一,平臺簡介:

主要是官方手冊指南、B站視頻(培訓視頻、軟件視頻)
1,超算平臺架構:
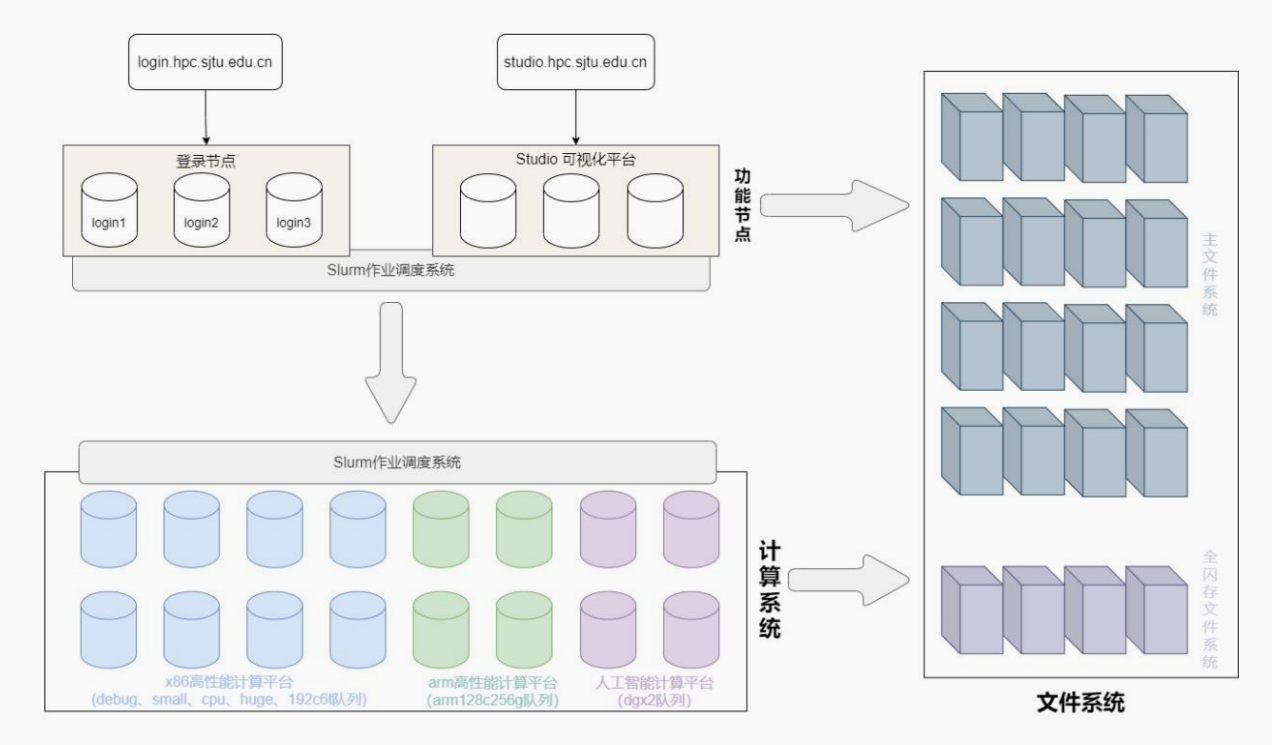
和普通的家用電腦的架構不同,
主要區別在于:層次化的結構
(1)超算是有很多張cpu卡、gpu卡,以及硬盤,然后通過高速網絡聯合起來;
(2)一般情況下,多個核心首先會組織成一個節點,然后多個節點聯合起來就形成了一個集群
然后節點部分又分為3個部分:
(1)功能節點:登入節點+可視化平臺節點+數據傳輸節點,
都是一些特殊的節點,設計用來執行不同的任務;比如說登入節點,承載用戶的登入,類似于前臺;
可視化節點用于在可視化平臺上的訪問服務;
數據傳輸節點:用戶數據傳輸的服務
——》專事專用,比如說禁止在登入節點上進行大型數據傳輸,當然一些小文件是可以的
(2)計算系統:一些節點,也就是計算資源,用于處理我們所提交的計算任務;
用戶實際上是不直接面對計算節點的,但是我們的作業需要在計算節點上去運行;
我們一般是在登入節點上用一種特定的格式,提交我們的作業,然后這個命令/作業會被提交給slurm作業調度系統——》這個系統其實就相當于是一種排隊機制,有好幾種隊列,就相當于是食堂的窗口,我們的作業來了就是排在隊尾;當前面的任務執行完畢之后,我們的作業就會被投入到某一個空閑的計算節點當中去運行
(3)文件系統:簡單理解來說就是硬盤,存儲遠程的數據

