Java并發基礎知識補全
啟動
啟動線程的方式只有:
1、X extends Thread;,然后X.start
2、X implements ?Runnable;然后交給Thread運行
線程的狀態
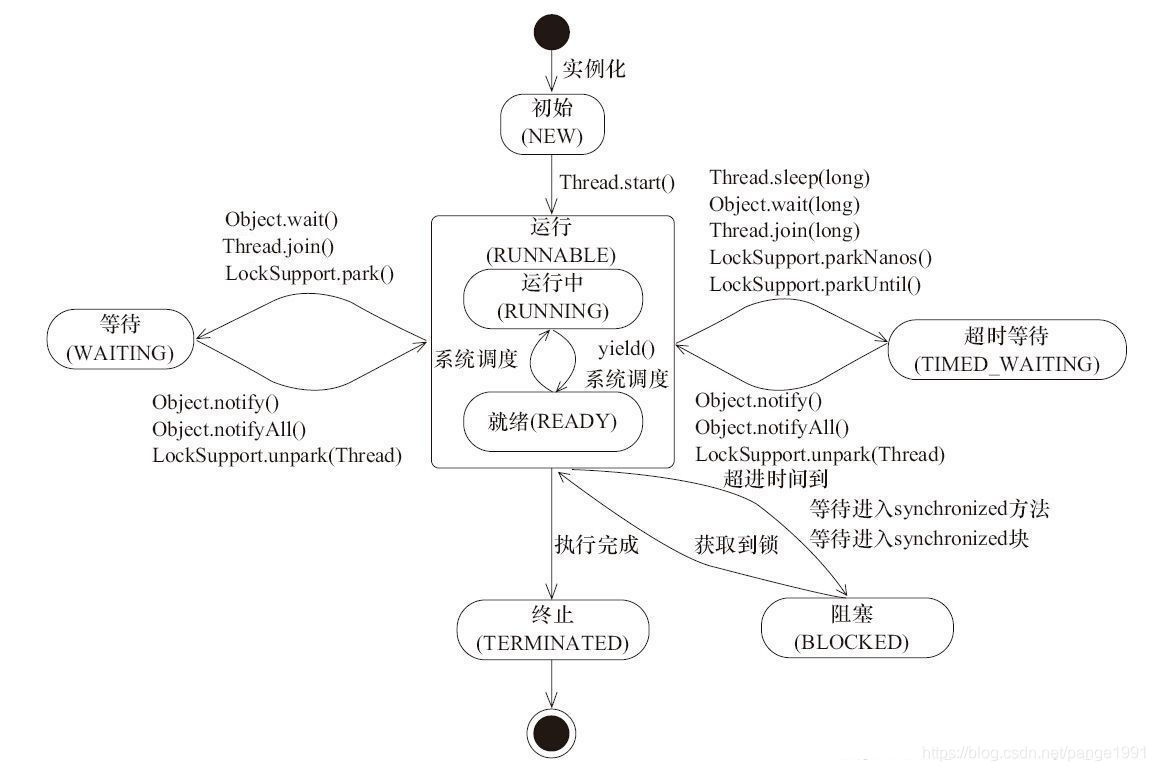
Java中線程的狀態分為6種:
1. 初始(NEW):新創建了一個線程對象,但還沒有調用start()方法。
2. 運行(RUNNABLE):Java線程中將就緒(ready)和運行中(running)兩種狀態籠統的稱為“運行”。
線程對象創建后,其他線程(比如main線程)調用了該對象的start()方法。該狀態的線程位于可運行線程池中,等待被線程調度選中,獲取CPU的使用權,此時處于就緒狀態(ready)。就緒狀態的線程在獲得CPU時間片后變為運行中狀態(running)。
3.?阻塞(BLOCKED):表示線程阻塞于鎖。
4.?等待(WAITING):進入該狀態的線程需要等待其他線程做出一些特定動作(通知或中斷)。1
5.?超時等待(TIMED_WAITING):該狀態不同于WAITING,它可以在指定的時間后自行返回。
6. 終止(TERMINATED):表示該線程已經執行完畢。
狀態之間的變遷如下圖所示

死鎖
概念
是指兩個或兩個以上的進程在執行過程中,由于競爭資源或者由于彼此通信而造成的一種阻塞的現象,若無外力作用,它們都將無法推進下去。此時稱系統處于死鎖狀態或系統產生了死鎖。
舉個例子:A和B去按摩洗腳,都想在洗腳的時候,同時順便做個頭部按摩,13技師擅長足底按摩,14擅長頭部按摩。
這個時候A先搶到14,B先搶到13,兩個人都想同時洗腳和頭部按摩,于是就互不相讓,揚言我死也不讓你,這樣的話,A搶到14,想要13,B搶到13,想要14,在這個想同時洗腳和頭部按摩的事情上A和B就產生了死鎖。怎么解決這個問題呢?
第一種,假如這個時候,來了個15,剛好也是擅長頭部按摩的,A又沒有兩個腦袋,自然就歸了B,于是B就美滋滋的洗腳和做頭部按摩,剩下A在旁邊氣鼓鼓的,這個時候死鎖這種情況就被打破了,不存在了。
第二種,C出場了,用武力強迫A和B,必須先做洗腳,再頭部按摩,這種情況下,A和B誰先搶到13,誰就可以進行下去,另外一個沒搶到的,就等著,這種情況下,也不會產生死鎖。
所以總結一下:
死鎖是必然發生在多操作者(M>=2個)情況下,爭奪多個資源(N>=2個,且N<=M)才會發生這種情況。很明顯,單線程自然不會有死鎖,只有B一個去,不要2個,打十個都沒問題;單資源呢?只有13,A和B也只會產生激烈競爭,打得不可開交,誰搶到就是誰的,但不會產生死鎖。同時,死鎖還有幾個要求,1、爭奪資源的順序不對,如果爭奪資源的順序是一樣的,也不會產生死鎖;
2、爭奪者拿到資源不放手。
學術化的定義
死鎖的發生必須具備以下四個必要條件。
1)互斥條件:指進程對所分配到的資源進行排它性使用,即在一段時間內某資源只由一個進程占用。如果此時還有其它進程請求資源,則請求者只能等待,直至占有資源的進程用畢釋放。
2)請求和保持條件:指進程已經保持至少一個資源,但又提出了新的資源請求,而該資源已被其它進程占有,此時請求進程阻塞,但又對自己已獲得的其它資源保持不放。
3)不剝奪條件:指進程已獲得的資源,在未使用完之前,不能被剝奪,只能在使用完時由自己釋放。
4)環路等待條件:指在發生死鎖時,必然存在一個進程——資源的環形鏈,即進程集合{P0,P1,P2,···,Pn}中的P0正在等待一個P1占用的資源;P1正在等待P2占用的資源,……,Pn正在等待已被P0占用的資源。
理解了死鎖的原因,尤其是產生死鎖的四個必要條件,就可以最大可能地避免、預防和解除死鎖。
只要打破四個必要條件之一就能有效預防死鎖的發生。
打破互斥條件:改造獨占性資源為虛擬資源,大部分資源已無法改造。
打破不可搶占條件:當一進程占有一獨占性資源后又申請一獨占性資源而無法滿足,則退出原占有的資源。
打破占有且申請條件:采用資源預先分配策略,即進程運行前申請全部資源,滿足則運行,不然就等待,這樣就不會占有且申請。
打破循環等待條件:實現資源有序分配策略,對所有設備實現分類編號,所有進程只能采用按序號遞增的形式申請資源。
避免死鎖常見的算法有有序資源分配法、銀行家算法。
危害
1、線程不工作了,但是整個程序還是活著的2、沒有任何的異常信息可以供我們檢查。3、一旦程序發生了發生了死鎖,是沒有任何的辦法恢復的,只能重啟程序,對正式已發布程序來說,這是個很嚴重的問題。
解決
關鍵是保證拿鎖的順序一致
兩種解決方式
-
- 內部通過順序比較,確定拿鎖的順序;
2、采用嘗試拿鎖的機制。
其他線程安全問題
活鎖
兩個線程在嘗試拿鎖的機制中,發生多個線程之間互相謙讓,不斷發生同一個線程總是拿到同一把鎖,在嘗試拿另一把鎖時因為拿不到,而將本來已經持有的鎖釋放的過程。
解決辦法:每個線程休眠隨機數,錯開拿鎖的時間。
線程饑餓
低優先級的線程,總是拿不到執行時間
ThreadLocal辨析
與Synchonized的比較
ThreadLocal和Synchonized都用于解決多線程并發訪問。可是ThreadLocal與synchronized有本質的差別。synchronized是利用鎖的機制,使變量或代碼塊在某一時該僅僅能被一個線程訪問。而ThreadLocal為每個線程都提供了變量的副本,使得每個線程在某一時間訪問到的并非同一個對象,這樣就隔離了多個線程對數據的數據共享。
ThreadLocal的使用
ThreadLocal類接口很簡單,只有4個方法,我們先來了解一下:
? void set(Object value)
設置當前線程的線程局部變量的值。
? public Object get()
該方法返回當前線程所對應的線程局部變量。
? public void remove()
將當前線程局部變量的值刪除,目的是為了減少內存的占用,該方法是JDK 5.0新增的方法。需要指出的是,當線程結束后,對應該線程的局部變量將自動被垃圾回收,所以顯式調用該方法清除線程的局部變量并不是必須的操作,但它可以加快內存回收的速度。
? protected Object initialValue()
返回該線程局部變量的初始值,該方法是一個protected的方法,顯然是為了讓子類覆蓋而設計的。這個方法是一個延遲調用方法,在線程第1次調用get()或set(Object)時才執行,并且僅執行1次。ThreadLocal中的缺省實現直接返回一個null。
public final static ThreadLocal<String> RESOURCE = new ThreadLocal<String>();RESOURCE代表一個能夠存放String類型的ThreadLocal對象。此時不論什么一個線程能夠并發訪問這個變量,對它進行寫入、讀取操作,都是線程安全的。
實現解析
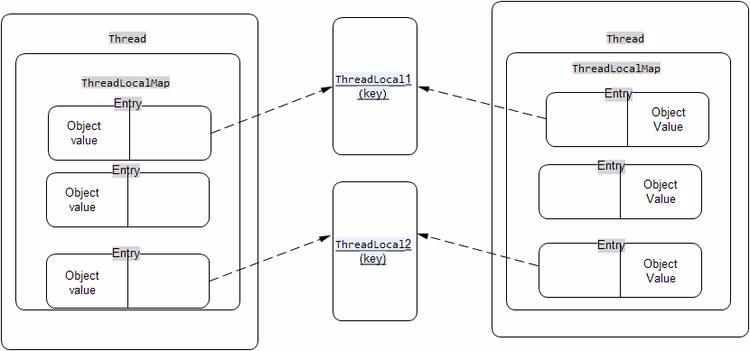




