題目:SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
地址:spla-tam.github.io
機構:CMU(卡內基梅隆大學)、MIT(美國麻省理工)

總結:SplaTAM,一個新的SLAM系統,利用3D Gaussian Splatting作為底層map表示,渲染和優化更快,明確的地圖空間范圍,和流線型的地圖稠密化。可以同時優化pose估計、場景重建和新視圖合成。
文章目錄
- 摘要
- 一、引言
- 二、相關工作
- 2.1 密集SLAM的傳統方法
- 2.2 預訓練的神經網絡表示
- 2.3 隱式場景表示
- 2.4 3D Gaussian Splatting(簡稱GS)
- 三、方法
- 3.1 高斯地圖表示
- 3.2 通過 Splatting的可微渲染
- 3.3 SLAM 系統
- 3.4 初始化
- 3.5 像機跟蹤
- 3.6 高斯稠密化
- 3.7 高斯地圖更新
- 四、實驗
- 4.1 數據集和驗證設置
- 4.2 相機pose估計實驗
- 4.3 高斯圖重建與攝像機pose的可視化
- 4.4 渲染質量
- 4.5 顏色和深度損失消融
- 4.6 局限性
- 總結
摘要
提示:這里可以添加本文要記錄的大概內容:
??密集的同步定位和建圖(SLAM)是具體化場景理解的關鍵。最近的工作表明,三維高斯使用多個姿態相機,高質量重建和實時渲染場景。我們首次表明,用三維高斯表示一個場景,可以使用無pose的單目RGB-D像機實現密集的SLAM。SplaTAM,解決了輻射場的表示的局限性,包括 快速渲染和優化,確定區域是否已經被map的能力,以及通過添加高斯的結構化地圖擴展 。我們 采用了一個在線跟蹤和建圖框架,同時裁剪它,以專門使用底層的高斯表示和通過可微渲染的silhouette(輪廓)引導的優化 。實驗表明,SplaTAM在相機pose估計、地圖構建和新視圖合成方面達到了高達2×的最先進的性能,同時允許實時渲染高分辨率的密集3D地圖。
一、引言
?? 視覺同時定位和建圖(SLAM)——估計視覺傳感器pose和環境地圖的任務——是視覺或機器人系統在以前看不見的3D環境中操作的基本能力。在過去的30年里,SLAM的研究廣泛地集中在地圖表示的問題上——導致了各種稀疏的[2,3,7,23]、密集的[4,6,8,13,15,25,26,34,41,42]和神經場景表示[21,29,30,37,45,54]。映射表示(Map representation)是一個基本的選擇,它會極大地影響到SLAM系統中的每個處理塊的設計,以及依賴于SLAM的輸出的下游任務。
??就密集的視覺SLAM而言,最成功的手工表示是點、surfels/flats 和符號距離場。 雖然基于這種地圖表示的系統在過去幾年中已經成熟到生產水平,但仍有重大的缺陷需要解決。跟蹤顯式表示的關鍵是依賴于豐富的三維幾何特征和高幀率捕獲的可用性。此外,這些方法只能可靠地解釋場景中觀察到的部分;許多應用程序,如混合現實和高保真度3D捕獲,需要的技術也能夠解釋/合成未觀察到的/新的相機視點
