背景
在實時計算平臺上通過YarnClient向yarn上提交flink任務時一直卡在那里,并在client端一直輸出如下日志:
(YarnClusterDescriptor.java:1036)- Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster看到這個的第一反應是yarn上的資源分配問題,于是來到yarn控制臺,發現Cluster Metrics中Apps Pending項為1。what?新提交的job為什么會處于pending狀態了?
1. 先確定cpu和內存情況如下:

可以看出cpu和內存資源充足,沒有發現問題。
2. 查看調度器的使用情況
集群中使用的調度器的類型如下圖:

可以看到,集群中使用的是Capacity Scheduler調度器,也就是所謂的容量調度,這種方案更適合多租戶安全地共享大型集群,以便在分配的容量限制下及時分配資源。采用隊列的概念,任務提交到隊列,隊列可以設置資源的占比,并且支持層級隊列、訪問控制、用戶限制、預定等等配置。但是,對于資源的分配占比調優需要更多的經驗處理。但它不會出現在使用FIFO Scheduler時會出現的有大任務獨占資源,會導致其他任務一直處于 pending 狀態的問題。
3. 查看任務隊列的情況
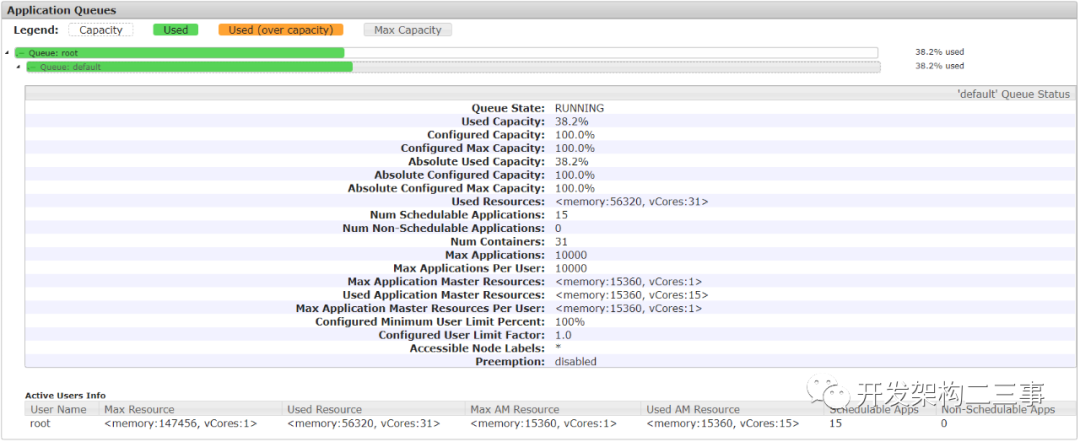
從上圖中可以看出Configured Minimum User Limit Percent的配置為100%,由于集群目前相對較小,用戶隊列沒有做租戶劃分,用的都是default隊列,從圖中可以看出使用的容量也只有38.2%,隊列中最多可存放10000個application,而實際的遠遠少于10000,貎似這里也看不出來什么問題。
4. 查看resourceManager的日志
日志內容如下:
2020-11-26 19:33:46,669 INFO org.apache.hadoop.yarn.server.resourcemanager.ClientRMService: Allocated new applicationId: 3172020-11-26 19:33:48,874 INFO org.apache.hadoop.yarn.server.resourcemanager.ClientRMService: Application with id 317 submitted by user root2020-11-26 19:33:48,874 INFO org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl: Storing application with id application_1593338489799_03172020-11-26?19:33:48,874?INFO?org.apache.hadoop.yarn.server.resourcemanager.RMAuditLogger:?USER=root????IP=x.x.x.x????OPERATION=Submit?Application?Request????TARGET=ClientRMService????RESULT=SUCCESS????APPID=application_1593338489799_03172020-11-26 19:33:48,874 INFO org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl: application_1593338489799_0317 State change from NEW to NEW_SAVING on event=START2020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.recovery.RMStateStore: Storing info for app: application_1593338489799_03172020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl: application_1593338489799_0317 State change from NEW_SAVING to SUBMITTED on event=APP_NEW_SAVED2020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.ParentQueue: Application added - appId: application_1593338489799_0317 user: root leaf-queue of parent: root #applications: 162020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler: Accepted application application_1593338489799_0317 from user: root, in queue: default2020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl: application_1593338489799_0317 State change from SUBMITTED to ACCEPTED on event=APP_ACCEPTED2020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.ApplicationMasterService: Registering app attempt : appattempt_1593338489799_0317_0000012020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptImpl: appattempt_1593338489799_0317_000001 State change from NEW to SUBMITTED2020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.LeafQueue: not starting application as amIfStarted exceeds amLimit2020-11-26 19:33:48,877 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.LeafQueue: Application added - appId: application_1593338489799_0317 user: org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.LeafQueue$User@6c0d5b4d, leaf-queue: default #user-pending-applications: 1 #user-active-applications: 15 #queue-pending-applications: 1 #queue-active-applications: 15從日志中可以看到一個Application在yarn上進行資源分配的完整流程,只是這個任務因為一些原因進入了pending隊列而已,與我們要查找的問題相關的日志主要是如下幾行:
2020-11-26 19:33:48,875 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.LeafQueue: not starting application as amIfStarted exceeds amLimit2020-11-26 19:33:48,877 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.LeafQueue: Application added - appId: application_1593338489799_0317 user: org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.LeafQueue$User@6c0d5b4d, leaf-queue: default #user-pending-applications: 1 #user-active-applications: 15 #queue-pending-applications: 1 #queue-active-applications: 15沒錯,問題就出來not starting application as amIfStarted exceeds amLimit,那么這個是什么原因引起的呢,我們看下stackoverflow[1]上的解釋:

