
??各位小伙伴們大家好,歡迎來到這個小扎扎的Redis 6專欄,在這個系列專欄中我對B站尚硅谷的Redis教程進行一個總結,鑒于 看到就是學到、學到就是賺到 精神,這波依然是血賺 ┗|`O′|┛
💡Redis知識點速覽
- 🍖 五大數據類型——列表(List)
- 🥩 List的底層數據結構
- 🥩 列表常用命令
- 🍖 五大數據類型——集合(Set)
- 🥩 Set的底層數據結構
- 🥩 集合常用命令
- 🍖 五大數據類型——哈希(Hash)
- 🥩 Hash的底層數據結構
- 🥩 哈希常用命令
- 🍖 五大數據類型——有序集合(Zset)
- 🥩 Zset的底層數據結構
- 🥩 有序集合常用命令
🍖 五大數據類型——列表(List)
??首先應該明確的一點就是,Redis中的五大數據結構是對value的概念,而不是指key的數據類型。Redis中的列表是一個簡單的字符串列表,按照插入的順序進行存儲并非是一個無序列表。List的底層實際上是一個雙向鏈表,所以你可以快速的向鏈表頭部或者尾添加元素,但是如果操作鏈表中間的元素的話性能就會很差
🥩 List的底層數據結構
??List的數據結構為快速鏈表quickList,那么有的小伙伴可能會有疑問了,你之前不是說過List的底層是一個雙向鏈表嗎,怎么又成快速鏈表了?實際上快速鏈表和雙向鏈表的概念并不沖突。
什么是快速鏈表?
??快速鏈表是Redis3.2之后引入的一種數據類型, 該結構是將許多的壓縮鏈表采用雙向鏈表的形式連接起來的一種結構, 這種鏈表中的每一個節點是一個壓縮鏈表. 這樣的設計能在時間效率和空間效率上實現較好的折中 ??在列表數據比較少的時候只使用一塊連續的內存存儲,這個結構就是壓縮鏈表(ziplist),當數據比較多的時候就,就使用很多個壓縮鏈表進行存儲,每個壓縮鏈表又作為一個節點采用雙向鏈表的形式連接起來,這就形成了一個快速鏈表
