
數據處理主要內容包括:
- 1. 特殊值處理
- 1.1 缺失值
- 1.2 離群值
- 1.3 日期
- 2. 數據轉換(base vs. dplyr)
- 2.1 篩選(subset vs. filter/select/rename)
- 2.2 排序(order vs. arrange)
- 2.3 轉換(transform vs. mutate/transmute)
- 2.4 分組與概括(group_by/summarise)
- 3. 數據框重塑(base vs. dplyr)
- 3.1 數據框的合并(rbind/cbind vs. bind_rows/bind_cols)
- 3.2 數據框的關聯(merge vs. *_ join)
- 3.3 數據框的長寬轉換(reshape2 包)
本文我們學習數據框重塑的有關內容。前文鏈接:
Sub-woo:R語言筆記(四):數據處理(上)?zhuanlan.zhihu.com

有出錯或補充的地方請大神們不吝賜教,作者會持續更新!
3. 數據框重塑
這篇文章我們主要介紹基本包和 dplyr 包中用于數據框操作的函數,包括多個數據框的合并、關聯以及長寬數據框的轉換。
字符串的拼接可以通過 paste() 函數實現,而多個數據框也同樣可以通過函數合成為一個數據框。與字符串不同的是,多個數據框的合成方式有兩種,一種是合并(父母之命,媒妁之言),另一種是關聯(相信緣分,因為愛情)。以下是段子,沒興趣的小伙伴可以跳過。
【段子:如何理解合并是“父母之命,媒妁之言”?這幾個要合并的數據框往往沒有相同的行或者列,我們只想硬生生地把它們拼成一個整體而已,或者說它們在一起不是因為相互有什么相同點,只是因為我們(父母)想[doge]。】
【段子:那又如何理解關聯是“因為愛情”呢?需要關聯的數據框往往具有某些相同的行或者列,比如有兩份數據框,一份是小明和小紅的數學成績,另一份是小明和小紅的英語成績,很顯然兩份數據框都有相同的人名,因此我們就可以將二者關聯,形成一份體現小明和小紅數學、英語成績的成績單。這些相同的行或列就好比緣分和愛情,正因為有了共同點,數據框們才能更緊密地結合,更幸福地生活=。=】
3.1 數據框的合并(rbind/cbind vs. bind_rows/bind_cols)
- base 包(rbind/cbind)
base 包提供的實現合并的函數有兩個,分別是:
rbind()
# 縱向合并
cbind()
# 橫向合并【注】rbind() 要求數據框的列數相同,同時列名也要一致;cbind() 要求數據框的行數相同。舉幾個例子:
set1 <- data.frame(a = 1: 4, b = LETTERS[1: 4])
set2 <- data.frame(a = 0, b = c("I", "love", "u"), c = c(5, 2, 0))set1 # 4×2 的數據框
# a b
# 1 1 A
# 2 2 B
# 3 3 C
# 4 4 D
set2 # 3×3 的數據框
# a b c
# 1 0 I 5
# 2 0 love 2
# 3 0 u 0# rbind(set1, set2) 列數不相同會報錯
# cbind(set1, set2) 行數不相同會報錯rbind(set1, set2[, 1:3]) # 只取 set2 的前兩列,使得列數與 set1 相同
# a b
# 1 1 A
# 2 2 B
# 3 3 C
# 4 4 D
# 5 0 I
# 6 0 love
# 7 0 u
cbind(set1[1: 3, ], set2) # 只取 set1 的前三行,使得行數與 set2 相同a b a b c
1 1 A 0 I 5
2 2 B 0 love 2
3 3 C 0 u 0
# 合并出現了兩個 a 列【注】使用 cbind() 合并數據框后,可能出現列名相同的情況,某種程度上算是 cbind() 的缺陷,因此作者也更傾向于使用 dplyr 包提供的合并函數。
- dplyr 包(bind_rows/bind_cols)
dplyr 包提供的數據框合并函數也有兩個,分別是:
bind_rows()
# 縱向拼接
bind_cols()
# 橫向拼接【注】bind_rows() 根據列名對數據框進行合并,同一列名的列進行合并,不同列名的列會自動進行補齊(默認使用 NA 補齊),最好保證相同列名的數據類型是一致的;bind_cols() 要求數據框的行數相同,若有相同列名,則會自動進行修改區分。接下來舉例說明:
library(dplyr)
one <- data.frame(a = c("I", "love", "U"), b = 0, c = c(5, 2, 0), stringsAsFactors = F)
two <- data.frame(a = c("13", "14"), d = LETTERS[1: 2], stringsAsFactors = F)
# 保證 two 的 a 列數據類型與 one 的 a 列一致,均為字符型one # 3×3 數據框
# a b c
# 1 I 0 5
# 2 love 0 2
# 3 U 0 0
two # 3×3 數據框
# a d
# 1 13 A
# 2 14 Bbind_rows(one, two)
# a b c d
# 1 I 0 5 <NA>
# 2 love 0 2 <NA>
# 3 U 0 0 <NA>
# 4 13 NA NA A
# 5 14 NA NA B
# 可以看到,bind_rows() 對相同列名的數據進行了合并,列名不同的列則自動使用 NA 進行了補齊。# bind_cols(one, two) 報錯,兩個數據框行數不一致
bind_cols(one[1:2, ], two)
# a b c a1 d
# 1 I 0 5 13 A
# 2 love 0 2 14 B
# 自動對相同的列名進行了修改3.2 數據框的關聯(merge vs. *_ join)
- base 包(merge)
