前言
? ? ? ? 今天是2024-2-21,農歷正月十二,相信今天開始是新的階段,盡管它不是新的周一、某月一日、某年第一天,盡管我是一個很講究儀式感的人。新年剛過去 12 天,再過 3 天就開學咯,開學之后我的大學時光就進入了沖刺階段,之前沒完成的目標和習慣務必嚴格要求自己執行,我也慢慢悟出了解決各種 "病癥" 的辦法了~
? ? ? ? 這里推薦我喜歡的幾本書:《黃金時代》、《一直特立獨行的豬》、《沉默的大多數》,都是王小波的,對我收益頗深。盡管這博客是寫給我自己看的 hahaha
? ? ? ? 言歸正傳,今天學習 DataX,這也是一個大數據工具,和 Maxwell 差不多,它是用來做全量數據同步的,前者主要是做增量數據同步的。
1、概述
1.1、什么是 DataX
????????DataX 是阿里巴巴開源的一個異構數據源離線同步工具(區別于 Maxwell、Cannal,這倆是主要是做增量同步的),致力于實現包括關系型數據庫(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP 等各種異構數據源之間穩定高效的數據同步功能。
源碼地址:https://github.com/alibaba/DataX
1.2、DataX 的設計
????????為了解決異構數據源同步問題,DataX 將復雜的網狀的同步鏈路變成了星型數據鏈路, DataX 作為中間傳輸載體負責連接各種數據源。當需要接入一個新的數據源的時候,只需要將此數據源對接到 DataX,便能跟已有的數據源做到無縫數據同步。
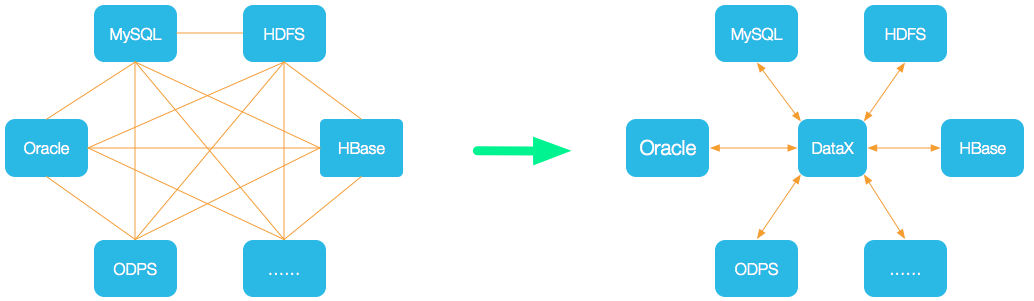
1.3、支持的數據源
| 類型 | 數據源 | Reader(讀) | Writer(寫) |
| RDBMS 關系型數據庫 | MySQL | √ | √ |
| Oracle | √ | √ | |
| OceanBase | √ | √ | |
| SQLServer | √ | √ | |
| PostgreSQL | √ | √ | |
| DRDS | √ | √ | |
| 通用RDBMS | √ | √ | |
| 阿里云數倉數據存儲 | ODPS | √ | √ |
| ADS | √ | ||
| OSS | √ | √ | |
| OCS | √ | √ | |
| NoSQL數據存儲 | OTS | √ | √ |
| Hbase0.94 | √ | √ | |
| Hbase1.1 | √ | √ | |
| Phoenix4.x | √ | √ | |
| Phoenix5.x | √ | √ | |
| MongoDB | √ | √ | |
| Hive | √ | √ | |
| Cassandra | √ | √ | |
| 無結構化數據存儲 | TxtFile | √ | √ |
| FTP | √ | √ | |
| HDFS | √ | √ | |
| Elasticsearch | √ | ||
| 時間序列數據庫 | OpenTSDB | √ | |
| TSDB | √ | √ |
1.4、框架設計

- Reader:數據采集模塊,負責采集數據源的數據,將數據發送給Framework。
- Writer:數據寫入模塊,負責不斷向Framework取數據,并將數據寫入到目的端。
- Framework:用于連接reader和writer,作為兩者的數據傳輸通道,并處理緩沖, 流控,并發,數據轉換等核心技術問題。
1.5、運行原理

