第3章 垃圾收集器與內存分配策略
3.2 對象已死
Java世界中的所有對象實例,垃圾收集器進行回收前就是確定對象哪些是活著的,哪些已經死去。
3.2.1 引用計數算法
常見的回答是:給對象中添加一個引用計數器,有地方引用,計數器+1,引用失效,計數器-1,任何時刻計數器為零的對象就是不可能再被使用了。
引用計數算法(Reference Counting)占了一些額外內存空間來計數,但原理簡單,判定效率高,大多數下也是一個好的算法。
Java領域主流虛擬機都沒用引用計數算法,原因為看似簡單,很多例外情況要考慮,要配合大量額外處理才能保證正確地的工作,例如很難解決對象之間相互循環引用的問題。
引用計數算法陷阱
package a.b.c;/*** */
public class ReferenceCountingGC {public Object instance = null;private static final int _1MB = 1024 * 1024;/*** 意義就是占點內存,以便能在GC日志中清楚是否有回收過*/private byte[] bigSize = new byte[2 * _1MB];public static void testGC() {ReferenceCountingGC objA = new ReferenceCountingGC();ReferenceCountingGC objB = new ReferenceCountingGC();objA.instance = objB;objB.instance = objA;objA = null;objB = null;System.out.println("---------進行GC!---------");//假設在這行發生GC,objA和objB是否能被回收?System.gc();}public static void main(String[] args) {testGC();}}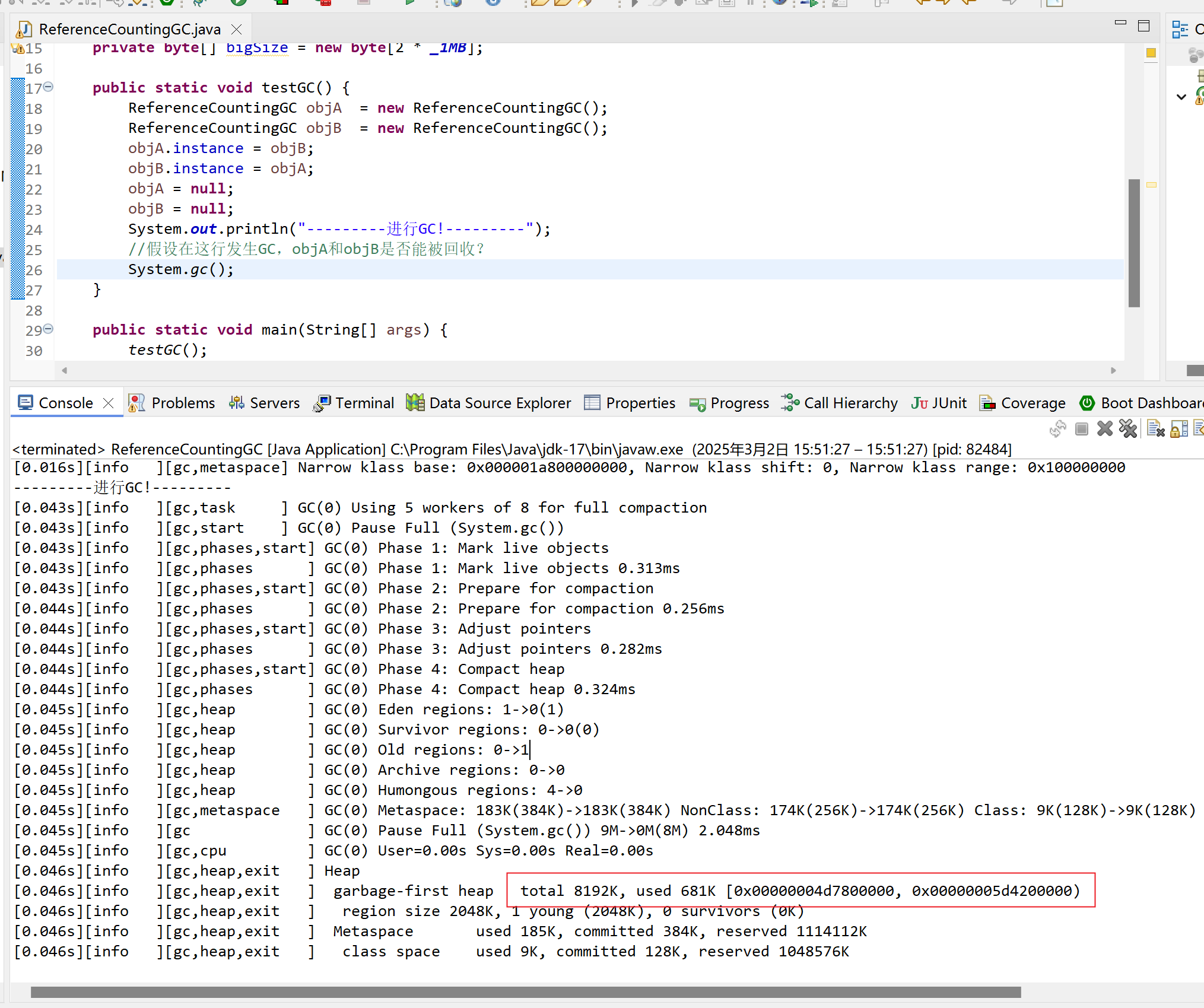
證明虛擬機沒有因為兩個對象互相引用就放棄回收它們。
所以Java虛擬機不是通過引用計數算法判斷對象是否存活的。
3.2.2 可達性分析算法
Java通過可達性分析(Reachability Analysis)算法來判定對象是否存活。
基本思路:通過一些列"GC Roots"的根對象作為起始節點集,根據引用關系向下搜索,搜索過程所走過的路徑稱為"引用鏈(Reference Chain)",如果某對象到GC Roots間沒有任何引用鏈相連,說明這個對象不可達,證明此對象不可能再被使用。
