目錄
一.Sora出道即巔峰
二.為何說Sora是該領域的巨頭
三.Sora無敵的背后究竟有怎樣先進的處理技術
1.Spacetime Latent Patches 潛變量時空碎片,建構視覺語言系統
2.擴散模型與Diffusion Transformer,組合成強大的信息提取器
3.DiT應用于潛變量時空碎片,學習獲得海量視頻中時空碎片的動態關聯
4.Sora 或Lumiere 視頻學習與生成的技術背后蘊含的原理分析
四.OpenAI官方給予Sora的說明
1.優勢及缺陷
2.安全問題的考慮及解決方案
3.研究技術
五.穿梭于虛實之間的sora是否會打破虛擬與現實的平衡
Sora官網https://openai.com/sora
一.Sora出道即巔峰
Sora是OpenAI在2024年2月16日發布的首個文本生成視頻模型。該模型能夠理解復雜場景中不同元素之間的物理屬性及其關系,從而深度模擬真實物理世界,生成具有多個角色、包含特定運動的復雜場景。Sora繼承了Dall·E-3的畫質和遵循指令能力,可以根據用戶的文本提示快速制作長達一分鐘的高保真視頻,還能獲取現有的靜態圖像并從中生成視頻。
?
Sora的發布使內容創作領域的專業難度降低,作為實現通用人工智能(AGI)的重要里程碑,其問世標志著人工智能在理解真實世界場景并與之互動的能力方面實現了重大飛躍。
二.為何說Sora是該領域的巨頭
Sora是OpenAI在2024年2月16日發布的首個文本生成視頻模型,能夠根據用戶的文本提示快速制作長達一分鐘的高保真視頻。該模型具有以下特點:
?
- 超長時長:可以直接輸出長達60秒的1080P高清視頻,而其他競品僅能實現20秒左右。
- 多視角切換:人物場景在三維空間的移動更為自然,并且能夠理解車窗倒影等物理規律,進行交互。
- 多模態輸入處理:可以接受文字、圖片、視頻的輸入提示,能夠根據圖像創建視頻或補充現有視頻,還能沿時間線向前或向后擴展視頻。
?
Sora主要按AI視頻生成領域應用場景分類,可應用于內容創作與廣告、影視制作與后期、教育與培訓、社交媒體與娛樂、新聞與媒體、虛擬角色與動畫等領域。
與其他視頻生成模型相比,Sora具有以下優勢:
?
- 生成視頻的時間更長:Sora生成的視頻時間最多可達1分鐘,而其他文生視頻大模型僅能生成3至4秒的視頻。
- 視頻質量更高:Sora生成的視頻在時間維度上更加清晰穩定,景物也更符合描述。
- 對用戶輸入語言的理解更精準:Sora能夠準確理解用戶輸入的語言,并表達出復雜的情感樣態。
- 對物理世界模擬的能力更強:Sora能夠模擬真實物理世界的運動,如物體的移動和相互作用,這被普遍認為是實現通用人工智能(AGI)的重要一步。
三.Sora無敵的背后究竟有怎樣先進的處理技術
Sora的工作原理是通過大量的學習視頻來理解現實世界的動態變化,并用計算機視覺技術來模擬這些變化,從而創作出全新的視覺內容。它已經不僅局限于學習圖片和視頻,同時它也在學習視頻里那個世界的“物理規律”。
1.Spacetime Latent Patches 潛變量時空碎片,建構視覺語言系統
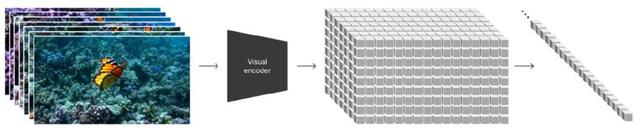
與ChatGPT首先引入Token Embedding思路一致,針對視覺數據的建模方法作為構建Sora最重要的第一步。碎片Patch已經被證明是一個有效的視覺數據表征模型,且高度可擴展表征不同類型的視頻和圖像。將視頻壓縮到一個低維的潛變量空間,然后將其拆解為時空碎片Spacetime Latent Patches。