但是這個硬盤不是鐵板一塊,也是分層的:
最高層的是一個全閃存文件系統,如果我們的作業有一個高輸入輸出的高頻率的需求,我們一般會將我們作業中用到的data copy到這個全閃存系統中,然后再去運行我們的作業;
當然,一般的文件傳輸需求就是我們的主文件系統;
最底層的歸檔文件系統:冷存儲,就是長時間不用的數據放在這里
2,slurm作業調度系統
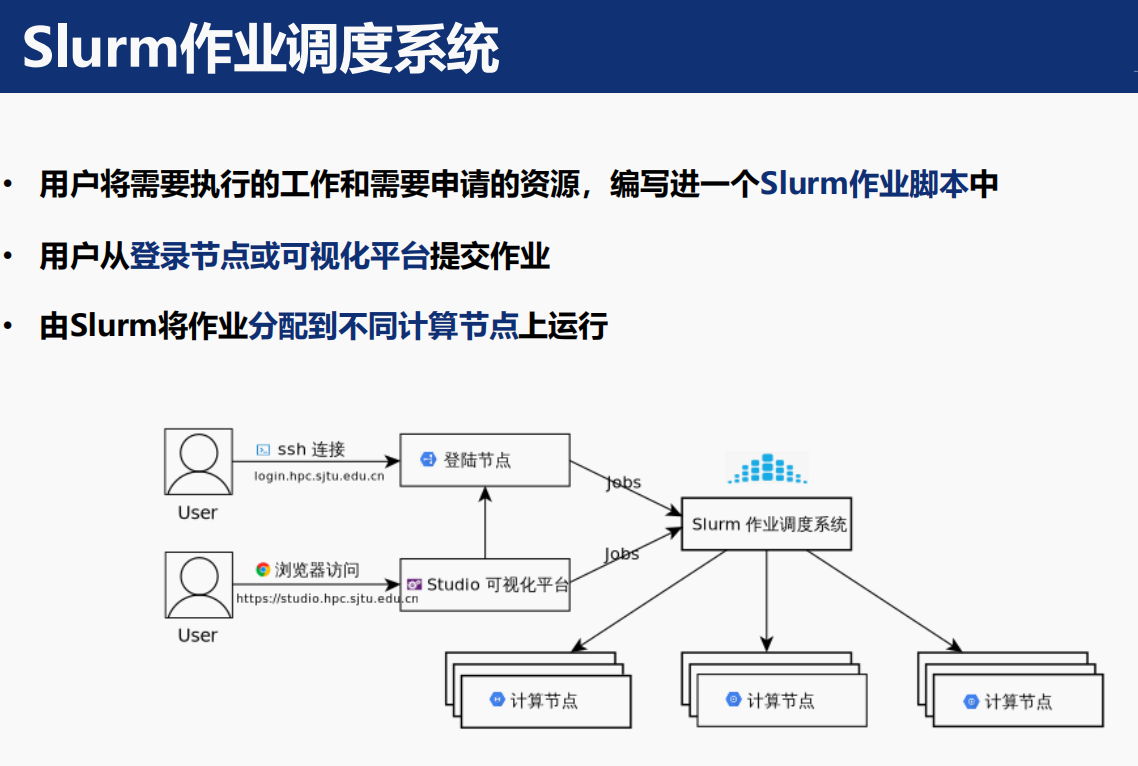
在登入節點提交slurm腳本,然后由slurm作業調度系統分配作業到不同計算節點進行任務執行
3,集群登入:
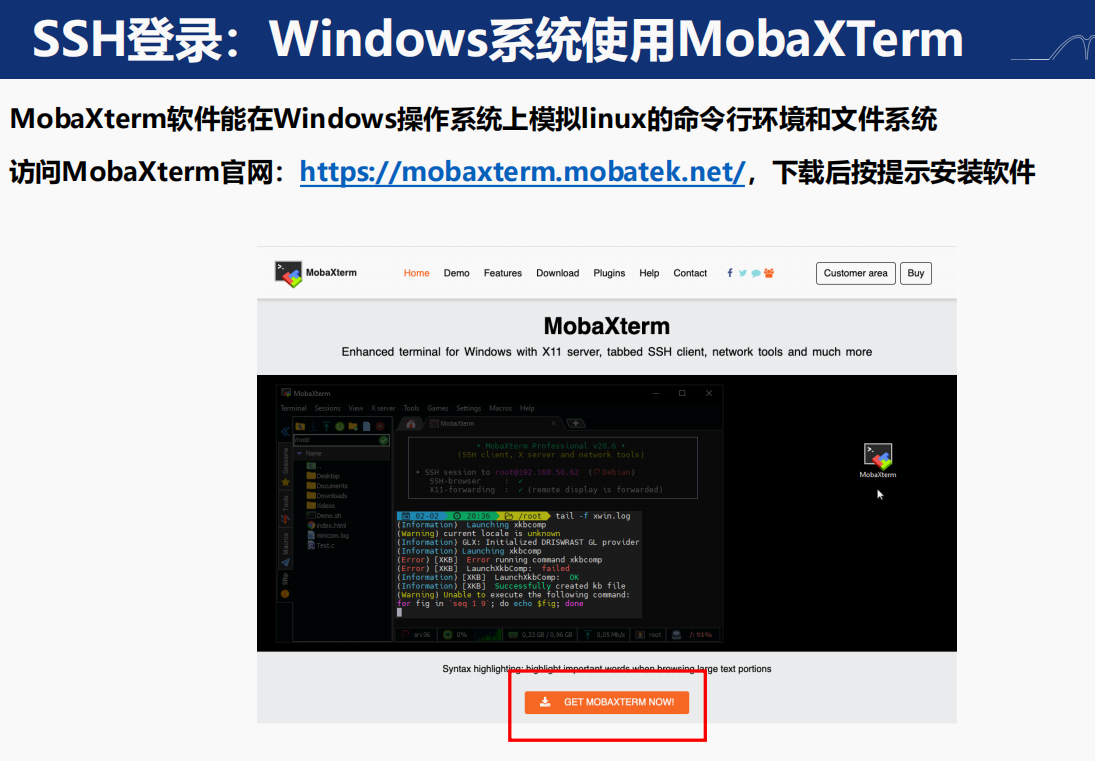
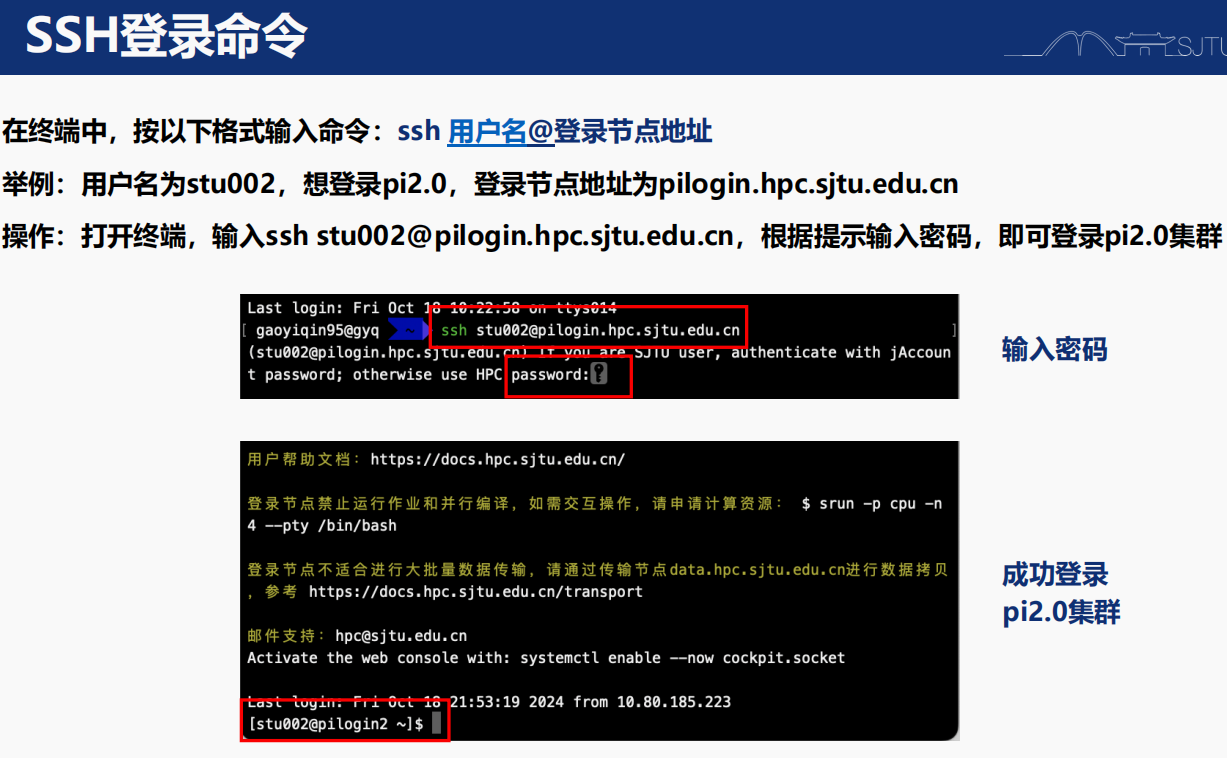
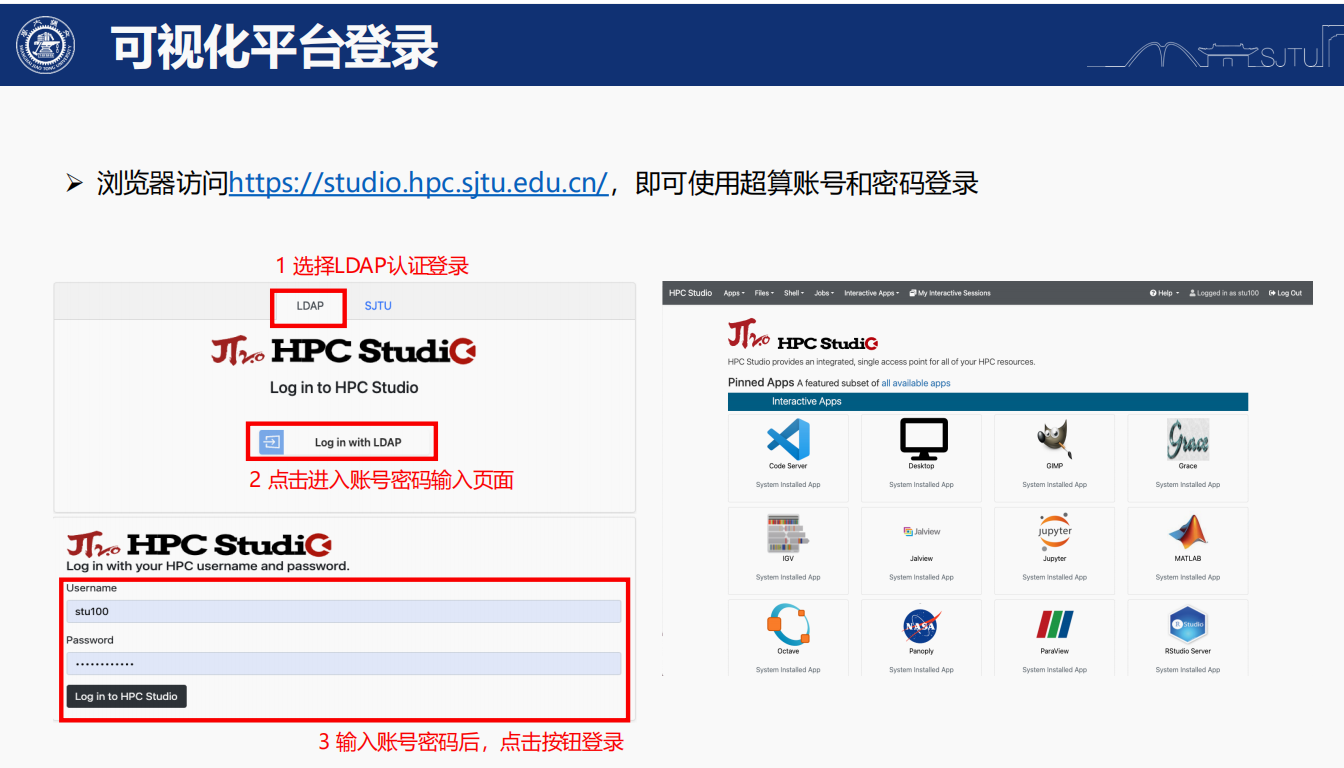
這個其實就很基本了,學生信的基本功;
我們在主校區一般是登入pi2.0節點
登入集群我首推vscode,畢竟以后要做coding,也得多平臺;其次是在沒辦法了再用mobaxterm
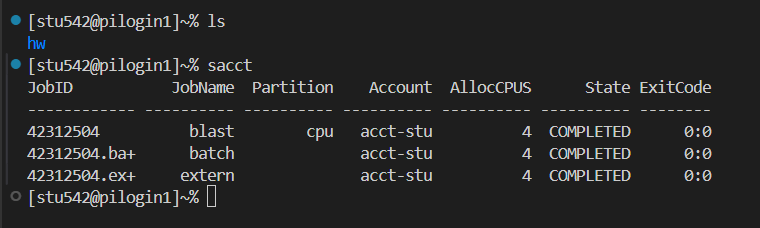
集群中一般使用的都是zsh,當然bash都可以隨時切換。
然后這里要提一嘴免密登入的問題了:
可以參考我之前的博客:https://blog.csdn.net/weixin_62528784/article/details/146028231?spm=1001.2014.3001.5501
比如說,這是一個我們的賬戶主界面:
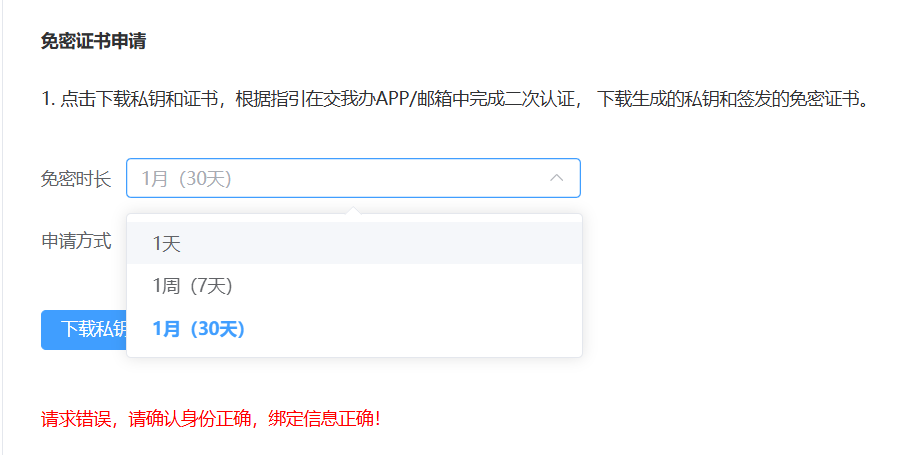
申請免密證書需要驗證郵箱,但是鑒于這是一個教學用臨時賬號,我們此處不進行免密登入。
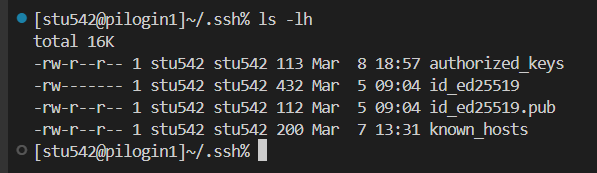
總之傳統的方式是不管用的
4,數據傳輸:
和登入節點類似,數據傳輸節點也有專門的節點,如果需要大批量數據的傳輸,建議登入到數據傳輸節點再進行;
登入方式和ssh類似
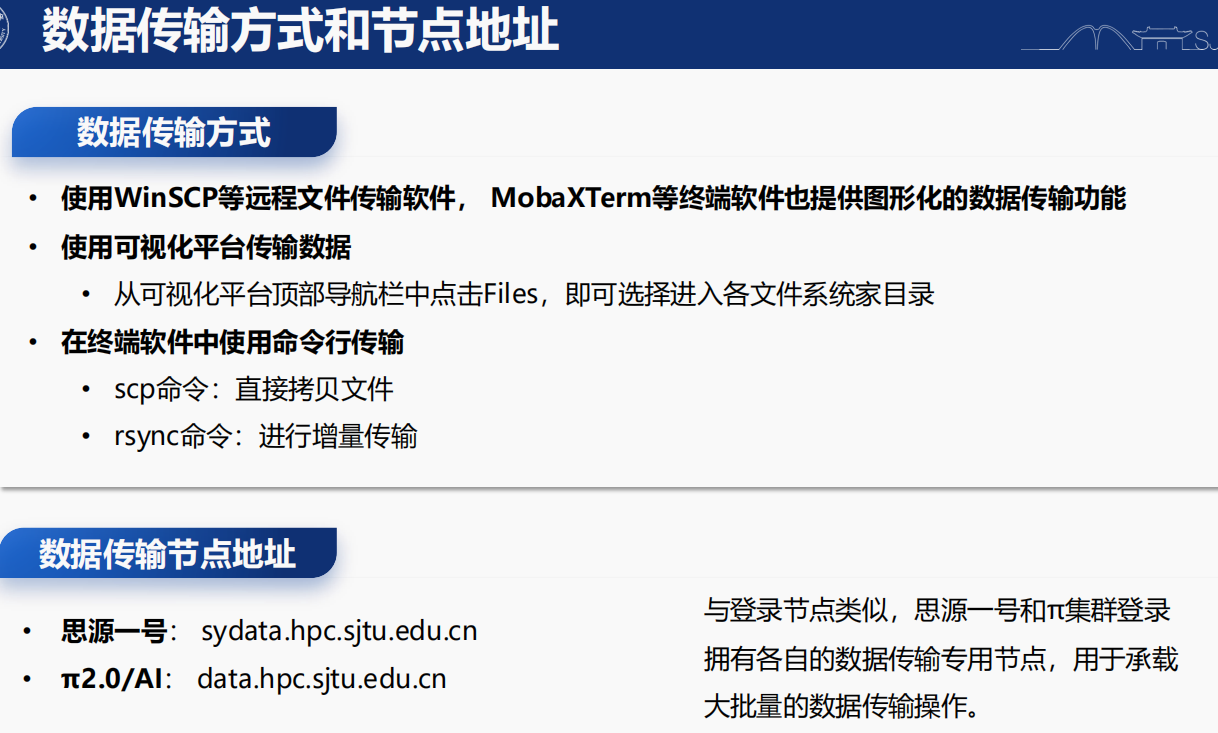
但是教學用賬號是沒有權限登入數據傳輸節點的,需要科研用正式實驗室賬號以及子賬號,才有權限登入(ssh stu542@dataxxxx,親測)
小白的話當然使用圖形化處理界面的SFTP:
其實可視化登入界面上也沒有什么,就很正常的linux-desktop

