點擊上方“計算機視覺life”,選擇“星標”
快速獲得最新干貨
作者:?Moonsmile
https://zhuanlan.zhihu.com/p/79628068
本文已由作者授權,未經允許,不得二次轉載
三維重建意義
三維重建作為環境感知的關鍵技術之一,可用于自動駕駛、虛擬現實、運動目標監測、行為分析、安防監控和重點人群監護等。現在每個人都在研究識別,但識別只是計算機視覺的一部分。真正意義上的計算機視覺要超越識別,感知三維環境。我們活在三維空間里,要做到交互和感知,就必須將世界恢復到三維。所以,在識別的基礎上,計算機視覺下一步必須走向三維重建。本文筆者將帶大家初步了解三維重建的相關內容以及算法。
三維重建定義
在計算機視覺中, 三維重建是指根據單視圖或者多視圖的圖像重建三維信息的過程. 由于單視頻的信息不完全,因此三維重建需要利用經驗知識. 而多視圖的三維重建(類似人的雙目定位)相對比較容易, 其方法是先對攝像機進行標定, 即計算出攝像機的圖象坐標系與世界坐標系的關系.然后利用多個二維圖象中的信息重建出三維信息。
常見的三維重建表達方式
常規的3D shape representation有以下四種:深度圖(depth)、點云(point cloud)、體素(voxel)、網格(mesh)。

深度圖其每個像素值代表的是物體到相機xy平面的距離,單位為 mm。

體素是三維空間中的一個有大小的點,一個小方塊,相當于是三維空間種的像素。

點云是某個坐標系下的點的數據集。點包含了豐富的信息,包括三維坐標X,Y,Z、顏色、分類值、強度值、時間等等。在我看來點云可以將現實世界原子化,通過高精度的點云數據可以還原現實世界。萬物皆點云,獲取方式可通過三維激光掃描等。

三角網格就是全部由三角形組成的多邊形網格。多邊形和三角網格在圖形學和建模中廣泛使用,用來模擬復雜物體的表面,如建筑、車輛、人體,當然還有茶壺等。任意多邊形網格都能轉換成三角網格。
三角網格需要存儲三類信息:
頂點:每個三角形都有三個頂點,各頂點都有可能和其他三角形共享。.
邊:連接兩個頂點的邊,每個三角形有三條邊。
面:每個三角形對應一個面,我們可以用頂點或邊列表表示面。
三維重建的分類
根據采集設備是否主動發射測量信號,分為兩類:基于主動視覺理論和基于被動視覺的三維重建方法。
主動視覺三維重建方法:主要包括結構光法和激光掃描法。
被動視覺三維重建方法:被動視覺只使用攝像機采集三維場景得到其投影的二維圖像,根據圖像的紋理分布等信息恢復深度信息,進而實現三維重建。
其中,雙目視覺和多目視覺理論上可精確恢復深度信息,但實際中,受拍攝條件的影響,精度無法得到保證。單目視覺只使用單一攝像機作為采集設備,具有低成本、易部署等優點,但其存在固有的問題:單張圖像可能對應無數真實物理世界場景(病態),故使用單目視覺方法從圖像中估計深度進而實現三維重建的難度較大。
近幾年代表性論文回顧
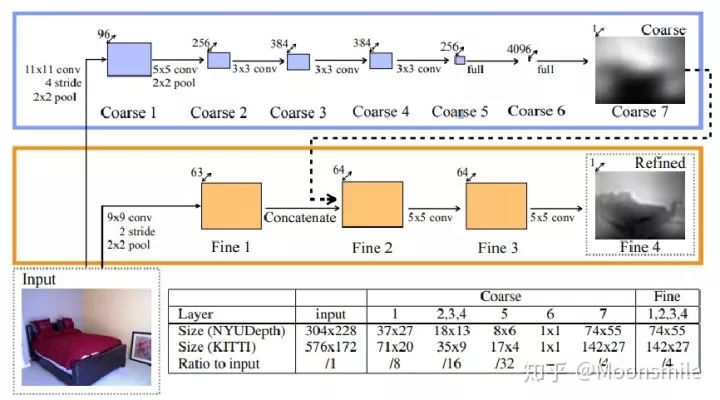
一、從單張圖像恢復深度圖

