本篇內容包括:HTTP 協議定義及其特點概述、關于 URL 定義及分類概述、Request 請求、Response 響應 以及 瀏覽器訪問一個網站的全過程 等內容…
一、HTTP 協議概述
HTTP(HyperText Transfer Protocol) 即 超文本傳輸協議,它是一種用于分布式、協作式和超媒體信息系統的應用層協議。HTTP 是萬維網(www)的數據通信的基礎。
HTTP 作為一個應用層協議,它由請求和響應兩部分構成,是一個標準的個客戶端和服務器模型,它的主要特點:支持客戶端/服務器模型、簡單快速、靈活、無連接、無狀態
1、簡單快速
客戶端向服務器發送服務請求時,只需傳路徑和請求方法。請求方法包括有 GET、POST、HEAD 等。每種方法規定了客戶端與服務器聯系的不同類型。由于 HTTP 協議簡單,使得 HTTP 服務器的程序規模小,因而通信速度很快
2、靈活
HTTP 允許傳輸任意類型的數據對象,正在傳輸的類型由 Content-Type 加以標記,最常見的 4 種 Content-Type 的取值如下:
- application/x-www-form-urlencoded(常見的 form 提交):最常見 POST 提交數據的方式。瀏覽器的原生 form 表單,如果不設置 enctype 屬性,那么最終就會以此鐘方式提交數據
- multipart/form-data(文件提交):另一種非常常見的 POST 數據提交的方式。我們在使用表單上傳文件時,必須讓 form 的 enctyped 等于這個值
- application/json(提交 json 格式的數據):現在越來越多的人把它作為請求頭,用來告訴服務端消息主體是序列化后的 JSON 字符串。由于 JSON 規范的流行,除了低版本 IE 之外的各大瀏覽器都原生支持 JSON.stringify,服務端語言也都有處理 JSON 的函數,使用 JSON 不會遇上什么麻煩
- text/xml(提交 xml 格式的數據) :XML-RPC(XML Remote Procedure Call)。它是一種使用 HTTP 作為傳輸協議,XML 作為編碼方式的遠程調用規范
3、無連接
無連接的含義是限制每次連接只處理一個請求,服務器處理完客戶端的請求,然后響應,并收到應答之后,就斷開連接,這種方式可以節省傳輸時間。
4、無狀態
HTTP 協議是無狀態協議,無狀態是指協議對于事務處理沒有記憶能力,這種方式的一個壞處就是,如果后續的處理需要用到之前的信息,則必須要重傳,這樣就導致了每次連接傳輸的數據量增大。好處就是,如果后續的連接不需要之前提供的信息,響應就會比較快。而為了解決 HTTP 的無狀態特性,出現了 Cookie 和 Session 技術.
二、關于 URL
1、URL 概述
URL(Uniform Resource Locator),即 統一資源定位器,是因特網的萬維網服務程序上用于指定信息位置的表示方法。在萬維網(www)上,每一信息資源都有統一的且在網上唯一的地址,該地址就叫 URL,它是 www 的統一資源定位標志,就是指網絡地址(就是我們俗稱的網址)。
URL 是互聯網上標準資源的地址,可以從互聯網上得到的資源的位置和訪問方法的一種簡潔的表示。互聯網上的每個文件都有一個唯一的URL,它包含的信息指出文件的位置以及瀏覽器應該怎么處理它。