進入之后是這樣的: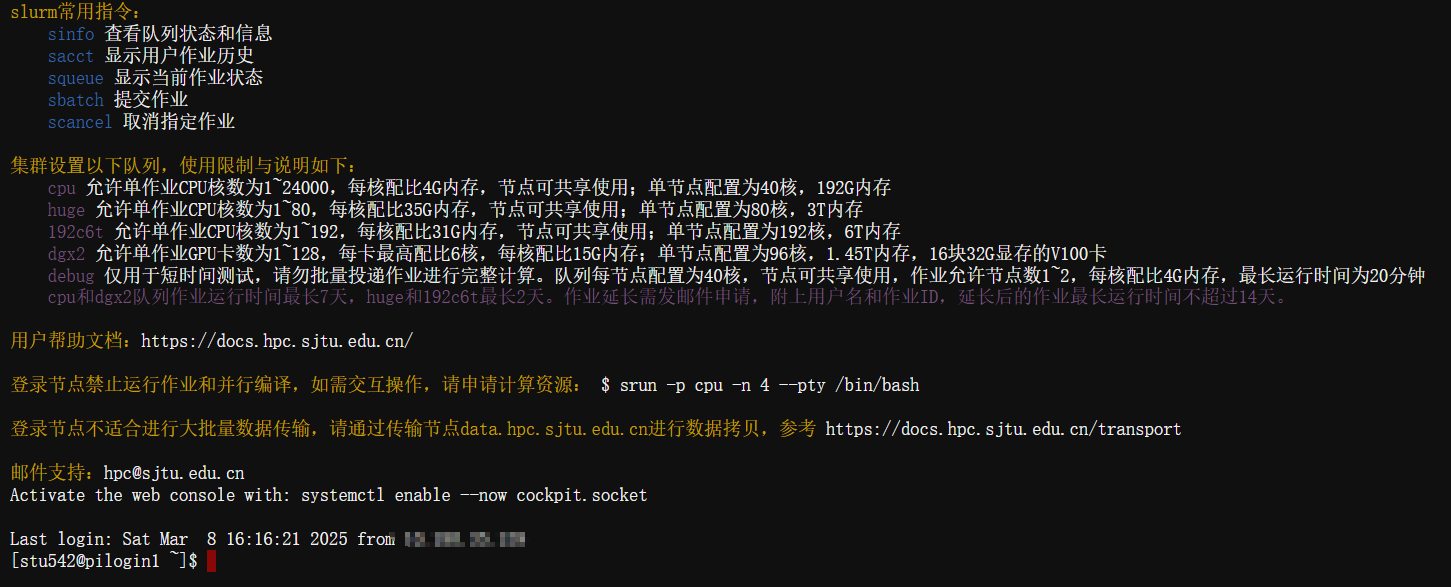
非小白的話,使用正常的文件傳輸命令操作即可:

也是常識,可以參考我之前博客: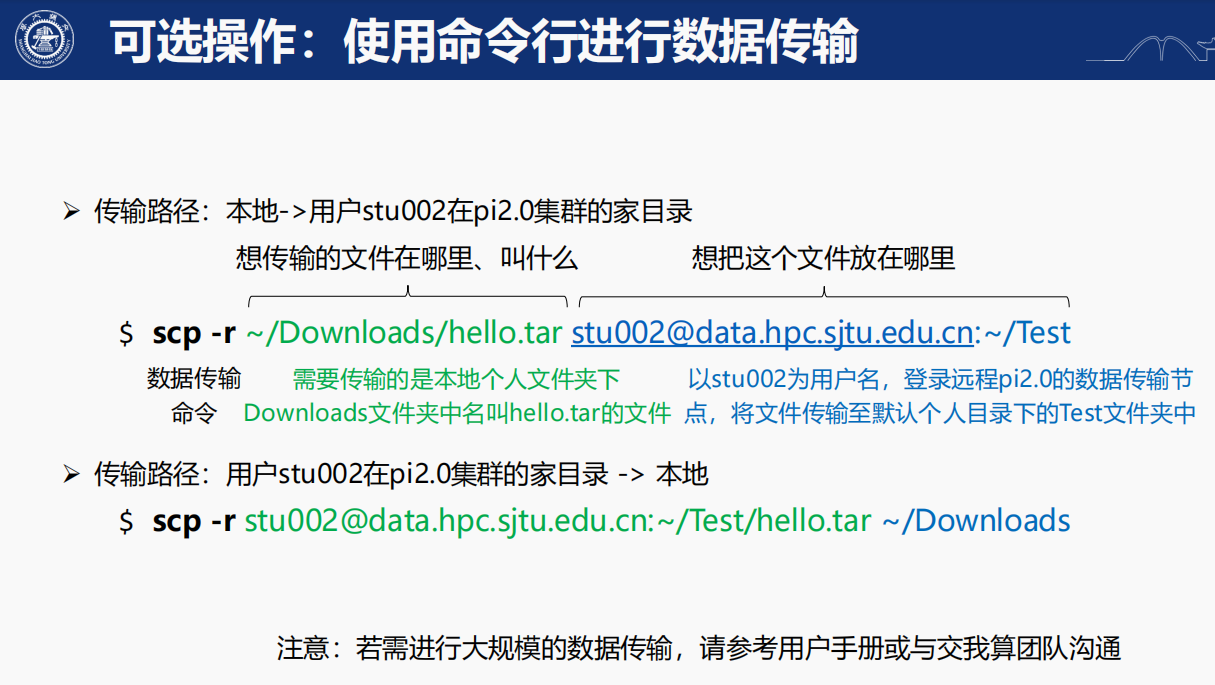
https://blog.csdn.net/weixin_62528784/article/details/146071769?spm=1001.2014.3001.5501
5,作業提交與查詢:
各種字母,后續在作業提交以及后臺監控時候會經常遇見

sbatch就很基本了,最基本的任務投遞命令
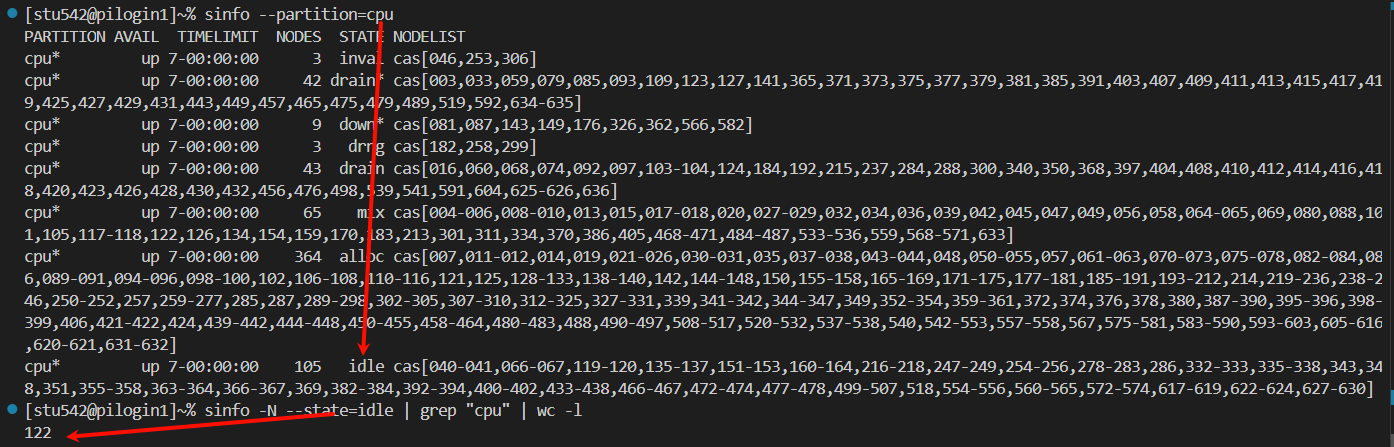
(1)sinfo:
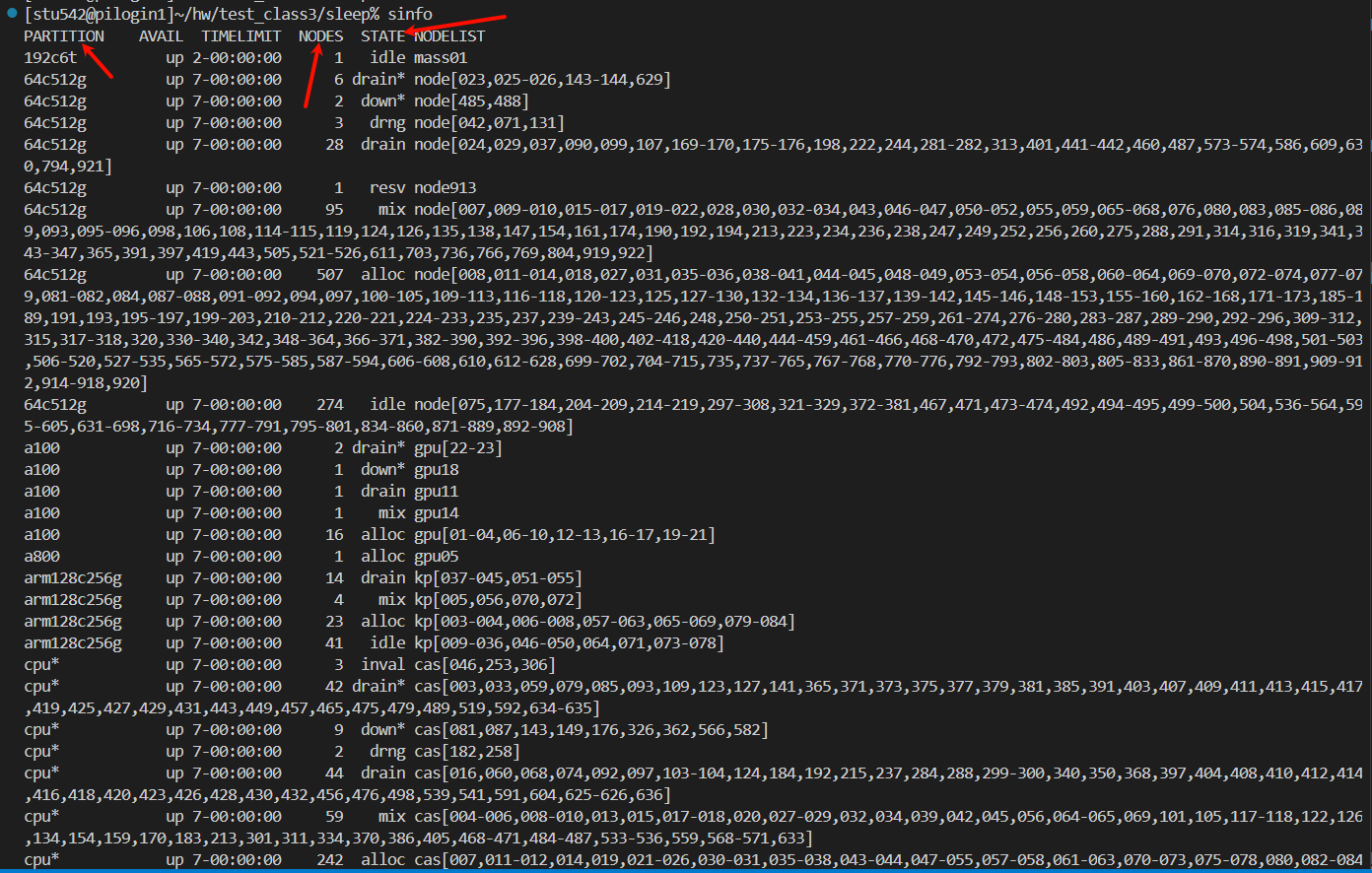
我們能夠查看每一個隊列的每一個狀態的節點到底有多少個