上面先取到當前線程,然后調用getMap方法獲取對應的ThreadLocalMap,ThreadLocalMap是ThreadLocal的靜態內部類,然后Thread類中有一個這樣類型成員,所以getMap是直接返回Thread的成員。
看下ThreadLocal的內部類ThreadLocalMap源碼:

可以看到有個Entry內部靜態類,它繼承了WeakReference,總之它記錄了兩個信息,一個是ThreadLocal<?>類型,一個是Object類型的值。getEntry方法則是獲取某個ThreadLocal對應的值,set方法就是更新或賦值相應的ThreadLocal對應的值。


回顧我們的get方法,其實就是拿到每個線程獨有的ThreadLocalMap
然后再用ThreadLocal的當前實例,拿到Map中的相應的Entry,然后就可以拿到相應的值返回出去。當然,如果Map為空,還會先進行map的創建,初始化等工作。
CAS基本原理
什么是原子操作?如何實現原子操作?
假定有兩個操作A和B(A和B可能都很復雜),如果從執行A的線程來看,當另一個線程執行B時,要么將B全部執行完,要么完全不執行B,那么A和B對彼此來說是原子的。
實現原子操作可以使用鎖,鎖機制,滿足基本的需求是沒有問題的了,但是有的時候我們的需求并非這么簡單,我們需要更有效,更加靈活的機制,synchronized關鍵字是基于阻塞的鎖機制,也就是說當一個線程擁有鎖的時候,訪問同一資源的其它線程需要等待,直到該線程釋放鎖,
這里會有些問題:首先,如果被阻塞的線程優先級很高很重要怎么辦?其次,如果獲得鎖的線程一直不釋放鎖怎么辦?(這種情況是非常糟糕的)。還有一種情況,如果有大量的線程來競爭資源,那CPU將會花費大量的時間和資源來處理這些競爭,同時,還有可能出現一些例如死鎖之類的情況,最后,其實鎖機制是一種比較粗糙,粒度比較大的機制,相對于像計數器這樣的需求有點兒過于笨重。
實現原子操作還可以使用當前的處理器基本都支持CAS()的指令,只不過每個廠家所實現的算法并不一樣,每一個CAS操作過程都包含三個運算符:一個內存地址V,一個期望的值A和一個新值B,操作的時候如果這個地址上存放的值等于這個期望的值A,則將地址上的值賦為新值B,否則不做任何操作。
CAS的基本思路就是,如果這個地址上的值和期望的值相等,則給其賦予新值,否則不做任何事兒,但是要返回原值是多少。循環CAS就是在一個循環里不斷的做cas操作,直到成功為止。

CAS實現原子操作的三大問題
ABA問題。
因為CAS需要在操作值的時候,檢查值有沒有發生變化,如果沒有發生變化則更新,但是如果一個值原來是A,變成了B,又變成了A,那么使用CAS進行檢查時會發現它的值沒有發生變化,但是實際上卻變化了。
ABA問題的解決思路就是使用版本號。在變量前面追加上版本號,每次變量更新的時候把版本號加1,那么A→B→A就會變成1A→2B→3A。舉個通俗點的例子,你倒了一杯水放桌子上,干了點別的事,然后同事把你水喝了又給你重新倒了一杯水,你回來看水還在,拿起來就喝,如果你不管水中間被人喝過,只關心水還在,這就是ABA問題。
如果你是一個講衛生講文明的小伙子,不但關心水在不在,還要在你離開的時候水被人動過沒有,因為你是程序員,所以就想起了放了張紙在旁邊,寫上初始值0,別人喝水前麻煩先做個累加才能喝水。
循環時間長開銷大。
自旋CAS如果長時間不成功,會給CPU帶來非常大的執行開銷。
只能保證一個共享變量的原子操作。
當對一個共享變量執行操作時,我們可以使用循環CAS的方式來保證原子操作,但是對多個共享變量操作時,循環CAS就無法保證操作的原子性,這個時候就可以用鎖。
還有一個取巧的辦法,就是把多個共享變量合并成一個共享變量來操作。比如,有兩個共享變量i=2,j=a,合并一下ij=2a,然后用CAS來操作ij。從Java 1.5開始,JDK提供了AtomicReference類來保證引用對象之間的原子性,就可以把多個變量放在一個對象里來進行CAS操作。
Jdk中相關原子操作類的使用
AtomicInteger
?int addAndGet(int delta):以原子方式將輸入的數值與實例中的值(AtomicInteger里的value)相加,并返回結果。
?boolean compareAndSet(int expect,int update):如果輸入的數值等于預期值,則以原子方式將該值設置為輸入的值。
?int getAndIncrement():以原子方式將當前值加1,注意,這里返回的是自增前的值。
?int getAndSet(int newValue):以原子方式設置為newValue的值,并返回舊值。
AtomicIntegerArray
主要是提供原子的方式更新數組里的整型,其常用方法如下。
?int addAndGet(int i,int delta):以原子方式將輸入值與數組中索引i的元素相加。
?boolean compareAndSet(int i,int expect,int update):如果當前值等于預期值,則以原子方式將數組位置i的元素設置成update值。
需要注意的是,數組value通過構造方法傳遞進去,然后AtomicIntegerArray會將當前數組復制一份,所以當AtomicIntegerArray對內部的數組元素進行修改時,不會影響傳入的數組。
更新引用類型
原子更新基本類型的AtomicInteger,只能更新一個變量,如果要原子更新多個變量,就需要使用這個原子更新引用類型提供的類。Atomic包提供了以下3個類。
AtomicReference
原子更新引用類型。
AtomicStampedReference
利用版本戳的形式記錄了每次改變以后的版本號,這樣的話就不會存在ABA問題了。這就是AtomicStampedReference的解決方案。AtomicMarkableReference跟AtomicStampedReference差不多, AtomicStampedReference是使用pair的int stamp作為計數器使用,AtomicMarkableReference的pair使用的是boolean mark。 還是那個水的例子,AtomicStampedReference可能關心的是動過幾次,AtomicMarkableReference關心的是有沒有被人動過,方法都比較簡單。
AtomicMarkableReference:
原子更新帶有標記位的引用類型。可以原子更新一個布爾類型的標記位和引用類型。構造方法是AtomicMarkableReference(V initialRef,booleaninitialMark)。
阻塞隊列和線程池原理
阻塞隊列
隊列

