Spark-Streaming概述
Spark Streaming 用于流式數據的處理。

和?Spark 基于 RDD 的概念很相似,Spark Streaming 使用離散化流(discretized stream)作為抽象表示,叫作?DStream。
DStream 是隨時間推移而收到的數據的序列。
Spark-Streaming的特點:易用、容錯、易整合到spark體系。
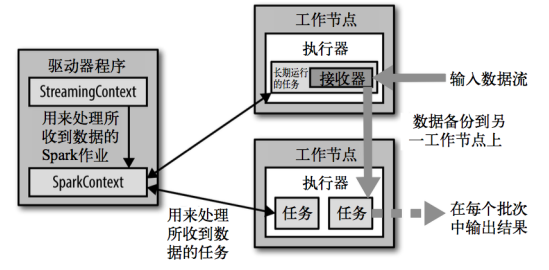
Spark-Streaming架構
DStream實操
案例:詞頻統計
idea中運行
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}object wordcount {def main(args: Array[String]): Unit = {// 創建 SparkConf 對象,設置運行模式為本地多線程,應用名為 streamingval sparkConf = new SparkConf().setMaster("local[*]").setAppName("streaming")// 創建 StreamingContext 對象,設置批處理間隔為 3 秒val ssc = new StreamingContext(sparkConf, Seconds(3))// 從指定的主機和端口接收文本流數據val lineStreams = ssc.socketTextStream("node01", 9999)// 將每行文本拆分為單詞val wordStreams = lineStreams.flatMap(_.split(" "))// 為每個單詞映射為 (單詞, 1) 的鍵值對val wordAndOneStreams = wordStreams.map((_, 1))// 按單詞進行分組并對每個單詞的計數進行累加val wordAndCountStreams = wordAndOneStreams.reduceByKey(_ + _)// 打印每個批次中每個單詞的計數結果wordAndCountStreams.print()// 啟動流式計算ssc.start()// 等待計算終止ssc.awaitTermination()}
}
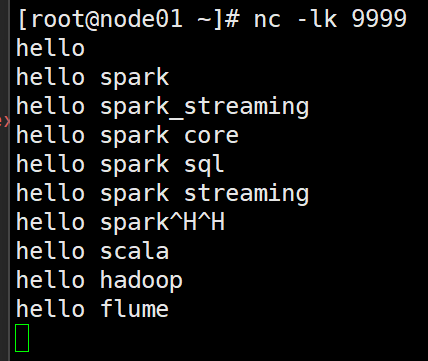
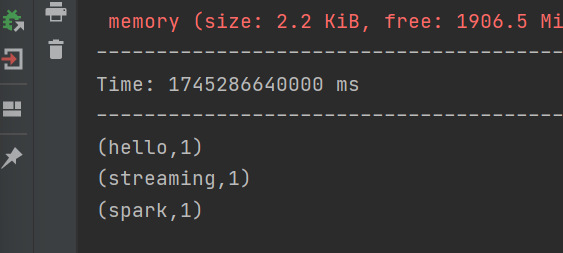
在虛擬機中輸入: nc -lk 9999? ?并輸入數據
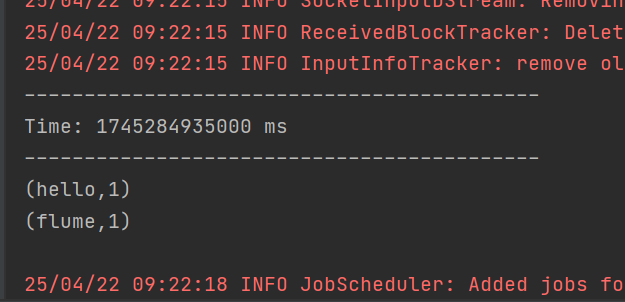
結果:
解析:

對數據的操作也是按照 RDD 為單位來進行的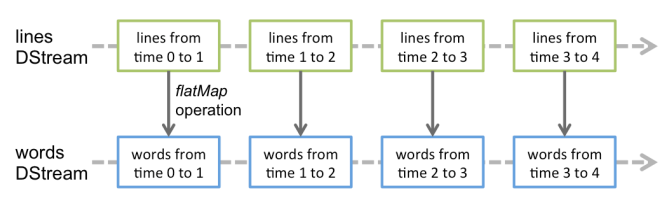
計算過程由 Spark Engine 來完成
DStream 創建
RDD隊列
案例:
循環創建幾個 RDD,將 RDD 放入隊列。通過 SparkStream 創建 Dstream,計算 WordCount
代碼
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.rdd.RDD
