?? 歡迎大家來到貝蒂大講堂??🎈🎈養成好習慣,先贊后看哦~🎈🎈
所屬專欄:數據結構與算法
貝蒂的主頁:Betty‘s blog

前言
隨著應用程序變得越來越復雜和數據越來越豐富,幾百萬、幾十億甚至幾百億的數據就會出現,而對這么大對數據進行搜索、插入或者排序等的操作就越來越慢,人們為了解決這些問題,提高對數據的管理效率,提出了一門學科即:數據結構與算法
1. 什么是數據結構
**數據結構(Data Structure)**是計算機存儲、組織數據的方式,指相互之間存在一種或多種特定關系的數據元素的集合。
下標是常見的數據結構:
| 名稱 | 定義 |
|---|---|
| 數組(Array) | 數組是一種聚合數據類型,它是將具有相同類型的若干變量有序地組織在一起的集合。 |
| 鏈表(Linked List) | 鏈表是一種數據元素按照鏈式存儲結構進行存儲的數據結構,這種存儲結構具有在物理上存在非連續的特點。 |
| 棧(Stack) | 棧是一種特殊的線性表,它只能在一個表的一個固定端進行數據結點的插入和刪除操作 |
| 隊列(Queue) | 隊列和棧類似,也是一種特殊的線性表。和棧不同的是,隊列只允許在表的一端進行插入操作,而在另一端進行刪除操作。 |
| 樹(Tree) | 樹是典型的非線性結構,它是包括,2 個結點的有窮集合 K |
| 堆(Heap) | 堆是一種特殊的樹形數據結構,一般討論的堆都是二叉堆。 |
| 圖(Graph) | 圖是另一種非線性數據結構。在圖結構中,數據結點一般稱為頂點,而邊是頂點的有序偶對 |
2. 什么是算法
**算法(Algorithm)😗*就是定義良好的計算過程,他取一個或一組的值為輸入,并產生出一個或一組值作為輸出。簡單來說算法就是一系列的計算步驟,用來將輸入數據轉化成輸出結果。
算法一般分為:排序,遞歸與分治,回溯,DP,貪心,搜索算法
- 算法往往數學密切相關,就如數學題一樣,每道數學題都有不同的解法,算法也是同理。
3. 復雜度分析
3.1 算法評估
我們在進行算法分析時,常常需要完成兩個目標**。一個是找出問題的解決方法,另一個就是找到問題的最優解**。而為了找出最優解,我們就需要從兩個維度分析:
- 時間效率:算法運行的快慢
- 空間效率:算法所占空間的大小
3.2 評估方法
評估時間的方法主要分為兩種,一種是實驗分析法,一種是理論分析法。
(1) 實驗分析法
實驗分析法簡單來說就是將不同種算法輸入同一臺電腦,統計時間的快慢。但是這種方法有兩大缺陷:
- 無法排查實驗自身條件與環境的條件的影響:比如同一種算法在不同配置的電腦上的運算速度可能完全不同,甚至結果完全相反。我們很難排查所有情況。
- 成本太高:同一種算法可能在數據少時表現不明顯,在數據多時速率較快
(2) 理論分析法
由于實驗分析法的局限性,就有人提出了一種理論測評的方法,就是漸近復雜度分析(asymptotic complexity analysis),簡稱復雜度分析。
這種方法體現算法運行所需的時間(空間)資源與輸入數據大小之間的關系,能有效的反應算法的優劣。
4. 時間復雜度與空間復雜度
4.1 時間復雜度
一個算法所花費的時間與其中語句的執行次數成正比例,算法中的基本操作的執行次數,為算法的時間復雜度。
為了準確的表述一段代表所需時間,我們先假設賦值(=)與加號(+)所需時間為1ns,乘號(×)所需時間為2ns,打印所需為3ns。
讓我們計算如下代碼所需總時間:
int main()
{int i = 1;//1nsint n = 0;//1nsscanf("%d", &n);for (i = 0; i < n; i++){printf("%d ", i);//3ns}return 0;
}
計算時間如下:
T ( n ) = 1 + 1 + 3 × n = 3 n + 2 T(n)=1+1+3×n=3n+2 T(n)=1+1+3×n=3n+2
但是實際上統計每一項所需時間是不現實的,并且由于是理論分析,當n—>∞時,其余項皆可忽略,T(n)的數量級由最高階決定。所以我們計算時間復雜度時,可以簡化為兩個步驟:
- 忽略除最高階以外的所有項。
- 忽略所有系數。
而上述代碼時間可以記為O(n),這種方法被稱為大O的漸進表示法。如果計算機結果全是常數,則記為O(1)。
- 并且計算復雜度時,有時候會出現不同情況的結果,這是應該以最壞的結果考慮。
4.2 空間復雜度
空間復雜度也是一個數學表達式,是對一個算法在運行過程中臨時占用存儲空間大小的量度 。空間復雜度的表示也遵循大O的漸進表示法
讓我們計算一下冒泡排序的空間復雜度
// 計算BubbleSort的空間復雜度?
