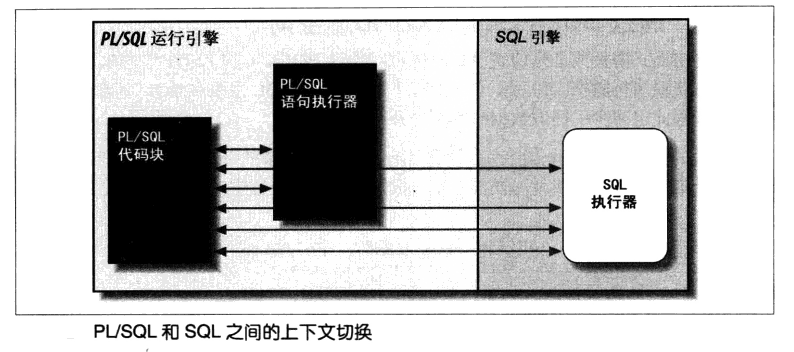
???PL/SQL程序中運行SQL語句是存在開銷的,因為SQL語句是要提交給SQL引擎處理,這種在PL/SQL引擎和SQL引擎之間的控制轉移叫做上下文卻換,每次卻換時,都有額外的開銷
???????請看下圖:
???????
???????但是,FORALL和BULK COLLECT可以讓PL/SQL引擎把多個上下文卻換壓縮成一個,這使得在PL/SQL中的要處理多行記錄的SQL語句執行的花費時間驟降
???????請再看下圖:
???????
BULK COLLECT 加速查詢
采用BULK COLLECT可以將查詢結果一次性地加載到collections中,而不是通過cursor一條一條地處理
?可以在select into ,fetch into , returning into語句使用BULK COLLECT
?注意在使用BULK COLLECT時,所有的INTO變量都必須是collections
select into語句中使用bulk collect
DECLARE TYPE sallist IS TABLE OF employees.salary%TYPE;sals sallist;
BEGINSELECT salary BULK COLLECT INTO sals FROM employees where rownum<=50;--接下來使用集合中的數據
END;
/在fetch into中使用bulk collect
DECLARETYPE deptrectab IS TABLE OF departments%ROWTYPE;dept_recs deptrectab;CURSOR cur IS SELECT department_id,department_name FROM departments where department_id>10;
BEGINOPEN cur;FETCH cur BULK COLLECT INTO dept_recs;--接下來使用集合中的數據
END;
/returning into中使用bulk collect
CREATE TABLE emp AS SELECT * FROM employees;DECLARE TYPE numlist IS TABLE OF employees.employee_id%TYPE;enums numlist;TYPE namelist IS TABLE OF employees.last_name%TYPE;names namelist;
BEGINDELETE emp WHERE department_id=30RETURNING employee_id,last_name BULK COLLECT INTO enums,names;DBMS_OUTPUT.PUT_LINE('deleted'||SQL%ROWCOUNT||'rows:');FOR i IN enums.FIRST .. enums.LASTLOOPDBMS_OUTPUT.PUT_LINE('employee#'||enums(i)||':'||names(i));END LOOP;
END;
/deleted6rows:
employee#114:Raphaely
employee#115:Khoo
employee#116:Baida
employee#117:Tobias
employee#118:Himuro
employee#119:Colmenares?BULK COLLECT 對大數據DELETE UPDATE的優化
DECLARE
--按rowid排序的cursor
--刪除條件是oo=xx,這個需根據實際情況來定CURSOR mycursor IS SELECT rowid FROM t WHERE OO=XX ORDER BY rowid;TYPE rowid_table_type IS TABLE OF rowid index by pls_integer;v_rowid rowid_table_type;
BEGINOPEN mycursor;LOOPFETCH mycursor BULK COLLECT INTO v_rowid LIMIT 5000;--5000行提交一次EXIT WHEN v_rowid.count=0;FORALL i IN v_rowid.FIRST..v_rowid.LASTDELETE t WHERE rowid=v_rowid(i);COMMIT;END LOOP;CLOSE mycursor;
END;
/限制BULK COLLECT 提取的記錄數
語法:
?????????????FETCH cursor BULK COLLECT INTO ...[LIMIT rows];
?????????????其中,rows可以是常量,變量或者求值的結果是整數的表達式
?????????????
