cpu執行程序的基本過程
- 譯碼器 輸入為n管腳,輸出為2^n根管腳,編號為從0到2^(n-1),用少的輸入端控制更多的輸出端
- 最常用的是三八譯碼器
- AD(Address bus)地址總線: 選中一行數據
- 每一行 8bit 組成8吧B cpu輸入端32根線,輸出端就可以控制 2^32 ,因此可以控制4G內存
- DB(Data bus)數據總線: 8根數據線組成數據總線,確定了每一列,通過行和列將1B數據數據通過數據總線傳輸到cpu內部的寄存器里面,使用R表示寄存器
- 程序最終是一條一條被讀入寄存器內執行的(有限 ,且按照功能進行分類,有通用寄存器和特殊寄存器,特殊寄存器只能被特殊的指令訪問,)用戶態(訪問通用寄存器) <=> 內核態(訪問特殊寄存器和通用寄存器)
- 內存條是一個臨時的保存中介
- 磁盤是一個永久的保存中介
- 地址總線的選中原理 (譯碼器原理)
- 了解四大類存儲器的速度和所處的位置? 容量大小
- 寄存器 (cpu內部)> cache(cpu內部) > 內存卡 (cpu外部)> 磁盤(cpu外部)
- 寄存器只會保存數據;cache也需要將數據拷貝到寄存器里面執行
- ALU 算數邏輯運算單元 負責運算
- 舉一個例子 計算機計算 3+2 計算器讀取3 將3讀到R1寄存器,然后讀+,ALU會讀+,因為+需要兩個數,因此通過地址總線形成地址,將2讀到R2寄存器,計算,通過R1和R2取數據,然后將數據計算結果存到寄存器R3,然后找地址,將數據結果存儲到內存的一個位置,(寫回內存)。


CPU位數 OS位數 內存地址總線數 內存數據總線數 邏輯地址位數 物理地址位數
- cpu位數 和 寄存器的位數相關,如果寄存器的個數是32則cpu是32位;如果寄存器個數是64則cpu是64位。
- 32位的寄存器可以處理2^32大小的數據;64位的寄存器可以處理2^64大小的數據
- os位數(操作系統的位數):硬件限制軟件;軟件可以自定義(軟件分成32位或者64位);os位數等價于邏輯地址的位數,二者相等。也等價于虛擬內存的理論大小。
- 32位cpu只可以安裝32位操作系統;64位cpu既可以安裝32位也可以安裝64位操作系統
- 數據總線數 如果是8根 如果傳輸32位數據,需要傳輸4次;64位 傳輸數據 需要8次;現實生活中有 8 、16 、32 和 64根數據總線
- 數據總線:一般考研常規使用的是8根數據總線 ,每次可以傳輸8位數據,如果寄存器的大小是32,需要傳輸4次將數據填滿一個寄存器;如果是64位寄存器,需要傳輸8次將數據填滿一個寄存器
- 可訪問內存的大小 + 磁盤大小 大于等于 虛擬內存的實際大小
- 虛擬內存理論大小 大于等于 虛擬內存實際大小
- 但是現實生活中有 16位 32位 64位數據總線
- 物理地址總線數 (物理地址總線數):比如上面的例子中,地址總線有32位,每一個地址是由32位0或者1組成,從硬件限制可訪問內存的大小。這里屬于1,硬件限制,限制了可訪問內存的大小。比如電腦是32位的,那么根據可以訪問的物理地址總線,有0-2^32-1,也就是4G的內存,即使安裝8G的內存條,剩余的空間是無法訪問的。
- 或者2,內存卡限制,比如32位機器安裝2G內存卡,剩余的空間無法訪問
- 或者3,軟件限制,比如譯碼器原理,限制輸入端輸入的位數,限制輸出端可以訪問的地址
- 三個限制 ,取最小值作為可訪問的內存大小
- 邏輯地址 是將程序從磁盤拷貝到內存,可以拷貝最大的行數,這個和操作系統的位數有很大的關系

