文章目錄
- 問題一:python 2.7版本解決TypeError: 'encoding' is an invalid keyword argument for this function。
- 問題二:python讀取文件時提示"UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multibyte sequence"
- 情景一:
- 情景二:
- 問題三:python執行SQL報錯:not enough arguments for format string
- 問題四:輸出的信息為轉義碼
- 問題五:使用list的clear()方法時的注意點
- 問題六:Python下調用json.dumps中文顯示問題解決辦法
- 問題七:報錯:pymysql.err.OperationalError: (1040, 'Too many connections')
- 問題八:ValueError: invalid literal for int() with base 10: “”
- 問題九:解決python中TypeError: not enough arguments for format string
- 問題十:消除python中控制臺輸出的警告信息
- 問題十一:報錯:UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)
最近要頻繁的玩Python,在這里總結下遇到的一些問題,持續更新中。
問題一:python 2.7版本解決TypeError: ‘encoding’ is an invalid keyword argument for this function。
用Python2.7來打開一些文件的時候,經常出現以上的所表示的問題,如
data_file = open("F:\\MyPro\\data.yaml", "r", encoding='utf-8')
運行的時候報錯:TypeError: ‘encoding’ is an invalid keyword argument for this function。但在Py3中運行卻不會遇到這樣的問題。
解決辦法:網上查找一番后,改成如下這樣就可以搞定
import io
data_file = io.open("F:\\MyPro\\data.yaml", "r", encoding='utf-8')
至于原因根據報錯的信息看也許跟Py2和Py3的API規定不同有關吧。
問題二:python讀取文件時提示"UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x80 in position 205: illegal multibyte sequence"
情景一:
同樣是讀取文件時,碰到的編碼問題。
解決辦法:
FILE_OBJECT= open('order.log','r', encoding='UTF-8')
