三、InnoDB數據存儲結構之數據頁結構
- 3.1 數據庫的存儲結構
- 3.1.1 MySQL 數據存儲目錄
- 3.1.2 頁的引入
- 3.1.3 頁的概述
- 3.1.4 頁的上層結構
- 3.2 數據頁結構
- 3.2.1 文件頭和文件尾
- 01、File Header(文件頭部)
- 02、File Trailer(文件尾部)
- 3.2.2 空閑空間、用戶記錄、最大最小記錄(上下確界)
- 01、Free Space(空閑空間)
- 02、User Record(用戶記錄)
- 03、Infimum + Supremum(最小最大記錄)
- 3.2.3 頁目錄、頁面頭部
- 01、Page Directory(頁目錄)
- 02、Page Header(頁面頭部)
- 3.3 從數據頁的角度看 B+ 樹如何查詢
- 3.3.1 B+ 樹是如何進行記錄檢索的?
- 3.3.2 普通索引和唯一索引在查詢效率上有什么不同?
3.1 數據庫的存儲結構
前文中說到,索引結構給我們提供了高效的查詢方式,而索引信息以及數據記錄都是保存在文件上的,確切地說是保存在頁結構中。
索引是在存儲引擎中實現的,MySQL 服務器上的存儲引擎負責對表中的數據進行讀取和寫入。但是不同的存儲引擎對數據的存放格式一般是不同的,比如:InnoDB 是將數據存儲到磁盤上、Memory 直接將數據存儲在內存中…
注:MySQL 默認的存儲引擎是 InnoDB,所以此文章以 InnoDB 存儲引擎展開。
3.1.1 MySQL 數據存儲目錄
使用命令查看目錄路徑:
show variables like 'datadir';
# 或
select @@datadir

這個是修改后的目錄路徑,實際上 MySQL 默認的存儲路徑為:/var/lib/mysql。
我們每創建一個數據庫 database_name,這個目錄下(包括自定義的)就會創建一個以數據庫名為名的目錄,然后里面存儲表結構和表數據文件。
InnoDB 存儲引擎創建的任何一張表的都會有兩個文件:
- test_table.frm:存儲
表結構的文件,保存表的原數據信息。 - test_table.ibd:存儲
表數據的文件,表數據既可以存儲在共享表空間文件中(ibdata1中),也可以存儲在獨占表空間中(后綴 .idb中)。是否存儲在獨占表中,可以通過參數 innodb_file_per_table控制,設置為 1,則會存儲在獨占表空間中,從 MySQL 5.6.6 版本之后,innodb_file_per_table 默認值就為 1 了,因此此后的版本,表數據都是存儲在獨占表中的。
