????????上學期的大數據處理課程,筆者被分配到Impala的匯報主題。然而匯報內容如果單純只介紹Impala的理論知識,實在是有些太過膚淺,最起碼得有一些實際操作來展示一下Impala的功能。但是Impala的配置實在是有些困難與繁瑣,于是筆者通過各種渠道找到了Cloudera公司(Hadoop數據管理軟件與服務提供商)在早些年發行的虛擬機文件,通過配置該虛擬機可以直接獲得一個較為完整的大數據處理應用環境(包括Hadoop、Impala等數種大數據處理應用)。
【虛擬機文件資源已上傳百度網盤,沒辦法,這個虛擬機文件實在是太大了(5+G),要不然我就直接在博客上資源綁定了】
鏈接:https://pan.baidu.com/s/1hRhJySvZTqmxUvqZJ3tYuQ?pwd=a6t3?
提取碼:a6t3?
?
虛擬機軟件
? ? ? ? 筆者使用的虛擬機軟件是Oracle VM VirtualBox(圖標如下),關于該軟件的詳細安裝步驟請恕筆者不在此贅述,直接進入配置階段。

?配置cloudera-quickstart虛擬機
將文件夾全部下載下來后,文件夾里應該有這兩個文件,不能有缺漏。

確認無誤后,打開虛擬機,導入該虛擬機文件,如下圖。
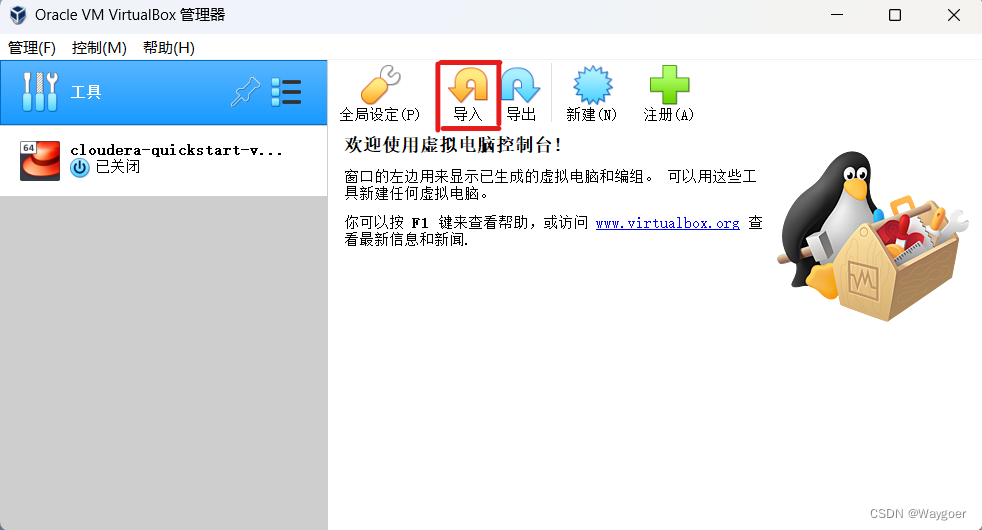
在下列劃橫線處選擇下載好的虛擬機文件路徑
(選擇圖標為黃色方塊的那個文件,文件格式為ovf)

