Zookeeper 是一個高性能的分布式一致系統,在分布式系統中有著廣泛的應用。基于它,可以實現諸如“分布式同步”、“配置管理”、“命名空間管理”等眾多功能,是分布式系統中常見的基礎系統。Zookeeper 主要用來解決分布式集群中應用系統的一致性問題。
~
本篇內容包括:Zookeeper————分布式過程協同技術 以及 Zookeeper 的數據結構。
文章目錄
- 一、Zookeeper————分布式過程協同技術
- 1、什么是“分布式過程協同技術”
- 2、關于 Zookeeper
- 3、Zookeeper 特性
- 二、Zookeeper 的數據結構
- 1、ZooKeeper 數據模型的結構
- 2、ZooKeeper 數據模型與 Unix 文件系統差異
- 3、Znode 節點
- 三、zookeeper 應用場景
- 1、通知協調(數據發布與訂閱)
- 2、命名服務
- 3、分布式鎖
- 4、負載均衡
- 5、配置管理
- 6、集群管理
一、Zookeeper————分布式過程協同技術
1、什么是“分布式過程協同技術”
分布式協同技術是用來解決多進程的同步控制,使得進程有序的訪問零界資源,而這種技術的本質是分布式鎖。
Zookeeper 主要作用為在分布式系統中協調多個任務,一個任務可以是協作或者是競爭。
- 協作意味著多個進程需要一同處理某些事情,一些進程采取某些行動使得其他進程可以繼續工作,例如:在主從模式中,主節點與從節點協作,主節點分配任務給從節點;
- 競爭是指兩個進程不能同時處理工作,一個進程必須等待另一個進程,例如:同樣在主從工作模式中,通過互斥排它鎖的方式保證任何時刻只有一個主。
2、關于 Zookeeper
關于 Zookeeper 名字的由來:Zookeeper 由雅虎研究院開發,開發團隊原來想使用動物命名項目,在討論時大家覺得分布式系統就像一個動物園,胡亂且難以管理,而 Zookeeper 就是將這一切變得可控。遂起名為 Zookeeper,意為動物園管理員。
Zookeeper 是一個高性能的分布式一致系統,在分布式系統中有著廣泛的應用。基于它,可以實現諸如“分布式同步”、“配置管理”、“命名空間管理”等眾多功能,是分布式系統中常見的基礎系統。有很多我們非常熟悉的系統的基礎都是采用的 Zookeeper,比如 Apache Kafka、Apache HBase、Apache Solr…
Zookeeper 主要用來解決分布式集群中應用系統的一致性問題。
Zookeeper 維護一個類似 Unix 文件系統的數據結構,其中每個節點均可存儲少量的數據,并且都可以被監聽,可以發通知。客戶端注冊監聽它關心的目錄節點,當目錄節點發生變化(數據改變、被刪除、子目錄節點增加刪除)時,Zookeeper 會通知客戶端來執行回調機制!
Zookeeper 在設計模式的角度上來看,是基于觀察者模式的,可以把它作為一個信息的中心。使用該服務的生產者和消費者都以 Zookeeper 中的數據為基準,即 “生產者可以改變節點上的狀態和數據;消費者訂閱節點,從而能夠在節點變動時收到通知”。基于這樣的機制,將 Zookeeper 作為信息中心,便可以實現分布式系統中節點狀態的最終一致性。
3、Zookeeper 特性
ZooKeeper 特性如下:
- 最終一致性(Eventually Consistent):客戶端不論連接到哪個 Zookeeper 的哪一個節點,最終都會收到同一份狀態。這是 Zookeeper 最重要的性能;
- 順序一致性(Sequential Consistency):來自相同客戶端提交的事務,ZooKeeper 將嚴格按照其提交順序依次執行;
- 全局一致性(Single System Image):ZooKeeper 每個 Server 保存一份相同的數據副本,Clinent 無論連接那個 Server,數據都是一致的;
- 原子性(Atomicity):于 ZooKeeper 集群中提交事務,只能成功或者失敗,沒有中間狀態;
- 可靠性(Reliability):事務一旦完成,其產生的狀態變化將永久保留,直到其他事務進行覆蓋;
- 實時性(Timeliness),在一定時間范圍內,Client 能讀到最新數據
- 等待無關(wait-free):慢的或者失效的 Client 不得干預快速的 Client 的請求,使得每個 Client 都能有效的等。
二、Zookeeper 的數據結構
1、ZooKeeper 數據模型的結構
ZooKeeper 數據模型的結構與 Unix 文件系統很類似,整體上可以看作是一棵樹,每個節點稱做一個 ZNode,每個 ZNode 默認能夠存儲 1MB 的數據,每個 ZNode 都可以通過其路徑唯一標識
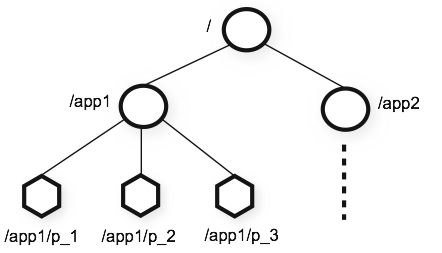
2、ZooKeeper 數據模型與 Unix 文件系統差異
ZooKeeper 數據模型在結構上和標準文件系統都是采用樹形層次結構,每個節點可以擁有子節點。但也有不同之處:
- 引用方式:Zonde 通過路徑引用,如同 Unix 中的文件路徑。路徑必須是絕對的,因此他們必須由斜杠字符來開頭。除此以外,他們必須是唯一的,也就是說每一個路徑只有一個表示,因此這些路徑不能改變。在 ZooKeeper 中,路徑由 Unicode 字符串組成,并且有一些限制。字符串 “/zookeeper” 用以保存管理信息,比如關鍵配額信息。