??手工表示的缺點,加上輻射場表示的高質量圖像的出現,推動了將場景編碼到神經網絡的權重空間的方法。基于輻射場的SLAM算法[30,53]受益于高保真的全局地圖和圖像重建損失,這些損失通過可微渲染捕獲密集的光度信息。然而,目前的方法使用隱式神經表示來模擬體輻射場,在SLAM中導致許多問題——計算效率低,不容易編輯,不明確地建模空間幾何,以及災難性遺忘。
??“ 如何使用顯式的體積表示來設計一個SLAM解決方案 ?”我們使用一個基于三維高斯的輻射場,來Splat(渲染),跟蹤,和建圖SLAM。有以下好處:
- 快速渲染,實現豐富的優化
Gaussian Splatting高達400 FPS的渲染速度,是隱式的替代方案,關鍵因素是3Dprimitives 的柵格化。SplaTAM做了簡單修改,,包括去除與視圖相關的外觀 和 使用各向同性高斯分布。此外,這允許我們實時使用密集光度損失的SLAM,而傳統的和隱式映射表示分別依賴于稀疏的三維幾何特征或像素采樣來保持效率。
- 可以顯式延申空間的地圖
通過只在觀察到的部分場景中添加高斯分布,可以很容易地控制現有地圖的空間邊界。給定一個新的圖像幀,這允許人們通過渲染一個silhouette(輪廓)來有效地識別場景的哪些部分是新的內容(在地圖的空間邊界之外)。這對于相機跟蹤至關重要,因為我們只想將場景的映射區域與新圖像進行比較。這對于隱式映射表示來說是困難的,因為網絡在對未映射空間的基于梯度的優化過程中會受到全局變化的影響
- 顯式地圖
通過簡單地添加更多的高斯分布,增加map的容量。顯式的體積表示能夠編輯場景的部分,同時仍然允許逼真的渲染。隱式方法不能輕易地增加它們的能力或編輯它們所表示的場景
- 參數的直接梯度流
場景是用物理三維位置、顏色和大小的高斯表示的,在參數和渲染之間有一個直接的、幾乎線性的(投影的)梯度流。因為相機的運動可以被認為是保持相機的靜止和移動的場景,我們也有一個直接的梯度到相機的參數,從而實現快速優化。基于神經的表示沒有這一點,因為梯度需要流過(可能有很多)非線性神經網絡層。
??圖1在模擬和真實數據的實驗結果:

二、相關工作
??簡要回顧使用密集SLAM的各種方法,特別是最近利用過擬合神經網絡中編碼的隱式表示進行跟蹤和映射的方法。
2.1 密集SLAM的傳統方法
??傳統的密集SLAM方法探索了各種顯式表示,包括2.5D圖像、(截斷)符號距離函數、高斯混合模型[9,10]和圓形曲面(平面)。與這項工作特別相關的是Keller等人[13]提出的基于點的融合,它在其映射表示中使用了一個flat作為原子單元。flat,或surfels,是通過RGB-D圖像輸入進行實時優化的彩色圓形表面元素。每個surfel 都能夠編碼一個表面上的多個點,允許更緊湊的映射表示。Surfels很容易被柵格化,就像[33,42]中通過可微柵格化跟蹤相機的pose。雖然上述的SLAM方法不假定可見性函數是可微的,但存在現代可微柵格器,使梯度流可以通過depth discontinuities[49]。本文使用三維高斯形式的volumetric(相對于僅表面)場景表示,這可以實現快速和準確的跟蹤和映射。
2.2 預訓練的神經網絡表示
??該方法已經與傳統的SLAM技術集成,主要集中于預測RGB圖像的深度。這些方法從直接將神經網絡的深度預測集成到SLAM [38]中,學習可解碼的變分自動編碼器,到同時學習預測深度成本量和跟蹤的方法。
2.3 隱式場景表示
