

在“R與生物統計專題”中,我們會從介紹R的基本知識展開到生物統計原理及其在R中的實現。以從淺入深,層層遞進的形式在投必得醫學公眾號更新。
在上一講中,我們介紹了第三講 R編程基礎-矩陣和數據框?(戳這里即可跳轉)。到現在為止,大家已經學完了R語言的基礎知識,馬上就開始進階地學習一些R語言相關的統計學技能了。
今天的更新,我們會帶您學習R的基本統計學技能:描述性統計分析。1. 將數據導入R
1.1 準備好你的數據命名約定避免名稱帶有空格。
? ????? 好的列名:patient_age或patient.age。
? ??????列名錯誤:patient age。
避免使用帶有特殊符號的名稱:?,$,*,+,#,(,),-,/,},{,|,>,
避免以數字開頭的變量名。請改用字母。
好的列名稱:patient_1st_meal或x1st_meal。
列名錯誤:1st_male
列名必須是唯一的。不允許重復的名稱。
R區分大小寫。這意味著名稱不同于名稱或名稱。
避免數據中出現空白行。
刪除文件中的任何評論。
用NA替換缺少的值(不可用)。
如果你有包含日期的列,請使用四位數格式。
格式良好:20160101。
格式錯誤:01/01/16
# 對于.txt文件my_data # 對于.csv文件my_data 在這里,我們將使用名為iris的內置R數據集。
# 導入R內自帶的iris數據集library(datasets)data(iris)# 將數據存儲在變量my_data中my_data 你可以使用head()和tails()函數檢查數據,這將分別顯示數據的第一部分和最后一部分。
# 顯示前六行內容head(my_data, 6)輸出結果如下
Sepal.Length?Sepal.Width?Petal.Length?Petal.Width?Species
1??????????5.1?????????3.5??????????1.4?????? 0.2??setosa
2??????????4.9?????????3.0??????????1.4???????0.2??setosa
3??????????4.7?????????3.2??????????1.3?????? 0.2??setosa
4??????????4.6?????????3.1??????????1.5???? ? 0.2??setosa
5??????????5.0?????????3.6??????????1.4???? ? 0.2??setosa
6??????????5.4?????????3.9??????????1.7?????? 0.4??setosa
2.?常用的描述性統計的R函數
一些用于計算描述性統計量的R函數:
??R函數?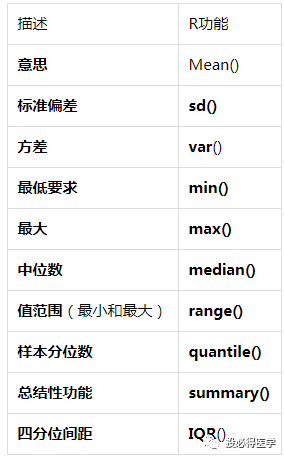
3. 單個組的描述性統計
3.1 集中趨勢的度量:均值,中位數,眾數粗略地說,集中趨勢衡量的是數據的“平均”或“中間”。最常用的衡量指標包括:
集中趨勢平均值:平均值。它對異常值很敏感。
中位數:中間值。這是一個強有力的替代手段。
眾數:最頻繁出現的值
在R中
函數mean()和median()可以分別計算平均值和中位數;
# 計算平均值mean(my_data$Sepal.Length)[1] 5.843333
# 計算中位數median(my_data$Sepal.Length)[1] 5.8
3.2 可變性的度量可變性度量給出了數據“分散”的程度。
范圍極值:最小值和最大值
范圍:最大值減去最小值
# 計算最小值min(my_data$Sepal.Length)[1] 4.3
# 計算最大值max(my_data$Sepal.Length)[1] 7.9
# 范圍range(my_data$Sepal.Length)[1] 4.3 7.9
四分位間距四分位數將數據均勻分為4部分。四分位數間距(IQR):對應于第一和第三四分位數之間的差異-有時被用作標準偏差的可靠替代方案。
R功能:
quantile(x, probs = seq(0, 1, 0.25))x:需要樣本分位數的數值向量。
probs:在[0,1]之間的概率數值向量。
例:
quantile(my_data$Sepal.Length)0% ?25% ?50% ?75% 100%
4.3 ?5.1 ?5.8 ?6.4 ?7.9