比如說上面,每一行都是一個隊列的一個狀態的節點情況,比如說cpu隊列中idle空閑的節點數目有233個
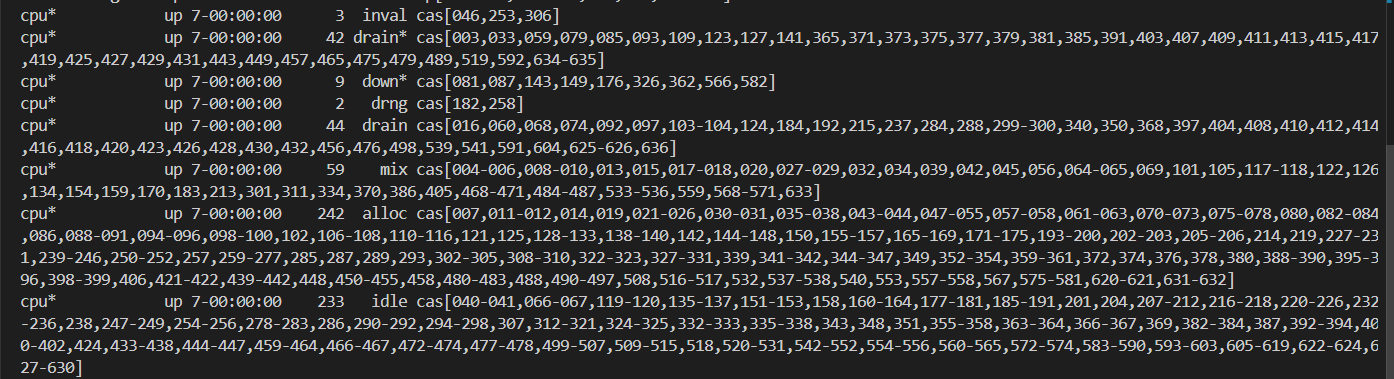

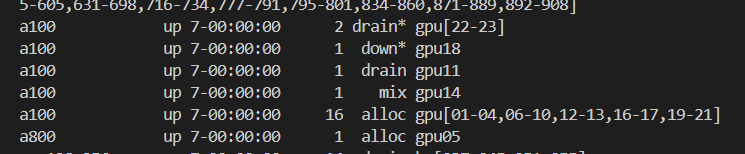
然后比如說上面的gpu節點,就完全沒有空閑的了,就全被占用了,說明深度學習煉丹跑模型的人很多。
我們一般關注的是空閑也就是idle的節點,一般來說我們應該在隊列任務投遞之前先查看一下這個隊列中節點的運行情況,如果說其中idle的節點比較多,那就意味著我們在任務投遞之后很快就可以輪到我們的任務執行了。
比如說我想查看一下無論哪個隊列中什么節點是空閑的:
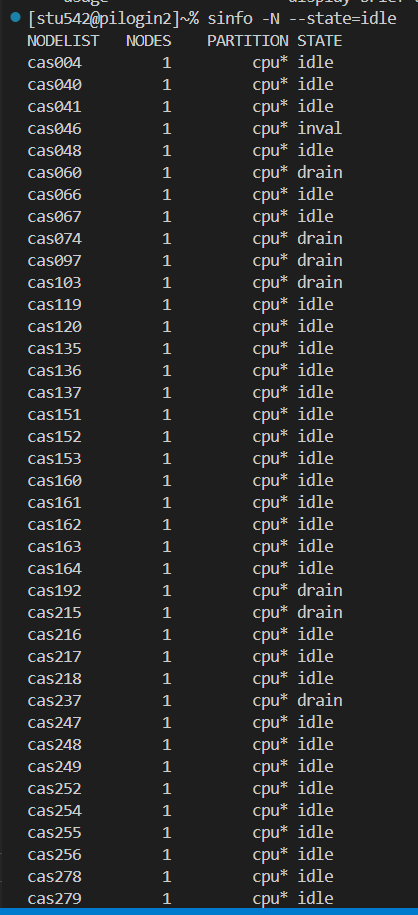
可以看到cpu隊列中很多節點都是空閑的

當前cpu隊列中有124個節點都是空閑的
當然可以實時查看
(2)squeue:
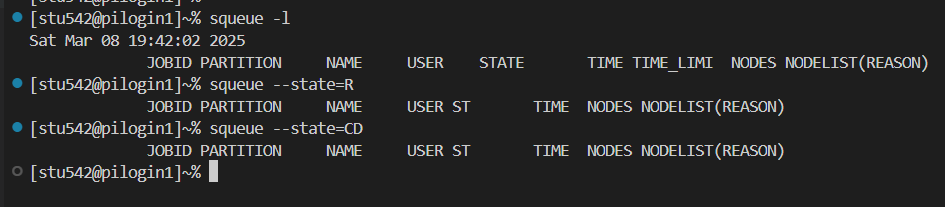
查看作業排隊情況,
比如說下面的sleep的c程序,
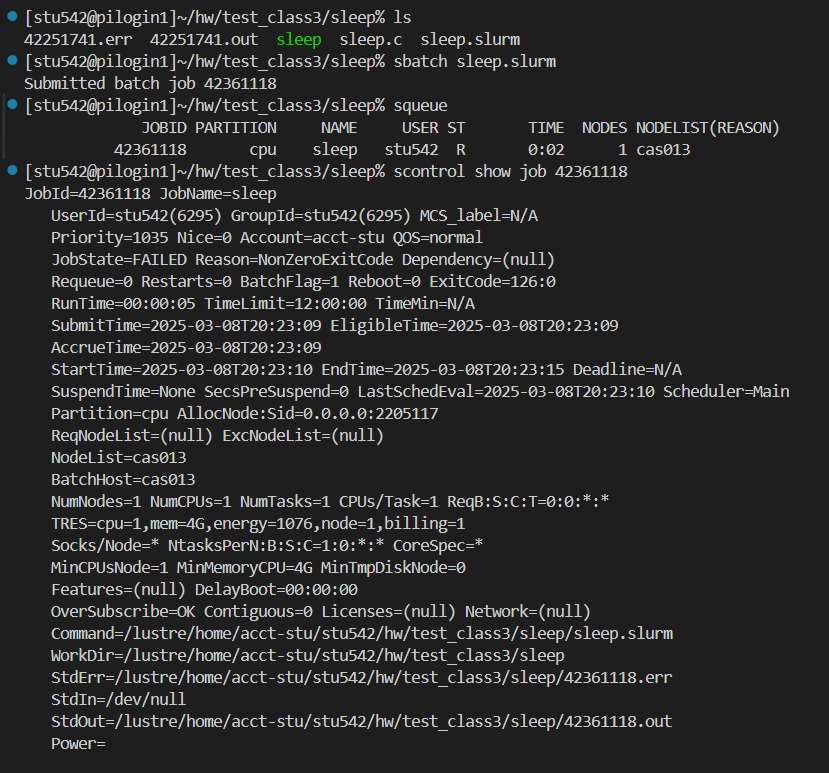
我們就可以看到作業狀態是在運行