3.1.2 頁的引入
為什么會提到頁呢?
InnoDB 是一個將表中的數據存儲到磁盤上的存儲引擎,即使我們關閉并重啟服務器,數據還是存在。而真正處理數據的過程發生在內存中,所以需要把磁盤中的數據加載到內存中。如果是要處理寫入或修改請求,還需要把內存中的內容刷新到磁盤上。而我們知道讀寫磁盤的速度是非常慢的,與讀寫內存差了幾個數量級。當我們想從表中獲取某些記錄時,InnoDB 存儲引擎需要一條一條地把記錄從磁盤上讀出來么?這樣會慢死,InnoDB 采取的方式是,將數據劃分為若干個頁,以頁作為磁盤和內存之間交互的基本單位。 —— 摘自《MySQL是怎樣運行的》
InnoDB 中頁的大小一般為 16KB,一般情況下,一次最少從磁盤中讀取 16KB 的內容到內存中,一次最少把內存中 16KB 的內容刷新到磁盤中。也就是說,數據庫 I/O 操作的最小單位是頁,每次刷盤時都必須是頁的整數倍。
SQL Server 中頁的大小為 8KB。
Oracle 中用 “塊” 來代表頁,支持的塊大小有 2KB、4KB、8KB(默認)、16KB、32KB、64KB。
3.1.3 頁的概述
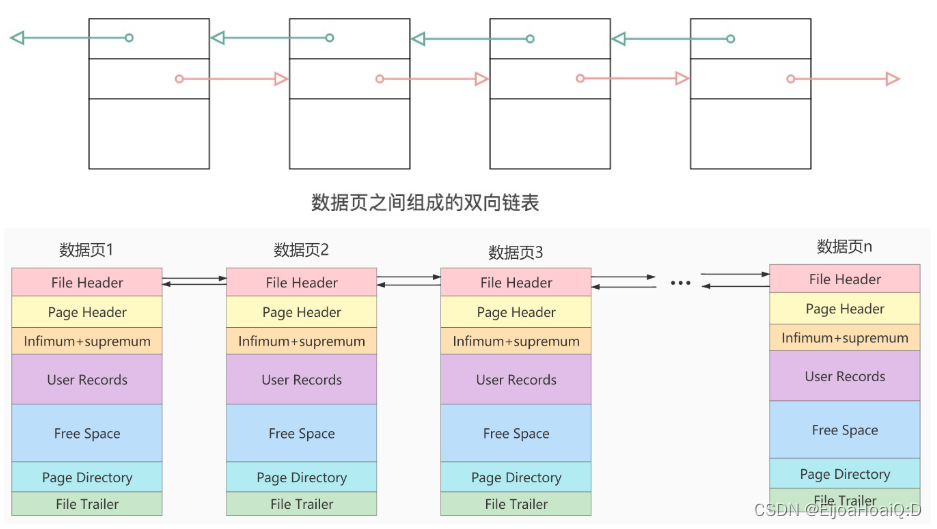
將數據劃分為若干個頁,這些頁可以不在物理結構上相連,只需要通過雙向鏈表使其在邏輯結構上相連即可。每個數據頁中的記錄都會按照主鍵值從小到大的順序組成一個單向鏈表,每個數據頁都會為存儲在它里邊的記錄生成一個頁目錄,再通過主鍵查找某條記錄的時候可以在頁目錄中使用二分法快速定位到對應的槽,然后再遍歷該槽對應分組中的記錄即可快速找到指定的記錄。
在 InnoDB 中,默認頁的大小是 16KB,可以通過命令來查看:
show variables like '%innodb_page_size%'
# 或者
select @@innodb_page_size

3.1.4 頁的上層結構
另外,在數據庫中,還存在著區、段、表空間的概念。行、頁、區、段、表空間的關系:
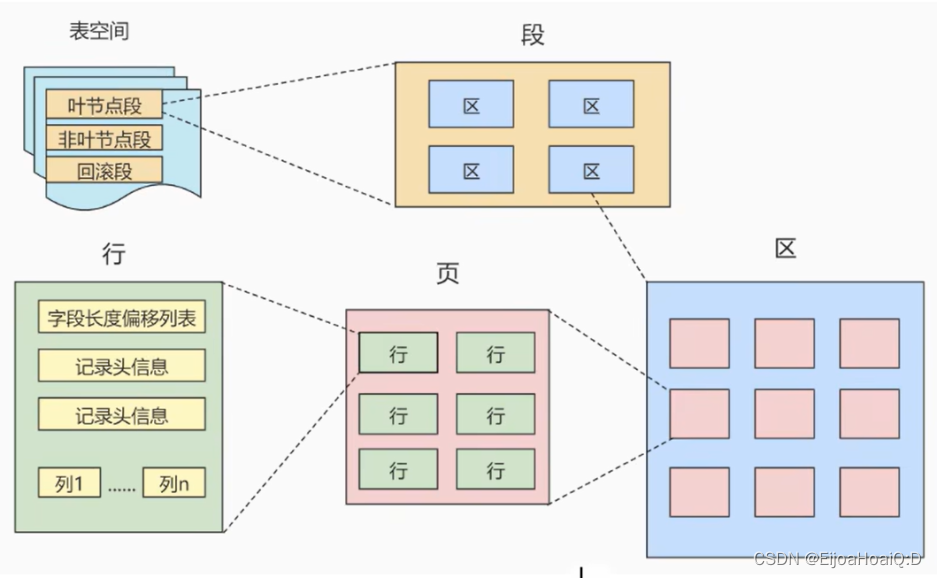
- 區(Extent)是比頁大一級的存儲結構,在 InnoDB 存儲引擎中,一個區會分配 64 個連鎖的頁,因為頁默認是 16KB,所以一個區的大小是 64 * 16KB = 1MB。