進入下一步,該頁面全部采用默認設置即可👇?
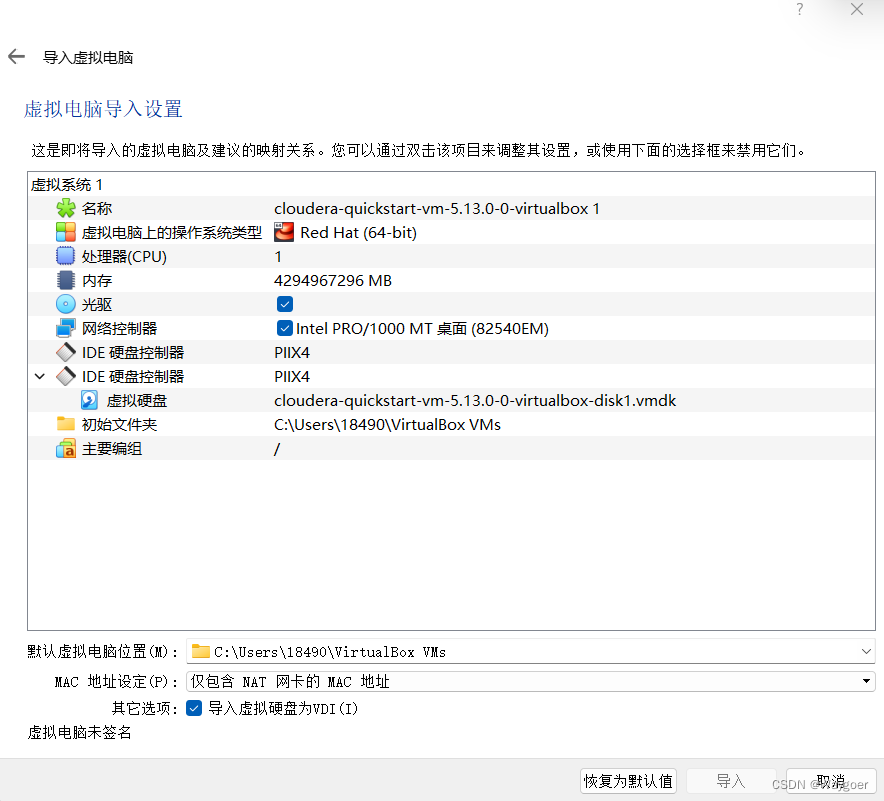
設置完成后,點擊導入即可在虛擬機首頁看到虛擬機文件。但此時還不能直接運行,因為該虛擬機對于內存和顯存都有一定要求,必須進行額外的設置才能滿足虛擬機運行的條件,筆者嘗試了一種可正常運行的設置方案如下:
首先點擊設置
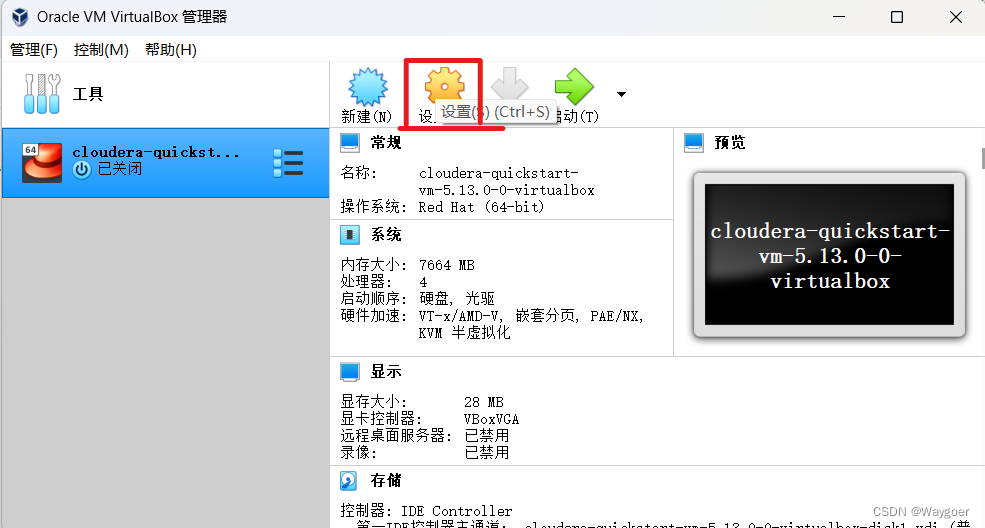
在“系統-主板”選項中,將內存改為7500MB(也可以再稍微調大一些,根據實際情況來)
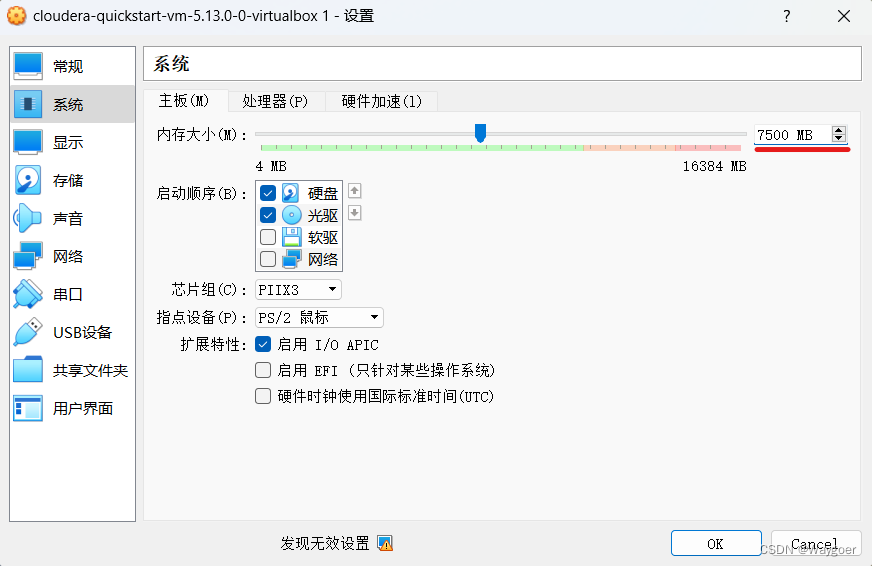
在“系統-處理器”界面,將“處理器數量”更改為4個。