然后不一會就failed
(3)scontrol:
查看作業提交詳細情況;
比如說下面提交的一個hello world的c程序,
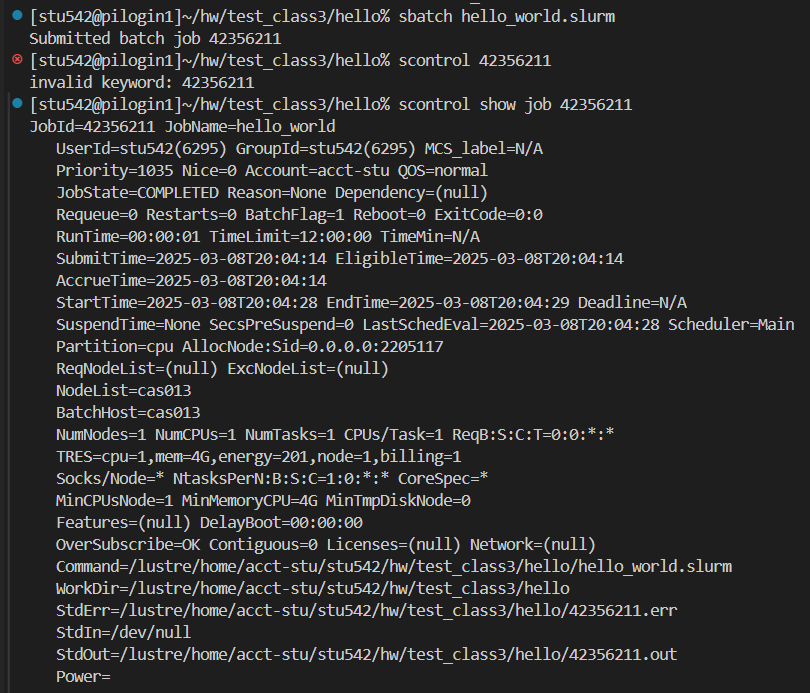
(4)sacct:
查看作業記錄,其實也是看不到細節的;
所以說sacct和squeue都是只能查看任務的排隊情況,或者說是作業的提交情況,至于詳細的細節,都需要使用scontrol命令中去查看;
如果不加命令的話,sacct只能查看當天中所有的運行記錄;
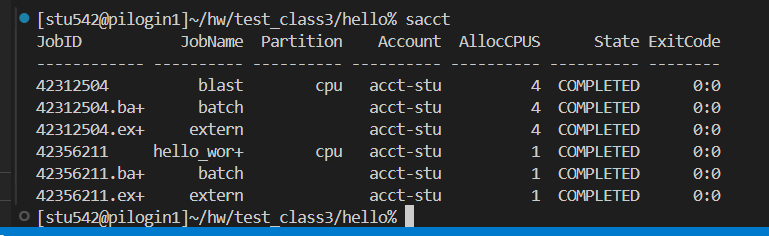
比如說上面運行的hello world的程序就是完成了的
如果需要查看所有的運行記錄的話,需要指定參數
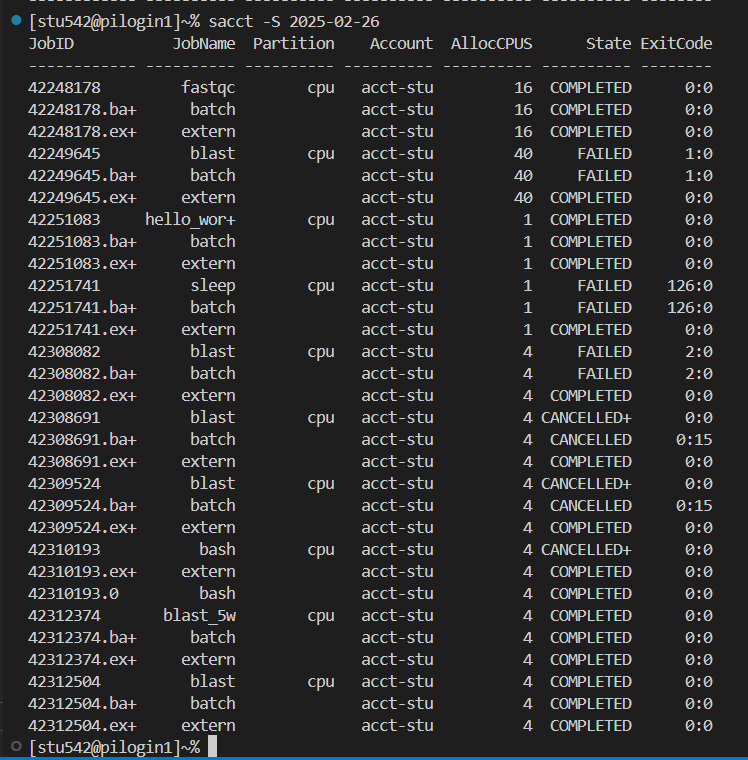
比如說上面就是我從上周3開始執行的示例任務,有很多是完成了,部分是fail了,還有被取消的
(5)scancel:
取消作業提交,尤其是在超算收費情況下,對于不需要或者說是fail的任務job,有必要及時cancel也就是kill
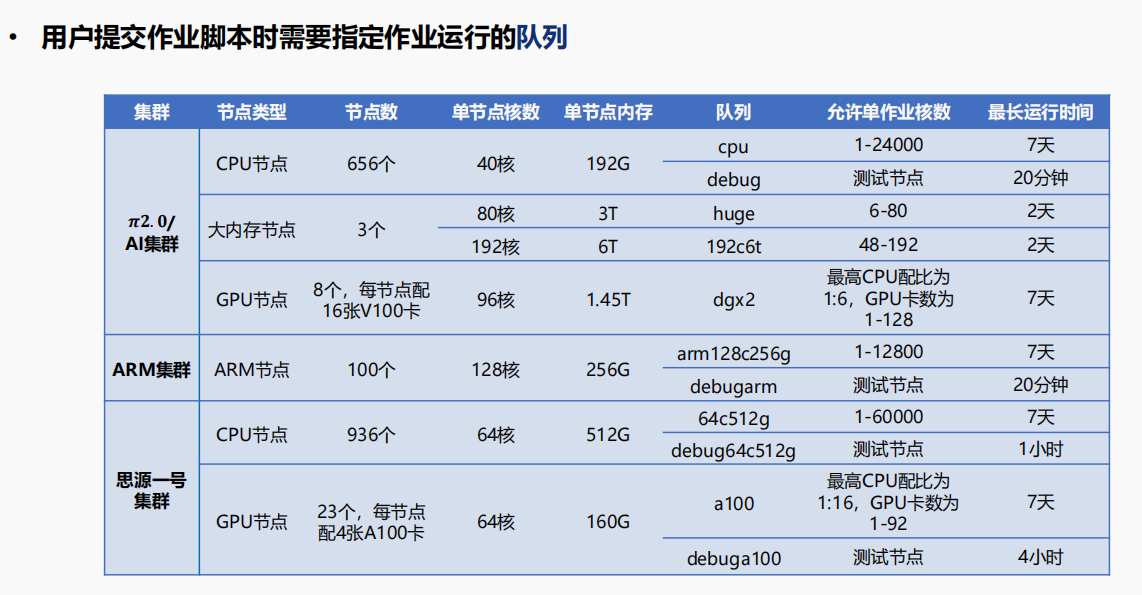
然后至于每個隊列也就是帶有不同資源的這些食堂窗口,提供不同的食品;
我們常用的是在pi2.0集群上的cpu隊列,如果要用gpu,則是dgx2隊列。
然后就是我們最關心的了:
sluram腳本的細節

其實就是前面“#”細節的差異,其余都和shell腳本沒有區別
1核就是最小1個cpu的核心、最小單位。
注意:“%j”就是作業號的意義!!!
**示例:
**

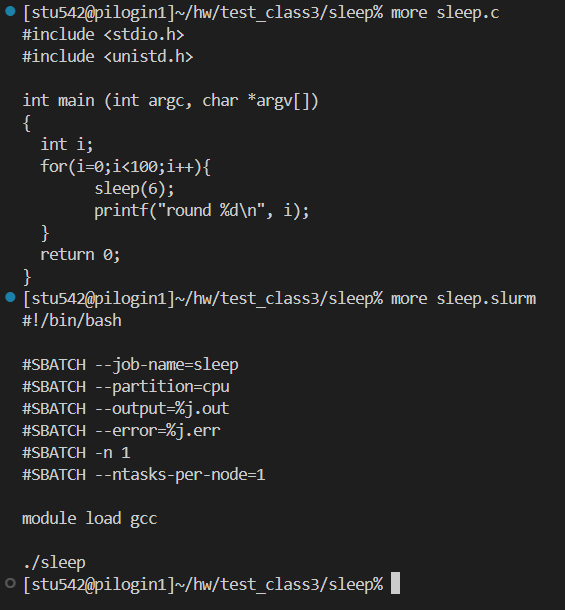
——》
當然,除了我們上面寫出來的,需要在slurm中提交到后臺計算節點的運行任務;
還有一種作業提交或者說是任務運行方式,需要我們注意