這篇論文思路很簡單,算是用深度學習做深度圖估計的開山之作,網絡分為全局粗估計和局部精估計,對深度由粗到精的估計,并且提出了一個尺度不變的損失函數。

本文總結
(1)提出了一個包含分為全局粗估計和局部精估計,可以由粗到精估計的網絡。
(2)提出了一個尺度不變的損失函數。
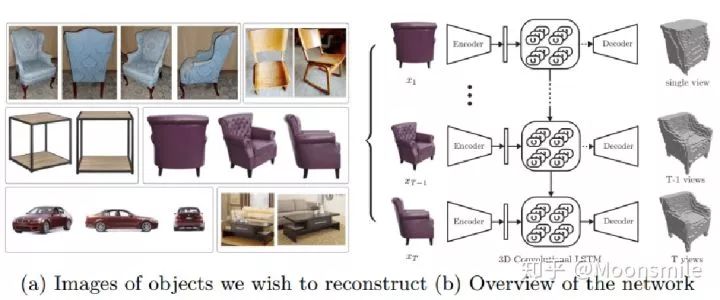
二、用體素來做單視圖或多視圖的三維重建

這篇文章挺有意思,結合了LSTM來做,如果輸入只有一張圖像,則輸入一張,輸出也一個結果。如果是多視圖的,則將多視圖看作一個序列,輸入到LSTM當中,輸出多個結果。
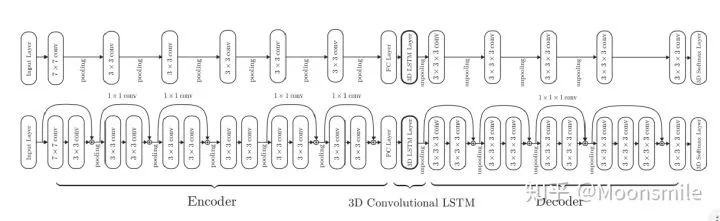
如主框架所示,這篇文章采用深度學習從2D圖像到其對應的3D voxel模型的映射: 首先利用一個標準的CNN結構對原始input image 進行編碼;再利用一個標準 Deconvolution network 對其解碼。中間用LSTM進行過渡連接, LSTM 單元排列成3D網格結構, 每個單元接收一個feature vector from Encoder and Hidden states of neighbors by convolution,并將他們輸送到Decoder中. 這樣每個LSTM單元重構output voxel的一部分。總之,通過這樣的Encoder-3DLSTM-Decoder?的網絡結構就建立了2D images -to -3D voxel model?的映射。
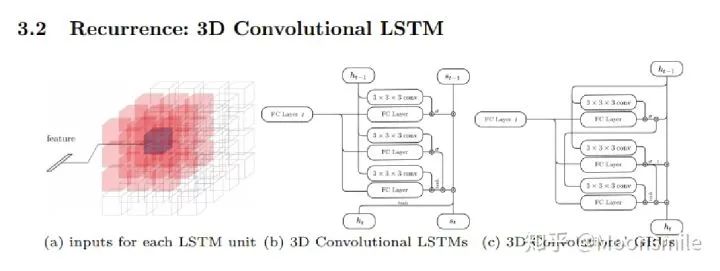
損失函數采用的是二分類的交叉熵損失,類似于在三維空間做分割,類別是兩類,分別是占有或者不占有。

除了交叉熵loss可以用作評價指標,還可以把預測結果跟標簽的IoU作為評價指標,如下圖所示:



本文總結
(1)采用深度學習從2D圖像到其對應的3D voxel模型的映射,模型設計為Encoder+3D LSTM + Decoder。
(2)既適用單視圖,也適用多視圖。
(3)以體素的表現形式做的三維重建。
(4)缺點是需要權衡體素分辨率大小(計算耗時)和精度大小。
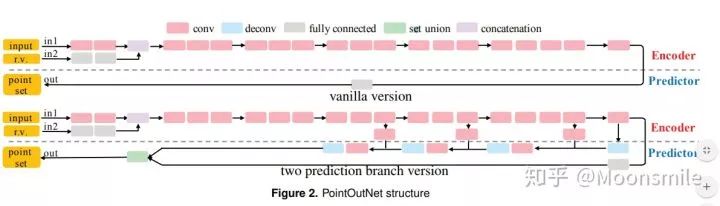
三、用點云來做單張RGB圖像的三維重建

大多數現存的工作都在使用深度網絡進行3D 數據采用體積網格或圖像集合(幾何體的2D視圖)。然而,這種表示導致采樣分辨率和凈效率之間的折衷。在這篇論文中,作者利用深度網絡通過單張圖像直接生成點云,解決了基于單個圖片對象生成3D幾何的問題。
點云是一種簡單,統一的結構,更容易學習,點云可以在幾何變換和變形時更容易操作,因為連接性不需要更新。該網絡可以由輸入圖像確定的視角推斷的3D物體中實際包含點的位置。

