Python有很多包可以抓取數據,如selenium、requests、scrapy、pandas,每個包都有其適用性,個人認為在抓取數據時,代碼簡潔性和數據獲取的準確性是需要考慮的因素,時間快慢倒不用太在意,畢竟用python抓數據本來就大大節省了時間,用不同的方法可能也就是1秒和1分鐘的區別。日常中我們總存在抓取表格數據的需求,本文試圖用pandas最簡潔的代碼抓取表格數據,代碼非常簡單,也很容易上手。
隨便選個網頁:
http://www.nafmii.org.cn/dcmfx/tzs/ppn/index.html
比如爬取下圖中定向工具的注冊批文(當然wind里面也有數據,本文只是為了展示如何爬取表格型數據)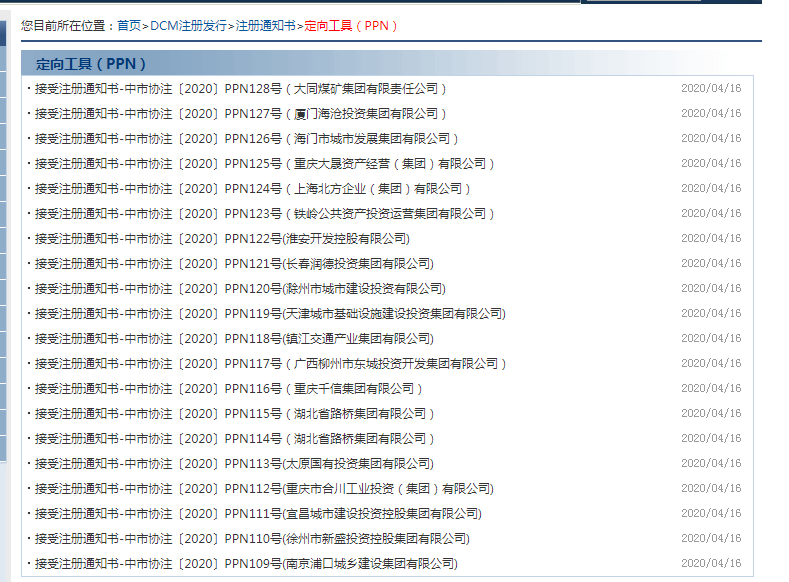
一、爬取當頁
只需要兩句關鍵代碼就可以抓取出來,前兩句是導入相關模塊,第三句輸入網址,第四句用pandas讀取,由于該網頁有很多表格,會以list格式存在ppn這個變量里,點擊查看可以發行第十四張表格正是我們所需要的內容。?
二、全部爬取
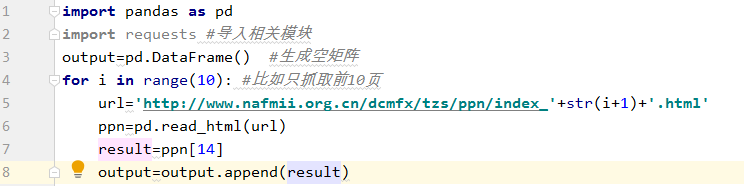
但是第一部分只抓取了第一頁,如果想要把所有頁都抓取出來,同樣非常簡單,只需編寫一個循環。點擊下一頁可以發現其網址會發生相應改變:http://www.nafmii.org.cn/dcmfx/tzs/ppn/index_2.html頁碼會體現在index后面的數字,因此可以將url改為變量的組合,具體看第五句。第一和二句依然是導入相關模塊,第三句是生成一個空矩陣,用于存儲抓取完的結果,第四句至第八句是一個簡單的循環,result變量就是每頁抓取的結果,然后不斷的添加到output里。最后output就是我們想要的結果。






)





選擇插件頁面傳遞經緯度)





 的容量 (7.0分))
