前言
本文主要介紹在pytorch中的Batch Normalization的使用以及在其中容易出現的各種小問題,本來此文應該歸屬于[1]中的,但是考慮到此文的篇幅可能會比較大,因此獨立成篇,希望能夠幫助到各位讀者。如有謬誤,請聯系指出,如需轉載,請注明出處,謝謝。
? \nabla ? 聯系方式:
e-mail: FesianXu@gmail.com
QQ: 973926198
github: https://github.com/FesianXu
知乎專欄: 計算機視覺/計算機圖形理論與應用
微信公眾號:
qrcode
Batch Normalization,批規范化
Batch Normalization(簡稱為BN)[2],中文翻譯成批規范化,是在深度學習中普遍使用的一種技術,通常用于解決多層神經網絡中間層的協方差偏移(Internal Covariate Shift)問題,類似于網絡輸入進行零均值化和方差歸一化的操作,不過是在中間層的輸入中操作而已,具體原理不累述了,見[2-4]的描述即可。
在BN操作中,最重要的無非是這四個式子:
注意到這里的最后一步也稱之為仿射(affine),引入這一步的目的主要是設計一個通道,使得輸出output至少能夠回到輸入input的狀態(當 γ = 1 , β = 0 \gamma=1,\beta=0 γ=1,β=0時)使得BN的引入至少不至于降低模型的表現,這是深度網絡設計的一個套路。
整個過程見流程圖,BN在輸入后插入,BN的輸出作為規范后的結果輸入的后層網絡中。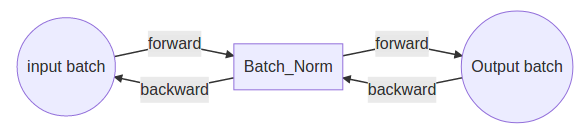
好了,這里我們記住了,在BN中,一共有這四個參數我們要考慮的:
??? γ , β \gamma, \beta γ,β:分別是仿射中的 w e i g h t \mathrm{weight} weight和 b i a s \mathrm{bias} bias,在pytorch中用weight和bias表示。
??? μ B \mu_{\mathcal{B}} μB?和 σ B 2 \sigma_{\mathcal{B}}^2 σB2?:和上面的參數不同,這兩個是根據輸入的batch的統計特性計算的,嚴格來說不算是“學習”到的參數,不過對于整個計算是很重要的。在pytorch中,這兩個統計參數,用running_mean和running_var表示[5],這里的running指的就是當前的統計參數不一定只是由當前輸入的batch決定,還可能和歷史輸入的batch有關,詳情見以下的討論,特別是參數momentum那部分。
Update 2020/3/16:
因為BN層的考核,在工作面試中實在是太常見了,在本文順帶補充下BN層的參數的具體shape大小。
以圖片輸入作為例子,在pytorch中即是nn.BatchNorm2d(),我們實際中的BN層一般是對于通道進行的,舉個例子而言,我們現在的輸入特征(可以視為之前討論的batch中的其中一個樣本的shape)為 x ∈ R C × W × H \mathbf{x} \in \mathbb{R}^{C \times W \times H} x∈RC×W×H(其中C是通道數,W是width,H是height),那么我們的 μ B ∈ R C \mu_{\mathcal{B}} \in \mathbb{R}^{C} μB?∈RC,而方差 σ B 2 ∈ R C \sigma^{2}_{\mathcal{B}} \in \mathbb{R}^C σB2?∈RC。而仿射中 w e i g h t , γ ∈ R C \mathrm{weight}, \gamma \in \mathbb{R}^{C} weight,γ∈RC以及 b i a s , β ∈ R C \mathrm{bias}, \beta \in \mathbb{R}^{C} bias,β∈RC。我們會發現,這些參數,無論是學習參數還是統計參數都會通道數有關,其實在pytorch中,通道數的另一個稱呼是num_features,也即是特征數量,因為不同通道的特征信息通常很不相同,因此需要隔離開通道進行處理。
有些朋友可能會認為這里的weight應該是一個張量,而不應該是一個矢量,其實不是的,這里的weight其實應該看成是 對輸入特征圖的每個通道得到的歸一化后的 x ^ \hat{\mathbf{x}} x^進行尺度放縮的結果,因此對于一個通道數為 C C C的輸入特征圖,那么每個通道都需要一個尺度放縮因子,同理,bias也是對于每個通道而言的。這里切勿認為 y i ← γ x ^ i + β y_i \leftarrow \gamma \hat{x}_i+\beta yi?←γx^i?+β這一步是一個全連接層,他其實只是一個尺度放縮而已。關于這些參數的形狀,其實可以直接從pytorch源代碼看出,這里截取了_NormBase層的部分初始代碼,便可一見端倪。
class _NormBase(Module):
??? """Common base of _InstanceNorm and _BatchNorm"""
??? _version = 2
??? __constants__ = ['track_running_stats', 'momentum', 'eps',
???????????????????? 'num_features', 'affine']
??? def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
???????????????? track_running_stats=True):
??????? super(_NormBase, self).__init__()
??????? self.num_features = num_features
