
索引查找算法BTREE
BTREE查找算法演變B-TREE :普通 BTREE,平衡多路查找樹(B-Tree)B+TREE :葉子節點雙向指針B++TREE(B*TREE):枝節點的雙向指針普通B-TREE
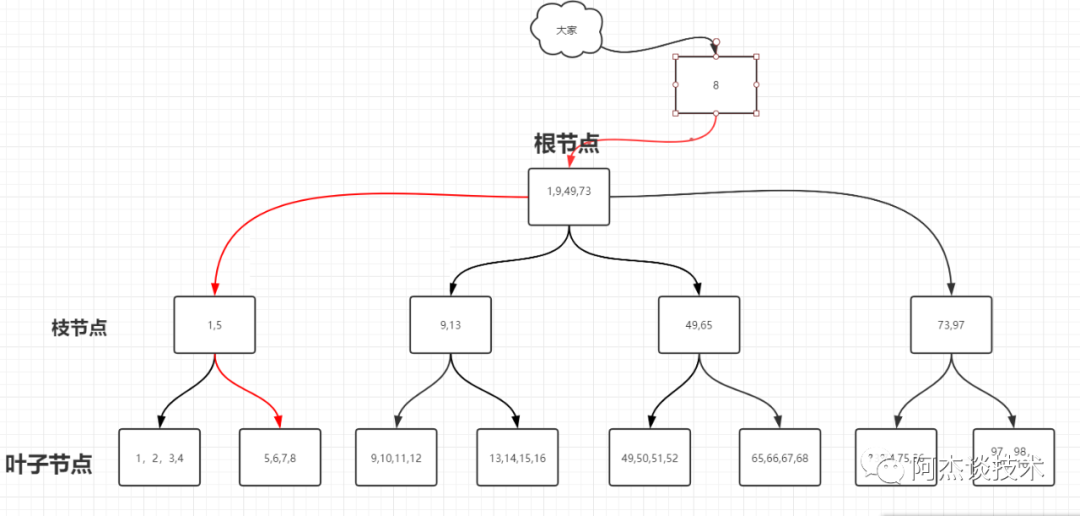
增強版B+TREE(B*TREE)
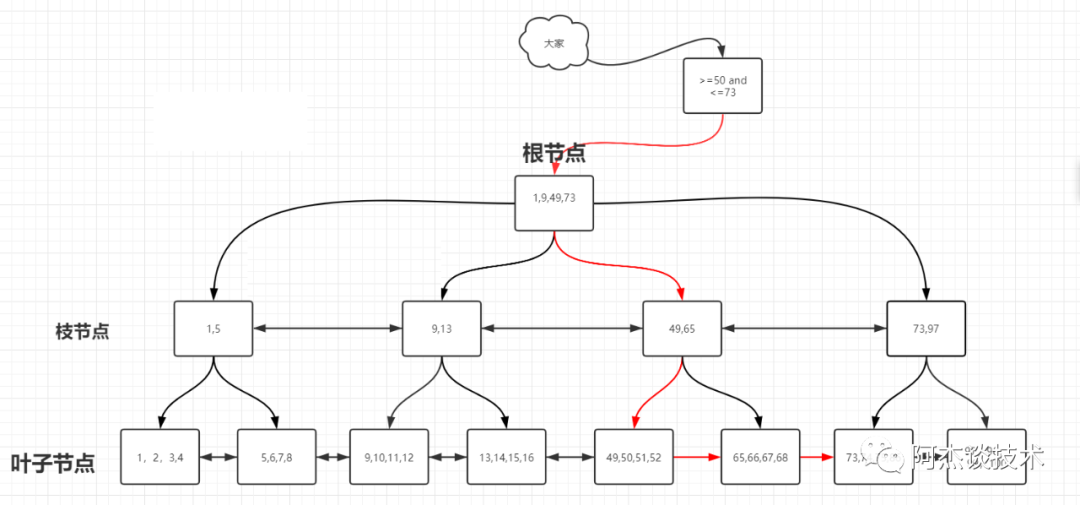
總結:從上圖看出,在B+Tree上有兩個頭指針,一個指向根節點,另一個指向關鍵字最小的葉子節點,而且所有葉子節點(即數據節點)之間是一種鏈式環結構。B+Tree是在B-Tree基礎上的一種優化,使其更適合實現外存儲索引結構,InnoDB存儲引擎就是用B+Tree實現其索引結構。從上圖中的B-Tree結構圖中可以看到每個節點中不僅包含數據的key值,還有data值。而每一個頁的存儲空間是有限的,如果data數據較大時將會導致每個節點(即一個頁)能存儲的key的數量很小,當存儲的數據量很大時同樣會導致B-Tree的深度較大,增大查詢時的磁盤I/O次數,進而影響查詢效率。在B+Tree中,所有數據記錄節點都是按照鍵值大小順序存放在同一層的葉子節點上,而非葉子節點上只存儲key值信息,這樣可以大大加大每個節點存儲的key值數量,降低B+Tree的高度。而BTree,這個是以B+Tree為基礎,在非葉子結點(枝節點)上增加了鏈表指針,BTree的空間利用率更高。
MySQL中如何使用BTREE
1 聚簇索引
聚簇索引也叫集群索引,聚集索引。它不是一種單獨的索引類型,而是一種數據存儲方式。Innodb的聚簇索引實際上在同一個結構中保存了B*Tree索引和數據行。當表有聚簇索引時,數據行實際上存儲在索引的葉子節點中。聚簇的意思是表示數據行和相鄰的鍵值緊湊地存儲在一起。一個表只能有一個聚簇索引。也就是按照每張表的主鍵構成一棵B+樹,葉子節點中存放整張表的行記錄數據,也將聚集索引的葉子節點成為數據頁,每個數據頁之間通過一個雙向鏈表來進行鏈接。數據頁存放的是每行的所有記錄,非數據頁存放的是鍵值和指向數據頁的偏移量。它可以在葉子節點直接找到數據,且對于主鍵的排序查找和范圍查找速度非常快,因為聚集索引是邏輯上連續的。比如查詢后10條數據,由于B+樹索引是雙向鏈表,可以很快找到隨后一個數據頁,然后取出最后的10條數據。
①前提條件
1.如果表中設置了主鍵(例如ID列),自動根據ID列生成索引樹。2.如果沒有設置主鍵,自動選擇第一個唯一鍵的列作為聚簇索引3.如果沒有唯一鍵,自動生成隱藏的聚簇索引。4.在建表時,推薦創建主鍵為數字自增列。②功能
1.錄入數據時,按照聚簇索引組織存儲數據,在磁盤上有序存儲數據行。2.加速查詢(基于ID作為條件的判斷查詢)。③聚簇索引的B*Tree構建過程