?????????????假設你需要查詢并處理1W行數據,你可以用BULK COLLECT一次取出所有行,然后填充到一個非常大的集合中
?????????????可是,這種方法會消耗該會話的大量PGA,APP可能會因為PGA換頁而導致性能下降
?????????????
?????????????這時,LIMIT子句就非常有用,它可以幫助我們控制程序用多大內存來處理數據
?
DECLARECURSOR allrows_cur IS SELECT * FROM employees;TYPE employee_aat IS TABLE OF allrows_cur%ROWTYPE INDEX BY BINARY_INTEGER;v_emp employee_aat;
BEGINOPEN allrows_cur;LOOPFETCH allrows_cur BULK FETCH INTO v_emp LIMIT 100;/*通過掃描集合對數據進行處理*/FOR i IN 1 .. v_emp.countLOOPupgrade_employee_status(v_emp(i).employee_id);END LOOP;EXIT WHEN allrows_cur%NOTFOUND;END LOOP;CLOSE allrows_cur;
END;
/?FORALL注意事項
使用FORALL時,應該遵循如下規則:
- FORALL語句的執行體,必須是一個單獨的DML語句,比如INSERT,UPDATE或DELETE。
- 不要顯式定義index_row,它被PL/SQL引擎隱式定義為PLS_INTEGER類型,并且它的作用域也僅僅是FORALL。
- 這個DML語句必須與一個集合的元素相關,并且使用FORALL中的index_row來索引。注意不要因為index_row導致集合下標越界。
- lower_bound和upper_bound之間是按照步進 1 來遞增的。
- 在sql_statement中,不能單獨地引用集合中的元素,只能批量地使用集合。
- 在sql_statement中使用的集合,下標不能使用表達式。
BULK COLLECT介紹
BULK COLLECT子句會批量檢索結果,即一次性將結果集綁定到一個集合變量中,并從SQL引擎發送到PL/SQL引擎。
通常可以在SELECT INTO、FETCH INTO以及RETURNING INTO子句中使用BULK COLLECT。下面逐一描述BULK COLLECT在這幾種情形下的用法
BULK COLLECT的注意事項
- BULK COLLECT INTO 的目標對象必須是集合類型。
- 只能在服務器端的程序中使用BULK COLLECT,如果在客戶端使用,就會產生一個不支持這個特性的錯誤。
- 不能對使用字符串類型作鍵的關聯數組使用BULK COLLECT子句。
- 復合目標(如對象類型)不能在RETURNING INTO子句中使用。
- 如果有多個隱式的數據類型轉換的情況存在,多重復合目標就不能在BULK COLLECT INTO子句中使用。
- 如果有一個隱式的數據類型轉換,復合目標的集合(如對象類型集合)就不能用于BULK COLLECTINTO子句中
DECLARE
CURSOR cur IS
select * from NEWLOG4 t where TO_CHAR(t.autudt,'YYYY-MM-DD') = '2021-03-09'and pushstate='3';
TYPE rec IS TABLE OF NEWLOG4%ROWTYPE;
recs rec;
BEGIN
OPEN cur;
WHILE (TRUE) LOOP
FETCH cur BULK COLLECT
INTO recs LIMIT 5000;
FORALL i IN 1 .. recs.COUNT
INSERT INTO NEWLOG4_202103 VALUES recs (i);COMMIT;EXIT WHEN cur%NOTFOUND;END LOOP;CLOSE cur;END;INSERT/*+parallel(10)*/ INTO NEWLOG4_202103 select * from NEWLOG4 t where TO_CHAR(t.autudt,'YYYY-MM-DD') = '2021-03-09'and pushstate='3';delete /*+parallel(10)*/ from NEWLOG4 nologging where TO_CHAR(autudt,'YYYY-MM-DD') = '2021-03-09'and pushstate='3';INSERT/*+parallel(10)*/ INTO NEWLOG4_202103 select * from NEWLOG4 t where TO_CHAR(t.autudt,'YYYY-MM-DD') = '2021-03-09'and pushstate='3';alter session enable parallel dml; DECLARE
CURSOR cur IS
select/*+parallel(8)*/ rowid from NEWLOG4 t where TO_CHAR(t.autudt,'YYYY-MM-DD') = '2021-03-03'and pushstate='3';
--TYPE rec IS TABLE OF NEWLOG4%ROWTYPE;