模型最終的目標是:給定一張單個的圖片(RGB或RGB-D),重構出完整的3D形狀,并將這個輸出通過一種無序的表示——點云(Point cloud)來實現。點云中點的個數,文中設置為1024,作者認為這個個數已經足夠表現大部分的幾何形狀。
鑒于這種非正統的網絡輸出,作者面臨的挑戰之一是如何在訓練期間構造損失函數。因為相同的幾何形狀可能在相同的近似程度上可以用不同的點云來表示,因此與通常的L2型損失不同。
本文使用的 loss
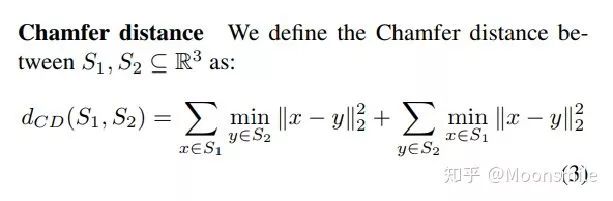

對于解決2D圖片重構后可能的形狀有很多種這個問題,作者構造了一個 Min-of-N loss (MoN) 損失函數。
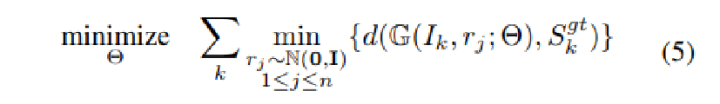
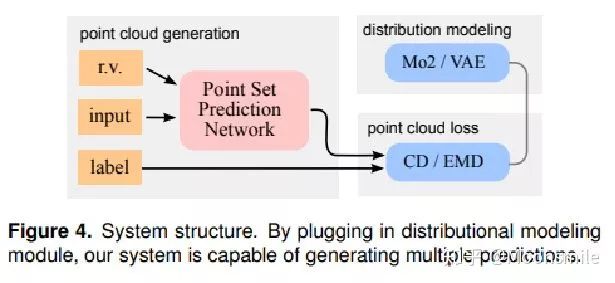
Min-of-N loss 的意思是,網絡G通過n個不同的r擾動項進行n次預測,作者認為從直覺上來看,我們會相信n次中會至少有一次預測會非常接近真正的答案,因此可以認為這n次預測與真正的答案的距離的最小值應該要最小。


本文總結
該文章的貢獻可歸納如下:
(1)開創了點云生成的先例(單圖像3D重建)。
(2)系統地探討了體系結構中的問題點生成網絡的損失函數設計。
(3)提出了一種基于單圖像任務的三維重建的原理及公式和解決方案。
總體來說,該篇文章開創了單個2D視角用點云重構3D物體的先河,是一篇值得一看的文章。
先中場休息一下,簡單先分析一下:
根據各種不同的表示方法我們可以知道volume受到分辨率和表達能力的限制,會缺乏很多細節;point cloud 的點之間沒有連接關系,會缺乏物體的表面信息。相比較而言mesh的表示方法具有輕量、形狀細節豐富的特點。

Mesh:?我不是針對誰,我是想說在座的各位都是垃圾(depth、volume、point cloud)
由于后邊的內容使用了圖卷積神經網絡(GCN),這里簡要介紹一下:

f(p,l), f(p,l+1)分別表示頂點p在卷積操作前后的特征向量;
N(p)指頂點p的鄰居節點;
W1,W2表示待學習的參數;
四、用三角網格來做單張RGB圖像的三維重建