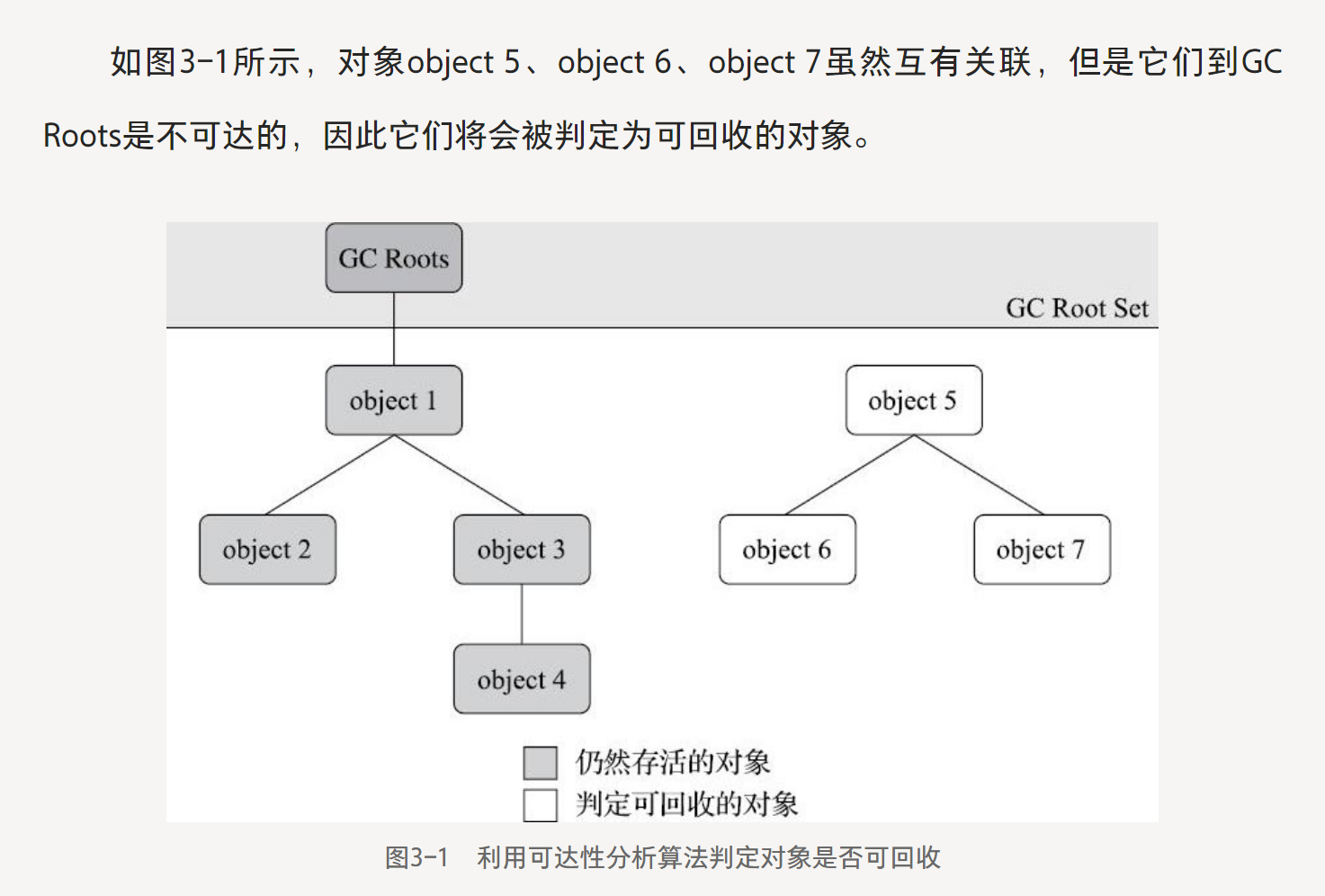
Java技術體系里,固定可作為GC Roots的對象包括以下幾種:
- 虛擬機棧(棧幀中的本地變量表)中引用的對象,各個線程被調用的方法堆棧中使用到的參數、局部變量、臨時變量等。
- 方法區中,類靜態屬性引用的對象。
- 方法區中,常量引用的對象,字符串常量池(String Table)里的引用。
- 本地方法棧中JNI(Native方法)引用的對象。
- Java虛擬機內部的引用,如基本數據類型對應的Class對象,常駐的異常對象NullPointException,OutOfMemoryError等,系統類加載器。
- 被同步鎖(synchronized關鍵字)持有的對象。
- 反映Java虛擬機內部情況的JMXBean,JVMTI中注冊的回調、本地代碼緩存等。
3.2.3 再談引用
Java引用的傳統定義:如果reference類型的數據中存儲的數值代表的是另一塊內存的起始地址,就稱該reference數據是代表某塊內存,某個對象的引用。
更廣義的講,Java對引用的概念進行了擴充,將引用分為**強引用(Strongly Reference)、軟引用(Soft Reference)、弱引用(Weak Reference)和虛引用(Phantom Reference)**4種,引用強度依次減弱。
- 強引用是最傳統的引用,指在程序代碼中普遍存在的引用賦值,類似"Object obj = new Object()",這種引用關系,無論任何情況下,只要強引用關系還存在,垃圾收集器就永遠不會回收掉被引用的對象。
- 軟引用用來描述一些還有用,但非必須得對象,只被軟引用關聯著的對象在系統發生內存溢出異常前,會把這些對象列進回收范圍之中進行第二次回收,如果這次回收,如果這次回收還沒有足夠內存,會拋出內存溢出異常,JDK1.2之后提供SoftReference類來實現軟引用。
- 弱引用也是用來描述非必須對象,強度比軟引用更弱,被弱引用關聯的對象只能生存到下一次垃圾收集發生為止,當垃圾收集器開始工作,無論當前內存是否足夠,都會回收弱引用關聯的對象,提供WeakReference類來實現。
- 虛引用也稱為幽靈引用或幻影引用,最弱的引用關系,一個對象是否有虛引用存在不會對其生成時間構成影響,也無法通過虛引用獲取對象實例,唯一目的是為了能在這個對象被收集器回收時收到一個系統通知,PhantomReference類實現。
3.2.4 生存還是死亡?
