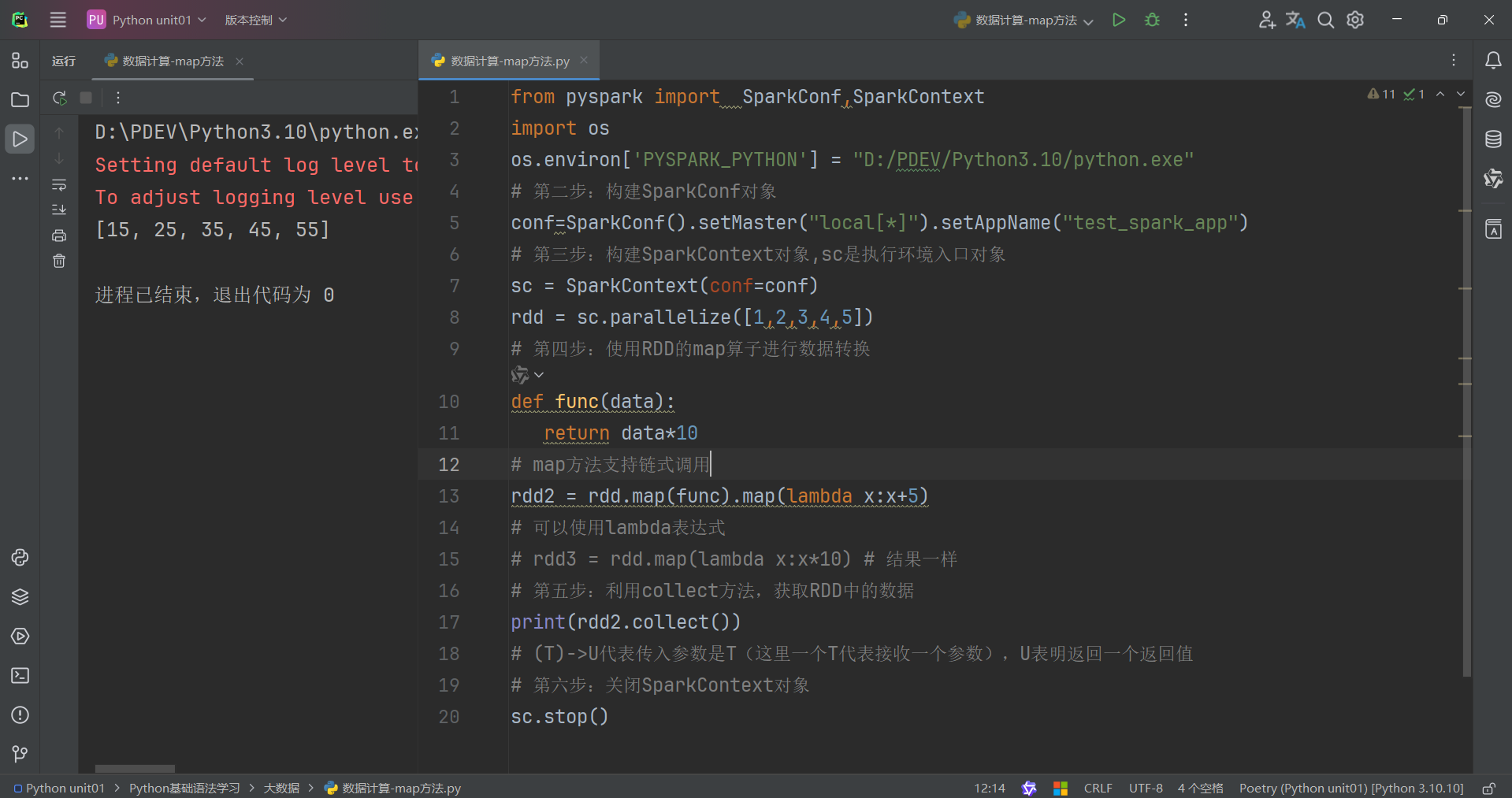
map方法會根據你序列的數據進行一個一個計算,并且返回新的rdd。
因此它也支持鏈式調用。
注:
這里使用map方法有兩個注意地方,作者花大量時間解決這個。一個就是看看自己的Python解釋器一定要是3.10及以下的3.11及最新不能使用,作者已經測試過了。如果你報錯,就一定要將Python解釋器裝一個3.10然后再換上3.10。這是第一個地方。
第二個地方一定要在前面加上import OS導入OS包。并且要在最前面加上:os.environ['PYSPARK_PYTHON'] = "D:/PDEV/Python3.10/python.exe"
這個路徑一定要根據你電腦Python解釋器上面填寫,根據自己電腦配置解釋器的位置進行調配。以上是最主要會導致你程序報錯的原因。
總結:
1.map算子(成員方法)
- 接受一個處理函數,可用lambda表達式快速編寫
- 對RDD內的元素逐個處理,并返回一個新的RDD
2.鏈式調用
- 對于返回值是新RDD的算子,可以通過鏈式調用的方
- 式多次調用算子
2.數據計算-flatMap算子
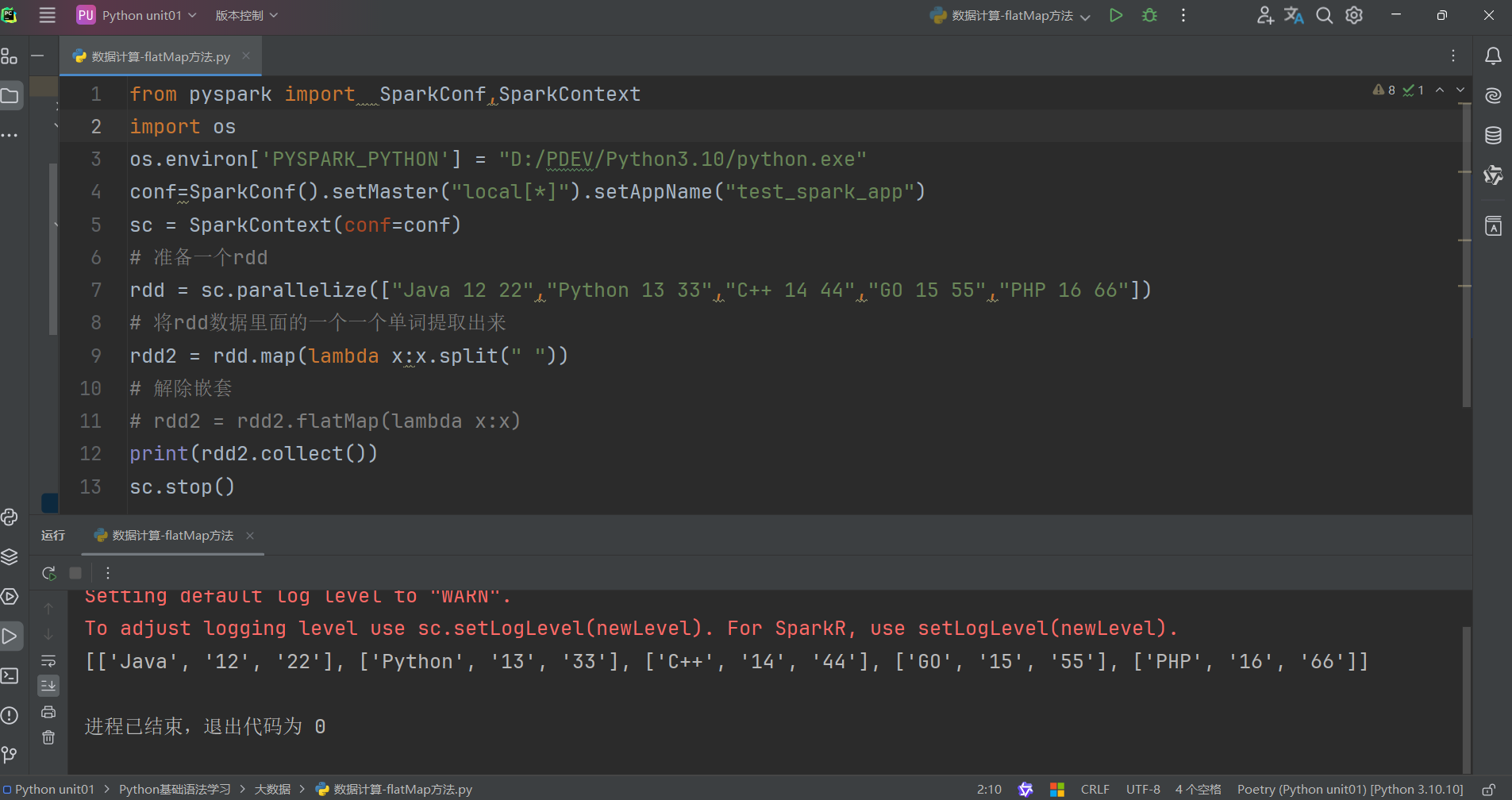
