一、5w2h(七問法)分析正則表達式
是的,5W2H 完全可以應用于研究 正則表達式(Regular Expressions)。通過回答 5W2H 的七個問題,我們可以全面理解正則表達式的定義、用途、使用方法、適用場景等,幫助我們更好地學習和掌握它。
1. What(什么是正則表達式?)
- 正則表達式是一種用于描述字符串模式的語法規則。它通過一些特殊的字符和符號來定義匹配文本的模式,廣泛應用于文本搜索、替換、驗證等操作中。正則表達式能夠匹配符合特定規則的字符串。
例如:
\d:匹配任何數字字符。^abc:匹配以"abc"開頭的字符串。\w+:匹配一個或多個字母、數字或下劃線。
2. Why(為什么要使用正則表達式?)
- 正則表達式通過其簡潔的語法提供了一種強大的工具,可以在文本中進行復雜的模式匹配,減少繁瑣的文本處理代碼,提升開發效率。
- 用途:
-
- 驗證輸入:比如驗證電子郵件地址、電話號碼等格式。
- 查找和替換:在文本中查找符合某個模式的字符串并替換。
- 文本提取:從文本中提取符合特定模式的信息。
3. When(何時使用正則表達式?)
- 當你需要處理或驗證字符串的格式時,尤其是在文本搜索、數據清洗、日志分析等場景下,正則表達式非常有用。
- 常見場景:
-
- 驗證用戶輸入(如郵箱、日期格式等)。
- 提取特定格式的數據(如從網頁抓取郵箱地址、電話號碼等)。
- 文本搜索和替換(如在代碼中查找函數定義或在文件中查找特定信息)。
4. Where(在哪里使用正則表達式?)
- 正則表達式可以在許多編程語言和工具中使用,幾乎所有現代編程語言都支持正則表達式(如 Java, Python, JavaScript, C# 等)。
- 應用場景:
-
- 編程語言:在 Python 中使用
re模塊,在 JavaScript 中使用RegExp對象,在 Java 中使用Pattern類等。 - 文本編輯器:許多文本編輯器(如 VS Code、Sublime Text)支持正則表達式來進行查找和替換。
- 命令行工具:如
grep,sed,awk等 Unix 工具支持正則表達式。
- 編程語言:在 Python 中使用
5. Who(誰使用正則表達式?)
- 程序員:正則表達式是開發人員必備的工具,特別是涉及文本處理、數據清理、日志分析等任務時。
- 測試人員:在自動化測試中,正則表達式可用于驗證字符串的格式或從響應中提取信息。
- 數據分析師:用于清洗和提取結構化或非結構化數據中的有用信息。
6. How(如何使用正則表達式?)
- 正則表達式的語法通常包括常用的特殊字符和元字符,如:
-
.:匹配任意單個字符。*:匹配前面的字符零次或多次。+:匹配前面的字符一次或多次。[]:定義字符集,匹配其中的任意一個字符。|:表示"或"操作,匹配左邊或右邊的表達式。():分組,用來定義子表達式或捕獲匹配。
- 使用方法:
-
- 在編程中,通常使用正則表達式的相關API進行匹配和操作。例如,在 Python 中:
import re
pattern = r'\d+' # 匹配一個或多個數字
result = re.findall(pattern, 'There are 123 apples and 456 oranges.')
print(result) # 輸出:['123', '456']7. How much(多少?)
