一、函數
函數是一個包含完成一定功能的執行代碼段。我們可以把函數看成一個"黑盒子", 你只要將數據送進去就能得到結果, 而函數內部究竟是如何工作的的, 外部程序是不知道的。外部程序所知道的僅限于輸入給函數什么以及函數輸出什么。函數提供了編制程序的手段,使之容易讀、寫、理解、排除錯誤、修改和維護。?
計算1-n的和
#include "stdio.h" void main() {//write once only once 只寫一次int i,s=0;for(i=1;i<=100;i++){s+=i;}printf("%d \n",s);s=0;for(i=1;i<=80;i++){s+=i;} printf("%d \n",s);s=0;for(i=1;i<=555;i++){s+=i;} printf("%d \n",s); }
?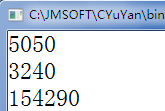
違背“write once only once 只寫一次”原則,重復。
#include "stdio.h"/* 函數定義 int 表示函數的返回值(return),沒返回值void sum 表示函數的名稱,符合變量命名 (int n) 參數列表,可以有0-n個 */ int sum(int n) {return n+1; }void main() {int x=sum(100);x=sum(x);printf("%d \n",x); //函數調用printf("%d \n",sum(9)); }
102
10
#include "stdio.h"/* 函數定義 int 表示函數的返回值(return),沒返回值void sum 表示函數的名稱,符合變量命名 (int n) 參數列表,可以有0-n個 */ int sum(int n) {int i,s=0;for(i=1;i<=n;i++){s+=i;}return s; }void main() {printf("%d \n",sum(100));printf("%d \n",sum(80));printf("%d \n",sum(555)); }
?
1.1、內置函數
內置函數是指像printf、scanf這類的系統庫函數,在編譯的過程中,編譯器會根據包含的頭文件查找相應的庫進行連接編譯,如果沒有包含頭文件的話,系統里面有很多庫文件,編譯器就無法找到對應的文件進行編譯。內置函數有許多,可以參考《C語言標準庫函數大全.chm》
1.2、自定義函數
1.2.1、函數定義語法
? ? ? ?函數類型? 函數名(類型 參數名,類型 參數名...)
????? {
????????? 函數體;
?????? }??
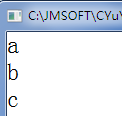
void show(char c) {printf("%c\n",c); }
1.2.2、函數調用
void main() {show('a');show('b');show('c'); }
?write once only once
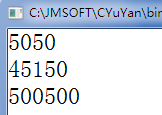
#include "stdio.h"//定義函數 //int 表示函數的返回值,無返回值void,return返回值 //sum 表示函數名稱,與變量命名規則相同 //int n表示參數,可以有0-n個,形參 int sum(int n) {int s=0,i;for(i=1;i<=n;i++){s+=i;}return s; }void p(int n){printf("%d \t",n); }void l() {printf("\n"); }void main() {p(sum(100));l();p(sum(300));l();p(sum(1000)); }
1.3、遞歸
函數直接或間接的調用自己叫遞歸。
int f(int n) {if(n==1) return 1;return f(n-1)+n; }void main() {printf("%d",f(100)); }
?
5050
f(n)=f(n-1)+n;
斐波那契數列(Fibonacci sequence),又稱黃金分割數列
//1 1 2 3 5 8 13 21 34 /* function f(n) f(5)=5 f(6)=8 f(7)=13 f(n)=f(n-1)+f(n-2) f(7)=f(6)+f(5) 13=8+5 */ int f(int n) //n第幾位 {if(n==1 || n==2) return 1;return f(n-1)+f(n-2); }void main() {printf("%d",f(45)); }
二、指針
指針是C語言中非常重要的數據類型,了解指針有助于更加深刻理解C語言。
2.1、指針的概念
指針是一個特殊的變量,它里面存儲的數值被解釋成為內存里的一個地址。?”指針是一種保存變量地址的變量“,指針是一個特殊的變量
#include "stdio.h" void main() {int n=100;int *p=&n;printf("%d \n",p); //輸入邏輯地址printf("%p \n",p); //%p 是以16進制的形式輸出內存地址 }
![]()
2.2、指針的定義
int *p; char *q;
"*"是一個說明符,用來說明這個變量是個指針變量,是不能省略的,但它不屬于變量名的一部分
前面的類型標識符表示指針變量所指向的變量的類型,而且只能指向這種類型的變量
2.3、指針的初始化
// 定義int類型的變量a int a = 10;// 定義一個指針變量p int *p;// 將變量a的地址賦值給指針變量p,所以指針變量p指向變量a p = &a;
?
// 定義int類型的變量a int a = 10;// 定義一個指針變量p // 并將變量a的地址賦值給指針變量p,所以指針變量p指向變量a int *p = &a;
?
2.4、指針運算符
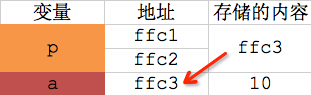
char a = 10; printf("修改前,a的值:%d\n", a);// 指針變量p指向變量a char *p = &a;// 通過指針變量p間接修改變量a的值 *p = 9;printf("修改后,a的值:%d", a);
?