隊列是一種特殊的線性表,特殊之處在于它只允許在表的前端(front)進行刪除操作,而在表的后端(rear)進行插入操作,和棧一樣,隊列是一種操作受限制的線性表。進行插入操作的端稱為隊尾,進行刪除操作的端稱為隊頭。
在隊列中插入一個隊列元素稱為入隊,從隊列中刪除一個隊列元素稱為出隊。因為隊列只允許在一端插入,在另一端刪除,所以只有最早進入隊列的元素才能最先從隊列中刪除,故隊列又稱為先進先出(FIFO—first in first out)線性表。
什么是阻塞隊列
1)支持阻塞的插入方法:意思是當隊列滿時,隊列會阻塞插入元素的線程,直到隊列不滿。
2)支持阻塞的移除方法:意思是在隊列為空時,獲取元素的線程會等待隊列變為非空。
在并發編程中使用生產者和消費者模式能夠解決絕大多數并發問題。該模式通過平衡生產線程和消費線程的工作能力來提高程序整體處理數據的速度。
在線程世界里,生產者就是生產數據的線程,消費者就是消費數據的線程。在多線程開發中,如果生產者處理速度很快,而消費者處理速度很慢,那么生產者就必須等待消費者處理完,才能繼續生產數據。同樣的道理,如果消費者的處理能力大于生產者,那么消費者就必須等待生產者。
為了解決這種生產消費能力不均衡的問題,便有了生產者和消費者模式。生產者和消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通信,而是通過阻塞隊列來進行通信,所以生產者生產完數據之后不用等待消費者處理,直接扔給阻塞隊列,消費者不找生產者要數據,而是直接從阻塞隊列里取,阻塞隊列就相當于一個緩沖區,平衡了生產者和消費者的處理能力。
阻塞隊列常用于生產者和消費者的場景,生產者是向隊列里添加元素的線程,消費者是從隊列里取元素的線程。阻塞隊列就是生產者用來存放元素、消費者用來獲取元素的容器。