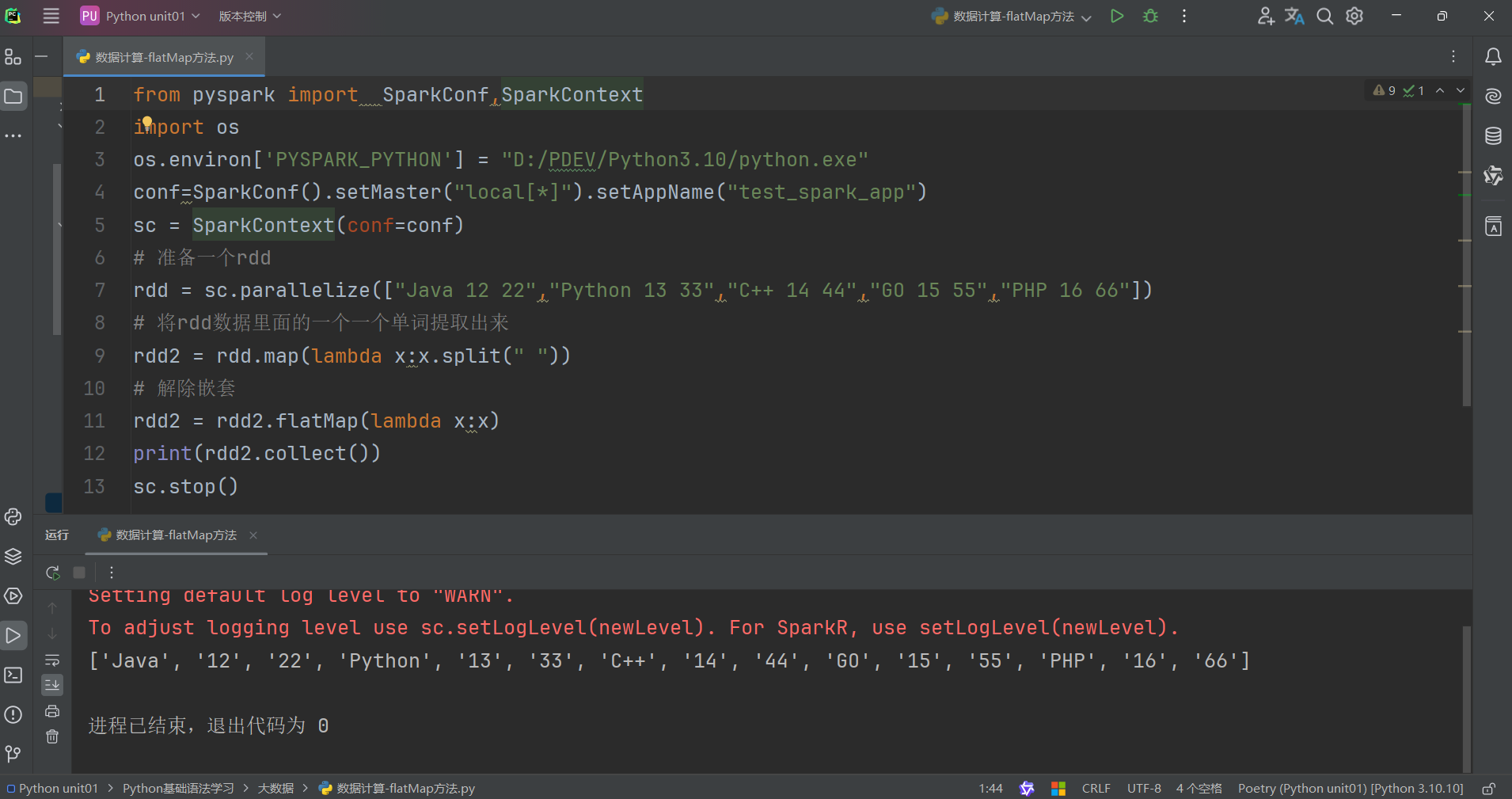
flatMap算子的功能: 對rdd執行map操作,然后進行解除嵌套操作
解除嵌套:

代碼如下:

代碼演示如下:
未使用flatMap方法代碼如下:
使用flatMap方法解除嵌套代碼如下:
總結:
1.flatMap算子
- 計算邏輯和map一樣
- 可以比map多出,解除一層嵌套的功能
3.數據計算-reduceByKey方法
reduceByKey算子的功能:針對KV型 RDD,自動按照key分組,然后根據你提供的聚合邏輯,完成組內數據(value)的聚合操作。
注:KV型指的是存儲數據是二元元組就稱為KV型。
用法:



注:
rdd中存放的是二元元組,元組元素有2個,第一個元素可以視作字典的鍵,第二個是鍵入的值。通過reduceByKey方法可以根據鍵來整合數據的運算操作,這就是聚合。
reduceByKey中接收的函數,只負責聚合,不理會分組。
分組是自動 by key 來分組的。
二元元組,幾元元組指的是元組內部的元素個數有幾個就稱作幾元元組。
reduceBeKey中的聚合邏輯是:
比如,有[1,2,3,4,5],然后聚合函數是:lambda a,b:a+b
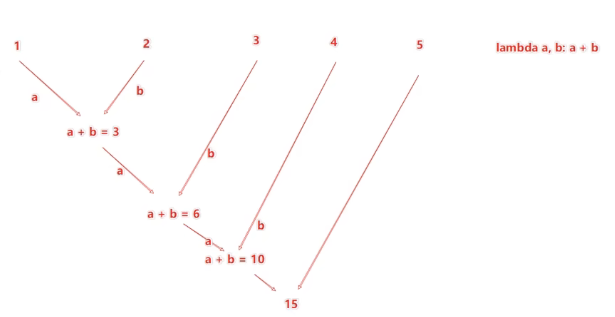