基本包提供的數據框關聯函數為 merge() ,能夠根據兩個數據框相關的列進行關聯,附上參考資料:R語言使用merge函數匹配數據(vlookup,join),語法如下:
merge(x, y, by = intersect(names(x), names(y)),by.x = 列名1, by.y = 列名2, all = FALSE, all.x = all, all.y = all,sort = TRUE, suffixes = c(".x",".y"), no.dups = TRUE,incomparables = NULL, ...)x,y:要合并的兩個數據集
by:用于連接兩個數據集的列,intersect(a,b)值向量a,b的交集,names(x)指提取數據集x的列名
by:intersect(names(x), names(y)) 是獲取數據集x,y的列名后,提取其公共列名,作為兩個數據集的連接列, 當有多個公共列時,需用下標指出公共列,如names(x)[1],指定x數據集的第1列作為公共列。也可以直接寫為 by = "公共列名" ,前提是兩個數據集中都有該列名,并且大小寫完全一致,R語言區分大小寫
by.x,by.y:指定依據哪些列關聯數據框,默認值為相同列名的列
all,all.x,all.y:指定x和y的行是否應該全在輸出文件
sort:by指定的列(即公共列)是否要排序
suffixes:指定除by外相同列名的后綴;如設置 suffixes = c(".xx", ".yy"),兩個數據框都有列名 grade,關聯后就會被區分為 grade.xx 和 grade.yy
incomparables:指定by中哪些單元不進行關聯
其中,常用的參數有 by(根據相同列名的列進行關聯);by.x/by.y(可以分別指定兩個數據框的列進行關聯);all/all.x/all.y(邏輯變量,控制返回 x 和 y 所有/僅 x 數據框/僅 y 數據框的行);sort(邏輯變量,根據關聯的列進行排序)。
下面舉例說明:
grade1 <- data.frame(number = c(2, 3, 1), Names = c("小明", "小紅", "小李"), math = c(90, 80, 100))
grade2 <- data.frame(number = c(3, 1, 4), NAMES = c("小紅", "小李", "小張"), english = c(100, 90, 80))
grade3 <- data
# 兩個數據框定義了學號、姓名和成績
grade1
# number Names math
# 1 2 小明 90
# 2 3 小紅 80
# 3 1 小李 100
grade2
# number NAMES english
# 1 3 小紅 100
# 2 1 小李 90
# 3 4 小張 80merge(grade1, grade2)
# number Names math NAMES english
# 1 1 小李 100 小李 90
# 2 3 小紅 80 小紅 100默認條件下,根據兩個數據框相同列名的列(學號)進行關聯,由于 Names 和 NAMES 大小寫不一致,因此不會關聯該列;只保留兩個數據框的交集部分(共有的),省略了小明和小張的數據。我們可以通過 by.x/by.y 分別指定需要關聯的列名:
merge(grade1, grade2, by.x = c("number", "Names"), by.y = c("number", "NAMES"))
# number Names math english
# 1 1 小李 100 90
# 2 3 小紅 80 100這樣就實現了通過學號和姓名進行數據框的關聯。接下來我們通過 all/all.x/all.y 指定保留我們想要的行:
merge(grade1, grade2, by.x = c("number", "Names"), by.y = c("number", "NAMES"),all = T) # 返回并集(保留所有行)
# number Names math english
# 1 1 小李 100 90
# 2 2 小明 90 NA
# 3 3 小紅 80 100
# 4 4 小張 NA 80
# 使用 NA 填補了缺失值merge(grade1, grade2, by.x = c("number", "Names"), by.y = c("number", "NAMES"),all.x = T) # 僅保留 x 數據框的所有行
# number Names math english
# 1 1 小李 100 90
# 2 2 小明 90 NA
# 3 3 小紅 80 100
# 保留了 x 的所有行,因此小明的成績被留下了merge(grade1, grade2, by.x = c("number", "Names"), by.y = c("number", "NAMES"),all.y = T) # 僅保留 y 數據框的所有行
# 大家猜猜看結果最后我們通過 sort 對關聯的變量進行排序,默認 sort = T,將 by 中的第一個變量作為第一依據,第二個變量作為第二依據,以此類推進行排序。注意觀察下述代碼與之前的差異:
merge(grade1, grade2, by.x = c("Names", "number"), by.y = c("NAMES", "number"),all = T)
# Names number math english
# 1 小紅 3 80 100
# 2 小李 1 100 90
# 3 小明 2 90 NA
# 4 小張 4 NA 80可以看到,將 by 中 names 移到首位后,排序方式也發生了變化——根據姓名升序排列。
- dplyr 包(* _ join)
dplyr 包提供的關聯數據框的函數包括以下幾種:
inner_join(x, y, by = , copy = F, suffix = c(), ...)