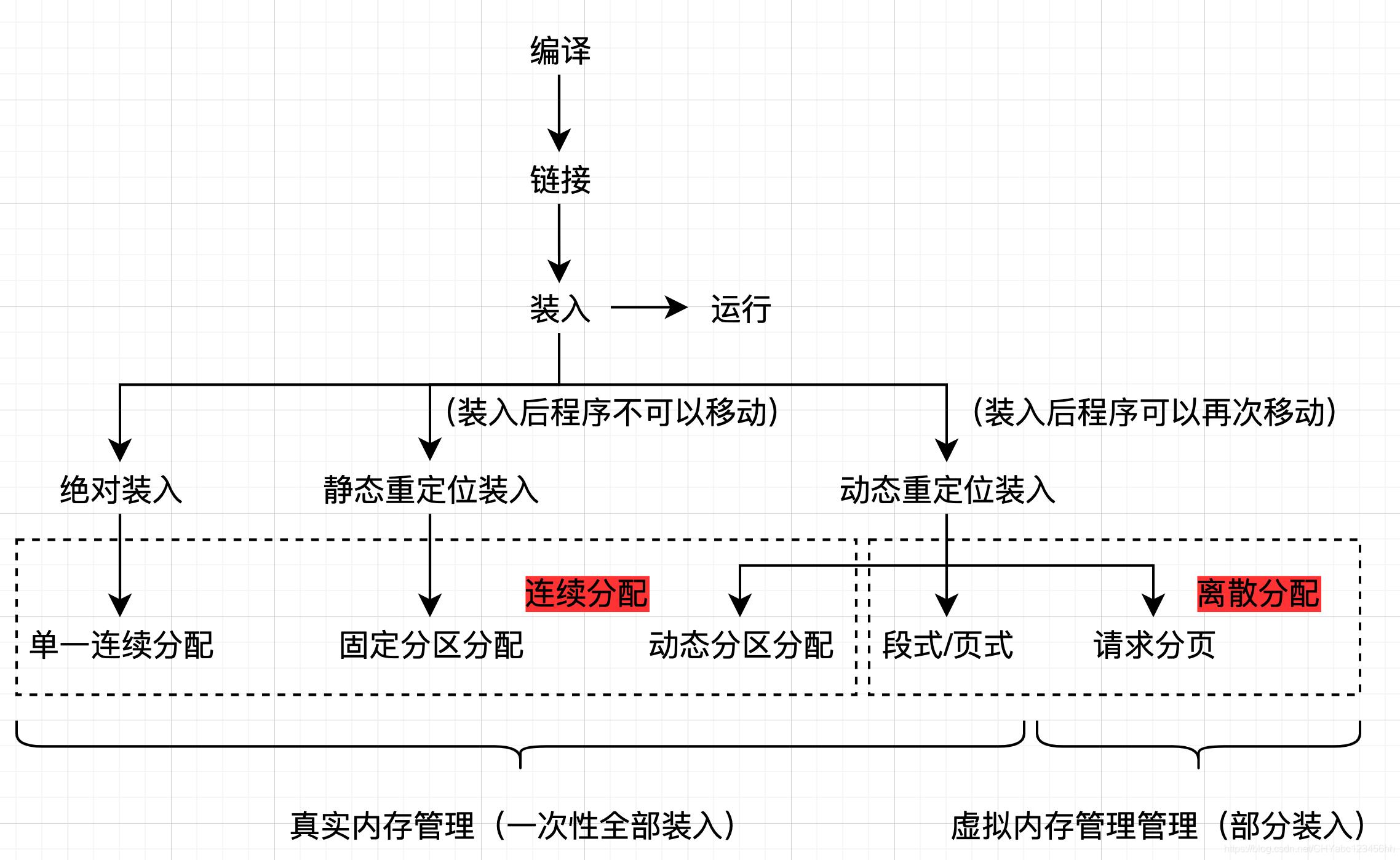
內存管理邏輯圖
- 程序經過編譯和鏈接形成exe程序,從磁盤將程序裝入內存執行,進行程序的運行
- 裝入?1,如何裝入?2,裝在哪里?(1)記錄 (表格)? (2) 查詢 (表格)
編譯和鏈接
- 編譯,將C語言轉化為匯編語言,機器語言
- 各個模塊的邏輯地址,邏輯地址也叫做相對地址
- 鏈接 ,將多個有交集的匯編語言、機器語言合并到一起,會改變先前的邏輯地址,經過編譯鏈接之后形成可執行文件
- LOAD 1,6? 將第六行的變量加到寄存器1里面;ADD 1,8 將第8行變量和寄存器1里面的數據相加;STORE 1,10 將計算的結果(寄存器1中的數據)存儲到第10行變量C
- 匯編 每一行指令占據兩行,匯編使用邏輯地址指向變量

