前言:
最近在實際工作中玩到了Azkaban,雖然之前有簡單的接觸,但是真正用到的時候,才能體會到這個工具的實用性有多強,總結下真個操作過程。在總結整個操作過程之前先簡單描述下工作流調度系統的優勢。
1、工作流調度系統的優勢
一個完整的數據分析系統通常都是由大量任務單元組成:
shell腳本程序,java程序,mapreduce程序、hive腳本等
- 各任務單元之間存在時間先后及前后依賴關系
- 為了很好地組織起這樣的復雜執行計劃,需要一個工作流調度系統來調度執行;
例如,我們可能有這樣一個需求,某個業務系統每天產生20G原始數據,我們每天都要對其進行處理,處理步驟如下所示:
- 通過Hadoop先將原始數據同步到HDFS上;
- 借助MapReduce計算框架對原始數據進行轉換,生成的數據以分區表的形式存儲到多張Hive表中;
- 需要對Hive中多個表的數據進行JOIN處理,得到一個明細數據Hive大表;
- 將明細數據進行復雜的統計分析,得到結果報表信息;
- 需要將統計分析得到的結果數據同步到業務系統中,供業務調用使用。
以上整個流程組成了我們的一個job,如果采用傳統的linux定時任務去處理這個流程的話,存在一個巨大的隱患,job失敗率很高,流程無法控制,沒有預警機制。所以類似的這種工作流調度器的工具就應運而生!
工作流調度實現方式:
簡單的任務調度:直接使用linux的crontab來定義;
復雜的任務調度:開發調度平臺或使用現成的開源調度系統,比如ooize、azkaban等
2、操作指南
2.1、首頁簡介
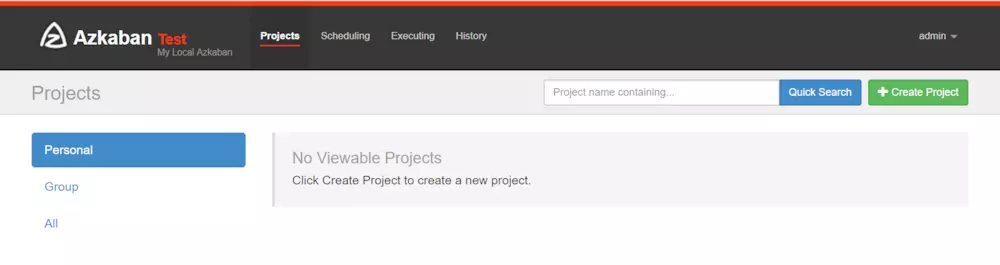
projects:最重要的部分,創建一個工程,所有flows將在工程中運行。
scheduling:顯示定時任務
executing:顯示當前運行的任務
history:顯示歷史運行任務
2.2、創建單一job
概念介紹