- 正則表達式本身是一個計算機程序語言的工具,它沒有直接的“成本”,但它的復雜度和匹配的文本量可能會影響性能。尤其是在大型文本處理時,正則表達式的效率和匹配速度可能會成為問題。
- 性能問題:
-
- 對于非常復雜的正則表達式,或者需要匹配大量文本的操作,可能會導致性能問題。因此在使用正則表達式時,需要謹慎設計,以避免過度復雜的匹配模式和低效的匹配操作。
總結:
通過使用 5W2H 方法來分析 正則表達式,可以幫助我們全面了解它的定義、目的、應用場景以及如何高效地使用它。在實際工作中,正則表達式是一個強大的工具,特別是在需要處理和分析字符串時,通過結構化思維,可以幫助我們更好地理解正則表達式的使用方式和最佳實踐。
二、正則表達式-菜鳥教程-整理
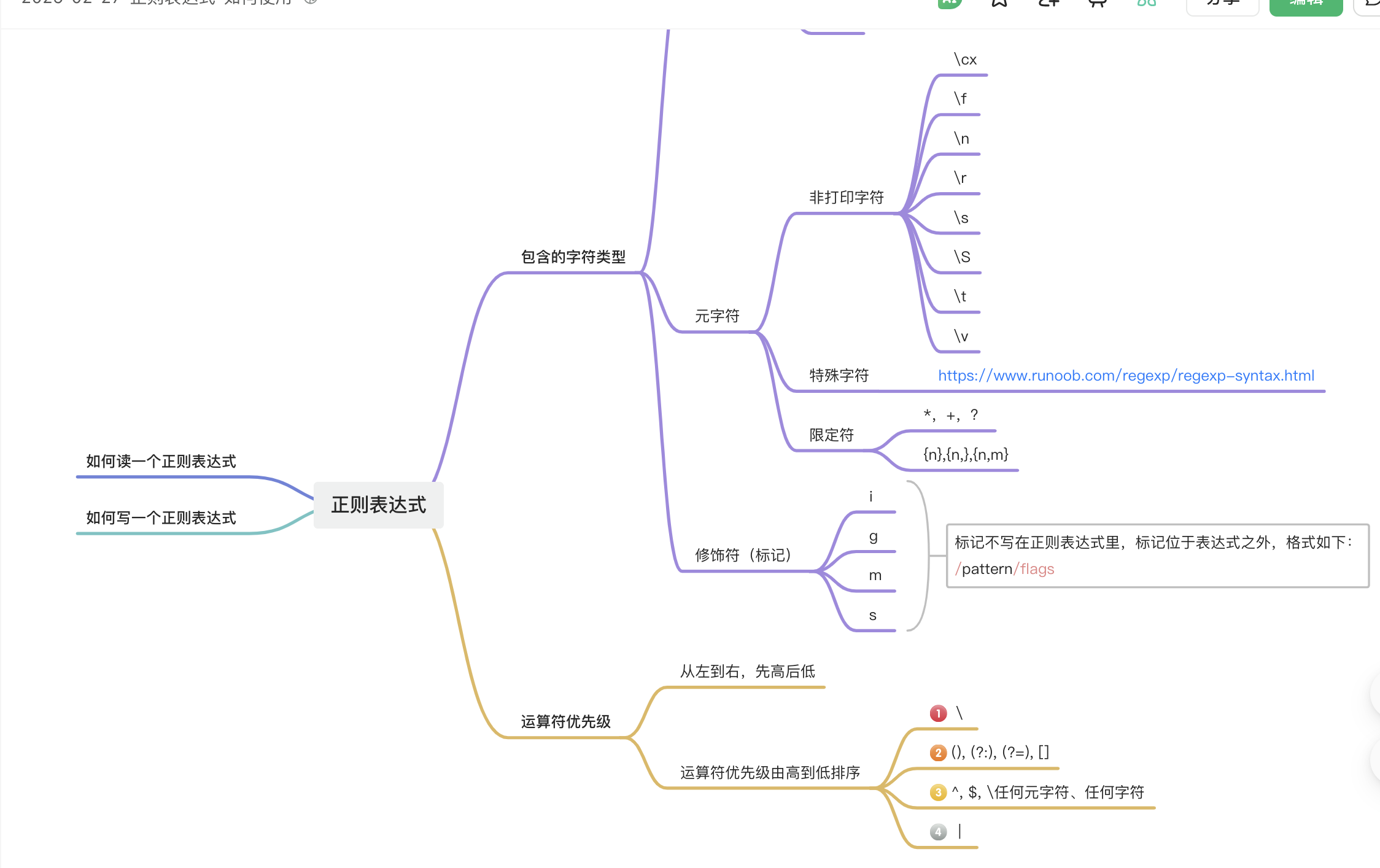
非打印字符
非打印字符也可以是正則表達式的組成部分。下表列出了表示非打印字符的轉義序列:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一個 Control-M 或回車符。x 的值必須為 A-Z 或 a-z 之一。否則,將 c 視為一個原義的 'c' 字符。 |
| \f | 匹配一個換頁符。等價于 \x0c 和 \cL。 |
| \n | 匹配一個換行符。等價于 \x0a 和 \cJ。 |
| \r | 匹配一個回車符。等價于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、換頁符等等。等價于 [ \f\n\r\t\v]。注意 Unicode 正則表達式會匹配全角空格符。 |
| \S | 匹配任何非空白字符。等價于 [^ \f\n\r\t\v]。 |
| \t | 匹配一個制表符。等價于 \x09 和 \cI。 |