裝入
- 如果隨意裝入程序,cpu可能無法找到每一條執行程序。因為編譯的代碼所使用的的指令是相對本程序而言的,比如 LOAD 1,6;是將第六行的變量放入到寄存器1里面,而cpu會將整個內存條的起始位置作為程序的開始位置,因此,對這個命令使用的位置6和整個內存條的位置6是沖突的,形成地址錯位。
- 地址錯位 本質上是由于 邏輯地址和物理地址不匹配 造成的沖突;
- 物理地址是絕對的;邏輯地址是相對的
- 將程序從磁盤 拷貝到 內存 ,其邏輯地址會發生變化,指令后面所使用的相對地址也要隨之變化,才可以運行。
- 程序編譯使用的是邏輯地址(相對地址);內存卡使用的是物理地址(絕對地址)。
- OS位數和邏輯地址的位數 是等價的。如果程序編譯很長,超出位數的代碼無法識別,不可以超過機器程序(2^操作系統的位數)的大小。
- C語言中 函數名字和變量名字本質上都是地址
- 解決方案 :1,絕對裝入;2,靜態重定位裝入;3,動態重定位裝入

解決虛擬地址和物理地址錯位的三種方法
1,絕對裝入
- 裝入前就確定好程序的裝入位置,使得程序邏輯地址和物理地址對齊,不錯位
- 開發程序的時候就指定我要從? 指定的位置上編譯程序,比如我的程序執行需要將程序拷貝到內存的第1000行以后,這樣內存地址和物理地址一一對齊,不會錯位
- 那么這個程序每次運行永遠拷貝到指定的位置
2,靜態重定位裝入
- 裝入時候,動態指定將程序裝入的位置,由裝入程序的邏輯地址進行一次性修改,從而避免錯位。每拷貝一行就改變一行中的地址,從而避免錯位(邊裝入邊修改)
- 如果不指定,都是默認從0開始作為起始地址
- 那么每次執行的程序的邏輯地址都是不同的,這個地址是裝入前動態設置的,因此是 重定位 的概念
- 靜態是指,這個程序一旦加載到內存,地址就指定了,就不可以改變了;要想移動,只可以關閉程序,重新指定程序的起始位置
3,動態重定位裝入
- 程序運行的時候,利用重定位寄存器來彌補作用,讓cpu認為邏輯地址和物理地址是對齊的,不錯位
- 將程序原封不動拷貝到內存,此時邏輯地址和物理地址是存在一個錯位。程序拷貝到內存會創建一個pcb,存儲相關信息,其中入口地址,指定程序拷貝到內存的位置。
- 利用CPU內部的重定位寄存器,存儲上述提到的內存位置。每次運行的時候,會在指令的后面 異步加上內存的位置,補齊邏輯地址和物理地址之間的錯位。
- 如果程序變化,程序直接移動,直接修改pcb和重定位寄存器里面數值就可以讓邏輯地址和程序地址對齊
內存保護
- 也叫做越界保護
- 內存保護 由 硬件和os操作系統共同保障
- 實現方法:
- 1,上下限寄存器,比如木馬程序拷貝到內存中的1000到2000行,那么下限是1000,上限是2000,如果內部程序想訪問3500,和上下限對比,不符合,因此報錯
- 2,基址寄存器(重定位) + 限長寄存器(界地址);告訴首地址,通過限長寄存器得到程序的占用空間,因此得到程序的上限

單一連續內存分配
- 內存卡分為系統區(os操作系統)和用戶區(操作軟件)
- 用戶區每次只可以裝入一個程序
- 特點:
- 1,單用戶 單任務
- 2,內存卡利用率極低 因為有內部碎片,程序只用到了一部分
- 3,通常采用絕對裝入的方式
固定分區分配
- 裝入多道程序?
- 克服單一連續分配只可以裝入一個程序的缺點,在用戶區進行劃分,每個區塊分配不同的程序
- 劃分可以都相等 或者 每個區塊的大小不一樣,減少浪費
- 特點:
- 1,用戶區分成很多小的分區,每個分區只裝入一道程序
- 2,分區的大小很有講究,太小裝不進程序;太大內存利用率低
- 3,有內部碎片(內部碎片:內存分給你了,你沒有合理使用內存,就叫內部碎片)
- *外部碎片:內存空間除去分給程序的各個分區之后,剩余的空間不足以放下任何程序,這個剩余的空間不屬于任何程序,叫做外部碎片
- 需要分區說明表 記錄分區號 分區的大小 起始位置 狀態
- 提交程序的時候,查看哪一塊內存是空閑的
- 一般使用靜態重定位技術