這篇文章提出的方法不需要借助點云、深度或者其他更加信息豐富的數據,而是直接從單張彩色圖片直接得到 3D mesh。
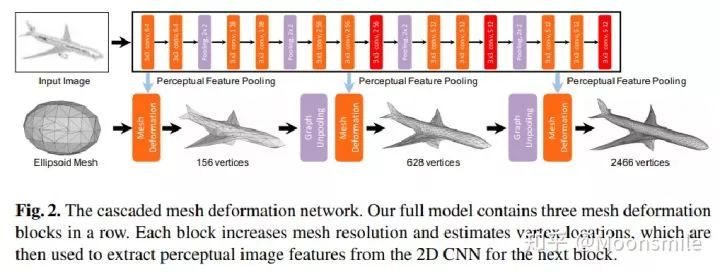
1、給定一張輸入圖像:Input image
2、為任意的輸入圖像都初始化一個橢球體作為其初始三維形狀:Ellipsoid Mesh
整個網絡可以大概分成上下兩個部分:
1、上面部分負責用全卷積神經網絡提取輸入圖像的特征;
2、下面部分負責用圖卷積神經網絡來表示三維mesh,并對三維mesh不斷進行形變,目標是得到最終的輸出(最后邊的飛機)。
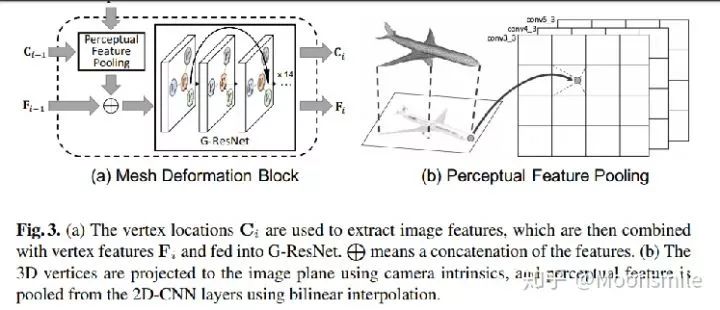
1、C表示三維頂點坐標,P表示圖像特征,F表示三維頂點特征;
2、perceptual feature pooling層負責根據三維頂點坐標C(i-1)去圖像特征P中提取對應的信息;
3、以上提取到的各個頂點特征再與上一時刻的頂點特征F(i-1)做融合,作為G-ResNet的輸入;
4、G-ResNet(graph-based ResNet)產生的輸出又做為mesh deformable block的輸出,得到新的三維坐標C(i)和三維頂點特征F(i)。
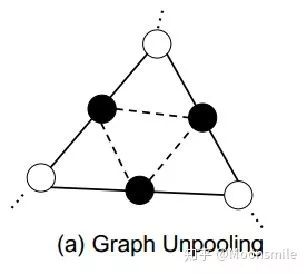
除了剛剛提到的mesh deformation,下面這部分還有一個很關鍵的組成是graph uppooling。文章提出這個圖上采樣層是為了讓圖節點依次增加,從圖中可以直接看到節點數是由156-->628-->2466變換的,這其實就是coarse-to-fine的體現,如下圖:
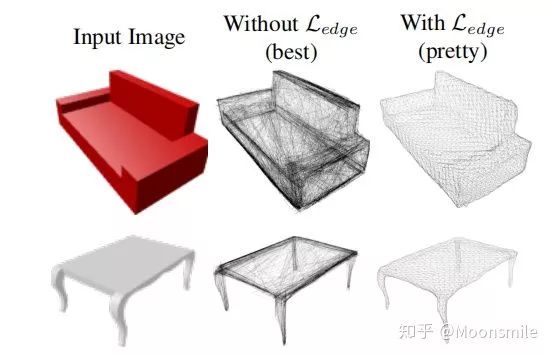
這篇文章定義了四種loss來約束網格更好的形變:


本文的實驗結果


本文總結
該文章的貢獻可歸納如下:
(1)文章實現用端到端的神經網絡實現了從單張彩色圖直接生成用mesh表示的物體三維信息;
(2)文章采用圖卷積神經網絡來表示3D mesh信息,利用從輸入圖像提到的特征逐漸對橢圓盡心變形從而產生正確的幾何形狀;
(3)為了讓整個形變的過程更加穩定,文章還采用coarse-to-fine從粗粒度到細粒度的方式;
(4)文章為生成的mesh設計了幾種不同的損失函數來讓整個模型生成的效果更加好;
文章的核心思路就是給用一個橢球作為任意物體的初始形狀,然后逐漸將這個形狀變成目標物體。
接下來介紹2019年的相關研究
由于相關內容涉及到mask-rcnn,先回顧一下:
mask-rcnn是對 faster rcnn 的擴展或者說是改進,其增加了一個用于分割的分支,并且將RoIpooling 改成了 RoIAlign。
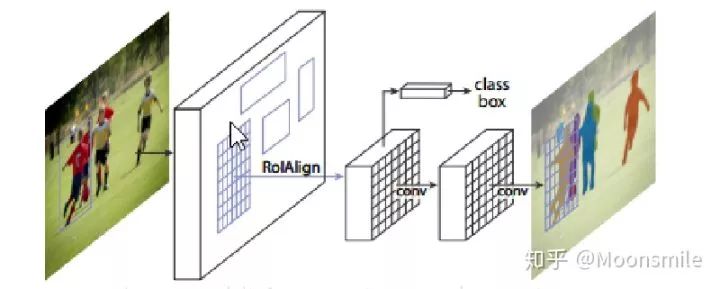
Mask RCNN可以看做是一個通用實例分割架構;。
Mask RCNN以Faster RCNN原型,增加了一個分支用于分割任務。
Mask RCNN比Faster RCNN速度慢一些,達到了5fps。
可用于人的姿態估計等其他任務;
首先介紹一篇2019年做三維重建的文章——Mesh R-CNN
這篇文章使用的正是mask rcnn 的框架,本篇文章提出了一種基于現實圖片的物體檢測系統,同時為每個檢測物體生成三角網格給出完整三維形狀。文中的系統mesh-rcnn是基于mask-rcnn的增強網絡,添加了一個網格預測分支,通過先預測轉化為物體的粗體素分布并轉化為三角形網格表示,然后通過一系列的圖卷積神經網絡改進網格的邊角輸出具有不同拓撲結構的網格。

