系列文章
iOS 匯編入門教程(一)ARM64 匯編基礎
iOS 匯編入門教程(二)在 Xcode 工程中嵌入匯編代碼
iOS 匯編入門教程(三)匯編中的 Section 與數據存取
iOS 匯編教程(四)基于 LLDB 動態調試快速分析系統函數的實現
iOS 匯編教程(五)Objc Block 的內存布局和匯編表示
前言
具有 ARM 體系結構的機器擁有相對較弱的內存模型,這類 CPU 在讀寫指令重排序方面具有相當大的自由度,為了保證特定的執行順序來獲得確定結果,開發者需要在代碼中插入合適的內存屏障,以防止指令重排序影響代碼邏輯[1]。
本文會介紹 CPU 指令重排的意義和副作用,并通過一個實驗驗證指令重排對代碼邏輯的影響,隨后介紹基于內存屏障的解決方案,以及在 iOS 開發中有關指令重排的注意事項。
指令重排
簡介
以 ARM 為體系結構的 CPU 在執行指令時,在遇到寫操作時,如果未獲得緩存段的獨占權限,需要基于緩存一致性協議與其他核協商,等待直到獲得獨占權限時才能完成這條指令的執行;再或者在執行乘法指令時遇到乘法器繁忙的情況,也需要等待。在這些情況下,為了提升程序的執行速度,CPU 會優先執行一些沒有前序依賴的指令。
一個例子
看下面一段簡單的程序:
; void acc(int *counter, int *flag);_acc:ldr x8, [x0]add x8, x8, #1str x8, [x0]ldr x9, [x1]mov x9, #1str x9, [x1]ret這段代碼將 counter 的值 +1,并將 flag 置為 1,按照正常的代碼邏輯,CPU 先從內存中讀取 counter (x0) 的值累加后回寫,隨后讀取 flag (x1) 的值置位后回寫。
但是如果 x0 所在的內存未命中緩存,會帶來緩存載入的等待,再或者回寫時無法獲取到緩存段的獨占權,為了保證多核的緩存一致性,也需要等待;此時如果 x1 對應的內存有緩存段,則可以優先執行 ldr x9, [x1],同時由于對 x9 的操作和對 x1 所在內存的操作不依賴于對 x8 和 x0 所在內存的操作,后續指令也可以優先執行,因此 CPU 亂序執行的順序可能變成如下這樣:
ldr x9, [x1]mov x9, #1str x9, [x1]ldr x8, [x0]add x8, x8, #1str x8, [x0]甚至如果寫操作都需要等待,還可能將寫操作都滯后:
ldr x9, [x1]mov x9, #1ldr x8, [x0]add x8, x8, #1str x9, [x1]str x8, [x0]再或者如果加法器繁忙,又會帶來全新的執行順序,當然這一切都要建立在被重新排序的指令之間不能相互他們依賴執行的結果。
副作用
指令重排大幅度提升了 CPU 的執行速度,但凡事都有兩面性,雖然在 CPU 層面重排的指令能保證運算的正確性,但在邏輯層面卻可能帶來錯誤。比如常見的自旋鎖場景,我們可能設置一個 bool 類型的 flag 來自旋等待某異步任務的完成,在這種情況下,一般是在任務結束時對 flag 置位,如果置位 flag 的語句被重排到異步任務語句的中間,將會帶來邏輯錯誤。下面我們會通過一個實驗來直觀展示指令重排帶來的副作用。
一個實驗
在下面的代碼中我們設置了兩個線程,一個執行運算,并在運算結束后置位 flag,另一個線程自旋等待 flag 置位后讀取結果。
我們首先定義一個保存運算結果的結構體。
typedef struct FlagsCalculate { int a; int b; int c; int d; int e; int f; int g;} FlagsCalculate;為了更快的復現重排帶來的錯誤,我們使用了多個 flag 位,存儲在結構體的 e, f, g 三個成員變量中,同時 a, b, c, d 作為運算結果的存儲變量:
int getCalculated(FlagsCalculate *ctx) { while (ctx->e == 0 || ctx->f == 0 || ctx->g == 0); return ctx->a + ctx->b + ctx->c + ctx->d;}為了更快的觸發未命中緩存,我們使用了多個全局變量;為了模擬加法器和乘法器繁忙,我們采用了密集的運算:
int mulA = 15;int mulB = 35;int divC = 2;int addD = 20;void calculate(FlagsCalculate *ctx) { ctx->a = (20 * mulA - mulB) / divC; ctx->b = 30 + addD; for (NSInteger i = 0; i < 10000; i++) { ctx->a += i * mulA - mulB; ctx->a *= divC; ctx->b += i * mulB / mulA - mulB; ctx->b /= divC; } ctx->c = mulA + mulB * divC + 120; ctx->d = addD + mulA + mulB + 5; ctx->e = 1; ctx->f = 1; ctx->g = 1;}接下來我們將他們封裝在 pthread 線程的執行函數內:
void* getValueThread(void *arg) { pthread_setname_np("getValueThread"); FlagsCalculate *ctx = (FlagsCalculate *)arg; int val = getCalculated(ctx); assert(val == -276387); return NULL;}void* calValueThread(void *arg) { pthread_setname_np("calValueThread"); FlagsCalculate *ctx = (FlagsCalculate *)arg; calculate(ctx); return NULL;}void newTest() { FlagsCalculate *ctx = (FlagsCalculate *)calloc(1, sizeof(struct FlagsCalculate)); pthread_t get_t, cal_t; pthread_create(&get_t, NULL, &getValueThread, (void *)ctx); pthread_create(&cal_t, NULL, &calValueThread, (void *)ctx); pthread_detach(get_t); pthread_detach(cal_t);}每次調用 newTest 即開始一輪新的實驗,在 flag 置位未被亂序執行的情況下,最終的運算結果是 -276387,通過短時間內不斷并發執行實驗,觀察是否遇到斷言即可判斷是否由重排引發了邏輯異常:
while (YES) { newTest();}筆者在一個 iOS Empty Project 中添加上述代碼,并將其運行在一臺 iPhone XS Max 上,約 10 分鐘后,遇到了斷言錯誤: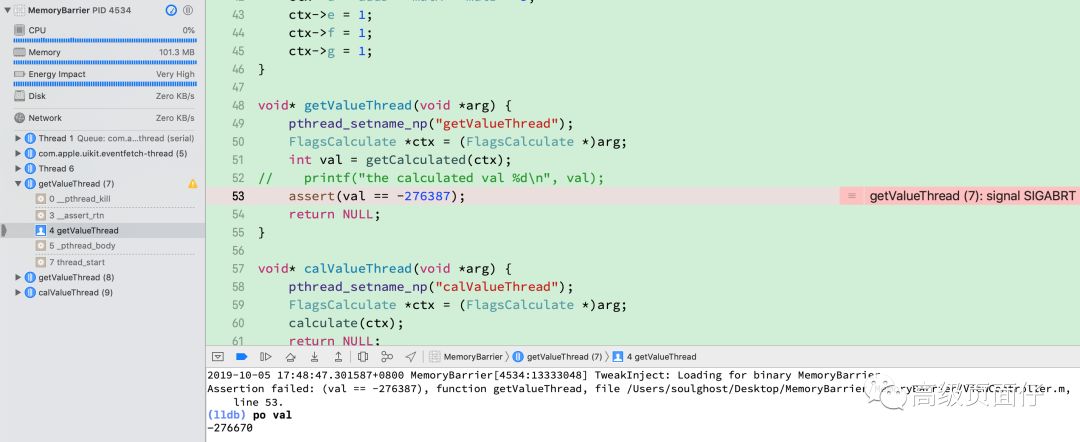
顯然這是由于亂序執行導致的 flag 全部被提前置位,從而導致異步線程獲取到的執行結果錯誤,通過實驗我們驗證了上面的理論。
答疑解惑
看到這里你可能驚出一身冷汗,開始回憶起自己職業生涯中寫過的類似邏輯,也許線上有很多正在運行,但從來沒出過問題,這又是為什么呢?