- Job:單個作業的管理節點,負責數據清理、子任務劃分、TaskGroup監控管理。一個 Job 啟動一個進程。
- Task:根據不同數據源的切分策略,一個?Job 會被切分為多個 Task(由 Split 模塊完成),Task 是 DataX 作業的最小單元,每個 Task 負責一部分數據的同步工作。
- TaskGroup:Scheduler 調度模塊會對 Task 進行分組,每個 TaskGroup?負責啟動 Task,單個 TaskGroup 的并發數量為 5(最多同時執行 5 個Task,一個 Task 執行完就會釋放掉,再進來一個 Task 繼續執行)。
- Reader -> Channel -> Writer :每個 Task 啟動后,都會固定啟動?Reader -> Channel -> Writer 來完成同步工作。
舉例來說,用戶提交了一個 DataX 作業,并且配置了 20 個并發,目的是將一個 100 張分表的 mysql 數據同步到 odps 里面。 DataX 的調度決策思路是:
- DataXJob 根據分庫分表切分成了 100 個 Task。
- 根據 20 個并發,DataX 計算共需要分配 4 個 TaskGroup。
- 4 個 TaskGroup 平分切分好的 100 個 Task,每一個 TaskGroup 負責以 5 個并發共計運行 25 個 Task。
1.6、與 Sqoop 對比

2、DataX3.0 部署
傻瓜式安裝解壓,然后執行下面的腳本
python /opt/module/datax/bin/datax.py /opt/module/datax/job/job.json運行結果:?

當出現上面的結果說明安裝成功,這里我們用的是 DataX 自帶的一個測試作業,它是一個 json 格式的文件,之后我們的 DataX 作業也是通過自己 編寫 json 文件來實現。
3、DataX 的使用
3.1、DataX 任務提交命令
????????DataX的使用十分簡單,用戶只需根據自己同步數據的數據源和目的地選擇相應的Reader和Writer,并將Reader和Writer的信息配置在一個json文件中,然后執行如下命令提交數據同步任務即可,就像我們安裝時測試執行 DataX 任務的操作一樣:
python /opt/module/datax/bin/datax.py /opt/module/datax/job/job.json3.2、DataX 配置文件格式
可以通過下面這個命令來查看 DataX 配置文件模板:
# -r 代表 reader -w 代表 writer
python bin/datax.py -r mysqlreader -w hdfswriter????????配置文件模板如下,json最外層是一個job,job包含setting和content兩部分,其中setting用于對整個job進行配置,content用戶配置數據源和目的地。

Reader和Writer的具體參數可參考官方文檔,地址:
https://github.com/alibaba/DataX/blob/master/README.md
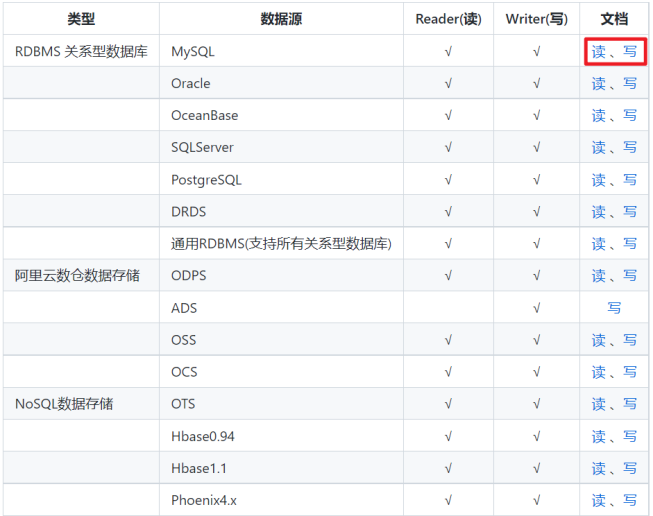
所以,如果我們需要自定義 DataX 任務的時候,就需要打開官網的 reader 和 writer 文檔,查看需要配置哪些參數,接下來我們就來練習一下:
4、使用案例
4.1、MySQL -> HDFS
從 MySQL 寫入到 HDFS ,我們就需要去官網查看?MySQLReader 和 HDFSWriter 的內容:
簡而言之,MysqlReader通過JDBC連接器連接到遠程的Mysql數據庫,并根據用戶配置的信息生成查詢SELECT SQL語句,然后發送到遠程Mysql數據庫,并將該SQL執行返回結果使用DataX自定義的數據類型拼裝為抽象的數據集,并傳遞給下游Writer處理。
對于用戶配置Table、Column、Where的信息,MysqlReader將其拼接為SQL語句發送到Mysql數據庫;對于用戶配置querySql信息,MysqlReader直接將其發送到Mysql數據庫。
案例要求:同步 gmall 數據庫中 base_province 表數據到 HDFS 的 /base_province 目錄
需求分析:要實現該功能,需選用 MySQLReader 和 HDFSWriter,MySQLReader 具有兩種模式分別是TableMode和QuerySQLMode,前者使用table,column,where等屬性聲明需要同步的數據;后者使用一條SQL查詢語句聲明需要同步的數據。
下面分別使用兩種模式進行演示:
4.1.1、MySQLReader &?TableMode
1)編寫配置文件
vim /opt/module/datax/job/base_province.json{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","name","region_id","area_code","iso_code","iso_3166_2"],"where": "id>=3","connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/gmall"],"table": ["base_province"]}],"password": "123456","splitPk": "","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}2)配置說明
1. Reader 參數說明

