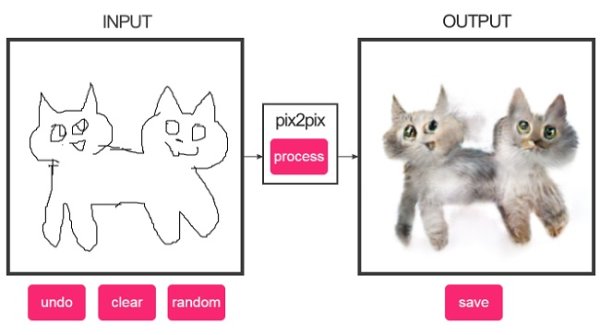
前一段時間,我開發了Sketchify, 該工具可以把任何以SVG為渲染技術的可視化轉化為手繪風格。(參考手繪風格的數據可視化實現 Sketchify)
那么問題來了,很多的chart是以Canvas為渲染技術的,那要怎么辦?
我拍腦袋一想,為什么不使用深度學習技術來做呢?
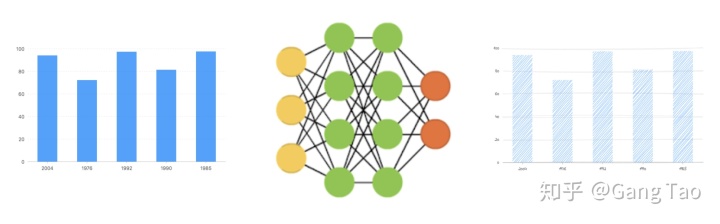
原理很簡單:
- 首先用相同的數據分別生成原始的和手繪風格的數據可視化圖數據。
- 然后利用深度神經網絡,使用該數據訓練一個模式,輸入是數據圖,輸出的手繪風格的圖。這樣就可以訓練一個生成手繪風格數據可視化的神經網絡了。
- 然后對于任何新的數據圖,輸入該網絡就可以輸出一個手繪風格的圖。
這聽起來就像如何把大象放到冰箱里一樣的簡單直接。
廢話少說,開始干。
準備數據
數據準備要生成一定數量的原始圖和手繪圖,利用Sketchify就可以完成功能,但是具體如何做到?參考如下架構:
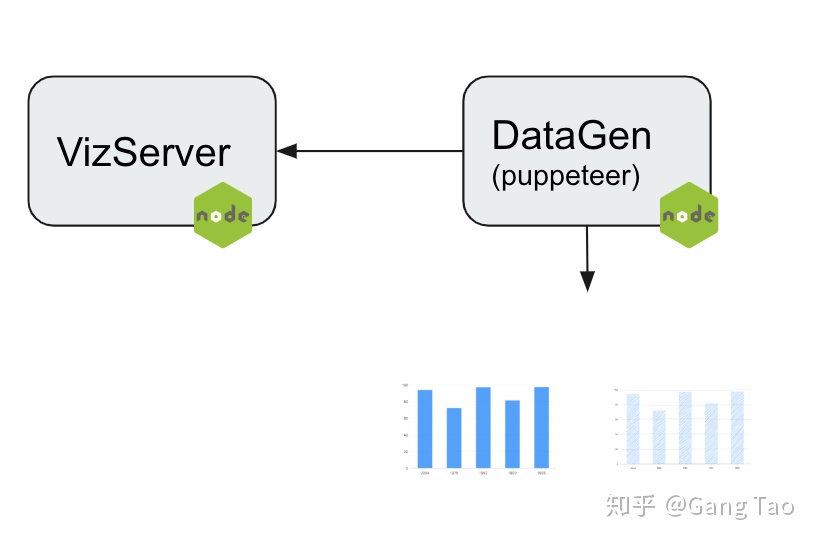
- VizServer是一個web服務,用nodejs開發,代碼在這里https://github.com/gangtao/handyModel/tree/master/vizService
VizServer使用restify提供RestAPI接口,利用squirrelly.js的模版引擎生成一個包含可視化的Html頁面。模版代碼在這里 - DataGen負責生成隨機的圖表數據,發送請求到VizServer,把返回的網頁利用puppeteer的headless browser渲染,并截圖。代碼在這里
其中,數據生成部分我是用了mockjs,我發現另一個比較有趣的庫可以做類似的功能是casual
訓練神經網絡
數據準備好以后就可以訓練神經網絡了。
深度神經網絡的訓練往往比較消耗資源。最好有相當大的內存和GPU。有倆個免費的選擇:
- google colab

colab就不需要介紹了,大家都很熟悉了,有免費GPU
- paperspace
paperspace是一個新的深度學習的免費環境,我試用了以下,免費的GPU配置還是很不錯的,大家可以試試看。
