一、基礎
1、編碼
UTF-8:中文占3個字節
GBK:中文占2個字節
Unicode、UTF-8、GBK三者關系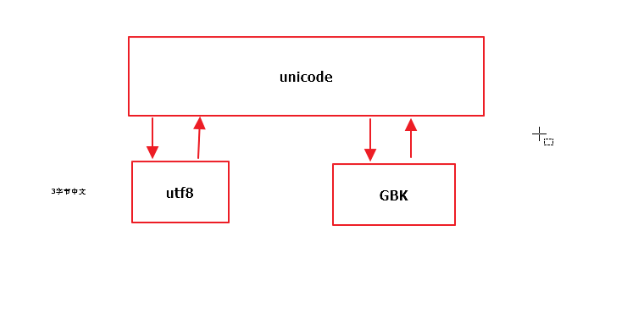
ascii碼是只能表示英文字符,用8個字節表示英文,unicode是統一碼,世界通用碼,規定采用2個字節對世界各地不同文字進行編碼,gbk是針對中國漢字提出的編碼標準,用2個字節對漢字進行表示。utf8是對unicode的升級改進版,但是unicode到utf-8并不是直接的對應。
UTF-8最大的一個特點,就是它是一種變長的編碼方式。它可以使用1~4個字節表示一個符號,根據不同的符號而變化字節長度,當字符在ASCII碼的范圍時,就用一個字節表示,保留了ASCII字符一個字節的編碼做為它的一部分,注意的是unicode一個中文字符占2個字節,而UTF-8一個中文字符占3個字節。
ascii和unicode可以相互轉換,gbk和unicode可以相互轉換。
2、input()函數
n = input(" ")
>>>hello
>>>n
>>>'hello'
n = input(" ")
>>>10
>>>n
>>>'10'
輸入數字10,這里的n是字符串'10',而非數字10
這里如果
n * 10將輸出
'10101010101010101010'
如果將字符串轉換數字,可以用Int( )
new_n = int(n)
3、while循環、continue、break
while 條件語句1:功能代碼1
else 條件語句2:功能代碼2
while循環也可以加else
例子:使用while循環輸入 1 2 3 4 5 6 8 9 10
n = 1
while n < 11:if n == 7 :passelse:print(n)n = n + 1
或者
count = 1
while count < 11if count == 7:count = count + 1continueprint(count)count = count + 1
當while執行到if count ==7時,遇到continue,下面的print語句和count=count + 1不會被執行,重新跳回while語句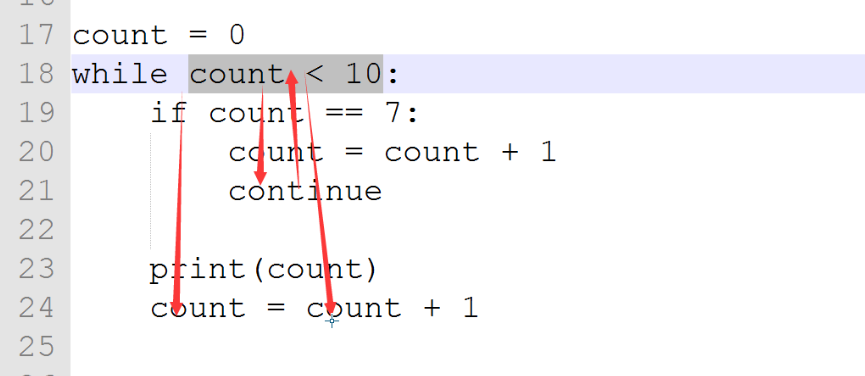
?
再比如
?
count = 1
while count < 11:count = count + 1continueprint('123')
print('end')
這里的print('123')永遠不能被執行到
第二個例子
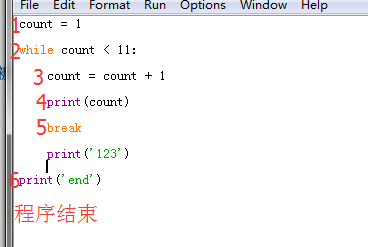
count = 1
while count < 11:count = count + 1print(count)breakprint('123')
print('end')
輸出結果
2
end
這里的print('123')也不能被執行到,遇到break語句直接跳出循環,只能執行一次循環,即輸出一次print(count)語句
此程序完整執行過程如下圖
?