??在列表數據比較少的時候只使用一塊連續的內存存儲,這個結構就是壓縮鏈表(ziplist),當數據比較多的時候就,就使用很多個壓縮鏈表進行存儲,每個壓縮鏈表又作為一個節點采用雙向鏈表的形式連接起來,這就形成了一個快速鏈表
🥩 列表常用命令
左插或者右插的方式創建K-V:
??lpush / rpush K V V V … lpush相當于雙向鏈表的頭插法,rpush相當于雙向鏈表的尾插法,關于這兩種方法的詳細介紹參考下面這篇博客:https://blog.csdn.net/jankin6/article/details/80954203
獲取key對應List索引范圍內的value:
?? 從左向右lrange key from to
從左邊或者右邊刪除一個值并返回:
??lpop / rpop key  從第一個List的右邊刪除一個值插到第二個List的左邊:
從第一個List的右邊刪除一個值插到第二個List的左邊:
??rpoplpush K K  獲取key對應List的索引位置元素:
獲取key對應List的索引位置元素:
??lindex key index
獲取key對應List的長度:
??llen key
在key對應List的某個元素之前插入元素:
??linsert key before ele newele
在key對應List的某個元素之后插入元素:
??linsert key after ele newele  在key對應List的某個元素之后插入元素:
在key對應List的某個元素之后插入元素:
??linsert key after ele newele 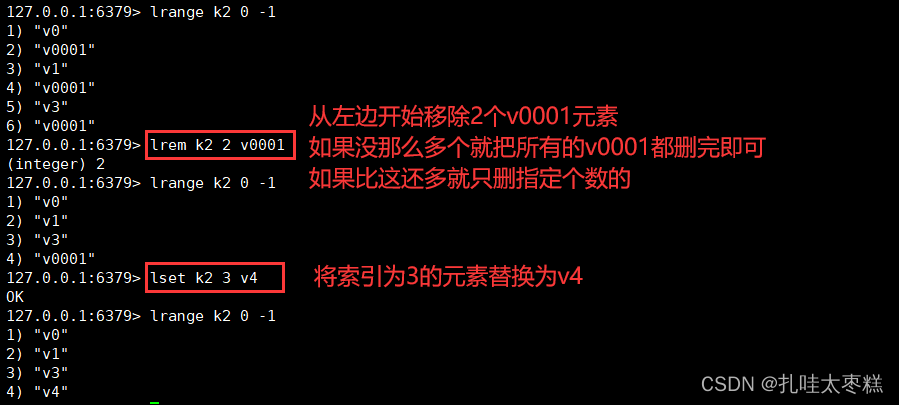
🍖 五大數據類型——集合(Set)
??Set集合的功能實際上與List列表很是類似,與List不同的就是集合內部的元素是無序不重復的,他可以對添加的元素實現自動去重功能,如果你想存儲一個列表數據但是又不想出現重復數據,還不在乎數據的存儲順序的話,可以是使用set集合實現。set集合的底層實際上就是一個value值為null的hash表,所以它查找數據的速度很快