模型目標:輸入一個圖像,檢測圖像中的所有對象,并輸出所有對象的類別標簽,邊界框、分割掩碼以及三維三角形網格。
模型主框架基于mask-rcnn,使用一個額外的網格預測器來獲得三維形狀,其中包括體素預測分支和網格細化分支。先由體素預測分支通過預選框對應的RoIAlign預測物體的粗體素分布,并將粗體素轉化為初始的三角形網格,然后網格細化分支使用作用在網格頂點上的圖卷積層調整這個初始網格的定點位置。總框架圖如下所示:
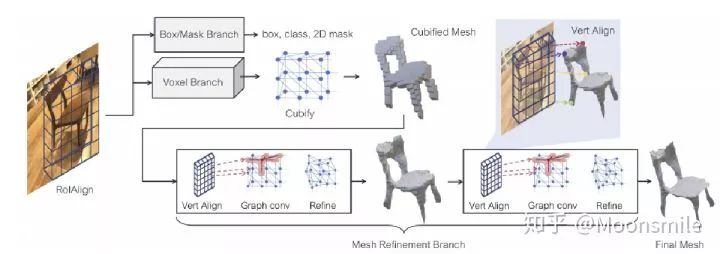
1、Box/Mask 分支:?和mask-rcnn中的兩個分支一樣
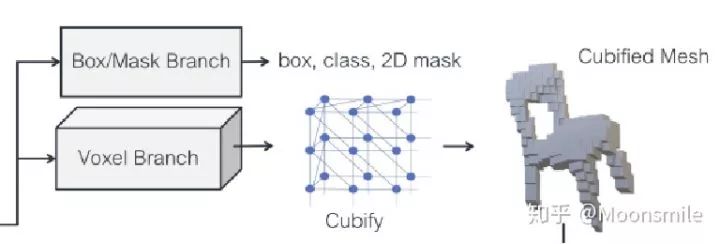
2、體素預測分支:類似于mask-rcnn中的mask分支,輸入是RoIAlign,將預選框假設位于一個分割成 G*G*G個粗體素的空間,然后預測分割出來的粗體素占用率。使用一個小的全卷積網絡來保持輸入特征和體素占用預測概率之間的對應關系。最后輸出用G個通道生成G*G的特征圖,為每個位置提供一列體素占用率分數。
3、體素占用轉化為網格表示:將體素占用概率轉化為二值化體素占用之后,將每個被占用的體素被替換為具有8個頂點、18個邊和12個面的立方體三角形網格(如上圖Cubify所示),然后合并相鄰占用體元之間的共享頂點和邊,消除共享內面就可以形成了一個拓撲結構依賴于體素預測的密集網格了。
網格細化分支
網格細化分支將初始的網格結構經過一系列精化階段(在文中作者使用了三個階段)來細化里面的頂點位置。每個精化階段都是輸入一個三角形網格),然后經過三個步驟獲得更精細的網格結構:頂點對齊(獲得頂點位置對應的圖像特征);圖卷積(沿著網格邊緣傳播信息);頂點細化(更新頂點位置)。網絡的每一層都為網格的每個頂點維護一個三維坐標以及特征向量。
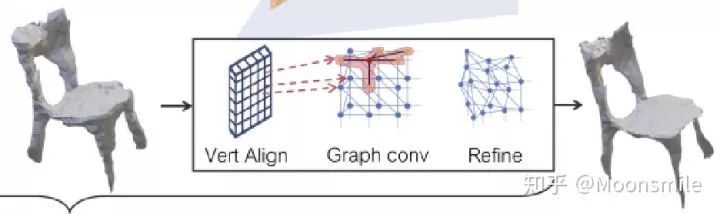
1、頂點對齊:利用攝像機的內在矩陣將每個頂點的三維坐標投影到圖像平面上。根據獲取的RoIAlign,在每個投影的頂點位置上計算一個雙線性插值圖像特征來作為對應頂點的圖像特征。
2、圖卷積:圖卷積用于沿著網格邊緣傳播頂點信息,公式定義如下:
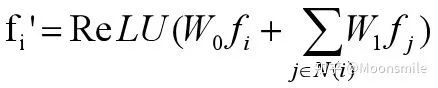
其中N(i)表示頂點i的鄰點集合,使用多個圖卷積層在局部網格區域上聚合信息。
3、頂點精化:使用2中更新后的頂點特征使用下面公式來更新頂點位置:
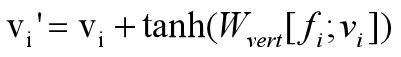
只更改頂點位置,不更改三角形平面。
模型損失函數

網格細化損失(從三個方面定義了三個損失函數)