動態程序分配
- 解決固定固定分區提前設定分區大小的弊端,進程程序要多少給你多少,不多分配不少分配。
- 如果用戶區間只剩下2MB不足以分配程序,那么需要等待先前程序釋放資源,比如qq退出,釋放了8MB的內存空間,lol立刻占用這8MB中的6MB,剩余2MB,這2MB就是外部碎片
- 由于程序的進進出出,導致的碎片數量越來越多,空間越來越小。進行碎片合并。將很多碎片合并在一起,形成一個大的區間,這個合并過程是一個隨機的事件
- 需要使用緊湊的技術,較少外部碎片,碎片的 移動? 合并,這個移動就涉及到了動態重定位
- 動態分區 需要分區說明表,每一塊分區的大小不確定,動態變化
- 如果一個程序加入內存,但是有很多區塊都可以存放數據,那么這個這個程序如何存放呢??
- 動態分區算法:
- 1,首次適應:從內存區間頭部開始,第一次可以存放的位置
- 2,最佳適應:從內存區間頭部開始,找一個盡可能不浪費的區塊;但這個并不是最佳的,反而會產生更多小的碎片,不可用,只能使用緊湊技術合并更多的碎片
- 3,最壞適應:從內存區間頭部開始,找一個最大的區塊;產生的碎片不會很小,反而可以給其他程序使用,因此不一定是最壞適應
- 4,鄰邊適應:每次找合適的區塊不是從頭開始,而是從上一次的位置開始往下找

覆蓋技術
- 軟件運行有128kb,要在64kb的內存上運行,覆蓋技術要求程序員在設計程序的時候,設計每個程序的啟動的先后順序,將內部分區分為固定區,存儲主程序;覆蓋區用于代碼之間的運行、覆蓋。
- 特色:
- 1,用在同一個程序進程中
- 2,覆蓋技術實現了小內存運行大程序,但是這不是萬能的
- 3,對程序員要求高 ,考慮性能
交換技術
- 交換技術發生在內存緊張的情況下
- 交換技術主要用于不同進程(程序)之間
- 覆蓋技術已經過時,交換技術仍然存在
- 將處于阻塞狀態下的程序拷貝到交換區域,將需要運行的程序拷貝進入內存區,交換是指內存和磁盤之間的交換

分頁
基本分頁存儲
- 先前使用的固定分區分配產生內部碎片,動態分區分配會產生外部碎片。
- 每個碎片可能很小,但是積少成多,總和是一個不小的浪費
- 分散分配:將大的程序進行拆分變成很多的小的碎片,每個碎片分別拷貝到內部或者外部產生的碎片中。
- 但是以什么作為標準進行切分呢??大小不等,切片很難。因此引入分頁思想,都切成一樣大小的
- 特色:
- 1,程序可以被切塊
- 2,內存也可以被切塊
- 3,切塊越小,浪費越小
- 因為碎片的大小是隨機產生的,因此對程序的切片不好處理,思路很簡單,實現很難
如何分頁
- 將內存卡(物理地址)和軟件程序(邏輯地址)都等分成4kb,然后將軟件程序的拷貝到內存卡上面執行,程序的大小和物理內存的分塊大小都一致,但是如果不可以整除,會有部分浪費,但是這種浪費很小。
- 內存、磁盤、程序都會被切塊,內存卡的一塊叫做 頁框(頁幀)
- 程序的片段叫做頁面,頁面可以被裝入頁框中
- 磁盤的分塊叫做 磁盤塊
- 磁盤 程序 和 內存 都按照4kb進行切割,這樣程序導入 磁盤和內存都很方便;切片的大小需要符合2的指數,2^0 = 1; 2^2 = 4;? 2^4 = 16;
- 為什么分塊使用4kb??這個不確定,有1Kb、16kb和32kb,4kb最常用,都是2的n次方的整數倍
- 設置mmu,就可以實現對內存、程序和磁盤的kb大小的選擇,切換1kb、4kb和16kb
頁表
- 內存卡的分塊編號,從0開始排序,其編號也叫做物理塊號、頁框號、頁幀號
- 程序 切分,也會進行編號,從0開始,其編號叫做頁號、頁面號
- 將內存卡切分的編號和程序切分的編號對應起來,叫做頁表。這個頁表存儲在內存中,每個進程都有自己的頁表。創建進程的同時會創建pcb,pcb會存儲這個頁表的信息,從而讓操作系統找到這個頁表
- 頁表有倆列,好多行,第一列存儲頁號,存儲邏輯地址;第二列存儲物理塊號,也是物理地址
- 頁表項 是 頁表的一行
- 頁表 通過pcb被查詢到
- 頁表只能記錄塊和塊之間的映射關系,4kb 可以存儲很多的代碼,因此不會得到每一行代碼在哪一塊中的哪一行等相關信息