·拋出異常:當隊列滿時,如果再往隊列里插入元素,會拋出IllegalStateException("Queuefull")異常。當隊列空時,從隊列里獲取元素會拋出NoSuchElementException異常。
·返回特殊值:當往隊列插入元素時,會返回元素是否插入成功,成功返回true。如果是移除方法,則是從隊列里取出一個元素,如果沒有則返回null。
·一直阻塞:當阻塞隊列滿時,如果生產者線程往隊列里put元素,隊列會一直阻塞生產者線程,直到隊列可用或者響應中斷退出。當隊列空時,如果消費者線程從隊列里take元素,隊列會阻塞住消費者線程,直到隊列不為空。
·超時退出:當阻塞隊列滿時,如果生產者線程往隊列里插入元素,隊列會阻塞生產者線程一段時間,如果超過了指定的時間,生產者線程就會退出。
常用阻塞隊列
·ArrayBlockingQueue:一個由數組結構組成的有界阻塞隊列。
·LinkedBlockingQueue:一個由鏈表結構組成的有界阻塞隊列。
·PriorityBlockingQueue:一個支持優先級排序的無界阻塞隊列。
·DelayQueue:一個使用優先級隊列實現的無界阻塞隊列。
·SynchronousQueue:一個不存儲元素的阻塞隊列。
·LinkedTransferQueue:一個由鏈表結構組成的無界阻塞隊列。
·LinkedBlockingDeque:一個由鏈表結構組成的雙向阻塞隊列。
以上的阻塞隊列都實現了BlockingQueue接口,也都是線程安全的。
有界無界?
有限隊列就是長度有限,滿了以后生產者會阻塞,無界隊列就是里面能放無數的東西而不會因為隊列長度限制被阻塞,當然空間限制來源于系統資源的限制,如果處理不及時,導致隊列越來越大越來越大,超出一定的限制致使內存超限,操作系統或者JVM幫你解決煩惱,直接把你 OOM kill 省事了。
無界也會阻塞,為何?因為阻塞不僅僅體現在生產者放入元素時會阻塞,消費者拿取元素時,如果沒有元素,同樣也會阻塞。
ArrayBlockingQueue
是一個用數組實現的有界阻塞隊列。此隊列按照先進先出(FIFO)的原則對元素進行排序。默認情況下不保證線程公平的訪問隊列,所謂公平訪問隊列是指阻塞的線程,可以按照阻塞的先后順序訪問隊列,即先阻塞線程先訪問隊列。非公平性是對先等待的線程是非公平的,當隊列可用時,阻塞的線程都可以爭奪訪問隊列的資格,有可能先阻塞的線程最后才訪問隊列。初始化時有參數可以設置
LinkedBlockingQueue
是一個用鏈表實現的有界阻塞隊列。此隊列的默認和最大長度為Integer.MAX_VALUE。此隊列按照先進先出的原則對元素進行排序。
Array實現和Linked實現的區別
1. 隊列中鎖的實現不同
ArrayBlockingQueue實現的隊列中的鎖是沒有分離的,即生產和消費用的是同一個鎖;
LinkedBlockingQueue實現的隊列中的鎖是分離的,即生產用的是putLock,消費是takeLock
2. 在生產或消費時操作不同
ArrayBlockingQueue實現的隊列中在生產和消費的時候,是直接將枚舉對象插入或移除的;
LinkedBlockingQueue實現的隊列中在生產和消費的時候,需要把枚舉對象轉換為Node<E>進行插入或移除,會影響性能
3. 隊列大小初始化方式不同
ArrayBlockingQueue實現的隊列中必須指定隊列的大小;
LinkedBlockingQueue實現的隊列中可以不指定隊列的大小,但是默認是Integer.MAX_VALUE
PriorityBlockingQueue
PriorityBlockingQueue是一個支持優先級的無界阻塞隊列。默認情況下元素采取自然順序升序排列。也可以自定義類實現compareTo()方法來指定元素排序規則,或者初始化PriorityBlockingQueue時,指定構造參數Comparator來對元素進行排序。需要注意的是不能保證同優先級元素的順序。
DelayQueue
是一個支持延時獲取元素的無界阻塞隊列。隊列使用PriorityQueue來實現。隊列中的元素必須實現Delayed接口,在創建元素時可以指定多久才能從隊列中獲取當前元素。只有在延遲期滿時才能從隊列中提取元素。
DelayQueue非常有用,可以將DelayQueue運用在以下應用場景。
緩存系統的設計:可以用DelayQueue保存緩存元素的有效期,使用一個線程循環查詢DelayQueue,一旦能從DelayQueue中獲取元素時,表示緩存有效期到了。
SynchronousQueue
是一個不存儲元素的阻塞隊列。每一個put操作必須等待一個take操作,否則不能繼續添加元素。SynchronousQueue可以看成是一個傳球手,負責把生產者線程處理的數據直接傳遞給消費者線程。隊列本身并不存儲任何元素,非常適合傳遞性場景。
LinkedTransferQueue
多了tryTransfer和transfer方法,
(1)transfer方法
如果當前有消費者正在等待接收元素(消費者使用take()方法或帶時間限制的poll()方法時),transfer方法可以把生產者傳入的元素立刻transfer(傳輸)給消費者。如果沒有消費者在等待接收元素,transfer方法會將元素存放在隊列的tail節點,并等到該元素被消費者消費了才返回。
(2)tryTransfer方法
tryTransfer方法是用來試探生產者傳入的元素是否能直接傳給消費者。如果沒有消費者等待接收元素,則返回false。和transfer方法的區別是tryTransfer方法無論消費者是否接收,方法立即返回,而transfer方法是必須等到消費者消費了才返回。
LinkedBlockingDeque
LinkedBlockingDeque是一個由鏈表結構組成的雙向阻塞隊列。所謂雙向隊列指的是可以從隊列的兩端插入和移出元素。雙向隊列因為多了一個操作隊列的入口,在多線程同時入隊時,也就減少了一半的競爭。
多了addFirst、addLast、offerFirst、offerLast、peekFirst和peekLast等方法,以First單詞結尾的方法,表示插入、獲取(peek)或移除雙端隊列的第一個元素。以Last單詞結尾的方法,表示插入、獲取或移除雙端隊列的最后一個元素。另外,插入方法add等同于addLast,移除方法remove等效于removeFirst。但是take方法卻等同于takeFirst,不知道是不是JDK的bug,使用時還是用帶有First和Last后綴的方法更清楚。在初始化LinkedBlockingDeque時可以設置容量防止其過度膨脹。另外,雙向阻塞隊列可以運用在“工作竊取”模式中。
線程池
為什么要用線程池?
Java中的線程池是運用場景最多的并發框架,幾乎所有需要異步或并發執行任務的程序都可以使用線程池。在開發過程中,合理地使用線程池能夠帶來3個好處。
第一:降低資源消耗。通過重復利用已創建的線程降低線程創建和銷毀造成的消耗。
第二:提高響應速度。當任務到達時,任務可以不需要等到線程創建就能立即執行。假設一個服務器完成一項任務所需時間為:T1 創建線程時間,T2 在線程中執行任務的時間,T3 銷毀線程時間。?? 如果:T1 + T3 遠大于 T2,則可以采用線程池,以提高服務器性能。線程池技術正是關注如何縮短或調整T1,T3時間的技術,從而提高服務器程序性能的。它把T1,T3分別安排在服務器程序的啟動和結束的時間段或者一些空閑的時間段,這樣在服務器程序處理客戶請求時,不會有T1,T3的開銷了。
第三:提高線程的可管理性。線程是稀缺資源,如果無限制地創建,不僅會消耗系統資源,還會降低系統的穩定性,使用線程池可以進行統一分配、調優和監控。
ThreadPoolExecutor 的類關系
Executor是一個接口,它是Executor框架的基礎,它將任務的提交與任務的執行分離開來。
ExecutorService接口繼承了Executor,在其上做了一些shutdown()、submit()的擴展,可以說是真正的線程池接口;
AbstractExecutorService抽象類實現了ExecutorService接口中的大部分方法;
ThreadPoolExecutor是線程池的核心實現類,用來執行被提交的任務。
ScheduledExecutorService接口繼承了ExecutorService接口,提供了帶"周期執行"功能ExecutorService;
ScheduledThreadPoolExecutor是一個實現類,可以在給定的延遲后運行命令,或者定期執行命令。ScheduledThreadPoolExecutor比Timer更靈活,功能更強大。
線程池的創建各個參數含義
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
corePoolSize
線程池中的核心線程數,當提交一個任務時,線程池創建一個新線程執行任務,直到當前線程數等于corePoolSize;
如果當前線程數為corePoolSize,繼續提交的任務被保存到阻塞隊列中,等待被執行;
如果執行了線程池的prestartAllCoreThreads()方法,線程池會提前創建并啟動所有核心線程。
maximumPoolSize
線程池中允許的最大線程數。如果當前阻塞隊列滿了,且繼續提交任務,則創建新的線程執行任務,前提是當前線程數小于maximumPoolSize
keepAliveTime
線程空閑時的存活時間,即當線程沒有任務執行時,繼續存活的時間。默認情況下,該參數只在線程數大于corePoolSize時才有用
TimeUnit
keepAliveTime的時間單位
workQueue
workQueue必須是BlockingQueue阻塞隊列。當線程池中的線程數超過它的corePoolSize的時候,線程會進入阻塞隊列進行阻塞等待。通過workQueue,線程池實現了阻塞功能。
一般來說,我們應該盡量使用有界隊列,因為使用無界隊列作為工作隊列會對線程池帶來如下影響。
1)當線程池中的線程數達到corePoolSize后,新任務將在無界隊列中等待,因此線程池中的線程數不會超過corePoolSize。
2)由于1,使用無界隊列時maximumPoolSize將是一個無效參數。
3)由于1和2,使用無界隊列時keepAliveTime將是一個無效參數。
4)更重要的,使用無界queue可能會耗盡系統資源,有界隊列則有助于防止資源耗盡,同時即使使用有界隊列,也要盡量控制隊列的大小在一個合適的范圍。
threadFactory
創建線程的工廠,通過自定義的線程工廠可以給每個新建的線程設置一個具有識別度的線程名,當然還可以更加自由的對線程做更多的設置,比如設置所有的線程為守護線程。
Executors靜態工廠里默認的threadFactory,線程的命名規則是“pool-數字-thread-數字”。
RejectedExecutionHandler
線程池的飽和策略,當阻塞隊列滿了,且沒有空閑的工作線程,如果繼續提交任務,必須采取一種策略處理該任務,線程池提供了4種策略:
(1)AbortPolicy:直接拋出異常,默認策略;
(2)CallerRunsPolicy:用調用者所在的線程來執行任務;
(3)DiscardOldestPolicy:丟棄阻塞隊列中靠最前的任務,并執行當前任務;
(4)DiscardPolicy:直接丟棄任務;
當然也可以根據應用場景實現RejectedExecutionHandler接口,自定義飽和策略,如記錄日志或持久化存儲不能處理的任務。
線程池的工作機制
1)如果當前運行的線程少于corePoolSize,則創建新線程來執行任務(注意,執行這一步驟需要獲取全局鎖)。
2)如果運行的線程等于或多于corePoolSize,則將任務加入BlockingQueue。
3)如果無法將任務加入BlockingQueue(隊列已滿),則創建新的線程來處理任務。
4)如果創建新線程將使當前運行的線程超出maximumPoolSize,任務將被拒絕,并調用RejectedExecutionHandler.rejectedExecution()方法。
提交任務
execute()方法用于提交不需要返回值的任務,所以無法判斷任務是否被線程池執行成功。
submit()方法用于提交需要返回值的任務。線程池會返回一個future類型的對象,通過這個future對象可以判斷任務是否執行成功,并且可以通過future的get()方法來獲取返回值,get()方法會阻塞當前線程直到任務完成,而使用get(long timeout,TimeUnit unit)方法則會阻塞當前線程一段時間后立即返回,這時候有可能任務沒有執行完。
關閉線程池
可以通過調用線程池的shutdown或shutdownNow方法來關閉線程池。它們的原理是遍歷線程池中的工作線程,然后逐個調用線程的interrupt方法來中斷線程,所以無法響應中斷的任務可能永遠無法終止。但是它們存在一定的區別,shutdownNow首先將線程池的狀態設置成STOP,然后嘗試停止所有的正在執行或暫停任務的線程,并返回等待執行任務的列表,而shutdown只是將線程池的狀態設置成SHUTDOWN狀態,然后中斷所有沒有正在執行任務的線程。
只要調用了這兩個關閉方法中的任意一個,isShutdown方法就會返回true。當所有的任務都已關閉后,才表示線程池關閉成功,這時調用isTerminaed方法會返回true。至于應該調用哪一種方法來關閉線程池,應該由提交到線程池的任務特性決定,通常調用shutdown方法來關閉線程池,如果任務不一定要執行完,則可以調用shutdownNow方法。
合理地配置線程池
要想合理地配置線程池,就必須首先分析任務特性
要想合理地配置線程池,就必須首先分析任務特性,可以從以下幾個角度來分析。
?任務的性質:CPU密集型任務、IO密集型任務和混合型任務。
?任務的優先級:高、中和低。
?任務的執行時間:長、中和短。
?任務的依賴性:是否依賴其他系統資源,如數據庫連接。
性質不同的任務可以用不同規模的線程池分開處理。
CPU密集型任務應配置盡可能小的線程,如配置Ncpu+1個線程的線程池。由于IO密集型任務線程并不是一直在執行任務,則應配置盡可能多的線程,如2*Ncpu。
混合型的任務,如果可以拆分,將其拆分成一個CPU密集型任務和一個IO密集型任務,只要這兩個任務執行的時間相差不是太大,那么分解后執行的吞吐量將高于串行執行的吞吐量。如果這兩個任務執行時間相差太大,則沒必要進行分解。可以通過Runtime.getRuntime().availableProcessors()方法獲得當前設備的CPU個數。
優先級不同的任務可以使用優先級隊列PriorityBlockingQueue來處理。它可以讓優先級高的任務先執行。
執行時間不同的任務可以交給不同規模的線程池來處理,或者可以使用優先級隊列,讓執行時間短的任務先執行。
建議使用有界隊列。有界隊列能增加系統的穩定性和預警能力,可以根據需要設大一點兒,比如幾千。
如果當時我們設置成無界隊列,那么線程池的隊列就會越來越多,有可能會撐滿內存,導致整個系統不可用,而不只是后臺任務出現問題。
AbstractQueuedSynchronizer
學習AQS的必要性
隊列同步器AbstractQueuedSynchronizer(以下簡稱同步器或AQS),是用來構建鎖或者其他同步組件的基礎框架,它使用了一個int成員變量表示同步狀態,通過內置的FIFO隊列來完成資源獲取線程的排隊工作。并發包的大師(Doug Lea)期望它能夠成為實現大部分同步需求的基礎。
AQS使用方式和其中的設計模式
AQS的主要使用方式是繼承,子類通過繼承AQS并實現它的抽象方法來管理同步狀態,在AQS里由一個int型的state來代表這個狀態,在抽象方法的實現過程中免不了要對同步狀態進行更改,這時就需要使用同步器提供的3個方法(getState()、setState(int newState)和compareAndSetState(int expect,int update))來進行操作,因為它們能夠保證狀態的改變是安全的。