??????? self.eps = eps
??????? self.momentum = momentum
??????? self.affine = affine
??????? self.track_running_stats = track_running_stats
??????? if self.affine:
??????????? self.weight = Parameter(torch.Tensor(num_features))
??????????? self.bias = Parameter(torch.Tensor(num_features))
??????? else:
??????????? self.register_parameter('weight', None)
??????????? self.register_parameter('bias', None)
??????? if self.track_running_stats:
??????????? self.register_buffer('running_mean', torch.zeros(num_features))
??????????? self.register_buffer('running_var', torch.ones(num_features))
??????????? self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
??????? else:
??????????? self.register_parameter('running_mean', None)
??????????? self.register_parameter('running_var', None)
??????????? self.register_parameter('num_batches_tracked', None)
??????? self.reset_parameters()
?
在Pytorch中使用
Pytorch中的BatchNorm的API主要有:
torch.nn.BatchNorm1d(num_features,
???????????????????? eps=1e-05,
???????????????????? momentum=0.1,
???????????????????? affine=True,
???????????????????? track_running_stats=True)
?
一般來說pytorch中的模型都是繼承nn.Module類的,都有一個屬性trainning指定是否是訓練狀態,訓練狀態與否將會影響到某些層的參數是否是固定的,比如BN層或者Dropout層。通常用model.train()指定當前模型model為訓練狀態,model.eval()指定當前模型為測試狀態。
同時,BN的API中有幾個參數需要比較關心的,一個是affine指定是否需要仿射,還有個是track_running_stats指定是否跟蹤當前batch的統計特性。容易出現問題也正好是這三個參數:trainning,affine,track_running_stats。
??? 其中的affine指定是否需要仿射,也就是是否需要上面算式的第四個,如果affine=False,則 γ = 1 , β = 0 \gamma=1,\beta=0 γ=1,β=0,并且不能學習被更新。一般都會設置成affine=True[10]
??? trainning和track_running_stats,track_running_stats=True表示跟蹤整個訓練過程中的batch的統計特性,得到方差和均值,而不只是僅僅依賴與當前輸入的batch的統計特性。相反的,如果track_running_stats=False那么就只是計算當前輸入的batch的統計特性中的均值和方差了。當在推理階段的時候,如果track_running_stats=False,此時如果batch_size比較小,那么其統計特性就會和全局統計特性有著較大偏差,可能導致糟糕的效果。
一般來說,trainning和track_running_stats有四種組合[7]
??? trainning=True, track_running_stats=True。這個是期望中的訓練階段的設置,此時BN將會跟蹤整個訓練過程中batch的統計特性。
??? trainning=True, track_running_stats=False。此時BN只會計算當前輸入的訓練batch的統計特性,可能沒法很好地描述全局的數據統計特性。
??? trainning=False, track_running_stats=True。這個是期望中的測試階段的設置,此時BN會用之前訓練好的模型中的(假設已經保存下了)running_mean和running_var并且不會對其進行更新。一般來說,只需要設置model.eval()其中model中含有BN層,即可實現這個功能。[6,8]
??? trainning=False, track_running_stats=False 效果同(2),只不過是位于測試狀態,這個一般不采用,這個只是用測試輸入的batch的統計特性,容易造成統計特性的偏移,導致糟糕效果。
同時,我們要注意到,BN層中的running_mean和running_var的更新是在forward()操作中進行的,而不是optimizer.step()中進行的,因此如果處于訓練狀態,就算你不進行手動step(),BN的統計特性也會變化的。如
model.train() # 處于訓練狀態
for data, label in self.dataloader:
?? ?pred = model(data) ?