在 iOS 開發中,我們常使用 GCD 作為多線程開發的框架,這類 High Level 的多線程模型本身已經提供好了天然的內存屏障來保證指令的執行順序,因此可以大膽的去寫上述邏輯而不用在意指令重排,這也是我們使用 pthread 來進行上述實驗的原因。
到這里你也應該意識到,如果采用 Low Level 的多線程模型來進行開發時,一定要注意指令重排帶來的副作用,下面我們將介紹如何通過內存屏障來避免指令重排對邏輯的影響。
內存屏障
簡介
內存屏障是一條指令,它能夠明確地保證屏障之前的所有內存操作均已完成(可見)后,才執行屏障后的操作,但是它不會影響其他指令(非內存操作指令)的執行順序[3]。
因此我們只要在 flag 置位前放置內存屏障,即可保證運算結果全部寫入內存后才置位 flag,進而也就保證了邏輯的正確性。
放置內存屏障
我們可以通過內聯匯編的形式插入一個內存屏障:
void calculate(FlagsCalculate *ctx) { ctx->a = (20 * mulA - mulB) / divC; ctx->b = 30 + addD; for (NSInteger i = 0; i < 10000; i++) { ctx->a += i * mulA - mulB; ctx->a *= divC; ctx->b += i * mulB / mulA - mulB; ctx->b /= divC; } ctx->c = mulA + mulB * divC + 120; ctx->d = addD + mulA + mulB + 5; __asm__ __volatile__("dmb sy"); ctx->e = 1; ctx->f = 1; ctx->g = 1;}隨后繼續剛才的試驗可以發現,斷言不會再觸發異常,內存屏障限制了 CPU 亂序執行對正常邏輯的影響。
volatile 與內存屏障
我們常常聽說 volatile 是一個內存屏障,那么它的屏障作用是否與上述 DMB 指令一致呢,我們可以試著用 volatile 修飾 3 個 flag,再做一次實驗:
typedef struct FlagsCalculate { int a; int b; int c; int d; volatile int e; volatile int f; volatile int g;} FlagsCalculate;結果最后觸發了斷言異常,這是為何呢?因為 volatile 在 C 環境下僅僅是編譯層面的內存屏障,僅能保證編譯器不優化和重排被 volatile 修飾的內容,但是在 Java 環境下 volatile 具有 CPU 層面的內存屏障作用[4]。不同環境表現不同,這也是 volatile 讓我們如此費解的原因。
在 C 環境下,volatile 常常用來保證內聯匯編不被編譯優化和改變位置,例如我們通過內聯匯編放置一個編譯層面的內存屏障時,通過 __volatile__ 修飾匯編代碼塊來保證內存屏障的位置不被編譯器改變:
__asm__ __volatile__("" ::: "memory");總結
到這里,相信你對指令重排和內存屏障有了更加清晰的認識,同時對 volatile 的作用也更加明確了,希望本文能對大家有所幫助。
參考資料
[1]緩存一致性(Cache Coherency)入門: https://www.infoq.cn/article/cache-coherency-primer
[2]CPU Reordering – What is actually being reordered?: https://mortoray.com/2010/11/18/cpu-reordering-what-is-actually-being-reordered/
[3]ARM Information Center - DMB, DSB, and ISB: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0489c/CIHGHHIE.html
[4]volatile 與內存屏障總結: https://zhuanlan.zhihu.com/p/43526907










)

)

![[算法]判斷一個數是不是2的N次方](http://pic.xiahunao.cn/[算法]判斷一個數是不是2的N次方)


子數涵數·C語言——條件語句)