import scala.collection.mutableobject RDD {def main(args: Array[String]): Unit = {// 創建 SparkConf 對象,設置運行模式為本地多線程,應用名為 RDDStreamval sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")// 創建 StreamingContext 對象,設置批處理間隔為 4 秒val ssc = new StreamingContext(sparkConf, Seconds(4))// 創建一個可變隊列,用于存儲 RDDval rddQueue = new mutable.Queue[RDD[Int]]()// 從隊列中創建輸入流,oneAtATime 為 false 表示可以同時處理多個 RDDval inputStream = ssc.queueStream(rddQueue, oneAtATime = false)// 將輸入流中的每個元素映射為 (元素, 1) 的鍵值對val mappedStream = inputStream.map((_, 1))// 按鍵對鍵值對進行聚合,統計每個鍵的出現次數val reducedStream = mappedStream.reduceByKey(_ + _)// 打印每個批次中每個鍵的計數結果reducedStream.print()// 啟動流式計算ssc.start()// 循環 5 次,每次向隊列中添加一個 RDD,并休眠 2 秒for (i <- 1 to 5) {rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)Thread.sleep(2000)}// 等待計算終止ssc.awaitTermination()}
}
運行結果:
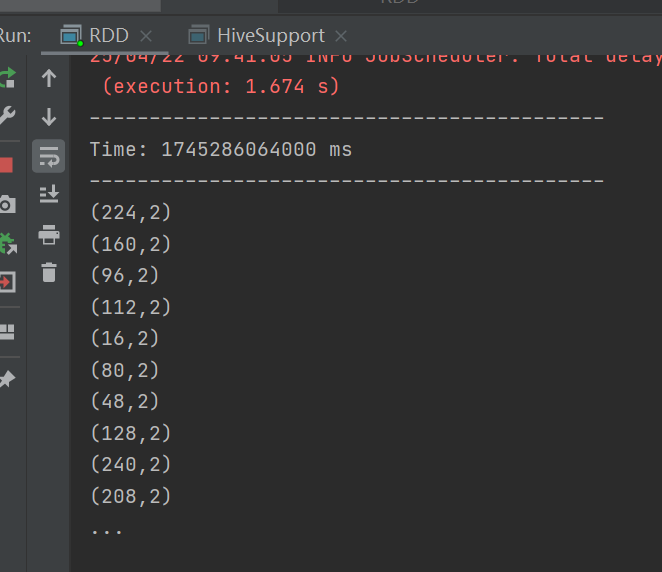
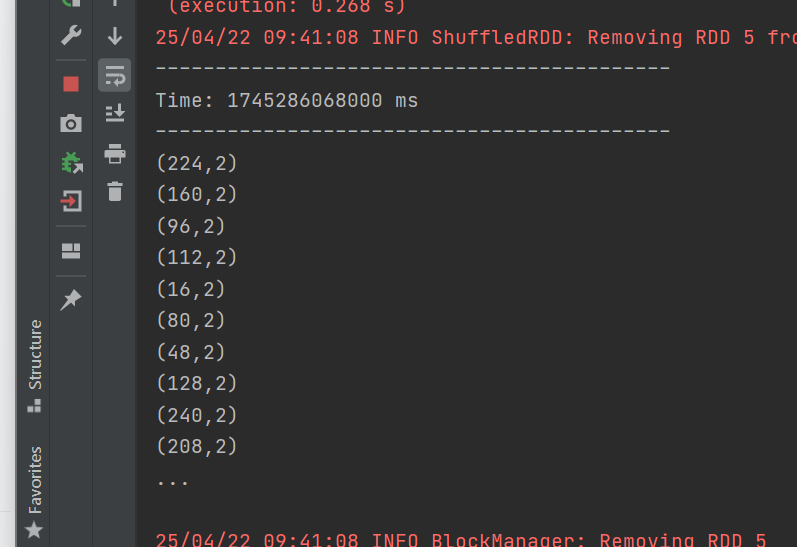
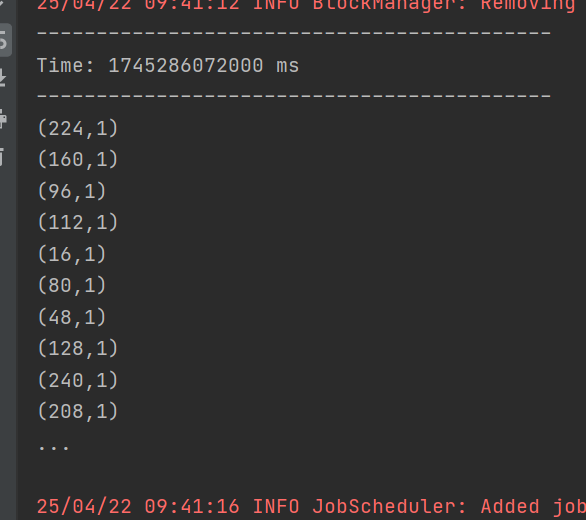
自定義數據源
自定義數據源
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsetsimport org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiverimport scala.util.control.NonFatalclass CustomerReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {override def onStart(): Unit = {new Thread("Socket Receiver") {override def run(): Unit = {receive()}}.start()}def receive(): Unit = {var socket: Socket = nullvar reader: BufferedReader = nulltry {socket = new Socket(host, port)reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))var input: String = reader.readLine()while (!isStopped() && input != null) {store(input)input = reader.readLine()}} catch {case NonFatal(e) =>restart("Error receiving data", e)} finally {if (reader != null) {try {reader.close()} catch {case NonFatal(e) =>println(s"Error closing reader: ${e.getMessage}")}}if (socket != null) {try {socket.close()} catch {case NonFatal(e) =>println(s"Error closing socket: ${e.getMessage}")}}}restart("Restarting receiver")}override def onStop(): Unit = {}
}
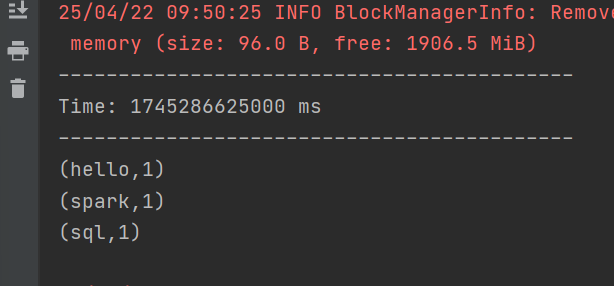
使用自定義的數據源采集數據
object sparkConf {def main(args: Array[String]): Unit = {try {// 創建 SparkConf 對象,設置運行模式為本地多線程,應用名為 streamval sparkConf = new SparkConf().setMaster("local[*]").setAppName("stream")// 創建 StreamingContext 對象,設置批處理間隔為 5 秒val ssc = new StreamingContext(sparkConf, Seconds(5))// 使用自定義 Receiver 創建輸入流val lineStream = ssc.receiverStream(new CustomerReceiver("node01", 9999))// 將每行文本拆分為單詞val wordStream = lineStream.flatMap(_.split(" "))// 為每個單詞映射為 (單詞, 1) 的鍵值對val wordAndOneStream = wordStream.map((_, 1))// 按單詞進行分組并對每個單詞的計數進行累加val wordAndCountStream = wordAndOneStream.reduceByKey(_ + _)// 打印每個批次中每個單詞的計數結果wordAndCountStream.print()// 啟動流式計算ssc.start()// 等待計算終止ssc.awaitTermination()
}}}




(ArkTs))













上使用WSL2+Ubuntu22.04+Conda+Tensorflow+GPU進行機器學習訓練)
(C++))