2、URL 結構組成
URL由三部分組成:資源類型、存放資源的主機域名、資源文件名。也可認為由4部分組成:協議、主機、端口、路徑。
http://host[:port]/[a_path]
http://IP(主機名/域名):端口/訪問的資源路徑
- http 表示要通過 HTTP 協議來定位網絡資源;
- host 表示合法的 Internet 主機域名或者IP地址;
- port 指定一個端口號,端口號為空則使用缺省端口 80;
- a_path 指定請求資源的 URl;如果 URL 中沒有給出 a_path,那么當它作為請求 URl 時,必須以 “/” 的形式給出,通常這個工作瀏覽器自動幫我們完成。
三、Request 請求
Request 請求:
- 作用:獲取瀏覽器發送過來的數據,
- 組成部分:請求行 請求頭 請求體
- 請求格式:
請求方式 請求資源 協議/版本 - 請求例子:GET /test/row?username=root&password=1234 HTTP/1.1
1、報文頭的屬性
下面是一個請求的報文:
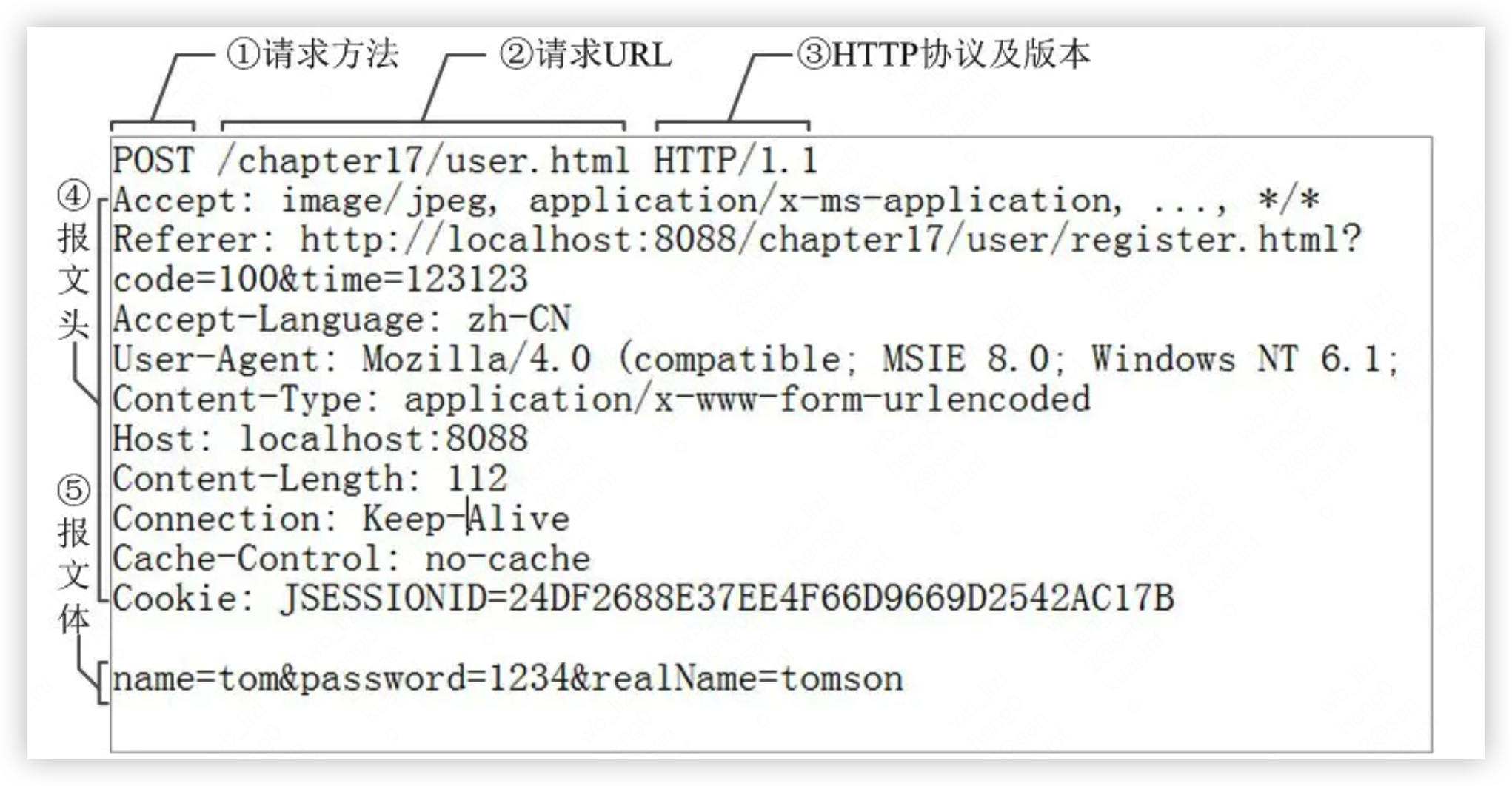
其中:
- ① 是請求方法,GET 和 POST 是最常見的 HTTP 方法,除此以外還包括 DELETE、HEAD、OPTIONS、PUT、TRACE。不過,當前的大多數瀏覽器只支持 GET 和 POST
- ② 為請求對應的 URL 地址,它和報文頭的Host屬性組成完整的請求URL,
- ③ 是協議名稱及版本號。
- ④ 是 HTTP 的報文頭,報文頭包含若干個屬性,格式為“屬性名:屬性值”,服務端據此獲取客戶端的信息。
- ⑤ 是報文體,它將一個頁面表單中的組件值通過
param1=value1¶m2=value2的鍵值對形式編碼成一個格式化串,它承載多個請求參數的數據。不但報文體可以傳遞請求參數,請求 URL也可以通過類似于/chapter15/user.html? param1=value1¶m2=value2的方式傳遞請求參數。
常見的報文頭的屬性:
| 字段 | 說明 | 示例 |
|---|---|---|
| Accept | 可接收的響應內容類型 | Accept:text/plain (文本類型) |
| Accept-Charset | 可接收的字符集 | Accept-Charset: utf-8 |
| Accept-Encoding | 可接受的響應內容的編碼方式 | Accept-Encoding: gzip, deflate |
| Accept-Language | 可接受的響應內容語言列表 | Accept-Language: en-US |
| Accept-Datetime | 可接受的按照時間來表示的響應內容版本 | Accept-Datetime: Oct, 26 Oct 2022 13:31:00 GMT |
| Authorization | HTTP協議中需要認證資源的認證信息 | Authorization: Basic OSdjJGRpbjpvcGVuIANlc2SdDE== |
| Cache-Control | 請求/回復中的,是否使用緩存機制 | Cache-Control: no-cache |
