?
不多說,直接上干貨!
?
?
HDFS升級和回滾機制
作為一個大型的分布式系統,Hadoop內部實現了一套升級機制,當在一個集群上升級Hadoop時,像其他的軟件升級一樣,可能會有新的bug或一些會影響現有應用的非兼容性變更出現。在任何有實際意義的HDFS系統中,丟失數據是不允許的,更不用說重新搭建啟動HDFS了。當然,升級可能成功,也可能失敗。如果失敗了,那就用rollback進行回滾;如果過了一段時間,系統運行正常,那就可以通過finalize正式提交這次升級。
?
相關升級和回滾命令如下:
bin/hadoop namenode一upgrade //升級bin/hadoop namenode一rollback //回滾bin/hadoop namenode一finalize //提交bin/hadoop namenode一importCheckpoint //從Checkpoint恢復
上述命令的importCheckpoint參數用于NameNode發生故障后,從某個檢查點恢復。HDFS允許管理員退回到之前的Hadoop版木,將集群的狀態回滾到升級之前。
在升級之前,管理員需要用以下命令刪除已存在的備份文件:
bin/hadoop dfsadmin-finalizeUpgrade //升級終結操作
?
?
?
?
?
下面簡單介紹一下一般的升級過程。
在升級Hadoop軟件之前,檢查是否已經存在一個備份,如果備份存在,可執行升級終結操作刪除這個備份。通過以下命令能夠知道是否需要對一個集群執行升級終結操作:
dfsadmin -upgradeProgress status
1) 停止集群并部署Hadoop的新版本。
2) 使用upgrade選項運行新的版本(bin/start-dfs.sh -upgrade)
在大多數情況下,集群都能夠正常運行。一旦我們認為新的HDFS運行正常(也許經過幾天的操作之后),就可以對其執行升級終結操作。需要注意的是,在對一個集群執行升級終結操作之前,刪除那些升級前就已經存在的文件并不會真正地釋放DataNode上的磁盤空間。
?
如果需要退回到老版本,執行步驟如下:
1) 停止集群并部署Hadoop的老版本。
2) 用回滾選項啟動集群,命令如下:
bin/start-dfs.h ?-rolback
上面介紹了HDFS的升級和回滾的基本機制,其實可以從狀態轉移的角度來理解理解HDFS的升級和回滾機制。整個HDFS的狀態有:Normal, Upgraded, Rollbacking, Upgrading,Finalizing五種,HDFS集群的狀態轉移示意圖,如下圖所示。
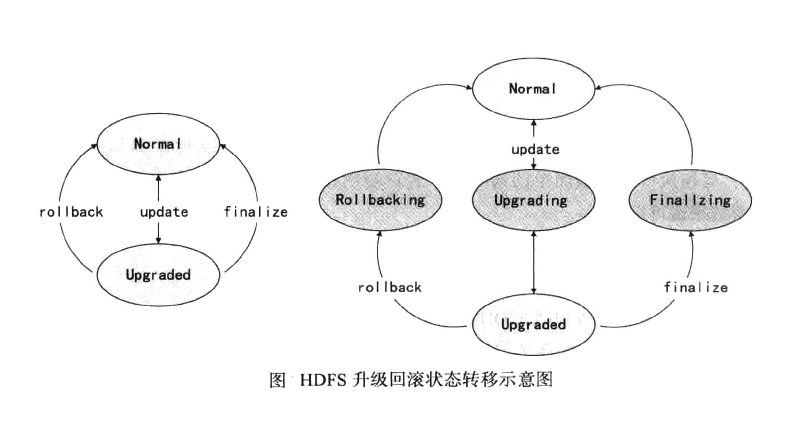
從上圖可以看出,升級、回滾、提交都不可能一下完成,這也就是說,在HDFS系統出現故障時,集群可能處于上圖右側圖中某一個狀態中,特別是在分布式的各個節點上,甚至可能出現有些節點已經升級成功,但有些節點可能處干中間狀態的情況,所以Hadoop采用類似于數據庫事務的升級機制也就很容易理解了。
?
?
?
?
?
?
?
?
同時,大家可以關注我的個人博客:
???http://www.cnblogs.com/zlslch/???和? ???http://www.cnblogs.com/lchzls/? ????http://www.cnblogs.com/sunnyDream/? ?
???詳情請見:http://www.cnblogs.com/zlslch/p/7473861.html
?
人生苦短,我愿分享。本公眾號將秉持活到老學到老學習無休止的交流分享開源精神,匯聚于互聯網和個人學習工作的精華干貨知識,一切來于互聯網,反饋回互聯網。
目前研究領域:大數據、機器學習、深度學習、人工智能、數據挖掘、數據分析。 語言涉及:Java、Scala、Python、Shell、Linux等 。同時還涉及平常所使用的手機、電腦和互聯網上的使用技巧、問題和實用軟件。 只要你一直關注和呆在群里,每天必須有收獲
?
? ? ? 對應本平臺的討論和答疑QQ群:大數據和人工智能躺過的坑(總群)(161156071)![]()
![]()
![]()
![]()
![]() ?
?
?

?
?
?
?
?

?
?
?
?
?
?




與內存分配 pragma pack(push,1)與#pragma pack(1)的區別)














