樹和圖論
樹的遍歷模版
#include <iostream>
#include <cstring>
#include <vector>
#include <queue> // 添加queue頭文件
using namespace std;const int MAXN = 100; // 假設一個足夠大的數組大小
int ls[MAXN], rs[MAXN]; // 定義左右子樹數組//后序遍歷
void dfs(int x) {if(ls[x]) dfs(ls[x]);if(rs[x]) dfs(rs[x]);cout << x << ' ';
}//層序遍歷
void bfs() {queue<int> q;//起始節點入隊q.push(1);//隊列不為空則循環while(q.size()) {//訪問隊列元素xint x = q.front();//取出隊列元素q.pop();//一系列操作cout << x << " ";if(ls[x]) q.push(ls[x]);if(rs[x]) q.push(rs[x]);}
}
int main() {int n;cin >> n;for(int i = 1; i <= n; i++) {cin >> ls[i] >> rs[i];}dfs(1);cout << endl;bfs();return 0;
}
最近公共祖先LCA
本質是一個dp,類似于之前的ST表
fa[i][j]表示i號節點,向上走2^j所到的節點,當dep[i]-2^j>=1時fa[i][j]有效
又因為我們知道2^(j-1) + 2^(j-1)= 2^j, i的2^(j-1) 級祖先的2^(j-1)級祖先 就是i的2^j級祖先。
形象理解:
我們要求x(5號節點)與y(10號節點)的 LCA
倍增的時候,我們發現y的深度比x的深度要小,于是現將y跳到8號節點,使他們深度一樣:

這個時候,x和y的深度就相同了,于是我們按倍增的方法一起去找LCA
我們知道n(10)之內最大的二的次方是8,于是我們向上跳8個單位,發現跳過了。
于是我們將8/2變成4,還是跳過了。
再將4/2變成2,跳到了0號節點。
雖然這時跳到了LCA,但是如果直接if(x==y)就確定的話,程序無法判斷是剛好跳到了還是跳過了,應為跳過了x也等于y
于是我們需要剛好跳到LCA的兒子上,然后判斷if(x的爸爸==y的爸爸)來確定LCA
由于每一個數都可以分解為幾個2^n的和(不信自己試),所以他們一定會跳到LCA的兒子上
于是我們就找到了LCA啦!
代碼模版:
int lca(int x,int y){//x喜歡跳。。。//如果x深度比y小,交換x和y 保證x深度大if(dep[x]<dep[y]) swap(x,y); //貪心:i從大到小 //x向上跳的過程中,保持dep[x]>=dep[y],深度不能超過y for(int i=20;i>=0;i--){if(dep[fa[x][i]]>=dep[y]) x=fa[x][i];} //x跳完 此刻x和y的dep相同//如果發現相遇了 那么就是這個點if(x==y) return x;//(int)(log(n)/log(2))就是n以內最大的2的次方,從最大的開始倍增for(int i=(int)(log(n)/log(2));i>=0;i--) //如果x和y爸爸不想同 則沒有找到//整個跳躍過程中,保持x!=y,不用x=y判斷if(fa[x][i]!=fa[y][i]) x=fa[x][i],y=fa[y][i];//x和y一起向上跳 return fa[x][0];//返回他們的爸爸,即是LCA
}
可是在寫LCA之前,我們還得進行預要處理些什么呢?
1.每一個點的深度,以便到時候判斷
2.每一個點2^i級的祖先,以便到時候倍增跳
于是我們用一個dep數組來記錄每一個點的深度,再用一個fa[i][j]表示節點i的2^j級祖先
void dfs(int x,int p){dep[x]=dep[p]+1;//x的深度是他父親的深度+1 fa[x][0]=p;//2^0是1,x向上一個的祖先就是他爸爸for(int i=1;i<=20;i++) fa[x][i]=fa[fa[x][i-1]][i-1];//父節點再向上2^i-1 for(const auto &y : g[x]){ //枚舉x所有兒子if(y==p) continue;//如果不是他爸爸 繼續dfsdfs(y,x);}
}
樹的重心
指對于某個點,將其刪除后,可以是的剩余聯通塊的最大值最小的點(剩余的若干子樹的大小最小)
性質:
- 中心若干棵子樹大小一定**<=n/2**;除了重心以外的所有其他節點,都必然存在一棵節點個數>n/2的子樹
- 一棵樹至多兩個重心,如果存在,則必然相鄰;將連接兩個重心的邊刪除后,一定劃分為兩棵大小相等的樹
- 樹中所有點到某個點的距離和中,到重心的距離和是最小的
- 兩棵樹通過一條邊相連,重心一定在較大的一棵樹一側的連接點與原重心之間的簡單路徑上。兩棵樹大小相同,則重心就是兩個連接點。
如何求解重心?