有了訓練環境,導入數據,設一個神經網絡,然后就可以訓練了。這里省去若干介紹如何加載數據png,轉換成tensor或tf的dataset。大家可以參考這些代碼。
總之,大象還是沒能順利的放入冰箱,我訓練的模型大都輸出這樣的手繪圖。

離我的設想的輸出差距比較大。為什么會失敗呢?我想大概有以下這些原因。
- 我的神經網絡比較簡單,受限于硬件,我不可能訓練非常復雜的神經網絡。
- 我的損失函數選擇不好
- 我的網絡不收斂
- 我的訓練時間不夠
總之,完成圖像到圖像的翻譯任務,我們需要更復雜和高深的技術。
圖像到圖像的翻譯
經研究我發現,這個任務是一個典型的圖像到圖像的翻譯,例如前些日子火遍大江南北的deepfake,就是基于圖像到圖像的翻譯。

有一些專門的的研究針對圖像到圖像的翻譯任務。一個是CycleGan,另一個是pix2pix(Conditional GAN),這兩個都是基于GAN(生成對抗網絡)的,所以我們先簡單講講GAN。 (參考 在瀏覽器中進行深度學習:TensorFlow.js (八)生成對抗網絡 (GAN))
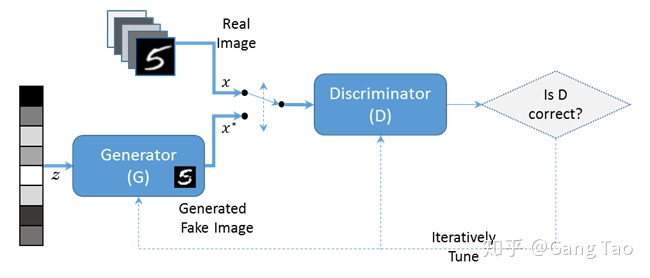
如上圖所示,GAN包含兩個互相對抗的網絡:G(Generator)和D(Discriminator)。正如它的名字所暗示的那樣,它們的功能分別是:
- Generator是一個生成器的網絡,它接收一個隨機的噪聲,通過這個噪聲生成圖片。
- Discriminator是一個鑒別器網絡,判別一張圖片或者一個輸入是不是“真實的”。它的輸入是數據或者圖片,輸出D表示輸入為真實圖片的概率,如果為1,就代表100%是真實的圖片,而輸出為0,就代表不可能是真實的圖片。
在訓練過程中,生成網絡G的目標就是盡量生成真實的圖片去欺騙判別網絡D。而D的目標就是盡量把G生成的圖片和真實的圖片分別開來。這樣,G和D構成了一個動態的“博弈過程”。在最理想的狀態下,G可以生成足以“以假亂真”的圖片
CycleGan
https://github.com/junyanz/CycleGAN
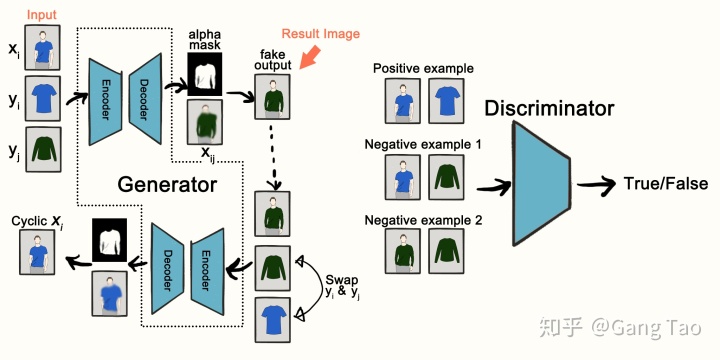
