前言:本篇文章主要從代碼實現角度研究 Bert Encoder和Transformer Encoder 有什么不同?應該可以幫助你:
- 深入了解Bert Encoder 的結構實現
- 深入了解Transformer Encoder的結構實現
本篇文章不涉及對注意力機制實現的代碼研究。
注:本篇文章所得出的結論和其它文章略有不同,有可能是本人代碼理解上存在問題,但是又沒有找到更多的文章加以驗證,并且代碼也檢查過多遍。
觀點不太一致的文章:bert-pytorch版源碼詳細解讀_bert pytorch源碼-CSDN博客?這篇文章中,存在 “這個和我之前看的transformers的殘差連接層差別還挺大的,所以并不完全和transformers的encoder部分結構一致。” 但是我的分析是:代碼實現上不太一樣,但是本質上沒啥不同,只是Bert Encoder在Attention之后多了一層Linear。具體分析過程和結論可以閱讀如下文章。
如有錯誤或問題,請在評論區回復。
1、研究目標
這里主要的觀察對象是BertModel中Bert Encoder是如何構造的?從Bert Tensorflow源碼,以及transformers庫中源碼去看。
然后再看TransformerEncoder是如何構造的?從pytorch內置的transformer模塊去看。
最后再對比不同。
2、tensorflow中BertModel主要代碼如下
class BertModel(object):def __init__(...):...得到了self.embedding_output以及attention_mask# transformer_model就代表了Bert Encoder層的所有操作self.all_encoder_layers = transformer_model(input_tensor=self.embedding_output, attention_mask=attention_mask,...)# 這里all_encoder_layers[-1]是取最后一層encoder的輸出self.sequence_output = self.all_encoder_layers[-1]...pooler層,對 sequence_output中的first_token_tensor,即CLS對應的表示向量,進行dense+tanh操作with tf.variable_scope("pooler"):first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)self.pooled_output = tf.layers.dense(first_token_tensor,config.hidden_size,activation=tf.tanh,kernel_initializer=create_initializer(config.initializer_range))def transformer_model(input_tensor, attention_mask=None,...):...for layer_idx in range(num_hidden_layers):# 如下(1)(2)(3)就是每一層Bert Encoder包含的結構和操作with tf.variable_scope("layer_%d" % layer_idx):# (1)attention層:主要包含兩個操作,獲取attention_output,對attention_output進行dense + dropout + layer_normwith tf.variable_scope("attention"):# (1.1)通過attention_layer獲得 attention_outputattention_output# (1.2)output層:attention_output需要經過dense + dropout + layer_norm操作with tf.variable_scope("output"):attention_output = tf.layers.dense(attention_output,hidden_size,...)attention_output = dropout(attention_output, hidden_dropout_prob)# “attention_output + layer_input” 表示 殘差連接操作attention_output = layer_norm(attention_output + layer_input)# (2)intermediate中間層:對attention_output進行dense+激活(GELU)with tf.variable_scope("intermediate"):intermediate_output = tf.layers.dense(attention_output,intermediate_size,activation=intermediate_act_fn,)# (3)output層:對intermediater_out進行dense + dropout + layer_normwith tf.variable_scope("output"):layer_output = tf.layers.dense(intermediate_output,hidden_size,kernel_initializer=create_initializer(initializer_range))layer_output = dropout(layer_output, hidden_dropout_prob)# "layer_output + attention_output"是殘差連接操作layer_output = layer_norm(layer_output + attention_output)all_layer_outputs.append(layer_output)3、pytorch的transformers庫中的BertModel主要代碼;
- 其中BertEncoder對應要研究的目標
