1. 文件路徑
/etc/kubeedge/config
edgecore.yaml是該目錄下唯一的文件
附上鏈接:edgecore.yaml
2. 文件生成方式
2.1 方式一
使用keadm安裝部署的方式,執行完keadm join --cloudcore-ipport=cloudcore監聽的IP地址:端口(默認為10002) --token=獲取到的token字符串后自動生成。
![[圖片]](https://img-blog.csdnimg.cn/direct/5e1555a622f248068d7477b08aa0e0c2.png)
執行后,edgecore節點會自行使用systemctl進行管理,并加入開機啟動項,同時啟動edgecore節點,此時edgecore節點的運行狀態不一定正常。
若edgecore狀態不正常,修改并檢查配置文件edgecore.yaml。
然后重啟
systemctl restart edgecore
2.2 方式二
如果使用二進制安裝,需要先獲取初始的最小化edgecore配置文件:(/etc/kubeedge/config路徑),或者
–defaultconfig創建完整配置文件。
edgecore --minconfig > edgecore.yaml
啟動edgecore服務
nohup ./edgecore --config edgecore.yaml 2>&1 > edgecore.log &
nohup : no hang up(不掛起),用于在系統后臺不掛斷地運行命令,退出終端不會影響程序的運行。
2>&1 : 將標準錯誤 2 重定向到標準輸出 &1 ,標準輸出 &1 再被重定向輸入到 edgecore.log 文件中。
0 – stdin (standard input,標準輸入)
1 – stdout (standard output,標準輸出)
2 – stderr (standard error,標準錯誤輸出)
在命令的末尾加個&符號后,程序可以在后臺運行。
3. 總體層次概述
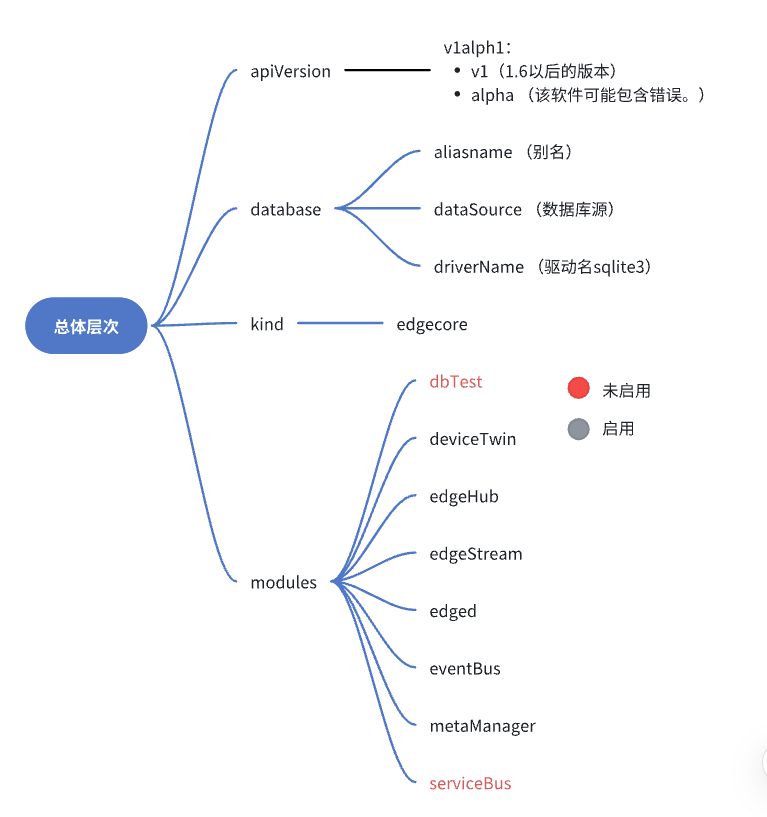
4. modules 組件概述
| 組件名 | 意義 |
|---|---|
| dbTest | 測試數據庫性能 |
| deviceTwin | 設備的動態屬性 |
| edgeHub | 通信接口,WebSocket 客戶端,用于云邊消息同步 |
| edgeStream | 支持ApiServer向Kubelet發起的containerLog、exec和metrics請求。云邊隧道基于WebSocket建造,支持雙向傳輸和流式傳輸 |
| edged | 管理邊緣的容器化應用程序,一個運行在 edge 節點的 agent 程序 |
| eventBus | 使用MQTT處理內部邊緣通信。 |
| metaManager | 管理邊緣節點上的元數據。 |
| serviceBus | HTTP 客戶端與 HTTP 服務器使用 REST 進行交互,為云端組件提供 HTTP 客戶端功能,使其請求到達運行在邊緣端的 HTTP 服務器 |
![[圖片]](https://img-blog.csdnimg.cn/direct/9adc1810a1334116bac2cd329bf4a6b0.png)
5. edged解析
5.1 edged啟動原理
EdgeD是管理節點生命周期的邊緣節點模塊,(輕量化的 kubelet),它可以幫助用戶在邊緣節點上部署容器化的工作負載或應用程序。這些工作負載可以執行任何操作,從簡單的遠程遙測數據操作到分析或ML推理等等。使用kubectl云端的命令行界面,用戶可以發出命令來啟動工作負載。
通過容器運行時接口Container Runtime Interface(CRI)支持幾種符合OCI的運行時runtimes。請參閱KubeEdge運行時配置,以獲取有關如何配置邊緣以利用其他運行時的更多信息。
edged內部模塊如圖所示:
當edged啟動時,首先初始化并啟動各個模塊,最后進行pod的sync。
各組件說明:edged
![[圖片]](https://img-blog.csdnimg.cn/direct/c80b52bc45ba448a8e325ae9f26af042.png)
當edged啟動時,首先初始化并啟動各個模塊,最后進行pod的sync。下面以一個pod的創建來看一下edged中各個模塊是如何協作完成pod的生命周期管理的。
當edged接收到pod的insert消息時,將pod所有信息加入podmanager、probemanager,podAdditionQueue加入node-namespace/node-name信息。