頁表、物理地址、邏輯地址三者之間的關系
- 數學關系
- 二進制向左移1位表示十進制除以2
- 人類視角? 十進制 整除取整為頁號;求余為業內偏移
- 機器視角? 二進制 高位為頁號;低位為業內偏移
- 32位 以4k作為一個頁,4k = 2^12 因此,低12位作為頁內偏移,12到32位作為頁號;讀高20位得到哪一頁(頁號),讀低12位知道屬于哪一行(業內偏移)


- ?通過邏輯地址 -> 頁表(頁號) -> 通過頁表里面的邏輯地址和物理地址的對應關系,找到物理塊號,將物理塊號 和 業內偏移合并在一起就得到了物理地址
- 邏輯地址和物理地址里面的業內偏移 是一一對應的,因為把程序切片拷貝到內存,代碼里面的地址是相對的,起始到終止的差距就是業內偏移。物理塊號代表這個物理塊開始的地址,加上這個代碼的業內偏移,也就是物理塊結束的地址。
- 編號為何從0開始?整除取整直接得到頁號
基本分頁 基本地址變換機構
- 對邏輯地址進行上面的操作,就可以得到頁號,通過頁號查詢頁表,查詢到某一頁程序被裝載到內存中哪一個物理塊里面,查詢到物理塊之后和業內偏移量拼接在一起,構成一個物理地址
- 上面這些需要使用到地址變換機構,才可以得到業內偏移等信息
- 邏輯地址 前20位表示頁號,后12位表示業內偏移量。 通過頁號 和 匹配的物理塊號對應,
- 頁表存儲在內存里邊,頁表記錄的是頁號和物理塊號(頁框號)的對應信息
- 頁表寄存器,存儲在cpu里面,前半段存儲頁表的起始地址,后半段存儲存儲頁表長度(程序放到內存里邊執行的時候最大的長度)。這個是唯一的,一級頁表,后面會有多級頁表,動態通過pcb進行更新
- 頁表寄存器 相當于給定指針 + 數據長度,得到的這一塊內存就是存儲的頁表信息
- 頁表長度 存儲的是所有頁號的信息
- 頁表長度 *? 4KB = 程序的大小
- 頁號 大于 頁表長度,說明這個程序不屬于當前程序,產生 越界中斷。如果小于 則屬于合法的,就可以進行查表,CPU先根據頁表寄存器里邊存儲的頁表起始地址找到 頁表開始的地方,根據頁表存儲的頁號,在頁表里面查詢。通過頁號找到后面存儲的頁框號(物理塊號),將頁框號(物理塊號) 和 業內偏移量拼接在一起,就形成了物理地址
- pcb更新頁表寄存器的數值
考點
- 執行一條指令一共會訪問幾次內存?
- 執行指令,需要物理地址,1,尋找物理地址,2,讀入cpu內部,3,執行指令
- 1,尋找物理地址:利用頁號到內存里邊的頁表查詢物理塊號,拼接形成物理地址,一次訪問內存
- 2,讀入cpu內部,找到物理地址需要將指令拷貝到CPU的內部,一次訪問內存? ?然后執行命令,一級頁表的前提下,需要訪問兩次內存
- 如果是兩條指令 則是4次

具有快表的地址變換機構
- 快表也是頁號和物理塊號的拼接,相對存儲在內存中的頁表,快表存儲在頁表寄存器,是比頁表先一步被訪問。主要的目的是記錄先前曾經訪問過的歷史記錄,類似于電腦的快捷訪問,為了減少訪問內存的次數,但是存儲的條數很少。因為存儲在寄存器,因此CPU先調用寄存器很快,如果找不到才會訪問內存。
- 因為快表會保存最新的訪問記錄,是一個動態更新的過程,因此在訪問內部指令的時候有可能會查到有可能查不到,有一定的概率。這個叫做命中率,局部性原理 時間 + 空間
- 問題:執行1條指令,命中率是90%,那么需要訪問幾次內存?如果快表存在 1次;如果快表不存在需要兩次;乘上對應的概率 總的訪問內存次數 = 0.9 * 1 + 2 * 0.1 = 1.1
- 因此:執行10條指令,命中率是90%,那么需要訪問幾次內存? 10 * 1.1 = 11次,相較于沒有快表,2 * 10 = 20次
- 快表 命中率很高 是因為程序的局部性原理,也就是for等循環,在這個地方執行很多次,局部原理 體現在時間和空間局部性