這個其實也很常見,就是排隊申請計算節點資源,申請到了,我們就相當于ssh進入了這個計算節點,然后一切操作就相當于是在前臺操作了,就和個人主機或者說是小型服務器很像了。
需要即時編譯,或者即時修改,即時debug時候操作。
可以參考我的上一篇博客:
https://blog.csdn.net/weixin_62528784/article/details/146118720?spm=1001.2014.3001.5502
在這一篇博客中,我就是使用了srun即時前臺申請了一個計算節點,然后安裝conda軟件seqtk,做了一個簡單的處理,然后稍微復雜一點的任務,我再將處理好之后的數據進行sbatch提交。
6,軟件模塊使用:
超算另外一個比較特殊的地方在于,那些非自己編譯的軟件、非本地軟件,常規方法是無法獲取的;
基本上需要你在執行某個任務的環境中去加載,module load,然后然后就相當于在你load的那個環境中將該程序添加到環境變量當中了,然后你就可以使用該軟件了。
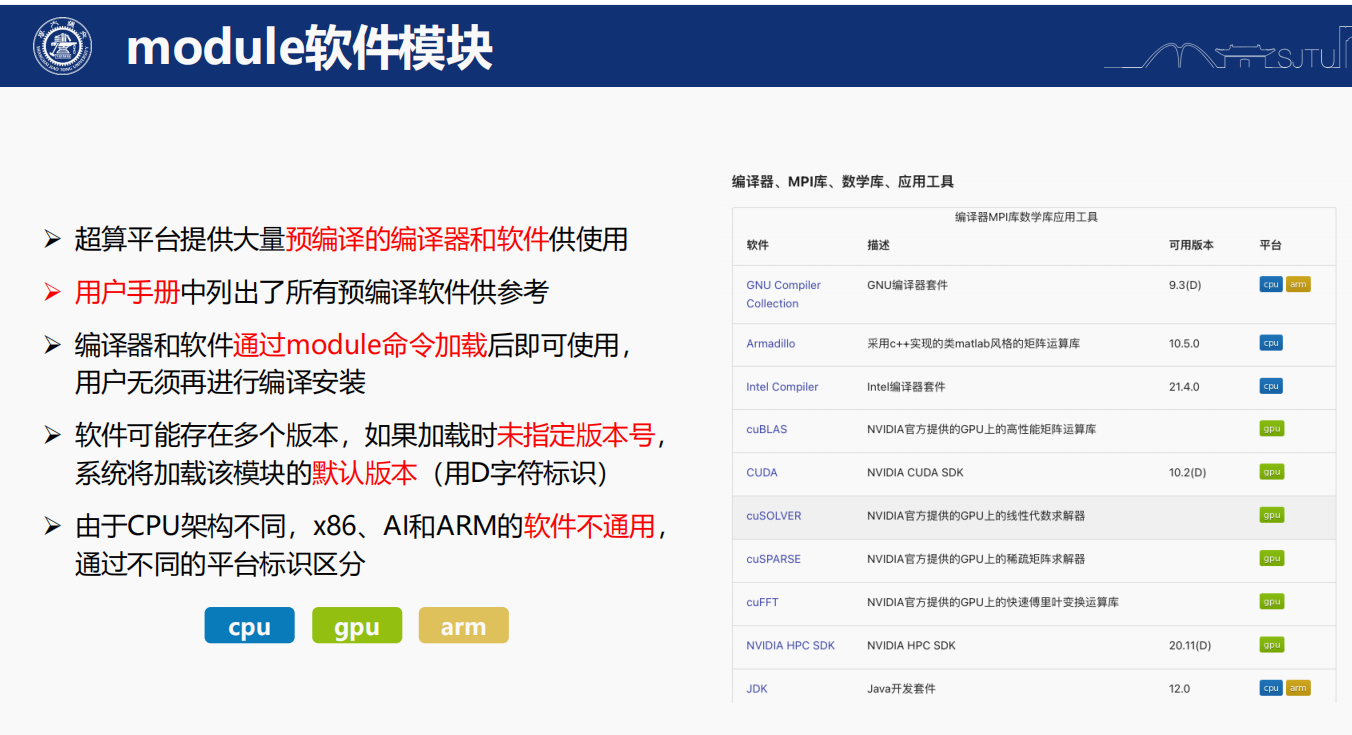
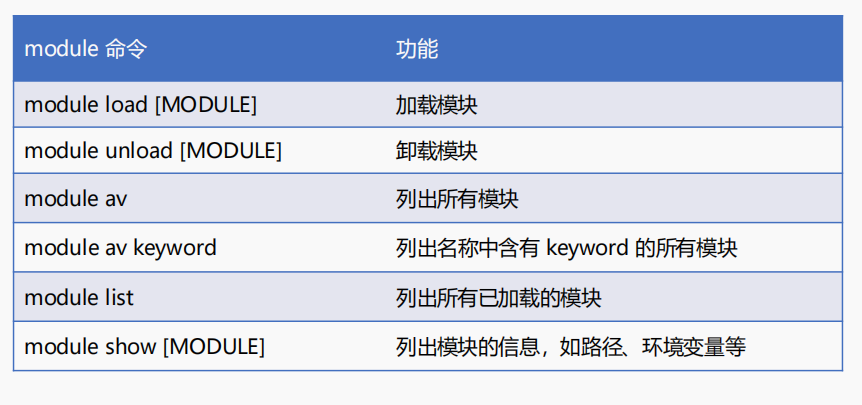
我們以加載g++(c語言的編譯器)的演示來做示例:
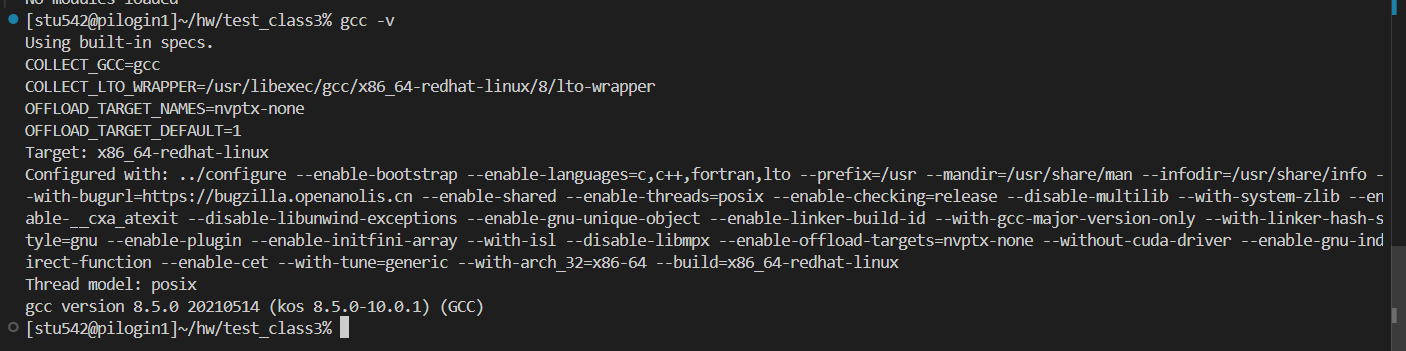
首先當前環境中無任何模塊加載:

然后這是當前的gcc版本,也就是登入節點中默認的版本,v8.5.0
我們可以先查看一下可用的gcc版本(注意是gcc/去搜索,否則會搜到很多也是gcc編譯但不是我們想要的軟件)
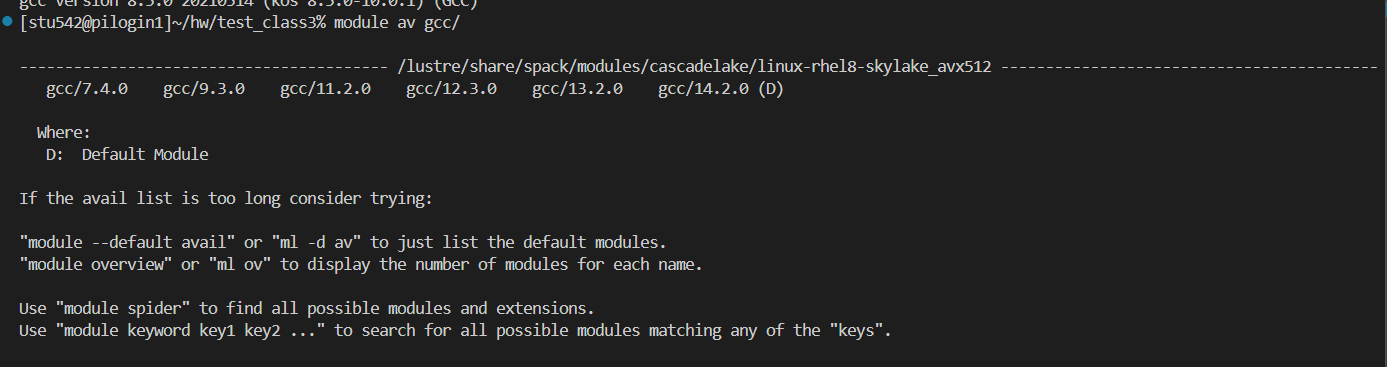
然后D就是默認版本,比如說我們module load gcc,然后沒有指定版本的話,那么加載的就是這個默認版本;
但是如果我們想要加載特定版本的gcc,
我們就需要指定版本參數,比如說我們想要加載11.2.0這個版本
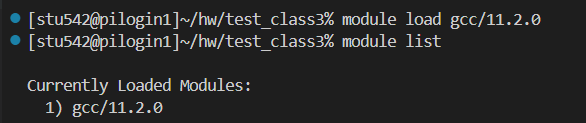
可以發現這個模塊被加載了
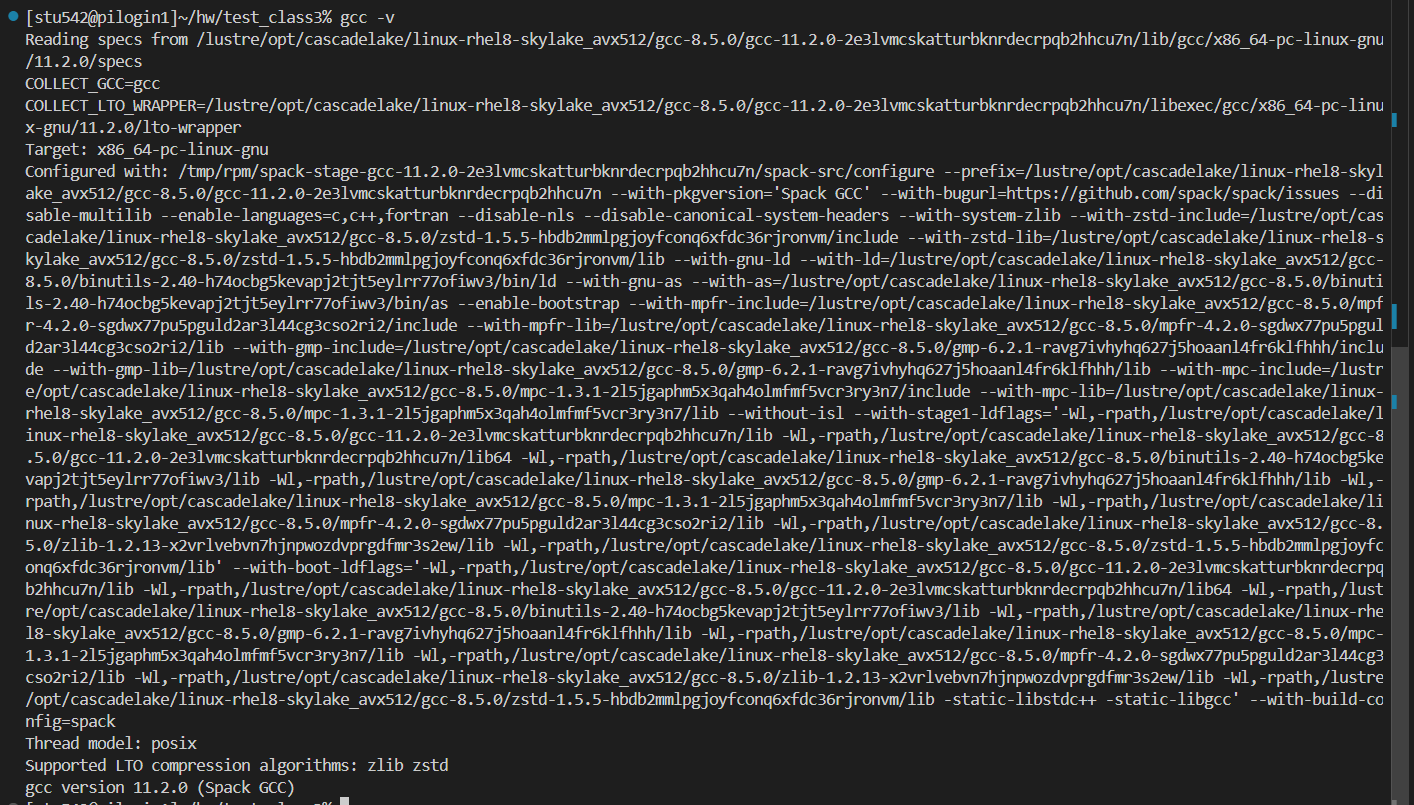
然后版本也確實對應變了;
我們可以接著卸載這個模塊,可以發現一切都變回來了: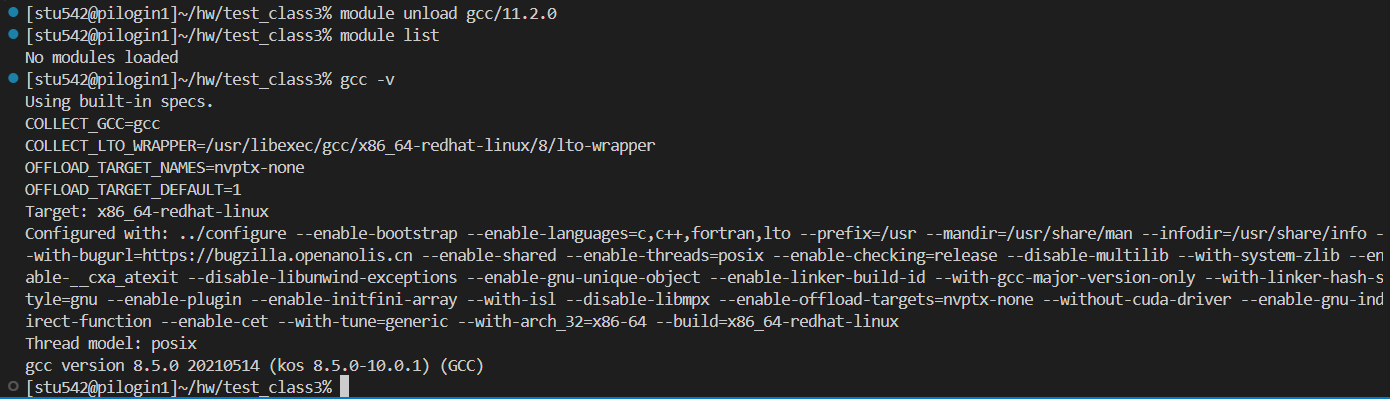