void BubbleSort(int* a, int n)
{assert(a);for (size_t end = n; end > 0; --end){int exchange = 0;for (size_t i = 1; i < end; ++i){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);exchange = 1;}}if (exchange == 0)break;}
}
- 通過觀察我們可以看出,冒泡排序并沒有開辟多余的空間,所以空間復雜度為O(1).
5. 復雜度分類
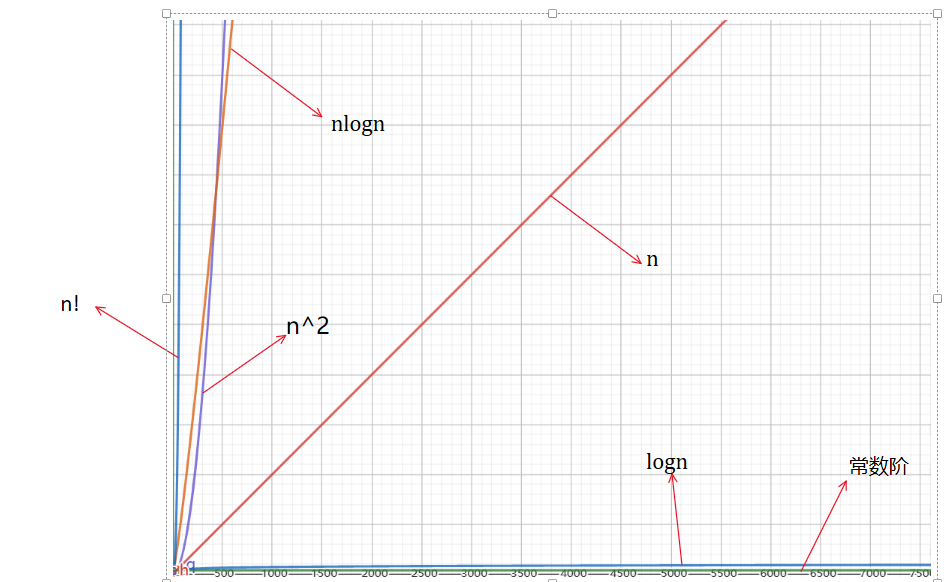
算法的復雜度有幾個量級,表示如下:
O ( 1 ) < O ( l o g N ) < O ( N ) < O ( N l o g N ) < O ( N 2 ) < O ( 2 N ) < O ( N ! ) O(1) < O( log N) < O(N) < O(Nlog N) < O(N 2 ) < O(2^N) < O(N!) O(1)<O(logN)<O(N)<O(NlogN)<O(N2)<O(2N)<O(N!)
- 從左到右復雜度依次遞增,算法的缺點也就越明顯
圖示如下:
5.1 常數O(1)階
常數階是一種非常快速的算法,但是在實際應用中非常難實現
以下是一種時間復雜度與空間復雜度皆為O(1)的算法:
int main()
{int a = 0;int b = 1;int c = a + b;printf("兩數之和為%d\n", c);return 9;
}
5.2 對數階O(logN)
對數階是一種比較快的算法,它一般每次減少一半的數據。我們常用的二分查找算法的時間復雜度就為O(logN)
二分查找如下:
int binary_search(int nums[], int size, int target) //nums是數組,size是數組的大小,target是需要查找的值
{int left = 0;int right = size - 1; // 定義了target在左閉右閉的區間內,[left, right]while (left <= right) { //當left == right時,區間[left, right]仍然有效int middle = left + ((right - left) / 2);//等同于 (left + right) / 2,防止溢出if (nums[middle] > target) {right = middle - 1; //target在左區間,所以[left, middle - 1]} else if (nums[middle] < target) {left = middle + 1; //target在右區間,所以[middle + 1, right]} else { //既不在左邊,也不在右邊,那就是找到答案了return middle;}}//沒有找到目標值return -1;
}
空間復雜度為O(logN)的算法,一般為分治算法
比如用遞歸實現二分算法:
int binary_search(int ar[], int low, int high, int key)
{if(low > high)//查找不到return -1;int mid = (low+high)/2;if(key == ar[mid])//查找到return mid;else if(key < ar[mid])return Search(ar,low,mid-1,key);elsereturn Search(ar,mid+1,high,key);
}
每一次執行遞歸都會對應開辟一個空間,也被稱為棧幀。
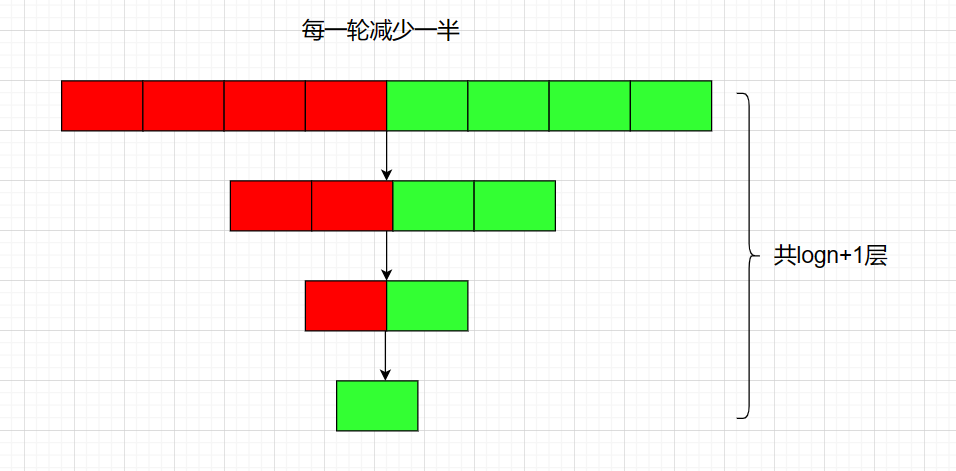
5.3 線性階O(N)
線性階算法,時間復雜度與空間復雜度隨著數量均勻變化。
遍歷數組或者鏈表是常見的線性階算法,以下為時間復雜度為O(N)的算法:
int main()
{int n = 0;int count = 0;scanf("%d", &n);for (int i = 0; i < n; i++){count += i;//計算0~9的和}return 0;
}
以下為空間復雜度為O(N)的算法
int main()
{int n = 0;int count = 0;scanf("%d", &n);int* p = (int*)malloc(sizeof(int) * n);//開辟大小為n的空間if (p == NULL){perror("malloc fail");return -1;}free(p);p=NULL;return 0;
}
5.4 線性對數階O(NlogN)
無論是時間復雜度還是空間復雜度,線性對數階一般出現在嵌套循環中,即一層的復雜度為O(N),另一層為O(logN)
比如說循環使用二分查找打印:
int binary_search(int nums[], int size, int target) //nums是數組,size是數組的大小,target是需要查找的值
{int left = 0;int right = size - 1; // 定義了target在左閉右閉的區間內,[left, right]while (left <= right) { //當left == right時,區間[left, right]仍然有效int middle = left + ((right - left) / 2);//等同于 (left + right) / 2,防止溢出if (nums[middle] > target) {right = middle - 1; //target在左區間,所以[left, middle - 1]}else if (nums[middle] < target) {left = middle + 1; //target在右區間,所以[middle + 1, right]}else { //既不在左邊,也不在右邊,那就是找到答案了printf("%d ", nums[middle]);}}//沒有找到目標值return -1;
}
void func(int nums[], int size, int target)
{for (int i = 0; i < size; i++){binary_search(nums, size, target);}
}
空間復雜度為O(NlogN)的算法,最常見的莫非歸并排序
void Merge(int sourceArr[],int tempArr[], int startIndex, int midIndex, int endIndex){int i = startIndex, j=midIndex+1, k = startIndex;while(i!=midIndex+1 && j!=endIndex+1) {if(sourceArr[i] > sourceArr[j])tempArr[k++] = sourceArr[j++];elsetempArr[k++] = sourceArr[i++];}while(i != midIndex+1)tempArr[k++] = sourceArr[i++];while(j != endIndex+1)tempArr[k++] = sourceArr[j++];for(i=startIndex; i<=endIndex; i++)sourceArr[i] = tempArr[i];
}//內部使用遞歸
void MergeSort(int sourceArr[], int tempArr[], int startIndex, int endIndex) {int midIndex;if(startIndex < endIndex) {midIndex = startIndex + (endIndex-startIndex) / 2;//避免溢出intMergeSort(sourceArr, tempArr, startIndex, midIndex);MergeSort(sourceArr, tempArr, midIndex+1, endIndex);Merge(sourceArr, tempArr, startIndex, midIndex, endIndex);}