啟動一個goroutine,創建下發到此節點的pod。
![[圖片]](https://img-blog.csdnimg.cn/direct/3a553ffdc327466982d547df2319bd26.png)
此時我們根據pod的定義成功創建pod,之后還要對pod的狀態進行管理。
啟動一個goroutine執行syncLoopIteration()函數:
①當liveness探針的結果更新,若內容是“failure”,根據container的restart policy執行相應的操作,比如:never->do nothing;onfailed->判斷container的status,若completed->do nothing,否則將加podAdditionQueue,等待被再次創建;always->加入podAddtionQueue,等待被再次創建。
②當收到PLEG的event,更新podmanager中podstatus(containerruntime中獲取當前sataus,probemanager更新ready狀態),更新statusmanager中的緩存podstatus。若event是containerdied,則根據restart policy執行相應操作。
另外,statusmanager中會定時(10s)將podstatus上傳至metamanager
![[圖片]](https://img-blog.csdnimg.cn/direct/78b56ab23ca9455384892c01e91aed89.png)
…
Edged 的注冊和啟動過程代碼在 edge/pkg/edged/edged.go 中。
edged.go源碼
5.2 edged配置項解析
kubeedge官網解釋:https://kubeedge.io/zh/docs/architecture/edge/edged
edged:cgroupDriver: cgroupfs #cri的cgroup驅動程序配置為cgroupfscgroupRoot: "" #默認為空,使用底層containter runtime的cgroup root,一般是 /sys/fs/cgroup/cgroupsPerQOS: true #對應 pod 容器的 QOS 級別clusterDNS: "" #集群dns(默認dns)clusterDomain: "" #集群域(默認域)cniBinDir: /opt/cni/bin #放可執行的原生CNI插件。cniCacheDirs: /var/lib/cni/cache #存儲運行容器的網絡配置信息cniConfDir: /etc/cni/net.d #CNI的配置文件,在不同CNI插件中表現為NetworkConfig結構體的差異。concurrentConsumers: 5 #并發devicePluginEnabled: false #設備插件是否啟用dockerAddress: unix:///var/run/docker.sock #Docker守護進程通信edgedMemoryCapacity: 7852396000 #邊緣內存容量enable: trueenableMetrics: true #一個集群范圍內的資源數據集和工具,只是顯示數據,并不提供數據存儲服務gpuPluginEnabled: false #gpu插件hostnameOverride: edgezh1-virtual-machine #覆蓋名imageGCHighThreshold: 80 #垃圾回收高閾值imageGCLowThreshold: 40 #垃圾回收低閾值imagePullProgressDeadline: 60maximumDeadContainersPerPod: 1networkPluginMTU: 1500nodeIP: 192.168.2.101nodeStatusUpdateFrequency: 10podSandboxImage: kubeedge/pause:3.1registerNode: trueregisterNodeNamespace: defaultremoteImageEndpoint: unix:///var/run/dockershim.sockremoteRuntimeEndpoint: unix:///var/run/dockershim.sockruntimeRequestTimeout: 2runtimeType: docker
5.2.1 cgroup
cgroup是什么?
