文章介紹了如何對隨機森林模型進行參數調優
原文來自:http://www.analyticsvidhya.com/blog/2015/06/tuning-random-forest-model/
為什么要調整機器學習算法?
一個月以前,我在kaggle上參加了一個名為TFI的比賽。 我第一次提交的結果在50%。 我不懈努力在特征工程上花了超過2周的時間,勉強達到20%。 出乎我意料的事是,在調整機器學習算法參數之后,我能夠達到前10%。
這是這就是機器學習算法參數調優的重要性。 隨機森林是在工業界中使用的最簡單的機器學習工具之一。 在我們以前的文章中,我們已經向您介紹了隨機森林和和CART模型進行了對比 。 機器學習工具包正由于這些算法的表現而被人所熟知。。
隨機森林是什么?
隨機森林是一個集成工具,它使用觀測數據的子集和變量的子集來建立一個決策樹。 它建立多個這樣的決策樹,然后將他們合并在一起以獲得更準確和穩定的預測。 這樣做最直接的事實是,在這一組獨立的預測結果中,用投票方式得到一個最高投票結果,這個比單獨使用最好模型預測的結果要好。
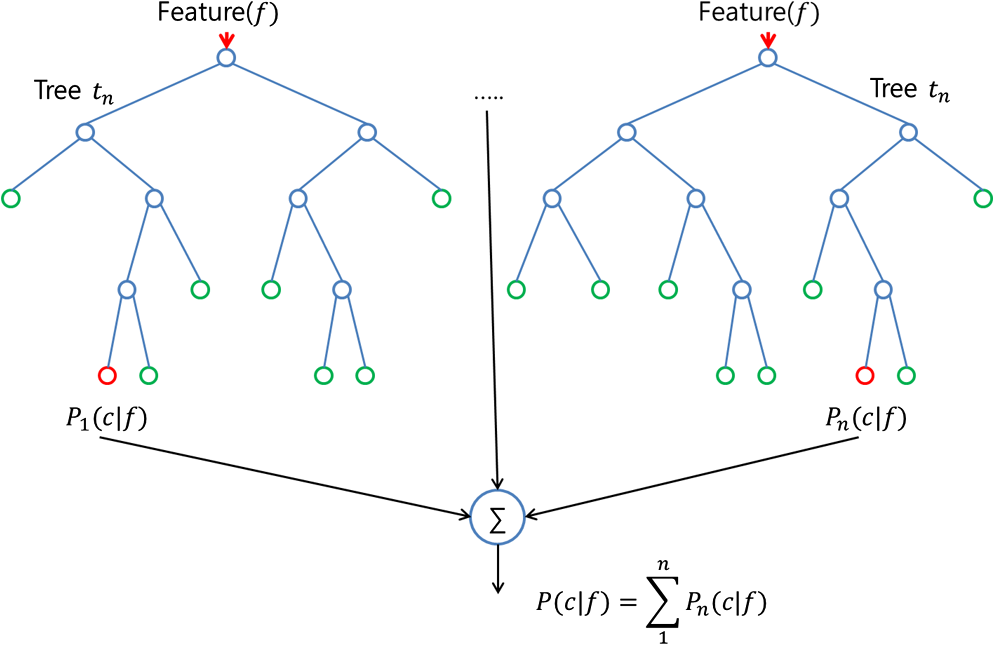 ?我們通常將隨機森林作為一個黑盒子,輸入數據然后給出了預測結果,無需擔心模型是如何計算的。這個黑盒子本身有幾個我們可以擺弄的杠桿。 每個杠桿都能在一定程度上影響模型的性能或資源 -- 時間平衡。 在這篇文章中,我們將更多地討論我們可以調整的杠桿,同時建立一個隨機林模型。
