一、事故現象
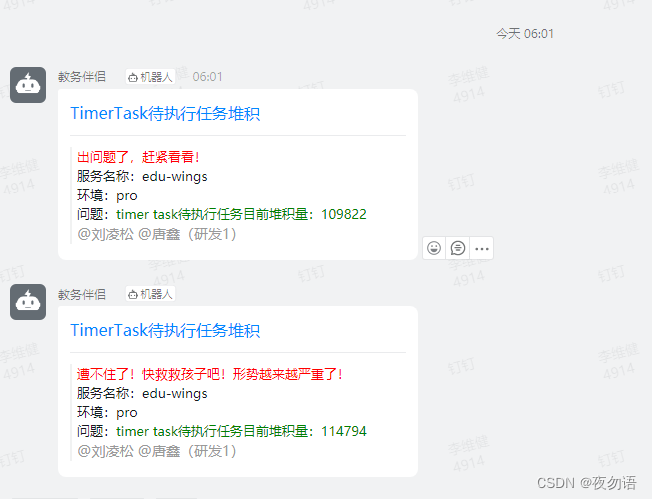
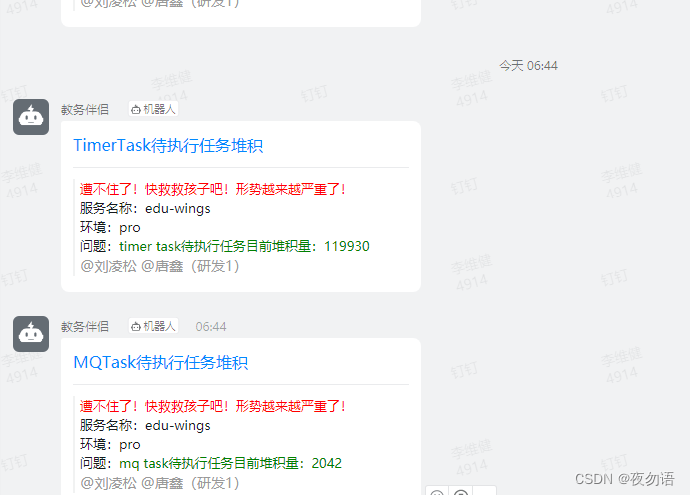
從早上6點開始edu-wings-admin的timer-task和mq就開始報警任務堆積,且數量持續上升,到6點50左右mq也開始告警,8點左右發現問題,開始排查,直到11點才找到問題,任務開始正常消費。
二、事故影響范圍
從27號0點4分到早上11點4分班級專欄、表彰發放以及監聽mq的班級、完課事件都被堵住,11點04分修改配置重啟后任務才陸續執行完畢。
三、事故原因分析
我們的任務是每秒掃描執行的,正常情況下,高峰期即使堆積也會立馬被消費,除非有大任務卡住情況(一般卡住的都是timer-task,而這次mq-task也同步出現問題,不過當時沒有意識到這個問題),所以根據以往經驗,查數據庫發現0點的任務就沒有執行了,而這批任務都是給用戶發表彰,但是從日志上沒有找到問題,數據庫也沒有慢sql,后面從應用行為大盤上只能看到xxl-job從0點開始就沒有執行了,也就是從0點開始任務就堵住了,由于任務堆積超過2000條才會告警,所以直到6點群里才開始報警。
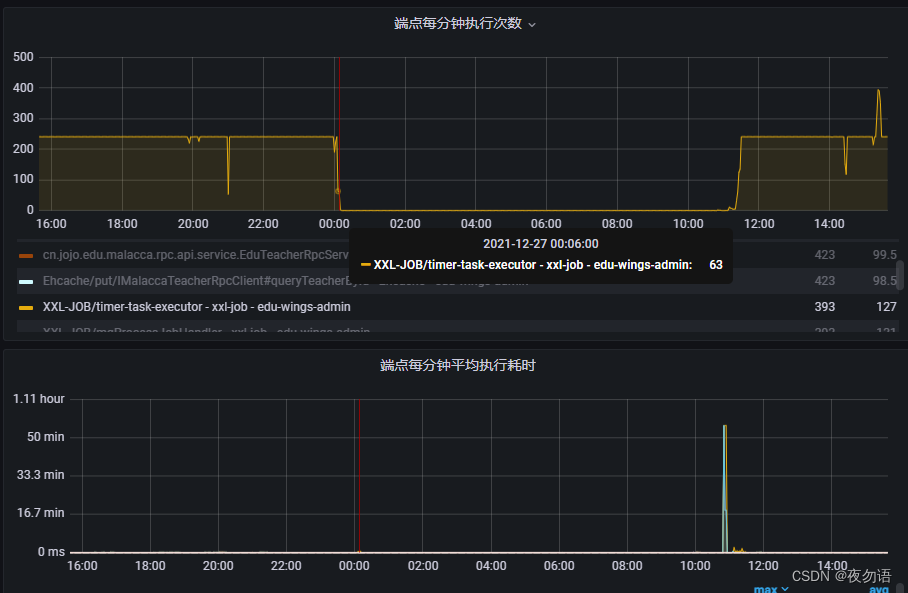
數據庫、pod CPU都很正常,但業務線程卻卡住,于是開始懷疑業務上是不是產生了死鎖,下載線程堆棧進行分析。
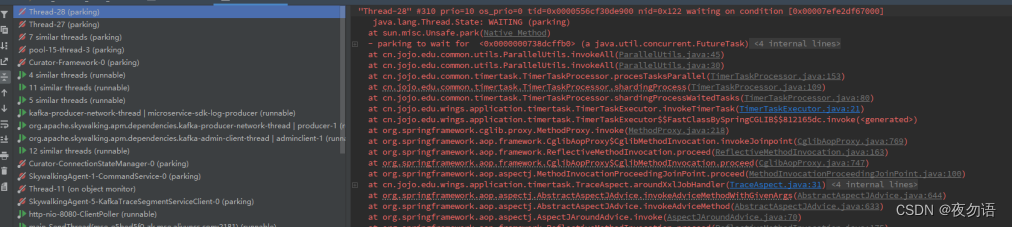