在“顯示-屏幕”選項中,將“顯存大小”更改為28MB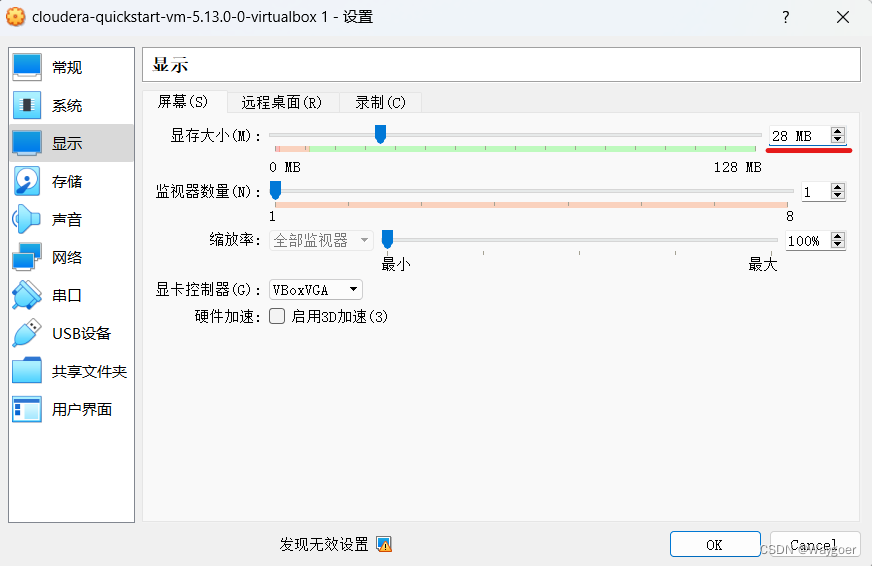 完成如上設置后,點擊運行虛擬機,一般情況下即可正常完成運行。虛擬機的啟動過程比較緩慢,需要耐心等待,啟動成功后虛擬機如下圖所示。該虛擬機中基本包含了大數據處理的所有基本應用(包括Hadoop、Impala、Hive等),虛擬機的操作系統是Red Hat,跟Ubuntu差不多,啟動這些應用可以直接通過終端命令行進行操作。?
完成如上設置后,點擊運行虛擬機,一般情況下即可正常完成運行。虛擬機的啟動過程比較緩慢,需要耐心等待,啟動成功后虛擬機如下圖所示。該虛擬機中基本包含了大數據處理的所有基本應用(包括Hadoop、Impala、Hive等),虛擬機的操作系統是Red Hat,跟Ubuntu差不多,啟動這些應用可以直接通過終端命令行進行操作。?
實操應用
本部分主要對Impala的大數據處理操作進行一些實操演示,并將其與Hive進行一個簡單對比。
Impala適用于處理在Hadoop集群中的大量數據的MPP(大規模并行處理)SQL查詢引擎。它是一個用C++和Java編寫的開源軟件。與其他Hadoop的SQL引擎相比,它提供了高性能和低延遲。
簡而言之,它提供了訪問存儲在Hadoop分布式文件系統中的數據的最快方法。但是Impala只能處理PB級別的數量級,更大數量級的數據處理起來性能很差。它的主要應用在于處理實時數據、進行交互計算。
接下來進行Impala的相關操作
首先啟動Impala,如下在命令行中直接輸入“impala-shell”。
Impala的控制語句和數據庫的控制語句基本相同,以下演示幾個基本命令。
【創建數據庫】