# 計算十分位數(0.1,0.2,0.3,…,0.9):quantile(my_data$Sepal.Length, seq(0, 1, 0.1))# 計算四分位間距:IQR(my_data$Sepal.Length)[1] 1.3
方差和標準差方差表示與均值的平均平方差之和。標準差是方差的平方根。它測量數據中數值與平均值的平均偏差。
# 計算方差var(my_data$Sepal.Length)# 計算標準差sd(my_data$Sepal.Length)絕對中位數(Median absolute deviation,MAD):數據中值與中值的偏差,即先計算出數據與它們的中位數之間的殘差(偏差),MAD就是這些偏差的絕對值的中位數。
# 計算中位數median(my_data$Sepal.Length)# 計算絕對中位數mad(my_data$Sepal.Length)范圍。它不經常使用,因為它對異常值非常敏感。
四分位間距。對于異常值,它非常強大。它多與中位數結合使用。
方差。完全無法解釋的,因為它不使用與數據相同的單位。除了用作數學工具外,很少被使用。
標準偏差。方差的平方根。它以與數據相同的單位表示。在均值是集中趨勢的分布(多指正態分布)的情況下,通常使用標準偏差。
絕對中位數。對于具有離群值的數據,這是一種估算標準偏差的可靠方法。但是不經常使用。
總而言之,四分位間距和標準差是用于報告數據變異性的兩種最常用的度量。
函數summary()可用于顯示一個變量或整個數據框的多個統計變量概況。
單個變量的概況。
返回六個值:平均值,中位數,第25和,75四分位數,最小值和最大值。
summary(my_data$Sepal.Length)輸出結果如下:
Min. 1st Qu. Median Mean 3rd Qu. Max.4.300 5.100 5.800 5.843 6.400 7.900在這種情況下,函數summary()將自動應用于每列。結果的格式取決于列中包含的數據類型。例如:
如果列是數字變量,則返回均值,中位數,最小值,最大值和四分位數。
如果該列是一個因素變量(factor),則返回每個組中的觀察數。
summary(my_data, digits = 1)輸出結果如下:
Sepal.Length Sepal.Width Petal.Length Petal.Width SpeciesMin. :4 Min. :2 Min. :1 Min. :0.1 setosa :501st Qu.:5 1st Qu.:3 1st Qu.:2 1st Qu.:0.3 versicolor:50Median :6 Median :3 Median :4 Median :1.3 virginica :50Mean :6 Mean :3 Mean :4 Mean :1.23rd Qu.:6 3rd Qu.:3 3rd Qu.:5 3rd Qu.:1.8Max. :8 Max. :4 Max. :7 Max. :2.5當數據包含缺失值時,即使僅缺少一個值,某些R函數也會返回錯誤或NA。
例如,即使向量中僅丟失一個值,mean()函數也將返回NA。使用參數na.rm = TRUE可以避免這種情況,該參數告訴函數在計算之前刪除所有NA。使用均值函數的示例如下:
mean(my_data$Sepal.Length, na.rm = TRUE)好了,本期講解就先到這里。
在之后的更新中,我們會進一步為您介紹R的入門,以及常用生物統計方法和R實現。歡迎關注,投必得醫學手把手帶您走入R和生物統計的世界。
提前打個預告,接下來我們要正式開始學習R語言的統計學技能啦,下一期將會更新“R的描述性統計分析”。喜歡的同學們快快關注起來吧。
 第一講 R-基本介紹及安裝第二講 R-編程基礎-運算、數據類型和向量等基本介紹第三講 R編程基礎-矩陣和數據框
第一講 R-基本介紹及安裝第二講 R-編程基礎-運算、數據類型和向量等基本介紹第三講 R編程基礎-矩陣和數據框當然啦,R語言的掌握是在長期訓練中慢慢積累的。一個人學習太累,不妨加入“R與統計交流群”,和數百位碩博一起學習。
快掃二維碼撩客服,
帶你進入投必得醫學交流群,
讓我們共同進步!
↓↓

- END -
長按二維碼關注「投必得醫學」,更多科研干貨在等你!

麻煩點一下在看再走唄







)





)
返回JSON消息的字符串...)
;方法不刷新的問題)