代碼演示如下:
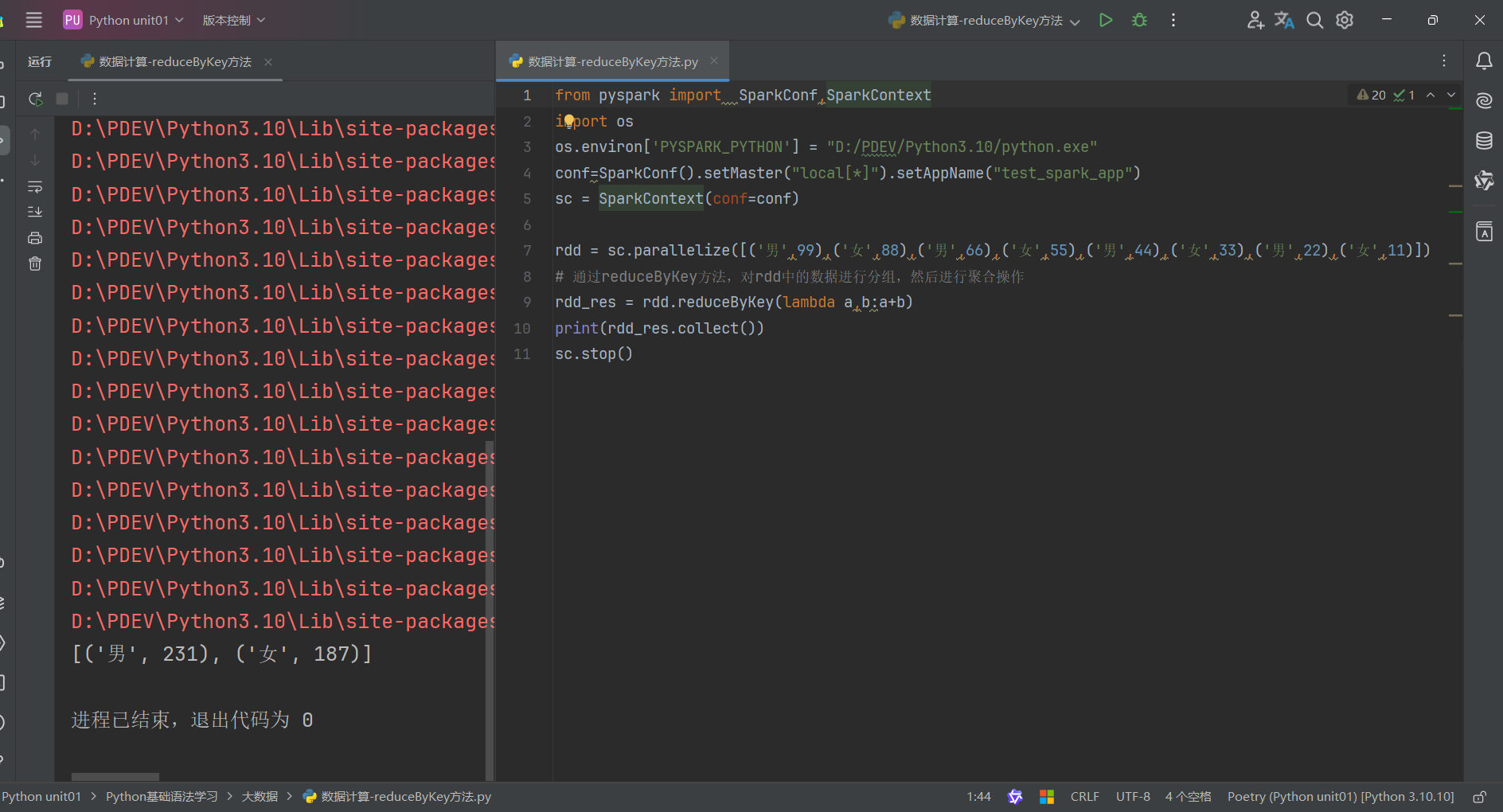
總結:
1.reduceByKey算子
接受一個處理函數,對數據進行兩兩計算
4.數據計算-filter方法
Filter方法的功能:過濾想要的數據進行保留
語法:
![]()
返回的是True的數據被保留,False的數據被丟棄。
代碼如下:

代碼演示如下:

總結:
1.filter算子
- 接受一個個處理函數,可用lambda快速編寫
- 函數對RDD數據逐個處理,得到True的保留至返回值的RDD中
5.數據計算-distinct方法
distinct算子
功能:對RDD數據進行去重,返回新RDD
語法: ![]()
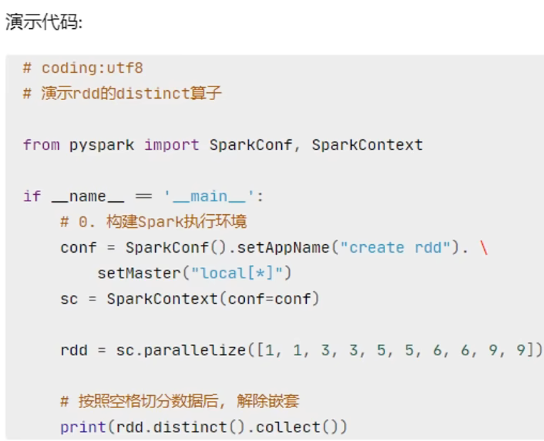
代碼演示如下:
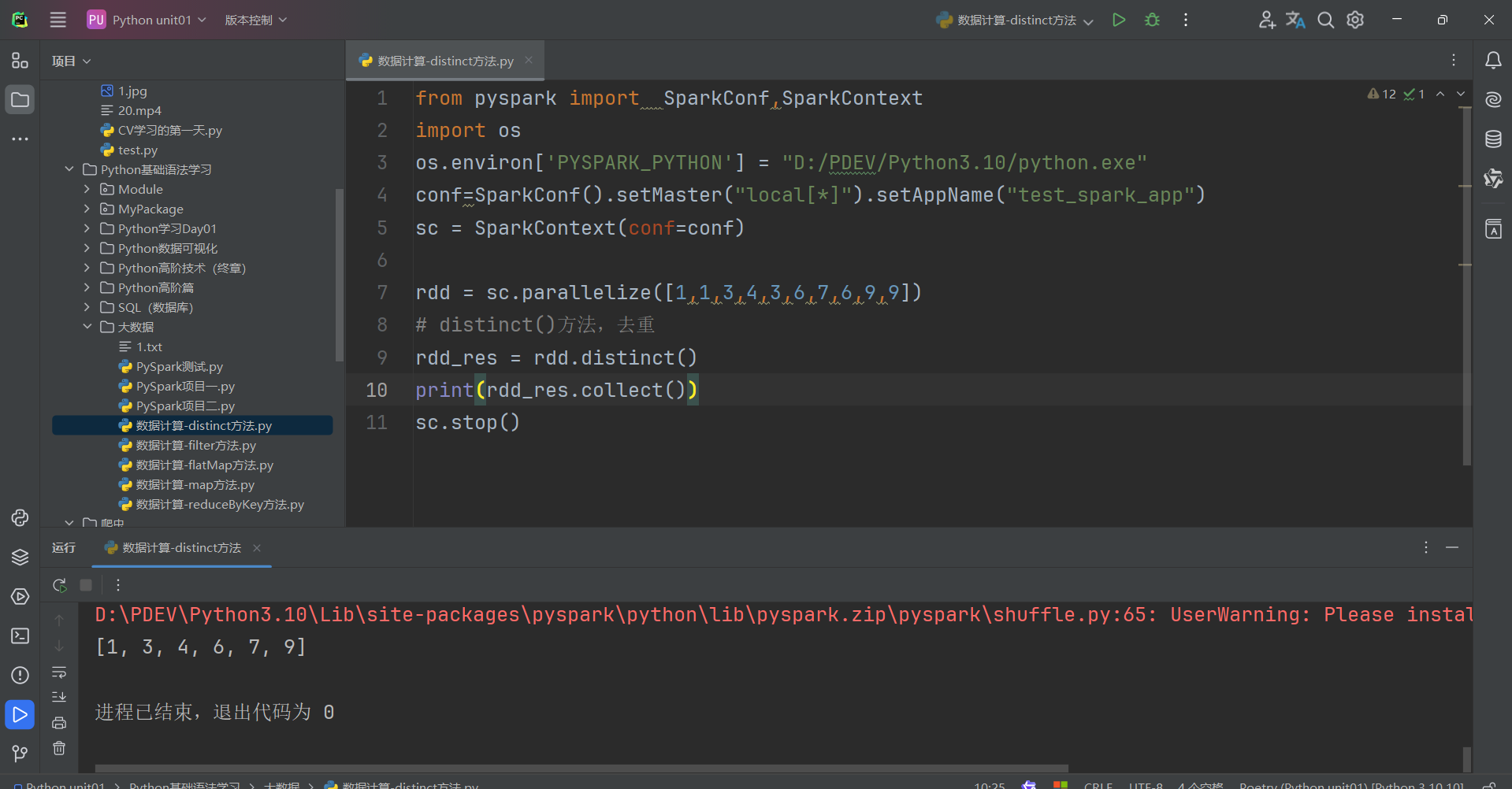
總結:
1.distinct算子
- 完成對RDD內數據的去重操作
6.數據計算-sortBy方法
sortBy算子功能:對RDD數據進行排序,基于你指定的排序依據。
語法:

代碼演示如下:
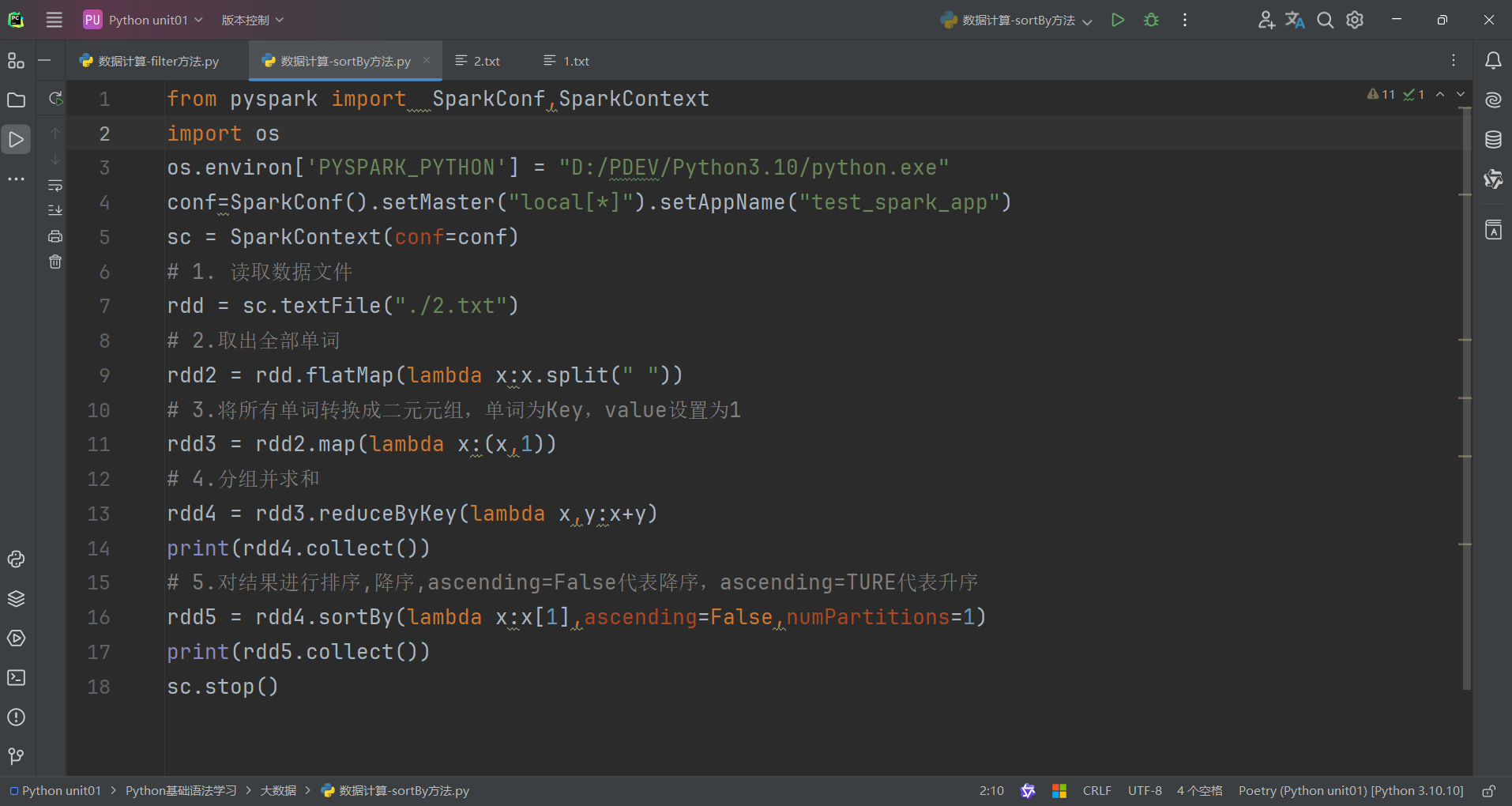