論文實驗
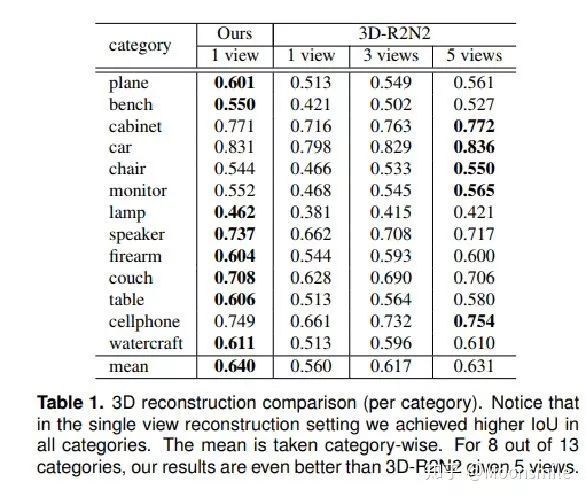
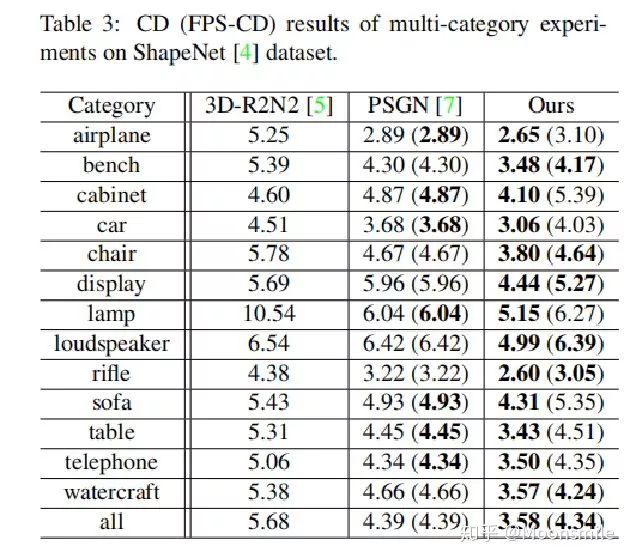
論文在兩個數據集上驗證模型:在ShapeNet數據集上對網格預測器進行了基準測試與最先進的方法進行比較并且對模型中的各個模塊進行單獨分析;在Pix3D數據集上測試完整Mesh R-Cnn模型在復雜背景下的物體三維網格預測結果。

在ShapeNet數據集:Mesh R-Cnn與其他的模型比較結果如圖下:
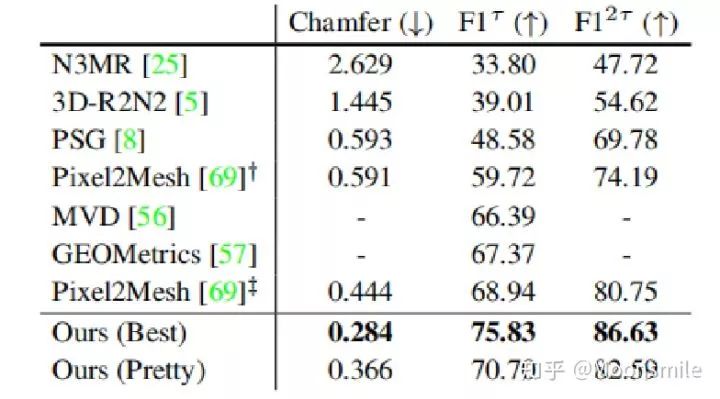
其中Ours(Best)表示去掉形狀正則化損失后的結果,在后面的實驗中可以發現,去掉形狀正則化損失后盡管在標準度量上有好的表現,但是在視覺層面上生成的網格并不如加上后的結果(Ours(Pretty))。
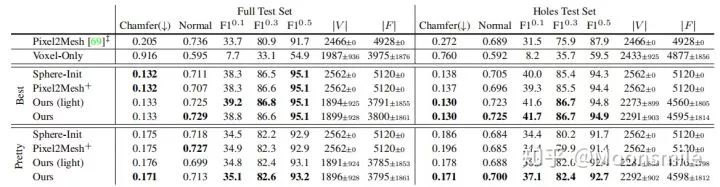
表格中比較了模型的完整版本以及不同去除模塊版本的表現,其中Full Test Set表示在完整測試集上的表現,Holes Test Set表示在打孔對象測試集中的表現;Voxel-Only表示不適用網格細化分支;Best和Perry分別表示不使用形狀正則化損失和使用形狀正則化損失;Ours(light)表示在網格細化分支中使用較輕量的非殘差架構。

Pix3D數據集


可視化結果


本文總結
該文章的貢獻可歸納如下:
(1)借鑒mask rcnn 框架;
(2)由粗到細調整的思想;
(3)使用圖卷積神經網絡;
(4)使用多種損失來約束訓練;
最后介紹一篇論文,也是CVPR 2019的文章