只需要加入對應的encoding參數就OK了,對于Python中的編碼問題,有時候也很麻煩。不過這類問題一般百度下就能找到對應的解決辦法。
情景二:
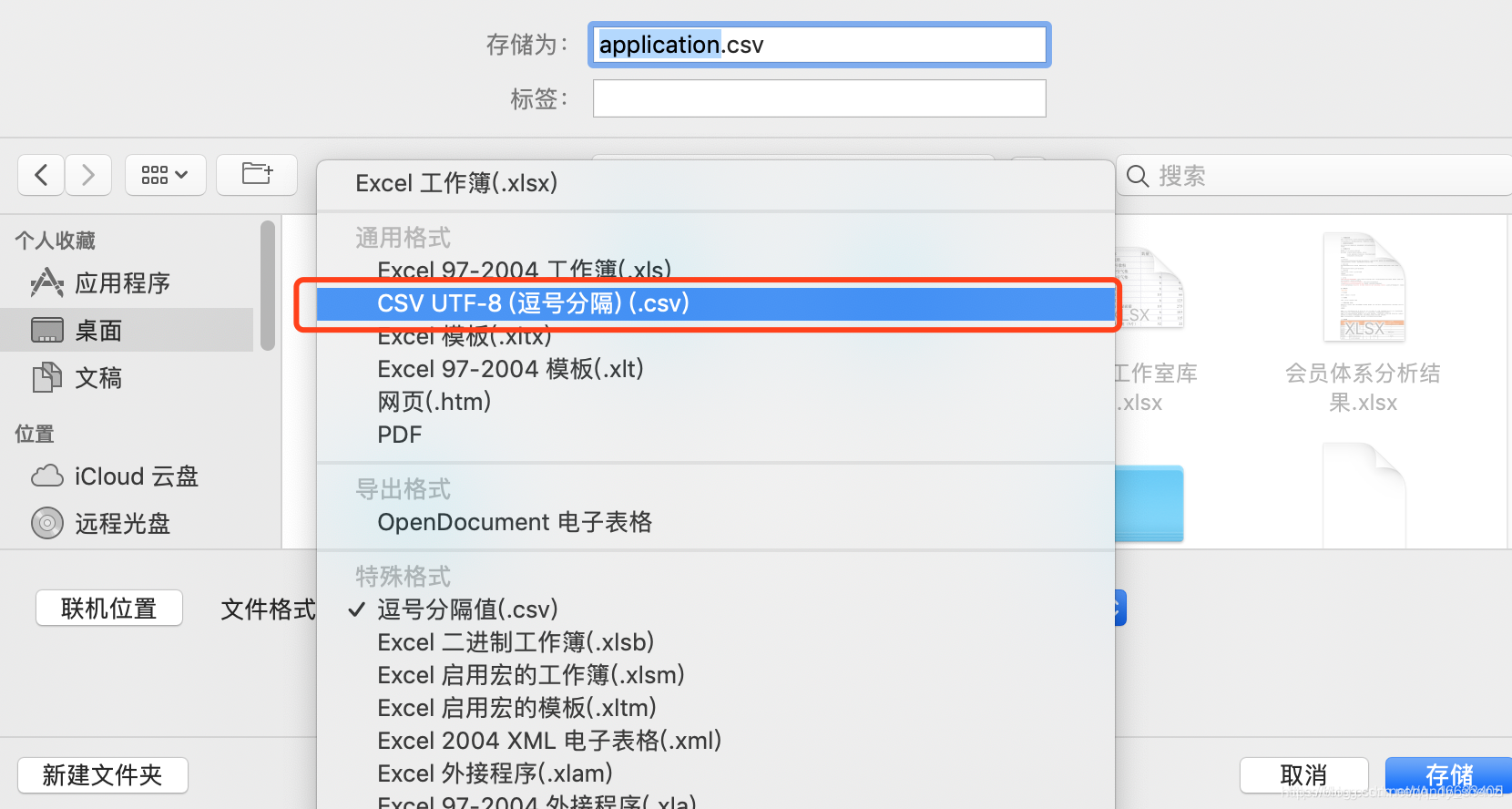
突然在用pandas讀取別人的.csv數據的時候出現了一種奇怪現象:用Python2的解釋器時可以讀取,用python3的解釋器卻無法讀取。報上面的錯誤,后來在方法中添加encoding參數依舊不可行,之后查閱資料才知道,原來是.csv文件本事的格式問題,首先確保你的.csv是utf8編碼(用notepad打開.csv文件查看文件編碼格式),其次要確保你的.csv在保存的時候也是.csv utf-8格式(可以再重新打開.csv文件再保存為.csv utf-8格式),如下圖所示:
問題三:python執行SQL報錯:not enough arguments for format string
在Python中執行SQL的查詢語句的時候爆出這樣的錯誤,如
sql='select * from Teacher where Tname like \'%%'+ keyword +'%%\''。后來才知道出現這類問題,主要是字符串中包含了%號,python 認為它是轉移符,而實際我們需要的就是%, 這個時候,可以使用%%來表示%,也就是說sql字符串中的百分號全都要用%%來表示。
問題四:輸出的信息為轉義碼
# ((u'01', u'\u5f20\u4e09'), (u'04', u'\u5f20\u4e09\u4e30')) # (u'01', u'\u5f20\u4e09')
這種情況也只有在Py2中才會出現,Py3中是不會出現的。
解決辦法:將輸出的轉義碼通過以下的eval方法轉化為對應的中文。
print(eval("u"+"\'"+exmple[1]+"\'"))問題五:使用list的clear()方法時的注意點
最近在寫一段如下代碼時:
for line in lines:# print(line)for x in jieba.lcut(line):# print(x)if x not in stopwords:text1.append(x)text2=text1corpora_documents.append(text2)# print(corpora_documents)text1.clear()
這里由于類型轉化問題不能采用簡便的方法來直接分詞并剔除停詞,所以只能用這種方式來實現相同的功能,但是在實現的過程中,原本期望返回的corpora_documents是下圖所示的效果:
但是卻得到了一組空的List。這讓博主很是郁悶(畢竟博主之前是寫Java的,面相對象的思想“根深蒂固”,以為聲明出來一個新的text2對象,就會開辟一塊新的內存空間來存儲text2的內容,這樣text1和text2也就是值傳遞了而非引用傳遞,可是這是java的內存加載機制。。。),不過后來隨著博主無意間將最后一行代碼改為:

text1=[]
得到了自己想要的結果,之后再分析原因的時候,發現博主沒有切換到Python的內存管理機制。其實整個過程對于Python來說內存管理如下:
for line in lines:# print(line)for x in jieba.lcut(line):# print(x)if x not in stopwords:text1.append(x)text2=text1#相當于將聲明的兩個對象的指針指向同一塊內存空間即text1所在的內存空間corpora_documents.append(text2)#Python采用的應該是延遲加載,也就是說這里corpora_documents只是將指針指向了text2的內存地址,并沒有直接就將text2里面的內容加載進來。# print(corpora_documents)text1.clear()#clear()就相當于擦除了text1中的內容,即text2指向了一個空的內容,由于Python延遲加載的特性也就造成了后面打印出來的corpora_documents的內容為空print(corpora_documents)
所以在使用clear()的時候一定要注意對象之間的關系,一不留神就會造成很大的損失。感覺這個問題好像在那本書中有提到,還得復習下基礎知識,很多問題只有不斷的Coding才能碰到,還是實踐太少,仍需繼續努力。
問題六:Python下調用json.dumps中文顯示問題解決辦法
最近在開發某個功能的時候,需要將前臺的信息返回到后天處理后,以json字符串的形式返回,但是返回的內容顯示在網頁中確實ASCII碼值,下面是這個問題的解決辦法:
配置下dumps方法中的ensure_ascii這個屬性!
data={"url":"http:www.dianwe.com","content":"采集Test","CreateTime":"2014-07-08 23:29"}
bizResult= json.dumps(data, ensure_ascii=False)
print(bizResult)
這樣便不會轉為Ascii 編號了!
問題七:報錯:pymysql.err.OperationalError: (1040, ‘Too many connections’)
mysql數據庫 Too many connections
出現這種錯誤明顯就是 mysql_connect 之后忘記 mysql_close;我的情況是實現了自動更新本地數據庫在測試的時候每次更新后又忘記關閉對應的connect,當大量的connect之后,就會出現Too many connections的錯誤,mysql默認的連接為100個。只需在代碼中添加對應的connect.close()方法即可。
問題八:ValueError: invalid literal for int() with base 10: “”
最近在寫代碼的時候,突然爆出這樣錯誤,根據字面意思是類型轉化的問題,但是仔細檢查了代碼,發現類型轉化沒有問題。無奈只能去求助度娘,很多博客也說是類型轉換的問題。以下是某博客的一個實驗:
>>> int('')
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: ''
>>>>>> int("x")
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'x'
從中可以看出這類錯誤就是字符無法轉換為int型。但是仍找不到對應的錯誤的位置在哪里,剛好看看到一個建議:“為了避免類似錯誤,以后進行int類型轉換時,注意檢查,或者直接加try 捕獲下”
# try:# print(int(re.sub("\D", "", x)))# except ValueError:# print("-"*40)# print("異常值"+x)
一查竟讓多出了一些nan值:
但是后來去和數據做比對的時候,實在是也沒有發現有什么nan值,這就很奇怪了,所以為了能讓程序跑下去,這里就先省去了這個int的強制變換。

問題九:解決python中TypeError: not enough arguments for format string
出現這類問題,主要是字符串中包含了%號,python 認為它是轉移符,而實際我們需要的就是%, 這個時候,可以使用%%來表示
問題十:消除python中控制臺輸出的警告信息
程序運行中經常會碰到python控制臺顯示警告提示SettingWithCopyWarning的信息,一般來說沒什么大事,但是當這些信息多了之后就會干擾你查看一些關鍵信息的效率,那么如何讓控制臺不提示這類告警呢?很簡單只需在代碼中添加以下兩行代碼即可:
import warnings
warnings.filterwarnings("ignore")
問題十一:報錯:UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 0: ordinal not in range(128)
使用python2.x的時候,即使在代碼頭部聲明了encoding=“utf-8”,但是程序執行的時候仍會報這個錯誤,這時候只需要在頭部添加如下代碼即可
import sys
reload(sys)
sys.setdefaultencoding('utf8')
ps:python3.x一般就不會出現這種情況!






)


》—第2章2.2節無處不在的二分搜索)
——jQuery插件開發與發布)


》——1.4 將Raspbian燒錄到SD卡)




2.3 理解ROS開源社區級)