- 段(Segment)是由一個或多個區組成,區在文件系統是一個連續分配的空間,但是在段中不要求區與區之間是相鄰的。
段是數據庫中的分配單位,不同類型的數據庫對象以不同的段形式存在。當我們要創建數據表、索引的時候,就會相應地創建對應的段(索引段、表段…)。 - 表空間(Tablespace)是一個邏輯容器,表空間存儲的對象是段,在一個表空間中可以有一個或多個段,但是一個段只能屬于一個表空間。數據庫由一個或多個表空間組成,表空間從管理上可以分為系統表空間、用戶表空間、撤銷表空間、臨時表空間等。
3.2 數據頁結構
頁如果按照類型劃分的話,常見的有:數據頁(保存 B+ 樹節點)、系統頁、Undo 頁、事務數據頁等。其中,數據頁是我們最常使用的頁。
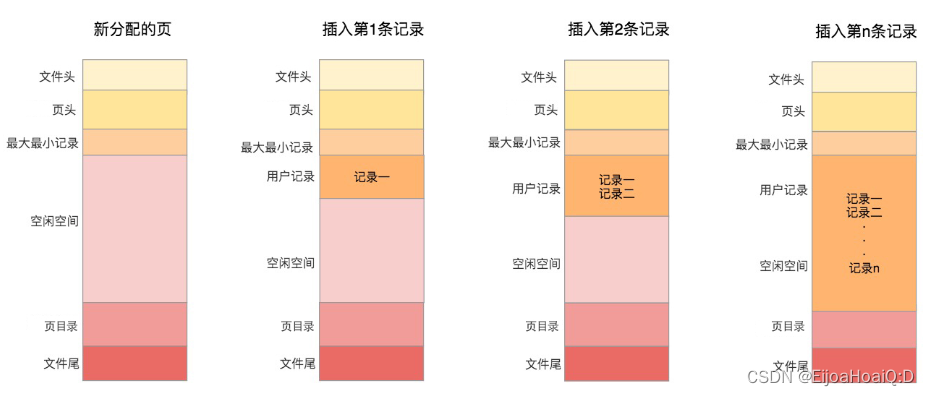
前面也有提到,數據頁的大小為 16KB,這 16KB 大小的存儲空間被劃分為七個部分:
- 文件頭部(File Header):占用 38 字節,主要描述頁的一些通用信息;
- 頁面頭部(Page Header):占用 56 字節,專門存儲頁的各種狀態信息;
- 頁面中的最小記錄和最大記錄(Infimum + Supremum):占用 26 字節,這是兩個虛擬的行記錄;
- 用戶記錄(User Records):占用空間由實際的記錄數據決定,主要存儲行記錄內容;
- 空閑空間(Free Space):占用空間由用戶記錄決定,是頁中還沒有被使用的空間;
- 頁目錄(Page Directory):占用空間由用戶記錄有關,存儲用戶記錄的相對位置,以便于查找;
- 文件尾部(File Trailer):占用 8 字節,校驗頁是否完整。
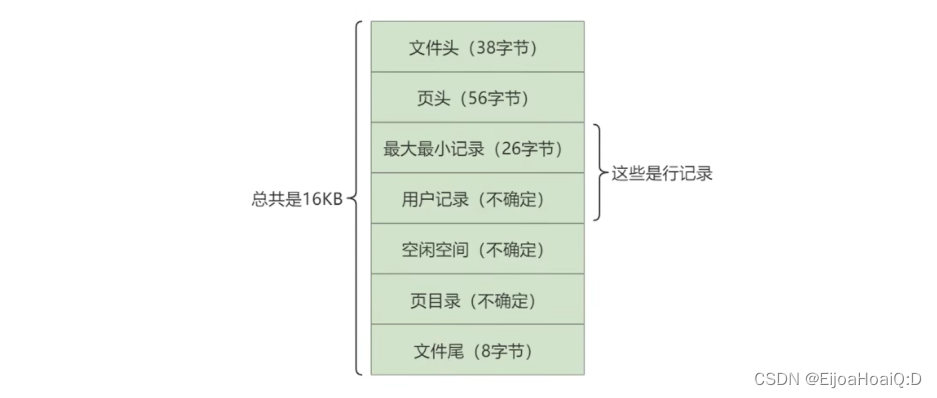
可以將以上 7 個結構歸為以下 3 個部分。
3.2.1 文件頭和文件尾
01、File Header(文件頭部)
文件頭部占用 38 字節,主要描述頁的一些通用信息,比如:頁的編號、其上一頁頁號、下一頁頁號…
File Header 的結構及描述如下:
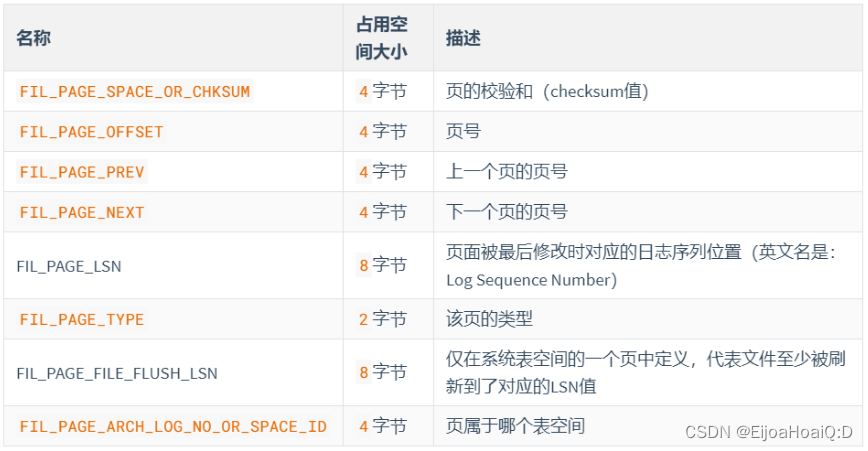
其中,我們需要重點關注一下標黃的屬性。
FIL_PAGE_OFFSET(4字節):
頁號,好比我們的身份證號,用來定位唯一的頁。
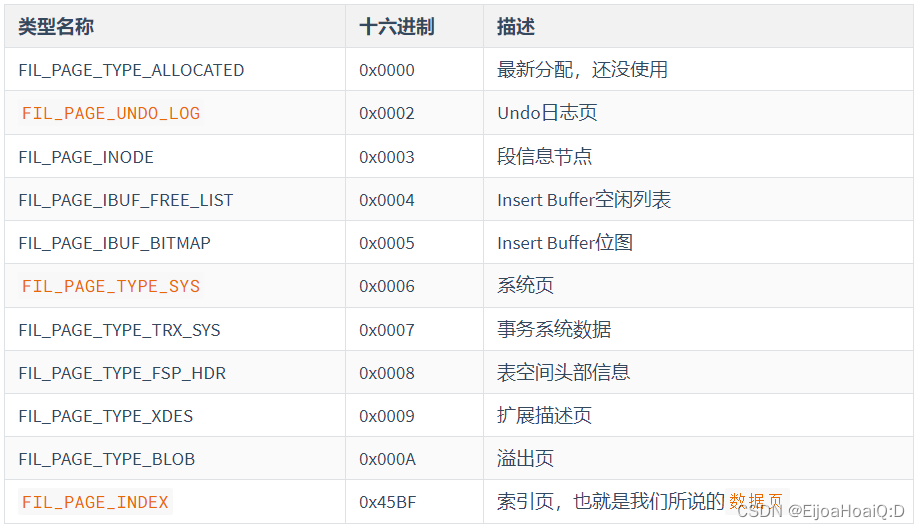
FIL_PAGE_TYPE(2字節):代表