??iMAP [37]首先使用神經隱式表示進行跟蹤和映射。為了提高可伸縮性,NICE-SLAM [53]提出了使用分層的多特征網格。在類似的線上,與[25,27]相比,iSDF [28]使用隱式表示來有效地計算有符號的距離。在此之后,[11,18,19,22,29,31,40,50,54]的一些工作最近通過多種方式推進了基于隱式的SLAM——通過持續學習(體驗回放)減少災難性遺忘,捕獲語義,合并不確定性,使用高效分辨率hash-grid和編碼,以及使用改進的損失。最近,Point-SLAM [30]提出了一種替代路線,類似于[44],通過使用神經點云,并使用特征插值進行體積渲染,提供了更好的三維重建,特別是對于機器人技術。然而,與其他隱式表示一樣,體積射線采樣極大地限制了其效率,因此求助于稀疏像素集的優化,而不是每像素密集的光度誤差。相反,SplaTAM的顯式體積輻射模型利用了快速的柵格化,使其能夠完全使用每像素密集的光度誤差。
2.4 3D Gaussian Splatting(簡稱GS)
??最近,3D高斯算法已經成為一種很有前途的3D場景表示[14,16,17,39],特別是能夠通過Splatting[14]極快地渲染。該方法也被擴展到具有密集6-DOF運動[20]的動態場景[20,43,46,47]模型。這種針對靜態和動態場景的方法都要求每個輸入幀都有一個精確的已知的6-DOF攝像機姿態,以成功地優化表示。SplaTAM首次消除了這個約束,同時估計相機的pose,同時也擬合潛在的高斯表示。
三、方法
??SplaTAM是第一個使用三維GS的密集RGB-D SLAM解決方案。通過將世界建模為可以渲染成高保真彩色和深度圖像的三維高斯圖像的集合,能夠直接使用可微渲染和基于梯度的優化,來優化每一幀的相機pose和一個 underlying volumetric discretized世界地圖。
3.1 高斯地圖表示
??splatam將場景的底層地圖表示為一組三維高斯分布,基于原始GS進行了一些簡化, 只使用與視圖無關的顏色,并迫使高斯分布是各向同性的。這意味著每個高斯值只由8個值參數化:3個為其RGB顏色c,3個為其中心位置μ∈R3,一個為其半徑r,一個為其不透明度o∈[0,1]。根據由高斯分布的不透明度加權的標準(非歸一化)高斯方程,每個高斯分布會影響三維空間x∈r3中的一個點:
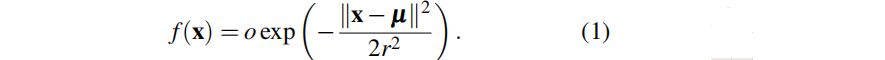
3.2 通過 Splatting的可微渲染
??方法的核心是能夠將底層高斯地圖中的高保真顏色、深度和輪廓圖像渲染到任何可能的相機參考幀中。這種 可微渲染允許我們直接計算底層場景表示(高斯)和相機參數的梯度,利用渲染和真實的RGB-D幀之間的誤差,并更新高斯和相機參數來減少誤差。
??GS渲染RGB圖像如下:給定一個三維高斯和相機pose的集合,首先從前到后對所有高斯進行排序。通過在像素空間中,依次α-合成每個高斯分布的二維投影,來渲染RGB圖像。
像素 p =(u, v) 渲染顏色公式:
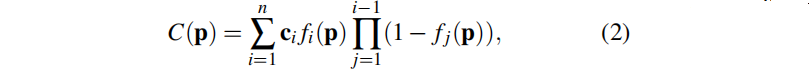
其中,fi(p) 的計算方法如等式(1),但在像素空間中splat的二維高斯的 μ 和 r 為:
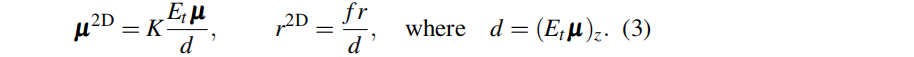