🥩 Set的底層數據結構
??Set的底層數據結構就是一個字典,只不過字典的實現方式是哈希表(hashtable),hashtable就是普通的哈希表(key為set的值,value為null)
🥩 集合常用命令
創建一個K-V:sadd K V V V…
查看key對應的value集合:smembers key 判斷集合中是否有該元素:sismember key value
判斷集合中是否有該元素:sismember key value
key對應的value集合長度:scard key
刪除集合中的元素:srem K V V V… 隨機刪除集合中元素并返回:spop key
隨機刪除集合中元素并返回:spop key
隨機取出集合中指定個元素:srandmember key num 將集合的元素移動到另一個集合:smove K K V
將集合的元素移動到另一個集合:smove K K V
兩個集合的交集:sinter K K
兩個集合的并集:sunion K K
兩個集合的差集:sdiff K K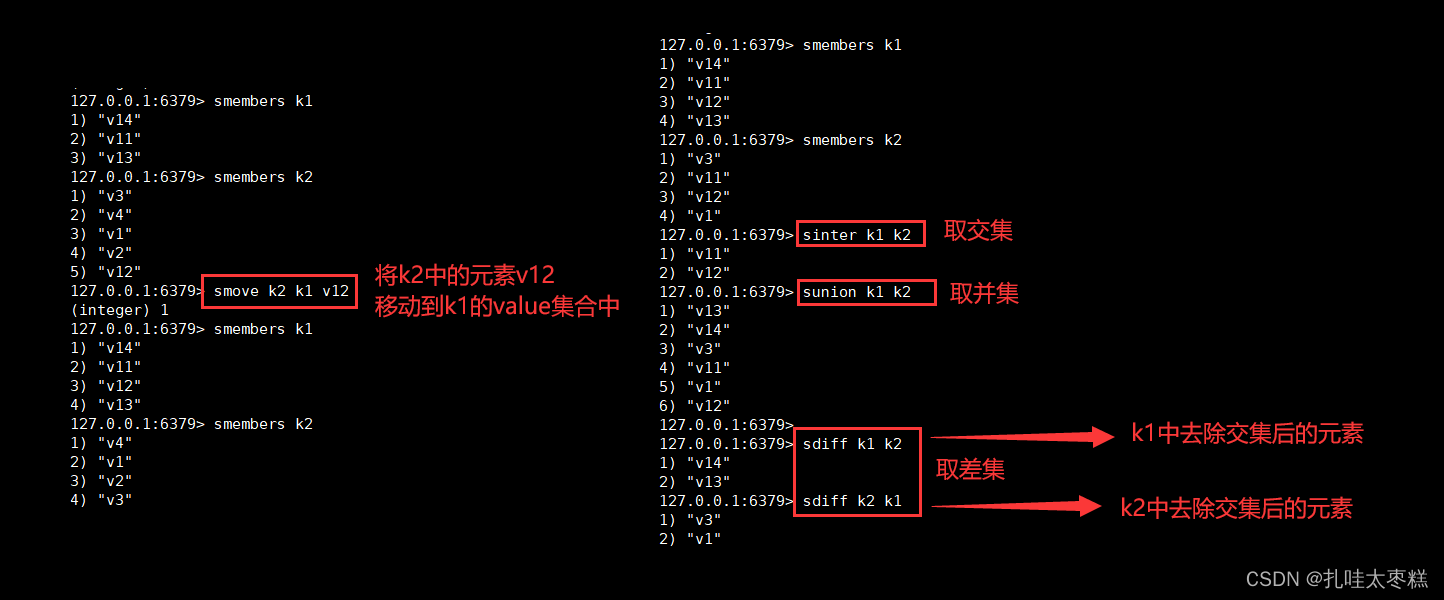
🍖 五大數據類型——哈希(Hash)
??Redis中的Hash實際上就是一個鍵值對的集合,Hash也是針對K-V中value的概念,就是value中存儲了一個String類型的field和value的映射表,十分類似于Java中Map集合元素存儲的映射關系,下面以Hash中的一個K-V為例畫圖幫助理解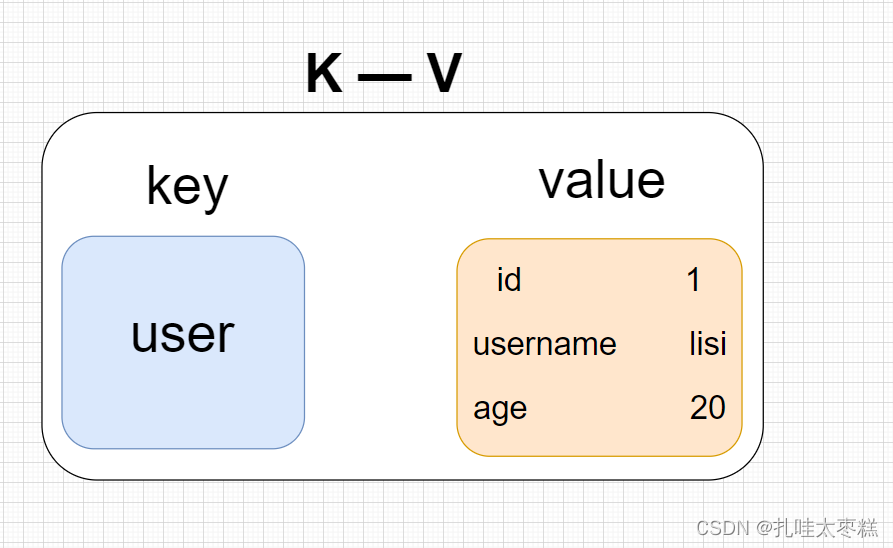
🥩 Hash的底層數據結構
??Hash類型對應的數據結構是兩種:ziplist(壓縮列表),hashtable(哈希表)。當field-value長度較短且個數較少時,使用ziplist,否則使用hashtable。
