英文也是泡菜的意思。
學完了,還是感覺這個模塊是蠻不錯的,對多數據保存到文件中,然后在使用的時候,再讀取出來,讓程序閑的更加優雅,簡潔。
一:介紹
1.為什么使用
在開篇已經介紹了,但是我這里粘貼一下別人對pickle的看法。
pickle是python語言的一個標準模塊,安裝python后已包含pickle庫,不需要單獨再安裝。
那么為什么需要序列化和反序列化這一操作呢?
1.便于存儲。序列化過程將文本信息轉變為二進制數據流。這樣就信息就容易存儲在硬盤之中,當需要讀取文件的時候,從硬盤中讀取數據,然后再將其反序列化便可以得到原始的數據。在Python程序運行中得到了一些字符串、列表、字典等數據,想要長久的保存下來,方便以后使用,而不是簡單的放入內存中關機斷電就丟失數據。python模塊大全中的Pickle模塊就派上用場了,它可以將對象轉換為一種可以傳輸或存儲的格式。
2.便于傳輸。當兩個進程在進行遠程通信時,彼此可以發送各種類型的數據。無論是何種類型的數據,都會以二進制序列的形式在網絡上傳送。發送方需要把這個對象轉換為字節序列,在能在網絡上傳輸;接收方則需要把字節序列在恢復為對象。
?
2.保存
pickle模塊是以二進制的形式序列化后保存到文件中(保存文件的后綴為”.pkl”),不能直接打開進行預覽。
而python的另一個序列化標準模塊json,則是human-readable的,可以直接打開查看(例如在notepad++中查看)。
?
二:操作
1.思路
數據不寫多了,這里只寫了一個列表,做演示。
主要分為兩個階段,一個是存放數據到文件。
第二個階段是從文件中讀取數據,獲取使用。
?
2.程序
1 ###第一階段,屬于腌制 2 import pickle 3 data_list=[1,2,3,4,5,6,7,8,'aaaa',[1,8,'a']] 4 5 file1=open('data.pkl','wb') 6 pickle.dump(data_list, file1) 7 file1.close() 8 9 ###第二階段,屬于使用 10 file2=open('data.pkl','rb') 11 newdata=pickle.load(file2) 12 print(newdata)
?
3.效果、
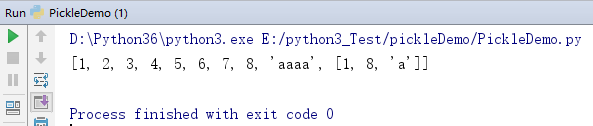
?
4.遇到的問題
module 'pickle' has no attribute 'dump'
解決方式:
python package中的名字寫成了pickle,后來修改成pickleDemo就好了,這個值得注意一下。
?



)








![[算法總結] 13 道題搞定 BAT 面試——字符串](http://pic.xiahunao.cn/[算法總結] 13 道題搞定 BAT 面試——字符串)

---爬蟲數據準備)

![[Err] 22007 - [SQL Server]從 nvarchar 數據類型到 datetime 數據類型的轉換產生一個超出范圍的值。](http://pic.xiahunao.cn/[Err] 22007 - [SQL Server]從 nvarchar 數據類型到 datetime 數據類型的轉換產生一個超出范圍的值。)

)