創建工程:創建之前我們先了解下之間的關系,一個工程包含一個或多個flows,一個flow包含多個job。job是你想在azkaban中運行的一個進程,可以是簡單的linux命令,可是java程序,也可以是復雜的shell腳本,當然,如果你安裝相關插件,也可以運行插件。一個job可以依賴于另一個job,這種多個job和它們的依賴組成的圖表叫做flow。
1、Command 類型單一 job 示例
- 首先創建一個工程,填寫名稱和描述
- 之后點擊完成后進入如下界面
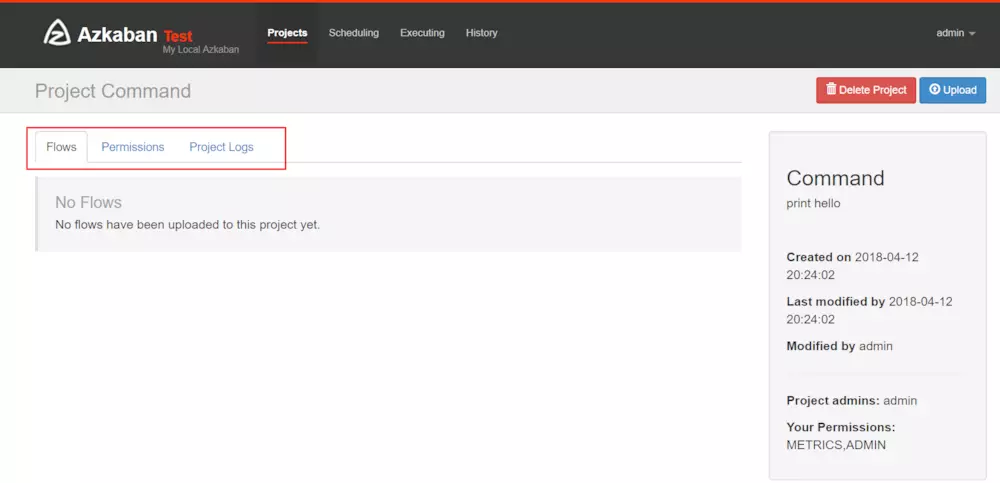
- Flows:工作流程,有多個job組成
- Permissions:權限管理
- Project Logs:工程日志
2、job的創建
創建job很簡單,只要創建一個以.job結尾的文本文件就行了,例如我們創建一個工作,用來打印hello,名字叫做command.job
command.job
type=command
command=echo 'hello'
一個簡單的job就創建好了,解釋下,type的command,告訴azkaban用unix原生命令去運行,比如原生命令或者shell腳本,當然也有其他類型,后面說。一個工程不可能只有一個job,我們現在創建多個依賴job,這也是采用azkaban的首要目的。
3、將 job 資源文件打包
注意:只能是zip格式
4、通過 azkaban web 管理平臺創建 project 并上傳壓縮包
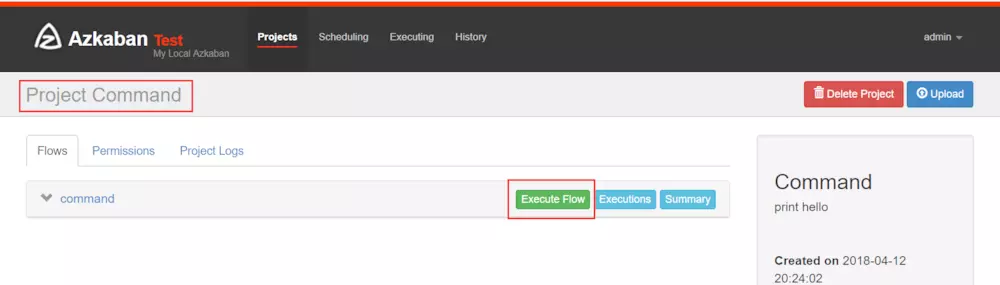
注意這里這里點擊Execute Flow后可以執行定時任務,也可立即執行
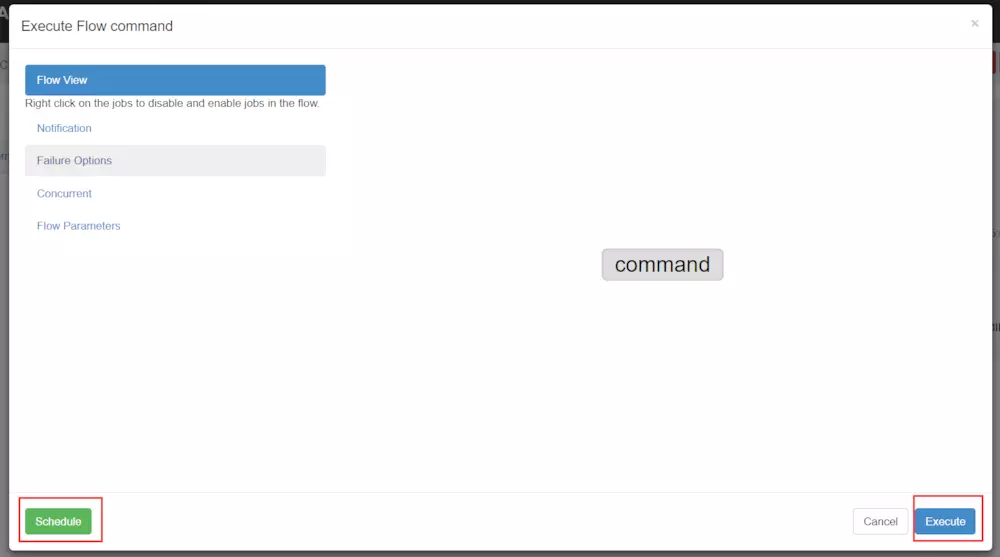
查看任務的執行情況
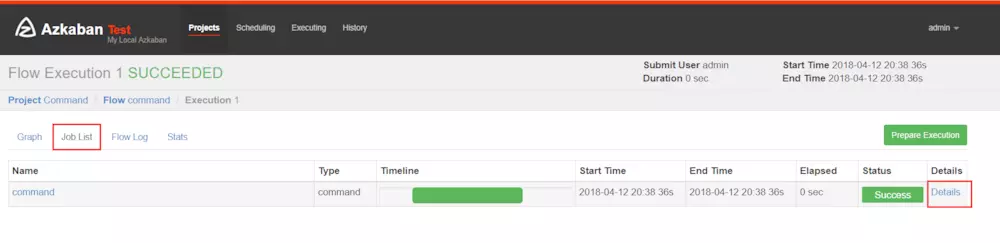
2.3、創建多job項目
我們說過多個jobs和它們的依賴組成flow。怎么創建依賴,只要指定dependencies參數就行了。比如導入hive前,需要進行數據清洗,數據清洗前需要上傳,上傳之前需要從ftp獲取日志。
定義5個job:
1、o2o_2_hive.job:將清洗完的數據入hive庫