class BertModel(BertPreTrainedModel):def __init__(self, config, add_pooling_layer=True):self.embeddings = BertEmbeddings(config)self.encoder = BertEncoder(config)self.pooler = BertPooler(config) if add_pooling_layer else Nonedef forward(...):# 這是嵌入層操作embedding_output = self.embeddings(input_ids=input_ids,position_ids=position_ids,token_type_ids=token_type_ids,...)# 這是BertEncoder層的操作encoder_outputs = self.encoder(embedding_output,attention_mask=extended_attention_mask,...)# 這里encoder_outputs是一個對象,encoder_outputs[0]是指最后一層Encoder(BertLayer)輸出sequence_output = encoder_outputs[0]# self.pooler操作是BertPooler層操作,是先取first_token_tensor(即CLS對應的表示向量),然后進行dense+tanh操作# 通常pooled_output用于做下游分類任務pooled_output = self.pooler(sequence_output) if self.pooler is not None else Noneclass BertEncoder(nn.Module):def __init__(self, config):...self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])...def forward(...):for i, layer_module in enumerate(self.layer):# 元組的append做法,將每一層的hidden_states保存到all_hidden_states;# 第一個hidden_states是BertEncoder的輸入,后面的都是每一個BertLayer的輸出if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)...# 執行BertLayer的forward方法,包含BertAttention層 + BertIntermediate中間層 + BertOutput層layer_outputs = layer_module(...)# 當前BertLayer的輸出hidden_states = layer_outputs[0]# 添加到all_hidden_states元組中if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)class BertLayer(nn.Module):def __init__(self, config):self.attention = BertAttention(config)self.intermediate = BertIntermediate(config)self.output = BertOutput(config)def forward(...):# (1)Attention是指BertAttention# BertAttention包含:BertSelfAttention + BertSelfOutput# BertSelfAttention包括計算Attention+Dropout# BertSelfOutput包含:dense+dropout+LayerNorm,LayerNorm之前會進行殘差連接self_attention_outputs = self.attention(...)# self_attention_outputs是一個元組,取[0]獲取當前BertLayer中的Attention層的輸出attention_output = self_attention_outputs[0]# (2)BertIntermediate中間層包含:dense+gelu激活# (3)BertOutput層包含:dense+dropout+LayerNorm,LayerNorm之前會進行殘差連接# feed_forward_chunk的操作是:BertIntermediate(attention_output) + BertOutput(intermediate_output, attention_output)# BertIntermediate(attention_output)是:dense+gelu激活# BertOutput(intermediate_output, attention_output)是:dense+dropout+LayerNorm;# 其中LayerNorm(intermediate_output + attention_output)中的“intermediate_output + attention_output”是殘差連接操作layer_output = apply_chunking_to_forward(self.feed_forward_chunk, ..., attention_output)4、pytorch中內置的transformer的TransformerEncoderLayer主要代碼
- torch.nn.modules.transformer.TransformerEncoderLayer