跑一遍dfs,如果mss[x]<=n/2,則x是重心,反之不是。
void dfs(int x,int fa){//初始化mss/sz數組sz[x]=1,mss[x]=0;for(const auto& y:g[x]){if(y==fa) continue;dfs(y,x);sz[x]+=sz[y];mss[x]=max(mss[x],sz[y]);}//后序位置比較mss大小并判斷mss[x]=max(mss[x],n-sz[x]);if(mss[x]<=n/2) v.push_back(x);
}
樹的直徑
樹上任意兩節點之間最長的簡單路徑即為樹的「直徑」。
直徑由u,v決定,若有一條直徑(u,v)滿足 : **1)**u和v度數均為1;2)在任意一個點為根的樹上,u和v中必然存在一個點作為最深的葉子節點。
如何求解直徑?
跑兩遍dfs:以任意節點為根的樹上跑一次dfs求所有點的深度,選最大的點作為u,再以u為根拍一次dfs,最深的點為v,路徑上點的個數為樹的dep[v]+1(根節點深度為0)/ dep[v](根節點深度為1)
樹上差分
差分的思想方法:
如果有一個區間內的權值發生相同的改變的時候,我們可以采用差分的思想方法,而差分的思想方法在于不直接改變區間內的值,而是改變區間[ L , r ] 對于 區間 [ 0, L - 1 ] & 區間[ r + 1, R]的 相對大小關系
差分,可以當做前綴和的逆運算。既然是逆運算,運算方法自然就是相反的了。定義差分數組
d i f f i = a i ? a i ? 1 diff_i=a_i-a_{i-1} diffi?=ai??ai?1?
compare:
| 原數列 | 9 | 4 | 7 | 5 | 9 |
|---|---|---|---|---|---|
| 前綴和 | 9 | 13 | 20 | 25 | 34 |
| 差分數組 | 9 | -5 | 3 | -2 | 4 |
| 前綴和的差分數組 | 9 | 4 | 7 | 5 | 9 |
| 查分數組的前綴和 | 9 | 4 | 7 | 5 | 9 |
樹上差分,就是利用差分的性質,對路徑上的重要節點進行修改(而不是暴力全改),作為其差分數組的值,最后在求值時,利用dfs遍歷求出差分數組的前綴和,就可以達到降低復雜度的目的。
這里差分的優點就非常明顯了:
- 算法復雜度超低
- 適用于一切 連續的 “線段”
這里所謂的線段可以是一段連續的區間,也可以是路徑
點差分:
模版題目:給出一棵 n 個點的樹,每個點點權初始為 0,現在有 m 次修改,每次修改給出 x,y,將 x,y 簡單路徑上的所有點的點權 +d,問修改完之后每個點的點權。
將序列差分轉移到樹上:比如我們要對 x,y 的路徑上的點統一加上 d。

涉及到的點有:x,h,b,f,y因此對于點 a 我們不能有影響,操作方案就是 b(回溯時左右加了兩次)的點權減去 d,a 的點權減去 d。
最后我們對整棵樹做一遍 dfs,將所有點的點權變為其子樹(含自己)內所有點的點權,這個操作仿照求每個點子樹的 Size 就可以完成了。
模版代碼:
同樣需要lca的兩個模版函數,并添加:
dlt[i]:存放每個點經過的次數
void dfs1(int x){for(int i=0;i<v[x].size();i++){int u=v[x][i];if(u!=fa[x][0]){dfs1(u);//回溯dlt[x]+=dlt[u];}}return;
}
int main() {cin>>n>>k;maxx=log2(n); for(int i=1;i<n;i++){int a,b;cin>>a>>b;v[a].push_back(b),v[b].push_back(a); }dfs(1,0);//k次詢問 處理k條路徑 for(int i=1;i<=k;i++){int a,b;cin>>a>>b;dlt[a]++,dlt[b]++;int c=lca(a,b);dlt[c]--,dlt[fa[c][0]]--;}dfs1(1);for(int i=1;i<=n;i++) cout<<dlt[i]<<" ";return 0;
}
美妙的例題:
[P3258 JLOI2014] 松鼠的新家 - 洛谷 (luogu.com.cn)