2、o2o_clean_data.job:調用mr清洗hdfs數據
3、o2o_up_2_hdfs.job:將文件上傳至hdfs
4、o2o_get_file_ftp1.job:從ftp1獲取日志
5、o2o_get_file_fip2.job:從ftp2獲取日志
依賴關系:
3依賴4和5,2依賴3,1依賴2,4和5沒有依賴關系。
注意command寫成執行sh腳本,建議這樣做,后期只需維護腳本就行了(將python腳本放到shell腳本中執行便于維護),azkaban定義工作流程
o2o_2_hive.jobtype=command
# 執行sh腳本,建議這樣做,后期只需維護腳本就行了,azkaban定義工作流程
command=sh /job/o2o_2_hive.sh
dependencies=o2o_clean_data
retries=3 #失敗重試3次
retry.backoff=30000 #每次重試間隔,單位為毫秒o2o_clean_data.jobtype=command
# 執行sh腳本,建議這樣做,后期只需維護腳本就行了,azkaban定義工作流程
command=sh /job/o2o_clean_data.sh
dependencies=o2o_up_2_hdfso2o_up_2_hdfs.jobtype=command#需要配置好hadoop命令,建議編寫到shell中,可以后期維護
command=hadoop fs -put /data/*
#多個依賴用逗號隔開
dependencies=o2o_get_file_ftp1,o2o_get_file_ftp2o2o_get_file_ftp1.jobtype=command
command=wget "ftp://file1" -O /data/file1o2o_get_file_ftp2.job
type=command
command=wget "ftp:file2" -O /data/file2
| 配置郵件接收者:在任務流Flow的最后一個.job中文件中添加如下內容 |