| \v | 匹配一個垂直制表符。等價于 \x0b 和 \cK。 |
特殊字符
所謂特殊字符,就是一些有特殊含義的字符,如上面說的?runoo*b?中的?*,簡單的說就是表示任何字符串的意思。如果要查找字符串中的?*?符號,則需要對?*?進行轉義,即在其前加一個?\,runo\*ob?匹配字符串?runo*ob。
許多元字符要求在試圖匹配它們時特別對待。若要匹配這些特殊字符,必須首先使字符"轉義",即,將反斜杠字符\?放在它們前面。下表列出了正則表達式中的特殊字符:
| 特別字符 | 描述 |
|---|---|
| $ | 匹配輸入字符串的結尾位置。如果設置了 RegExp 對象的 Multiline 屬性,則 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,請使用 \$。 |
| ( ) | 標記一個子表達式的開始和結束位置。子表達式可以獲取供以后使用。要匹配這些字符,請使用 \( 和 \)。 |
| * | 匹配前面的子表達式零次或多次。要匹配 * 字符,請使用 \*。 |
| + | 匹配前面的子表達式一次或多次。要匹配 + 字符,請使用 \+。 |
| . | 匹配除換行符 \n 之外的任何單字符。要匹配 . ,請使用 \. 。 |
| [ | 標記一個中括號表達式的開始。要匹配 [,請使用 \[。 |
| ? | 匹配前面的子表達式零次或一次,或指明一個非貪婪限定符。要匹配 ? 字符,請使用 \?。 |
| \ | 將下一個字符標記為或特殊字符、或原義字符、或向后引用、或八進制轉義符。例如, 'n' 匹配字符 'n'。'\n' 匹配換行符。序列 '\\' 匹配 "\",而 '\(' 則匹配 "("。 |
| ^ | 匹配輸入字符串的開始位置,除非在方括號表達式中使用,當該符號在方括號表達式中使用時,表示不接受該方括號表達式中的字符集合。要匹配 ^ 字符本身,請使用 \^。 |