?我們通常將隨機森林作為一個黑盒子,輸入數據然后給出了預測結果,無需擔心模型是如何計算的。這個黑盒子本身有幾個我們可以擺弄的杠桿。 每個杠桿都能在一定程度上影響模型的性能或資源 -- 時間平衡。 在這篇文章中,我們將更多地討論我們可以調整的杠桿,同時建立一個隨機林模型。
調整隨機森林的參數/杠桿
隨機森林的參數即可以增加模型的預測能力,又可以使訓練模型更加容易。 以下我們將更詳細地談論各個參數(請注意,這些參數,我使用的是Python常規的命名法):
1.使模型預測更好的特征
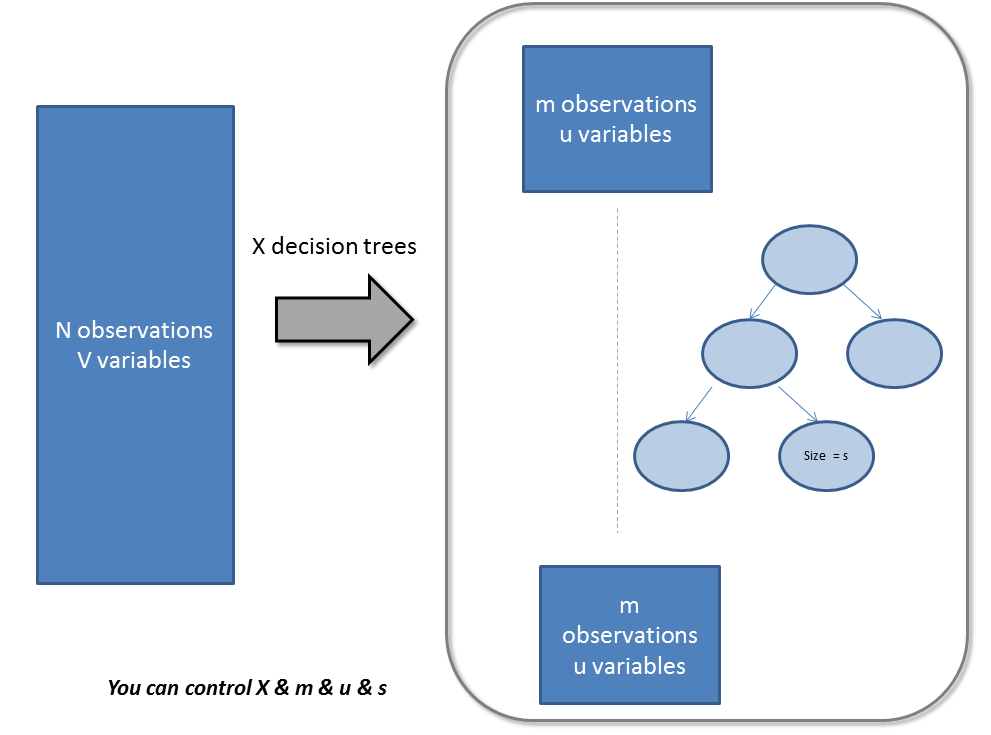
主要有3類特征可以被調整,以改善該模型的預測能力:
A. max_features:
隨機森林允許單個決策樹使用特征的最大數量。 Python為最大特征數提供了多個可選項。 下面是其中的幾個:
-
Auto/None :簡單地選取所有特征,每顆樹都可以利用他們。這種情況下,每顆樹都沒有任何的限制。
-
sqrt :此選項是每顆子樹可以利用總特征數的平方根個。 例如,如果變量(特征)的總數是100,所以每顆子樹只能取其中的10個。“log2”是另一種相似類型的選項。
-
0.2:此選項允許每個隨機森林的子樹可以利用變量(特征)數的20%。如果想考察的特征x%的作用, 我們可以使用“0.X”的格式。
max_features如何影響性能和速度?