邊差分:
模版題目:給出一棵 n個點的樹,每條邊邊權初始為 0,現在有 m 次修改,每次修改給出 x,y將 x,y簡單路徑上的所有邊邊權 +d,問修改完之后每條邊的邊權。
首先我們需要一種叫做**“邊權轉點權”的方法,就是對于每個點我們認為其點權代表這個點與其父節點之間的邊的邊權**,對于每條邊我們認為其邊權是這條邊所連兩個點中深度較大的點的點權,根節點點權無意義。
還是修改 x,y路徑上的邊,還是這張圖:
涉及的邊/點:x,h,f,y,對于點 b 我們不能有影響,操作方案就是 b(回溯時左右加了兩次 實則不變)的點權(b與父親節點的邊權)減去 2d。
同樣的做完之后一遍 dfs 求一下每個點的點權即可。
圖的遍歷模版
DFS:
bitset<N> vis;//vis[i]=true說明i點已經走過
void dfs(int x){vis[x]=true;for(const auto& y:g[x]){if(vis[y]) continue;dfs(y);}
}
BFS:
維護一個queue,通常用于求邊權相等情況下的最短距離
bitset<N> vis;
queue<int> qu;
void bfs() { qu.push(1);//從1開始while (!qu.empty()) { int x = qu.front(); qu.pop(); if (vis[x]) continue; // 避免重復處理 vis[x] = true; // 標記已訪問 for (const auto& y : g[x]) { if (!vis[y]) qu.push(y); // 未訪問的鄰居入隊 } }
}
例題1:幫派弟位
找到每個節點i 的子樹大小siz[i]
#include <bits/stdc++.h>
using namespace std;
const int N=1e5+9;
vector<int> g[N];
int siz[N];//存放包含自己在內的子樹節點個數
void dfs(int x,int p){siz[x]=1;//葉子如果設為0則對父節點的size毫無影響for(const auto &y:g[x]){if(y==p) continue;dfs(y,x);siz[x]+=siz[y];}
}
struct Node{int id,siz;//rule:主要按 siz 降序(siz > u.siz) siz 相同,則按 id 升序(id < u.id)bool operator < (const Node &u)const {return siz==u.siz?id<u.id:siz>u.siz;}
};int main()
{int n,m;cin>>n>>m;for(int i=1;i<n;i++){int r,l;cin>>l>>r;//存儲有向樹g[r].push_back(l);}dfs(1,0);//v存儲每個編號的手下人數多少vector<Node> v;//vector下標必須從0開始i=0存for(int i=0;i<n;i++) v.push_back({i,siz[i]-1});sort(v.begin(),v.end());for(int i=0;i<n;i++) if(v[i].id==m) cout<<i+1<<endl;return 0;
}
例題2: 可行路徑的方案數
計算從節點 1 到節點 n 的最短路徑數量
理解:
- “當前路徑” = 從城市1到
x的已知最短路徑 + 邊x→y。 - 這條路徑的長度是
d[x] + 1(因為所有邊權為1,即每走一步距離+1)。
- 如果
d[x] + 1 < d[y]:- 發現了一條更短的路徑到
y。 - 更新
d[y] = d[x] + 1,并重置dp[y] = dp[x](因為舊路徑不再有效)。 - 將
y加入隊列,繼續探索。
- 發現了一條更短的路徑到
- 如果
d[x] + 1 == d[y]:- 找到了一條等長的最短路徑到
y。 - 累加方案數:
dp[y] += dp[x](模p防止溢出)。 - 無需重復入隊(因為距離未變,BFS保證先到的最短路徑已處理)。
- 找到了一條等長的最短路徑到
- 如果