當前頁的類型。前面說過,InnoDB 為了不同的目的而把頁分為不同的類型,除了我們常用的數據頁之外,還有很多其他類型的頁。
FIL_PAGE_PREV(4字節)和 FIL_PAGE_NEXT(4字節):InnoDB 都是以頁為單位存放數據的,如果數據分散到多個不連續的頁中存儲,就需要把這些頁關聯起來,FIL_PAGE_PREV 和 FIL_PAGE_NEXT 就分別代表本頁的
上一頁和下一頁的頁號。
通過建立一個雙向鏈表,保證這些頁與頁之間在邏輯上連接而非物理連接。
FIL_PAGE_SPACE_OR_CHKSUM(4字節):代表
當前頁面的校驗和(checksum)。
? 什么是校驗和?
就類似于一個很長的字符串,通過某種算法計算出一個比較短的值來代表這個字符串,這個比較短的值就是校驗和。
? 為什么要使用校驗和?
在比較兩個很長的字符串時,如果直接進行比較的話,肯定會比較慢的。但是,如果通過比較兩個字符串的校驗和(其中,生成校驗和耗時可以忽略不計):校驗和相同就代表兩個字符串相同,反之則不同。這種方式很明顯會縮短比較時的耗時。
? 校驗和在頁面上有什么作用?
校驗和這個屬性是存在于文件頭部和文件尾部的。InnoDB 以頁為單位把數據加載到內存中處理,如果該頁中的數據在內存中被修改了,那么在修改后的某個時間就需要把數據同步刷新到磁盤中了。但是同步時可能會出現斷電、磁盤損壞等一系列不可抗因素,從而造成數據頁傳輸的不完整。
為了檢測一個頁是否刷盤成功,就可以通過文件頭部的校驗和與文件尾部的校驗和做對比,如果兩個值不相等則說明頁刷盤失敗,需要重新刷盤(數據重試或回滾操作);否則認為頁刷盤成功。
FIL_PAGE_LSN(8字節):頁面被最后修改時對應的日志序列位置(Log Sequence Number,簡稱:LSN)。
02、File Trailer(文件尾部)
- 前 4 個字節:代表頁的校驗和,這個部分與 File Header 中的校驗和相對應。
- 后 4 個字節:代表頁面被最后修改時對應的日志序列位置(LSN),這個部分也是為了校驗頁的完整性,如果首部和尾部的 LSN 值校驗不成功的話,也說明同步過程出現了錯了(刷盤失敗)。
3.2.2 空閑空間、用戶記錄、最大最小記錄(上下確界)
頁的主要作用是存儲記錄,所以,用戶記錄和最大最小記錄占了頁結構的主要空間。
01、Free Space(空閑空間)