二,slurm作業調度系統詳解
Slurm(Simple Linux Utility for Resource Management)是一個常用的作業調度系統,已被全世界的國家超級計算機中心廣泛采用,它可以管理計算集群上的資源,并調度和執行作業(例如腳本或分析任務),幫助用戶高效地在多個計算節點上運行任務。
我們需要知道的是:1臺計算機就是1個節點(1個cpu節點,對應著1個臺電腦;1個gpu節點,1張gpu卡)
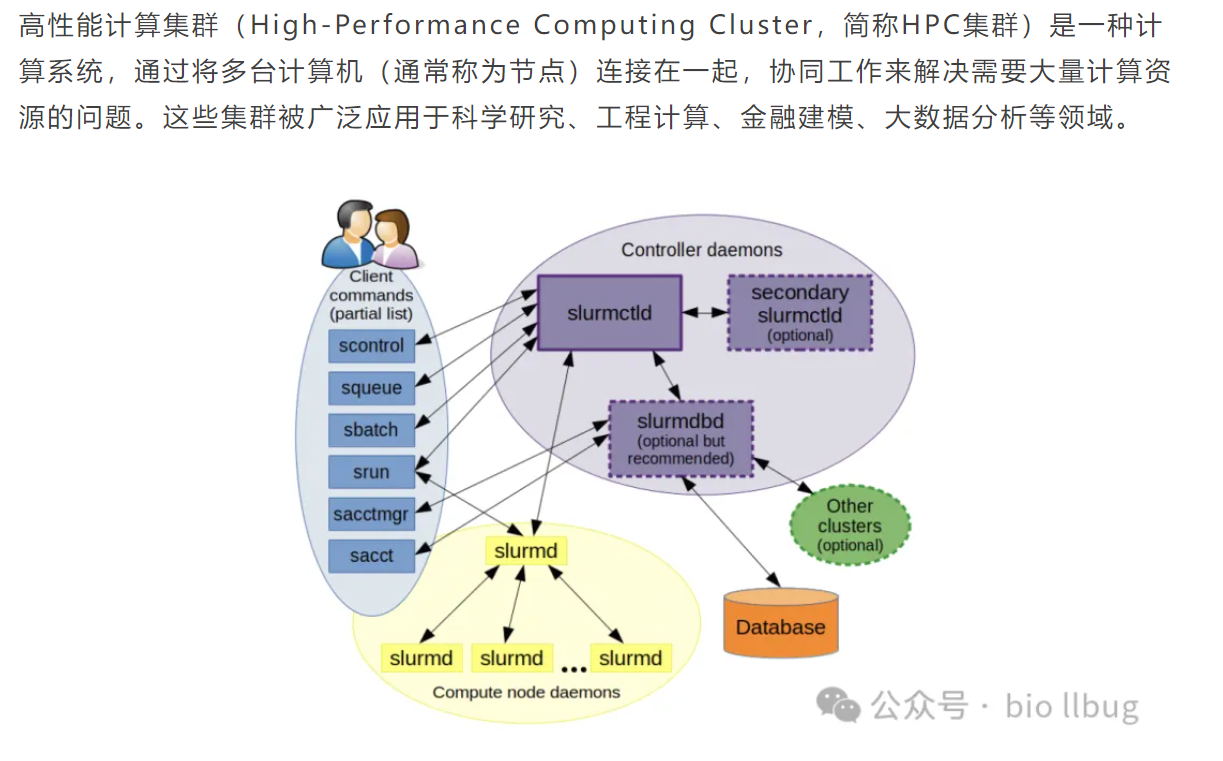


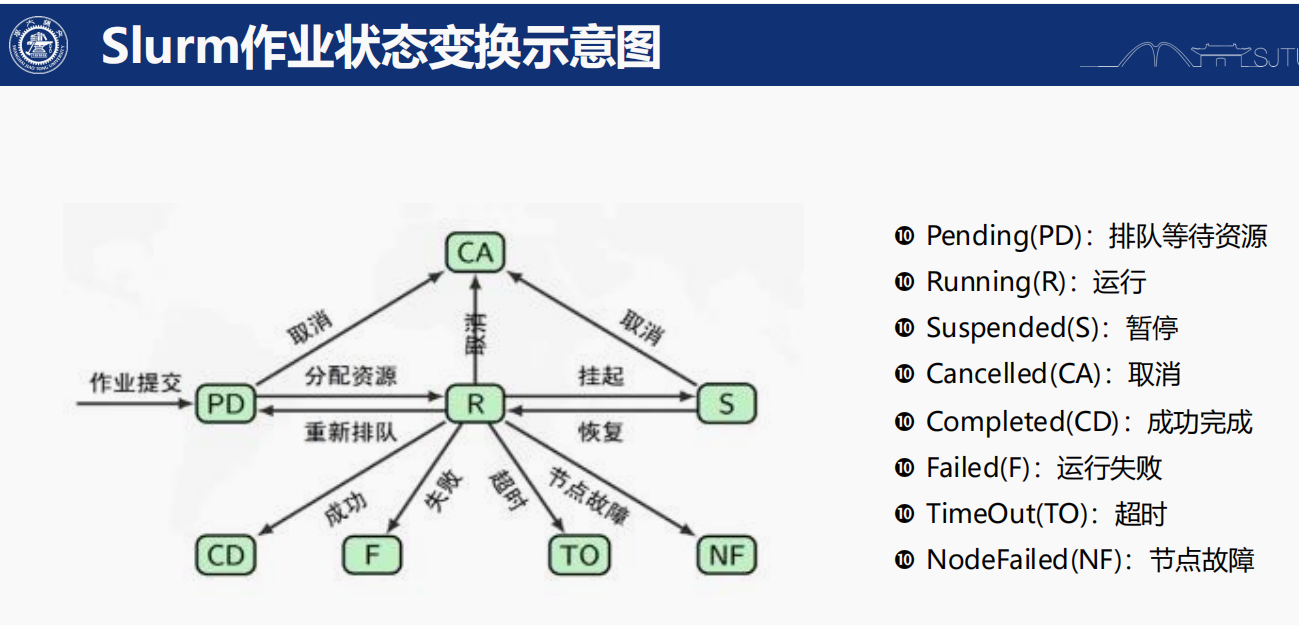
Slurm 的基本概念
作業 (Job): 用戶提交給集群去執行的任務,例如運行一個腳本。
- 節點 (Node): 集群中的一臺計算機,負責執行作業。
- 登錄節點 (Login Node): 用戶通過 SSH 進入集群后最初登錄的節點。它用于準備作業、編寫腳本和提交作業,但不是作業執行的地方。
- 分配節點 (Allocated Node): 當你提交作業并成功分配資源時,作業將在這些節點上運行,它們由 Slurm 根據你的資源需求來選擇。
- 分區 (Partition): 一組節點的集合(也可以叫做“隊列”),不同分區可能有不同的資源配置或策略。
- 調度器 (Scheduler): Slurm 根據資源可用性和作業的優先級,決定作業何時、在哪些節點上執行。
基本工作流程
- 提交作業: 用戶通過
sbatch命令提交編寫好的作業腳本,描述作業的資源需求(如節點數、CPU數、內存等)和執行命令,或者使用srun運行交互式作業。 - 資源分配:Slurm的調度器根據當前的資源可用情況和作業隊列中的優先級,分配資源給新提交的作業。
- 監控作業: 使用
squeue查看作業的狀態(例如,正在運行或等待中)。 - 作業輸出: 作業完成后,輸出通常會保存在用戶指定的文件中。