【向表格中插入數據】
在Impala中的相關操作,都可以在虛擬機中自帶的Hue中進行可視化數據查看,如下展示了筆者通過Impala插入了若干數據后查看的結果。
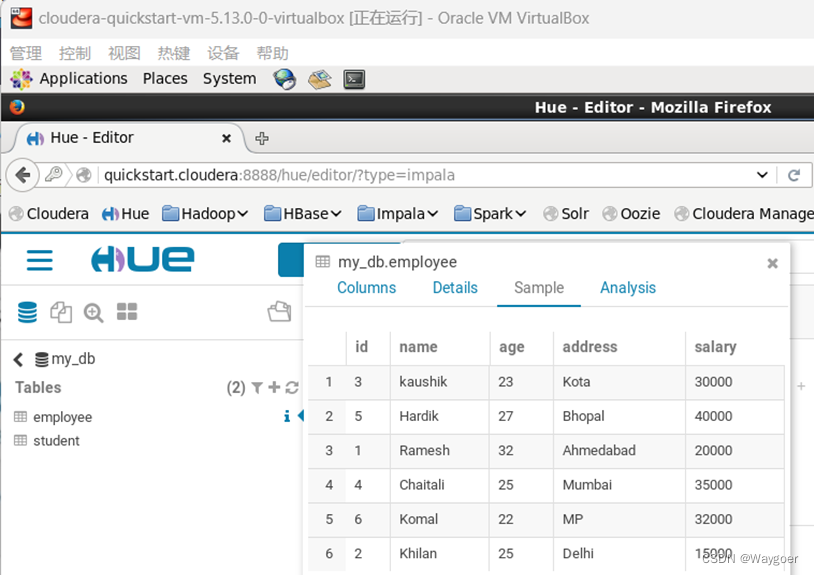
為了更好地理解Impala”快“的特點,筆者簡單插入了20個數據,并將impala和hive進行取數據的時間對比,比較兩者的速度差異。(左側為hive,右側為impala)
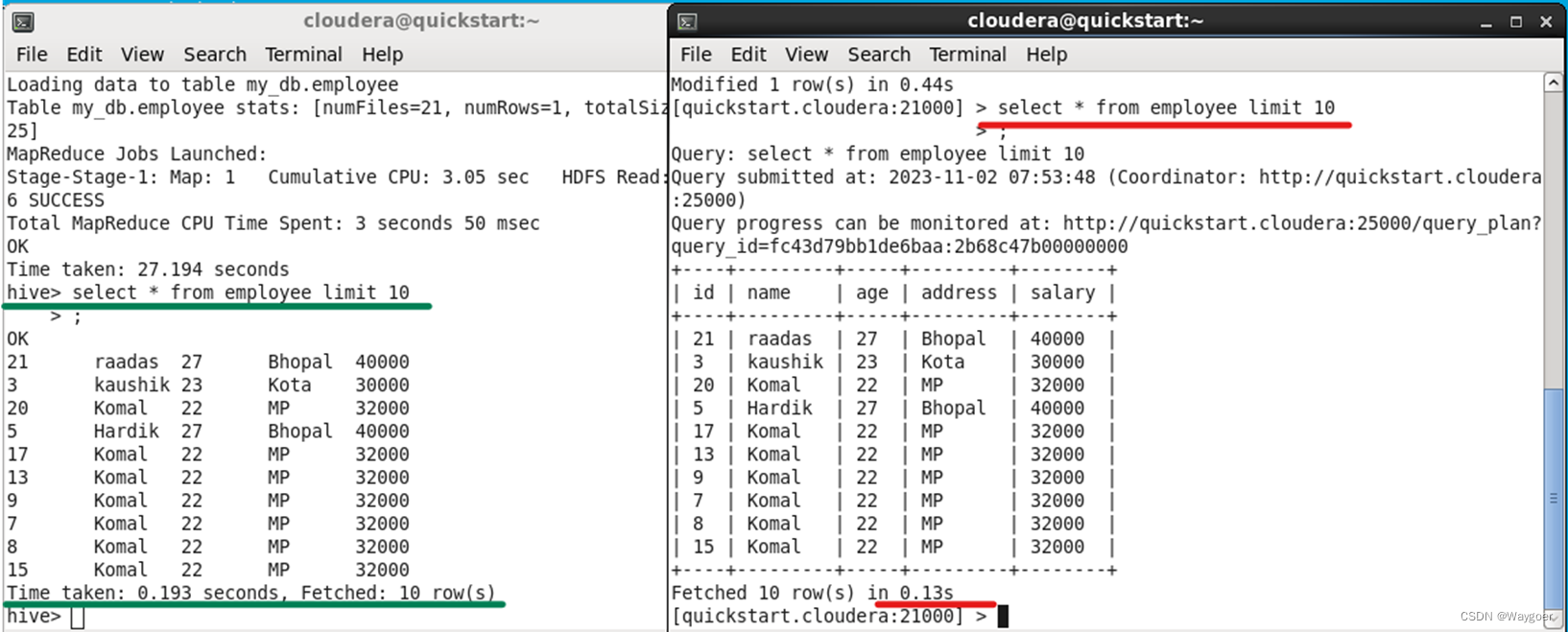
筆者進行多次操作確保時間達到相對穩定的值,可以看到,在較少樣本的情況下,impala仍然能比hive快0.06s。
當然以上的對比差異可能不夠顯著,主要是因為樣本的數量實在過少,但是根據筆者搜索到的一個大樣本數據測試顯示,impala在實時處理、交互計算方面確實存在明顯的優勢。
以上就是本篇博客的全部內容,歡迎大家下載資源進行測試。cloudera的虛擬機文件近年來已經不再發行了,本篇博客中的虛擬機文件差不多算是絕品了,筆者當時能找到這個文件真的是費勁了九牛二虎之力啊,實屬不易~果然做研究是必須要下大功夫的!


)
對象—— vba實現)






和構造方法執行優先級比較)




)


流重載)