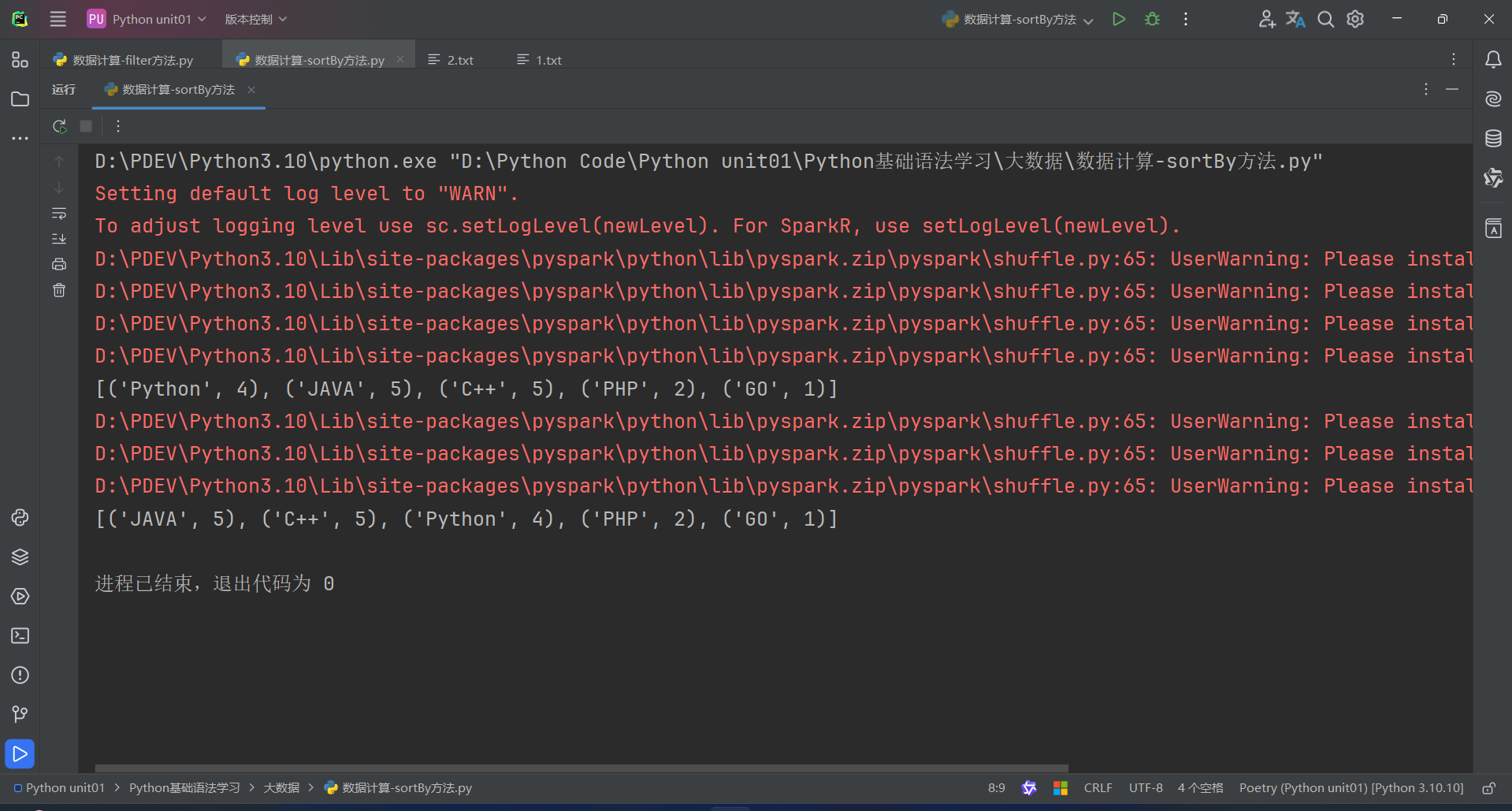
1.sortBy算子
- 接收一個處理函數,可用lambda快速編寫
- 函數表示用來決定排序的依據
- 可以控制升序或降序
- 全局排序需要設置分區數為1
五.數據輸出
此小節分為:輸出為Python對象和輸出到文件中。
1.輸出Python對象
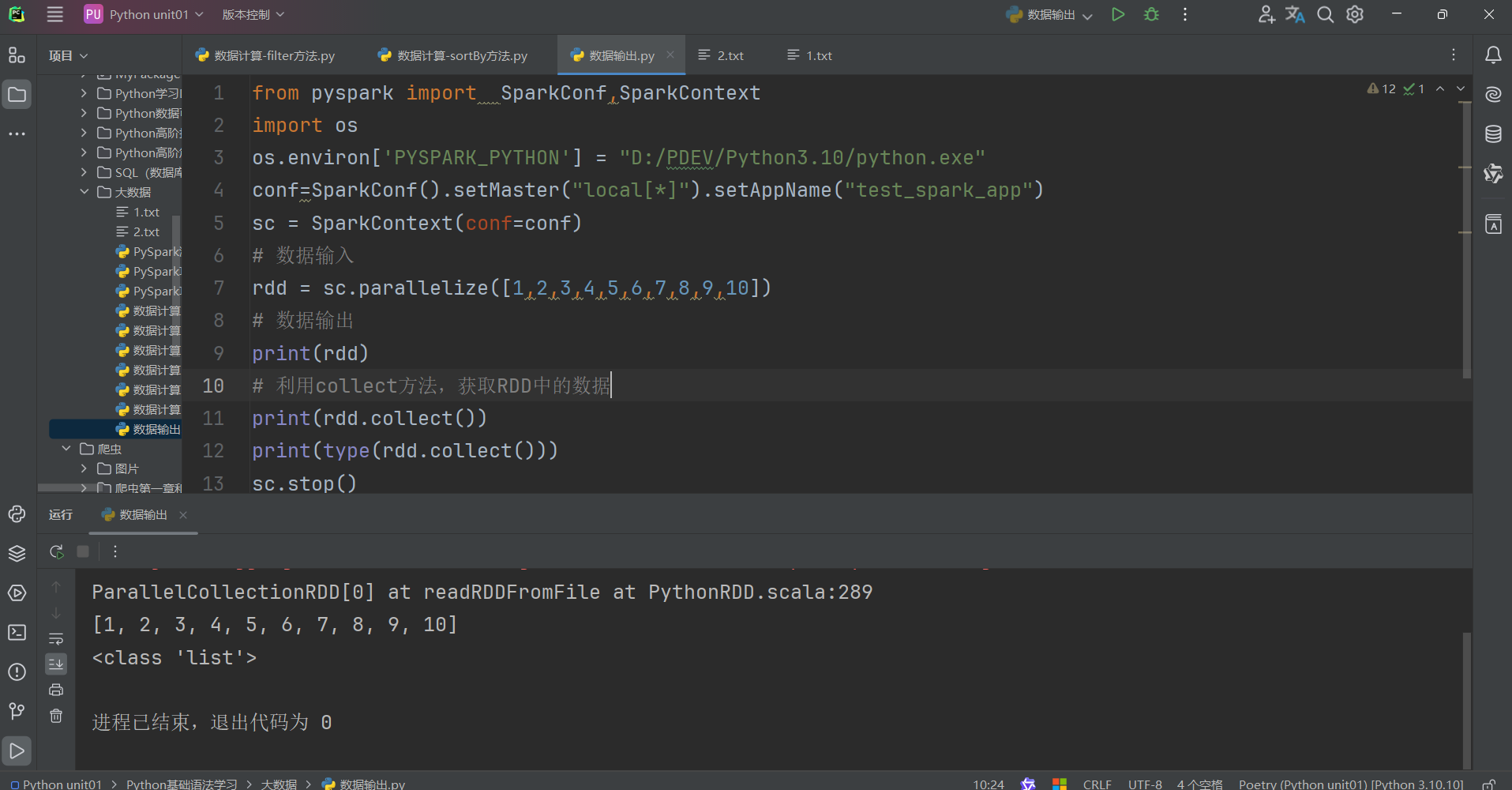
數據輸出
數據輸入:
- sc.parallelize
- sc.textFile
數據計算:
- rdd.map
- rdd.flatMap
- rdd.reduceByKey
- ………
(1)collect算子
collect算子的功能:將RDD各個分區內的數據,統一收集到Driver中,形成一個List對象。
用法:
![]()
返回值是一個List
(2)reduce算子
reduce算子功能: 對RDD數據集按照你傳入的邏輯進行聚合
語法:

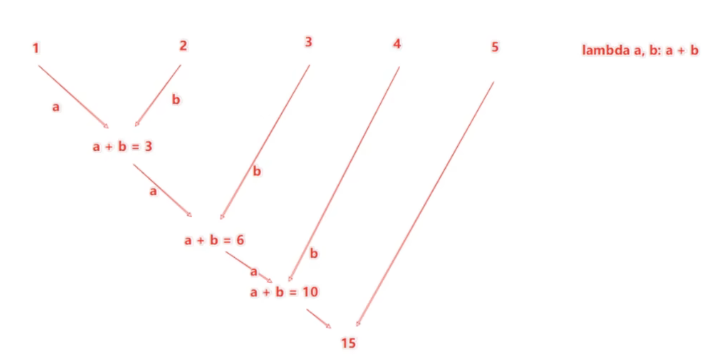

返回值等同于計算函數的返回值
代碼演示如下:
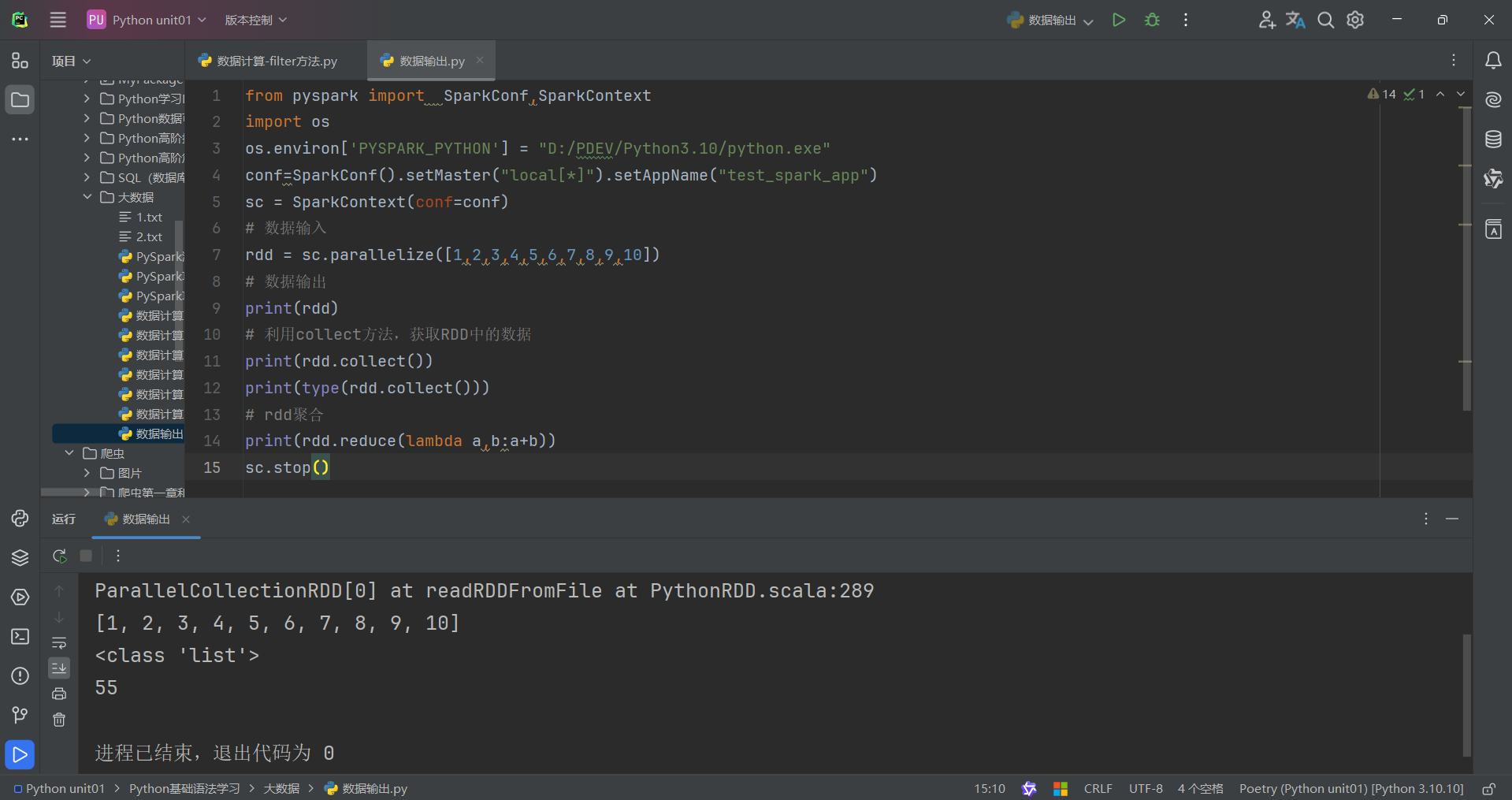
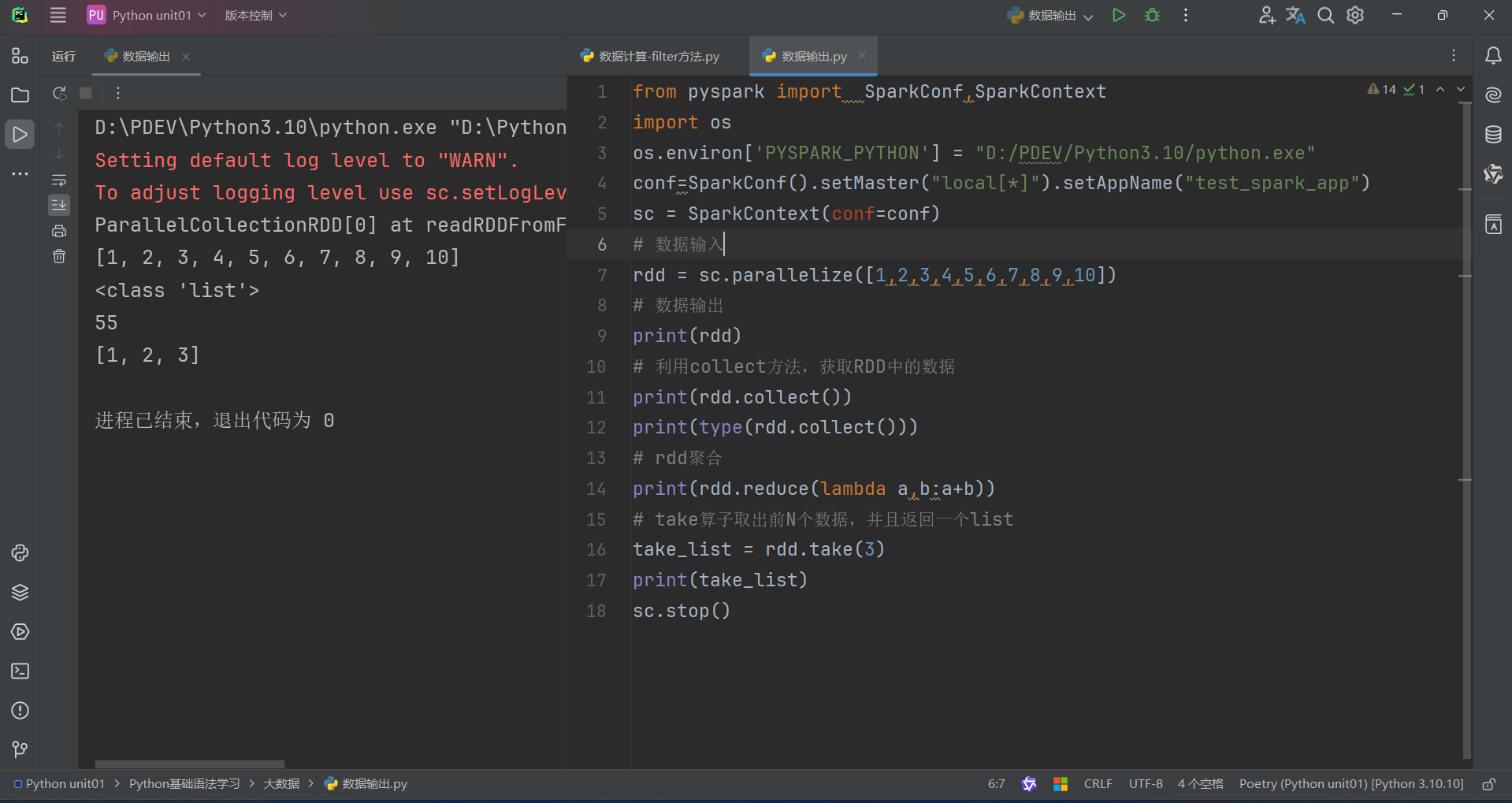