取出指針所指向變量的值
char a = 10;char *p; p = &a;char value = *p; printf("取出a的值:%d", value);
練習:定義一個函數,使用指針完成兩個數交換。
?
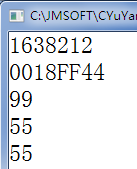
/* Note:Your choice is C IDE */ #include "stdio.h" void main() {int n=99;int *p=&n; //定義指針p,可以指向int類型變量的地址//&n是取出n的地址 printf("%d\n",p);printf("%p\n",p);printf("%d \n",*p); //取出地址對應的值*p=55; //將p指向的地址對應的值修改為55 printf("%d\n",n);printf("%d \n",*p); //取出地址對應的值 }
2.5、指針與數組
int array[10]={0,1,2,3,4,5,6,7,8,9},value;?
array就是數組的地址。
value=array[0];//也可寫成:value=*array;?
value=array[3];//也可寫成:value=*(array+3);?
value=array[4];//也可寫成:value=*(array+4);?
int array[10];?
int (*ptr)[10]; ? //指向地址的地址
ptr=&array;?
上例中ptr是一個指針,它的類型是int (*)[10],他指向的類型是int [10]?
,我們用整個數組的首地址來初始化它。在語句ptr=&array中,array代表數組本?
身。?
int arrays[3]={1,2,3};
int (*ptr)[3];
ptr=&arrays;
printf("%d\n",**ptr+3); ?//指向地址的地址
三、宏
C語言中提供的宏定義命令,其主要目的是為程序員在編程時提供一定的方便,并能在一定程度上提高程序的運行效率。
3.1、簡單宏定義
[#define指令(簡單的宏)] #define 標識符替換列表
替換列表是一系列的C語言記號,包括標識符、關鍵字、數、字符常量、字符串字面量、運算符和標點符號。當預處理器遇到一個宏定義時,會做一個 “標識符”代表“替換列表”的記錄。在文件后面的內容中,不管標識符在任何位置出現,預處理器都會用替換列表代替它。
#define STE_LEN 80
#define TRUE 1
#define FALSE 0
#define PI 3.14159
3.2、帶參數的宏
帶參數的宏定義有如下格式:
[#define指令—帶參數的宏] #define 標識符(x1, x2,…,xn)替換列表
其中x1, x2,…,xn是標識符(宏的參數)。這些參數可以在替換列表中根據需要出現任意次。
在宏的名字和左括號之間必須沒有空格。如果有空格,預處理器會認為是在定義一個簡單的宏,其中(x1,x2,…,xn)是替換列表的一部分。
例如,假定我們定義了如下的宏:
#define MAX(x,y) ((x)>(y) ? (x) :(y)) #define IS_EVEN(n) ((n)%2==0)
現在如果后面的程序中有如下語句:
i = MAX(j+k, m-n); if (IS_EVEN(i)) i++;
預處理器會將這些行替換為
i = ((j+k)>(m-n)?(j+k):(m-n)); if (((i)%2==0)) i++;
200
#define?PRINT_INT(x)????printf("%d\n",?x) ?
3.3、C語言中常用的宏
01: 防止一個頭文件被重復包含
#ifndef COMDEF_H
#define COMDEF_H
//頭文件內容
#endif
02: 重新定義一些類型
防止由于各種平臺和編譯器的不同,而產生的類型字節數差異,方便移植。
typedef unsigned char boolean; /* Boolean value type. */
typedef unsigned long int uint32; /* Unsigned 32 bit value */
typedef unsigned short uint16; /* Unsigned 16 bit value */
typedef unsigned char uint8; /* Unsigned 8 bit value */
typedef signed long int int32; /* Signed 32 bit value */
typedef signed short int16; /* Signed 16 bit value */
typedef signed char int8; /* Signed 8 bit value */
//下面的不建議使用
typedef unsigned char byte; /* Unsigned 8 bit value type. */
typedef unsigned short word; /* Unsinged 16 bit value type. */
typedef unsigned long dword; /* Unsigned 32 bit value type. */
typedef unsigned char uint1; /* Unsigned 8 bit value type. */
typedef unsigned short uint2; /* Unsigned 16 bit value type. */
typedef unsigned long uint4; /* Unsigned 32 bit value type. */
typedef signed char int1; /* Signed 8 bit value type. */
typedef signed short int2; /* Signed 16 bit value type. */
typedef long int int4; /* Signed 32 bit value type. */
typedef signed long sint31; /* Signed 32 bit value */
typedef signed short sint15; /* Signed 16 bit value */
typedef signed char sint7; /* Signed 8 bit value */
03: 得到指定地址上的一個字節或字