那么yarn.scheduler.capacity.maximum-am-resource-percent參數的真正含義是什么呢?國語意思就是集群中可用于運行application master的資源比例上限,這通常用于限制并發運行的應用程序數目,它的默認值為0.1。
查看了下集群上目前的任務總數有15個左右,每個任務分配有一個約1G左右的jobmanager(jobmanager為Application master類型的application),占15G左右,而集群上的總內存為144G,那么15>144 * 0.1 ,從而導致jobmanager的創建處于pending狀態。
5. 解決驗證
修改capacity-scheduler.xml的yarn.scheduler.capacity.maximum-am-resource-percent配置為如下:
yarn.scheduler.capacity.maximum-am-resource-percent 0.5 除了動態減少隊列數目外,capacity-scheduler.xml的其他配置的修改是可以動態更新的,更新命令為:
yarn rmadmin -refreshQueues執行命令后,在resourceManager的日志中可以看到如下輸出:
2020-11-27 09:37:56,340 INFO org.apache.hadoop.conf.Configuration: found resource capacity-scheduler.xml at file:/work/hadoop-2.7.4/etc/hadoop/capacity-scheduler.xml2020-11-27 09:37:56,356 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler: Re-initializing queues...---------------------------------------------------------------------------2020-11-27 09:37:56,371 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler: Initialized queue mappings, override: false2020-11-27 09:37:56,372 INFO org.apache.hadoop.yarn.server.resourcemanager.RMAuditLogger: USER=root IP=x.x.x.x OPERATION=refreshQueues TARGET=AdminServicRESULT=SUCCESS仔細查看日志可以看到更新已經成功,在平臺上重新發布任務顯示成功,問題解決。
yarn Queue的配置
Resource Allocation
| Property | Description |
yarn.scheduler.capacity..capacity | Queue capacity in percentage (%) as a float (e.g. 12.5) OR as absolute resource queue minimum capacity. The sum of capacities for all queues, at each level, must be equal to 100. However if absolute resource is configured, sum of absolute resources of child queues could be less than it’s parent absolute resource capacity. Applications in the queue may consume more resources than the queue’s capacity if there are free resources, providing elasticity. |
yarn.scheduler.capacity..maximum-capacity | Maximum queue capacity in percentage (%) as a float OR as absolute resource queue maximum capacity. This limits the elasticity for applications in the queue. 1) Value is between 0 and 100. 2) Admin needs to make sure absolute maximum capacity >= absolute capacity for each queue. Also, setting this value to -1 sets maximum capacity to 100%. |
yarn.scheduler.capacity..minimum-user-limit-percent | Each queue enforces a limit on the percentage of resources allocated to a user at any given time, if there is demand for resources. The user limit can vary between a minimum and maximum value. The former (the minimum value) is set to this property value and the latter (the maximum value) depends on the number of users who have submitted applications. For e.g., suppose the value of this property is 25. If two users have submitted applications to a queue, no single user can use more than 50% of the queue resources. If a third user submits an application, no single user can use more than 33% of the queue resources. With 4 or more users, no user can use more than 25% of the queues resources. A value of 100 implies no user limits are imposed. The default is 100. Value is specified as a integer. |
yarn.scheduler.capacity..user-limit-factor | The multiple of the queue capacity which can be configured to allow a single user to acquire more resources. By default this is set to 1 which ensures that a single user can never take more than the queue’s configured capacity irrespective of how idle the cluster is. Value is specified as a float. |
yarn.scheduler.capacity..maximum-allocation-mb | The per queue maximum limit of memory to allocate to each container request at the Resource Manager. This setting overrides the cluster configuration?yarn.scheduler.maximum-allocation-mb. This value must be smaller than or equal to the cluster maximum. |
