基礎
state的分類
key state和operate state
state 的重分布
Flink狀態管理詳解:Keyed State和Operator List State深度解析 - 掘金
checkpoint 和save point
https://zhuanlan.zhihu.com/p/79526638
?flink job 的容錯策略
如果在沒有持續消息輸出的情況下,如何定時輸出
主要是現實有可能不會一直有消息輸入,但是要定時輸出的情況
@Overridepublic void processElement(Tuple2<String, String> value, Context ctx, Collector<Tuple2<String, Long>> out) throws Exception {// retrieve the current countCountWithTimestamp current = state.value();if (current == null) {current = new CountWithTimestamp();current.key = value.f0;}// update the state's countcurrent.count++;// set the state's timestamp to the record's assigned event time timestampcurrent.lastModified = ctx.timestamp();// write the state backstate.update(current);// schedule the next timer 60 seconds from the current event time// 這里注冊一個timerctx.timerService().registerEventTimeTimer(current.lastModified + 60000);}@Overridepublic void onTimer(long timestamp, OnTimerContext ctx, Collector<Tuple2<String, Long>> out) throws Exception {// get the state for the key that scheduled the timerCountWithTimestamp result = state.value();// check if this is an outdated timer or the latest timerif (timestamp == result.lastModified + 60000) {// emit the state on timeoutout.collect(new Tuple2<String, Long>(result.key, result.count));//每次發送一個消息后,再注冊一個timerctx.timerService().registerEventTimeTimer(current.lastModified + 60000);}}state backend 有哪幾類
-
HashMapStateBackend:
- 默認狀態后端,適用于大多數情況。
- 狀態數據作為 Java 對象存儲在 JVM 堆上。
- 適用于大型狀態、長窗口、大型鍵值狀態的作業。
- 推薦在高可用性設置中使用。
- 建議將管理內存設置為零,以確保 JVM 上用戶代碼的最大內存分配。
-
EmbeddedRocksDBStateBackend:
- 將數據存儲在 RocksDB 數據庫中,通常存儲在 TaskManager 的本地數據目錄。
- 數據以序列化的字節數組形式存儲,而不是 Java 對象。
- 支持異步快照,適合需要大量狀態和長窗口的大型作業。
- 由于 RocksDB 的 JNI 橋接 API 基于 byte[],每個鍵和值的最大支持大小為 2^31 字節。
- 支持增量快照,可以減少檢查點時間,提高恢復速度。
-
選擇正確的狀態后端:
- HashMapStateBackend 提供快速的訪問和更新,但狀態大小受限于集群內的可用內存。
- EmbeddedRocksDBStateBackend 可以根據可用磁盤空間擴展,是唯一支持增量快照的狀態后端,但性能可能較慢。
-
配置狀態后端:
- 默認情況下,如果未指定其他配置,Flink 會使用 HashMapStateBackend。
- 可以在 Flink 配置文件中設置默認狀態后端,也可以在每個作業中單獨設置。
-
RocksDB 狀態后端細節:
- 支持增量快照,可以減少檢查點時間。
- 內存管理:Flink 默認配置 RocksDB 的內存分配,以確保 TaskManagers 的內存使用在環境限制內。
- 定時器(Heap vs. RocksDB):默認情況下,即使使用 RocksDB 存儲其他狀態,定時器也存儲在 RocksDB 中。可以選擇將定時器存儲在 JVM 堆上。
-
高級配置:
- 可以手動控制 RocksDB 的內存分配,通過配置 RocksDBOptionsFactory。
- 可以啟用 RocksDB 的原生指標,但可能會對性能產生負面影響。
-
變更日志(Changelog):
- 旨在減少檢查點時間,提高端到端延遲。
- 通過持續上傳狀態變化形成變更日志,檢查點時只需上傳相關部分。
- 支持從保存點和檢查點恢復。
如果我用的EmbeddedRocksDBStateBackend,為啥還要配置checkpoint目錄
-
檢查點數據存儲:檢查點是 Flink 用于確保流處理作業容錯性的關鍵機制。當啟用檢查點時,Flink 會定期保存作業的狀態快照。這些快照包括了作業的當前狀態信息,如鍵值狀態、窗口狀態、定時器等。即使狀態數據存儲在 RocksDB 中,檢查點的元數據和可能的狀態快照(如增量快照)仍然需要被保存到文件系統中。
-
恢復和故障轉移:在作業失敗時,Flink 需要從最近的檢查點恢復狀態。這要求檢查點數據必須被持久化到一個可靠的存儲系統中,通常是分布式文件系統(如 HDFS、Amazon S3 等)。這樣,無論作業的狀態數據存儲在哪里,檢查點數據都可以從這個目錄中恢復。
-
增量快照:對于
EmbeddedRocksDBStateBackend,Flink 支持增量快照。這意味著檢查點不僅保存了狀態數據的完整副本,還記錄了自上次檢查點以來狀態的變化。這些增量快照也需要被保存到檢查點目錄中,以便在恢復時能夠更高效地重建狀態。 -
配置一致性:配置檢查點目錄為 Flink 提供了一個統一的配置點,無論使用哪種狀態后端,都可以在同一個配置文件中指定檢查點的存儲位置。這有助于簡化配置管理,并確保在不同狀態后端之間切換時的一致性。
flink 與spark 簡單比較
flink 有哪幾種時間
| 時間概念 | 描述 | 適用場景 |
|---|---|---|
| 事件時間 (Event Time) | 數據本身所攜帶的時間戳,在事件生成時確定。 | 處理亂序事件、處理延遲數據的場景 |
| 處理時間 (Processing Time) | 數據到達 Flink 系統時的系統時間。 | 實時流處理任務、簡單的數據處理場景 |
| 攝取時間 (Ingestion Time) | 數據進入 Flink 系統時所攜帶的時間戳,由 Source 接收到數據時確定。 | 中間場景,在事件時間和處理時間之間權衡 |
flink 有哪些語義
| 流處理語義 | 描述 | 應用場景 |
|---|---|---|
| 精確一次語義 (Exactly-Once) | 每個事件都會被處理且僅被處理一次,不會出現數據丟失或重復處理的情況。 | 金融交易處理、關鍵業務數據處理 |
| 至少一次語義 (At-Least-Once) | 每個事件至少會被處理一次,但可能會出現數據重復處理的情況。 | 實時日志收集、實時指標計算 |
| 無語義 (No Semantics) | 對事件的處理不進行任何語義上的保證,可能會出現數據丟失、重復處理甚至亂序處理的情況。 | 實時推薦系統、實時監控系統 |
flink 任務流程
flink 廣播變量
flink 的operator chain
flink 窗口有哪幾種
| 窗口類型 | 描述 | 使用場景 |