Cgroup (Control Group)是對一組進程的資源使用(CPU、內存、磁盤 I/O 和網絡等)進行限制、審計和隔離。
![[圖片]](https://img-blog.csdnimg.cn/direct/42e06a2d88ec4e0d9b6552fe71659e1b.png)
cgroups(Control Groups) 是 linux 內核提供的一種機制。(對多組,暫時場景不是多組,所以不深入探究)。
cgroupfs:
類似于procfs和sysfs,是一種虛擬文件系統。并且cgroupfs是可以掛載的,默認情況下掛載在/sys/fs/cgroup目錄。
![[圖片]](https://img-blog.csdnimg.cn/direct/df3e587fe83347f9818b63b041715f74.png)
![[圖片]](https://img-blog.csdnimg.cn/direct/8e554a97ce3e4517baebcbb4b55f41f8.png)
三個核心功能:
分組:根據需求把一系列系統任務及其子任務整合(或分隔)到按資源劃分等級的不同組內。
限制:可以限制、記錄任務組所使用的物理資源。
調度:內核附加在程序上的一系列鉤子(hook),通過程序運行時對資源的調度觸發相應的鉤子以達到資源追蹤和限制的目的。
cgroup如何分組?
可以先看這個目錄層次,或者到云端設備上查看。
內容較多,資源切分方面可根據下圖的指引結合理解。

- cgroup.clone_ children, cpuset 的 subsystem 會讀取這個配置文件,如果這個值是 1 (默認是 0),子 cgroup 才會繼承父 cgroup 的 cpuset 的配置。
- cgroup.procs 是樹中當前節點 cgroup 中的進程組 ID,現在的位置是在根節點,這個文件中會有現在系統中所有進程組的 ID。
- notify_on_release 和 release agent 會一起使用。 notify_on_release 標識當這個 cgroup 最后一個進程退出的時候是否執行了 release_agent; release_agent 則是一個路徑,通常用作進程退出之后自動清理掉不再使用的 cgroup。
- tasks 標識該 cgroup 下面的進程 ID,如果把一個進程 ID 寫到 tasks 文件中,便會將相應的進程加入到這個 cgroup 中。
cgroupsPerQOS配置項中提到QoS級別是什么?

cgroup如何限制?