#define MEM_B(x) (*((byte *)(x)))
#define MEM_W(x) (*((word *)(x)))
04: 求最大值和最小值
#define MAX(x,y) (((x)>(y)) ? (x) : (y))
#define MIN(x,y) (((x) < (y)) ? (x) : (y))
05: 得到一個field在結構體(struct)中的偏移量
#define FPOS(type,field) ((dword)&((type *)0)->field)
06: 得到一個結構體中field所占用的字節數
#define FSIZ(type,field) sizeof(((type *)0)->field)
07: 按照LSB格式把兩個字節轉化為一個Word
#define FLIPW(ray) ((((word)(ray)[0]) * 256) + (ray)[1])
08: 按照LSB格式把一個Word轉化為兩個字節
#define FLOPW(ray,val) (ray)[0] = ((val)/256); (ray)[1] = ((val) & 0xFF)
09: 得到一個變量的地址(word寬度)
#define B_PTR(var) ((byte *) (void *) &(var))
#define W_PTR(var) ((word *) (void *) &(var))
10: 得到一個字的高位和低位字節
#define WORD_LO(xxx) ((byte) ((word)(xxx) & 255))
#define WORD_HI(xxx) ((byte) ((word)(xxx) >> 8))
11: 返回一個比X大的最接近的8的倍數
#define RND8(x) ((((x) + 7)/8) * 8
12: 將一個字母轉換為大寫
#define UPCASE(c) (((c)>='a' && (c) <= 'z') ? ((c) – 0×20) : (c))
13: 判斷字符是不是10進值的數字
#define DECCHK(c) ((c)>='0' && (c)<='9')
14: 判斷字符是不是16進值的數字
#define HEXCHK(c) (((c) >= '0' && (c)<='9') ((c)>='A' && (c)<= 'F') \
((c)>='a' && (c)<='f'))
15: 防止溢出的一個方法
#define INC_SAT(val) (val=((val)+1>(val)) ? (val)+1 : (val))
16: 返回數組元素的個數
#define ARR_SIZE(a) (sizeof((a))/sizeof((a[0])))
17: 返回一個無符號數n尾的值MOD_BY_POWER_OF_TWO(X,n)=X%(2^n)
#define MOD_BY_POWER_OF_TWO( val, mod_by ) ((dword)(val) & (dword)((mod_by)-1))
18: 對于IO空間映射在存儲空間的結構,輸入輸出處理
#define inp(port) (*((volatile byte *)(port)))
#define inpw(port) (*((volatile word *)(port)))
#define inpdw(port) (*((volatile dword *)(port)))
#define outp(port,val) (*((volatile byte *)(port))=((byte)(val)))
#define outpw(port, val) (*((volatile word *)(port))=((word)(val)))
#define outpdw(port, val) (*((volatile dword *)(port))=((dword)(val)))
19: 使用一些宏跟蹤調試
ANSI標準說明了五個預定義的宏名。它們是:
__LINE__
__FILE__
__DATE__
__TIME__
__STDC__
C++中還定義了 __cplusplus
如果編譯器不是標準的,則可能僅支持以上宏名中的幾個,或根本不支持。記住編譯程序也許還提供其它預定義的宏名。
__LINE__ 及 __FILE__ 宏指示,#line指令可以改變它的值,簡單的講,編譯時,它們包含程序的當前行數和文件名。
__DATE__ 宏指令含有形式為月/日/年的串,表示源文件被翻譯到代碼時的日期。
__TIME__ 宏指令包含程序編譯的時間。時間用字符串表示,其形式為: 分:秒
__STDC__ 宏指令的意義是編譯時定義的。一般來講,如果__STDC__已經定義,編譯器將僅接受不包含任何非標準擴展的標準C/C++代碼。如果實現是標準的,則宏__STDC__含有十進制常量1。如果它含有任何其它數,則實現是非標準的。
__cplusplus 與標準c++一致的編譯器把它定義為一個包含至少6為的數值。與標準c++不一致的編譯器將使用具有5位或更少的數值。
可以定義宏,例如:當定義了_DEBUG,輸出數據信息和所在文件所在行
#ifdef _DEBUG
#define DEBUGMSG(msg,date) printf(msg);printf(“%d%d%d”,date,_LINE_,_FILE_)
#else
#define DEBUGMSG(msg,date)
#endif
20: 宏定義防止錯誤使用小括號包含。
例如:
有問題的定義:#define DUMP_WRITE(addr,nr) {memcpy(bufp,addr,nr); bufp += nr;}
應該使用的定義: #difne DO(a,b) do{a+b;a++;}while(0)
例如:
if(addr)
DUMP_WRITE(addr,nr);
else
do_somethong_else();
//宏展開以后變成這樣:
if(addr)
{memcpy(bufp,addr,nr); bufp += nr;};
else
do_something_else();
更多


)


)

![BZOJ4107 : [Wf2015]Asteroids](http://pic.xiahunao.cn/BZOJ4107 : [Wf2015]Asteroids)



...)

函數和.sum(axis=0)函數的使用)



-數據類型)

![[改善Java代碼]非穩定排序推薦使用List](http://pic.xiahunao.cn/[改善Java代碼]非穩定排序推薦使用List)