| { | 標記限定符表達式的開始。要匹配 {,請使用 \{。 |
| | | 指明兩項之間的一個選擇。要匹配 |,請使用 \|。 |
限定符
限定符用來指定正則表達式的一個給定組件必須要出現多少次才能滿足匹配。有?*?或?+?或???或?{n}?或?{n,}?或?{n,m}?共6種。
正則表達式的限定符有:
| 字符 | 描述 | 實例 |
|---|---|---|
| * | 匹配前面的子表達式零次或多次。例如,zo*?能匹配?"z"?以及?"zoo"。*?等價于?{0,}。 | 嘗試一下 ? |
| + | 匹配前面的子表達式一次或多次。例如,zo+?能匹配?"zo"?以及 "zoo",但不能匹配?"z"。+?等價于?{1,}。 | 嘗試一下 ? |
| ? | 匹配前面的子表達式零次或一次。例如,do(es)??可以匹配?"do"?、?"does"、?"doxy"?中的?"do"?和?"does"。??等價于?{0,1}。  | 嘗試一下 ? |
| {n} | n 是一個非負整數。匹配確定的?n?次。例如,o{2}?不能匹配?"Bob"?中的?o,但是能匹配?"food"?中的兩個?o。 | 嘗試一下 ? |
| {n,} | n 是一個非負整數。至少匹配n 次。例如,o{2,}?不能匹配?"Bob"?中的?o,但能匹配?"foooood"?中的所有?o。o{1,}?等價于?o+。o{0,}?則等價于?o*。 | 嘗試一下 ? |
| {n,m} | m 和 n 均為非負整數,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3}?將匹配?"fooooood"?中的前三個?o。o{0,1}?等價于?o?。請注意在逗號和兩個數之間不能有空格。 |