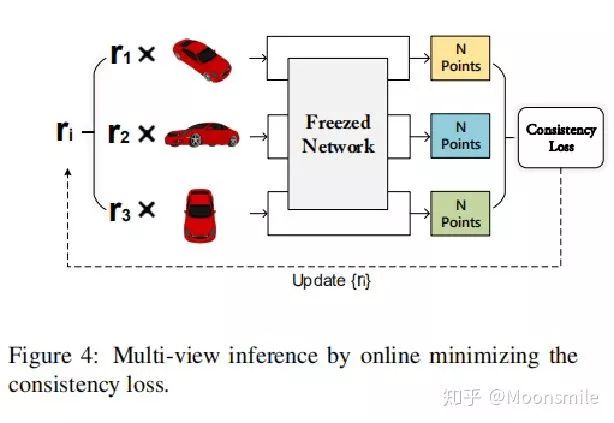
這篇文章同樣是既可以對單視圖,也可以對多視圖進行重建,只不過這篇文章的重點不在這,而在于它可以對不可見部分(不確定性)進行建模。
基本思想就是,每個輸入圖像都可以預測出多個重建結果,然后取交集就是最終結果。

下圖是主框架,左邊是訓練階段,右邊是測試階段。
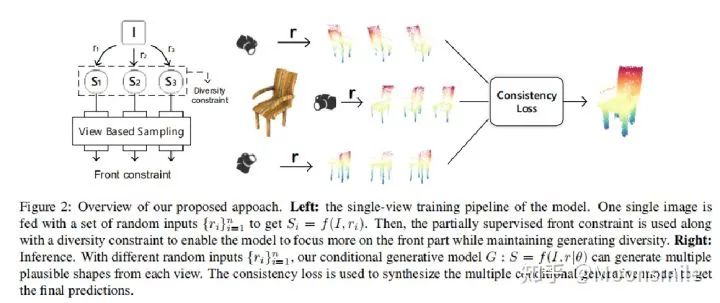
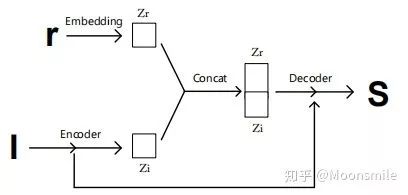
左邊訓練階段的意思是,輸入一張圖像 I,對其加入多個噪聲(r),生成多個重建結果(S)(類似于條件生成模型)。對改模型的訓練要加約束,這里提出了front constraint和diversity constraint。
右邊是測試階段,提出了一個一致性損失(consistency loss)來進行在線優化。
Distance Metric:
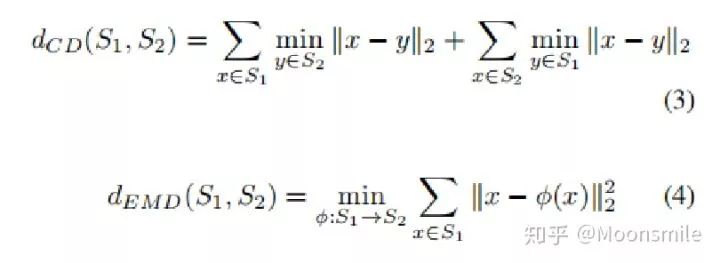
Diversity Constraint: 目的是讓條件生成器生成的重建結果更具有多樣性。
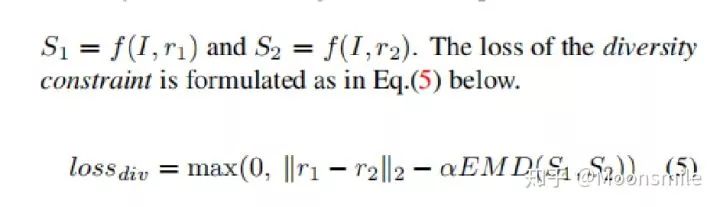
Front Constraint:?對圖像前邊部分(部分點)有監督訓練,所以這里有一個采樣過程,具體內容如下圖所示:


對于條件生成器生成的結果,用一個判別器去判斷這個形狀是否合理,公式如下:
Latent Space Discriminator(判別器是直接從WGAN-GP中拿來的)
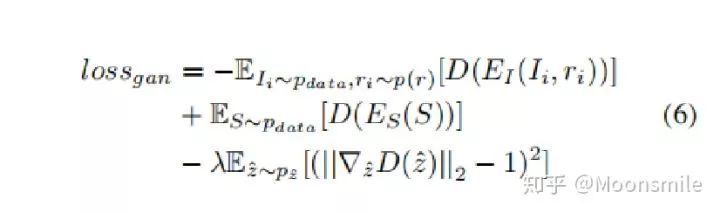
訓練總的損失:
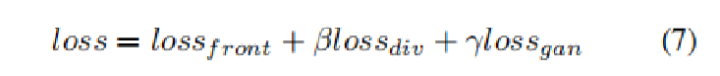
Inference (consistency constraint):
公式中Si 和 Sj 代表兩個點云集合。
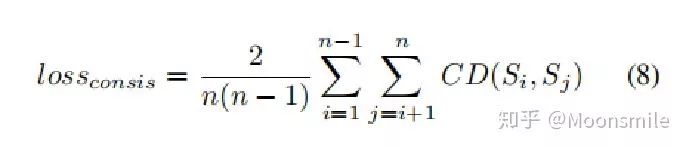
條件生成器的構:
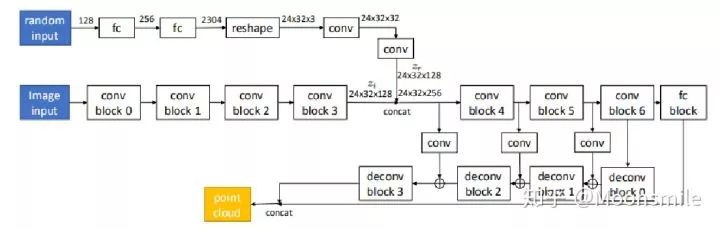
實驗結果