這里,K是相機內參,Et 是第 t 幀處的相機旋轉和平移的外參,f 是焦距(已知),d 是相機坐標下的第 i 個高斯值的深度。
我們提出類似的深度渲染(可以與輸入深度圖比較,返回相對于3D地圖的梯度):
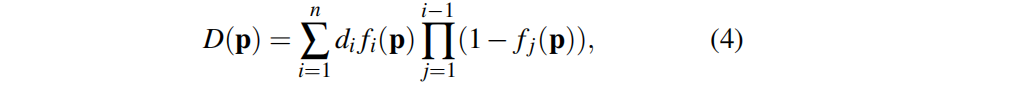
??我們還渲染一個silhouette(輪廓)圖像來確定可見性——例如,一個像素是否包含來自當前地圖的信息:
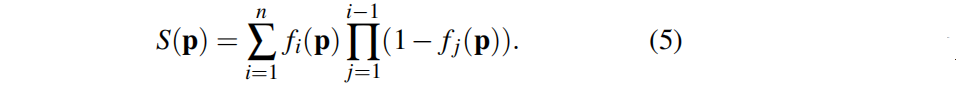
3.3 SLAM 系統

??我們從高斯表示和可微渲染器建立了一個SLAM系統。先簡要概述:假設我們有一個現有的地圖(通過一組三維高斯分布表示),它已經擬合了第 1 幀到 t幀。給定一個新的RGB-D幀 t+1,SLAM系統執行以下步驟(見圖2):
1.像機跟蹤。我們利用t+1 幀的相機pose參數,最小化RGB-D序列的圖像和深度重建誤差,但只評估可見輪廓內的像素的誤差
2. 高斯密度。根據渲染的輪廓和輸入深度,向地圖中添加新的高斯
3. 地圖更新。給定從幀1到幀t+1的相機pose,通過最小化所有圖像的RGB和深度誤差來更新高斯分布參數。在實踐中,為了保持批處理大小的可管理性,將對選好的,與最近幀重疊的關鍵幀子集進行優化。
3.4 初始化
??初始化。第一幀跳過跟蹤步驟,將相機pose設置為identity。在稠密化步驟中,由于渲染的輪廓為空,所有像素都用于初始化新的高斯。具體來說,對于每個像素,我們添加一個顏色為像素的新高斯,中心位置為投影的像素深度,不透明度0.5,半徑等于一個像素半徑投影到2d圖像的深度除以焦距: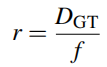
3.5 像機跟蹤
??相機跟蹤:旨在估計當前輸入的在線RGB-D圖像的相機pose。通過對相機中心+四元數空間中姿態參數的恒定速度正向投影,為一個新的時間步初始化相機pose。例如,初始化(公式7)
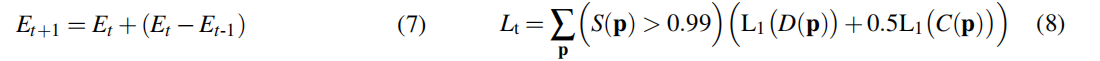
然后,通過基于梯度的優化,通過可微分地渲染RGB,深度和輪廓圖,并更新相機參數,同時保持高斯參數不變,以最小化損失(公式8):
??以上為深度和顏色渲染上的L1損失,顏色的權重減少了一半。只應用以上損失于通過輪廓圖渲染的像素。輪廓圖捕獲了地圖的不確定性。這對于跟蹤新的相機姿勢非常重要,因為新幀通常包含在我們的地圖中尚未捕獲或經過良好優化的新信息。如果一個像素沒有Grountruth深度,那么L1損失為0。
??
3.6 高斯稠密化
??稠密化的目的是:為每個進入的在線,在地圖中初始化新的高斯分布。在跟蹤之后,我們對這一幀的相機pose有了一個準確的估計,對于深度圖像,我們對高斯分布在場景中的位置有了好的估計。然而,當前的高斯已經準確地表示場景幾何時,不需要添加高斯,因此,我們創建了一個密集化mask來確定哪些像素應該被密集化:
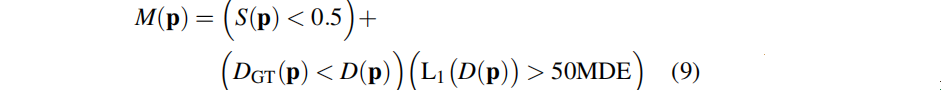
??此mask指示地圖密度不足的地方(S < 0.5),或者在當前估計的幾何圖形前面應該有新的幾何圖形(地面真實深度在預測深度的前面,并且深度誤差大于中值深度誤差(MDE)的50倍)。對于每個像素,基于這個mask,添加一個新的高斯進行第一幀初始化。
??