| Connection | 客戶端想要優先使用的連接類型 | Connection: keep-alive Connection: Upgrade |
| Content-Length | 以8進制表示的請求體的長度 | Content-Length: 348 |
| Content-Type | 請求體的MIME類型 | Content-Type: application/x-www-form-urlencoded |
| Date | 發送該消息的日期和時間 | Date: Oct, 26 Oct 2022 13:31:00 GMT |
| Expect | 表示客戶端要求服務器做出特定的行為 | Expect: 100-continue |
| From | 發起此請求的用戶的郵件地址 | From: user@qq.com |
| Host | 服務器域名和端口號,默認端口可省略 | Host: www.baidu.com:80 or www.baidu.com |
| If-Match | 主要用于PUT,實體匹配才可以操作 | If-Match: “9jd00cdj34pss9ejqiw39d82f20d0ikd” |
| If-Modified-Since | 資源未被修改的情況下返回304未修改 | If-Modified-Since: Dec, 26 Dec 2015 17:30:00 GMT |
| User-Agent | 瀏覽器的身份標識字符串 | User-Agent: Mozilla/ |
| … | … | … |
2、報文的方法
# GET
GET 請求是最常見的一種請求方式,當客戶端要從服務器中讀取文檔時,當點擊網頁上的鏈接或者通過在瀏覽器的地址欄輸入網址來瀏覽網頁的,使用的都是GET方式。
GET方法要求服務器將URL定位的資源放在響應報文的數據部分,回送給客戶端。GET方法請求參數和對應的值附加在URL后面,利用一個?代表URL的結尾以及附帶參數的開始,參數用key=value鍵值對的方式書寫,參數和參數之間用&符號隔開.一般GET請求的參數的大小受限,最大不超過1024.由于參數明文的顯示在了URL上面,因此不太適合傳遞私密的數據.
# POST
對于上面提到的不適合使用 GET 方式的情況,可以考慮使用 POST 方式,因為使用 POST 方法可以允許客戶端給服務器提供信息較多
POST 方法將請求參數封裝在 HTT P請求數據中,以名稱/值的形式出現,可以傳輸大量數據,這樣 POST 方式對傳送的數據大小沒有限制,而且也不會顯示在 URL 中
# GET和POST的區別
- 在參數傳遞上,GET 請求的參數是直接拼接在地址欄URL的后面,而 POST 請求的參數是放到請求體里面的
- 在長度限制上,GET 請求有具體的長度限制,即一般不超過1024KB,而 POST 理論上沒有,界限取決于瀏覽器限制
- 在安全角度上。GET 請求因為數據都是明文顯示在 URL 上面的,所以 GET 安全和私密性不如 POST
- 總的來說,GET 和 POST 都是 TCP 連接,并無實質的區別,但是由于 HTTP 瀏覽器的限定,導致它們在應用過程中體現出了一些不同,GET 產生一個數據包,POST 產生兩個數據包
- 對于 GET 請求,瀏覽器會把 header 和 data 一并發出去,服務器響應 200(返回數據).