🥩 哈希常用命令
添加K-V數據: hset K field value field value…
添加K-V數據: hmset K field value field value…
查看K對應的V中field的值: hget K field
判斷K對應的V中field是否存在: hexistst K field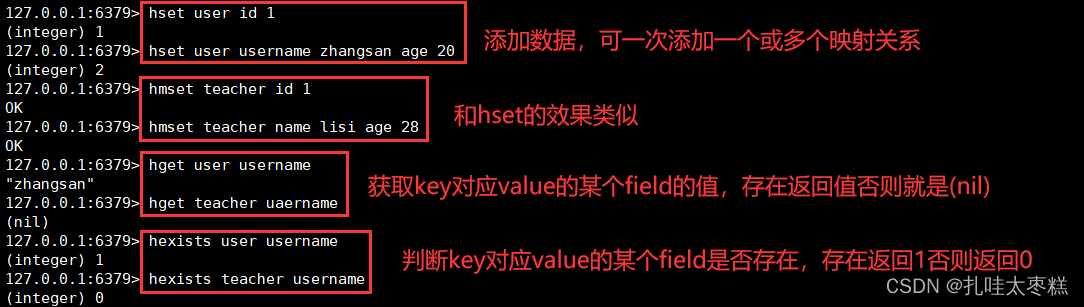 獲取K對應的V中所有的field: hkeys K
獲取K對應的V中所有的field: hkeys K
獲取K對應的V中所有的field的值: hvals K
K對應的V中的field的值加幾: hincrby K field num
添加一個映射關系存在則失敗: hsetnx K field value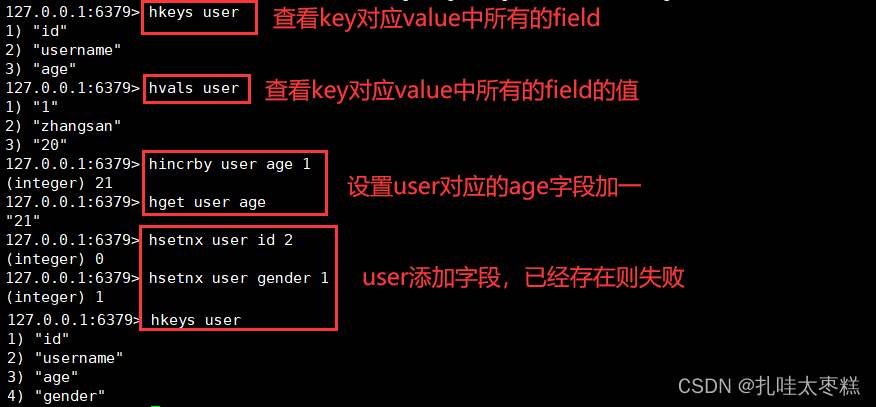
🍖 五大數據類型——有序集合(Zset)
??有序集合zset與普通集合set非常相似,是一個沒有重復元素的字符串集合。
不同之處是有序集合的每個成員都關聯了一個評分(score),結合會按照這個評分(score)從低最高排序集合中的成員。集合的成員是唯一的,但是評分可以重復。
??因為元素是有序的, 所以你也可以很快的根據評分(score)或者次序(position)來獲取一個范圍的元素。訪問有序集合的中間元素也是非常快的,因此你能夠使用有序集合作為一個沒有重復成員的智能列表。
🥩 Zset的底層數據結構
??SortedSet(zset)底層使用了兩個數據結構:使用hash關聯元素value和權重score,保障元素value的唯一性,可以通過元素value找到相應的score值。還用跳躍表給元素value排序,根據score的范圍獲取元素列表