總結:continue終止當前循環進行下次循環,break終止整個循環
4、算術運算符
+? ? ? ?-? ? ?*? ? ?/? ? ? %? ? ? ? **? ? ? ? ?//
加? ?減? ?乘? ?除? ?取余? ?乘方? ? 取整數商
5、字符串
name = "馬大帥"
if "馬" in name :print("ok")
else:print("error")
'馬大帥' 稱為字符串
'馬' 成為一個字符
'馬大'或者'大帥'稱為子字符串,也可以叫做子序列,注意這里的字符要連續的,而'馬帥'不能稱之為子字符串
6、成員運算:
判斷某個字符在某個字符串用in 或者not in
name = "馬大帥"
if "嗎" not in name :print("ok")
else:print("error")
7、布爾值
if語句和while語句都使用布爾值作為條件。
布爾值只有兩種情況:
真 True 假 False
if 條件判斷語句功能代碼某塊
這里的條件判斷語句最終會產生一個布爾值,或者是True 或者False
name = "馬大帥"
p ="嗎" not in name
print(p)
if p:print("ok")
else:print("error")
輸出結果
True
ok
布爾操作符:and or not
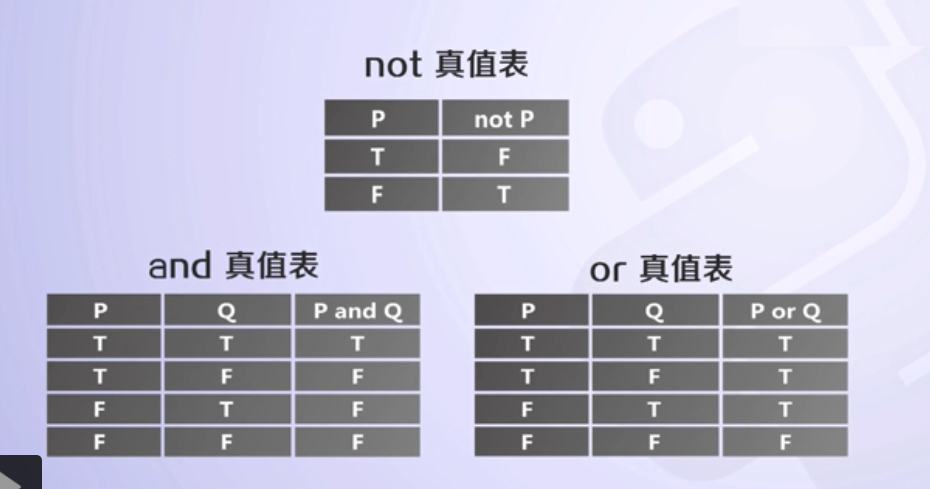
在 Python 看來,只有以下內容會被看作假(注意冒號括號里邊啥都沒有,連空格都不要有!):False None 0 "" '' () [] {}
其他一切都被解釋為真!
?

?
舉個例子
i = 10
while i:print ("我愛學習!")
print("end")
輸出結果
我愛學習!
我愛學習!
我愛學習!
我愛學習!
我愛學習!
我愛學習!
我愛學習!
我愛學習!
我愛學習!
...(這里代表一直輸出"我愛學習")
這個程序會一直輸出"我愛學習",除非按下CTRL+C停止執行程序
而print("end")語句永遠不會被執行到。
再比如
i = 10
while i:print ("我愛學習!",i)i = i -1
print("end")
輸出結果
我愛學習! 10
我愛學習! 9
我愛學習! 8
我愛學習! 7
我愛學習! 6
我愛學習! 5
我愛學習! 4
我愛學習! 3
我愛學習! 2
我愛學習! 1
end
通過觀察"我愛學習"后的數字變化,我們可以看到,這個循環的執行過程,當i循環到0時 ,即while 0 :,0為False,終止循環。開始執行
print("end")語句。
8、比較運算符:判斷大小符號
== 等于
> 大于
< 小于
>= 大于等于
<= 小于等于
!= 不等于
?