|---|---|---|
| 滾動窗口 (Tumbling Windows) | 固定大小的窗口,按固定的時間間隔對數據流進行切分。 | 對數據流進行固定時間間隔的聚合操作。 |
| 滑動窗口 (Sliding Windows) | 由固定大小和滑動時間間隔組成的窗口,窗口之間可以有重疊部分。 | 對數據流進行連續的聚合操作。 |
| 會話窗口 (Session Windows) | 根據數據流中的會話間隙劃分窗口,一個會話表示一段連續的時間內數據的集合。 | 對非連續數據流進行聚合操作。 |
| 全局窗口 (Global Windows) | 將整個數據流作為一個窗口處理,不對數據進行切分。 | 對整個數據流進行全局聚合操作 |
flink 內存管理
原理
雙流JOIN 實現原理
Flink DataStream 如何實現雙流Join-騰訊云開發者社區-騰訊云
和維度關聯的幾種方案
| 方案 | 描述 | 優點 | 缺點 |
|---|---|---|---|
| 提前加載方案 | 在實現方案啟動時從外部存儲加載維度數據,實現簡單,但不能更新數據 | 實現簡單,適用于靜態數據,不需要頻繁更新的場景 | 不能更新數據,不適用于頻繁變動的維度數據 |
| 定時更新方案 | 定時從外部存儲加載維度數據,然后存儲,定時更新,解決了不能更新數據的問題,但不支持實時更新,有延時,不適用于大數據量 | 可以解決數據不能更新的問題 | 不能實時更新,有延時,不適用于大數據量 |
| 實時更新方案 | 實時從外部存儲查詢維度數據,支持超大數據量,但可能會產生查詢瓶頸,可以使用異步查詢的方案 | 可以支持超大數據量,可以實現實時更新 | 可能會產生查詢瓶頸,實時性取決于外部存儲的性能和網絡延遲 |
| 廣播數據的方案 | 將更新后的數據通過廣播形式和業務數據進行 Join,可以實現實時更新維表 | 可以實時更新維表 | 需要維護廣播數據的一致性和更新機制,可能會增加網絡傳輸和內存消耗 |
| Temporal Table Function 方案 | 在 Flink SQL 中通過 Temporal Table Function 方案實現,可以 join 不同時間的維度數據 | 可以實現不同時間的維度數據的 join | 適用于 Flink SQL,可能需要對應的支持和功能 |
watermark生成策略
| 策略 | 描述 |
|---|---|
| 周期性生成 | 定期生成 Watermark,例如每隔一定時間(如每100毫秒)生成一個 Watermark,表示事件時間已經到達或者超過了這個 Watermark 所表示的時間戳。 |
| 事件驅動生成 | 當特定類型的事件到達時,觸發生成一個 Watermark。例如,在基于窗口操作的情況下,當收到窗口關閉事件時,可以根據這個事件生成一個 Watermark,表示當前處理的時間戳已經到達或者超過了窗口的關閉時間。 |
| 自定義生成策略 | Flink 提供了靈活的 API,允許用戶根據自己的需求實現自定義的 Watermark 生成策略。通過實現 AssignerWithPunctuatedWatermarks 或者 AssignerWithPeriodicWatermarks 接口,用戶可以定義自己的 Watermark 生成邏輯。 |
flink 一次性實現實現
| 實現方式 | 描述 |
|---|---|
| Checkpointing 機制 | Flink 使用 Checkpointing 機制來實現 Exactly-Once 語義。Checkpoint 是 Flink 在作業執行過程中創建的狀態快照,用于保存作業狀態。Flink 在執行任務時周期性地創建 Checkpoint,并將 Checkpoint 存儲到可靠的持久化存儲系統中。當作業失敗或需要恢復時,Flink 可以使用最近的 Checkpoint 來恢復作業狀態,從而實現 Exactly-Once 語義。Checkpointing 機制還包括了分布式快照的協調和一致性保證,確保在失敗時能夠正確恢復狀態。 |