# 返回交集
left_join(x, y, by = , copy = F, suffix = c(), ...)
# 返回 x 所有的行數據與交集,類似 merge 中 all.x = T
right_join(x, y, by = , copy = F, suffix = c(), ...)
# 返回 y 所有的行數據與交集,類似 all.y = T
full_join(x, y, by = , copy = F, suffix = c(), ...)
# 返回并集(所有數據),類似 all = T
semi_join(x, y, by = , copy = F)
# 保留 x 所有的列名,返回行的交集
anti_join(x, y, by = , copy = F)
# 保留 x 所有的列名,返回行的 x 與 !y 的交集(從 x 中剔除與 y 匹配的行)【注】by 可以賦值行名,也可以通過 by = c("列名1" = "列名2", ...) 進行指定;suffix 的功能與 merge 中的 suffixes 類似。下面介紹一下 semi_ join() 與 anti_ join() 的效果:
grade1 <- data.frame(number = c(2, 3, 1), Names = c("小明", "小紅", "小李"), math = c(90, 80, 100))
grade2 <- data.frame(number = c(3, 1, 4), NAMES = c("小紅", "小李", "小張"), english = c(100, 90, 80))
# 繼續使用上面的數據框semi_join(grade1, grade2)
# Joining, by = "number"
# number Names math
# 1 3 小紅 80
# 2 1 小李 100inner_join(grade1, grade2) # 對比交集
# number Names math NAMES english
# 1 3 小紅 80 小紅 100
# 2 1 小李 100 小李 90觀察到 semi_ join 保持了 grade1 的表格形式,數據則是 grade1 與 grade2 的交集,因此也可以理解為將數據的交集填入形如 grade1 的表格中。anti_ join 也是類似的效果:
anti_join(grade1, grade2)
# Joining, by = "number"
# number Names math
# 1 2 小明 90返回的數據是 grade1 中除去了與 grade2 共有的部分(即 x & !y,或者是
3.3 數據框的長寬轉換(reshape2 包)
- 什么是長數據/寬數據
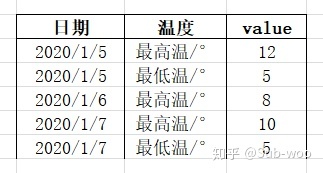
首先聊聊什么是長數據和寬數據。作者是這樣理解的,長數據的格式可以較為籠統地認為只有三列,一列用于存儲索引值,一列用于存儲 variable,最后一列用于存儲 value【類似于映射,第一列對應坐標,第二列對應映射方式(函數),第三列對應函數值(value)】。只是當索引值以多個維度存在的時候,就會出現四列甚至更多,舉個例子,將日期作為索引值,最高溫/最低溫作為 variable,溫度值作為 value 存儲時,數據框就可能是如下類型:
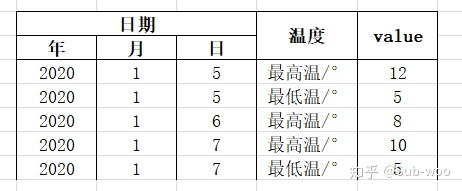
當索引值以更高維度表現時,如將日期格式的年/月/日分開書寫,就會是下面的樣子:
那寬數據又是什么樣的呢?類似于長數據,可以籠統地認為寬數據只有兩行,第一行用于存儲變量名,第二行用于存儲每個變量名對應的 value(列向量的形式存在),我們平時觀察的表格往往就是寬數據的形式。同樣使用溫度的數據,其寬數據的表現形式就像下面的表格:
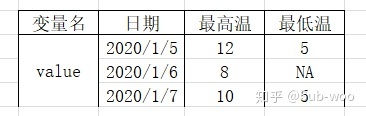
是不是看起來親切很多?