TYPE rowid_table_type IS TABLE OF rowid index by pls_integer;v_rowid rowid_table_type;
--recs rec;
BEGIN
OPEN cur;
WHILE (TRUE) LOOP
FETCH cur BULK COLLECT
INTO v_rowid LIMIT 1000;
EXIT WHEN v_rowid.count=0;
FORALL i IN 1 .. v_rowid.COUNT
---delete NEWLOG4 where current of recs (i);
delete/*+parallel(8)*/ from NEWLOG4 nologging where rowid=v_rowid (i);COMMIT;EXIT WHEN cur%NOTFOUND;END LOOP;CLOSE cur;END;DECLARE
v_exists NUMBER (10, 0);
v_exists1 NUMBER (10, 0);
--recs rec;
BEGIN
select /*+parallel(12)*/ count(1)into v_exists from NEWLOG4 t where TO_CHAR(t.autudt,'YYYY-MM-dd') = '2021-03-06'and pushstate='3';
WHILE (TRUE) LOOPdelete /*+parallel(12)*/ from NEWLOG4 nologging where TO_CHAR(autudt,'YYYY-MM-DD') = '2021-03-06'and pushstate='3';EXIT WHEN v_exists1=v_exists+1;v_exists1:= v_exists1+1;if (v_exists=10000) thenCOMMIT;end if;END LOOP;COMMIT;END;select count(1) from NEWLOG4 t where TO_CHAR(t.autudt,'YYYY-MM-DD') = '2021-03-01'
select b.sid, b.username, b.serial#, a.spid, b.paddr, c.sql_text, b.machinefrom v$process a, v$session b, v$sqlarea cwhere a.addr = b.paddrand b.sql_hash_value = c.hash_value;CREATE OR REPLACE PROCEDURE NEWLOG4_SUB_TABLE2 (delete_date in varchar2)
IS-- table_name1 VARCHAR2(50);-- create_table_sql VARCHAR2(4000);
-- insert_data_sql VARCHAR2(4000);delete_data_sql VARCHAR2(4000);
-- v_exists INT:=0;-- v_exists NUMBER (10, 0);CURSOR cur IS
select * from NEWLOG4 t where TO_CHAR(t.autudt,'YYYY-MM-DD') = delete_date and pushstate='3';
TYPE rec IS TABLE OF NEWLOG4%ROWTYPE;
recs rec;
BEGIN--將FATHER_TABLE表中取上月記錄 添加到新創建的分表中。-- insert_data_sql := 'INSERT INTO ' || table_name1 || ' SELECT * FROM NEWLOG4 WHERE autudt <(systimestamp - NUMTODSINTERVAL(30,''day'')) and pushstate=''3''';-- EXECUTE IMMEDIATE insert_data_sql;
OPEN cur;
WHILE (TRUE) LOOP
FETCH cur BULK COLLECT
INTO recs LIMIT 5000;
FORALL i IN 1 .. recs.COUNT
INSERT INTO NEWLOG4_202103_10 VALUES recs (i);COMMIT;EXIT WHEN cur%NOTFOUND;END LOOP;CLOSE cur;--刪除FATHER_TABLE表中時間在上個月范圍內的所有數據--delete_data_sql := 'DELETE FROM NEWLOG4 WHERE autudt <(systimestamp-NUMTODSINTERVAL(30,''day''))and pushstate=''3''';delete_data_sql :='delete /*+parallel(10)*/ from NEWLOG4 nologging where TO_CHAR(t.autudt,''YYYY-MM-DD'') = delete_date and pushstate=''3''';EXECUTE IMMEDIATE delete_data_sql;COMMIT;--EXCEPTION--WHEN OTHERS THEN-- ROLLBACK;