當我們存儲一條數據的時候,存儲的記錄會按照指定的行格式存儲到 User Records 部分。但是在最開始生成頁的時候,其實是沒有 User Record 這個部分的。當每次插入一條記錄時,都會從 Free Space(空閑空間)中申請一個記錄大小的空間劃分到 User Record 部分。當 Free Space 的空間被劃分完之后,也就意味著這個頁使用完了,如果還有新的記錄插入的話,就需要去申請新的頁了。
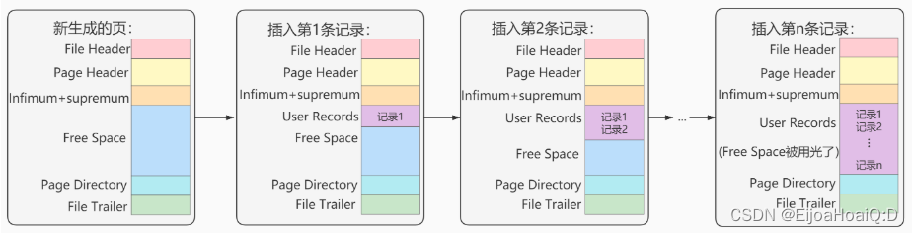
02、User Record(用戶記錄)
User Record 中的這些記錄按照指定的行格式一條一條地擺在 User Record 部分,相互之間形成單鏈表。
至于這里的一條一條記錄是如何存儲的,可以查看:InnoDB 行格式。
03、Infimum + Supremum(最小最大記錄)
對于一條完整的記錄來說,比較記錄的大小就是比較主鍵的大小,記錄會按照主鍵值從小到大的順序形成一個單向鏈表。
InnoDB 規定的最小記錄和最大記錄這兩條記錄的構造其實很簡單,都是由 5 字節大小的記錄頭信息和 8 字節大小的一個固定的部分組成的:
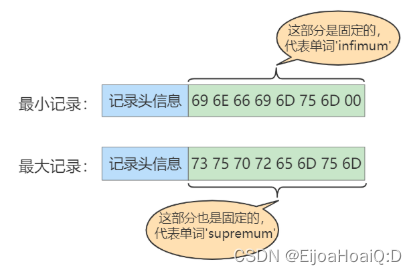
這兩條記錄其實不是用戶自己插入的,而是在生成頁的時候默認自動創建的,并稱為偽記錄或虛擬記錄,它們并不存放在 User Record 部分,而是單獨存放在 Infimum + Supremum 部分:

這里記錄頭信息中有一個屬性:heap_no(記錄在堆中的相對位置)。InnoDB 把記錄一條一條親密無間排列的結構稱之為堆,其實此屬性就是當前記錄在本頁中的位置,并把這兩條偽記錄的值分別設為 0 和 1。
3.2.3 頁目錄、頁面頭部
01、Page Directory(頁目錄)
為什么需要頁目錄?
在頁中,記錄是以單向鏈表的形式進行存儲的。單向鏈表的特點就是插入、刪除非常方便,但是檢索效率不高,最差的情況下需要遍歷鏈表上的所有節點才能完成檢索。所以在頁結構中專門設計了頁目錄這個模塊,專門給記錄做一個目錄,通過二分查找法的方式進行檢索,提升效率。
假設現在有一條查詢語句:
select * from page_demo where c1 = 3;
根據主鍵查找頁中的某條記錄,如何實現快速查找呢?
? 方式一
順序查找:從 Infimum 記錄(最小記錄)開始,沿著鏈表一直往后找,數據量非常大的時候,性能非常差。
? 方式二
使用頁目錄,二分法查找。