d[x] + 1 > d[y]:- 當前路徑比已知最短路徑長,直接跳過。
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5 + 9;
const int p = 1e9 + 7;
vector<int> g[N];
// d[]表示從索引值城市到城市1的距離;dp[]表示從索引值城市到城市1最近的路徑
int d[N], dp[N];
void bfs() {bitset<N> vis;queue<int> qu;qu.push(1);memset(d, 0x3f, sizeof d); //給每個城市最近距離初始化為無窮d[1] = 0;//1到第一個城市的距離為0dp[1] = 1; //到第一個城市方案數為1while(!qu.empty()) {//訪問并取出隊頭 判斷并標記為visitedint x = qu.front();qu.pop();if(vis[x]) continue;vis[x] = true;//找下一個城市y 判斷d[y]與d[x]+1的關系for(const auto & y : g[x]) {//從城市1到城市y的距離比之前走過的遠,不考慮if(d[x] + 1 > d[y]) continue;//找到另一條最短路徑,累加方案數if(d[x] + 1 == d[y]) dp[y] = dp[y] + dp[x] % p;//找到一條更短的經過x y的路else d[y] = d[x] + 1, dp[y] = dp[x];qu.push(y);}}
}
int main() {int n, m;cin >> n >> m;//雙向圖for(int i = 1; i <= m; i++) {int a, b;cin >> a >> b;g[a].push_back(b);g[b].push_back(a);}bfs();cout << dp[n] << endl;return 0;
}
實例:
1 -- 2 -- 3 \ / 4
bfs過程:
-
從城市1出發,
d[1]=0,dp[1]=1。 -
遍歷1的鄰居
{2, 4}- 更新
d[2]=1,dp[2]=1;d[4]=1,dp[4]=1。
- 更新
-
處理城市2:
-
鄰居
{1, 3, 4}- 1已訪問(
d[1]=0),跳過。 - 到3的“當前路徑”長度
d[2]+1=2,更新d[3]=2,dp[3]=1。 - 到4的“當前路徑”長度
d[2]+1=2,但d[4]=1(更短),跳過。
- 1已訪問(
-
-
處理城市4:
-
鄰居
{1, 2}- 1已訪問,跳過。
- 到2的“當前路徑”長度
d[4]+1=2,但d[2]=1(更短),跳過。
-
-
處理城市3:
- 鄰居
{2},已處理。
- 鄰居
最小生成樹Kruskal
與Prim算法不同,該算法的核心思想是歸并邊,而Prim算法的核心思想是歸并點。若邊數遠少于完全圖,Kruskal比Prim算法更高效。
思想回顧:
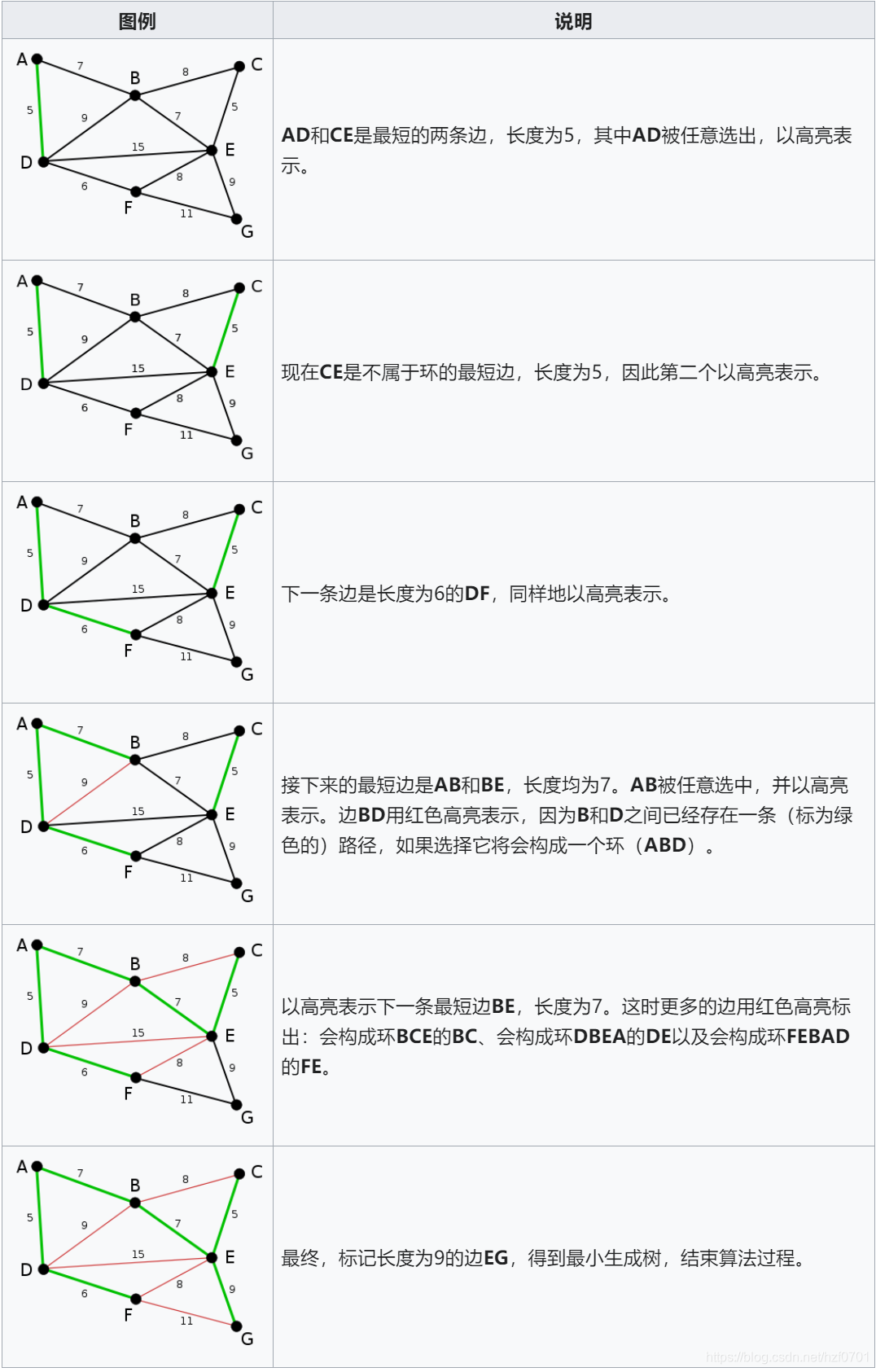
步驟:
- 按照所有邊權排序
- 從小到大遍歷所有邊(u,v),如果已聯通就跳過,否則就選中(u,v),將其連通。(用到并查集)
模版題代碼:旅行銷售員
走完N個城市,每公里消耗1升油,找出所需油箱的最小容量。
#include <iostream>
#include <vector>
#include <algorithm> using namespace std;
using ll = long long; // 使用長整型存儲權值 // 邊結構體:起點x、終點y、權值c
struct Edge { ll x, y, c; // 重載<運算符,按權值升序排序 bool operator<(const Edge& u) const { return c < u.c; }
}; // 并查集:查找根節點(帶路徑壓縮)
//目標:確定哪些節點屬于同一個連通分量,它并不關心邊的方向性
int root(vector<int>& pre, int x) { return pre[x] == x ? x : pre[x] = root(pre, pre[x]);