在實現上,子類推薦被定義為自定義同步組件的靜態內部類,AQS自身沒有實現任何同步接口,它僅僅是定義了若干同步狀態獲取和釋放的方法來供自定義同步組件使用,同步器既可以支持獨占式地獲取同步狀態,也可以支持共享式地獲取同步狀態,這樣就可以方便實現不同類型的同步組件(ReentrantLock、ReentrantReadWriteLock和CountDownLatch等)。
同步器是實現鎖(也可以是任意同步組件)的關鍵,在鎖的實現中聚合同步器。可以這樣理解二者之間的關系:
鎖是面向使用者的,它定義了使用者與鎖交互的接口(比如可以允許兩個線程并行訪問),隱藏了實現細節;
同步器面向的是鎖的實現者,它簡化了鎖的實現方式,屏蔽了同步狀態管理、線程的排隊、等待與喚醒等底層操作。鎖和同步器很好地隔離了使用者和實現者所需關注的領域。
實現者需要繼承同步器并重寫指定的方法,隨后將同步器組合在自定義同步組件的實現中,并調用同步器提供的模板方法,而這些模板方法將會調用使用者重寫的方法。
模板方法模式
同步器的設計基于模板方法模式。模板方法模式的意圖是,定義一個操作中的算法的骨架,而將一些步驟的實現延遲到子類中。模板方法使得子類可以不改變一個算法的結構即可重定義該算法的某些特定步驟。我們最常見的就是Spring框架里的各種Template。
實際例子
我們開了個蛋糕店,蛋糕店不能只賣一種蛋糕呀,于是我們決定先賣奶油蛋糕,芝士蛋糕和慕斯蛋糕。三種蛋糕在制作方式上一樣,都包括造型,烘焙和涂抹蛋糕上的東西。所以可以定義一個抽象蛋糕模型

然后就可以批量生產三種蛋糕

![]()
![]()

這樣一來,不但可以批量生產三種蛋糕,而且如果日后有擴展,只需要繼承抽象蛋糕方法就可以了,十分方便,我們天天生意做得越來越賺錢。突然有一天,我們發現市面有一種最簡單的小蛋糕銷量很好,這種蛋糕就是簡單烘烤成型就可以賣,并不需要涂抹什么食材,由于制作簡單銷售量大,這個品種也很賺錢,于是我們也想要生產這種蛋糕。但是我們發現了一個問題,抽象蛋糕是定義了抽象的涂抹方法的,也就是說擴展的這種蛋糕是必須要實現涂抹方法,這就很雞兒蛋疼了。怎么辦?我們可以將原來的模板修改為帶鉤子的模板。

小蛋糕的時候通過flag來控制是否涂抹,其余已有的蛋糕制作不需要任何修改可以照常進行。

AQS中的方法
模板方法
實現自定義同步組件時,將會調用同步器提供的模板方法,

這些模板方法同步器提供的模板方法基本上分為3類:獨占式獲取與釋放同步狀態、共享式獲取與釋放、同步狀態和查詢同步隊列中的等待線程情況。
可重寫的方法
?

訪問或修改同步狀態的方法
重寫同步器指定的方法時,需要使用同步器提供的如下3個方法來訪問或修改同步狀態。
?getState():獲取當前同步狀態。
?setState(int newState):設置當前同步狀態。
?compareAndSetState(int expect,int update):使用CAS設置當前狀態,該方法能夠保證狀態設置的原子性。
CLH隊列鎖
CLH隊列鎖即Craig, Landin, and Hagersten (CLH) locks。
CLH隊列鎖也是一種基于鏈表的可擴展、高性能、公平的自旋鎖,申請線程僅僅在本地變量上自旋,它不斷輪詢前驅的狀態,假設發現前驅釋放了鎖就結束自旋。
當一個線程需要獲取鎖時:
1. 創建一個的QNode,將其中的locked設置為true表示需要獲取鎖,myPred表示對其前驅結點的引用

2. 線程A對tail域調用getAndSet方法,使自己成為隊列的尾部,同時獲取一個指向其前驅結點的引用myPred

線程B需要獲得鎖,同樣的流程再來一遍

3.線程就在前驅結點的locked字段上旋轉,直到前驅結點釋放鎖(前驅節點的鎖值 locked == false)
4.當一個線程需要釋放鎖時,將當前結點的locked域設置為false,同時回收前驅結點

如上圖所示,前驅結點釋放鎖,線程A的myPred所指向的前驅結點的locked字段變為false,線程A就可以獲取到鎖。
CLH隊列鎖的優點是空間復雜度低(如果有n個線程,L個鎖,每個線程每次只獲取一個鎖,那么需要的存儲空間是O(L+n),n個線程有n個myNode,L個鎖有L個tail)。CLH隊列鎖常用在SMP體系結構下。
Java中的AQS是CLH隊列鎖的一種變體實現。
ReentrantLock的實現
鎖的可重入
重進入是指任意線程在獲取到鎖之后能夠再次獲取該鎖而不會被鎖所阻塞,該特性的實現需要解決以下兩個問題。
1)線程再次獲取鎖。鎖需要去識別獲取鎖的線程是否為當前占據鎖的線程,如果是,則再次成功獲取。
2)鎖的最終釋放。線程重復n次獲取了鎖,隨后在第n次釋放該鎖后,其他線程能夠獲取到該鎖。鎖的最終釋放要求鎖對于獲取進行計數自增,計數表示當前鎖被重復獲取的次數,而鎖被釋放時,計數自減,當計數等于0時表示鎖已經成功釋放。
nonfairTryAcquire方法增加了再次獲取同步狀態的處理邏輯:通過判斷當前線程是否為獲取鎖的線程來決定獲取操作是否成功,如果是獲取鎖的線程再次請求,則將同步狀態值進行增加并返回true,表示獲取同步狀態成功。同步狀態表示鎖被一個線程重復獲取的次數。
如果該鎖被獲取了n次,那么前(n-1)次tryRelease(int releases)方法必須返回false,而只有同步狀態完全釋放了,才能返回true。可以看到,該方法將同步狀態是否為0作為最終釋放的條件,當同步狀態為0時,將占有線程設置為null,并返回true,表示釋放成功。
公平和非公平鎖
ReentrantLock的構造函數中,默認的無參構造函數將會把Sync對象創建為NonfairSync對象,這是一個“非公平鎖”;而另一個構造函數ReentrantLock(boolean fair)傳入參數為true時將會把Sync對象創建為“公平鎖”FairSync。
nonfairTryAcquire(int acquires)方法,對于非公平鎖,只要CAS設置同步狀態成功,則表示當前線程獲取了鎖,而公平鎖則不同。tryAcquire方法,該方法與nonfairTryAcquire(int acquires)比較,唯一不同的位置為判斷條件多了hasQueuedPredecessors()方法,即加入了同步隊列中當前節點是否有前驅節點的判斷,如果該方法返回true,則表示有線程比當前線程更早地請求獲取鎖,因此需要等待前驅線程獲取并釋放鎖之后才能繼續獲取鎖。
深入理解并發編程和歸納總結
JMM基礎-計算機原理
Java內存模型即Java Memory Model,簡稱JMM。JMM定義了Java 虛擬機(JVM)在計算機內存(RAM)中的工作方式。JVM是整個計算機虛擬模型,所以JMM是隸屬于JVM的。Java1.5版本對其進行了重構,現在的Java仍沿用了Java1.5的版本。Jmm遇到的問題與現代計算機中遇到的問題是差不多的。
物理計算機中的并發問題,物理機遇到的并發問題與虛擬機中的情況有不少相似之處,物理機對并發的處理方案對于虛擬機的實現也有相當大的參考意義。
根據《Jeff Dean在Google全體工程大會的報告》我們可以看到