https://zhuanlan.zhihu.com/p/636467664
對cgroup的基本操作:https://zhuanlan.zhihu.com/p/651405353
以一個關聯cpu和memory的一個控制組my_group為例子,
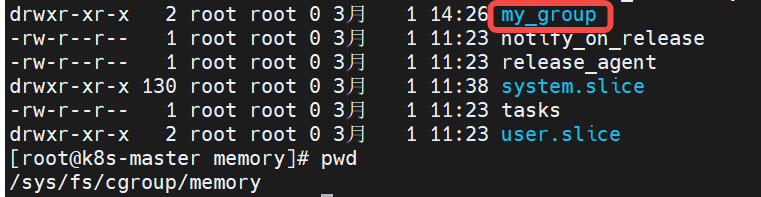
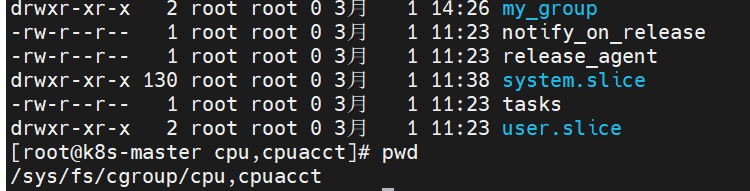
Container級別:
路徑:
- Guaranteed container:默認 /sys/fs/cgroup/{controller}/kubepods/{pod_id}/{container_id}/;
- Burstable container:默認 /sys/fs/cgroup/{controller}/kubepods/burstable/{pod_id}/{container_id}/;
- BestEffort container:默認 /sys/fs/cgroup/{controller}/kubepods/besteffort/{pod_id}/{container_id}/。
一個資源申請(容器)的例子:
apiVersion: v1
kind: Pod
spec:containers:
name: busybox
image: busybox
resources:limits:cpu: 500m memory: "400Mi" requests:cpu: 250mmemory: "300Mi"
command: ["md5sum"]
args: ["/dev/urandom"]
在Kubernetes中,資源請求和限制通常使用以下單位來表示:
CPU:以"millicores"為單位,即千分之一的CPU核心。例如,1000m表示一個核心。
內存:以字節為單位(B),可以使用K、Ki、M、Mi、G、Gi等后綴來表示。例如,1Gi表示1GB。
requests 經過轉換之后會寫入 cpu.share, 表示這個 cgroup 最少可以使用的 CPU;
limits 經過轉換之后會寫入 cpu.cfs_quota_us, 表示這個 cgroup 最多可以使用的 CPU;
resources.requests.cpu:指定容器所需的CPU資源數量;
resources.requests.memory:指定容器所需的內存資源數量;
resources.limits.cpu:指定容器的CPU資源限制;
resources.limits.memory:指定容器的內存資源限制。
Pod 級別:
Pod 配置在 QoS cgroup 配置的下一級,
- Guaranteed Pod:默認 /sys/fs/cgroup/{controller}/kubepods/{pod_id}/;
- Burstable Pod:默認 /sys/fs/cgroup/{controller}/kubepods/burstable/{pod_id}/;
- BestEffort Pod:默認 /sys/fs/cgroup/{controller}/kubepods/besteffort/{pod_id}/。
kubelet 計算 pod requets/limits 的過程
一個Pod的容器的request和limits是通過在Pod的容器定義中設置資源請求和限制來確定的。
在Pod的容器定義中,可以為每個容器定義資源請求和限制。資源請求是指容器在運行時對某一資源(如CPU或內存)的需求量。資源限制是指容器在運行時對某一資源的最大使用量。
在計算一個Pod的所有容器的資源請求和限制時,Kubernetes將遵循以下規則:
如果一個容器沒有設置資源請求和限制,Kubernetes將默認使用集群級別的資源限制。
如果一個Pod中的容器設置了資源請求,但沒有設置資源限制,Kubernetes將使用資源請求作為容器的限制值。
如果一個Pod中的容器同時設置了資源請求和限制,Kubernetes將使用設置的資源請求和限制值。
總結起來,一個Pod的所有容器的資源請求和限制是根據容器定義中設置的值來計算的,如果沒有設置則會采用默認值。這些資源請求和限制對于Kubernetes調度和資源管理非常重要,可以確保在容器運行時有足夠的資源可用,并保證不會過度使用資源。
cgroup如何調度?