a. 葉子節點:存儲數據行時就是有序的,直接將數據行的page作為葉子節點(相鄰的葉子結點,有雙向指針)b. 枝節點 :提取葉子節點ID的范圍+指針,構建枝節點(相鄰枝節點,有雙向指針)c. 根節點 :提取枝節點的ID的范圍+指針,構建根節點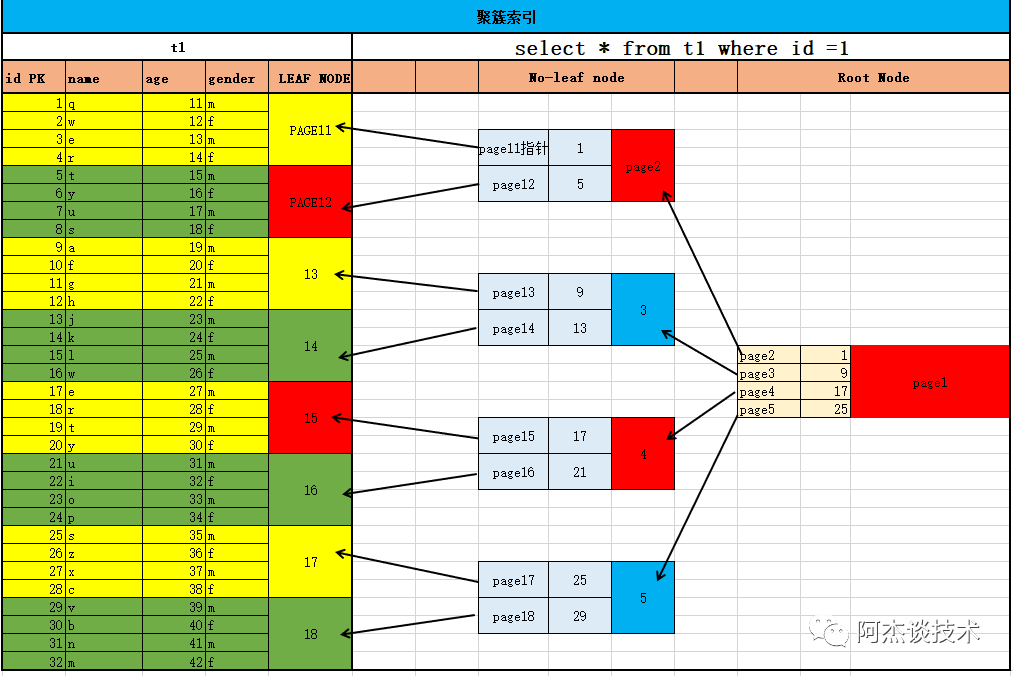
2 輔助索引
輔助索引需要人為創建輔助索引,將經常作為查詢條件的列創建輔助索引,起到加速查詢的效果。也稱非聚集索引,按照每張表創建的索引列創建一棵B+樹,葉子節點并不包含行記錄的全部數據。葉子節點包含鍵值 和 書簽,書簽用來告訴InnoDB存儲引擎在哪可以找到與索引對應的行數據,每張表可以有多個輔助索引。如果某個查詢是通過輔助索引查找數據的,則查找過程為:先遍歷輔助索引并找到葉節點找到指針獲取主鍵索引的主鍵,然后通過主鍵索引找到對應的頁從而找到一個完整的行記錄。注:沒執行一次查詢就是一次IO,比如 輔助索引樹高度為3,聚集索引樹高度為2,則通過輔助索引查詢數據時就要進行3+2次邏輯IO最終得到一個數據頁。
輔助索引的B*Tree 構建過程
a. 葉子節點:提取主鍵(ID)+輔助索引列,按照輔助索引列進行從小到大排序后,生成葉子節點。(多個輔助索引列,以最左邊的列為標準。相鄰的葉子結點,有雙向指針。)b. 枝節點 :提取葉子節點輔助索引列的范圍+指針,構建枝節點(相鄰枝節點,有雙向指針)c. 根節點 :提取枝節點的輔助索引列的范圍+指針,構建根節點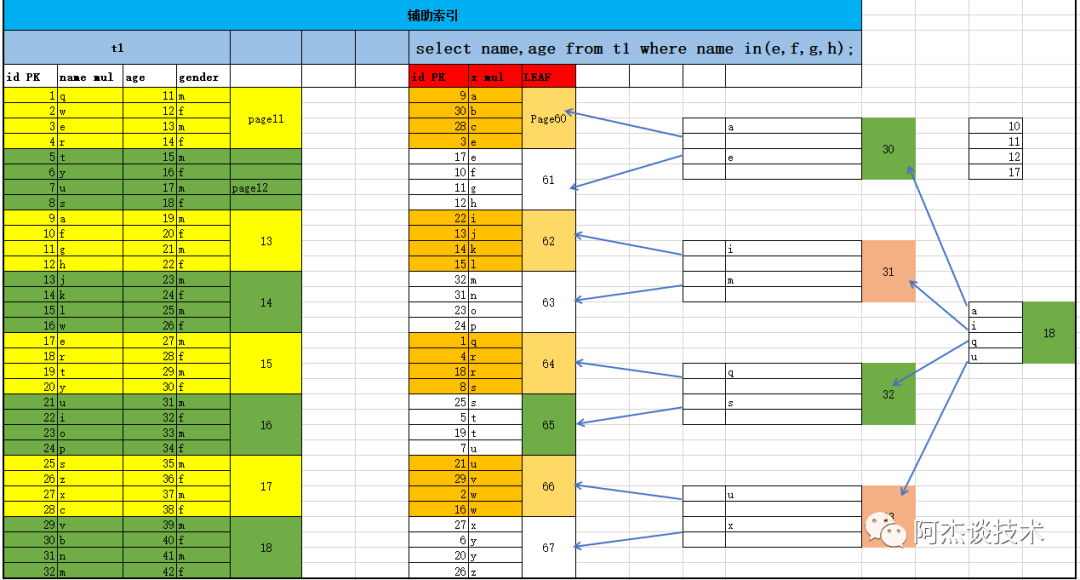
輔助索引查詢過程:
# 按照輔助索引列,作為查詢條件時。1. 查找輔助索引樹,得到ID值2. 拿著ID值回表(聚簇索引)查詢①單列索引
只拿一個非主鍵列來創建索引,如下:
# 單列輔助索引 select * from test.t100w where k2='780P' # 優化方式: alter table 表名 add index 索引名(列名); mysql> alter table t100w add index idx_k2(k2);②聯合索引
# 使用多個非主鍵列創建輔助索引mysql> alter table t100w add index idx_k1_num(k1,num);③前綴索引
列值長度越長,數據量大的話,會影響到索引高度,需要使用前綴索引,也就是截取列值的前綴生成新的索引以提高效率。
# 判斷前綴長度多少合適:截取字符串之后得到的總記錄數越接近截取之前的越好,說明前綴的唯一性高!select count(distinct(left(name,5))) from city ;select count(distinct name) from city ;# 創建前綴索引mysql> alter table city add index idx_n(name(5)); # 刪除索引mysql> alter table city drop index idx_n;關于索引的相關問題
1 回表問題