END NEWLOG4_SUB_TABLE2;
CREATE OR REPLACE PROCEDURE NEWLOG4_SUB_TABLE
IStable_name1 VARCHAR2(50);create_table_sql VARCHAR2(4000);insert_data_sql VARCHAR2(4000);delete_data_sql VARCHAR2(4000);
-- v_exists INT:=0;v_exists NUMBER (10, 0);
BEGINSELECT 'NEWLOG4_' || TO_CHAR(ADD_MONTHS(SYSDATE, -1), 'YYYYMM') INTO table_name1 FROM DUAL;select count(1) into v_exists from user_tables where table_name=UPPER(table_name1);--dbms_output.put_line(sname);--dbms_output.put_line(table_name1);if (v_exists <1)then-- dbms_output.put_line(sname);create_table_sql := 'create table ' || table_name1 || ' (autudt TIMESTAMP(6),authentype VARCHAR2(2000),userid VARCHAR2(2000),orgid VARCHAR2(2000),org2id VARCHAR2(2000),realname VARCHAR2(2000),success VARCHAR2(2000),idpname VARCHAR2(2000),idpip VARCHAR2(2000),vistorip VARCHAR2(2000),vistorbrowser VARCHAR2(2000),spid VARCHAR2(2000),spurl VARCHAR2(2000),info VARCHAR2(2000),autdesc VARCHAR2(2000),taketime VARCHAR2(2000),orgnamefullpath VARCHAR2(2000),ines INTEGER default 0,logid VARCHAR2(32),inputaccount VARCHAR2(2000),channel NUMBER(32),pushstate NUMBER(2) default 0,appid VARCHAR2(50))';EXECUTE IMMEDIATE create_table_sql;commit;end if;--將FATHER_TABLE表中取上月記錄 添加到新創建的分表中。insert_data_sql := 'INSERT INTO ' || table_name1 || ' SELECT * FROM NEWLOG4 WHERE autudt <(systimestamp - NUMTODSINTERVAL(30,''day'')) and pushstate=''3''';EXECUTE IMMEDIATE insert_data_sql;--刪除FATHER_TABLE表中時間在上個月范圍內的所有數據delete_data_sql := 'DELETE FROM NEWLOG4 WHERE autudt <(systimestamp-NUMTODSINTERVAL(30,''day''))and pushstate=''3''';EXECUTE IMMEDIATE delete_data_sql;COMMIT;--EXCEPTION--WHEN OTHERS THEN-- ROLLBACK;
END NEWLOG4_SUB_TABLE;
CREATE OR REPLACE PROCEDURE NEWLOG4_day_TABLE (delete_date in varchar2)
ISinsert_data_sql VARCHAR2(4000);delete_data_sql VARCHAR2(4000);CURSOR cur IS
select * from NEWLOG4 t where TO_CHAR(t.autudt,'YYYY-MM-DD') = delete_date and pushstate='3';
TYPE rec IS TABLE OF NEWLOG4%ROWTYPE;
recs rec;
BEGIN
OPEN cur;
WHILE (TRUE) LOOP
FETCH cur BULK COLLECT
INTO recs LIMIT 5000;
FORALL i IN 1 .. recs.COUNT
--EXECUTE IMMEDIATE insert_data_sql;
INSERT INTO NEWLOG4_DAY_INTERVAL_PARTITION VALUES recs (i);COMMIT;EXIT WHEN cur%NOTFOUND;END LOOP;CLOSE cur;--EXCEPTION--WHEN OTHERS THEN-- ROLLBACK;
END NEWLOG4_day_TABLE;
?
?
?
?
?
?

)






學習總結及部署記錄(主從復制、讀寫分離、主從切換))




)