調度算法根據各 node 當前可供分配的資源量(Allocatable),為容器選擇合適的 node; 注意,k8s 的調度只看 requests,不看 limits。
5.2.2 cni
kubelet創建/刪除pod時,會調用CRI,然后CRI會調用CNI來進行pod網絡的構建/刪除。
cni標準規范也是一套標準的容器網絡接口規范。
cniBinDir: /opt/cni/bin #放可執行的原生CNI插件。
cniCacheDirs: /var/lib/cni/cache #存儲運行容器的網絡配置信息
cniConfDir: /etc/cni/net.d #CNI的配置文件,在不同CNI插件中表現為NetworkConfig結構體的差異。
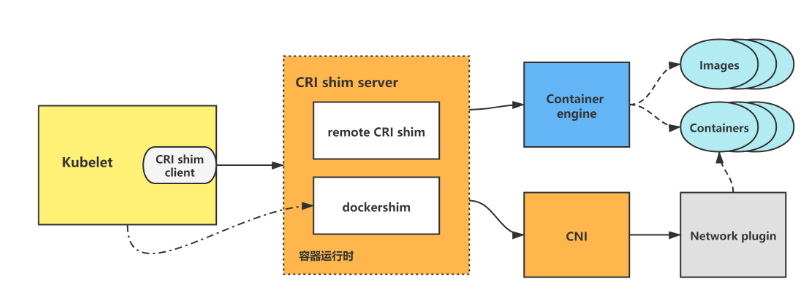
在這個示意圖中,我們看到有一個容器運行時 (Container Runtime) 和多個不同的網絡插件 (Network Plugins),它們可以是 Calico、Flannel、Weave 等等。CNI 提供了一個統一的接口,使得容器運行時可以與任何支持 CNI 規范的網絡插件進行通信。
當一個容器啟動時,容器運行時會調用 CNI 接口,并將容器的網絡配置傳遞給網絡插件。網絡插件會根據配置信息來創建和管理容器的網絡,同時也負責處理容器之間的通信。CNI 還定義了一些標準的網絡配置參數,用于指定容器的 IP 地址、網關、子網等。
5.2.3 GC
垃圾回收機制(Garbage collection)的設計和實現
與鏡像回收有關的主要有以下倆參數:
imageGCHighThreshold:表示一個 pod 最多可以保存多少個已經停止的容器,默認為1;
imageGCLowThreshold:一個 node 上最多可以保留多少個已經停止的容器,默認為 -1,表示沒有限制;
鏡像回收的過程如下:
當用于存儲鏡像的磁盤使用率達到百分之–image-gc-high-threshold時將觸發鏡像回收,刪除最近最久未使用(LRU,Least Recently Used)的鏡像直到磁盤使用率降為百分之–image-gc-low-threshold或無鏡像可刪為止。
查看當前磁盤使用率 :df -lh
儲存docker的鏡像信息:/var/lib/docker
官網說明:
- The image garbage collector is an edged routine which wakes up every 5 secs, and collects information about disk usage based on the policy used.
鏡像垃圾收集器是一個邊緣例程,每5秒喚醒一次,并根據所使用的策略收集磁盤使用信息。 - The policy for garbage collecting images takes two factors into consideration, HighThresholdPercent and LowThresholdPercent .
圖像垃圾收集策略需要考慮兩個因素:HighThresholdPercent和LowThresholdPercent。 - Disk usage above the high threshold will trigger garbage collection, which attempts to delete unused images until the low threshold is met.
磁盤使用率高于高閾值將觸發垃圾收集,垃圾收集將嘗試刪除未使用的映像,直到達到低閾值。 - Least recently used images are deleted first.