class TransformerEncoderLayer(Module):'''Args:d_model: the number of expected features in the input (required).nhead: the number of heads in the multiheadattention models (required).dim_feedforward: the dimension of the feedforward network model (default=2048).dropout: the dropout value (default=0.1).activation: the activation function of intermediate layer, relu or gelu (default=relu).Examples::>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)>>> src = torch.rand(10, 32, 512)>>> out = encoder_layer(src)'''def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu"):super(TransformerEncoderLayer, self).__init__()self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout)# Implementation of Feedforward modelself.linear1 = Linear(d_model, dim_feedforward)self.dropout = Dropout(dropout)self.linear2 = Linear(dim_feedforward, d_model)self.norm1 = LayerNorm(d_model)self.norm2 = LayerNorm(d_model)self.dropout1 = Dropout(dropout)self.dropout2 = Dropout(dropout)self.activation = _get_activation_fn(activation)def forward(...):# 過程:# (1)MultiheadAttention操作:src2 = self.self_attn# (2)Dropout操作:self.dropout1(src2)# (3)殘差連接:src = src + self.dropout1(src2)# (4)LayerNorm操作:src = self.norm1(src)# 如下是FeedForword:做兩次線性變換,為了更深入的提取特征# (5)Linear操作:src = self.linear1(src)# (6)RELU激活(默認RELU)操作:self.activation(self.linear1(src))# (7)Dropout操作:self.dropout(self.activation(self.linear1(src)))# (8)Linear操作:src2 = self.linear2(...)# (9)Dropout操作:self.dropout2(src2)# (10)殘差連接:src = src + self.dropout2(src2)# (11)LayerNorm操作:src = self.norm2(src)src2 = self.self_attn(src, src, src, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src = self.norm1(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))src = src + self.dropout2(src2)src = self.norm2(src)return src5、區別總結
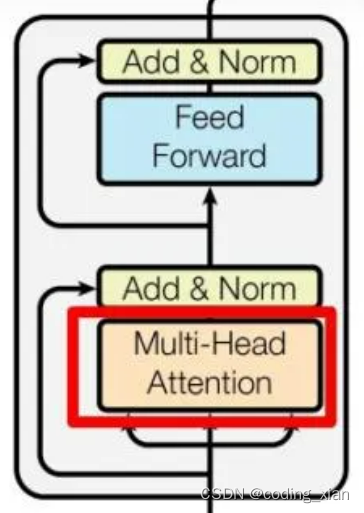
????????Transformer Encoder的結構如上圖所示,代碼也基本和上圖描述的一致,不過代碼中在Multi-Head Attention和Feed Forward之后都存在一個Dropout操作。(可以認為每層網絡之后都會接一個Dropout層,是作為網絡模塊的一部分)
可以將Transformer Encoder過程表述為:
(1)MultiheadAttention + Dropout + 殘差連接 + LayerNorm
(2)FeedForword(Linear + RELU + Dropout + Linear + Dropout) + 殘差連接 + LayerNorm;Transformer默認的隱含層激活函數是RELU;
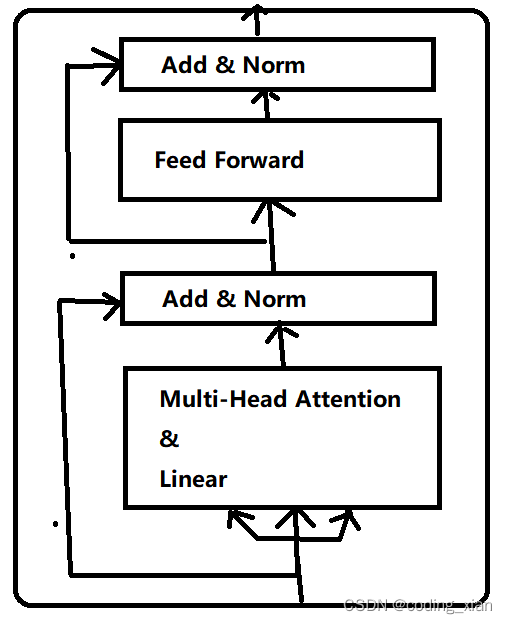
可以將 Bert Encoder過程表述為:
(1)BertSelfAttention: MultiheadAttention + Dropout
(2)BertSelfOutput:Linear+ Dropout + 殘差連接 + LayerNorm; 注意:這里的殘差連接是作用在BertSelfAttention的輸入上,不是Linear的輸入。
(3)BertIntermediate:Linear + GELU激活
(4)BertOutput:Linear + Dropout + 殘差連接 + LayerNorm;注意:這里的殘差連接是作用在BertIntermediate的輸入上,不是Linear的輸入;
進一步,把(1)(2)合并,(3)(4)合并:
(1)MultiheadAttention + Dropout + Linear + Dropout + 殘差連接 + LayerNorm
(2)FeedForword(Linear + GELU激活 + Linear + Dropout) + 殘差連接 + LayerNorm;Bert默認的隱含層激活函數是GELU;
所以,Bert Encoder和Transformer Encoder最大的區別是,Bert Encoder在做完Attention計算后,還會用一個線性層去提取特征,然后才進行殘差連接。其次,是FeedForword中的默認激活函數不同。Bert Encoder圖結構如下:
Bert 為什么要這么做?或許是多一個線性層,特征提取能力更強,模型表征能力更好。
GELU和RELU:GELU是RELU的改進版,效果更好。
Reference
- GeLU、ReLU函數學習_gelu和relu-CSDN博客






用法詳解)




![LeetCode 刷題 [C++] 第763題.劃分字母區間](http://pic.xiahunao.cn/LeetCode 刷題 [C++] 第763題.劃分字母區間)