可達性分析算法判定為不可達對象也不似非死不可,這時候處于緩刑,宣告對象死亡要經歷兩次標記過程:對象可達性分析后沒有與GC Roots相連接的引用鏈,第一次標記,對象沒有覆蓋finalize()方法或此方法已經被虛擬機調用過,虛擬機將這兩種情況視為"沒有必要執行"。
對象被判定為執行finalize()方法,會被放到F-Queue隊列中,由虛擬機自動建立,低調度優先級的Finalizer線程去執行它們的finalize()方法。
最后一次逃脫機會是在F-Queue隊列的對象被收集器第二次小規模標記,若對象重新與引用鏈連接上,第二次標記會溢出即將回收的集合,若沒有逃脫,那么就要回收了。
一次對象的自我拯救演示
package a.b.c;public class FinalizeEscapeGC {public static FinalizeEscapeGC SAVE_HOOK = null;public void isAlive() {System.out.println("yes,i am still alive 0.0");}@Overrideprotected void finalize() throws Throwable {super.finalize();System.out.println("finalize method executed!");FinalizeEscapeGC.SAVE_HOOK = this;}public static void main(String[] args) throws InterruptedException {SAVE_HOOK = new FinalizeEscapeGC();//對象第一次成功拯救自己SAVE_HOOK = null;System.gc();//因為Finalizer方法優先級很低,暫停0.5秒,等待它Thread.sleep(500);if(SAVE_HOOK!=null) {SAVE_HOOK.isAlive();} else {System.out.println("no,i am dead *.*");}//下面這段代碼與上面完全相同,但這次自救卻失敗了SAVE_HOOK = null;System.gc();//因為Finalizer方法優先級很低,暫停0.5秒,等待它Thread.sleep(500);if(SAVE_HOOK!=null) {SAVE_HOOK.isAlive();} else {System.out.println("no,i am dead *.*");}}}
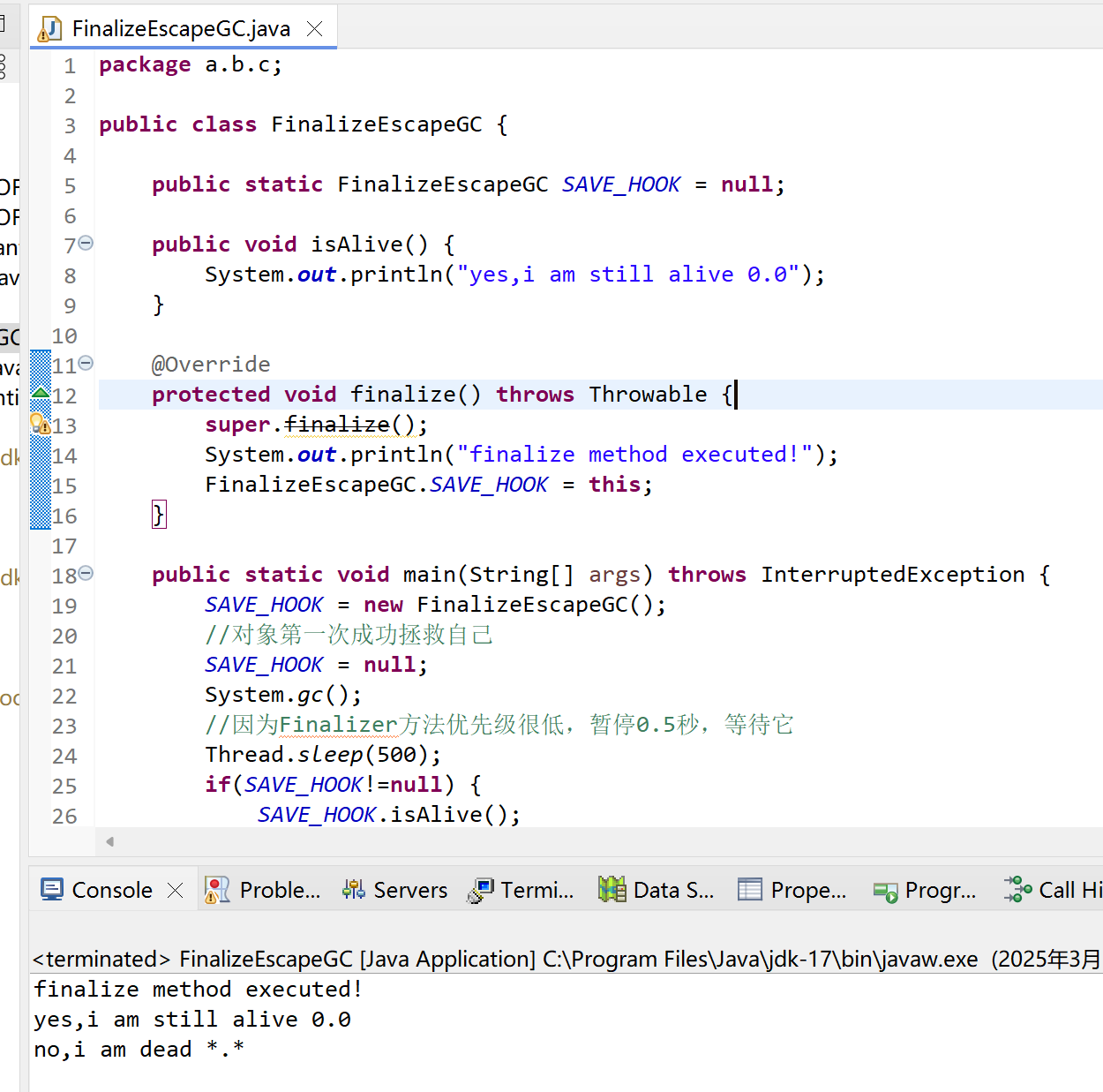
兩段完全一樣的代碼執行結果一次逃脫成功,一次失敗,因為finalize()方法只會被系統自動調用一次,第二次不執行了,第二段代碼自救失敗了。
finalize()方法不推薦使用,把它忘了吧。
3.2.5 回收方法區
方法區垃圾收集性價比低,主要回收:廢棄的常量和不再使用的類型,如沒有任何一個字符串對象引用常量池中的"java"常量,虛擬機中其他地方也沒引用,則它會被系統清理出常量池。
不是使用的類,判定起來比較苛刻:
- 該類以及子類所有實例已經被回收。
- 加載該類的類加載器已經被回收。
- 該類對應的java.lang.Class對象沒有在任何地方被引用,無法在任何地方通過反射訪問該類的方法。
也僅僅是被允許,提供了一系列參數控制類的卸載,自己查吧。
大量使用反射,動態代理,CGLib等字節碼框架,動態生成JSP以及OSGi這類頻繁自定義類加載器的場景,通常都需要具備Java虛擬機類型卸載的能力,保證不會對方法區造成過大的內存壓力。
3.3 垃圾回收算法
理論細節參考《垃圾回收算法手冊》2~4章內容。
垃圾回收算法可劃分為:**引用計數式垃圾收集(Reference Counting GC)和追蹤式垃圾收集(Tracing GC)**兩大類。
主流Java虛擬機都采用的是追蹤式垃圾收集。
3.3.1 分代收集理論
當前商業虛擬機的垃圾收集器,大多數遵循"分代收集"(Generational Collection)的理論進行設計。是程序的經驗法則,建立在兩個分代假說之上:
1.弱分代假說(Weak Generational Hypothesis):絕大多數對象都是朝生夕死。
2.強分代假說(Strong Generational Hypothesis):熬過越多次垃圾收集過程的對象就越難消亡。
這兩個假說奠定了垃圾收集器的一致設計原則:
收集器將Java堆劃分出不同的區域,將回收對象依據年齡(熬過垃圾收集的次數)分配到不同的區域之中存儲。大多數朝生夕死的對象放在一起,每次回收只關注少量存活的對象,而不去標記大量要被回收的對象,以低頻率來回收這個區域,同時兼顧了垃圾收集的時間開銷和內存空間的有效利用。