# 關于輔助索引回表是什么?回表會帶來什么問題?怎么減少回表?a. 回表:按照輔助索引列作為查詢條件時,先查找輔助索引樹,再到聚簇索引樹查找數據行的過程。b. 影響:IO量多、IO次數多、隨機IO會增多c. 減少回表: 1. 輔助索引能夠完全覆蓋查詢結果,可以使用聯合索引。 2. 盡量讓查詢條件精細化,盡量使用唯一值多的列作為查詢條件 3. 優化器:MRR(Multi-Range-Read), 錦上添花的功能。 mysql> select @@optimizer_switch; mysql> set global optimizer_switch='mrr=on';功能:(1)輔助索引查找后得到ID值,進行自動排序(2)一次性回表,很有可能受到B+TREE中的雙向指針的優化查找。2 索引樹高度的影響因素
a. 高度越低越好b. 數據行越多,高度越高。 1. 分區表。一個實例里管理。基本不再使用了! 2. 按照數據特點,進行歸檔表。 3. 分布式架構。針對海量數據、高并發業務主流方案。 4. 在設計方面,滿足三大范式。c. 主鍵規劃:長度過長。 1. 主鍵,盡量使用自增數字列。 d. 列值長度越長,數據量大的話,會影響到高度。 1. 使用前綴索引 比如列值長100字符,那么只取前10個字符,構建索引樹。 e. 數據類型的選擇。 選擇合適的、簡短的數據類性。 例如: 1. 存儲人的年齡 ,使用 tinyint 和 char(3)哪個好一些 2. 存儲人名,char(20)和varchar(20)的選擇哪一個好。 a. 站在數據插入性能角度思考,應該選:char b. 從節省空間角度思考,應該選:varchar c. 從索引樹高度的角度思考,應該選:varchar結論:建議使用varchar類型存儲變長列值創建索引
查詢表索引
mysql> desc city;+-------------+----------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-------------+----------+------+-----+---------+----------------+| ID | int(11) | NO | PRI | NULL | auto_increment || Name | char(35) | NO | MUL | | || CountryCode | char(3) | NO | UK | | || District | char(20) | NO | | | || Population | int(11) | NO | | 0 | |+-------------+----------+------+-----+---------+----------------+5 rows in set (0.00 sec) PK --> 主鍵(聚簇索引) MUL --> 