拓展:賈揚清:深度學習框架caffe(Convolutional Architecture for Fast Feature Embedding)
主要貢獻:
深度可分離卷積(Depthwise separable convolution)+逐點卷積(Pointwise convolution):保證各類視覺任務準確度不變的條件下,將計算量、參數量壓縮30倍。引入網絡寬度和輸入圖像分辨率超參數,進一步控制網絡尺寸。
拓展:空間可分離卷積(效果遠遠不足深度可分離卷積)
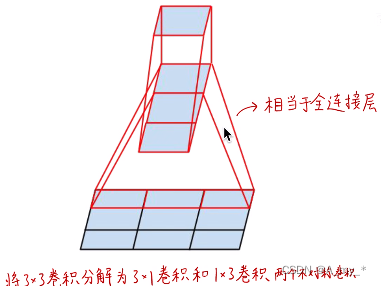
傳統卷積:一個卷積核生成一個feature?map(卷積核的通道數和輸入的通道數應相同,各通道卷積后再對應相加,生成一個feature?map),Dout個卷積核生成Dout個feature?map,即輸出的通道數為Dout。要使輸出與輸入通道數相同,則卷積核個數應與輸入通道數相同,即下一步卷積核的個數應為Dout,其中一個卷積核的通道數也應為Dout。
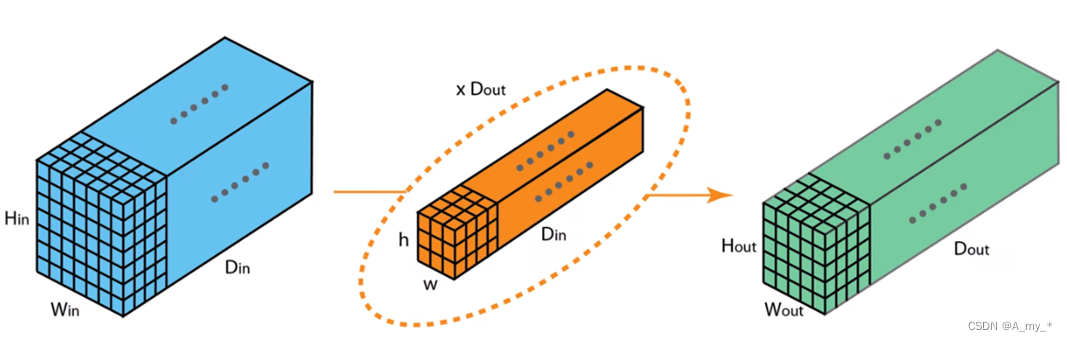
深度可分離卷積+逐點卷積:之前是一個卷積核負責三個通道,現在是每個卷積核只負責一個通道。Depthwise只處理長寬方向的空間信息,Pointwise只處理跨通道的信息融合
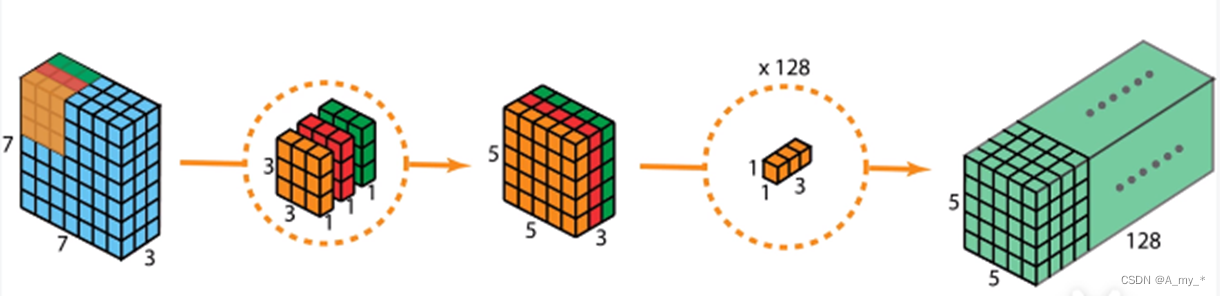
拓展:Xception中先Pointwise再Depthwise(區別不大)
計算量、參數量分析:

?
? ? ? ? ? ??![]()
?
還引入兩個控制網絡大小的超參數:a,網絡寬度超參數,控制卷積核的個數;p,輸入圖像分辨率超參數,控制輸入圖像的尺寸,進而控制中間層feature?map的大小。那么所有的M、N乘a,所有乘p,計算量、參數量變得更小
![]() ? ?
? ?