Java堆劃分區域后,每次只回收某一個或某部分區域,也就有了**“Minor GC,新生代垃圾回收”,“Major GC,老年代垃圾回收”,“Full GC”**這些回收類型的劃分,也就有了針對不同區域與存儲對象存亡特征相匹配的垃圾收集算法,“標記-清除算法”,“標記-整理算法”,“標記清除算法”。Minor:/?ma?n?r/未成年,少數的,次要的,Major:/?me?d??r/主要的,大的。
一般至少會把堆分為"新生代(Young Generation)"和**老年代(Old Generation)**兩個區域。
新生代中,每次垃圾收集都發現大批對象死去,每次回收后存活的少量對象都會逐步晉升到老年代中存放。分代收集并非簡單劃分內存區域那么簡單,至少有1條,對象不是孤立的,對象之間會存在跨代引用。
假設進行新生代區域的收集(Minor GC),新生代對象可能被老年代所引用,為找出新生代中的存活對象,不得不在固定的GC Roots之外,再額外遍歷整個老年代中所有對象來確保可達性分析結果的正確性,反過來也一樣。遍歷老年代所有對象可行,但為內存回收帶來很大的性能負擔,為解決這個問題,添加第三條經驗法則:
3.跨代引用假說(Intergenerational Reference Hypothesis):跨代引用相對于同代引用來說僅占極少數。
隱含推論:存在互相引用關系的兩個對象,應該傾向于同時生存或者同時消亡的。
如某新生代對象引用老年代對象,老年代對象難以消亡,新生代對象得以存活,進而年齡增長后晉升到老年代中,這時跨代引用也隨之消除了。
根據第3假說,不應該為少量跨代引用去掃描整個老年代,也不必浪費空間記錄每個對象是否存在跨代引用,只需再新生代上建立全局的數據結構(記憶集,Remembered Set),此結構把老年代劃分若干小塊,標識老年代哪塊內存存在跨代引用,發生MinorGC時,跨代引用小塊的對象才會被加入到GC Roots進行掃描。改變引用關系維護記錄數據的正確性會增加一點開銷,但是比起掃描整個老年代來說還是劃算的。
收集分類
- 部分收集(Partial GC):指目標不是完整收集整個Java堆,而是收集部分,又分為:
- 新生代收集(Minor GC/Young GC):只收集新生代的垃圾收集。
- 老年代收集(Major GC/Old GC):只是老年代的垃圾收集。目前只有CMS會單獨收集老年代的行為,另外注意,Major GC說法有混淆,根據上下文看到底是指老年代收集還是整堆收集。
- 混合收集(Mixed GC):
- 整堆收集(Full GC):收集整個Java堆的方法區的垃圾收集。
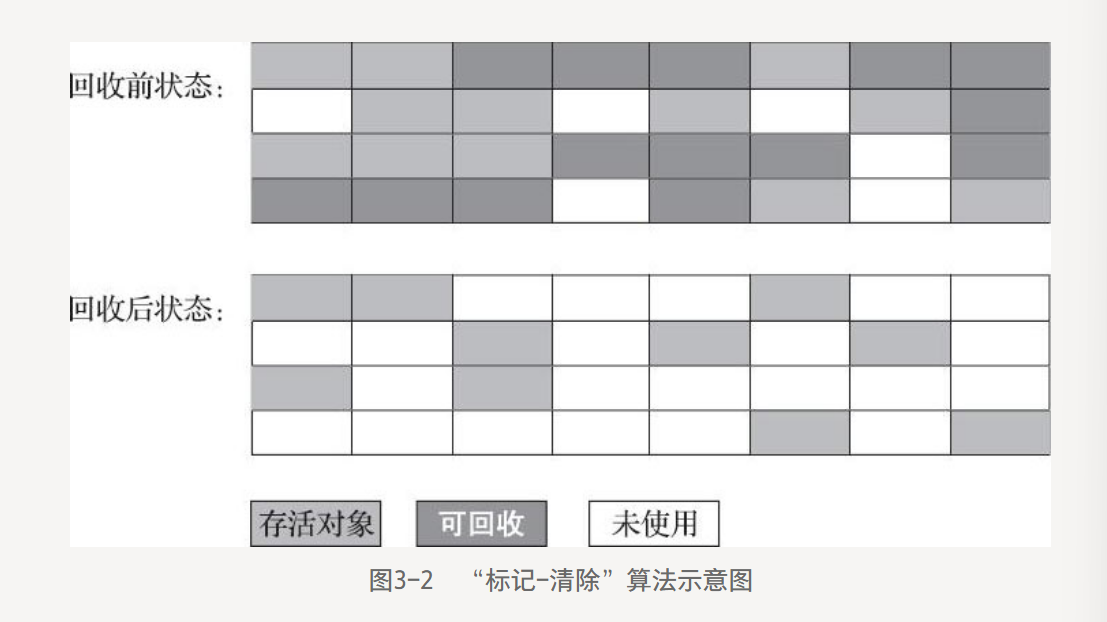
3.3.2 標記-清除算法
最基礎的垃圾收集算法,**標記-清除(Mark-Sweep)**算法。
算法分為兩階段:
- 標記階段:標記所有需要回收的對象。
- 清除階段:標記完成后回收掉所有被標記的對象。
缺點有兩個:
- 執行效率不穩定,堆中包含大量對象,大部分需要被回收,要進行大量標記和清除動作,兩個動作的執行效率隨對象數量增長而降低。
- 內存碎片化問題,清除后產生大量不連續的內存碎片,碎片太多當程序需要分配大對象時無法找到連續的內存而不得不提前觸發一次垃圾收集動作。
3.3.3 標記-復制算法
簡稱為復制算法,解決了大量可回收對象執行效率低的問題。
最早提出的了"半區復制(Semispace Copying)",將可用內存按容量劃分為大小相等的兩塊,每次只使用其中的一塊,一塊用完,將存活的對象復制到另外一塊上面,把已使用過的內存空間一次清理掉。
優點:不用考慮內存碎片,分配內存時移動堆頂的指針,按順序分配即可實現簡單,運行高效。
缺點:可用內存縮小為原來的一半,空間浪費太多。
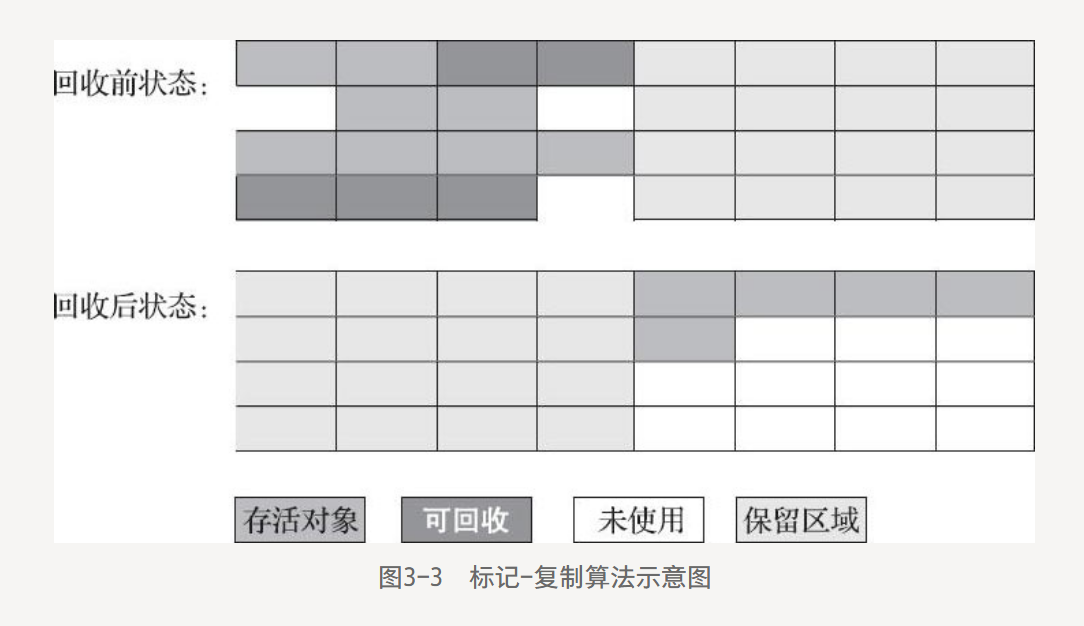
現在的Java虛擬機優化了這種收集算法。
新生代中的對象98%熬不過第一輪收集,因此不需要1:1的比例來劃分新生代的內存空間。
更優化的半區復制分代策略,稱為"Appel式回收"。

HotSpot虛擬機的Serial、ParNew等新生代收集器采用這種策略。
新生代內存區域,每次使用Eden+其中1個Survivor,共計90%內存區域。
- Eden,80%
- Survivor0,10%
- Survivor1,10%
老年代內存區域
若上面Minor GC垃圾回收后,復制到Survivor中的對象超過10%,觸發了分配擔保(Handle Promotion),將這些對象直接進入到老年代,這是安全的。
3.3.4 標記-整理算法
復制算法中,對象存活率高的極端情況,復制操作多,效率低,而且不想浪費50%內存就要進行分配擔保,用來應對100%對象存活的極端情況,所有老年代一般不能直接選用這種算法。
根據老年代對象活的久的特點,提出了"標記-整理算法(Mark-Compact)".