- 將所有的記錄分成若干個組,這些記錄中包含最小記錄和最大記錄,但不包括
被標記為刪除的記錄。 - 第 1 組只有一條記錄,最小記錄所在的組。最后一組,也就是最大記錄所在的分組,會有 1-8 條記錄。其他分組,會有 4-8 條記錄。【這樣做的好處是除了第 1 組外,其余組的記錄數會
盡量平分】。 - 每個組中的最后一條記錄的頭信息中會存儲該組中一共有多少條記錄,來作為 n_owned 字段的值。
頁目錄用來存儲最后一條記錄的地址偏移量,這些地址偏移量會按照順序存儲起來,每組的地址偏移量也被稱為槽(Slot),每個槽相當于指針指向了不同組的最后一條記錄。
假設現在的 page_demo 表中正常的記錄共有 6 條,InnoDB 會把它們分成兩組,第一組中只有一個最小記錄,第二組中是剩余的 5 條記錄。分組后:
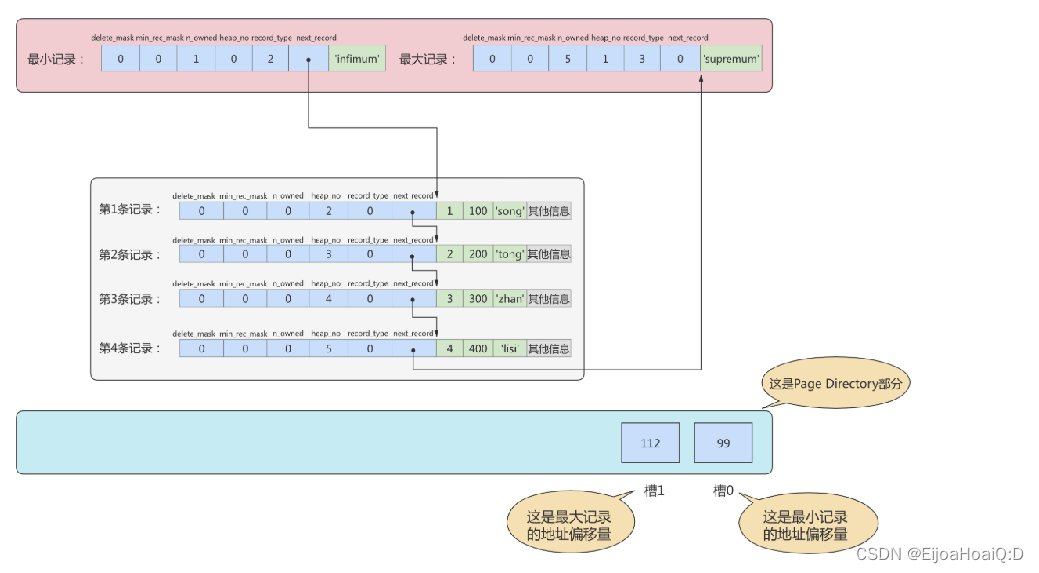
上圖的槽位:
- 槽 0:指向的是最小記錄的地址偏移量。
- 槽 1:指向的是最大記錄的地址偏移量。
用指針代替數字后:
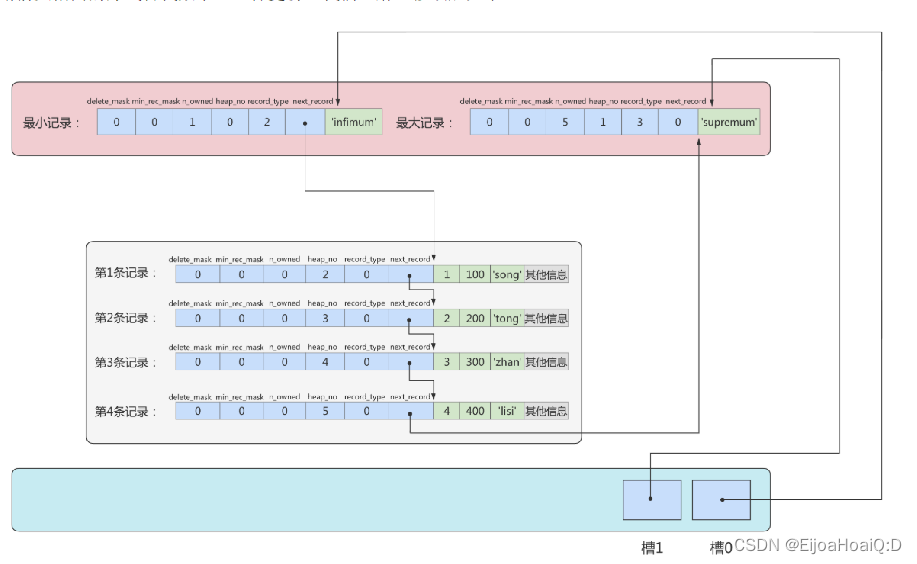
再換個角度看,單純從邏輯上看一下這些記錄和頁目錄的關系:
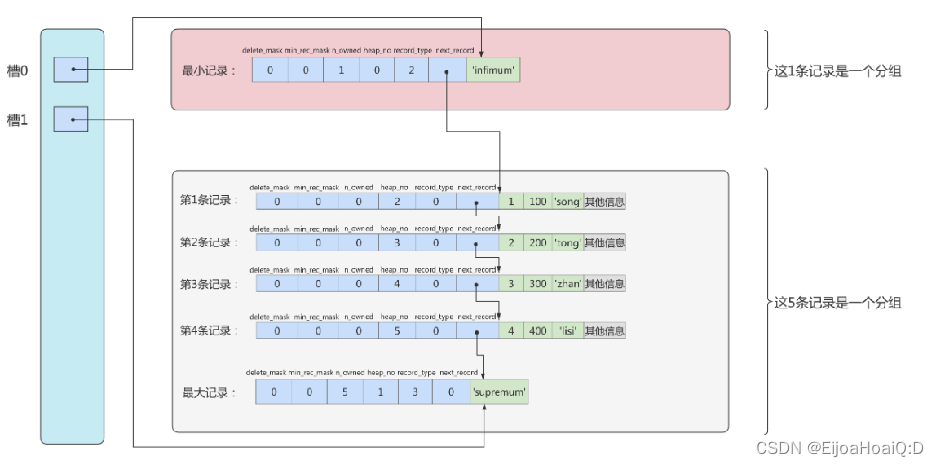
對頁目錄有個大致的了解后,引申出兩個問題:
? 問題一:頁目錄分組的個數是如何確定的?
在上述分組中,為什么最小記錄的 n_owned 為 1,而最大記錄的 n_owned 的值為 5 呢?
InnoDB 規定:對于最小記錄所在的分組只能有 1 條記錄,最大記錄所在的分組擁有的記錄條數只能在 1~8 條之間,剩下的分組中記錄的條數范圍只能是在 4~8 條之間。
分組的步驟是這樣的:
- 初始情況下只有兩條記錄(兩個槽):最大記錄和最小記錄,它們分別屬于兩個組。
- 每當插入一條記錄,都會從頁目錄中找到主鍵值比本身記錄的主鍵值大,并且差值最小的槽(從本質上來說,槽是一個組內最大的那條記錄在頁面中的地址偏移量,通過槽可以快速找到對應的主鍵值),然后把該槽對應記錄的 n_owned 值加一(表示本組內又添加了一條記錄),直到該組中的記錄數等于 8 個。
- 當一個組中的記錄數等于 8 后,再插入一條記錄時,會將組中的記錄拆分成兩個組,其中一個組中 4 條記錄,另一個 5 條記錄。這個拆分的過程會在頁目錄中新增一個槽 ,記錄這個新增分組中最大的那條記錄的偏移量。
? 問題二:頁目錄結構下如何快速查找記錄?