Slurm 概覽
| Slurm | 功能 |
|---|---|
| sinfo | 集群狀態 |
| srun | 啟動交互式作業 |
| squeue | 排隊作業狀態,當前作業狀態監控 |
| sbatch | 作業/腳本提交 |
| scontrol | 查看和修改作業參數 |
| sacct | 顯示用戶的作業歷史,默認情況下,sacct顯示過去 24小時 的賬號作業信息。 |
| scancel | 刪除作業 |
| sreport | 生成使用報告 |
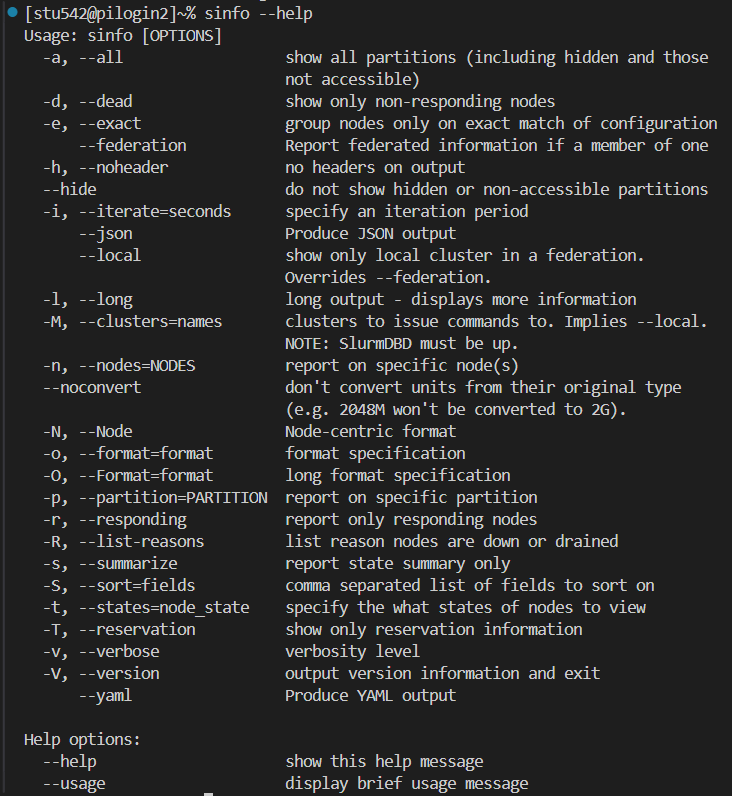
sinfo 查看集群狀態和信息
| Slurm | 功能 |
|---|---|
| sinfo -s | 簡要格式輸出 |
| sinfo -N | 查看節點級信息 |
| sinfo -N --states=idle | 查看可用節點信息 |
| sinfo --partition=cpu | 查看隊列信息 |
| sinfo --help | 查看所有選項 |
輸出字段:
- PARTITION: 分區名稱
- AVAIL: 節點可用性狀態(up/down)
- TIMELIMIT: 分區的時間限制
- NODES: 分區中的節點數量
- STATE: 節點狀態:
drain(節點故障),alloc(節點在用),idle(節點可用),down(節點下線),mix(節點被占用,但仍有剩余資源) - NODELIST: 節點名稱列表
查看總體資源信息:
sinfo
#PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
#cpu up 7-00:00:0 656 idle cas[001-656]
#dgx2 up 7-00:00:0 8 idle vol[01-08]
查看某個特定節點的信息:
sinfo -n <節點名稱>
sacct顯示用戶作業歷史
- 用途: 查詢作業歷史記錄,顯示已完成和正在進行的作業信息,默認情況下,sacct顯示過去 24小時 的賬號作業信息。
- 參數:
-j <jobid>查詢特定作業-S <YYYY-MM-DD>查詢指定開始日期的作業-u <username>查詢特定用戶的作業
- 輸出字段:
- JobID: 作業ID
- JobName: 作業名稱
- Partition: 分區名稱
- Account: 用戶賬戶
- State: 作業狀態(COMPLETED、FAILED、CANCELLED等)
- Elapsed: 作業運行時間
squeue 查看作業信息
| Slurm | 功能 |
|---|---|
| squeue -j <作業的jobid> | 查看作業信息 |
| squeue -l | 查看細節信息 |
| squeue --nodelist=<節點名稱> | 查看特定節點作業信息 |
| squeue | 查看USER_LIST的作業 |
| squeue --state=R | 查看特定狀態的作業 |
| squeue --help | 查看所有的選項 |
輸出字段:
- JOBID: 作業ID
- PARTITION: 分區名稱
- NAME: 作業名稱
- USER: 用戶名
- ST: 作業狀態包括
R(正在運行),PD(正在排隊),CG(即將完成),CD(已完成) - TIME: 作業運行時間
- NODES: 作業使用的節點數量
- NODELIST(REASON): 作業所在節點或排隊原因
默認情況下,squeue只會展示在排隊或在運行的作業。
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
18046 dgx2 ZXLing eenl R 1:35:53 1 vol04
17796 dgx2 python eexdl R 3-00:22:04 1 vol02
顯示您自己賬戶下的作業:
squeue -u <用戶名>
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
17923 dgx2 bash hpcwj R 1-12:59:05 1 vol05
-l選項可以顯示更細節的信息。
squeue -u <用戶名> -l
JOBID PARTITION NAME USER STATE TIME TIME_LIMI NODES NODELIST(REASON)
17923 dgx2 bash hpcwj RUNNING 1-13:00:53 30-00:00:00 1 vol05
srun 啟動交互式作業
srun --partition=<分區> --nodes=<節點數> --ntasks=<任務數> --t=<時長> --mem=<內存> --c=<調用的CPU數量> --pty bash
運行此命令后,你會獲得一個交互式的 shell,能夠在該節點上直接執行命令。但是srun的缺點是一旦斷線就無法重新連接回去,因此推薦使用Linux終端復用神器tmux/screen+srun配合運行
sbatch作業提交
準備作業腳本然后通過sbatch提交是 Slurm 的最常見用法。為了將作業腳本提交給作業系統,Slurm 使用
sbatch my_job_script.sh
Slurm 具有豐富的參數集。以下最常用的。
| Slurm | 含義 |
|---|---|
-n [count] | 總進程數 |
--ntasks-per-node=[count] | 每臺節點上的進程數 |
-p [partition] | 作業隊列 |
--job-name=[name] | 作業名 |
--output=[file_name] | 標準輸出文件 |
--error=[file_name] | 標準錯誤文件 |
--time=[dd-hh:mm:ss] | 作業最大運行時長 |
--exclusive | 獨占節點 |
--mail-type=[type] | 通知類型,可選 all, fail, end,分別對應全通知、故障通知、結束通知 |
--mail-user=[mail_address] | 通知郵箱 |
--nodelist=[nodes] | 偏好的作業節點 |
--exclude=[nodes] | 避免的作業節點 |
--depend=[state:job_id] | 作業依賴 |
--array=[array_spec] | 序列作業 |
這是一個名為cpu.slurm的作業腳本,該腳本向cpu隊列申請1個節點40核,并在作業完成時通知。在此作業中執行的命令是/bin/hostname。
#SBATCH --job-name作業名稱#SBATCH --output標準輸出文件:如/share/home/pengchen/work/%x_%A_%a.out#SBATCH --errorERROR輸出文件:如/share/home/pengchen/work/%x_%A_%a.err#SBATCH --partition工作分區,我們用cpu之類的#SBATCH --nodelist可以制定在哪個節點運行任務#SBATCH --exclude可以設置不放在某個節點跑任務#SBATCH --nodes使用nodes數量#SBATCH --ntaskstasks數量,可能分配給不同node#SBATCH --ntasks-per-node每個節點的tasks數量,由于我們只有1 node,所以ntasks和ntasks-per-node是相同的#SBATCH --cpus-per-task每個task使用的core的數量(默認 1 core per task),同一個task會在同一個node#SBATCH --mem這個作業要求的內存 (Specified in MB,GB)#SBATCH --mem-per-cpu每個core要求的內存 (Specified in MB,GB)
#!/bin/bash#SBATCH --job-name=hostname
#SBATCH --partition=cpu
#SBATCH -N 1
#SBATCH --mail-type=end
#SBATCH --mail-user=YOU@EMAIL.COM
#SBATCH --output=%j.out
#SBATCH --error=%j.err/bin/hostname
用以下方式提交作業:
sbatch cpu.slurm
squeue可用于檢查作業狀態。用戶可以在作業執行期間通過SSH登錄到計算節點。輸出將實時更新到文件[jobid] .out和[jobid] .err。
這里展示一個更復雜的作業要求,其中將啟動80個進程,每臺主機40個進程。
#!/bin/bash#SBATCH --job-name=LINPACK
#SBATCH --partition=cpu
#SBATCH -n 80
#SBATCH --ntasks-per-node=40
#SBATCH --mail-type=end
#SBATCH --mail-user=YOU@EMAIL.COM
#SBATCH --output=%j.out
#SBATCH --error=%j.err
以下作業請求4張GPU卡,其中1個CPU進程管理1張GPU卡。
#!/bin/bash#SBATCH --job-name=GPU_HPL
#SBATCH --partition=dgx2
#SBATCH -n 4
#SBATCH --ntasks-per-node=4
#SBATCH --gres=gpu:4
#SBATCH --mail-type=end
#SBATCH --mail-user=YOU@MAIL.COM
#SBATCH --output=%j.out
#SBATCH --error=%j.err
以下作業啟動一個3任務序列(從0到2),每個任務需要1個CPU內核。
#!/bin/bash#SBATCH --job-name=python_array
#SBATCH --mail-user=YOU@MAIL.COM
#SBATCH --mail-type=ALL
#SBATCH --ntasks=1
#SBATCH --time=00:30:00
#SBATCH --array=0-2
#SBATCH --output=python_array_%A_%a.out
#SBATCH --output=python_array_%A_%a.errmodule load miniconda2/4.6.14-gcc-4.8.5source activate YOUR_ENV_NAMEecho "SLURM_JOBID: " $SLURM_JOBID
echo "SLURM_ARRAY_TASK_ID: " $SLURM_ARRAY_TASK_ID
echo "SLURM_ARRAY_JOB_ID: " $SLURM_ARRAY_JOB_IDpython < vec_${SLURM_ARRAY_TASK_ID}.py
在提交到SLURM的作業腳本中,可以激活Conda環境以確保作業在正確的軟件環境中運行。以下是一個示例SLURM作業腳本:
#!/bin/bash
#SBATCH --job-name=myjob # 作業名稱
#SBATCH --output=myjob.out # 標準輸出和錯誤日志
#SBATCH --error=myjob.err # 錯誤日志文件
#SBATCH --ntasks=1 # 運行的任務數
#SBATCH --time=01:00:00 # 運行時間
#SBATCH --partition=compute # 作業提交的分區# 加載Conda
source ~/miniconda3/etc/profile.d/conda.sh# 激活環境
conda activate myenv# 運行命令
python my_script.py
scancel取消指定作業
- 用途: 取消一個或多個作業。
- 示例:
scancel 12345
- 參數:
-u <username>取消特定用戶的所有作業-p <partition>取消特定分區中的作業
Slurm環境變量
| Slurm | 功能 |
|---|---|
| $SLURM_JOB_ID | 作業ID |
| $SLURM_JOB_NAME | 作業名 |
| $SLURM_JOB_PARTITION | 隊列的名稱 |
| $SLURM_NTASKS | 進程總數 |
| $SLURM_NTASKS_PER_NODE | 每個節點請求的任務數 |
| $SLURM_JOB_NUM_NODES | 節點數 |
| $SLURM_JOB_NODELIST | 節點列表 |
| $SLURM_LOCALID | 作業中流程的節點本地任務ID |
| $SLURM_ARRAY_TASK_ID | 作業序列中的任務ID |
| $SLURM_SUBMIT_DIR | 工作目錄 |
| $SLURM_SUBMIT_HOST | 提交作業的主機名 |
參考:
https://docs.hpc.sjtu.edu.cn/index.html
https://mp.weixin.qq.com/s/sTTCokxsYFaffdt2aZyoDw
https://mp.weixin.qq.com/s/BpbRL958AugB_dcYfYaXEg






)





)

)