yarn.scheduler.capacity..maximum-allocation-vcores | The per queue maximum limit of virtual cores to allocate to each container request at the Resource Manager. This setting overrides the cluster configuration?yarn.scheduler.maximum-allocation-vcores. This value must be smaller than or equal to the cluster maximum. |
yarn.scheduler.capacity..user-settings..weight | This floating point value is used when calculating the user limit resource values for users in a queue. This value will weight each user more or less than the other users in the queue. For example, if user A should receive 50% more resources in a queue than users B and C, this property will be set to 1.5 for user A. Users B and C will default to 1.0. |
Resource Allocation using Absolute Resources configuration
CapacityScheduler?supports configuration of absolute resources instead of providing Queue?capacity?in percentage. As mentioned in above configuration section for?yarn.scheduler.capacity..capacity?and?yarn.scheduler.capacity..max-capacity, administrator could specify an absolute resource value like?[memory=10240,vcores=12]. This is a valid configuration which indicates 10GB Memory and 12 VCores.
Running and Pending Application Limits
The?CapacityScheduler?supports the following parameters to control the running and pending applications:
| Property | Description |
yarn.scheduler.capacity.maximum-applications?/?yarn.scheduler.capacity..maximum-applications | Maximum number of applications in the system which can be concurrently active both running and pending. Limits on each queue are directly proportional to their queue capacities and user limits. This is a hard limit and any applications submitted when this limit is reached will be rejected. Default is 10000. This can be set for all queues with?yarn.scheduler.capacity.maximum-applications?and can also be overridden on a per queue basis by setting?yarn.scheduler.capacity..maximum-applications. Integer value expected. |
yarn.scheduler.capacity.maximum-am-resource-percent?/?yarn.scheduler.capacity..maximum-am-resource-percent | Maximum percent of resources in the cluster which can be used to run application masters - controls number of concurrent active applications. Limits on each queue are directly proportional to their queue capacities and user limits. Specified as a float - ie 0.5 = 50%. Default is 10%. This can be set for all queues with?yarn.scheduler.capacity.maximum-am-resource-percent?and can also be overridden on a per queue basis by setting?yarn.scheduler.capacity..maximum-am-resource-percent |
更多配置
參考:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
附
如果想要不重啟集群來動態刷新hadoop配置可嘗試如下方法:
1、刷新hdfs配置
在兩個(以三節點的集群為例)namenode節點上執行:
hdfs dfsadmin -fs hdfs://node1:9000 -refreshSuperUserGroupsConfigurationhdfs dfsadmin -fs hdfs://node2:9000 -refreshSuperUserGroupsConfiguration2、刷新yarn配置
在兩個(以三節點的集群為例)namenode節點上執行:
yarn rmadmin -fs hdfs://node1:9000 -refreshSuperUserGroupsConfigurationyarn rmadmin -fs hdfs://node2:9000 -refreshSuperUserGroupsConfiguration參考
?https://stackoverflow.com/questions/33465300/why-does-yarn-job-not-transition-to-running-state?https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html?https://stackoverflow.com/questions/29917540/capacity-scheduler?https://cloud.tencent.com/developer/article/1357111?https://cloud.tencent.com/developer/article/1194501
References
[1]?stackoverflow:?https://stackoverflow.com/questions/33465300/why-does-yarn-job-not-transition-to-running-state






(轉載))
詳解)



)




)