有了時空碎片這一統一的語言,Sora自然解鎖了多種技能:
1. 自然語言理解,
采用DALLE3 生成視頻文本描述,用GPT豐富文本prompts,作為合成數據訓練Sora,架起了GPT與Sora語言空間的更精確關聯,等于在Token與Patch之間統一了“文字”;
2. 圖像視頻作為prompts,
用戶提供的圖像或視頻可以自然地編碼為時空碎片Patch,用于各種圖像和視頻編輯任務——靜態圖動畫、擴展生成視頻、視頻連接或編輯等。
2.擴散模型與Diffusion Transformer,組合成強大的信息提取器
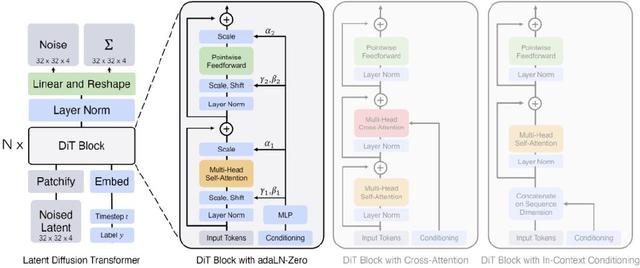
OpenAI講Sora是一個Diffusion Transformer,這來自伯克利學者的工作Diffusion Transformer?(摘取大佬原文https://blog.csdn.net/qq_44681809/article/details/135531494):“采用Transformer的可擴展擴散模型 Scalable diffusion models with transformers”[2],整體架構如下:
Diffusion Transformer (DiT)架構。
左:我們訓練調節的潛DiT模型。輸入潛變量被分解成幾個patch并由幾個DiT塊處理。
右:DiT塊的細節。我們對標準Transformer的變體進行了實驗,這些變體通過自適應層歸一化、交叉注意力和額外的輸入token做調節。自適應層歸一化效果最好。
擴散模型的工作原理是通過連續添加高斯噪聲來破壞訓練數據,然后通過逆轉這個加噪過程來學習恢復數據。訓練后可以使用擴散模型來生成數據,只需通過學習到的去噪過程來傳遞隨機采樣的噪聲。擴散模型是一種潛變量模型,逐漸向數據添加噪聲,以獲得近似的后驗
圖像漸進地轉化為純高斯噪聲。訓練擴散模型的目標是學習逆過程,即訓練pθ(xt-1|xt)。通過沿著這個過程鏈向后遍歷,可以生成新的數據。
從信息熵的角度可以這樣理解:結構化信息信息熵低,多輪加高斯噪音,提高其信息熵,逐步掩蓋原來的結構信息。本就無序的非結構化部分,信息熵很高,添加少量高斯噪音,甚至不用添加高斯噪音,已然很無序。
在此視角下,學習到的內容其實是原來結構化信息(如圖像)的“底片”。類似化學上的酸堿中和,本來很酸的地方,得放更多的堿,現在我們學到了放堿的分布和節奏,反過來,剔除堿的分布,酸的分布就被還原了。
基礎的擴散模型,過程中不降維、無壓縮,還原度比較高。學習過程中的概率分布作為潛變量參數化,訓練獲取其近似分布,用KL散度計算概率分布之間的距離[3]。Diffusion Transformer (DiT) 因為引入Transformer做多層多頭注意力和歸一化,因而引入了降維和壓縮,diffusion方式下的底片信息提取過程,原理與LLM的重整化無異。
3.DiT應用于潛變量時空碎片,學習獲得海量視頻中時空碎片的動態關聯
與“LLM在其高維語言空間中通過Transformer提取人類語言中無數的結構與關聯信息”類似,Sora是個基于擴散模型的Transformer,被用于從高維的時空碎片長成的空間中,觀察并提取豐富的時空碎片之間的關聯與演化的動態過程。如果把前者對應人類讀書,后者就是人類的視覺觀察。