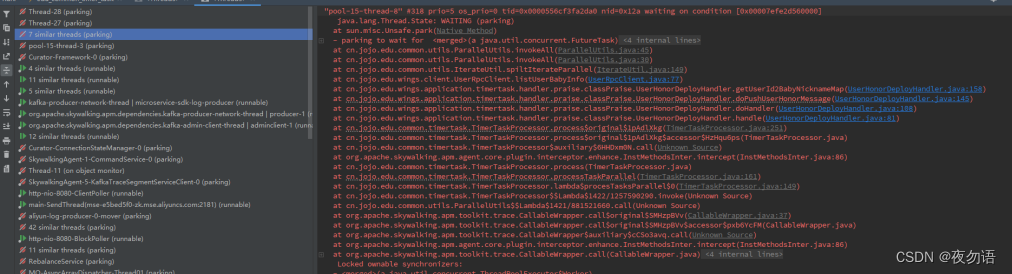
從上圖我們可以發現線程最終都是卡在了ParallelUtils.invokeAll方法上(看到這個其實應該立馬反應過來線程池中線程被卡住了,導致線程資源耗盡,但實際上我們還走了不少彎路),這個類是我們執行并行任務的一個工具類,里面維護了一個單例的線程池。

核心線程數只有8個,最大線程數雖然設置了200,但隊列長度設置為50000,而我們并行任務是達不到50000的,所以一直都只會有8個線程在跑,但是為什么線程會卡住呢?
從上面堆棧日志圖中可以看到UserRpcClient.listUserBabyInfo這個方法,在發用戶表彰時就需要調用這個方法查詢寶貝昵稱,而這個方法之前是串行調用的,由于單次傳入參數太多,所以使用IterateUtil.spiltIterateParallel并行分批調用,問題就在這里,spiltIterateParallel內部也是調用工具類方法ParallelUtils.invokeAll,這就相當于是在父任務中開辟了子任務,父子任務用的又是同一個線程池,同一時間只要有8個父任務在執行,那子任務去獲取線程就會卡住,而父任務又要等子任務返回,導致死鎖。
四、解決方案
- 臨時解決方案:修改timer-task占用線程數為1,默認配置為8,重啟。這樣在同一個pod上同一時間只會有一個父任務在跑,也就只會占用一個線程,剩余7個留給子任務
- 最終解決方案:修改公用組件,隔離timer-task、mq-task和業務線程的線程池,避免相互影響。目前wings-admin已升級并上線,其余服務后續逐步升級發布。
五、反思
- 這次問題其實在0點就發生了,但經過了6小時才告警,這是由于異步任務告警閾值目前僅根據數量(固定2000)觸發,需要加入任務執行時間等因素。
- 使用線程池時需要考慮使用場景,核心線程數、最大線程數、阻塞隊列長度、拒絕策略的配置以及是否需要隔離線程。,此次事故中最大線程數完全沒起作用就是因為阻塞隊列長度過長導致。后續考慮實現動態可監測線程池,做到線程池統一管理、可動態配置,出現問題及時告警等
![haproxy集成國密ssl功能[下]](http://pic.xiahunao.cn/haproxy集成國密ssl功能[下])














之搭建maven私服)