9、運算的優先級
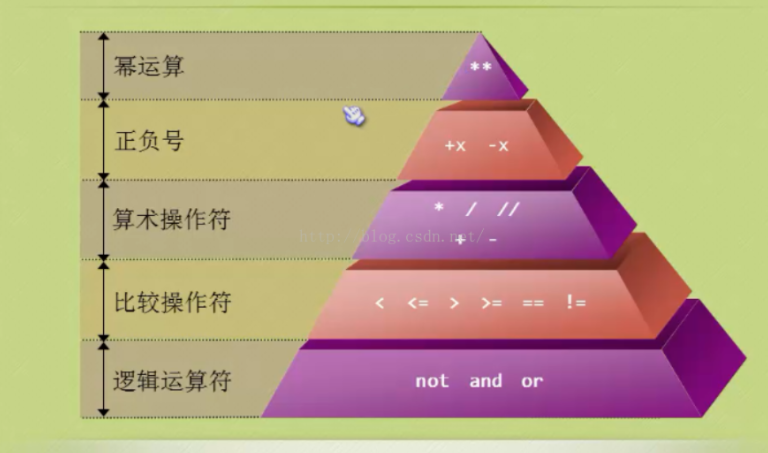
先計算括號內,復雜的表達式推薦使用括號
一般的執行順序:從左到右
布爾運算優先級
從高到低:not and or
例子:
user = 'nicholas'
psswd ='123'
v = user == 'nicholas' and passwd == '123' or 1 == 2 and pwd == '9876'
print(v)
分析:
v = true and true or
此時不用繼續計算即可得出v為真的結果,不用考慮布爾運算的優先級,注意這個運算是從左到右的,**而非看到and自動進行運算而后從左到右運算**
一些結論:
從左到右
(1)第一個表達式 or
True or ————>>得出結果True
(2)第一個表達式 and
True and ————>>繼續運算
(3)第一個表達式 or
False or ————>>繼續運算
(4)第一個表達式 and
False and ————>>得出結果False
即**短路邏輯**
短路邏輯
表達式從左至右運算,若 or 的左側邏輯值為 True ,則短路 or 后所有的表達式(不管是 and 還是 or),直接輸出
?or 左側表達式 (即True)。
?表達式從左至右運算,若 and 的左側邏輯值為 False ,則短路其后所有 and 表達式,直到有 or 出現,輸出 and 左側表達式到
?or 的左側,參與接下來的邏輯運算。
?若 or 的左側為 False ,或者 and 的左側為 True 則不能使用短路邏輯。
?
?
10、賦值運算符
>= 簡單的賦值運算符 c = a + b 將 a + b 的運算結果賦值給c
+= 加法賦值運算符 c += a 等效于 c = c + a
-= 減法賦值運算符 c -= a 等效于 c = c - a
*= 乘法賦值運算符 c *= a 等效于 c = c * a
/= 除法賦值運算符 c /= a 等效于 c = c / a
%= 取模賦值運算符 c %= a 等效于 c = c % a
**= 冪賦值運算符 c **= a 等效于 c = c ** a
//= 取整除賦值運算符 c //= a 等效于 c = c // a
?
二、基本數據類型
(1)數字 int
a = 1
a = 2
int整型(整數類型)
python3中用int表示,沒有范圍
python2中int有一定范圍
超過一定范圍,Python2中有長整型即long
python3中只有整型,用int,取消了long類型
**①**、int()將字符串轉換為數字
a = "123"
type(a)
b = int(a)
print(b)
type(b)
輸出
<class 'str'>
123
<class 'int'>
type()即可查看變量類型
但是
a = "123n"
b = int(a)
此時是無法用int()轉換字符串為數字的。
num = "c"
v = int(num,base = 16)
print(v)
注釋: v = int(num,base = 16) 將num以16進制看待,將num轉為10進制的數字。這里是可以的。
②bit_lenghth
當前數字的二進制,至少用n位表示
age = 5
r = age.bit_length()
#當前數字的二進制,至少占用了n位表示
print(r)
輸出結果
3
即5在二進制中表示為101,至少需要3個位置來表示
(2)字符串 str
a ='hello'
a= 'ssssdda'
字符串方法介紹
a--capitalize()
# capitalize() 首字母大寫
test = "lingou"
v1 = test.capitalize( )
print(v1)
輸出結果
Lingou
b--casefold( )、lower()
#lower() 所有變小寫
# casefold( ) 所有變小寫,與lower相比casefold更牛逼,很多未知(不是英文的,如法文、德文等)的對相應變小寫
#lower() 方法只對ASCII編碼,也就是‘A-Z’有效,對于其他語言(非漢語或英文)中把大寫轉換為小寫的情況只能用 casefold() 方法。
?