增加max_features一般能提高模型的性能,因為在每個節點上,我們有更多的選擇可以考慮。 然而,這未必完全是對的,因為它降低了單個樹的多樣性,而這正是隨機森林獨特的優點。 但是,可以肯定,你通過增加max_features會降低算法的速度。 因此,你需要適當的平衡和選擇最佳max_features。
B. n_estimators:
在利用最大投票數或平均值來預測之前,你想要建立子樹的數量。 較多的子樹可以讓模型有更好的性能,但同時讓你的代碼變慢。 你應該選擇盡可能高的值,只要你的處理器能夠承受的住,因為這使你的預測更好更穩定。
C. min_sample_leaf:
如果您以前編寫過一個決策樹,你能體會到最小樣本葉片大小的重要性。 葉是決策樹的末端節點。 較小的葉子使模型更容易捕捉訓練數據中的噪聲。 一般來說,我更偏向于將最小葉子節點數目設置為大于50。在你自己的情況中,你應該盡量嘗試多種葉子大小種類,以找到最優的那個。
2.使得模型訓練更容易的特征
有幾個屬性對模型的訓練速度有直接影響。 對于模型速度,下面是一些你可以調整的關鍵參數:
A. n_jobs:
這個參數告訴引擎有多少處理器是它可以使用。 “-1”意味著沒有限制,而“1”值意味著它只能使用一個處理器。 下面是一個用Python做的簡單實驗用來檢查這個指標:
%timeit
model = RandomForestRegressor(n_estimator = 100, oob_score = TRUE,n_jobs = 1,random_state =1)
model.fit(X,y)
Output ———- 1 loop best of 3 : 1.7 sec per loop%timeit
model = RandomForestRegressor(n_estimator = 100,oob_score = TRUE,n_jobs = -1,random_state =1)
model.fit(X,y)
Output ———- 1 loop best of 3 : 1.1 sec per loop
“%timeit”是一個非常好的功能,他能夠運行函數多次并給出了最快循環的運行時間。 這出來非常方便,同時將一個特殊的函數從原型擴展到最終數據集中。
B. random_state:
此參數讓結果容易復現。 一個確定的隨機值將會產生相同的結果,在參數和訓練數據不變的情況下。 我曾親自嘗試過將不同的隨機狀態的最優參數模型集成,有時候這種方法比單獨的隨機狀態更好。
C. oob_score:
這是一個隨機森林交叉驗證方法。 它和留一驗證方法非常相似,但這快很多。 這種方法只是簡單的標記在每顆子樹中用的觀察數據。 然后對每一個觀察樣本找出一個最大投票得分,是由那些沒有使用該觀察樣本進行訓練的子樹投票得到。
下面函數中使用了所有這些參數的一個例子:
model = RandomForestRegressor(n_estimator = 100, oob_score = TRUE, n_jobs = -1,random_state =50,max_features = "auto", min_samples_leaf = 50)model.fit(x, y)
通過案例研究學習
我們以在以前的文章中經常提到泰坦尼克號為例。 讓我們再次嘗試同樣的問題。 這種情況下的目標是,了解調整隨機森林參數而不是找到最好的特征。 試試下面的代碼來構建一個基本模型:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import roc_auc_score
import pandas as pd
x = pd.read_csv("train.csv")
y = x.pop("Survived")
model = RandomForestRegressor(n_estimator = 100 , oob_score = TRUE, random_state = 42)
model.fit(x(numeric_variable,y)
print "AUC - ROC : ", roc_auc_score(y,model.oob_prediction)AUC - ROC:0.7386
這是一個非常簡單沒有參數設定的模型。 現在讓我們做一些參數調整。 正如我們以前討論過,我們有6個關鍵參數來調整。 我們有一些Python內置的的網格搜索算法,它可以自動調整所有參數。在這里讓我們自己動手來實現,以更好了解該機制。 下面的代碼將幫助您用不同的葉子大小來調整模型。
練習:試試運行下面的代碼,并在評論欄中找到最佳葉片大小。
sample_leaf_options = [1,5,10,50,100,200,500]for leaf_size in sample_leaf_options :model = RandomForestRegressor(n_estimator = 200, oob_score = TRUE, n_jobs = -1,random_state =50,max_features = "auto", min_samples_leaf = leaf_size)model.fit(x(numeric_variable,y)print "AUC - ROC : ", roc_auc_score(y,model.oob_prediction)
備注
就像是隨機森林,支持向量機,神經網絡等機器學習工具都具有高性能。 他們有很高的性能,但用戶一般并不了解他們實際上是如何工作的。 不知道該模型的統計信息不是什么問題,但是不知道如何調整模型來擬合訓練數據,這將會限制用戶使用該算法來充分發揮其潛力。 在一些后續的文章中,我們將討論其他機器學習算法,像支持向量機,GBM和neaural networks。






)


 ))



)


)


