? ? ? ? ?這里的網絡結構及原理可以看這篇博客,DeepLabV3+: 在DeepLabV3基礎上引入了Decoder_matlab deeplabv3+resnet101-CSDN博客該博客翻譯原論文解釋得很清楚。
一、引言
? ? ? ?語義分割的目標是為圖像中的每個像素分配語義標簽。在這項研究中,考慮了兩種類型的神經網絡:使用了空間金字塔池化的模塊、編解碼器結構;前者可以通過在不同分辨率下匯集特性來獲取豐富的上下文信息,后者能夠獲得清晰的物體邊界。
? ? ? ?為了在不同尺度下獲得上下文信息,DeepLabv3使用了幾個并行的不同速率的空洞卷積(空洞空間金字塔池化,ASPP);而PSPNet則是在不同網格尺度上執行池化操作。盡管在最后一個feature map上編碼了豐富的語義信息,但由于在網絡backbone中使用了帶有步長的池化或者卷積操作,與物體邊界相關的細節信息卻丟失了。這個問題,可以通過使用空洞卷積提取密集的feature maps來改善。
? ? ? ? ?DeepLabv3+,通過增加一個簡單有效的解碼器模塊擴展了DeepLabv3,以恢復物體邊界。在DeepLabv3的輸出中,已經編碼了豐富的語義信息,其使用空洞卷積來控制編碼特征的密度,這取決于計算資源。此外,解碼器模塊可以恢復詳細的物體邊界。本質上deeplabv3+就是deeplabv3加上一個decoder.
? ? ? ? 總體來講,貢獻如下:
- 在DeepLabv3基礎上,加了一個解碼器;
- 可以通過控制空洞卷積速率來任意改變編碼器輸出的feature map分辨率;
- 使用Xception作為backbone(也可使用ResNet101等),并在ASPP和解碼器模塊中使用了深度可分離卷積,從而產生了一個更快、更強的編解碼網絡;
- 該模型達到了新的SOTA;
- 開源了代碼;
二、網絡結構
? ? ? ?DeepLabV3+的網絡結構如下圖所示,主要為Encoder-Decoder結構。
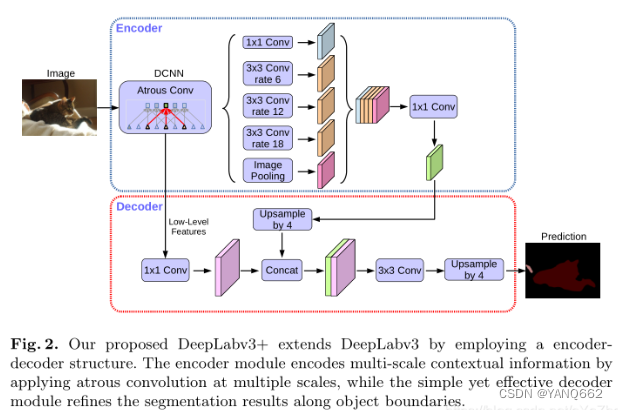
? ? ? ? Encoder-decoder: 編解碼結構已經被用于多種計算機視覺任務,如人體姿態估計、目標檢測、語義分割。通常,編碼器-解碼器網絡包含(1)一個編碼器模塊(Encoder),逐步減少特征映射并捕獲更高的語義信息,(2)一個解碼器模塊(Decoder),逐步恢復空間信息。在此基礎上,我們提出了使用DeepLabv3作為編碼器模塊,并添加一個簡單而有效的解碼器模塊,以獲得更清晰的分割。
1.Encoder
? ? ? ?在encoder部分,主要包括了backbone(DCNN)、ASPP兩大部分。encoder中連接的第一個模塊是DCNN, 他代表的是用于提取圖片特征的主干網絡,DCNN右邊是一個ASPP網絡,他用一個1*1的卷積、3個3*3的 空洞卷積和一個全局池化來對主干網絡的輸出進行處理。然后再將其結果都連接起來并用一個1*1的卷積 來縮減通道數。具體如下:
- 其中backbone有兩種網絡結構:將layer4改為空洞卷積的Resnet系列、改進的Xception。從backbone出來的feature map分兩部分:一部分是最后一層卷積輸出的feature maps,另一部分是中間的低級特征的feature maps;backbone輸出的第一部分送入ASPP模塊,第二部分則送入Decoder模塊。
- ASPP模塊接受backbone的第一部分輸出作為輸入,使用了四種不同膨脹率的空洞卷積塊(包括卷積、BN、激活層)和一個全局平均池化塊(包括池化、卷積、BN、激活層)得到一共五組feature maps,將其concat起來之后,經過一個1*1卷積塊(包括卷積、BN、激活、dropout層),最后送入Decoder模塊。
? ? ? ?可分離空洞卷積的優點:
- 減小計算量,是普通卷積計算量的1/9;
- 擴大感受野:神經網絡加深,單個像素感受野擴大,但特征圖尺寸縮小,空間分辨率降低,為此,空洞卷積出現了,一方面感受野大了可以檢測分割大目標,另一方面分辨率高了可以精確定位目標。
- 捕獲多尺度上下文信息:兩列之間填充 (r-1) 個0,這個 r 可自己設置,不同 r 可得到不同尺度信息。
2.Decoder
? ? ? 在Decoder部分,接收來自backbone中間層的低級feature maps和來自ASPP模塊的輸出作為輸入。
- 首先,對低級feature maps使用1*1卷積進行通道降維,從256降到48(之所以需要降采樣到48,是因為太多的通道會掩蓋ASPP輸出的feature maps的重要性,且實驗驗證48最佳);
- 然后,對來自ASPP的feature maps進行插值上采樣,得到與低級featuremaps尺寸相同的feature maps;
- 接著,將通道降維的低級feature maps和線性插值上采樣得到的feature maps使用concat拼接起來,并送入一組3*3卷積塊進行處理;
- 最后,再次進行線性插值上采樣,得到與原圖分辨率大小一樣的預測圖。
3.Xception
Xception網絡結構如下:
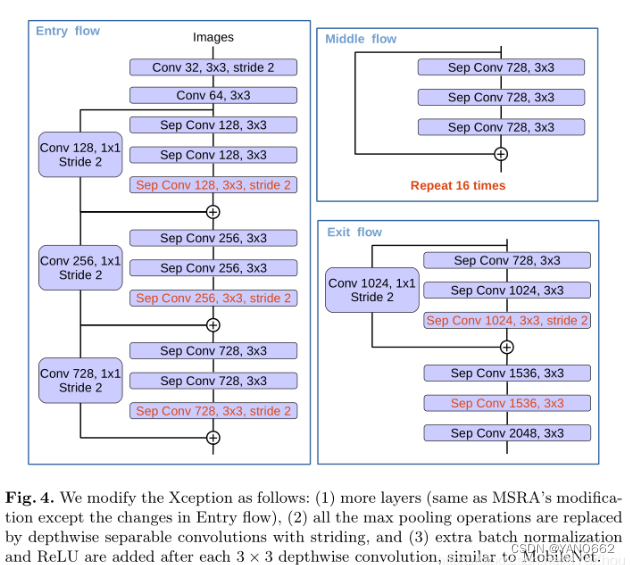
? ? ? ? Xception網絡是由inception結構加上depthwise separable convlution,再加上殘差網絡結構改進而來。Xception結構由36層卷積層組成網絡的特征提取基礎,分為Entry flow,Middle flow,Exit flow;被分成了14個模塊,除了第一個和最后一個外,其余模塊間均有線性殘差連接。
? ? ? ? Xception結構演變:(輕量化網絡結構——Xception_xception網絡結構-CSDN博客)
? ? ? ? Xception 并不是真正意義上的輕量化模型,是Google繼Inception后提出的對Inception v3的另一種改進,主要是采用depthwise separable convolution來替代原來的Inception v3中的卷積操作,這種性能的提升是來自于更有效的使用模型參數而不是提高容量。
? ? ? ? 既然是在Inception v3上進行改進的,那么Xception是如何一步一步的從Inception v3演變而來。Inception v3結構如下圖1(這個網絡結構是最基礎的google提出的inceptuon網絡結構的改進,大家可以查找資料進一步了解)
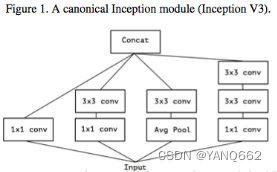
注:1x1卷積的作用:?1)降維:較少計算量 2)升維:小型網絡,通道越多,效果會更好 3)1x1是有一個參數學習的卷積層,可以增加跨通道的相關性。
下圖簡化了上圖的inception module(就只考慮1x1的那條支路,不包含Avg pool)如下:

? ? ? ?下圖把上圖的第一部分的3個1x1卷積核統一起來,變成1個1x1的卷積核,然后連接3個3x3的卷積,這3個卷積操作只將前面1x1卷積結果中的一部分作為自己的輸入(只負責一部分通道)。

? ? ? ?下圖An“extreme” version of Inception module,先用1x1卷積核對各通道之間(cross-channel)進行卷積,之后使用3x3的卷積對每個輸出通道進行卷積操作,也就是3x3卷積的個數和1x1卷積的輸出channel個數相同。
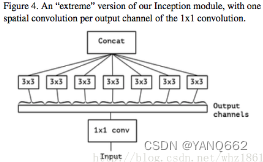
? ? ? ? 在Xception中主要采用depthwise separable convolution,和原版的相比有兩個不同之處:
(1)原版的Depthwise convolution,先是逐通道卷積,再1x1卷積;而Xception是反過來,先1x1卷積,再逐通道卷積。
(2)原版Depthwise convolution的兩個卷積之間是不帶激活函數的,而Xception再經過1x1卷積之后會帶上一個Relu的非線性激活函數。
三、結論
? ? ? ? 我們提出的模型“DeepLabv3+”采用了編碼器-解碼器結構,其中使用DeepLabv3對豐富的上下文信息進行編碼,采用簡單有效的解碼器模塊恢復對象邊界。也可以根據可用的計算資源,應用空洞卷積以任意分辨率提取編碼器特征。還對Xception模型和空洞可分離卷積進行了研究,使所提出的模型更快、更強。最后,我們的實驗結果表明,所提出的模型在PASCAL VOC 2012和Cityscapes數據集達到SOTA。
? ? ? ? 一句話總結DeepLabV3+:
? ? ? ??DeepLabv3作為Encoder提取特征,上采樣后與backbone中間的低級特征以concat的方式融合,然后利用3*3卷積獲得細化的特征,最后再進行上采樣恢復到原始分辨率;在backbone部分,使用可分離卷積改進了Xception。
? ? ? ?本質上,DeepLabV3+就是DeepLabV3加上一個decoder。
)






如何在面試中介紹自己的項目經驗)
)
:映射一個Raster對象)
)



))


)
 SOC市場分類)
)