計算機在做一些我們平時的基本操作時,需要的響應時間是不一樣的。
(以下案例僅做說明,并不代表真實情況。)
如果從內存中讀取1M的int型數據由CPU進行累加,耗時要多久?
做個簡單的計算,1M的數據,Java里int型為32位,4個字節,共有1024*1024/4 = 262144個整數 ,則CPU 計算耗時:262144 *0.6 = 157 286 納秒,而我們知道從內存讀取1M數據需要250000納秒,兩者雖然有差距(當然這個差距并不小,十萬納秒的時間足夠CPU執行將近二十萬條指令了),但是還在一個數量級上。但是,沒有任何緩存機制的情況下,意味著每個數都需要從內存中讀取,這樣加上CPU讀取一次內存需要100納秒,262144個整數從內存讀取到CPU加上計算時間一共需要262144*100+250000 = 26 464 400 納秒,這就存在著數量級上的差異了。
而且現實情況中絕大多數的運算任務都不可能只靠處理器“計算”就能完成,處理器至少要與內存交互,如讀取運算數據、存儲運算結果等,這個I/O操作是基本上是無法消除的(無法僅靠寄存器來完成所有運算任務)。早期計算機中cpu和內存的速度是差不多的,但在現代計算機中,cpu的指令速度遠超內存的存取速度,由于計算機的存儲設備與處理器的運算速度有幾個數量級的差距,所以現代計算機系統都不得不加入一層讀寫速度盡可能接近處理器運算速度的高速緩存(Cache)來作為內存與處理器之間的緩沖:將運算需要使用到的數據復制到緩存中,讓運算能快速進行,當運算結束后再從緩存同步回內存之中,這樣處理器就無須等待緩慢的內存讀寫了。


在計算機系統中,寄存器劃是L0級緩存,接著依次是L1,L2,L3(接下來是內存,本地磁盤,遠程存儲)。越往上的緩存存儲空間越小,速度越快,成本也更高;越往下的存儲空間越大,速度更慢,成本也更低。從上至下,每一層都可以看做是更下一層的緩存,即:L0寄存器是L1一級緩存的緩存,L1是L2的緩存,依次類推;每一層的數據都是來至它的下一層,所以每一層的數據是下一層的數據的子集。

在現代CPU上,一般來說L0, L1,L2,L3都集成在CPU內部,而L1還分為一級數據緩存(Data Cache,D-Cache,L1d)和一級指令緩存(Instruction Cache,I-Cache,L1i),分別用于存放數據和執行數據的指令解碼。每個核心擁有獨立的運算處理單元、控制器、寄存器、L1、L2緩存,然后一個CPU的多個核心共享最后一層CPU緩存L3
Java內存模型(JMM)
從抽象的角度來看,JMM定義了線程和主內存之間的抽象關系:線程之間的共享變量存儲在主內存(Main Memory)中,每個線程都有一個私有的本地內存(Local Memory),本地內存中存儲了該線程以讀/寫共享變量的副本。本地內存是JMM的一個抽象概念,并不真實存在。它涵蓋了緩存、寫緩沖區、寄存器以及其他的硬件和編譯器優化。


可見性
可見性是指當多個線程訪問同一個變量時,一個線程修改了這個變量的值,其他線程能夠立即看得到修改的值。
由于線程對變量的所有操作都必須在工作內存中進行,而不能直接讀寫主內存中的變量,那么對于共享變量V,它們首先是在自己的工作內存,之后再同步到主內存。可是并不會及時的刷到主存中,而是會有一定時間差。很明顯,這個時候線程 A 對變量 V 的操作對于線程 B 而言就不具備可見性了 。
要解決共享對象可見性這個問題,我們可以使用volatile關鍵字或者是加鎖。
原子性
原子性:即一個操作或者多個操作 要么全部執行并且執行的過程不會被任何因素打斷,要么就都不執行。
我們都知道CPU資源的分配都是以線程為單位的,并且是分時調用,操作系統允許某個進程執行一小段時間,例如 50 毫秒,過了 50 毫秒操作系統就會重新選擇一個進程來執行(我們稱為“任務切換”),這個 50 毫秒稱為“時間片”。而任務的切換大多數是在時間片段結束以后,
那么線程切換為什么會帶來bug呢?因為操作系統做任務切換,可以發生在任何一條CPU 指令執行完!注意,是 CPU 指令,CPU 指令,CPU 指令,而不是高級語言里的一條語句。比如count++,在java里就是一句話,但高級語言里一條語句往往需要多條 CPU 指令完成。其實count++至少包含了三個CPU指令!
volatile詳解
volatile特性
可以把對volatile變量的單個讀/寫,看成是使用同一個鎖對這些單個讀/寫操作做了同步

可以看成

所以volatile變量自身具有下列特性:
可見性。對一個volatile變量的讀,總是能看到(任意線程)對這個volatile變量最后的寫入。
原子性:對任意單個volatile變量的讀/寫具有原子性,但類似于volatile++這種復合操作不具有原子性。
volatile雖然能保證執行完及時把變量刷到主內存中,但對于count++這種非原子性、多指令的情況,由于線程切換,線程A剛把count=0加載到工作內存,線程B就可以開始工作了,這樣就會導致線程A和B執行完的結果都是1,都寫到主內存中,主內存的值還是1不是2
volatile的實現原理
volatile關鍵字修飾的變量會存在一個“lock:”的前綴。
Lock前綴,Lock不是一種內存屏障,但是它能完成類似內存屏障的功能。Lock會對CPU總線和高速緩存加鎖,可以理解為CPU指令級的一種鎖。
同時該指令會將當前處理器緩存行的數據直接寫會到系統內存中,且這個寫回內存的操作會使在其他CPU里緩存了該地址的數據無效。
synchronized的實現原理
Synchronized在JVM里的實現都是基于進入和退出Monitor對象來實現方法同步和代碼塊同步,雖然具體實現細節不一樣,但是都可以通過成對的MonitorEnter和MonitorExit指令來實現。
對同步塊,MonitorEnter指令插入在同步代碼塊的開始位置,而monitorExit指令則插入在方法結束處和異常處,JVM保證每個MonitorEnter必須有對應的MonitorExit。總的來說,當代碼執行到該指令時,將會嘗試獲取該對象Monitor的所有權,即嘗試獲得該對象的鎖:
1、如果monitor的進入數為0,則該線程進入monitor,然后將進入數設置為1,該線程即為monitor的所有者。
2、如果線程已經占有該monitor,只是重新進入,則進入monitor的進入數加1.
3.如果其他線程已經占用了monitor,則該線程進入阻塞狀態,直到monitor的進入數為0,再重新嘗試獲取monitor的所有權。
對同步方法,從同步方法反編譯的結果來看,方法的同步并沒有通過指令monitorenter和monitorexit來實現,相對于普通方法,其常量池中多了ACC_SYNCHRONIZED標示符。
JVM就是根據該標示符來實現方法的同步的:當方法被調用時,調用指令將會檢查方法的 ACC_SYNCHRONIZED 訪問標志是否被設置,如果設置了,執行線程將先獲取monitor,獲取成功之后才能執行方法體,方法執行完后再釋放monitor。在方法執行期間,其他任何線程都無法再獲得同一個monitor對象。
synchronized使用的鎖是存放在Java對象頭里面,Java對象的對象頭由 mark word 和? klass pointer 兩部分組成:
1)mark word存儲了同步狀態、標識、hashcode、GC狀態等等。
2)klass pointer存儲對象的類型指針,該指針指向它的類元數據
另外對于數組而言還會有一份記錄數組長度的數據。

鎖信息則是存在于對象的mark word中,MarkWord里默認數據是存儲對象的HashCode等信息,

但是會隨著對象的運行改變而發生變化,不同的鎖狀態對應著不同的記錄存儲方式

了解各種鎖
鎖的狀態
一共有四種狀態,無鎖狀態,偏向鎖狀態,輕量級鎖狀態和重量級鎖狀態,它會隨著競爭情況逐漸升級。鎖可以升級但不能降級,目的是為了提高獲得鎖和釋放鎖的效率。
偏向鎖
引入背景:大多數情況下鎖不僅不存在多線程競爭,而且總是由同一線程多次獲得,為了讓線程獲得鎖的代價更低而引入了偏向鎖,減少不必要的CAS操作。
偏向鎖,顧名思義,它會偏向于第一個訪問鎖的線程,如果在運行過程中,同步鎖只有一個線程訪問,不存在多線程爭用的情況,則線程是不需要觸發同步的,減少加鎖/解鎖的一些CAS操作(比如等待隊列的一些CAS操作),這種情況下,就會給線程加一個偏向鎖。?如果在運行過程中,遇到了其他線程搶占鎖,則持有偏向鎖的線程會被掛起,JVM會消除它身上的偏向鎖,將鎖恢復到標準的輕量級鎖。它通過消除資源無競爭情況下的同步原語,進一步提高了程序的運行性能。
偏向鎖獲取過程:
步驟1、 訪問Mark Word中偏向鎖的標識是否設置成1,鎖標志位是否為01,確認為可偏向狀態。
步驟2、 如果為可偏向狀態,則測試線程ID是否指向當前線程,如果是,進入步驟5,否則進入步驟3。
步驟3、 如果線程ID并未指向當前線程,則通過CAS操作競爭鎖。如果競爭成功,則將Mark Word中線程ID設置為當前線程ID,然后執行5;如果競爭失敗,執行4。
步驟4、 如果CAS獲取偏向鎖失敗,則表示有競爭。當到達全局安全點(safepoint)時獲得偏向鎖的線程被掛起,偏向鎖升級為輕量級鎖,然后被阻塞在安全點的線程繼續往下執行同步代碼。(撤銷偏向鎖的時候會導致stop the word)
步驟5、 執行同步代碼。