- 對于 POST 請求,瀏覽器先發送 header,服務器響應 100 continue,瀏覽器再發送 data,服務器響應 200 ok
# HEAD
HEAD 就像 GET,只不過服務端接受到 HEAD 請求后只返回響應頭,而不會發送響應內容。當我們需要查看某個頁面的狀態的時候,使用 HEAD 是非常高效的,因為在傳輸的過程中省去了響應內容部分。
Ps1:HTTP是無狀態的面向連接的協議,無狀態不代表HTTP不能保持TCP連接,HTTP使用的不是UDP協議(無連接)
Ps2:從HTTP/1.1起,默認都開啟了Keep-Alive,保持連接特性,簡單地說,當一個網頁打開完成后,客戶端和服務器之間用于傳輸HTTP數據的TCP連接不會關閉,如果客戶端再次訪問這個服務器上的網頁,會繼續使用這一條已經建立的連接
Ps3:Keep-Alive不會永久保持連接,它有一個保持時間,可以在不同的服務器軟件(如Apache)中設定這個時間
四、Response 響應
HTTP 協議定義了 web 客戶端如何從 web 服務器請求頁面,以及服務器如何把頁面傳送給客戶端。
HTTP協議采用了 請求/響應 模型,即客戶端向服務器發送一個請求報文(請求報文包括請求的方法、url、協議版本,請求頭部和請求數據),服務器以一個響應狀態行作為響應(響應的內容包括協議的版本、成功或者錯誤代碼、服務器信息、響應頭部和響應數據)

- 作用:接收到請求之后,服務器向瀏覽器寫回數據
- 組成部分:響應行 響應頭 空行 響應體
- 響應行:
協議/版本 狀態碼 狀態碼說明
1、HTTP 響應構成
HTTP 響應是由四部分構成: 響應行 響應頭 空行 響應體
- 響應行(狀態行):由 HTTP/1.1(協議版本) 200(狀態碼) OK(狀態碼的描述) 構成
- 響應頭:由一些鍵值對構成,用來說明客戶端要使用的一些附加信息
- 空行:響應頭后面的空行時必須的
- 響應體(響應正文):服務器返回給客戶端的文本信息
2、常見響應狀態碼
- 1xx:已發送請求
- 2xx:已完成響應:200:正常響應;
- 3xx:還需瀏覽器進一步操作:302:重定向 配合響應頭:location;304:讀緩存
- 4xx:用戶操作錯誤:404:用戶操作錯誤;405:訪問的方法不存在
- 5xx:服務器錯誤:500:內部異常
五、瀏覽器訪問一個網站的全過程
當我們使用瀏覽器訪問一個網站時,其實是基于 HTTP 協議,瀏覽器作為客戶端向服務器端發送一次請求,而服務器端在接收到這次請求后,給瀏覽器反饋一個響應。下面是具體的過程:
- 當用戶訪問一個網站時,首先輸入訪問的 URL,先通過 DNS 進行域名解析,將域名解析成對應的 IP 地址
- 經過解析之后,瀏覽器會發起一個 TCP 的連接請求
- 服務器接受請求后,通過三次握手建立連接
- 客戶端在確認建立連接成功后,向服務端發送 HTTP 請求格式的數據包
- 服務器端解析 HTTP 數據包,執行用戶的這次請求并生成一個 HTTP 響應格式的數據包,發送給客戶端
- 瀏覽器在收到服務器端的數據包之后再進行解析,再通過 HTML 格式呈現給用戶
- 客戶端再通過四次握手釋放連接

(1))

