假設現在新增了 12 條數據(模擬大數據量下查找記錄的過程):
INSERT INTO page_demo
VALUES
(5, 500, 'zhou'),
(6, 600, 'chen'),
(7, 700, 'deng'),
(8, 800, 'yang'),
(9, 900, 'wang'),
(10, 1000, 'zhao'),
(11, 1100, 'qian'),
(12, 1200, 'feng'),
(13, 1300, 'tang'),
(14, 1400, 'ding'),
(15, 1500, 'jing'),
(16, 1600, 'quan');
新添加 12 條記錄后,頁里共有 18 條記錄了(包括最大記錄和最小記錄),這些記錄被分成了 5 組:
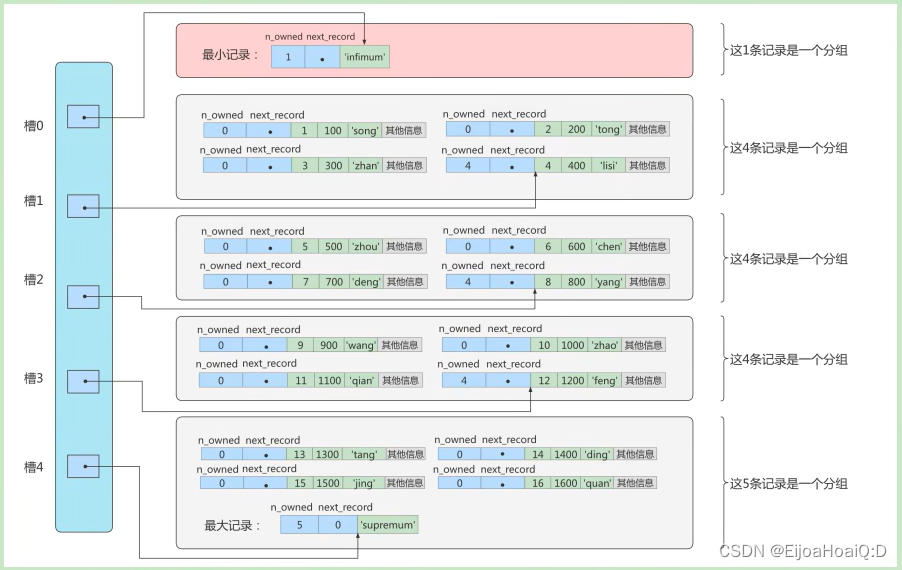
這里為了方便展示,只保留了 16 條記錄的記錄頭信息中的 n_owned 和 next_record 屬性,省略了各個記錄之間的箭頭。
這五個槽位的編號分別為:0、1、2、3、4,所以最初情況下最低的槽就是 low = 0,最高槽就是 high = 4。由于各個槽代表的記錄的主鍵值都是從小到大排序的,所以可以采用二分法來進行快速查找主鍵值為 6 的記錄:
- 計算中間槽的位置:(0 + 4)/ 2 = 2,所以查看槽 2 對應記錄的主鍵值為 8,而 8 > 6,所以設置 high = 2,low 保持不變。
- 重新計算中間槽的位置:(0 + 2)/ 2 = 1,所以查看槽 1 對應記錄的主鍵值為 4,而 4 < 6,所以設置 low = 1,high 保持不變。
- 因為 high - low 的值為 1,所以確定主鍵值為 6 的記錄在槽 2 對應的組中。沿著槽 2 中主鍵值所在的單鏈表中遍歷即可得到主鍵值為 6 的記錄。
由于每個組中包含的記錄的條數只能是 1~8 條,所以遍歷一個組中的記錄的代價是很小的。
在一個數據頁中查找指定主鍵值的記錄的過程分為兩步:
- 通過二分法在頁目錄中確定要查找的主鍵所在槽位的上一個槽位,并找到該槽所在分組中主鍵值最大的記錄;
- 從當前主鍵值最大的記錄開始,通過 next_record 屬性往后遍歷,直到找到要查找的記錄為止。
02、Page Header(頁面頭部)
為了能得到一個數據頁中存儲的記錄的狀態信息,比如:
- 本頁中已經存儲了多少條記錄?
- 第一條記錄的地址是什么?