*?和?+?限定符都是貪婪的,因為它們會盡可能多的匹配文字,只有在它們的后面加上一個 ? 就可以實現非貪婪或最小匹配。
例如,您可能搜索 HTML 文檔,以查找在?h1?標簽內的內容。HTML 代碼如下:
<h1>RUNOOB-菜鳥教程</h1>
貪婪:下面的表達式匹配從開始小于符號 (<) 到關閉 h1 標記的大于符號 (>) 之間的所有內容。
/<.*>/

非貪婪:如果您只需要匹配開始和結束 h1 標簽,下面的非貪婪表達式只匹配 <h1>。
/<.*?>/

也可以使用以下正則表達式來匹配 h1 標簽,表達式則是:
/<\w+?>/

通過在?*、+?或???限定符之后放置??,該表達式從"貪婪"表達式轉換為"非貪婪"表達式或者最小匹配。
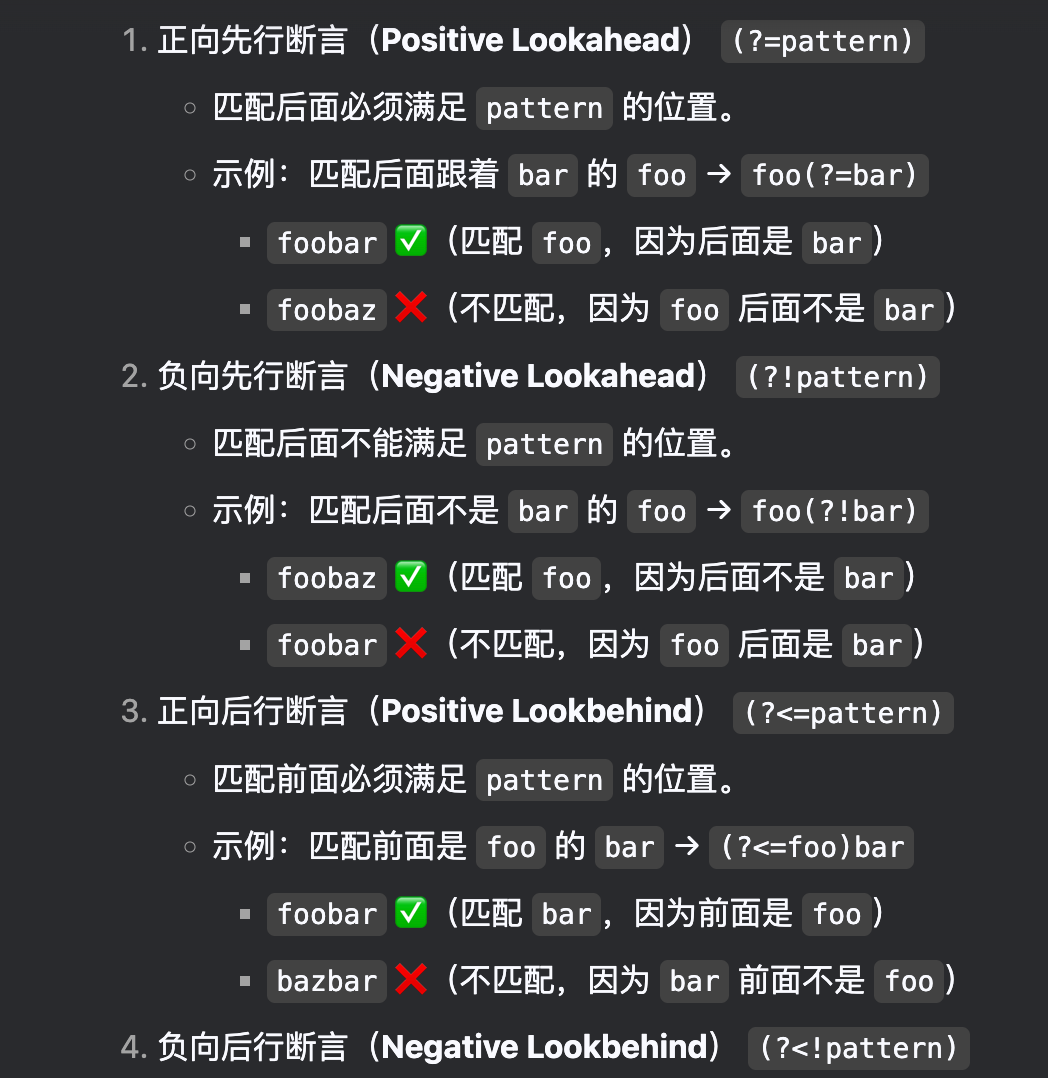
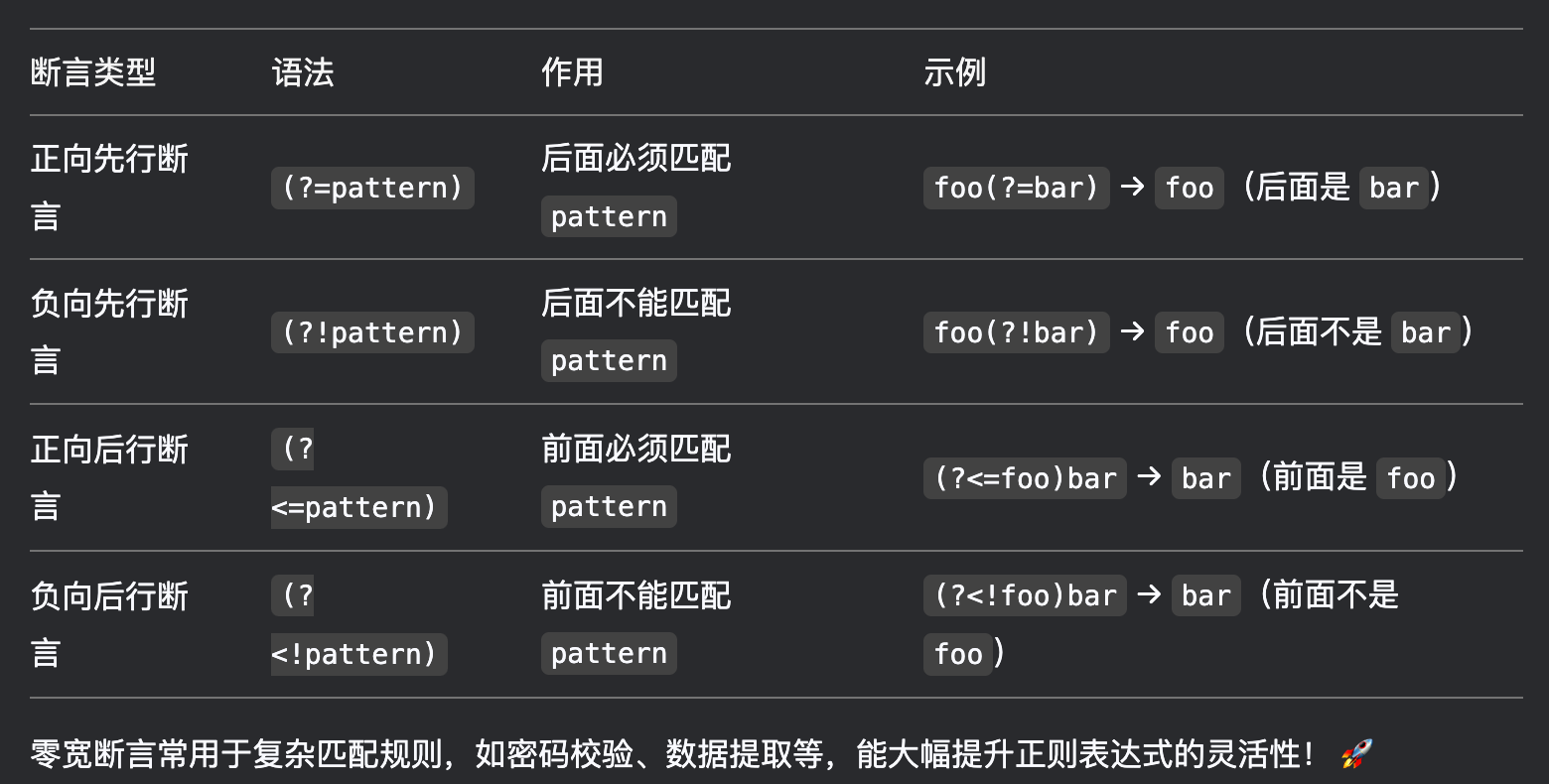
以下列出 ?=、?<=、?!、?<! 的使用區別
exp1(?=exp2):查找 exp2 前面的 exp1。

(?<=exp2)exp1:查找 exp2 后面的 exp1。

exp1(?!exp2):查找后面不是 exp2 的 exp1。

(?<!exp2)exp1:查找前面不是 exp2 的 exp1。


三、如何分析正則表達式-案例
你提供的正則表達式 ^[0-9]{1,}\.([^。|\r]*)[。|\r] 用于匹配以數字開頭、后跟句點(.),并以句號(。)或換行符(\r)結尾的字符串。以下是對該正則表達式的詳細解析:
1. 正則表達式解析
^[0-9]{1,}\.([^。|\r]*)[。|\r]各部分含義:
^: 匹配字符串的開頭。[0-9]{1,}:
-
[0-9]: 匹配任意一個數字(0到9)。{1,}: 表示前面的模式(數字)至少出現1次,可以出現多次。- 整體含義:匹配一個或多個數字。