(3)take算子
take算子的功能:取RDD的前N個元素,組成list返回給你
用法:

代碼如下:
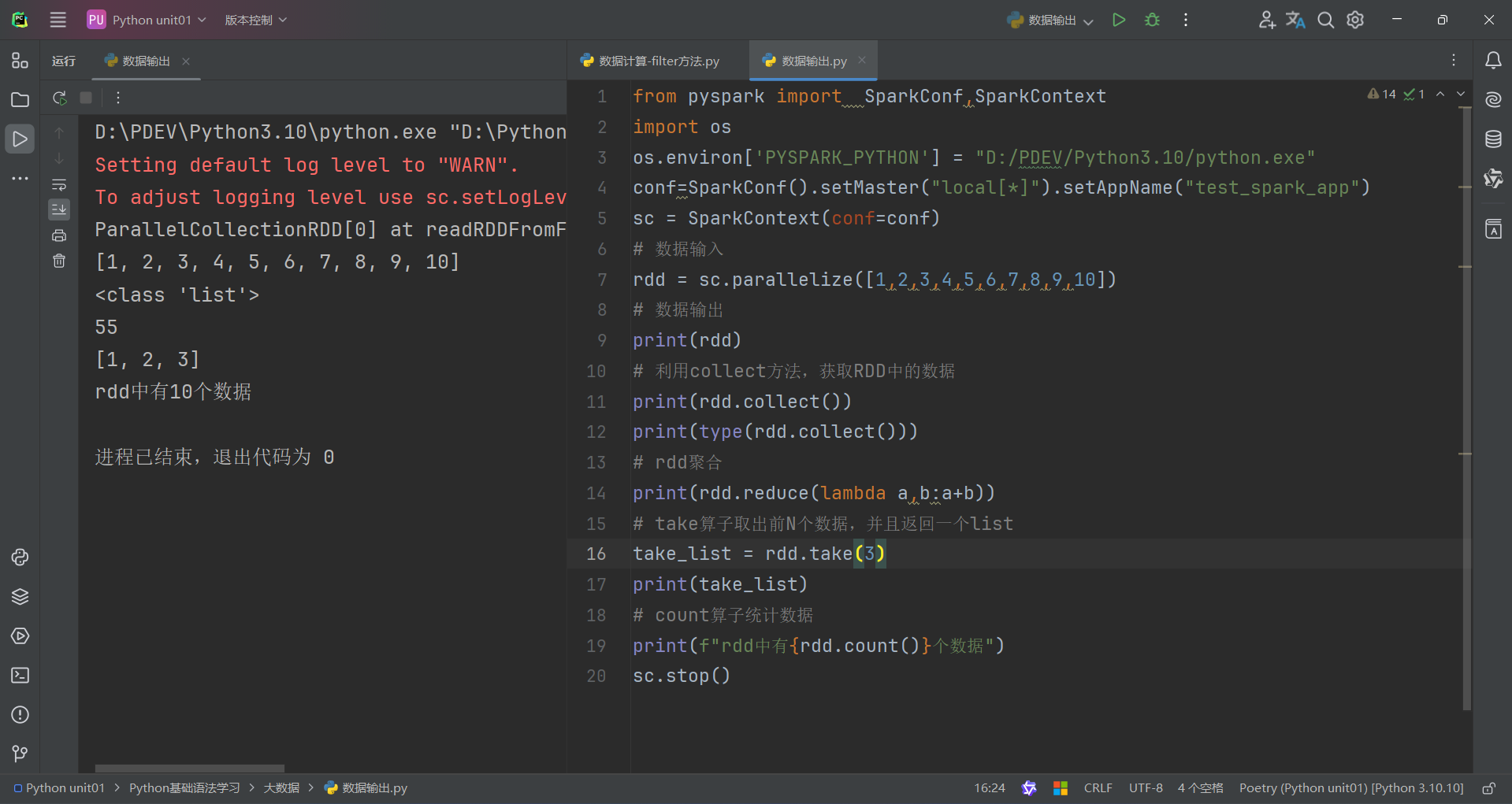
(4)count算子
count算子的功能:計算RDD有多少條數據,返回值是一個數字
用法:

代碼演示如下:
總結:
1.Spark的編程流程就是:
- 將數據加載為RDD(數據輸入)
- 對RDD進行計算(數據計算)
- 將RDD轉換為Python對象(數據輸出)
2.數據輸出的方法
- collect:將RDD內容轉換為list
- reduce:對RDD內容進行自定義聚合
- take:取出RDD的前N個元素組成list
- count:統計RDD元素個數
數據輸出可用的方法是很多的,本小節簡單的介紹了4個
2.輸出到文件中
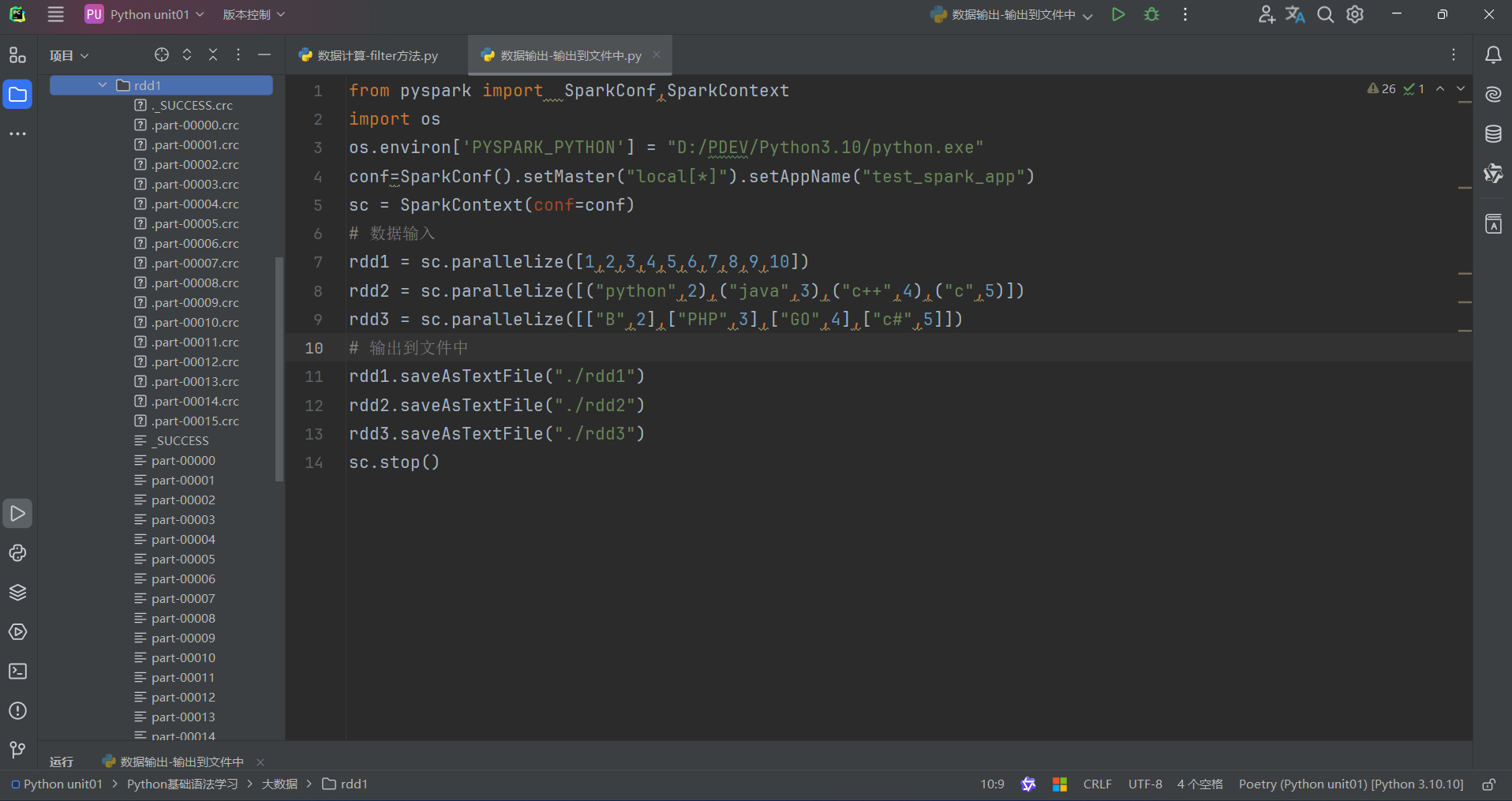
(1)saveAsTextFile算子
saveAsTextFile算子的功能: 將RDD的數據寫入文本文件中
支持 本地寫出,hdfs等文件系統
代碼:

注:
這里需要配置hadoop,作者也是花了大量時間去配置這個東西,它操作太繁瑣,首先你需要有JAVA的JDK并且最好是JDK8,最新版本可能導致不兼容,然后由于我使用的Windows系統還需要去改動一些項目文件中的代碼,這里作者只能說都是淚。由于作者是計科專業不是大數據專業,校內也未給我們開設過Python的課程,這些配置純由作者一點一滴配置完成,吃過苦頭,受過折磨得出的經驗。
注意事項
調用保存文件的算子,需要配置Hadoop依賴
下載Hadoop安裝包
- http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
解壓到電腦任意位置
在Python代碼中使用os模塊配置:os.environ['HADOOP_HOME”]='HADOOP解壓文件夾路徑
下載winutils.exe,并放入Hadoop解壓文件夾的bin目錄內
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
下載hadoop.dll,并放入:C:/Windows/System32 文件夾內
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll
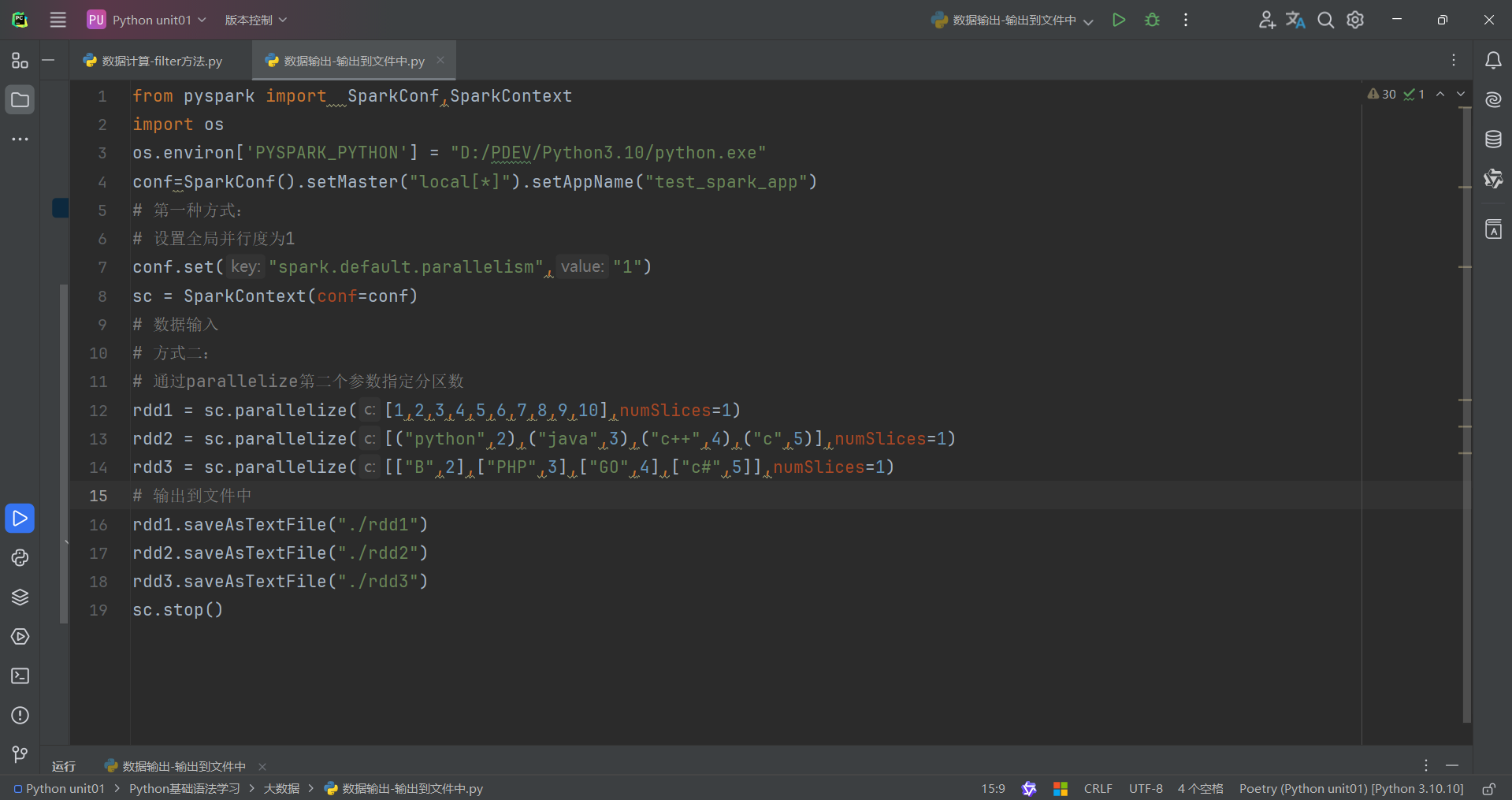