?計算性能分析:
?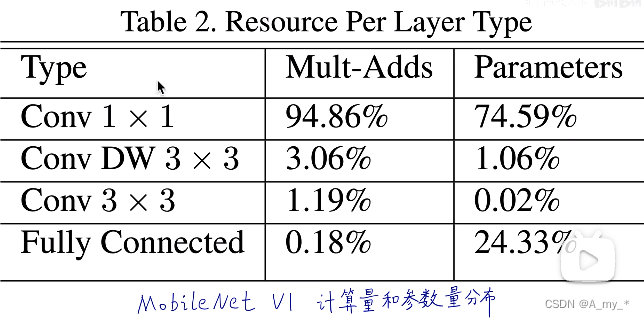
乘法加法計算量,參數量都集中在1*1卷積,計算核心在于加速1*1卷積(跨層通信,引入額外非線性,利用卷積核的個數進行降維或者升維)
拓展:實現標準卷積代碼,長寬移動需要兩個循環,對應元素相乘需要一個循環,循環非常耗時;改進:將卷積運算變為矩陣乘法運算(im2col)。而1*1卷積本來就是一個向量,很容易加速
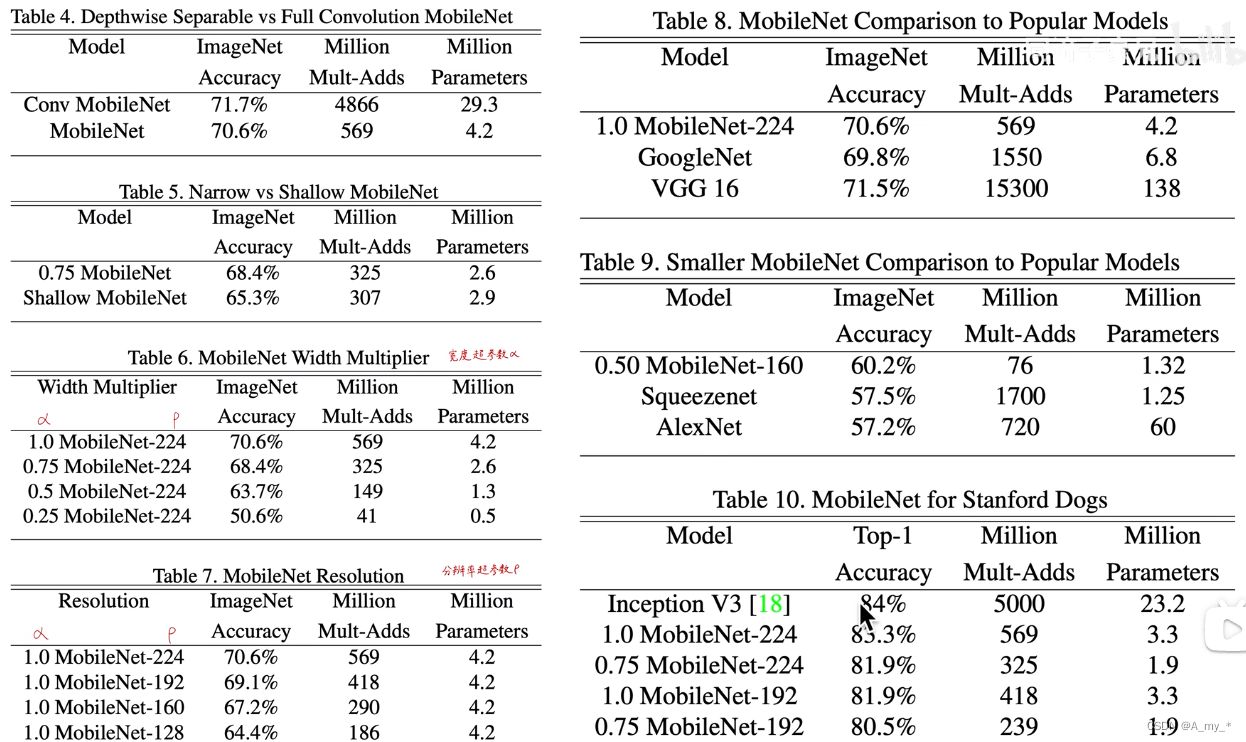
?由上表可見,計算性能大大提升
參考1
)
![LeetCode 刷題 [C++] 第279題.完全平方數](http://pic.xiahunao.cn/LeetCode 刷題 [C++] 第279題.完全平方數)














: 索引操作)