| 狀態管理和恢復 | Flink 通過狀態管理和恢復機制來保證作業狀態的一致性和恢復。Flink 的狀態管理器負責管理作業的狀態,并在需要時將狀態持久化到外部存儲系統中。當作業失敗或需要恢復時,Flink 可以從外部存儲系統中恢復狀態,以確保作業能夠從失敗的地方繼續執行,并且保持一致性 |
flink 端到端一次性實現實現
| 要點 | 描述 |
|---|---|
| Exactly-Once 語義支持 | 使用支持事務性寫入的數據源,如 Apache Kafka、Apache Hudi、Apache HBase 等。確保 Flink 作業的容錯機制能夠正確處理故障情況,如使用 Flink 的 Checkpointing 機制實現狀態的持久化和恢復。 |
| Exactly-Once 語義的語義保證 | 確保所有算子都是冪等的。確保 Flink 作業的狀態管理和狀態恢復機制能夠確保狀態一致性。 |
| 端到端一致性保證 | 保證與外部系統的交互也具有 Exactly-Once 語義,可能需要與外部系統的事務性交互或通過冪等性操作和重試機制來實現。實現適當的錯誤處理機制,包括故障恢復、冪等性操作、重試策略等,以確保在發生故障或異常情況時能夠正確處理并保持端到端的一致性。 |
| 持久化數據源的選擇 | 選擇支持事務性寫入和 Exactly-Once 語義的持久化數據源,如 Apache Kafka、Apache Hudi、Apache HBase 等。這些數據源能夠提供端到端的一致性保證,并且與 Flink 的 Exactly-Once 語義兼容。 |
| 錯誤處理機制 | 實現適當的錯誤處理機制,包括故障恢復、冪等性操作、重試策略等。確保在發生故障或異常情況時能夠正確處理并保持端到端的一致性。 |
flink 撤回語義
Flink 提供了撤回語義(Retraction Semantics),這是指在流式計算中對數據進行修正或撤回的能力。撤回語義通常用于在處理實時數據流時,對先前發出的結果進行更新或刪除。
實現撤回語義的一種方法是使用特殊的數據表示來表示撤回操作。通常,使用特殊的撤回消息來標識先前發出的數據應該被撤回,而不是直接刪除數據。這樣做可以保持數據流的完整性,并允許系統在撤回消息到達時正確地更新之前計算的結果。
flink為啥state用的rocksdb
-
可靠性和持久性:RocksDB 提供了高度可靠的持久化存儲,能夠在發生故障時恢復狀態。這對于需要長時間運行的流處理應用非常重要。
-
性能:RocksDB 是一個高效的鍵值存儲引擎,具有快速的讀取和寫入速度。對于處理大量數據和需要快速訪問狀態的應用場景,RocksDB 提供了比內存狀態后端更好的性能。
-
可擴展性:RocksDB 具有良好的可擴展性,能夠處理大規模的狀態數據。這對于處理高吞吐量和大規模數據的流應用非常重要。
-
內存管理:使用 RocksDB 作為狀態后端可以有效地管理狀態數據的內存,避免了因為狀態數據過大導致內存不足的問題。RocksDB 可以自動將部分數據存儲在磁盤上,從而降低了內存使用量。
-
靈活性:RocksDB 提供了豐富的配置選項和優化參數,可以根據具體的應用需求進行調整和優化,從而提高性能和可靠性。
-
唯一支持增量的狀態后端
Hash shuffle 和sort shuffle
反壓如何分析
Flink反壓原理及分析 - 墨天輪
反壓的實現原理
checkpoint 超時可能是由啥導致的
| 因素 | 描述 |
|---|---|
| 資源不足 | 集群資源不足以處理所有任務和狀態,例如 TaskManager 的資源(如CPU、內存)不足以處理數據流和狀態的快照,或者網絡帶寬不足以傳輸大量的狀態數據。 |
| 狀態大小 | 狀態數據量過大,需要花費較長時間來生成和傳輸快照,可能受到數據流速率、窗口大小、狀態保留策略等因素的影響。 |
| IO負載 | 集群的IO負載較高,可能影響快照的生成和傳輸速度,例如數據存儲和傳輸過程中的瓶頸導致的,如磁盤IO限制或網絡傳輸速度限制。 |
| 網絡延遲 | 集群中節點之間的網絡延遲較高,會影響快照的傳輸速度,可能受到網絡拓撲、節點間距離、網絡擁塞等因素的影響。 |
| 任務處理時間長 | 任務的處理時間超過了配置的 checkpoint 超時時間,可能是由于任務邏輯復雜、處理大量數據或計算密集型操作導致的。 |