- 數據訪問:ZooKeeper 中的每個節點存儲的數據要被原子性的操作。也就是說讀操作將獲取與節點相關的所有數據,寫操作也將替換掉節點的所有數據。另外,每一個節點都擁有自己的ACL(訪問控制列表),這個列表規定了用戶的權限,即限定了特定用戶對目標節點可以執行的操作。
- 觀察:客戶端可以在節點上設置 watch,我們稱之為監視器。當節點狀態發生改變時(Znode 的增、刪、改)將會觸發 watch 所對應的操作。當 watch 被觸發時,ZooKeeper 將會向客戶端發送且僅發送一條通知,因為 watch 只能被觸發一次,這樣可以減少網絡流量。
3、Znode 節點
ZooKeeper 命名空間中的 Znode,兼具文件和目錄兩種特點。既像文件一樣維護著數據、元信息、ACL、時間戳等數據結構,又像目錄一樣可以作為路徑標識的一部分。圖中的每個節點稱為一個Znode。 每個 Znode 由3部分組成:
- stat:此為狀態信息, 描述該Znode的版本, 權限等信息
- data:與該Znode關聯的數據
- children:該Znode下的子節點
ZooKeeper 雖然可以關聯一些數據,但并沒有被設計為常規的數據庫或者大數據存儲,相反的是,它用來管理調度數據,比如分布式應用中的配置文件信息、狀態信息、匯集位置等等。這些數據的共同特性就是它們都是很小的數據,通常以 KB 為大小單位。ZooKeeper 的服務器和客戶端都被設計為嚴格檢查并限制每個 Znode 的數據大小至多 1M,但常規使用中應該遠小于此值。
# Znode類型
ZooKeeper 創建 ZNode 時,可以指定四種類型,節點的類型在創建時即被確定,并且不能改變:
- PERSISTENT,持久性 ZNode。創建后,即使客戶端與服務端斷開連接也不會刪除,只有客戶端主動刪除才會消失。
- PERSISTENT_SEQUENTIAL,持久性順序編號 ZNode。和持久性節點一樣不會因為斷開連接后而刪除,并且 ZNode 的編號會自動增加。
- EPHEMERAL,臨時性 ZNode。客戶端與服務端斷開連接,該 ZNode 會被刪除。
- EPEMERAL_SEQUENTIAL,臨時性順序編號 ZNode。和臨時性節點一樣,斷開連接會被刪除,并且 ZNode 的編號會自動增加。
Ps:當創建 Znode 的時候,用戶可以請求在 ZooKeeper 的路徑結尾添加一個遞增的計數。這個計數對于此節點的父節點來說是唯一的,它的格式為"%10d"(10 位數字,沒有數值的數位用 0 補充,例如"0000000001")。當計數值大于 2^32-1 時,計數器將溢出。
三、zookeeper 應用場景
1、通知協調(數據發布與訂閱)
應用配置集中到節點上,應用啟動時主動獲取,并在節點上注冊一個 watcher,每次配置更新都會通知到應用。
數據發布/訂閱(Publish/Subscribe)系統,即所謂的配置中心,顧名思義就是發布者將數據發布到 ZooKeeper 的一個或一系列節點上,供訂閱者進行數據訂閱,進而達到動態獲取數據的目的,實現配置信息的集中式管理和數據的動態更新。
2、命名服務
分布式命名服務,創建一個節點后,節點的路徑就是全局唯一的,可以作為全局名稱使用
命名服務是分步實現系統中較為常見的一類場景,分布式系統中,被命名的實體通常可以是集群中的機器、提供的服務地址或遠程對象等,通過命名服務,客戶端可以根據指定名字來獲取資源的實體、服務地址和提供者的信息。Zookeeper 也可幫助應用系統通過資源引用的方式來實現對資源的定位和使用,廣義上的命名服務的資源定位都不是真正意義上的實體資源,在分布式環境中,上層應用僅僅需要一個全局唯一的名字。Zookeeper 可以實現一套分布式全局唯一 ID 的分配機制。
3、分布式鎖
Zookeeper 能保證數據的強一致性,用戶任何時候都可以相信集群中每個節點的數據都是相同的。一個用戶創建一個節點作為鎖,另一個用戶檢測該節點,如果存在,代表別的用戶已經鎖住,如果不存在,則可以創建一個節點,代表擁有一個鎖。
4、負載均衡
通過 Zookeeper 來實現服務動態注冊、機器上線與下線的動態感知,擴容方便,容錯性好,且無中心化結構能夠解決之前使用負載均衡設備所帶來的單點故障問題。只有當配置信息更新時服務消費者才會去 Zookeeper上獲取最新的服務地址列表,其他時候使用本地緩存即可,這樣服務消費者在服務信息沒有變更時,幾乎不依賴配置中心,能大大降低配置中心的壓力。
5、配置管理
在分布式應用環境中很常見,例如同一個應用系統需要多臺節點運行,但是它們運行的應用系統的某些配置項是相同的,如果要修改這些相同的配置項,那么就必須同時修改每臺運行這個應用系統的 PC Server,這樣非常麻煩而且容易出錯。像這樣的配置信息完全可以交給 Zookeeper 來管理,將配置信息保存在 Zookeeper 的某個目錄節點中,然后將所有需要修改的應用機器監控配置信息的狀態,一旦配置信息發生變化,每臺應用機器就會收到 Zookeeper 的通知,然后從 Zookeeper 獲取新的配置信息應用到系統中。
6、集群管理
每個加入集群的機器都創建一個節點,寫入自己的狀態。監控父節點的用戶會受到通知,進行相應的處理。離開時刪除節點,監控父節點的用戶同樣會收到通知。



