什么是跳躍表(skiplist)?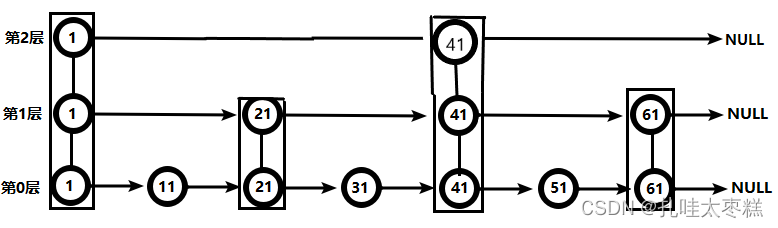 跳躍表就是每往上一層就跳一個元素組成鏈表,跳躍表都是從最高層開始查找,比如說查找51的過程大致如下:
跳躍表就是每往上一層就跳一個元素組成鏈表,跳躍表都是從最高層開始查找,比如說查找51的過程大致如下:
- 從第2層開始,1節點比51節點小,向后比較到41節點比51節點小,繼續向后比較,后面就是NULL了,所以從41節點向下到第1層
- 在第1層,41節點比51節點小,繼續向后,61節點比51節點大,所以返回從41向下到第0層
- 第0層中,41節點比51節點小,繼續向后到要查找的51節點
共經歷查找4次,流程如下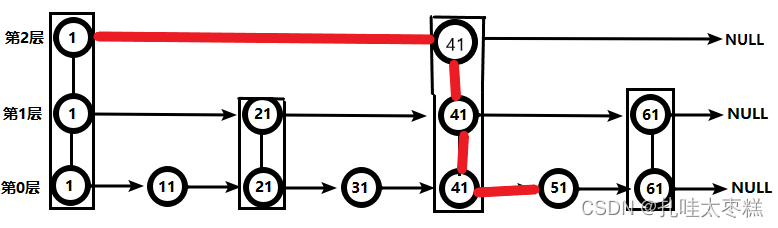
🥩 有序集合常用命令
添加K-V數據(帶上評分): zadd K score value score value…
查看K-V數據: zrange K from to
查看K-V數據(帶上評分): zrange K from to withscores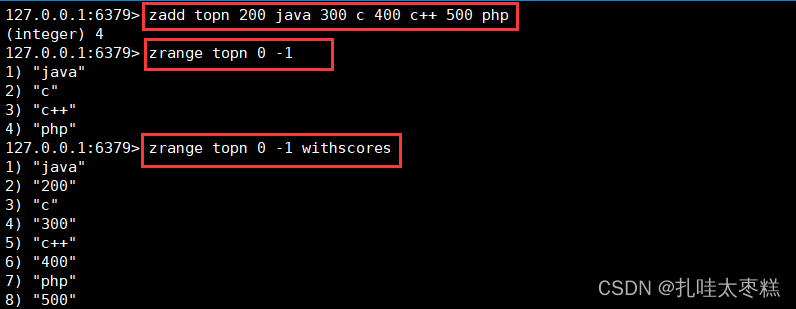 按照評分查看范圍內的值
按照評分查看范圍內的值
從小到大排: zrangebyscore K min max
從大到小排: zrevrangebyscore K max min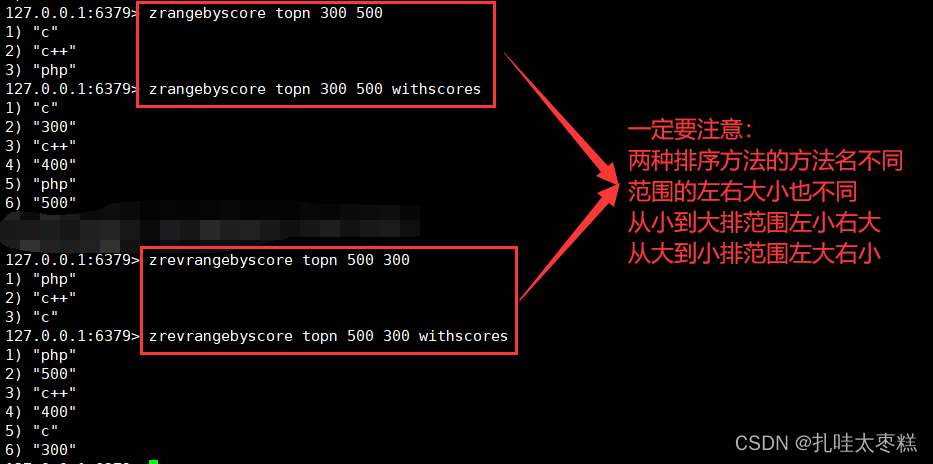 增加value對應的score: zincrby K num value
增加value對應的score: zincrby K num value
按照value刪除: zrem K value
計算score在范圍內的個數: zcount K min max
查詢value按score的排名: zrank K value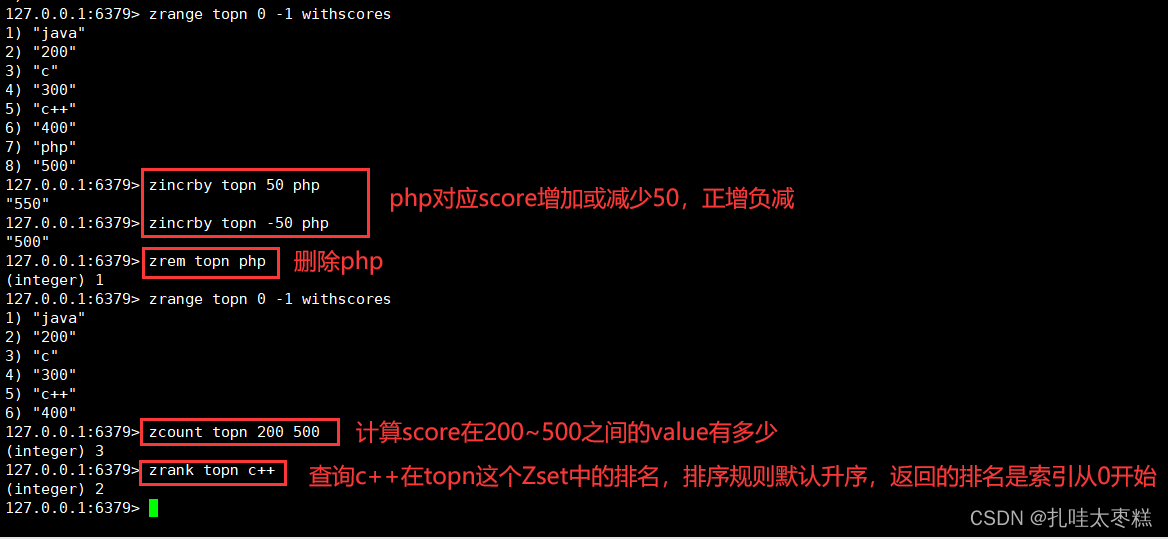







)





)