}
5.5 平方階O(N2)
平方階與線性對數階相似,常見于嵌套循環中,每層循環的復雜度為O(N)
時間復雜度為O(N2),最常見的就是冒泡排序
void BubbleSort(int* a, int n)
{assert(a);for (size_t end = n; end > 0; --end){int exchange = 0;for (size_t i = 1; i < end; ++i){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);exchange = 1;}}if (exchange == 0)break;}
}
計算過程如下;
T ( N ) = 1 + 2 + 3 + . . . . . . + n ? 1 = ( n 2 ? n ) / 2 = O ( n 2 ) T(N)=1+2+3+......+n-1=(n^2-n)/2=O(n^2) T(N)=1+2+3+......+n?1=(n2?n)/2=O(n2)
空間復雜度為O(N2),最簡單的就是動態開辟。
{int n = 0;int count = 0;scanf("%d", &n);int* p = (int*)malloc(sizeof(int) * n*n);//開辟大小為n的空間if (p == NULL){perror("malloc fail");return -1;}free(p);p=NULL;return 0;
}
5.6 指數階O(2N)
指數階的算法效率低,并不常用。
常見的時間復雜度為O(2N)的算法就是遞歸實現斐波拉契數列:
int Fib1(int n)
{if (n == 1 || n == 2){return 1;}else{return Fib1(n - 1) + Fib1(n - 2);}
}
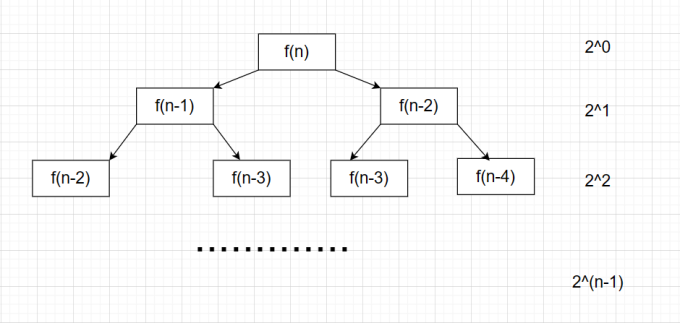
粗略估計
T ( n ) = 2 0 + 2 1 + 2 2 + . . . . . + 2 ( n ? 1 ) = 2 n ? 1 = O ( 2 N ) T(n)=2^0+2^1+2^2+.....+2^(n-1)=2^n-1=O(2^N) T(n)=20+21+22+.....+2(n?1)=2n?1=O(2N)
- 值得一提的是斐波拉契的空間復雜度為O(N),因為在遞歸至最深處后往回歸的過程中,后續空間都在銷毀的空間上建立的,這樣能大大提高空間的利用率。
空間復雜度為O(2N)的算法一般與樹有關,比如建立滿二叉樹
TreeNode* buildTree(int n) {if (n == 0)return NULL;TreeNode* root = newTreeNode(0);root->left = buildTree(n - 1);root->right = buildTree(n - 1);return root;
}
5.7 階乘階O(N!)
階乘階的算法復雜度最高,幾乎不會采用該類型的算法。
這是一個時間復雜度為階乘階O(N!)的算法
int func(int n)
{if (n == 0)return 1;int count = 0;for (int i = 0; i < n; i++) {count += func(n - 1);}return count;
}
示意圖:
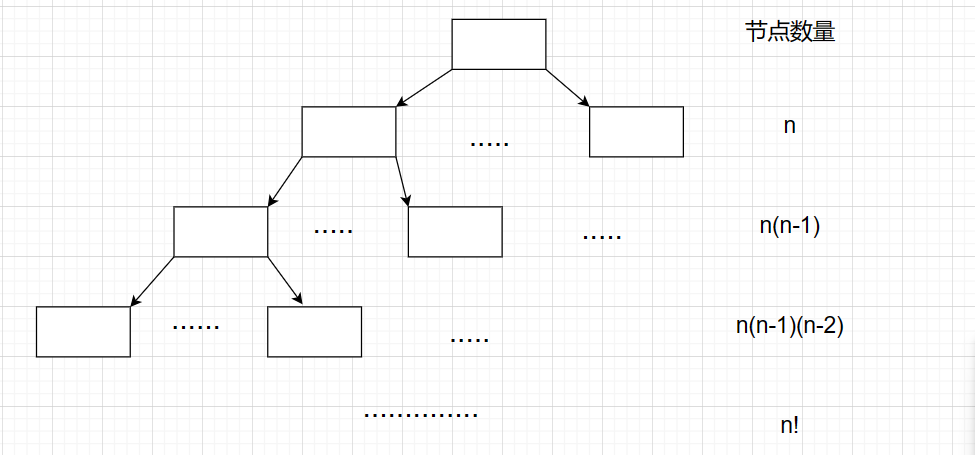
- 空間復雜度為階乘階O(N!)的算法并不常見,這里就不在一一列舉。




Windows系統---保姆級教程)

)




)


)
)
)


