1.第一范式(1NF)(列不能再拆分)
原子性,字段不可分(列的信息),只要是關系型數據庫,就自動滿足1NF;
2.第二范式(2NF)(主鍵唯一,且被依賴)
在第一范式基礎上建立的,即滿足第二范式的必須先滿足第一范式。要求DB表中的每個實例或行必須可以被唯一區分,通常設計一個主鍵來實現,其他屬性完全依賴主鍵。
3.第三范式(3NF)(表與其他表間沒有關聯)
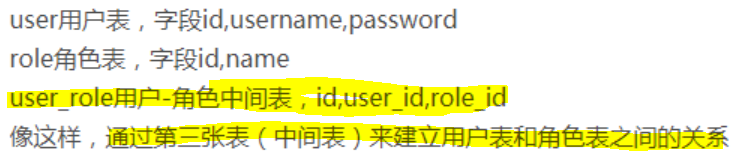
必須滿足第二范式,要求一個數據庫表中不包含已在其他表中已包含的非主鍵字段。即:表的信息,如果能夠被推導出來,就不應該單獨設計一個字段來存放(能盡量外鍵join就用外鍵join)。很多時候,為滿足第三范式往往會把一張表分成多張表,如:
4.反范式
通過增加冗余或重復的數據來提高數據庫的讀性能。
具體做法:在概念數據模型設計時遵守第三范式,降低范式標準的工作放到物理數據模型設計時考慮。降低范式就是增加字段,減少了查詢時的關聯,提高查詢效率,因為在數據庫的操作中查詢的比例要遠遠大于DML的比例。但是反范式化一定要適度,并且在原本已滿足三范式的基礎上再做調整。
實際,比如:可以減少關聯查詢時,jion表的次數,如:在3中,增加字段role_name。
5.范式化優點及缺點:
優點:
.更新操作通常比反范式化要快;
.范式化的表通常更小,沒有數據冗余,更省數據庫空間,同時可以放在內存,所以執行操作會更快。
.很少有多余數據意味著檢索列表數據更少需要distinct或group by語句。
.數據較好的范式化,只有很少或沒有重復數據,所以,只需要修改更少的數據。
缺點:
.范式化schema通常需要關聯,可能使一些索引策略無效。
.范式等級越高,設計出來的表越多,可能會增加查詢需要的時間。
6.反范式化優點及缺點:
優點:
.可以很好避免關聯。
.如果不需要關聯表,對大部分查詢最差情況,沒有使用索引,全表掃描,當數據比內存大時,可能比關聯快,避免隨機IO
7.實際經驗
實際中,不會極端使用范式化或反范式化schema,可能使用部分范式化schema、緩存表、及其他技巧。
最常見反范式化數據方法:復制或緩存,在不同表中存儲相同的特定列,比如:實際業務涉及的表非常多,表間連接會比較多,對表的操作要盡量快,通常會使用反范式設計,用空間換時間,把數據冗余在多張表中,查詢時可以減少或避免表間關聯。

)


)
——對象創建)

失敗_C# 調用百度AI 人臉識別)


...)

)
)





![python調用菜單響應事件_[Python] wxpython 編程觸發菜單或按鈕事件](http://pic.xiahunao.cn/python調用菜單響應事件_[Python] wxpython 編程觸發菜單或按鈕事件)