兩種格式各有優點,多數時候長數據的存儲占用空間比寬數據小(從缺失值可以大概領會一點),長數據的增刪讀取比寬數據效率更高;寬數據在形式上更清晰,而且由于其 value 是以列向量的形式存在,也能更好地適應 R 語言大多函數的調用。
- 長寬數據轉換的代碼實現
基本包中的 reshape/stack/unstack 函數可以實現長寬數據的轉換,但使用起來比較麻煩,現在很少有人使用,目前使用比較多的是 tidyr 包中的 gather/spread 函數和 reshape2 包中的 melt/dcast 函數。本篇文章只介紹 reshape2 包中轉換數據框長寬數據的函數(只會這個...):
melt(data, id.vars, measure.vars,variable.name = "variable", ..., na.rm = FALSE, value.name = "value",factorsAsStrings = TRUE)
# 將寬數據轉換為長數據dcast(data, formula, fun.aggregate = NULL, ..., margins = NULL,subset = NULL, fill = NULL, drop = TRUE,value.var = guess_value(data))
# 將長數據轉換為寬數據在 melt() 中,id.vars(亦作 id ) 對應長數據的第二列(映射方式/函數);measure.vars(亦作 measure ) 對應長數據的第三列(value/函數值);variable.name 指定第二列的列名;value.name 指定第三列的列名;na.rm = F 不移除缺失值,為 T 則移除缺失值;factorsAsStrings = T 將因子轉換為字符串,為 F 則不轉換。
在 dcast() 中,formula 的形式為 x_variable + x_2 ~ y_variable + y_2 ~ z_variable ~ ...,左端對應寬數據中的索引值,右端對應寬數據中的 variable 和 value;fun.aggregate 用于指定函數,若對應某個索引值的 value 個數多于一個,則需要通過 fun.aggregate 函數處理這些 values,使之聚合為一個 value(每個 x 有且僅有一個 y 值與之對應,才能成為映射),如函數 sum/mean/sd 等;fill 指定填補缺失值,默認用 fun.aggregate 函數對空向量返回的值填補。
下面用 R 自帶的 airquality 數據集舉例說明:
library(reshape2)
dat <- airquality
head(dat) # 顯示前六條數據
# Ozone Solar.R Wind Temp Month Day
# 1 41 190 7.4 67 5 1
# 2 36 118 8.0 72 5 2
# 3 12 149 12.6 74 5 3
# 4 18 313 11.5 62 5 4
# 5 NA NA 14.3 56 5 5
# 6 28 NA 14.9 66 5 6可以看到,airquality 是寬數據的形式,接下來我們嘗試將其轉換為長數據。
dat_long <- melt(dat, id.vars = c("Month", "Day"), measure.vars = c("Ozone", "Solar.R"), na.rm = T,variable.name = "Vars", value.name = "Vals")
head(dat_long)
# Month Day Vars Vals
# 1 5 1 Ozone 41
# 2 5 2 Ozone 36
# 3 5 3 Ozone 12
# 4 5 4 Ozone 18
# 6 5 6 Ozone 28
# 7 5 7 Ozone 23【注】代碼中設置了 na.rm = T 因此缺失值會直接被移除,如 5 月 5 日的 Ozone 沒有觀測值,5 月 6 日的 Solar.R 沒有觀測值,因此這里不會顯示 5 月 5 日的 Ozone。
以 Month 和 Day 構建二維的索引值,Ozone 和 Solar.R 作為 variable,兩個變量對應的數據作為 value 填入。但前六條記錄沒有顯示出 Solar.R 是為什么呢?因為 R 將 Ozone 的值存儲完畢以后才進行 Solar.R 的存儲,如下圖所示:
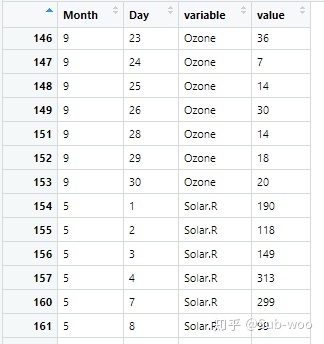
【注】代碼的運行結果可以看到 5 月 6 日的 Solar.R 沒有觀測值,因此在長數據中會被移除,但 5 月 6 日的 Ozone 有觀測值,在長數據中沒有被移除,與寬數據格式中缺失值的移除有所差異(寬數據格式中,缺失值會被按行移除,意味著 5 月 6 日的所有數據都會被 remove)
下面我們試試將長數據轉換為寬數據:
dat_wide <- dcast(dat_long, Month + Day ~ Vars)
# 注意這里使用 Vars 而不是 Ozone 和 Solar.R
# 因為在 dat_long 中只有 Vars
head(dat_wide)
# Month Day Ozone Solar.R
# 1 5 1 41 190
# 2 5 2 36 118
# 3 5 3 12 149
# 4 5 4 18 313
# 5 5 6 28 NA
# 6 5 7 23 299這里沒有 5 月 5 日的數據是因為在將 dat 轉換為 dat_long 的過程中,分別刪除了 Ozone 和 Solar. R 的缺失值,而 5 月 5 日恰巧同時缺失這兩個數據,因此后續將 dat_long 轉換為 dat_wide 后,dat_wide 中就不存在 5 月 5 日的數據了。我們嘗試將 na.rm 設置為 F 看看結果有什么不同:
dat <- airquality
dat_long <- melt(dat, id = c("Month", "Day"), measure = c("Ozone", "Solar.R"))
head(dat_long)
# Month Day variable value
# 1 5 1 Ozone 41
# 2 5 2 Ozone 36
# 3 5 3 Ozone 12
# 4 5 4 Ozone 18
# 5 5 5 Ozone NA
# 6 5 6 Ozone 28dat_wide <- dcast(dat_long, Month + Day ~ variable)
head(dat_wide)
# Month Day Ozone Solar.R
# 1 5 1 41 190
# 2 5 2 36 118
# 3 5 3 12 149
# 4 5 4 18 313
# 5 5 5 NA NA
# 6 5 6 28 NA如結果所示,5 月 5 日的數據會一直被保留下來。
再來看一個更復雜的例子:
set.seed(100)
grades <- data.frame(Month = rep(c(7,8), each = 5), Day = rep(seq(1, 31, by = 7), times = 2), Tom = sample(85:100, 10), Amy = sample(90:100, 10))
# 生成一個關于 Tom 和 Amy 在七、八月份的周測成績成績單如下表所示:
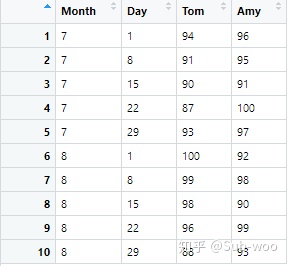
接著我們想要將其存儲在數據庫中,將其轉換為長數據:
grades_long <- melt(grades, id = c("Month", "Day"), measure = c("Tom", "Amy"))結果如下表所示:
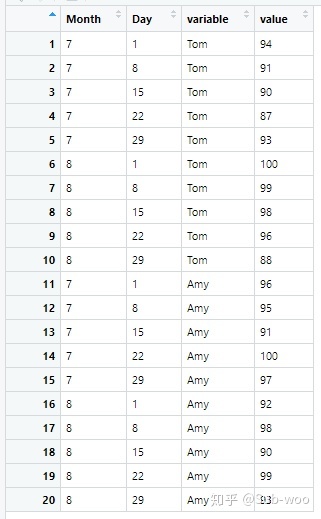
到了開家長會的時候,我們想要計算 Tom 和 Amy 的每月平均成績,可以通過如下代碼實現:
grades_wide <- dcast(grades_long, Month ~ variable, fun.aggregate = mean)
grades_wide
# Month Tom Amy
# 1 7 91.0 95.8
# 2 8 96.2 94.4由于每一個 Month 的值都對應 7 個 grades,因此我們使用 mean 求平均值,這樣通過 dcast() 中的 fun.aggregate 參數就可以非常便捷地獲得我們想要的數據啦~












—— 強大的Attention機制...)
![[機器人-2]:開源MIT Min cheetah機械狗設計(二):機械結構設計](http://pic.xiahunao.cn/[機器人-2]:開源MIT Min cheetah機械狗設計(二):機械結構設計)