參照Google Lumiere的技術原理來大膽推演一下。視頻其實是記錄了時空信息的載體:時空碎片patch可以看作是三維空間的點集(x,y,z)的運動(t),或者說其實是個四維時空模型(x,y,z,t)。Sora和Lumiere之類的生成模型的第一步都是如何從中提取出相應的關鍵信息。
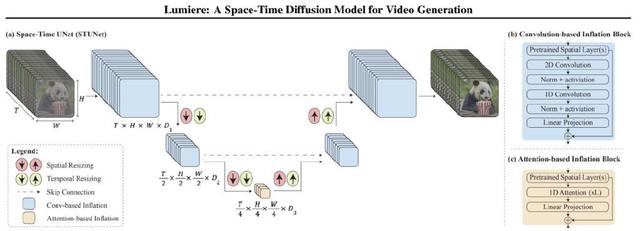
Lumiere(Google推出的AI視頻大模型) STUNet架構。將預訓練的T2I U-Net架構(Ho et al., 2022a)“膨脹”到一個時空UNet (STUNet),在空間和時間上對視頻進行上下采樣。
(a)STUNet激活圖的示例;顏色表示不同時序模塊產生的特征:
(b)基于卷積的塊,由預訓練的T2I層和因子化時空卷積組成
(c)在最粗的U-Net級別上基于注意力的塊,其中預訓練的T2I層和時間注意力。由于視頻表征在最粗的級別上被壓縮,我們使用有限的計算開銷堆疊幾個時間注意力層。
谷歌Lumiere: A Space-Time Diffusion Model for Video Generation[4]也選擇了擴散模型,堆疊了歸一化與注意力層,類似Sora的DiT,但細節如時長、分辨率、長寬比等的處理方式不同。細節決定成敗,OpenAI稱Sora摒棄了“其他文生視頻調整視頻大小、裁剪或修剪到標準大小的通常做法”,以可變時長、原始分辨率與長寬比訓練視頻生成獲得重要優勢,如采樣靈活性,改進的創作與成幀
4.Sora 或Lumiere 視頻學習與生成的技術背后蘊含的原理分析
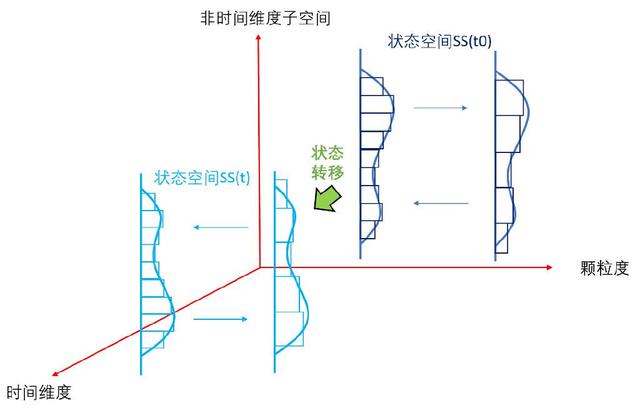
1.?狀態空間對事物的表征和刻畫:狀態空間的高維度,某時刻的信息,即某時刻的事物的能量的概率分布,是眾多維度的聯合概率分布,各維度都可能具有連續性和非線性,如何用線性系統近似,并最大努力消除非線性的影響非常關鍵;不同層次的潛變量空間,對信息的提取,和粗顆粒度逐層抽象,都需要類似重整化群RG中的反復歸一化,以消除“近似非線性處理”對整體概率為 1 的偏離。關于重整化群信息提取的原理,請參考筆者梳理的“大模型認知框架”,此處不再贅述。這里Sora采用的Diffusion Transformer (DiT) 架構與谷歌Lumiere 采用的Space-Time UNet (STUNet) 都具備注意力與歸一化,神經網路架構差異看起來主要來自是否采用“調整視頻大小、裁剪或修剪到標準大小的通常做法”。
2.?狀態空間的動態性:即從時間的維度,研究整個狀態空間的變遷。這個變遷是狀態空間的大量非時間維度的信息逐層提取,疊加時間這一特殊維度的(狀態-時間)序列sequence。不管是高維度低層次的細顆粒度的概率分布的時間變化,還是低維度高層次的粗顆粒度概率分布的時間變化,都是非線性時變系統,用線性時不變(LTI)的模型都是無法很好刻畫的。
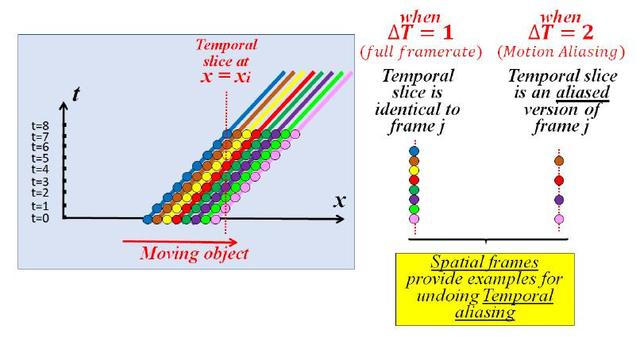
Sora的具體做法技術綜述中沒有透露。Lumiere的處理中可以窺見端倪。這里可以有多種建模的方式,最自然的方式就是 ((x,y,z), t )的方式,將事物整體的演化看成時間序列,但此種方式往往存在數字視頻采樣頻率不足導致的運動模糊與運動混淆問題。比如高速運轉的輪子有時候看起來像在倒轉。