偏向鎖的釋放:
偏向鎖的撤銷在上述第四步驟中有提到。偏向鎖只有遇到其他線程嘗試競爭偏向鎖時,持有偏向鎖的線程才會釋放偏向鎖,線程不會主動去釋放偏向鎖。偏向鎖的撤銷,需要等待全局安全點(在這個時間點上沒有字節碼正在執行),它會首先暫停擁有偏向鎖的線程,判斷鎖對象是否處于被鎖定狀態,撤銷偏向鎖后恢復到未鎖定(標志位為“01”)或輕量級鎖(標志位為“00”)的狀態。
偏向鎖的適用場景
始終只有一個線程在執行同步塊,在它沒有執行完釋放鎖之前,沒有其它線程去執行同步塊,在鎖無競爭的情況下使用,一旦有了競爭就升級為輕量級鎖,升級為輕量級鎖的時候需要撤銷偏向鎖,撤銷偏向鎖的時候會導致stop the word操作;?
在有鎖的競爭時,偏向鎖會多做很多額外操作,尤其是撤銷偏向所的時候會導致進入安全點,安全點會導致stw,導致性能下降,這種情況下應當禁用。
jvm開啟/關閉偏向鎖
開啟偏向鎖:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
關閉偏向鎖:-XX:-UseBiasedLocking
輕量級鎖
輕量級鎖是由偏向鎖升級來的,偏向鎖運行在一個線程進入同步塊的情況下,當第二個線程加入鎖爭用的時候,偏向鎖就會升級為輕量級鎖;?
輕量級鎖的加鎖過程:
1、在代碼進入同步塊的時候,如果同步對象鎖狀態為無鎖狀態且不允許進行偏向(鎖標志位為“01”狀態,是否為偏向鎖為“0”),虛擬機首先將在當前線程的棧幀中建立一個名為鎖記錄(Lock Record)的空間,用于存儲鎖對象目前的Mark Word的拷貝,官方稱之為 Displaced Mark Word。
2、拷貝對象頭中的Mark Word復制到鎖記錄中。
3、拷貝成功后,虛擬機將使用CAS操作嘗試將對象的Mark Word更新為指向Lock Record的指針,并將Lock record里的owner指針指向object mark word。如果更新成功,則執行步驟4,否則執行步驟5。
4、如果這個更新動作成功了,那么這個線程就擁有了該對象的鎖,并且對象Mark Word的鎖標志位設置為“00”,即表示此對象處于輕量級鎖定狀態
5、如果這個更新操作失敗了,虛擬機首先會檢查對象的Mark Word是否指向當前線程的棧幀,如果是就說明當前線程已經擁有了這個對象的鎖,那就可以直接進入同步塊繼續執行。否則說明多個線程競爭鎖,那么它就會自旋等待鎖,一定次數后仍未獲得鎖對象。重量級線程指針指向競爭線程,競爭線程也會阻塞,等待輕量級線程釋放鎖后喚醒他。鎖標志的狀態值變為“10”,Mark Word中存儲的就是指向重量級鎖(互斥量)的指針,后面等待鎖的線程也要進入阻塞狀態。
自旋鎖
原理
自旋鎖原理非常簡單,如果持有鎖的線程能在很短時間內釋放鎖資源,那么那些等待競爭鎖的線程就不需要做內核態和用戶態之間的切換進入阻塞掛起狀態,它們只需要等一等(自旋),等持有鎖的線程釋放鎖后即可立即獲取鎖,這樣就避免用戶線程和內核的切換的消耗。
但是線程自旋是需要消耗CPU的,說白了就是讓CPU在做無用功,線程不能一直占用CPU自旋做無用功,所以需要設定一個自旋等待的最大時間。
如果持有鎖的線程執行的時間超過自旋等待的最大時間扔沒有釋放鎖,就會導致其它爭用鎖的線程在最大等待時間內還是獲取不到鎖,這時爭用線程會停止自旋進入阻塞狀態。
自旋鎖的優缺點
自旋鎖盡可能的減少線程的阻塞,這對于鎖的競爭不激烈,且占用鎖時間非常短的代碼塊來說性能能大幅度的提升,因為自旋的消耗會小于線程阻塞掛起操作的消耗!
但是如果鎖的競爭激烈,或者持有鎖的線程需要長時間占用鎖執行同步塊,這時候就不適合使用自旋鎖了,因為自旋鎖在獲取鎖前一直都是占用cpu做無用功,占著XX不XX,線程自旋的消耗大于線程阻塞掛起操作的消耗,其它需要cup的線程又不能獲取到cpu,造成cpu的浪費。
自旋鎖時間閾值
自旋鎖的目的是為了占著CPU的資源不釋放,等到獲取到鎖立即進行處理。但是如何去選擇自旋的執行時間呢?如果自旋執行時間太長,會有大量的線程處于自旋狀態占用CPU資源,進而會影響整體系統的性能。因此自旋次數很重要
JVM對于自旋次數的選擇,jdk1.5默認為10次,在1.6引入了適應性自旋鎖,適應性自旋鎖意味著自旋的時間不在是固定的了,而是由前一次在同一個鎖上的自旋時間以及鎖的擁有者的狀態來決定,基本認為一個線程上下文切換的時間是最佳的一個時間。
JDK1.6中-XX:+UseSpinning開啟自旋鎖;?JDK1.7后,去掉此參數,由jvm控制;

不同鎖的比較

看看一線大廠面試題
sychronied修飾普通方法和靜態方法的區別?什么是可見性?
對象鎖是用于對象實例方法,或者一個對象實例上的,類鎖是用于類的靜態方法或者一個類的class對象上的。我們知道,類的對象實例可以有很多個,但是每個類只有一個class對象,所以不同對象實例的對象鎖是互不干擾的,但是每個類只有一個類鎖。
但是有一點必須注意的是,其實類鎖只是一個概念上的東西,并不是真實存在的,類鎖其實鎖的是每個類的對應的class對象。類鎖和對象鎖之間也是互不干擾的。
可見性是指當多個線程訪問同一個變量時,一個線程修改了這個變量的值,其他線程能夠立即看得到修改的值。
由于線程對變量的所有操作都必須在工作內存中進行,而不能直接讀寫主內存中的變量,那么對于共享變量V,它們首先是在自己的工作內存,之后再同步到主內存。可是并不會及時的刷到主存中,而是會有一定時間差。很明顯,這個時候線程 A 對變量 V 的操作對于線程 B 而言就不具備可見性了 。
要解決共享對象可見性這個問題,我們可以使用volatile關鍵字或者是加鎖。
鎖分哪幾類?