標記過程:還是標記-清除算法。
整理過程:將所有存活的對象向內存空間一端移動,然后直接清理邊界以外的內存。
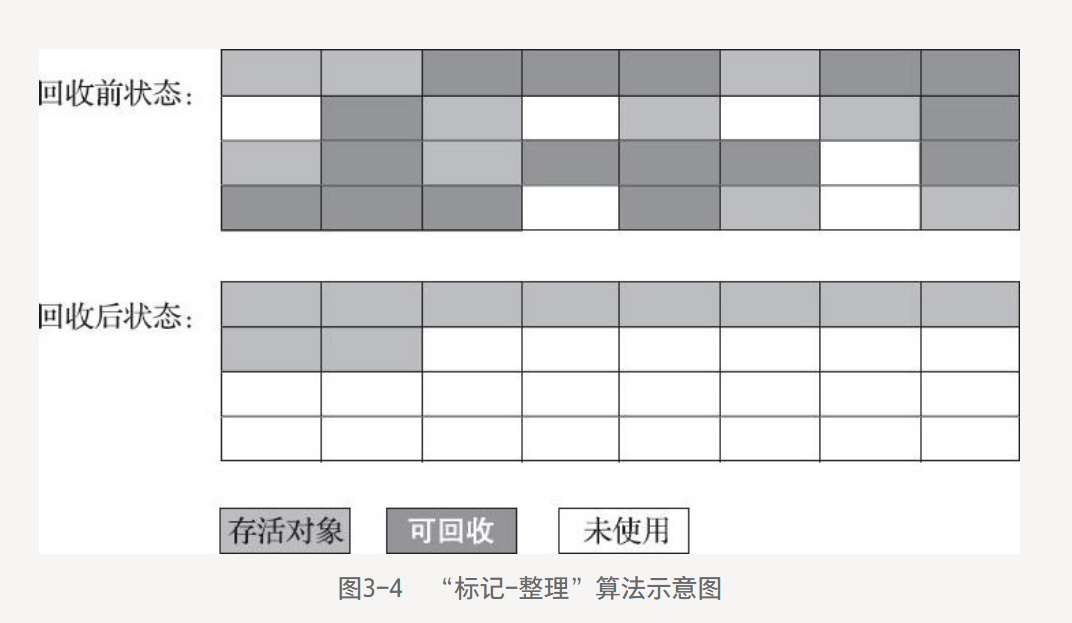
移動存活的對象是極重的負擔, 操作過程要暫停用戶應用程序才能進行。
Stop The World,全局停止,世界停止,這個系統開銷也了不得。
如果不考慮移動和整理的話,空間碎片化問題就要用"分區空閑分配鏈表"來解決,增加額外負擔,影響程序的吞吐量。
基于以上了兩點,是否移動對象都有弊端,移動則內存回收復雜,不移動則內存分配復雜。
有一種折中的方法,虛擬機平時多數時間采用標記-清除算法,暫時容忍碎片,知道內存碎片大到影響對象分配時,再采用標記整理算法收集一次,以獲得規整的內存空間,基于標記-清除算法CMS收集器面臨的空間碎片過多時就采用這種辦法。
3.4 HotSpot的算法細節實現
較枯燥,可先看垃圾收集器。
3.5 經典垃圾收集器
如果說收集算法是內存回收的方法論,那垃圾收集器就是內存回收的實踐者。
規范沒有對垃圾回收器的實現做規定。
各款經典收集器之間的關系圖:
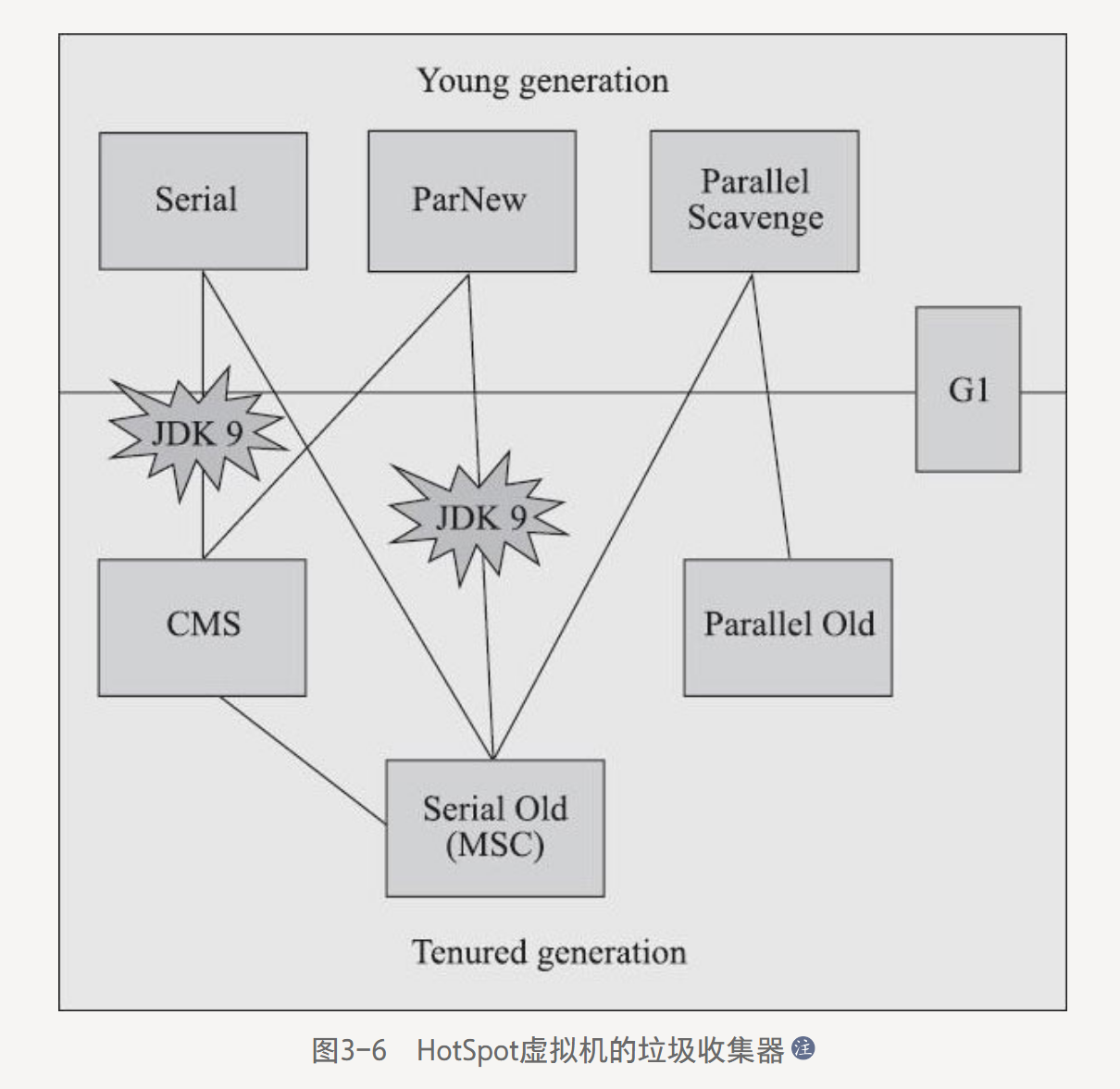
展示了7種作用于不同分代的收集器,兩個收集器之間存在連線,就說明它們可以搭配使用。
收集器所處的區域標識它們屬于新生代收集器或是老年代收集器(Tenured,終身的,長期保有的)。
明確一個觀點:各個收集器的比較不是挑選最好的收集器出來,沒出現最好的收集器,更不存在萬能收集器,只是選擇最合適的收集器。
新生代垃圾回收器:Serial,ParNew,ParallelScavenge
老年代垃圾回收器:CMS,Serial Old(MSC),Parallel Old
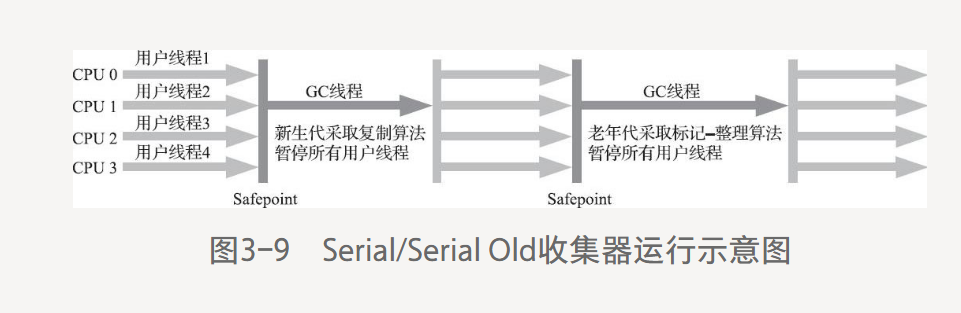
3.5.1 Serial收集器
Serial/?s??ri?l/連續的,排成順序的。
最基礎,歷史最悠久,JDK1.3.1之前是新生代收集器的唯一選擇。
單線程工作的收集器。
不僅僅使用一個處理器或一條收集線程去完成垃圾收集工作,進行垃圾收集時,必須暫停其他所有工作線程,直到它收集結束。
會"Stop The World",在用戶不可知的情況下,把正常工作的線程全部停掉,這無法接受。
下圖Serial/Serial Old收集器的運行過程。
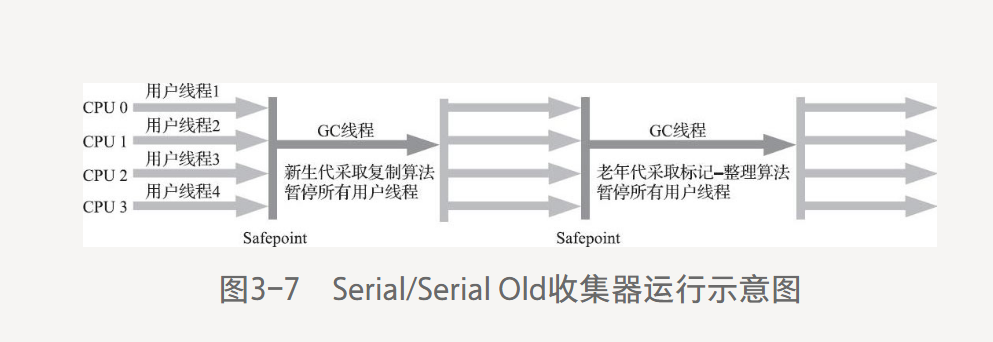