Nyquist-Shannon采樣定理
告訴我們,對于模擬信號,如果希望同時看到信號的各種特性,采樣頻率應該大于原始模擬信號的最大頻率的兩倍,否則將發生混疊即相位或頻率模糊。因而Lumiere采用了自監督時間超分辨率 (TSR) 與空間超分辨率 (SSR) 技術[5],將事物的運動建模成多維度兩兩組合的模型:(x,y), … ,(x,t),(y,t),(z,t)。
小的時空碎片會在視頻序列的各個維度上重復出現,特別是空間和時間維度之間進行交換時,因而可以對其在時間域與空間域的表征做關聯分析,慢逆時針有可能是快順時針的假象,也可能就是慢逆時針。即使時域無法分辨,空域可以調整頻率,看到更模糊或者沒有特別變化的表征。當物體快速移動時,x-t和y-t切片中的Patch看起來是高分辨率x-y切片 (傳統幀) 的低分辨率版本。在t方向上增加這些x-t和y-t切片的分辨率與增加視頻的時間分辨率是一樣的。因此,空間x-y視頻幀提供了如何在同一視頻中增加x-t和y-t切片的時間分辨率的示例。
即將t看成第四維度,可以用x-y高分辨率訓練修正x-t, y-t。同理,當物體移動非常緩慢時,x-t和y-t切片中的Patch呈現為x-y幀中Patch的拉伸版本,表明這些時間切片可以為如何提高視頻幀的空間分辨率提供示例。即時間切片,反過來提升空間分辨率。如果SSM學到了物理規律(如運動方程),直接輸出高頻幀理論上也應當可行。
“跨維”遞歸的一維圖示。1D對象向右移動。當適當的采樣時間 (T=1),時間切片類似于空間切片 (1D“幀”)。然而,當時間采樣率過低 (T=2) 時,時間切片是空間切片的欠采樣(混疊 aliasing)版本。因此,空間幀提供了消除時間混疊的示例。
3.?狀態空間時間序列的非馬爾可夫性:思考attention 的價值,時序數據上的attention注意到了什么?諸如趨勢、周期性、 一次性事件等。非時間維度子空間內的attention,注意到的是范疇內與范疇間的關系, 即某個時刻的狀態空間。狀態空間的時序,研究的是狀態空間的動力學,外在驅動“力”或因素導致的狀態的“流動”,即狀態空間t時刻與 t-n時刻之間的關系,注意到的是其時間依賴規律,往往不具備馬爾可夫性。(馬爾可夫性描述了一個系統在其當前狀態下,其未來的狀態只與其當前狀態相關,而與之前的任何狀態無關。)非馬爾可夫性其實是世界的常態,事實上時延系統基本都是非馬爾可夫的。時間維度的注意力與狀態空間選擇性非常關鍵。OpenAI對Sora視頻生成模型的技術綜述文章取了“視頻生成模型作為世界模擬器video generation models as world simulators”的題目,可見其宏大的愿景。既然模擬世界,就繞不開萬事萬物的長程時間關聯或者因果關系


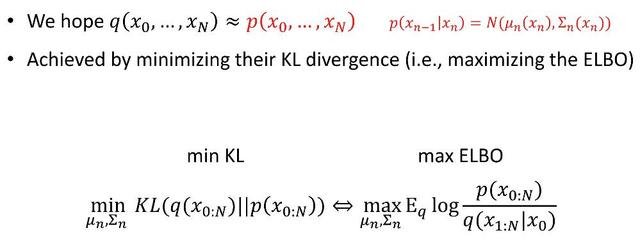
四.OpenAI官方給予Sora的說明
1.優勢及缺陷
Sora能夠生成具有多個字符、特定運動類型以及主題和背景的準確細節的復雜場景。該模型不僅能理解用戶在提示符中的要求,還能理解這些東西在物理世界中是如何存在的。
該模型對語言有深刻的理解,使其能夠準確地解釋提示,并生成引人注目的字符,表達充滿活力的情感。Sora還可以在一個生成的視頻中創建多個鏡頭,這些鏡頭能夠準確地持久化字符和視覺樣式。