#任務執行失敗發送郵件,多個接收郵件人之間用“,”分隔
failure.emails=AAAAAAA@126.com,BBBBB@163.com
#任務執行成功發送郵件
success.emails=AAAAA@126.com
#任務執行完成,無論成功還是失敗發送郵件
notify.emails=BBBBBBB@126.com
可以運行unix命令,也可以運行python腳本(強烈推薦)。將上述job打成zip包。
效果圖(可以在下圖中點擊每個job,再次編輯job中的內容)
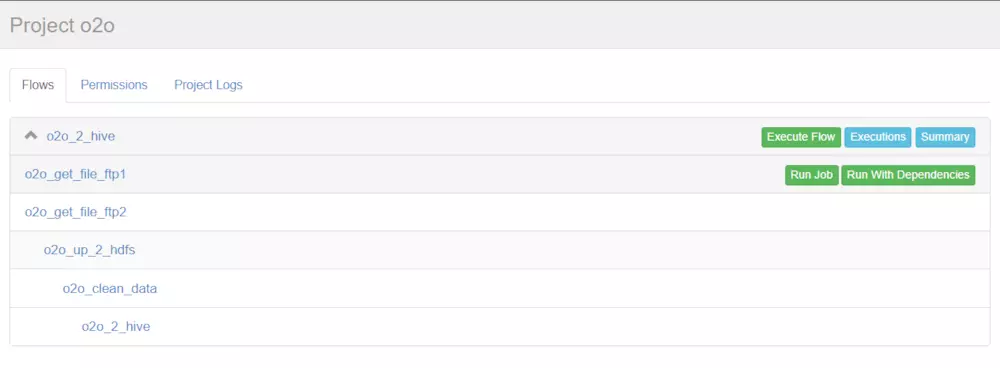
點擊o2o_2_hive進入流程,azkaban流程名稱以最后一個沒有依賴的job定義的。查看各個job間的依賴關系

下圖是配置執行當前流程或者執行定時流程。
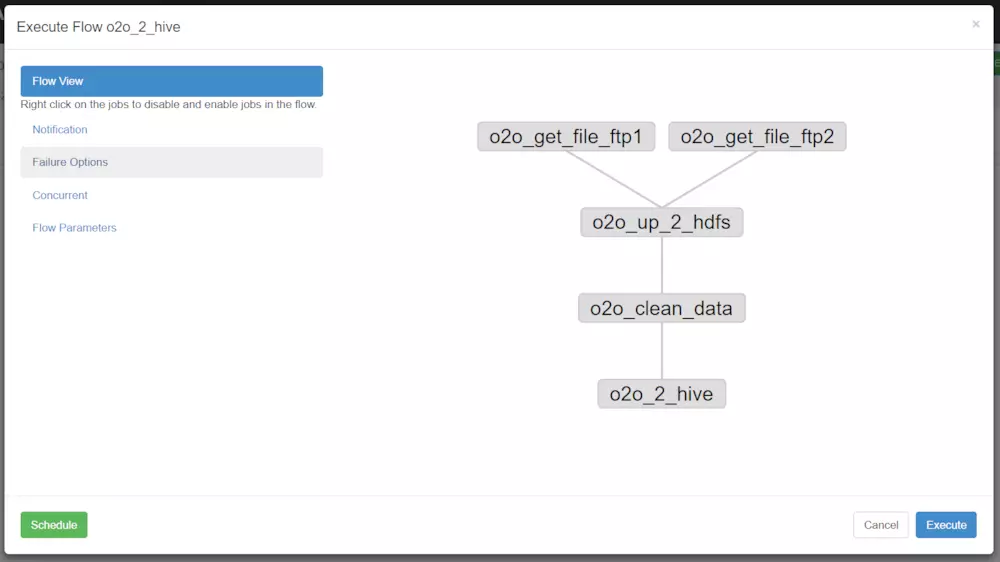
| 說明 |
Flow view:流程視圖。可以禁用,啟用某些job(這里想要單獨運行某個job時,可以操作隱藏其他的依賴job)
Notification:定義任務成功或者失敗是否發送郵件
Failure Options:定義一個job失敗,剩下的job怎么執行
Concurrent:并行任務執行設置
Flow Parametters:參數設置。
參考:https://blog.csdn.net/aizhenshi/article/details/80828726
參考:https://www.jianshu.com/p/3b78164477e8


![導入Anaconda中的第三方庫運行時報錯:ImportError: Missing required dependencies ['pandas']](http://pic.xiahunao.cn/導入Anaconda中的第三方庫運行時報錯:ImportError: Missing required dependencies ['pandas'])



)