注意:這里的 splitPk 參數是數據分片字段,一般是主鍵,僅支持整型?,而且只有 TableMode 模式下才有效。
2. Writer 參數說明

我們的 hdfswriter 中有一個 column 參數,但是我們知道 HDFS 是沒有列的這個概念的。其實,這里代表的是我們Hive表中數據的字段類型,這個配置參數是給 Hive 看的。之后我們在使用 hdfsreader 的時候 依然要配置這個參數,這個參數的意義仍然是 hive 的數據字段。
注意:這里的 fileName 參數指的是 HDFS 前綴名而并不是完整文件名!
3)提交任務
使用DataX向HDFS同步數據時,必須確保目標路徑已存在!
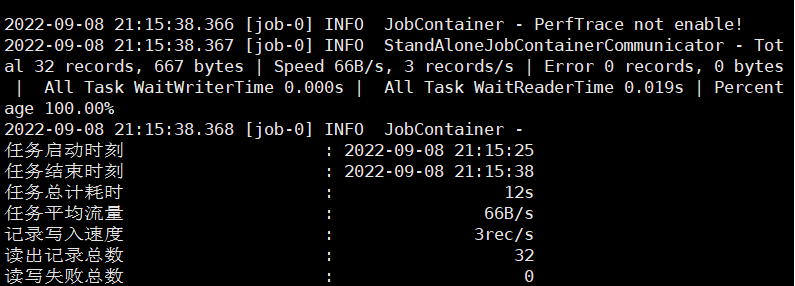
hadoop fs -mkdir /base_provincepython bin/datax.py job/base_province.json執行結果:

 ?可以看到,我們的文件名是由我們 hdfswriter 中指定的前綴 fileName + uuid 組成的。
?可以看到,我們的文件名是由我們 hdfswriter 中指定的前綴 fileName + uuid 組成的。
?查看HDFS?中的文件內容(因為我們的文件是經過 gzip 壓縮的,所以網頁端查看不了):
hadoop fs -cat /base_province/* | zcat
可以看到,MySQL 中?34 條數據一共寫入了 32 條,這是因為我們設置了 where 參數的值為 id>=3?
4.1.2、MySQLReader & QuerySQLMode
1)配置文件
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/gmall"],"querySql": ["select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3"]}],"password": "123456","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}????????可以看到,TableMode 的 mysqlreader 中是通過在 connection 參數設置 table 參數的值來指定我們的表,而這里 QuerySQLMode 模式是通過 querySql 參數來指定 SQL ,從SQL中可以得到表名。此外,QuerySQLMode 模式沒有 columns 和 where 參數,因為這些都可以在 SQL 中指定。
????????那 TableMode 和 QuerySQLMode 有什么區別呢?其實?QuerySQLMode 正因為它可以指定 SQL ,所以就更加靈活,我們可以使用復雜的 join 和聚合函數,這一點是 TableMode 所實現不了的。反過來,我們上面知道 TableMode 的配置文件中可以在 mysqlreader 中指定一個參數 splitPk 來開啟多個 Task 去讀取一張表,這一點同樣是?QuerySQLMode 所不具備的,QuerySQLMode 只支持單個 Task。
????????QuerySQLMode 這種模式用的還是比較少的,畢竟我們的 Hive 也可以完成數據的聚合和聯結。
此外,關于 hdfswriter 還有一些注意事項:
注意事項:
HFDS?Writer并未提供nullFormat參數:也就是用戶并不能自定義null值寫到HFDS文件中的存儲格式。默認情況下,HFDS?Writer會將null值存儲為空字符串(''),而Hive默認的null值存儲格式為\N。所以后期將DataX同步的文件導入Hive表就會出現問題。
解決該問題的方案有兩個:
????????一是修改DataX?HDFS?Writer的源碼,增加自定義null值存儲格式的邏輯(也就是如果讀取到 null 就把它替換為 "\\N",雙斜杠是因為 DataX 是 Java 寫的),可參考這里。
????????二是在Hive中建表時指定null值存儲格式為空字符串(''")
2)配置文件說明
mysqlreader:
 ?
?
hdfswriter 和上面的是一樣的。
3)提交任務
結果和上面是一樣的,這里不再演示。
4.1.3、DataX 傳參
????????通常情況下,離線數據同步任務需要每日定時重復執行(就像我們之前 flume 上傳到 HDFS 也指定過),故HDFS上的目標路徑通常會包含一層日期,以對每日同步的數據加以區分,也就是說每日同步數據的目標路徑不是固定不變的,因此DataX配置文件中 HDFS?Writer 的path參數的值應該是動態的。為實現這一效果,就需要使用DataX傳參的功能。
1)修改配置文件
????????DataX傳參的用法如下,在JSON配置文件中使用${param}引用參數,在提交任務時使用-p"-Dparam=value"傳入參數值,我們只需要修改 hdfswriter 下 parameter 參數下的 path 為:
"path": "/base_province/${dt}"?2)創建 hdfs 路徑
hadoop fs -mkdir /base_province/2020-06-143)提交任務
python bin/datax.py -p"-Ddt=2020-06-14" job/base_province.json4.2、HDFS -> MySQL
案例要求:同步HDFS上的/base_province目錄下的數據到 MySQL gmall?數據庫下的 test_province表。
需求分析:要實現該功能,需選用 HDFSReader 和 MySQLWriter。
1)編寫配置文件
vim test_province.json{"job": {"content": [{"reader": {"name": "hdfsreader","parameter": {"defaultFS": "hdfs://hadoop102:8020","path": "/base_province","column": ["*"],"fileType": "text","compress": "gzip","encoding": "UTF-8","nullFormat": "\\N","fieldDelimiter": "\t",}},"writer": {"name": "mysqlwriter","parameter": {"username": "root","password": "123456","connection": [{"table": ["test_province"],"jdbcUrl": "jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&characterEncoding=utf-8"}],"column": ["id","name","region_id","area_code","iso_code","iso_3166_2"],"writeMode": "replace"}}}],"setting": {"speed": {"channel": 1}}}