test = "LinGou"
v2 = test.casefold( )
print(v2)
v3 =test.lower()
print(v3)
輸出結果
lingou
lingou
c--center( )
#center( ) 設置寬度,并將內容居中,這里的"*"可以不寫,默認為空白。
#這里的30是總寬度,單位字節
?
test = "LinGou"
v4 = test.center(30,"*" )
print(v4)
輸出結果
************LinGou************
空白情況
test = "LinGou"
v5 = test.center(30 )
print(v5)
輸出結果
LinGou
?注:這個輸出結果LinGou左右是有空格的
d--count( )
#count( ) 去字符串中尋找,尋找子序列的出現次數
#count(sub[, start[, end]])
#count( 子序列,尋找的開始位置,尋找的結束位置)
#count( sub, start=None, end=None) None默認表示此參數不存在
?
test = "LinGouLinGengxin"
v6 = test.count("in" )
print(v6)
v7 = test.count("in",3,6)
#這里的3,6 是對字符串"LinGouLinGengxin"的索引編碼,從第三個開始到第六個結束
#L i n G o u L i n G e n g x i n
#0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
print(v7)
v8 = test.count("in",3)#從第3個位置開始找
print(v8)輸出結果
3
0
2
e--endswith()、startswith()
#endswith() 以什么什么結尾
#startswith()以什么什么開始
test = "LinGouLinGengxin"
v9 = test.endswith("in" )
v10 = test.startswith("in")
print(v9)
print(v10)
輸出結果
?
True
False
f--find()、index()
#find()從開始往后找,找到第一個之后,獲取其索引位置
#index()功能同上,index找不到,報錯,一般建議用find()
?
test = "LinGouLinGengxin"
v11 = test.find("in" )
v12 = test.find("XING" )
v13 = test.index("in")
# v14 = test.index("XING" )
print(v11)
print(v12)
print(v13)
#print(v14)
輸出結果
?
1
-1
1
取消v14 = test.index("XING" )和print(v14)的注釋后運行程序會直接報錯
因為index找不到"XING",而find()找不到會返回-1
g--format()
#format()格式化,將一個字符串中的占位符替換為指定的值
# { }就是占位符,通過format將占位符替換為指定的值
?
test = "I am {name}"
print(test)
v15 = test.format(name = "LinGou" )
print(v15)
輸出結果
I am {name}
I am LinGou
-第二個
test = "I am {name},age{a}"
print(test)
v16 = test.format(name = "LinGou",a = 19 )
print(v16)
輸出結果
I am {name},age{a}
I am LinGou,age19
-第三個
test = "I am {0},age{1}"
print(test)
v17 = test.format("LinGou",19 )
print(v17)
輸出結果
I am {0},age{1}
I am LinGou,age19
當占位符有數字代表,format函數里不再需要具體的name =""
這里是按照先后順序替換的。
第四個
#format_map()格式化,傳入的值
# 書寫格式{"name":"LinGou","a":19}
?
test = "I am {name},age {a}"
print(test)
v18 = test.format_map({"name":"LinGou","a":19} )
v19 = test.format(name = "LinGou",a = "19")
print(v18)
print(v19)
輸出結果
I am {name},age {a}
I am LinGou,age 19
I am LinGou,age 19
分析:這里的v18和v19是等價的,只是書寫方式不一樣。format_map后面加的是字典。
h--isalnum( )
#isalnum( )字符串中是否只包含 字母和數字
?
test = "LinGou"
v20 = test.isalnum( )
print(v20)
test2 = "LinGou+"
v21 = test2.isalnum( )
print(v21)
輸出結果
True
False
?








python操作redis的api框架redis-py簡單使用)