?? ?# 在這里就會更新model中的BN的統計特性參數,running_mean, running_var
?? ?loss = self.loss(pred, label)
?? ?# 就算不要下列三行代碼,BN的統計特性參數也會變化
?? ?opt.zero_grad()
?? ?loss.backward()
?? ?opt.step()
?
這個時候要將model.eval()轉到測試階段,才能固定住running_mean和running_var。有時候如果是先預訓練模型然后加載模型,重新跑測試的時候結果不同,有一點性能上的損失,這個時候十有八九是trainning和track_running_stats設置的不對,這里需要多注意。 [8]
假設一個場景,如下圖所示: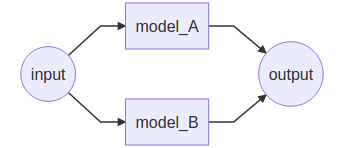
此時為了收斂容易控制,先預訓練好模型model_A,并且model_A內含有若干BN層,后續需要將model_A作為一個inference推理模型和model_B聯合訓練,此時就希望model_A中的BN的統計特性值running_mean和running_var不會亂變化,因此就必須將model_A.eval()設置到測試模式,否則在trainning模式下,就算是不去更新該模型的參數,其BN都會改變的,這個將會導致和預期不同的結果。
Update 2020/3/17:
評論區的Oshrin朋友提出問題
??? 作者您好,寫的很好,但是是否存在問題。即使將track_running_stats設置為False,如果momentum不為None的話,還是會用滑動平均來計算running_mean和running_var的,而非是僅僅使用本batch的數據情況。而且關于凍結bn層,有一些更好的方法。
這里的momentum的作用,按照文檔,這個參數是在對統計參數進行更新過程中,進行指數平滑使用的,比如統計參數的更新策略將會變成: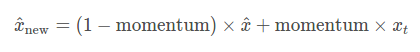
其中的更新后的統計參數 x ^ n e w \hat{x}_{\mathrm{new}} x^new?,是根據當前觀察 x t x_t xt?和歷史觀察 x ^ \hat{x} x^進行加權平均得到的(差分的加權平均相當于歷史序列的指數平滑),默認的momentum=0.1。然而跟蹤歷史信息并且更新的這個行為是基于track_running_stats為true并且training=true的情況同時成立的時候,才會進行的,當在track_running_stats=true, training=false時(在默認的model.eval()情況下,即是之前談到的四種組合的第三個,既滿足這種情況),將不涉及到統計參數的指數滑動更新了。[12,13]
這里引用一個不錯的BN層凍結的例子,如:[14]
import torch
import torch.nn as nn
from torch.nn import init
from torchvision import models
from torch.autograd import Variable
from apex.fp16_utils import *
def fix_bn(m):
??? classname = m.__class__.__name__
??? if classname.find('BatchNorm') != -1:
??????? m.eval()
model = models.resnet50(pretrained=True)
model.cuda()
model = network(model)
model.train()
model.apply(fix_bn) # fix batchnorm
input = Variable(torch.FloatTensor(8, 3, 224, 224).cuda())
output = model(input)
output_mean = torch.mean(output)
output_mean.backward()
總結來說,在某些情況下,即便整體的模型處于model.train()的狀態,但是某些BN層也可能需要按照需求設置為model_bn.eval()的狀態。
Update 2020.6.19:
評論區有個同學問了一個問題:
??? K.G.lee:想問博主,為什么模型測試時的參數為trainning=False, track_running_stats=True啊??測試不是用訓練時的滑動平均值嗎?為什么track_running_stats=True呢?為啥要跟蹤當前batch??