- 頁目錄中存儲了多少個槽?…
特意在頁中定義了一個叫 Page Header 的部分,這個部分占用固定的 56 個字節,專門存儲各種狀態信息。
有這些屬性:
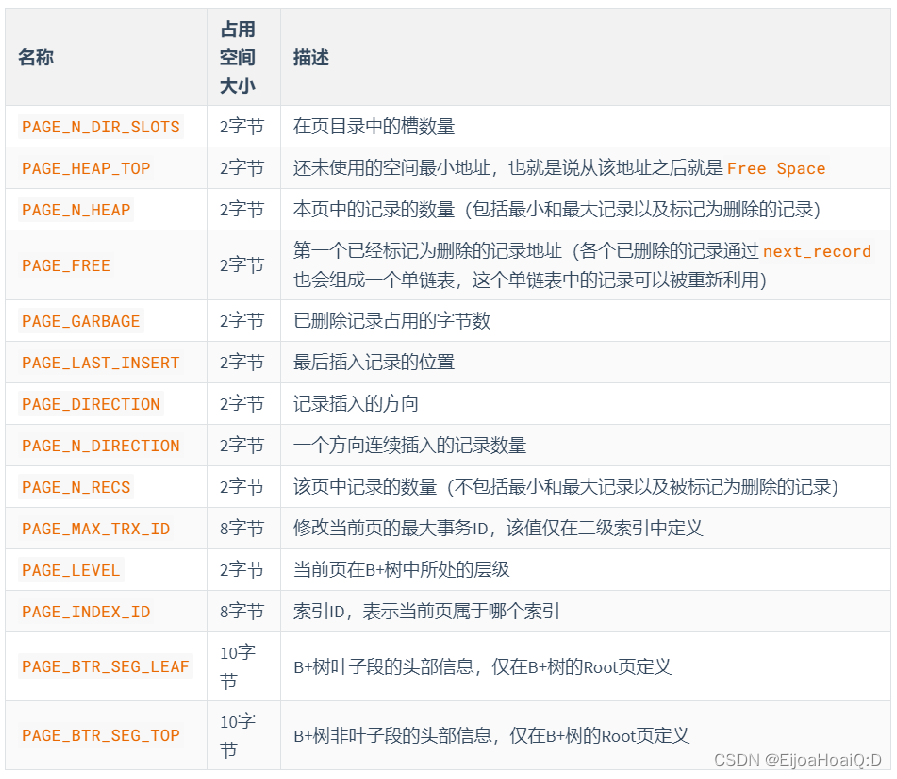
PAGE_DIRECTION:記錄插入的方向。
比如:新插入的一條記錄的主鍵值比上一條記錄的主鍵值大,就說這條記錄的插入方向是右邊;反之則是左邊。
PAGE_N_DIRECTION:一個方向連續插入的記錄數量。
假設連續幾次插入新紀錄的方向都是一致的,InnoDB 會把沿著同一個方向插入記錄的條數記錄下來,這個條數就使用此狀態表示。但如果最后一條記錄的插入方向改變了的話,這個狀態的值是會被清零重新統計的。
3.3 從數據頁的角度看 B+ 樹如何查詢
一顆 B+ 樹按照節點類型可以分成兩部分:
- 葉子節點:B+ 樹最底層的節點,節點的高度為 0,存儲行記錄。
- 非葉子節點:節點的高度大于 0,存儲索引鍵和頁面指針,并不存儲行記錄本身。
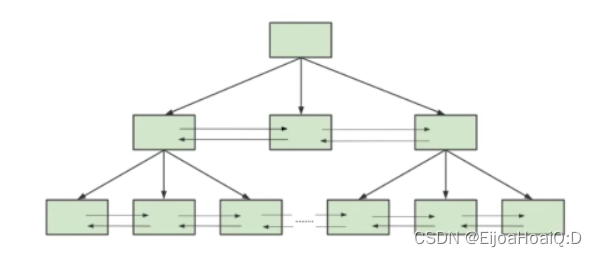
3.3.1 B+ 樹是如何進行記錄檢索的?
通過 B+Tree 的索引查詢記錄,首先是從根節點開始逐層檢索,直到找到記錄所在的葉子節點,然后將整個數據頁從磁盤中加載到內存中,頁目錄中的槽(slot)可以通過 二分查找的方式定位到記錄所在的槽(分組),通過鏈表遍歷的方式查找到記錄。
3.3.2 普通索引和唯一索引在查詢效率上有什么不同?
唯一索引其實就是在普通索引上增加了約束,也就是關鍵字唯一,找到關鍵字之后就停止檢索。
而普通索引存在用戶記錄中的關鍵字相同的情況。根據頁結構的原理,當我們讀取一條記錄的時候,不是單獨將這條記錄從磁盤中讀出去,而是將這個記錄所在的頁加載到內存中進行讀取,而一個頁中可能存儲著上千個記錄。因為普通索引可能存在關鍵字重復的情況,所以查找到關鍵字后仍需往后再多幾次 “判斷下一條記錄” 的操作,而此時頁已經被加載到內存中去了,所以不會涉及 I/O 操作了,而在內存中判斷所消耗的時間是可以忽略不計的。
所以,對一個索引字段進行檢索時,采用普通索引還是唯一索引在檢索效率上基本是沒有區別的。

)

 AI單詞助手(谷歌瀏覽器插件))





,經歷坎坷但值了!)