給用戶帶來惡劣體驗,早起設計者們完全理解,但也很委屈,你媽媽給你打掃房間的時候,肯定會讓你老老實實的在椅子上或者房間外待著,如果她一邊打掃,一邊扔紙屑,這房間還能打掃完?,這也合情合理。
看似老而無用,實則依然是HotSpot運行在客戶端模式下默認的新生代收集器。
優點:簡單而高效,內存受限的情況下,內存額外消耗最小,對于單核或處理器核心少的環境來說,沒有線程交互的開銷,尤其微服務應用中,分配內存小,收集幾十到一兩百兆新生代,垃圾回收停頓時間可以控制在十幾、幾十毫秒,最多100毫秒以內,只要不頻繁發生,這些停頓時間可以接受。
缺點:單線程,暫停世界導致全部工作線程頻繁停頓,不適合在大內存虛擬機中使用。
3.5.2 ParNew收集器
ParNew是Serial收集器的多線程并行版本。
除了使用多條線程進行垃圾收集之外,其余包括Serial可用的所有控制參數
-XX:SurvivorRatio,ratio(比例),SurvivorRatio 指的是幸存區比例。在垃圾回收機制中,通常會有新生代和老年代等不同的內存區域劃分,而新生代中又有 Eden 區和兩個 Survivor 區。SurvivorRatio 這個參數用于設置 Eden 區和 Survivor 區的大小比例關系。例如,如果設置為 8,則表示 Eden 區和 Survivor 區的大小比例為 8:1:1。
-XX:PretenureSizeThreshold,中文意思是 “晉升到老年代的大小閾值”。在 Java 虛擬機中,這個參數用于設置對象從新生代晉升到老年代之前的大小閾值。如果對象的大小超過這個閾值,就會直接晉升到老年代,而不是在新生代中經歷多次垃圾回收。這個參數可以幫助優化垃圾回收的性能,根據不同的應用場景進行調整。例如,對于創建大型對象較多的應用,可以適當調大這個閾值,以減少新生代的垃圾回收次數。一般來說,大對象是32K,也有1M,或2M。
-XX:HandlerPromotionFailure,垃圾回收(GC)過程中的對象晉升失敗相關,原因有老年代空間不足,老年代內存碎片放不下晉升的對象,大對象直接分配給老年代導致老年代空間不足。老年代還未充分整理,新生代對象就晉升為老年代,導致空間不足,JVM設置的老年代太小導致無法滿足晉升的需求。
收集算法,暫停世界,對象分配規則等與Serial收集器完全一致,共用很多代碼。
ParNew收集器工作過程:
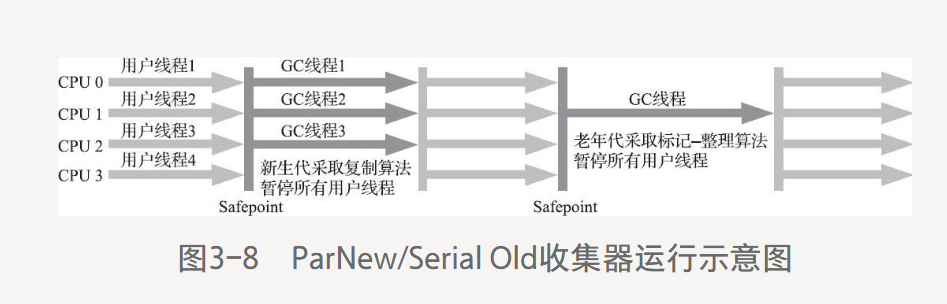