3.7 高斯地圖更新
??旨在基于估計的在線相機pose下,更新三維高斯地圖的參數。這也是通過可微渲染和基于梯度的優化來實現的,然而與跟蹤不同的是,相機pose是固定的,高斯分布的參數被更新。
??這相當于對已知pose的圖像擬合輻射場的“經典”問題。然而,我們做了兩個重要的修改。1.不是從頭開始,而是從最近構建的地圖中預熱,開始優化。2.不優化所有之前的(關鍵)幀,而是選擇了可能影響新添加的高斯分布的幀。我們將每n幀保存為關鍵幀,并選擇k幀進行優化,包括當前幀、最近的關鍵幀,以及k?2之前與當前幀重疊最高的關鍵幀。重疊是通過取當前幀深度圖的點云,并確定每個關鍵幀的錯誤點數來確定的
??階段優化與跟蹤過程中類似的損失,不使用輪廓mask(因為要優化所有的像素)。此外,我們在RGB渲染中添加了一個SSIM損失,并剔除了不透明度接近0的無用高斯分布。
四、實驗
4.1 數據集和驗證設置
??在四個數據集上評估了我們的方法: ScanNet++ 、Replica、TUM-RGBD 和原始的ScanNet 。選擇后三種方法是為了遵循以往基于輻射場的SLAM方法Point-SLAM [30]和NICE-SLAM [53]的評價程序。然而,我們也添加了ScanNet++ [48]評估,因為其他三個基準測試中都沒有一個能夠評估新視圖上的渲染質量,并且只評估訓練視圖上的攝像機姿態估計和渲染。
??Replica是最簡單的基準測試,因為它包含合成場景,高度精確和完整的(合成)深度地圖,以及連續的相機姿態之間的小位移。TUM-RGBD 和原始的ScanNet比較困難,特別是對于密集的方法,因為RGB和深度圖像質量都很差,因為它們都使用舊的低質量的相機。深度圖像非常稀疏,缺少大量的信息,并且彩色圖像有非常多的運動模糊量。對于ScanNet++ [48],我們使用來自兩個場景的DSLR捕獲,在這些場景中存在完全密集的軌跡。與其他基準測試相比,ScanNet++的顏色和深度圖像是非常高的質量,并為每個場景提供了第二個捕獲循環來評估完全新穎的保留視圖。然而,每個相機的姿勢之間相距很遠,這使得姿勢估計非常困難。在ScanNet++上,連續幀之間的差異與復制品上的30幀間隙大致相同。對于除ScanNet++之外的所有基準測試,我們從Point-SLAM [30]中獲取基線數字。類似于Point-SLAM,我們對每5幀的訓練視圖渲染基準進行評估。此外,對于所有與之前基線的比較,我們將結果表示為3個種子(0-2)的平均值,并使用種子0進行消融