} void solve() { int n, m; // 節點數、邊數 cin >> n >> m; // 初始化并查集 vector<int> pre(n + 1); for (int i = 1; i <= n; ++i) { pre[i] = i; // 初始時每個節點的父節點是自己 } // 讀取所有邊 vector<Edge> es; for (int i = 1; i <= m; ++i) { ll x, y, c; cin >> x >> y >> c; es.push_back({x, y, c}); } // 按邊權升序排序 sort(es.begin(), es.end()); ll res = 0; // 記錄MST中的最大邊權 for (const auto& edge : es) { int x = edge.x; int y = edge.y; ll c = edge.c; // 若x和y不連通,則合并它們 if (root(pre, x) != root(pre, y)) { res = max(res, c); // 更新最大邊權 pre[root(pre, x)] = root(pre, y); // 合并操作 } } cout << res << endl; // 輸出結果
} int main() { int T = 0; // 測試數據組數 cin >> T; while (T--) { solve(); // 處理每組數據 } return 0;
}
最小生成樹Prim
思想回顧:
與dijkstra很像,逐步擴大樹中所含頂點的數目,直到遍及連通圖的所有頂點。下面描述我們假設N = ( V , E ) 是連通網,T E 是N 上最小生成樹中邊的集合。

- 每次找出不再mst中且d[]最小的點x,d[x]就是選中的那條邊的邊權。
- 將x加入mst,并更新其所有出點y,
d[y]=min(d[y],w) //w為x到y的距離 - 如果d[y]變小,就加入到優先隊列中作為可能的拓展點
mst使用bitset數組實現即可
代碼模版題:
#include<bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1E6 + 5;
ll n, m, inf = 1e9;
struct Edge {ll x, w;bool operator <(const Edge&u)const {return w > u.w; //小根堆}
};
//鄰接表
vector<Edge>g[N];
//記錄從起點(節點1)到各個節點的最小權重
ll d[N];
ll Prim() {//小根堆priority_queue<Edge>pq;bitset<N>vis;pq.push({1, d[1] = 0});ll res = 0;while(pq.size()) {//訪問并取出元素x 判斷并標記為visited//x為不在mst且權重最小的邊ll x = pq.top().x;pq.pop();if(vis[x])continue;vis[x] = true;//更新mst最小權重總和res = max(res, d[x]);//遍歷x所有鄰接節點for(const auto & temp : g[x]) {ll y = temp.x;ll w = temp.w;//比較w和d[y] w 更小則更新d[y]if(w < d[y])pq.push({y, d[y] = w});}}return res;
}
void solve() {cin >> n >> m;//每次clear g[N]for(int i = 1; i <= n; i++)g[i].clear(), d[i] = inf;while(m--) {ll x, y, w;cin >> x >> y >> w;//輸入帶權值的雙向邊模版g[x].push_back({y, w});g[y].push_back({x, w});}cout << Prim() << endl;
}
int main() {int t;cin >> t;while(t--)solve();return 0;
}











)
)
 對比)


: 神煩狗(DOGE))
)