| 故障節點 | 在 checkpoint 過程中涉及的節點出現故障或性能下降,例如 TaskManager 節點宕機或網絡故障,可能導致 checkpoint 操作失敗或超時。 |
架構
flink 架構有哪些角色
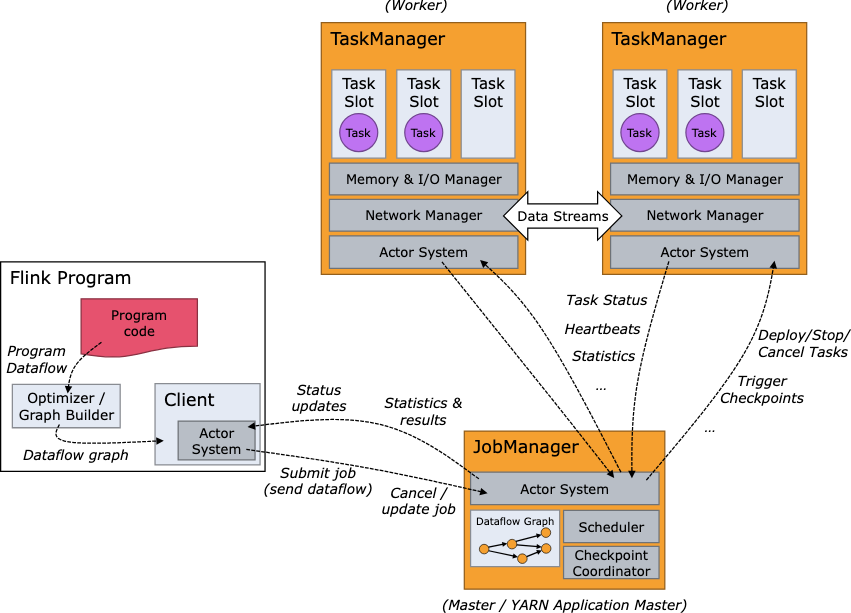
| 組件 | 描述 |
|---|---|
| JobManager | 負責整個作業的調度和協調、管理作業的生命周期(包括啟動、監控和故障處理)、負責觸發和協調作業的 Checkpoint、管理集群的資源(與資源管理器通信進行資源分配)、在高可用性模式下確保集群的高可用性。 |
| TaskManager | 執行實際的數據處理任務、管理任務的狀態(包括數據流程圖、中間結果、緩存的狀態等)、負責數據交換(通過網絡傳輸數據流)、管理本地資源(如 CPU、內存等)、與 JobManager 協調資源的分配和釋放。 |
高可用實現
如何一個架構同時支持流和批
批是流的一種特殊情況
| 組件 | 描述 |
|---|---|
| DataStream API | 用于處理無限和有限的數據流,支持流式和批處理,具有事件時間處理、窗口操作等特性。 |
| 運行時架構 | 分布式流處理引擎,用于處理實時數據流;優化器和執行引擎,針對批處理作業進行優化和執行。 |
| 狀態管理 | 高效可靠的狀態管理機制,用于在流處理和批處理作業中管理狀態。 |
| 任務調度和資源管理 | 負責將作業中的任務分配給集群中的計算資源,并確保任務按照預期的方式執行,同時合理地利用集群資源。 |
應用
flink cdc
? ? ?mysql cdc
? ? ?tidb cdc
? ? ?無鎖算法
? ? ?如何確保順序? ? ??
? ? ?如何確保任務失敗后,可以從中斷節點開始消費
Flink CDC 2.0 正式發布,詳解核心改進 - 知乎
flink sql
flink 如何實現top n 操作
CREATE TABLE transactions (user_id STRING,amount DOUBLE
) WITH ('connector' = 'kafka','topic' = 'transactions_topic','format' = 'json'
);-- 計算每個用戶的交易總額,并獲取Top N
SELECTuser_id,total_amount
FROM (SELECTuser_id,SUM(amount) AS total_amount,ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY SUM(amount) DESC) AS row_numFROMtransactionsGROUP BYuser_id
)
WHERErow_num <= 10;
flink 優化實時任務? ? ?
| 優化方法 | 描述 |
|---|---|
| 狀態后端選擇 | 根據任務需求選擇適合的狀態后端,如RocksDB或內存 |
| 并行度調整 | 根據數據量和任務復雜度調整并行度以提高性能 |
| 窗口優化 | 考慮使用滑動窗口、會話窗口等優化窗口設計 |
| 算子鏈優化 | 合并多個算子以減少狀態轉換和數據序列化的開銷 |
| 網絡通信優化 | 減少網絡通信開銷,如使用本地連接和網絡拓撲優化 |
| 內存管理優化 | 優化內存分配和管理以減少GC開銷 |
| 數據分區優化 | 合理分區數據以提高并行度和減少數據傾斜 |
| 代碼優化 | 優化代碼邏輯和數據處理邏輯以提高執行效率 |
| 任務調度優化 | 調整任務調度策略以更好地利用資源和平衡負載 |
:Microcontroller Driver)




)





)





![【Bugs】class path resource [xxx.xml] cannot be opened because it does not exist](http://pic.xiahunao.cn/【Bugs】class path resource [xxx.xml] cannot be opened because it does not exist)