實現圖像間的翻譯,借助GAN,應該有兩個domain的鑒別器,每個鑒別器單獨判斷各自domain的數據是否是真實數據。至于generator,圖像的翻譯需要將domain A的圖像翻成domain B的圖像,所以generator有點像自編碼器結構,只是decoder的輸出不是domain A的圖像,而是domain B的圖像。為了充分利用兩個discriminator,還應該有一個翻譯回去的過程,也就是說,還有一個generator,它將domain B的數據翻譯到domain A。
CycleGAN作者做了很多有意思的實驗,包括horse2zebra,apple2orangle,以及風格遷移,如:對風景畫加上梵高的風格。

Pix2pix
https://github.com/phillipi/pix2pix
pix2pix是基于條件對抗生成網絡,關于CGAN和GAN的架構區別可以參考下圖:
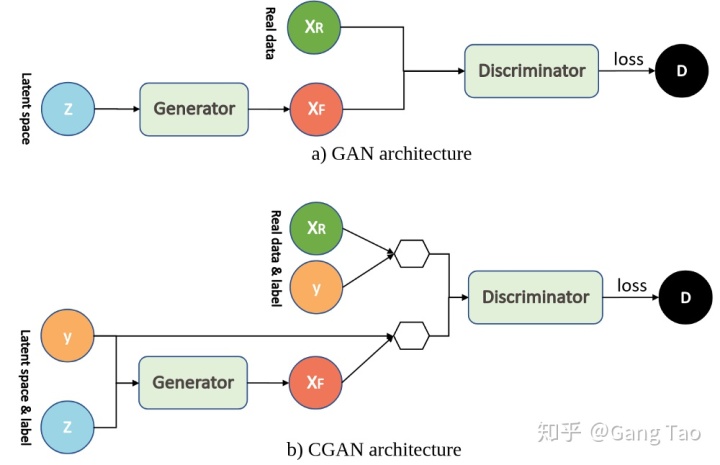
CGAN與GAN非常相似,除了生成器和鑒別器均以某些額外信息y為條件。可以通過將鑒別器和生成器作為附加輸入層輸入來執行這種調節。“ y”可以是任何種類的輔助信息,例如類別標簽或來自其他模態的數據。在本教程中,我們將類標簽用作“ y”。這里條件信息y是添加的額外條件信息,生成器G和鑒別器D都學會了以某些模式進行操作。例如,在面部生成應用程序的情況下,我們可以要求生成器生成帶有微笑的面部,并詢問鑒別器特定圖像是否包含帶有微笑的面部。
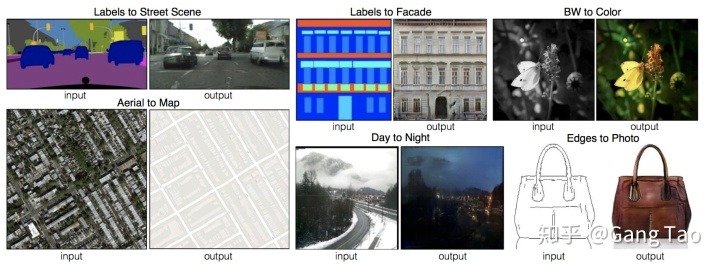
作者舉了幾個圖像到圖像翻譯的應用例子,都挺有趣的。
好了擁有了強大的工具以后,后面的事情就比較簡單了。
我利用前面提到的生成工具生成了400對bar chart的原始和手繪圖,另外分別有100對測試和驗證數據集。利用paperspace的免費GPU,運行https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix的pix2pix代碼,使用缺省的參數,訓練了200個epoch,每個epoch大概50秒,總共耗時3小時左右。
[Network G] Total number of parameters : 54.414 M
[Network D] Total number of parameters : 2.769 M缺省的網絡的參數數量如上圖所示。
訓練結果如下圖:
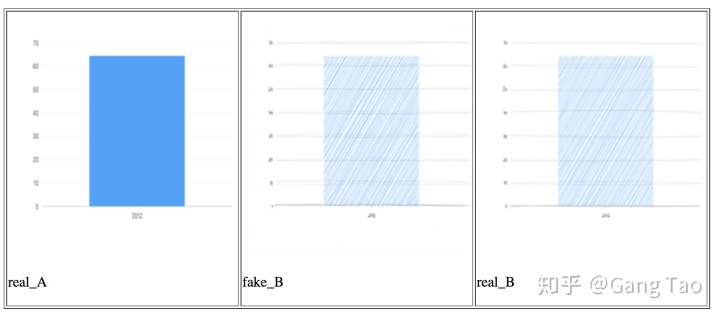