輔助索引 UK --> 唯一索引 mysql> show index from city;+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+| city | 0 | PRIMARY | 1 | ID | A | 4188 | NULL | NULL | | BTREE | | || city | 1 | CountryCode | 1 | CountryCode | A | 232 | NULL | NULL | | BTREE | | || city | 1 | idx_name | 1 | Name | A | 3554 | 5 | NULL | | BTREE | | |+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ # Cardinality值越大,索引優先級越高。創建索引
# 單列輔助索引 select * from test.t100w where k2='780P'; # 該表沒有索引,大量數據查詢耗時極大,需要優化! 優化方式:語法:alter table 表名 add index 索引名(列名); alter table t100w add index idx_k2(k2); # 聯合索引創建 mysql> alter table t100w add index idx_k1_num(k1,num); # 前綴索引創建# 判斷前綴長度多少合適:select count(distinct(left(name,5))) from city ;select count(distinct name) from city ;# 創建前綴索引mysql> alter table city add index idx_n(name(5)); # 刪除索引alter table city drop index idx_n;執行計劃獲取和分析
1 執行計劃工具
# 獲取語句的執行計劃工具 explain des# 使用方法 :mysql> desc select * from city where countrycode='CHN';mysql> explain select * from city where countrycode='CHN';+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+2 執行計劃信息
table :此次查詢訪問的表type :索引查詢的類型(ALL、index、range、ref、eq_ref、const(system)、NULL)possible_keys :可能會應用的索引key : 最終選擇的索引key_len :索引覆蓋長度,主要是用來判斷聯合索引應用長度。rows :需要掃描的行數Extra :額外信息3 Type信息詳解
代價從高到低!