回歸正題,由于作者電腦是CPU是15核,所以生成15個分區,這15個分區存儲的數據有一些有,有一些沒有。因此我們想要修改RDD分區為1有如下方式:

代碼演示如下:
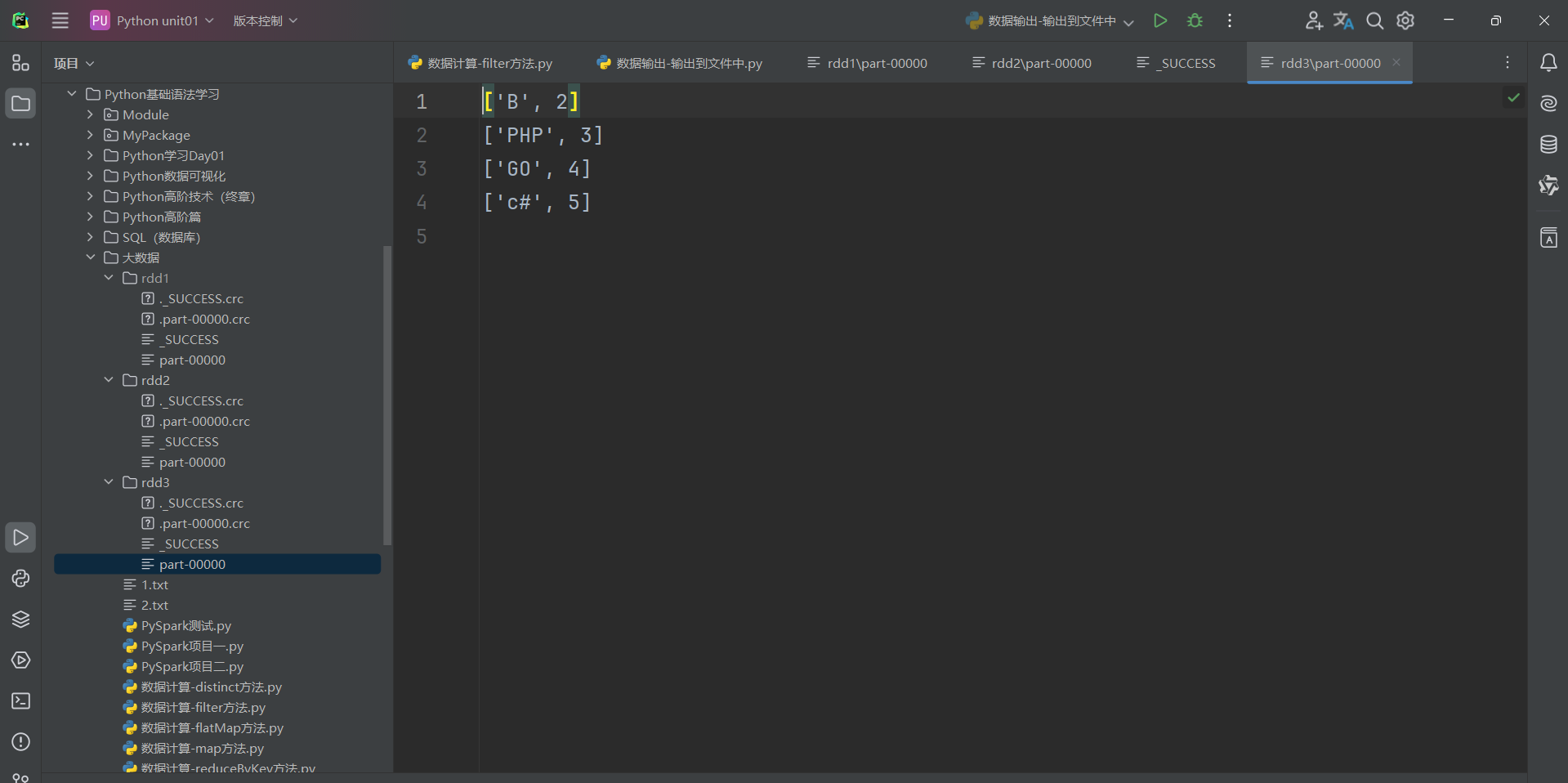
總結:
1.RDD輸出到文件的方法
- rdd.saveAsTextFile(路徑)
- 輸出的結果是一個文件夾
- 有幾個分區就輸出多少個結果文件
2.如何修改RDD分區
SparkConf對象設置conf.set("spark.default.parallelism","1")
創建RDD的時候,sc.parallelize方法傳入numSlices參數為1
六.分布式集群運行(作者談感受)
分布式集群需要Linux系統,作者還沒學,不過作者已經配置好了分布式集群,后續若用到我會在此補充。未來作者還是會去學習Linux系統。希望我未來在企業能用到這個吧。盡力了這一節作者沒法演示了,作者才大一新生,還是一個雙非排名靠后的本科,通過自身學習一步一步學,無導師指導甚至前輩指導都沒有,作者都是一個人鉆研,一鉆研可能就是幾天甚至半個月,這個環境配置作者一直沒有放棄一直在整配置,用過AI去尋求幫助,但是AI都不太行,我認為AI對比于人來說,可能人優勢還是非常大,人的優勢就是能過靈活隨機應變并且擁有真正解決問題的能力,AI是一貫的套路,甚至它們給