首先刪除最近最少使用的圖像。
5.2.4 taints
- effect: NoSchedule key: node-role.kubernetes.io/edgevolumeStatsAggPeriod: 60000000000
每個污點的組成如下:
key=value:effect
每個污點有一個 key 和 value 作為污點的標簽,其中 value 可以為空,e?ect 描述污點的作用。
當前 taint e?ect 支持如下三個選項:
NoSchedule :表示k8s將不會將Pod調度到具有該污點的Node上
PreferNoSchedule :表示k8s將盡量避免將Pod調度到具有該污點的Node上
NoExecute :表示k8s將不會將Pod調度到具有該污點的Node上,同時會將Node上已經存在的Pod驅逐出去
6. edgestream解析
Stream是KubeEdge中提供云邊隧道的模塊,目前支持ApiServer向Kubelet發起containerLog、exec和metrics請求。云邊隧道基于WebSocket建造,支持雙向傳輸和流式傳輸。
參考自:
edgestream啟動原理
主要功能是啟動創建websocket
- 讀取本地的證書配置
- 連接cloud 端的 tunnel server(也就是下面提到的server端)
edgeStream: handshakeTimeout: 30 #握手超時時間(second) default 30readDeadline: 15 #讀取證書的截止時間:15s內server: 1.94.44.163:30004tlsTunnelCAFile: /etc/kubeedge/ca/rootCA.crttlsTunnelCertFile: /etc/kubeedge/certs/server.crttlsTunnelPrivateKeyFile: /etc/kubeedge/certs/server.key writeDeadline: 15 #寫證書的截止時間:15s內
7. edgeHub解析
官網解釋
EdgeHub是Azure IoT Edge的核心組件之一,是一個輕量級的消息路由器,用于在邊緣設備上與云平臺進行通信。它起到了以下幾個作用:
-
消息路由:EdgeHub允許邊緣設備與云平臺之間進行雙向的消息傳遞。它可以接收來自云平臺的消息,并將其路由到邊緣設備上運行的模塊,也可以將來自邊緣設備的消息發送到云平臺。這種消息路由的能力使得邊緣設備能夠與云平臺進行實時的通信和數據交換。
-
模塊通信:在邊緣設備上運行的模塊之間可能需要相互通信,例如將傳感器數據從一個模塊傳遞給另一個模塊進行處理。EdgeHub提供了一個統一的消息傳遞機制,使得模塊之間可以通過發送和接收消息進行通信。這種模塊之間的通信能力使得邊緣設備上的各個模塊可以協同工作,共同完成復雜的任務。
-
安全性:EdgeHub提供了對消息傳輸的安全保護。它使用TLS來加密消息,以確保消息在傳輸過程中的機密性和完整性。此外,EdgeHub還支持設備身份驗證和授權,只有經過身份驗證的設備才能與邊緣設備進行通信,從而增加了系統的安全性。
總的來說,EdgeHub在邊緣端起到了消息路由、模塊通信和安全性保護等重要作用,使得邊緣設備能夠與云平臺進行可靠的通信,并提供了模塊之間的協同工作能力。
edgeHub: #通信接口,WebSocket 客戶端,用于云邊消息同步enable: trueheartbeat: 15 #根據心跳時間向云端發送心跳 15s發一次httpServer: https://1.94.44.163:30002 #httpclient:用于與EdgeCore與CloudCore通信所需證書的申請projectID: e632aba927ea4ac2b575ec1603d56f10quic: #quic client:負責與CloudCore的日常通信(資源下發、狀態上傳等)enable: falsehandshakeTimeout: 30 #握手超時時間:30s(默認30)readDeadline: 15 #讀取證書的截止時間:15s內server: 1.94.44.163:30001writeDeadline: 15rotateCertificates: true #證書輪轉tlsCaFile: /etc/kubeedge/ca/rootCA.crttlsCertFile: /etc/kubeedge/certs/server.crttlsPrivateKeyFile: /etc/kubeedge/certs/server.keytoken: 111900b80a0a2a87b0910b2590963e5dadbfa56f977810909b7eabdf0cc1668c.eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MDY1NjMzNDF9.QSRQsMmL_YZQFEfLC0r0Rr6_HgNBKmBPvs50VLfHGnUwebsocket: #websocket:負責與CloudCore的日常通信(資源下發、狀態上傳等)enable: truehandshakeTimeout: 30readDeadline: 15server: 1.94.44.163:30000writeDeadline: 15