}2)配置說明
hdfsreader:
 ?
?
mysqlwriter:
 ?
?
????????其中 writeMode 的三種不同取值代表三種不同的 SQL 語句,其中 replace 和 on duplicate key update 都要求我們的 MySQL 表是有主鍵的。我們經常使用的?insert 語句是不需要主鍵的,所以當有主鍵重復的時候會直接報錯。而 replace 語句如果遇到表中已經存在該主鍵的數據會直接替換掉, on duplicate key update 語句的話如果遇到表中已經存在該主鍵的數據會更新不同值的字段。
3)提交任務
創建 HDFS 輸出端 MySQL 的表:
DROP TABLE IF EXISTS `test_province`;
CREATE TABLE `test_province` (`id` bigint(20) NOT NULL,`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`region_id` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`area_code` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`iso_code` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`iso_3166_2` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;提交任務:
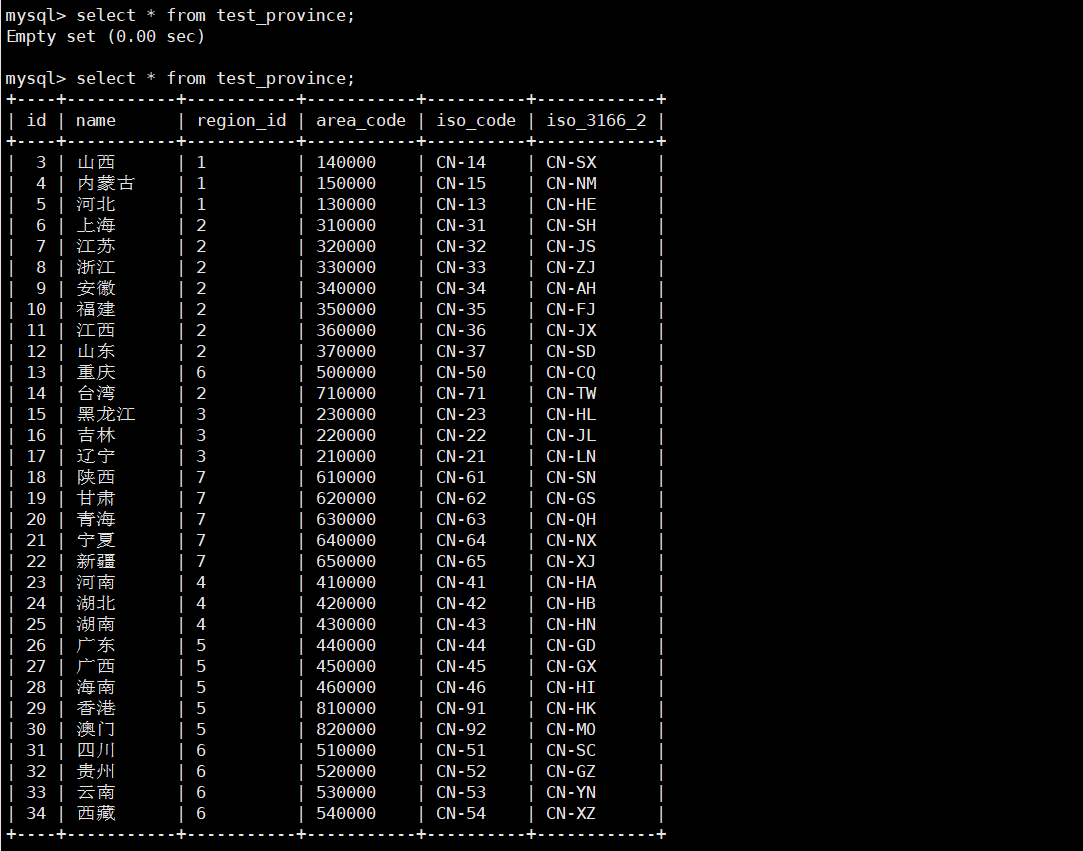
bin/datax.py job/test_province.json4)查看結果
 ?
?
 ?
?
5、DataX 優化
? ? ? ? 上面 DataX 的任務配置文件中,job 下有兩個參數 content 和 setting,content 是配置 reader 和 writer 的,而 setting 其實就是來給?DataX 優化用的(通過控制流量、并發)。
5.1、速度控制
????????DataX3.0提供了包括通道(并發)、記錄流、字節流三種流控模式,可以隨意控制你的作業速度,讓你的作業在數據庫可以承受的范圍內達到最佳的同步速度。
關鍵優化參數如下:
| 參數 | 說明 |
| job.setting.speed.channel | 并發數 |
| job.setting.speed.record | 總 record 限速(tps:條數/s) |
| job.setting.speed.byte | 總 byte 限速(bps:字節數/s) |
| core.transport.channel.speed.record | 單個 channel 的record限速,默認值為10000(10000條/s) |
| core.transport.channel.speed.byte | 單個channel的byte限速,默認值1024*1024(1M/s) |
注意事項:
1. 若配置了總 record 限速,則必須配置單個 channel 的 record 限速
2. 若配置了總 byte 限速,則必須配置單個 channe 的 byte 限速
3. 若配置了總 record 限速和總 byte 限速,channel 并發數參數就會失效。因為配置了總record限速和總 byte 限速之后,實際 channel 并發數是通過計算得到的:
計算公式為:
min(總byte限速/單個channel的byte限速,總record限速/單個 channel 的record限速)
配置示例:
{"core": {"transport": {"channel": {"speed": {"byte": 1048576 //單個channel byte限速1M/s}}}},"job": {"setting": {"speed": {"byte" : 5242880 //總byte限速5M/s}},...}
}5.2、內存調整
????????當提升DataX Job內Channel并發數時,內存的占用會顯著增加,因為DataX作為數據交換通道,在內存中會緩存較多的數據。例如Channel中會有一個Buffer,作為臨時的數據交換的緩沖區,而在部分Reader和Writer的中,也會存在一些Buffer,為了防止OOM等錯誤,需調大JVM的堆內存。
????????建議將內存設置為4G或者8G,這個也可以根據實際情況來調整。
????????調整JVM xms xmx參數的兩種方式:一種是直接更改datax.py腳本;另一種是在啟動的時候,加上對應的參數,如下:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" /path/to/your/job.json總結
? ? ? ? DataX 這個工具的學習就結束了,比我想象的要簡單多,但是也需要好好熟悉練習一下。目前只學習了 DataX 在 HDFS 和 MySQL 之間的相互數據傳遞,以后用到其它框架的時候還需要精進一下。


 用ChatGPT實現音頻長度測量和音量調整)


)
)



![[linux]進程間通信(IPC)———共享內存(shm)(什么是共享內存,共享內存的原理圖,共享內存的接口,使用演示)](http://pic.xiahunao.cn/[linux]進程間通信(IPC)———共享內存(shm)(什么是共享內存,共享內存的原理圖,共享內存的接口,使用演示))
)