的方法不一定對于實際問題有合理解決的方法,所以我認為AI很代替真正能夠善于解決問題的人,它們現在只是一個輔助工具,未來AI是什么樣的我不清楚,但是我知道的是人的潛力是AI永遠代替不了的,我通過不斷鉆研學習,盡管今天的技術也許我這輩子用不到,但是我對于計算機的熱愛,還是比較濃厚的我愿意花很大的時間在這個上面,我學了很多的東西盡管很雜亂,也許因為雜亂我可能很快忘了它們但是我知道這個印象永遠在我腦海,因為我花了很多的時間在某一關卡,一卡可能是一天甚至一周乃至一個月,但是我沒放棄過去思考這些問題,我認為只要是問題總會有突破口,計算機需要你花很多的時間,我聽過很多說計算機如今行業不行了,但是我不在意因為熱愛一件事情不一定要去思考它未來怎么樣,只要一直走下去遲早這個技術會在你手里發光發熱,而不是因為自己懶惰和自己不想去找到屬于自己的興趣愛好以及道路而放棄,可以不熱愛學習,但是一定要熱愛自己有興趣的事情。
注:
這一節作者沒法演示,只能講我這學過來的感受從C語言的一點不會到Python、JAVA、C++這些語言我都學過了。未來我更新的東西會很多也很雜亂,不知道未來在企業能否用到,甚至高薪,但是走一步看一步吧。未來我還會繼續更新我的學習,大學四年是一個學習積累非常好的一個機會。
))

















)