CAS無鎖編程的原理。
使用當前的處理器基本都支持CAS()的指令,只不過每個廠家所實現的算法并不一樣,每一個CAS操作過程都包含三個運算符:一個內存地址V,一個期望的值A和一個新值B,操作的時候如果這個地址上存放的值等于這個期望的值A,則將地址上的值賦為新值B,否則不做任何操作。
CAS的基本思路就是,如果這個地址上的值和期望的值相等,則給其賦予新值,否則不做任何事兒,但是要返回原值是多少。循環CAS就是在一個循環里不斷的做cas操作,直到成功為止。
還可以說說CAS的三大問題。
ReentrantLock的實現原理。
線程可以重復進入任何一個它已經擁有的鎖所同步著的代碼塊,synchronized、ReentrantLock都是可重入的鎖。在實現上,就是線程每次獲取鎖時判定如果獲得鎖的線程是它自己時,簡單將計數器累積即可,每 釋放一次鎖,進行計數器累減,直到計算器歸零,表示線程已經徹底釋放鎖。
底層則是利用了JUC中的AQS來實現的。
AQS原理?(小米?京東)
是用來構建鎖或者其他同步組件的基礎框架,比如ReentrantLock、ReentrantReadWriteLock和CountDownLatch就是基于AQS實現的。它使用了一個int成員變量表示同步狀態,通過內置的FIFO隊列來完成資源獲取線程的排隊工作。它是CLH隊列鎖的一種變體實現。它可以實現2種同步方式:獨占式,共享式。
AQS的主要使用方式是繼承,子類通過繼承AQS并實現它的抽象方法來管理同步狀態,同步器的設計基于模板方法模式,所以如果要實現我們自己的同步工具類就需要覆蓋其中幾個可重寫的方法,如tryAcquire、tryReleaseShared等等。
這樣設計的目的是同步組件(比如鎖)是面向使用者的,它定義了使用者與同步組件交互的接口(比如可以允許兩個線程并行訪問),隱藏了實現細節;同步器面向的是鎖的實現者,它簡化了鎖的實現方式,屏蔽了同步狀態管理、線程的排隊、等待與喚醒等底層操作。這樣就很好地隔離了使用者和實現者所需關注的領域。
在內部,AQS維護一個共享資源state,通過內置的FIFO來完成獲取資源線程的排隊工作。該隊列由一個一個的Node結點組成,每個Node結點維護一個prev引用和next引用,分別指向自己的前驅和后繼結點,構成一個雙端雙向鏈表。
Synchronized的原理以及與ReentrantLock的區別。(360)
synchronized (this)原理:涉及兩條指令:monitorenter,monitorexit;再說同步方法,從同步方法反編譯的結果來看,方法的同步并沒有通過指令monitorenter和monitorexit來實現,相對于普通方法,其常量池中多了ACC_SYNCHRONIZED標示符。
JVM就是根據該標示符來實現方法的同步的:當方法被調用時,調用指令將會檢查方法的 ACC_SYNCHRONIZED 訪問標志是否被設置,如果設置了,執行線程將先獲取monitor,獲取成功之后才能執行方法體,方法執行完后再釋放monitor。在方法執行期間,其他任何線程都無法再獲得同一個monitor對象。
Synchronized做了哪些優化?(京東)
引入如自旋鎖、適應性自旋鎖、鎖消除、鎖粗化、偏向鎖、輕量級鎖、逃逸分析
等技術來減少鎖操作的開銷。
逃逸分析
如果證明一個對象不會逃逸方法外或者線程外,則可針對此變量進行優化:
同步消除synchronization Elimination,如果一個對象不會逃逸出線程,則對此變量的同步措施可消除。
鎖消除和粗化
鎖消除:虛擬機的運行時編譯器在運行時如果檢測到一些要求同步的代碼上不可能發生共享數據競爭,則會去掉這些鎖。
鎖粗化:將臨近的代碼塊用同一個鎖合并起來。
消除無意義的鎖獲取和釋放,可以提高程序運行性能。
Synchronized?static與非static鎖的區別和范圍(小米)
對象鎖是用于對象實例方法,或者一個對象實例上的,類鎖是用于類的靜態方法或者一個類的class對象上的。我們知道,類的對象實例可以有很多個,但是每個類只有一個class對象,所以不同對象實例的對象鎖是互不干擾的,但是每個類只有一個類鎖。
但是有一點必須注意的是,其實類鎖只是一個概念上的東西,并不是真實存在的,類鎖其實鎖的是每個類的對應的class對象。類鎖和對象鎖之間也是互不干擾的。
volatile?能否保證線程安全?在DCL上的作用是什么?
不能保證,在DCL的作用是:volatile是會保證被修飾的變量的可見性和 有序性,保證了單例模式下,保證在創建對象的時候的執行順序一定是
1.分配內存空間
2.實例化對象instance
3.把instance引用指向已分配的內存空間,此時instance有了內存地址,不再為null了
的步驟, 從而保證了instance要么為null 要么是已經完全初始化好的對象。
volatile和synchronize有什么區別?(B站?小米?京東)
volatile是最輕量的同步機制。
volatile保證了不同線程對這個變量進行操作時的可見性,即一個線程修改了某個變量的值,這新值對其他線程來說是立即可見的。但是volatile不能保證操作的原子性,因此多線程下的寫復合操作會導致線程安全問題。
關鍵字synchronized可以修飾方法或者以同步塊的形式來進行使用,它主要確保多個線程在同一個時刻,只能有一個線程處于方法或者同步塊中,它保證了線程對變量訪問的可見性和排他性,又稱為內置鎖機制。
什么是守護線程?你是如何退出一個線程的?
Daemon(守護)線程是一種支持型線程,因為它主要被用作程序中后臺調度以及支持性工作。這意味著,當一個Java虛擬機中不存在非Daemon線程的時候,Java虛擬機將會退出。可以通過調用Thread.setDaemon(true)將線程設置為Daemon線程。我們一般用不上,比如垃圾回收線程就是Daemon線程。
線程的中止:
要么是run執行完成了,要么是拋出了一個未處理的異常導致線程提前結束。
暫停、恢復和停止操作對應在線程Thread的API就是suspend()、resume()和stop()。但是這些API是過期的,也就是不建議使用的。因為會導致程序可能工作在不確定狀態下。
安全的中止則是其他線程通過調用某個線程A的interrupt()方法對其進行中斷操作,被中斷的線程則是通過線程通過方法isInterrupted()來進行判斷是否被中斷,也可以調用靜態方法Thread.interrupted()來進行判斷當前線程是否被中斷,不過Thread.interrupted()會同時將中斷標識位改寫為false。
sleep?、wait、yield?的區別,wait?的線程如何喚醒它?(東方頭條)
yield()方法:使當前線程讓出CPU占有權,但讓出的時間是不可設定的。也不會釋放鎖資源。所有執行yield()的線程有可能在進入到就緒狀態后會被操作系統再次選中馬上又被執行。
yield() 、sleep()被調用后,都不會釋放當前線程所持有的鎖。
調用wait()方法后,會釋放當前線程持有的鎖,而且當前被喚醒后,會重新去競爭鎖,鎖競爭到后才會執行wait方法后面的代碼。
Wait通常被用于線程間交互,sleep通常被用于暫停執行,yield()方法使當前線程讓出CPU占有權。
wait 的線程使用notify/notifyAll()進行喚醒。
sleep是可中斷的么?(小米)
sleep本身就支持中斷,如果線程在sleep期間被中斷,則會拋出一個中斷異常。
線程生命周期。
Java中線程的狀態分為6種:
1. 初始(NEW):新創建了一個線程對象,但還沒有調用start()方法。
2. 運行(RUNNABLE):Java線程中將就緒(ready)和運行中(running)兩種狀態籠統的稱為“運行”。
線程對象創建后,其他線程(比如main線程)調用了該對象的start()方法。該狀態的線程位于可運行線程池中,等待被線程調度選中,獲取CPU的使用權,此時處于就緒狀態(ready)。就緒狀態的線程在獲得CPU時間片后變為運行中狀態(running)。
3.?阻塞(BLOCKED):表示線程阻塞于鎖。
4.?等待(WAITING):進入該狀態的線程需要等待其他線程做出一些特定動作(通知或中斷)。
5.?超時等待(TIMED_WAITING):該狀態不同于WAITING,它可以在指定的時間后自行返回。
6. 終止(TERMINATED):表示該線程已經執行完畢。
ThreadLocal是什么?
ThreadLocal是Java里一種特殊的變量。ThreadLocal為每個線程都提供了變量的副本,使得每個線程在某一時間訪問到的并非同一個對象,這樣就隔離了多個線程對數據的數據共享。
在內部實現上,每個線程內部都有一個ThreadLocalMap,用來保存每個線程所擁有的變量副本。
線程池基本原理。
在開發過程中,合理地使用線程池能夠帶來3個好處。
第一:降低資源消耗。第二:提高響應速度。第三:提高線程的可管理性。
1)如果當前運行的線程少于corePoolSize,則創建新線程來執行任務(注意,執行這一步驟需要獲取全局鎖)。
2)如果運行的線程等于或多于corePoolSize,則將任務加入BlockingQueue。
3)如果無法將任務加入BlockingQueue(隊列已滿),則創建新的線程來處理任務。
4)如果創建新線程將使當前運行的線程超出maximumPoolSize,任務將被拒絕,并調用RejectedExecutionHandler.rejectedExecution()方法。
有三個線程T1,T2,T3,怎么確保它們按順序執行?
可以用join方法實現。







![Python3+Request+Pytest+Allure+Jenkins 接口自動化測試[手動寫的和AI寫的對比]](http://pic.xiahunao.cn/Python3+Request+Pytest+Allure+Jenkins 接口自動化測試[手動寫的和AI寫的對比])










)