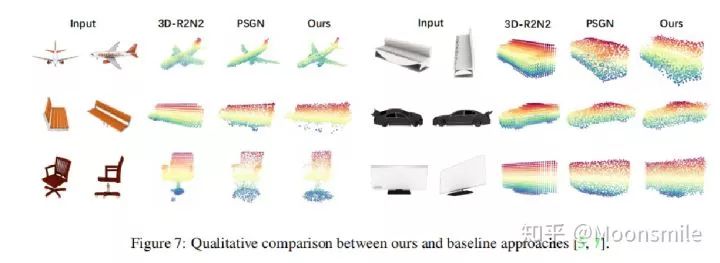

本文總結
該文章的貢獻可歸納如下:
(1)提出對不可見部分的不確定性進行建模;
(2)使用了條件生成模型;
(3)提出了三種約束;
從零開始學習三維視覺核心技術SLAM,掃描查看介紹,3天內無條件退款
 早就是優勢,學習切忌單打獨斗,這里有教程資料、練習作業、答疑解惑等,優質學習圈幫你少走彎路,快速入門!
早就是優勢,學習切忌單打獨斗,這里有教程資料、練習作業、答疑解惑等,優質學習圈幫你少走彎路,快速入門!
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、算法競賽、圖像檢測分割、三維視覺、GAN、醫學影像、計算攝影、自動駕駛、綜合等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進入相關微信群。請勿在群內發送廣告,否則會請出群,謝謝理解~

推薦閱讀
前段時間參加了個線下交流會(附SLAM入門視頻)
計算機視覺方向簡介 | 從全景圖恢復三維結構
計算機視覺方向簡介 | 陣列相機立體全景拼接
計算機視覺方向簡介 | 單目微運動生成深度圖
計算機視覺方向簡介 | 深度相機室內實時稠密三維重建
計算機視覺方向簡介 | 深度圖補全
計算機視覺方向簡介 | 人體骨骼關鍵點檢測綜述
計算機視覺方向簡介 | 人臉識別中的活體檢測算法綜述
計算機視覺方向簡介 | 目標檢測最新進展總結與展望
計算機視覺方向簡介 | 唇語識別技術
計算機視覺方向簡介 | 三維深度學習中的目標分類與語義分割
計算機視覺方向簡介 | 基于單目視覺的三維重建算法
計算機視覺方向簡介 | 用深度學習進行表格提取
計算機視覺方向簡介 |?立體匹配技術簡介
計算機視覺方向簡介 | 人臉表情識別
計算機視覺方向簡介 | 人臉顏值打分
計算機視覺方向簡介 | 深度學習自動構圖
計算機視覺方向簡介 | 基于RGB-D的3D目標檢測
計算機視覺方向簡介 | 人體姿態估計
計算機視覺方向簡介 | 三維重建技術概述
計算機視覺方向簡介 | 視覺慣性里程計(VIO)
計算機視覺方向簡介 | 多目標跟蹤算法(附源碼)
計算機視覺方向簡介 | 基于自然語言的跨模態行人re-id的SOTA方法(上)
計算機視覺方向簡介 | 圖像拼接
目標檢測技術二十年綜述
最全綜述 | 醫學圖像處理
最全綜述 | 圖像分割算法
最全綜述 | 圖像目標檢測
綜述 | 視頻分割在移動端的算法進展
綜述 | 語義分割經典網絡及輕量化模型盤點
綜述 | 機器視覺表面缺陷檢測
Graph Neural Networks 綜述
關于GANs在醫學圖像領域應用的總結
計算機視覺中,目前有哪些經典的目標跟蹤算法?
激光雷達深度補全
最新AI干貨,我在看??




使用)


源碼解析)




解析)

解析)

)

![數據挖掘技術簡介[轉]](http://pic.xiahunao.cn/數據挖掘技術簡介[轉])
)