ALL
# 沒有使用到索引a. 查詢條件沒建立索引# district并沒有被創建成輔助索引mysql> desc select * from city where district='shandong';+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | SIMPLE | city | NULL | ALL | NULL | NULL | NULL | NULL | 4188 | 10.00 | Using where |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) b. 有索引不走# 這三種查詢不走索引mysql> desc select * from city where countrycode!='CHN';mysql> desc select * from city where countrycode not in ('CHN','USA');mysql> desc select * from city where countrycode like '%CH%';index
# 全索引掃描 mysql> desc city;+-------------+----------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-------------+----------+------+-----+---------+----------------+| ID | int(11) | NO | PRI | NULL | auto_increment || Name | char(35) | NO | MUL | | || CountryCode | char(3) | NO | MUL | | || District | char(20) | NO | | | || Population | int(11) | NO | | 0 | |+-------------+----------+------+-----+---------+----------------+5 rows in set (0.00 sec) mysql> desc select countrycode from city;+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+| 1 | SIMPLE | city | NULL | index | NULL | CountryCode | 3 | NULL | 4188 | 100.00 | Using index |+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) # 由于country是輔助索引,這里查詢會遍歷掃描索引,效率也是一種問題。range
從這里開始,我們可以接受這些類型的索引查詢,但是無法容忍上述兩種!
# 索引范圍掃描# 會受到:B+TREE額外優化,葉子節點雙向指針# >、=、<=、in、or、between and、likemysql> desc select * from city where id<10;mysql> desc select * from city where countrycode like 'CH%';+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | city | NULL | range | CountryCode | CountryCode | 3 | NULL | 397 | 100.00 | Using index condition |+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.00 sec) # 這種情況下,主鍵索引性能還可以,如果查詢條件是輔助索引,就會牽扯到回表次數問題而導致性能較低。 # 以下兩種查詢,大幾率受不到葉子節點雙向指針優化。# 他會遍歷兩個值之間的數據,而這種遍歷是沒有必要的!mysql> desc select * from city where countrycode in ('CHN','USA');mysql> desc select * from city where countrycode='CHN' or countrycode='USA'; # 建議:如果查詢列重復值少的話,我們建議改寫為 union all (2-3個,如果超過50%,那就沒什么卵用了!)desc select * from city where countrycode='CHN'union allselect * from city where countrycode='USA';+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+| 1 | PRIMARY | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL || 2 | UNION | city | NULL | ref | CountryCode | CountryCode | 3 | const | 274 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+2 rows in set, 1 warning (0.00 sec)ref
# 輔助索引等值查詢desc select * from city where countrycode='CHN';+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+1 row in set, 1 warning (0.00 sec) #?等值查詢的代價比range就要低很多了。?
eq_ref
# 多表連接查詢中,非驅動表的連接條件是主鍵或唯一鍵時。mysql> desc select city.name,country.name from city left join country on city.countrycode=country.code where city.population<100;# 在非驅動表country中code是主鍵,在多表連接中如果顯示未eq_ref,那就是最佳的優化實踐,也是性能最好的一種場景。這也是多表連接中非驅動表的優化方向。驅動表后續會介紹。+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-------------+| 1 | SIMPLE | city | NULL | ALL | NULL | NULL | NULL | NULL | 4188 | 33.33 | Using where || 1 | SIMPLE | country | NULL | eq_ref | PRIMARY | PRIMARY | 3 | world.city.CountryCode | 1 | 100.00 | NULL |+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-------------+2 rows in set, 1 warning (0.00 sec) # 這個時候我們把population條件創建為一個輔助索引,驅動表走的索引就是range。這也是最好的一種優化了,沒有別的方式比這個性能更好了,知足吧!mysql> alter table city add index idx_p(population);mysql> desc select city.name,country.name from city left join country on city.countrycode=country.code where city.population<100;+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-----------------------+| 1 | SIMPLE | city | NULL | range | idx_p | idx_p | 4 | NULL | 1 | 100.00 | Using index condition || 1 | SIMPLE | country | NULL | eq_ref | PRIMARY | PRIMARY | 3 | world.city.CountryCode | 1 | 100.00 | NULL |+----+-------------+---------+------------+--------+---------------+---------+---------+------------------------+------+----------+-----------------------+2 rows in set, 1 warning (0.00 sec)const(system)
# 主鍵或唯一鍵等值查詢# 性能最好,只需回表一次,這是一種奢望!mysql> desc select * from city where id=1;+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| 1 | SIMPLE | city | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+1 row in set, 1 warning (0.00 sec)NULL
# 查不到數據的時候性能最好!那我要你有何用!!!不用管了!!!mysql> desc select * from city where id=1000000000000000;總結
通常最常見的執行計劃類型是:range、ref、eq_ref。如果出現index或者all的情況,那就可能涉及到改寫sql查詢語句,或者得找業務溝通查詢條件了。

)









)