8. MetaManager解析
官網解釋
MetaManager在edge端的作用是對邊緣設備進行管理和控制。它能夠對邊緣設備的資源進行監控和調度,管理邊緣計算節點和資源的分配,以及實現邊緣設備的遠程配置和更新。通過MetaManager,用戶可以實現對邊緣設備的集中管理,提升邊緣計算的效率和可靠性。
metaManager: #它管理邊緣節點上的元數據。contextSendGroup: hubcontextSendModule: websocket #上下文發送的模塊,客戶端和服務端之間建立tcp連接的通信enable: truemetaServer:enable: falseserver: 127.0.0.1:10550podStatusSyncInterval: 60 #定期發送MetaSync操作消息的同步間隔,同步pod狀態,60s(默認)。remoteQueryTimeout: 60 #發送請求超時時間,60s(默認)
9. DeviceTwin解析
官網解釋
在Edge設備上,Device Twin是Azure IoT Hub提供的一個關鍵功能。它允許開發人員在設備端和云端之間同步設備的狀態和屬性。
具體而言,Device Twin在Edge端的作用包括:
-
設備狀態管理:Device Twin允許設備端將其當前狀態(如溫度、濕度、電池電量等)報告給云端,并將其保存為設備的狀態屬性。這樣,云端可以隨時了解設備的最新狀態。
-
遠程配置:設備端可以使用Device Twin獲取來自云端的配置信息,并根據配置信息調整自己的行為。這樣,設備可以動態地適應不同的環境和需求。
-
雙向通信:Device Twin允許設備端和云端之間進行雙向通信。設備可以向云端發送命令、請求或報告設備狀態,云端可以向設備端發送配置信息、命令或其他指令。
-
設備拓撲管理:Device Twin允許設備端創建和管理設備拓撲。設備可以將自己作為父設備或子設備與其他設備進行關聯,并在Device Twin中管理這些關聯關系。
總的來說,Device Twin在Edge端提供了一種可靠的、雙向的設備與云端之間的通信機制,使得設備可以靈活地與云端進行交互,并根據云端的配置和指令適應不同的場景和需求。在Edge設備上,Device Twin是Azure IoT Hub提供的一個關鍵功能。它允許開發人員在設備端和云端之間同步設備的狀態和屬性。
10. EventBus解析
EventBus在邊緣端起到了以下作用:
-
事件發布與訂閱:EventBus允許在邊緣端組件之間進行松散耦合的通信,組件可以發布事件,并且其他組件可以訂閱這些事件。這種事件驅動的機制能夠提高邊緣端的可擴展性和靈活性。
-
實時數據傳遞:邊緣端的設備和傳感器通常會產生大量的實時數據。EventBus可以用于在邊緣端不同組件之間實時傳遞數據,實現實時數據的處理和分發。這種實時的數據傳遞能夠幫助邊緣端系統實時響應和處理數據。
-
解耦和管理:EventBus可以解耦邊緣端的不同組件,使它們之間的通信更加靈活和可擴展。通過訂閱事件的方式,組件之間不需要直接耦合在一起,降低了代碼的依賴性和復雜性。同時,EventBus還可以管理事件的發布和訂閱,確保事件的交付和處理。
-
系統集成:邊緣端的系統往往由多個組件和服務組成,這些組件和服務可能來自不同的廠商或者遵循不同的通信協議。EventBus可以作為一個中間件,幫助不同的組件和服務進行集成和協同工作。通過發布和訂閱事件的方式,不同的組件可以通過EventBus進行通信和協作。
總之,EventBus在邊緣端起到了解耦和管理組件之間通信、實時數據傳遞、系統集成等作用,提高了邊緣端系統的可擴展性、靈活性和實時性。
eventBus: #使用MQTT處理內部邊緣通信。enable: trueeventBusTLS:enable: falsetlsMqttCAFile: /etc/kubeedge/ca/rootCA.crttlsMqttCertFile: /etc/kubeedge/certs/server.crttlsMqttPrivateKeyFile: /etc/kubeedge/certs/server.keymqttMode: 2 #啟用內部 mqtt 代理(mqttMode=2)。mqttQOS: 0mqttRetain: falsemqttServerExternal: tcp://127.0.0.1:1883mqttServerInternal: tcp://127.0.0.1:1884mqttSessionQueueSize: 100
(mqttMode=0):bothMqttMode:啟用內部和外部代理(mqttMode=1):externalMqttMode:僅啟用外部代理
11. ServiceBus解析
在邊緣端,ServiceBus起多個作用:
ServiceBus在邊緣端起到了連接邊緣設備和云端的橋梁作用,提供可靠的消息傳遞、數據集成、高可用性和離線操作等功能。這使得邊緣設備可以更好地與云端進行交互,并實現更強大的功能和應用場景。
serviceBus: enable: falseport: 9060server: 127.0.0.1timeout: 60




SpringCloud系列——openfeign的高級特性實戰內容介紹)







)