??評價指標。為了測量RGB渲染性能,我們使用了PSNR、SSIM和LPIPS。對于深度渲染性能,我們使用深度L1損失。對于攝像機姿態估計跟蹤,我們使用平均絕對軌跡誤差(ATE RMSE)
??Baselines。我們比較的主要基線方法是Point-SLAM [30],因為它是以前的基于密集輻射場的SLAM的最先進的(SOTA)方法。我們還與較舊的密集SLAM方法進行了比較,如NICE-SLAM [53]、Vox-Fusion [45]和適當的ESLAM [12]。在TUM-RGBD上,我們還比較了三種傳統的SLAM系統:Kintinuous[41]、ElasticFusion[42]和ORB-SLAM2 [23]。在困難的ScanNet++上,除了點-SLAM外,我們還評估了ORB-SLAM3 [3]作為一個具有代表性的基于特征的傳統SLAM系統。
4.2 相機pose估計實驗
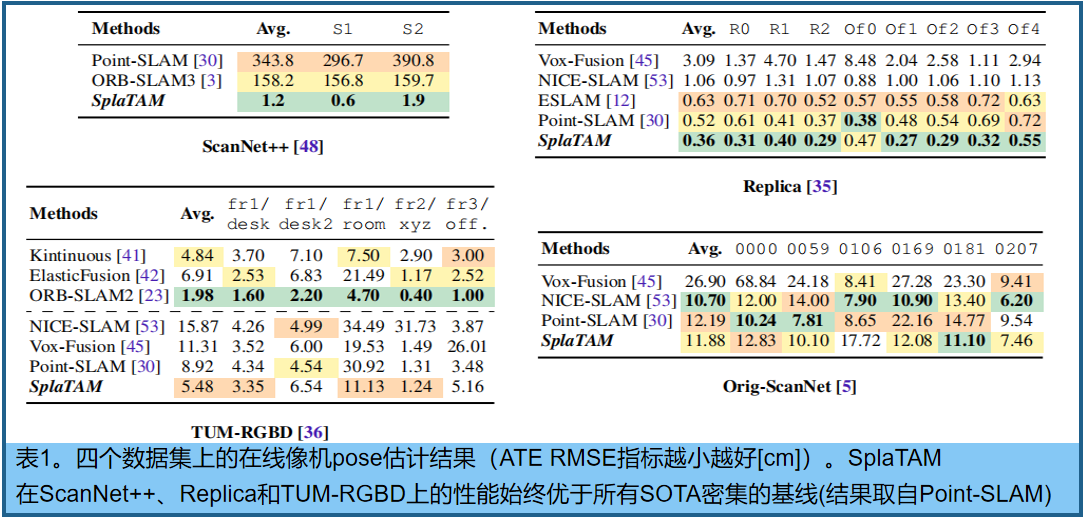
??在ScanNet++ [48]上,SOTA SLAM接近點SLAM[30]和ORB-SLAM3 [3](RGB-D變體)由于相鄰攝像機之間的位移,完全無法正確跟蹤攝像機的姿態,因此給出非常大的姿態估計誤差。特別是,對于ORB-SLAM3,我們觀察到無紋理的ScanNet++掃描由于缺乏特性而導致跟蹤多次重新初始化。相比之下,我們的方法成功地在兩個序列上跟蹤攝像機,平均軌跡誤差僅為1.2厘米
??在相對簡單的合成Replica數據集上,即之前事實上的評估基準,我們的方法將比之前的SOTA [30]的軌跡誤差減少了30%以上,從0.52cm減少到0.36cm。
??在TUM-RGBD [36]上,由于深度傳感器信息差(非常稀疏)和RGB圖像質量差(極高的運動模糊),所有的體積方法都非常困難。然而,與這類[30,53]方法相比,我們的方法仍然明顯優于這類[30]中先前SOTA的軌跡誤差減少了近40%,從8.92cm減少到5.48cm。然而,在這個基準測試中,基于特征的稀疏跟蹤方法,如ORB-SLAM2 [23],仍然優于密集的方法
??在ScanNet++上的結果表明,如果有高質量的干凈輸入圖像,我們的方法可以成功地和準確地執行SLAM,即使在相機位置之間的巨大運動。
4.3 高斯圖重建與攝像機pose的可視化
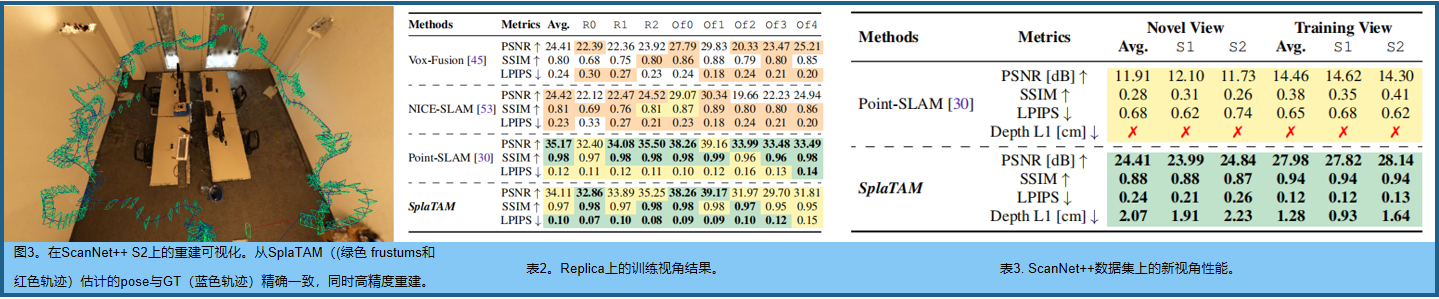