我感覺這個問題問得挺好的,我們需要去翻下源碼[15],我們發現我們所有的BatchNorm層都有個共同的父類_BatchNorm,我們最需要關注的是return F.batch_norm()這一段,我們發現,其對training的判斷邏輯是
training=self.training or not self.track_running_stats
那么,其實其在eval階段,這里的track_running_stats并不能設置為False,原因很簡單,這樣會使得上面談到的training=True,導致最終的期望程序錯誤。至于設置了track_running_stats=True是不是會導致在eval階段跟蹤測試集的batch的統計參數呢?我覺得是不會的,我們追蹤會發現[16],整個流程的最后一步其實是調用了torch.batch_norm(),其是調用C++的底層函數,其參數列表可和track_running_stats一點關系都沒有,只是由training控制,因此當training=False時,其不會跟蹤統計參數的,只是會調用訓練集訓練得到的統計參數。(當然,時間有限,我也沒有繼續追到C++層次去看源碼了)。
class _BatchNorm(_NormBase):
??? def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
???????????????? track_running_stats=True):
??????? super(_BatchNorm, self).__init__(
??????????? num_features, eps, momentum, affine, track_running_stats)
??? def forward(self, input):
??????? self._check_input_dim(input)
??????? # exponential_average_factor is set to self.momentum
??????? # (when it is available) only so that it gets updated
??????? # in ONNX graph when this node is exported to ONNX.
??????? if self.momentum is None:
??????????? exponential_average_factor = 0.0
??????? else:
??????????? exponential_average_factor = self.momentum
??????? if self.training and self.track_running_stats:
??????????? # TODO: if statement only here to tell the jit to skip emitting this when it is None
??????????? if self.num_batches_tracked is not None:
??????????????? self.num_batches_tracked = self.num_batches_tracked + 1
??????????????? if self.momentum is None:? # use cumulative moving average
??????????????????? exponential_average_factor = 1.0 / float(self.num_batches_tracked)
??????????????? else:? # use exponential moving average
??????????????????? exponential_average_factor = self.momentum
??????? return F.batch_norm(
??????????? input, self.running_mean, self.running_var, self.weight, self.bias,
??????????? self.training or not self.track_running_stats,
??????????? exponential_average_factor, self.eps)
?? def batch_norm(input, running_mean, running_var, weight=None, bias=None,
?????????????? training=False, momentum=0.1, eps=1e-5):
??? # type: (Tensor, Optional[Tensor], Optional[Tensor], Optional[Tensor], Optional[Tensor], bool, float, float) -> Tensor? # noqa
??? r"""Applies Batch Normalization for each channel across a batch of data.
??? See :class:`~torch.nn.BatchNorm1d`, :class:`~torch.nn.BatchNorm2d`,
??? :class:`~torch.nn.BatchNorm3d` for details.
??? """
??? if not torch.jit.is_scripting():
??????? if type(input) is not Tensor and has_torch_function((input,)):
??????????? return handle_torch_function(
??????????????? batch_norm, (input,), input, running_mean, running_var, weight=weight,
??????????????? bias=bias, training=training, momentum=momentum, eps=eps)
??? if training:
??????? _verify_batch_size(input.size())
??? return torch.batch_norm(
??????? input, weight, bias, running_mean, running_var,
??????? training, momentum, eps, torch.backends.cudnn.enabled
??? )
??
Reference
[1]. 用pytorch踩過的坑
[2]. Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]// International Conference on International Conference on Machine Learning. JMLR.org, 2015:448-456.
[3]. <深度學習優化策略-1>Batch Normalization(BN)
[4]. 詳解深度學習中的Normalization,BN/LN/WN
[5]. https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/batchnorm.py#L23-L24
[6]. https://discuss.pytorch.org/t/what-is-the-running-mean-of-batchnorm-if-gradients-are-accumulated/18870
[7]. BatchNorm2d增加的參數track_running_stats如何理解?
[8]. Why track_running_stats is not set to False during eval
[9]. How to train with frozen BatchNorm?
[10]. Proper way of fixing batchnorm layers during training
[11]. 大白話《Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift》
[12]. https://discuss.pytorch.org/t/what-does-model-eval-do-for-batchnorm-layer/7146/2
[13]. https://zhuanlan.zhihu.com/p/65439075
[14]. https://github.com/NVIDIA/apex/issues/122
[15]. https://pytorch.org/docs/stable/_modules/torch/nn/modules/batchnorm.html#BatchNorm2d
[16]. https://pytorch.org/docs/stable/_modules/torch/nn/functional.html#batch_norm
————————————————
版權聲明:本文為CSDN博主「FesianXu」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/LoseInVain/article/details/86476010



)


)

)





——遠程調試及發布到Azure)