是JDK7之前遺留系統中首選的新生代收集器。
有一個重要原因:除Serial收集器外,只有它能與CMS收集器配合工作。
ParNew是激活CMS后的默認新生代收集器,也只能相互搭配使用,不能和其他收集器配合了。
- 并行(Parallel):并行描述的是多條垃圾收集器線程之間的關系,說明同一時間有多條線程在協同工作,通常默認此時用戶線程是出于等待狀態。
- 并發(Concurrent):并發描述的垃圾收集器線程和用戶線程之間的關系,說明同一時間垃圾收集器線程與用戶線程都在運行。
3.5.3 Parallel Scavenge(清理)收集器
也是新生代收集器,基于標記復制算法,能夠并行收集的多線程收集器。
特點與其他不同,CMS等關注點是縮短用戶線程的停頓時間。
而它則是達到一個可控制的吞吐量(Throughput)。
$ 吞吐量=\frac{運行用戶代碼時間}{運行用戶代碼時間+運行垃圾收集時間} $
如果虛擬機完成某個任務,總共耗費100分鐘,垃圾收集花費1分鐘,吞吐量就是99%。
Parallel Scavenge收集器提供兩個參數用于精確控制吞吐量:
最大垃圾收集停頓時間:-XX:MaxGCPauseMillis:大于0的毫秒數,越小,頻率越高
直接設置吞吐量大小:-XX:GCTimeRatio:0<整數<100,默認99,則允許1%,19則是5%。
也經常被稱為"吞吐量優先收集器"
自適應調節策略(GC Ergonomics)也是Parallel Scavenge收集器區別于ParNew收集器的重要特征,把內存管理的調優任務交給虛擬機完成,把內存數據設置好-Xmx。
3.5.4 Serial Old收集器
是Serial收集器的老年代版本,同樣是一個單線程收集器,使用標記復制算法。
JDK5之前與Parallel Scavenge收集器搭配使用。
作為CMS收集器發生失敗時的后備預案。
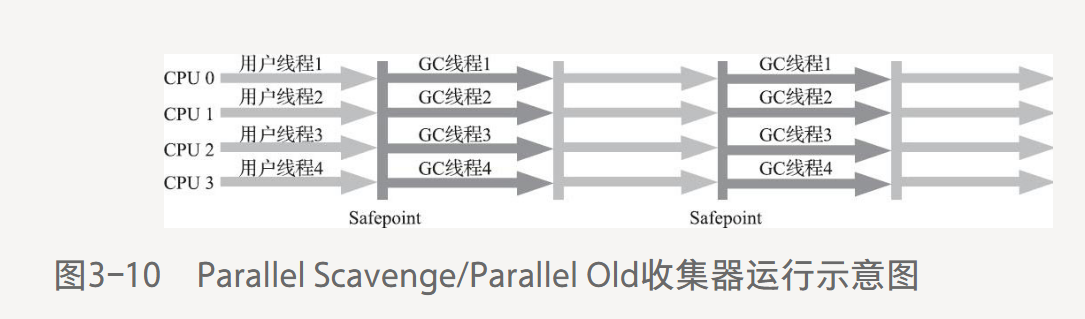
3.5.5 Parallel Old收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,支持多線程并發收集,標記-整理算法。
3.5.6 CMS收集器
CMS(Concurrent Mark Sweep)是以獲取最短回收停頓時間為目標的收集器。
B/S架構更關注服務的響應速度,希望系統停頓時間更短,CMS更符合要求。
基于標記-清除算法實現的:
- 初始標記(CMS initial mark),標記GC Roots關聯到的對象,速度很快,會Stop The World。
- 并發標記(CMS concurrent mark),通過GC Roots的直接關聯對象遍歷整個對象圖的過程,可與用戶線程并發。
- 重新標記(CMS remark),修正并發標記期間用戶繼續運行導致的標記產生變動的對象,會STW
- 并發清除(CMS concurrent sweep),并發刪除掉已經判斷死亡的對象,可與用戶線程并發。

優點:并發收集、低停頓。
缺點:1.對處理器資源敏感,核心4個以上,并發回收線程不超過25%,2.無法處理浮動垃圾(新產生的垃圾),3.空間碎片多,空間不夠分配對象會Full GC。
3.5.7 Garbage First收集器
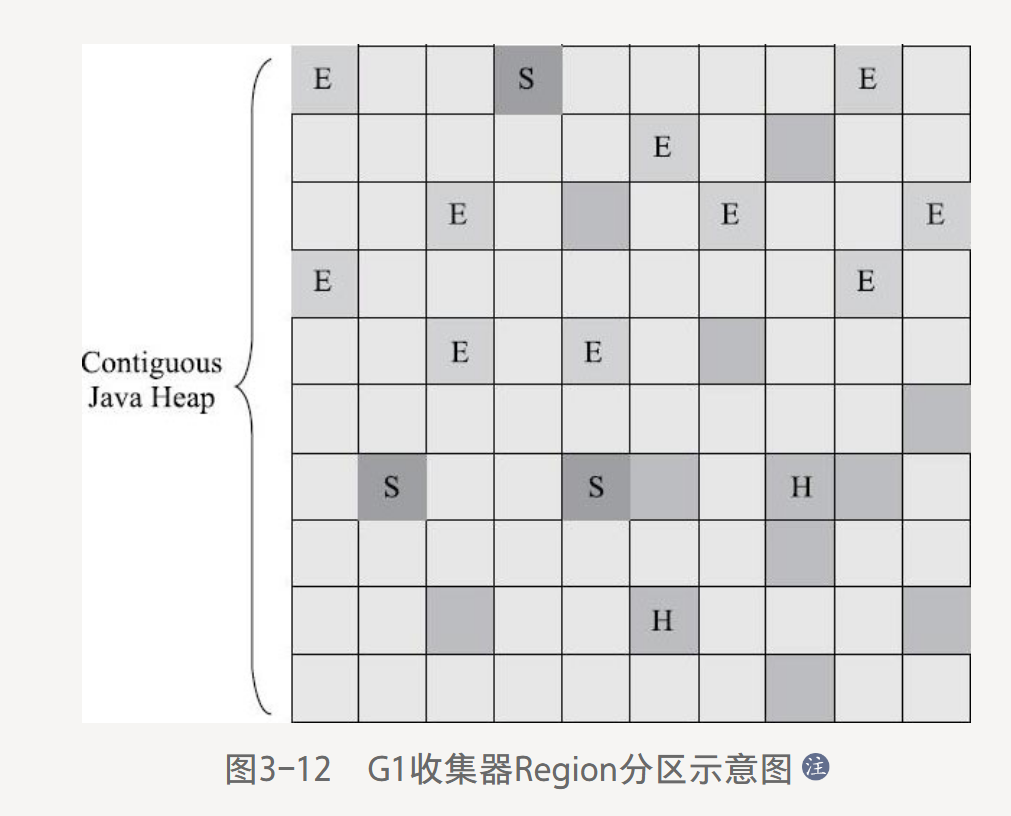
G1,全功能垃圾回收器,服務端默認回收器。
開創Region布局,遵循分代理論,但是堆內存劃分為大小相等的獨立區域(Region),每個區域可以根據需要扮演新生代Eden,Survivor,老年代。
Region中超過容量(1-32MB,為2的冪,通常2MB)的一半判定為大對象,存放在多個Humongous Region塊中,把它看成老年代。

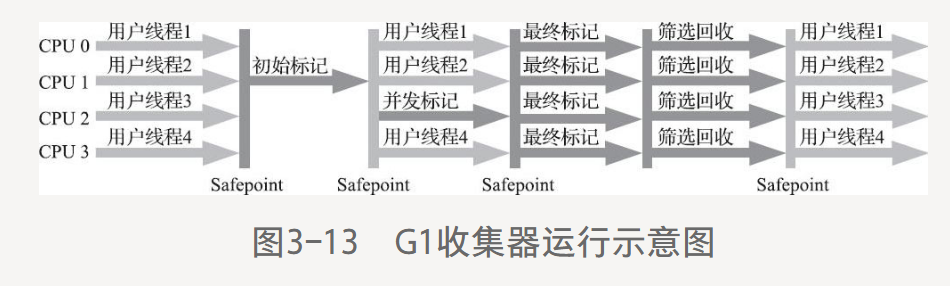
6-8GB內存以上,G1表現更好,否則CMS。
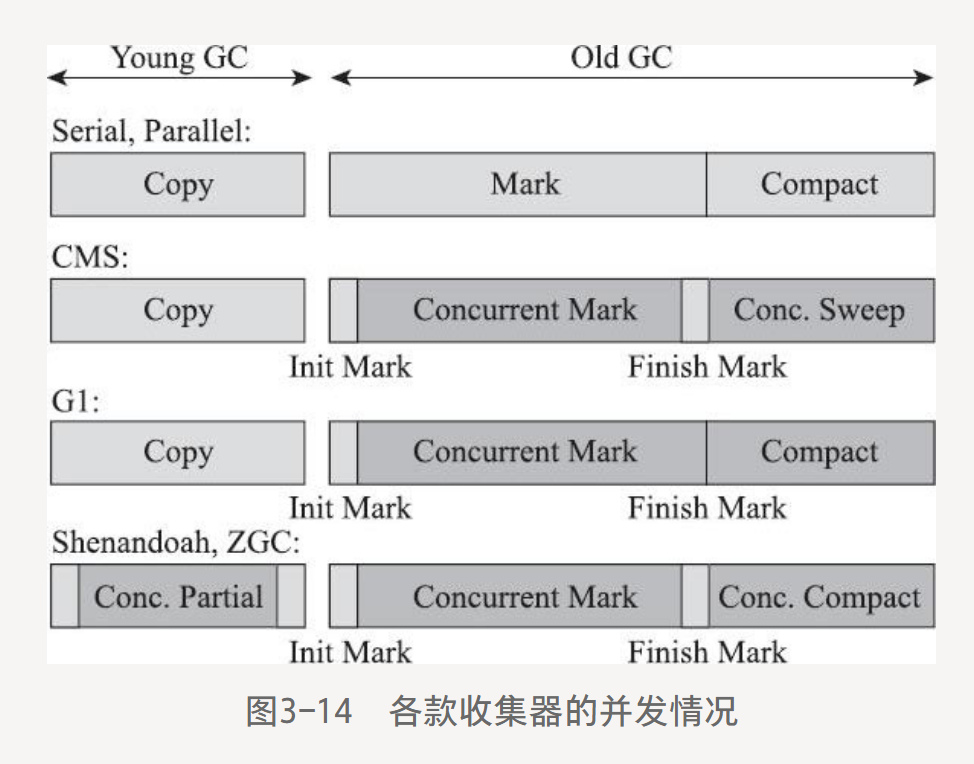
3.6 低延遲垃圾收集器
垃圾收集器三項最重要指標:內存占用(Footprint)、吞吐量(Throughtput)、延遲(Latency)。
不可能三角,最多占兩個。延遲是最重要的指標。
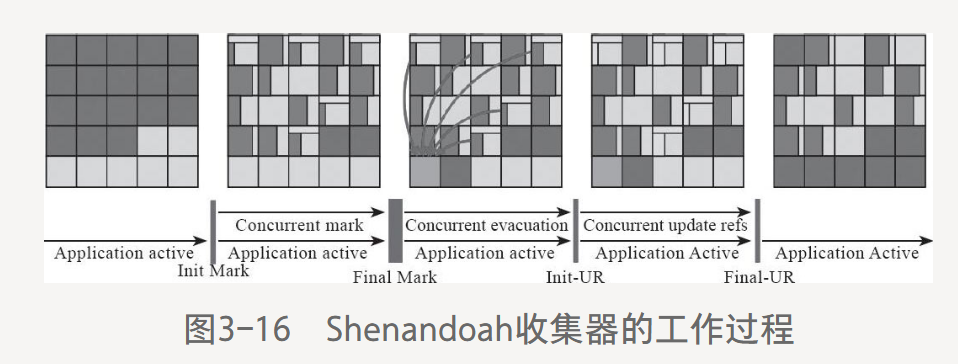
3.6.1 Shenandoah收集器(謝南多厄)
同G1相似,基于Region堆,放大對象Humongous Region,優先處理回收價值最大的Region。
不同點:支持并發整理算法,回收階段以多線程并行,卻不能與用戶線程并發。不分代。
工作過程分為9個階段:
等待。。。
3.6.2 ZGC收集器
JDK11加入,低延遲垃圾收集器。垃圾收集停頓時間限制在10毫秒。
也采用Region堆內存布局:


待定。。。









的數據)

)

?)
:馬爾可夫鏈——從詩歌分析到人工智能的數學工具)

)


)