目前的模式存在弱點。它可能難以準確地模擬復雜場景的物理,也可能不理解因果的具體實例。例如,一個人可能會咬一口餅干,但之后,餅干可能沒有咬痕。該模型還可能混淆提示的空間細節,例如,左右混淆,并且可能難以精確描述隨時間發生的事件,比如遵循特定的攝像機軌跡。
2.安全問題的考慮及解決方案
在OpenAI的產品中提供Sora之前,我們將采取幾個重要的安全措施。我們正在與red teamers合作--錯誤信息、仇恨內容和偏見等領域的領域專家--他們將對模型進行對抗性測試。我們還在構建一些工具來幫助檢測誤導性內容,例如一個檢測分類器,它可以判斷Sora何時生成視頻。我們計劃包括C2PA元數據未來如果我們將該模型部署在OpenAI產品中。
除了開發新技術為部署做準備之外,我們還利用現有安全方法我們為我們的產品打造的使用DALL·E 3的產品,該產品同樣適用于Sora。
例如,一旦進入OpenAI產品,我們的文本分類器將檢查并拒絕違反我們使用政策的文本輸入提示,比如那些請求極端暴力、性內容、仇恨圖像、名人肖像或他人IP的提示。我們還開發了健壯的圖像分類器,用于檢查生成的每個視頻的幀,以幫助確保它在顯示給用戶之前符合我們的使用策略。
我們將與世界各地的決策者、教育工作者和藝術家接觸,以了解他們的關切,并確定這項新技術的積極用例。盡管進行了廣泛的研究和測試,但我們無法預測人們使用我們技術的所有有益方式,也無法預測人們濫用技術的所有方式。這就是為什么我們相信,隨著時間的推移,從真實世界的使用中學習是創建和發布越來越安全的人工智能系統的關鍵組成部分。
3.研究技術
Sora是一種擴散模型,它通過從一個看起來類似靜態噪聲的視頻開始生成視頻,然后通過多次去除噪聲逐漸將其轉換。Sora能夠同時生成整個視頻,或者能夠擴展已生成的視頻使其更長。通過一次提供許多幀的模型前瞻,我們解決了一個具有挑戰性的問題,即確保一個主題即使暫時消失也保持不變。
與GPT模型類似,Sora使用transformer架構,解鎖了卓越的擴展性能。
我們將視頻和圖像表示為更小的數據單元,稱為補丁,每個補丁都類似于GPT中的令牌。通過統一我們表示數據的方式,我們可以在比以前更廣泛的可視化數據上訓練擴散轉換器,跨越不同的持續時間、分辨率和縱橫比。
Sora建立在過去對DALL·E和GPT模型的研究之上。它使用了DALL·E 3中的重新捕獲技術,該技術包括為可視化訓練數據生成高度描述性的標題。因此,該模型能夠更忠實地跟隨用戶在生成的視頻中的文字說明。
除了能夠僅僅從文字說明生成視頻之外,該模型還能夠獲取現有的靜止圖像并從中生成視頻,準確地動畫圖像的內容,并注意到小細節。該模型還可以獲取現有視頻并對其進行擴展或填充缺失的幀。技術報道.
五.穿梭于虛實之間的sora是否會打破虛擬與現實的平衡
對于這個問題我并沒有答案,只是有一些擔憂,在現實世界中由于AI繪圖的發展,將靜態圖片作為某個事件證據的證明性大大降低,如果AI生成視頻再超速發展,那未來我們還能看到多少真實的過去?又有多少是來源于虛擬,到底那些才是深埋于地底的現實,我們無從知曉.
視頻好似已成為了鏈接虛擬與現實的最后一條鎖鏈,當我們斬斷它后,那些記錄著現實的虛擬和那些自詡封存于虛擬的現實到底哪些才是我們真正經歷過的,哪些是AI所代替的
我希望人類的未來不會取決于AI的未來
我看不清AI的未來,也捉摸不透人類的未來
PS:本文對于Sora的技術原理剖析摘自其他大佬,有興趣者可以從瀏覽器搜索

類型)















)