??圖3展示了來自ScanNet++在兩個序列上重建的高斯圖的可視化結果。我們還展示了相機的軌跡和相機的pose frustums,由我們的方法估計的這兩個序列疊加在地圖上。人們可以很容易地看到經常發生在連續相機姿態之間的大位移,這是一個非常困難的SLAM基準,然而我們的方法卻非常準確地解決了這個問題。
4.4 渲染質量
??表2在Replica的輸入視圖上評估了渲染質量。我們的方法獲得了與PointSLAM 相似的PSNR、SSIM和LPIPS結果,盡管比較不公平,因為PointSLAM具有不公平的優勢,因為它將這些圖像的真實深度作為輸入,以便進行渲染。
??個更好的評價是評價新視圖渲染。然而,目前所有的SLAM基準測試并沒有一組與SLAM算法估計的相機軌跡分開的保留圖像,因此它們不能用于此目的。因此,我們使用新的高質量ScanNet++數據集建立了一個新的基準, 新視圖和訓練視圖渲染的結果可以在表3中找到。我們的方法獲得了一個良好的新視圖合成結果,平均為24.41 PSNR,在27.98 PSNR的訓練視圖上略高。請注意,這是在估計未知的相機pose時,即,完全未曝光的新視圖合成結果。由于Point-SLAM [30]不能成功地估計相機的姿態,因此它也完全不能完成新視圖合成的任務
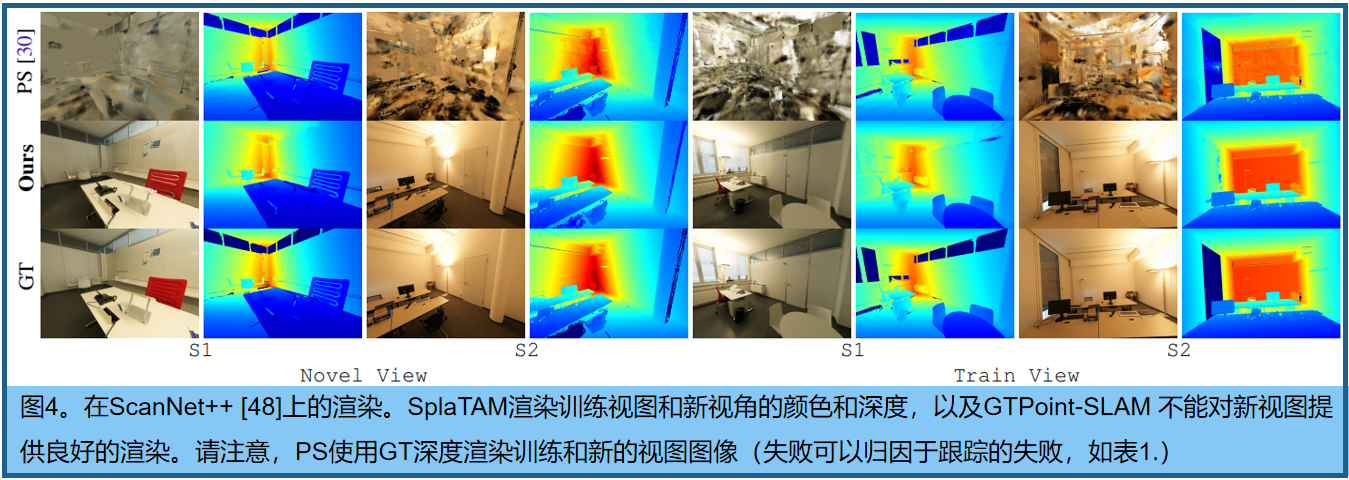
??新視圖和訓練視圖渲染的結果可以在表3中找到。我們的方法獲得了一個良好的新視圖合成結果,平均為24.41 PSNR,在27.98 PSNR的訓練視圖上略高。請注意,這是在估計未知的相機姿態時,即,完全未曝光的新視圖合成結果。由于Point-SLAM [30]不能成功地估計相機的pose,因此它也完全不能完成新視圖合成的任務
4.5 顏色和深度損失消融

4.6 局限性
??雖然SplaTAM達到了最先進的性能,但我們發現我們的方法對運動模糊、大深度噪聲和侵略性旋轉顯示出一定的敏感性。我們認為,一個可能的解決辦法是暫時模擬這些影響,并希望在今后的工作中解決這一問題。此外,SplaTAM可以通過像OpenVDB [24]這樣的高效表示來擴展到大規模場景。最后,我們的方法需要已知的相機內部信息和密集的深度作為執行SLAM的輸入,而刪除這些依賴關系是未來的一個有趣的途徑。
??
??
總結
??SplaTAM,一個新的SLAM系統,利用三維GS輻射場作為其底層地圖表示,使更快的渲染和優化,明確的地圖空間范圍,和流線型的地圖稠密化。我們證明了它在實現相機pose估計、場景重建和新視圖合成的最新結果方面的有效性。







Linux下搭建私有代碼倉庫Gitblit的安裝和使用詳解)



)
)




階段測試題見資料)