\.: 匹配一個句點(.)。由于句點在正則表達式中有特殊含義(匹配任意字符),因此需要用反斜杠(\)進行轉義。([^。|\r]*):
-
[^。|\r]: 匹配不是句號(。)或換行符(\r)的任意字符。*: 表示前面的模式(非句號或換行符)可以出現0次或多次。- 整體含義:匹配一段不包含句號或換行符的文本,并將其捕獲為一個分組。
[。|\r]: 匹配一個句號(。)或換行符(\r),表示字符串的結束。
2. 匹配示例
假設有以下文本:
1.這是一個測試。
2.這是另一個測試
3.這是第三個測試。匹配結果:
1.這是一個測試。:
-
- 匹配內容:
1.這是一個測試。 - 捕獲的分組:
這是一個測試
- 匹配內容:
2.這是另一個測試:
-
- 匹配內容:
2.這是另一個測試 - 捕獲的分組:
這是另一個測試
- 匹配內容:
3.這是第三個測試。:
-
- 匹配內容:
3.這是第三個測試。 - 捕獲的分組:
這是第三個測試
- 匹配內容:
3. 改進建議
你的正則表達式已經可以滿足基本需求,但有一些地方可以優化:
- 字符集語法:
-
[^。|\r]中的|是多余的,應該直接寫成[^。\r]。- 修正后:
([^。\r]*)
- 換行符處理:
-
- 如果需要匹配多種換行符(如
\n或\r\n),可以將\r替換為\r?\n。 - 修正后:
[。\r?\n]
- 如果需要匹配多種換行符(如
改進后的正則表達式:
^[0-9]{1,}\.([^。\r]*)[。\r?\n]4. 總結
- 原始正則表達式:
^[0-9]{1,}\.([^。|\r]*)[。|\r] - 功能: 匹配以數字開頭、后跟句點,并以句號或換行符結尾的字符串。
- 優化建議: 修正字符集語法,并考慮多種換行符的情況。













)
)

)


)