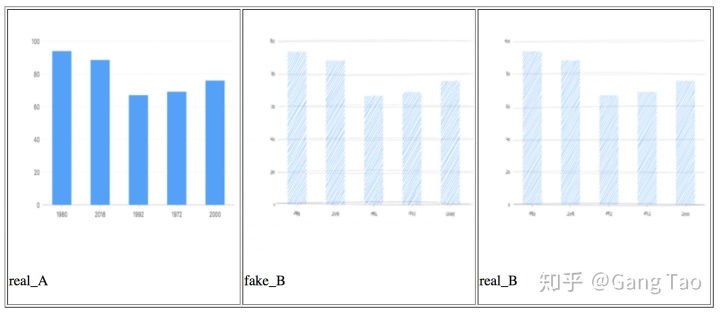
上面兩個是我的測試數據中的兩個例子。A是原始域,B是手繪域。中間的fakeB是pix2pix模型根據原始A圖生成的結果。我們看到該生成圖形幾乎可以亂真。
下一步
到這里是不是大功告成了呢?還沒有,想想我們之前要解決的問題,對于任意的基于Canvas渲染的可視化圖表,我們改如何運用該模型呢?這里我列出還需要做的工作:
- 增強數據生成功能,生成更多不同類型,數據,風格的圖數據來訓練一個更通用的模型(在本例子中,我們只有Bar Chart的缺省風格的訓練數據)
- 部署該模型為一個服務,在客戶端瀏覽器中利用JS把Canvas數據發送請求至該服務來獲得手繪風格的輸出。
- 或者利用Keras訓練該模型并利用tensorflowJs直接部署到瀏覽器,這樣做就不需要服務器端的交互,更利于集成。
總結
本文給出了一個利用深度學習實現數據可視化到手繪風格轉化的實際例子,利用機器學習或者深度學習解決一個具體的問題很有趣,但是要完成端到端的功能,需要很多很瑣碎的知識和系統思考的能力。希望這個故事對你有所幫助。有問題請發評論給我。
參考:
- 手繪風格的數據可視化實現 Sketchify
- 訓練數據生成代碼
- Pix2pix 原始論文 https://phillipi.github.io/pix2pix/
- AI從繪圖制作出精美的照片(pix2pix)
- 利用深度學習實現從圖像到圖像的翻譯
- 條件對抗網絡的圖像到圖像翻譯 Pix2Pix
- 圖像到圖像的翻譯 CycleGANS和Pix2Pix
- Pix2pix論文的Pytorch代碼 https://github.com/junyanz/pytorch-CycleGA
- 一篇關于pix2pix的介紹 https://machinelearningmastery.com/a-gentle-introduction-to-pix2pix-generative-adversarial-network/
- 另一篇關于pix2pix的介紹 https://ml4a.github.io/guides/Pix2Pix/
- 在瀏覽器中進行深度學習:TensorFlow.js (八)生成對抗網絡 (GAN)















)


)