兩級頁表
- 引入兩級頁表的原因?
- 一級頁表 頁號 + 物理塊號 組成的頁表項,一共有n個頁表項
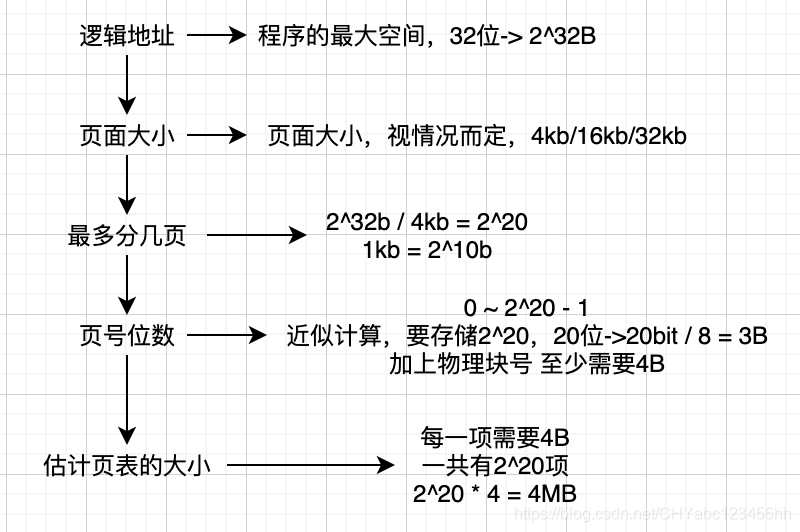
- 一個頁表項有多大?估計
- 估計的邏輯:1,邏輯地址 (程序最大空間) -> 2,頁面大小 (視情況而定,4kb、16kb) 3,做多分幾頁;4,頁號位數;5,估計頁表大小項?補充
- 頁表項確定之后,一個頁表項有多大 ,因為一個頁表很大,如果多個頁表進入內存,會很卡,考慮到分頁的時候,程序和內存都可以被分塊,頁表是不是也可以分塊??
- 發明一個頁表,記錄頁表的切塊,變成了兩級頁表的概念
如何設計兩級頁表
- 條件:32位操作系統 4kb頁面大小 4B頁表項大小
- 設計
- 1,按照最大程序進行切割
- 2,頁表切塊,塊大小 = 頁面大小
- 3,當一個頁表可以裝在一個頁面之內時,多級頁表就設計結束
- 4,邏輯地址切塊,塊位數 = 該級頁表每塊容納的頁表項

如何設計多級頁表
- 條件:64位操作系統 4kb頁面大小 4B頁表項大小
- 設計
- 1,按照最大程序進行切割
- 2,頁表切塊,塊大小 = 頁面大小
- 3,當一個頁表可以裝在一個頁面之內時,多級頁表就設計結束
- 4,邏輯地址切塊,塊位數 = 該級頁表每塊容納的頁表項

虛擬內存
引入請求分頁的原因
- 將QQ程序拷貝到磁盤,由于文件管理,將qq程序在磁盤上進行存儲。運行的時候,將QQ程序從磁盤拷貝到內存,QQ程序的登錄界面只會執行一次,體現了一次性,如果他只執行一次卻一直留在內存會導致內存的浪費,駐留性。因此 需要優化一次性和駐留性,
- 優化的依據,程序的局部性原理,程序中有太多的循環,太多的模塊
- 如何優化,按照需要分批裝入、調出? ->? 請求分頁存儲管理? (虛擬內存)
- 請求分頁管理的操作流程? ->? 運行程序之前,為程序分配小于整體大小的內存空間,比如先裝入登錄模塊的程序,登錄完成之后,將登錄模塊的程序調出,將需要的程序按照需要逐個裝入。

請求分頁的工作原理
- 在內存的一個地方存儲一個QQ程序的頁表,查詢頁表實現邏輯地址和物理地址的轉換,從而得到程序的片段存儲到物理磁盤的哪一個塊里面,以及存儲在物理塊里面的哪一行
- 在cpu的內部存儲一個快表,快表是程序的頁表歷史記錄的備份。因為基本分頁,頁表是存儲的QQ程序切割之后存儲到內存中物理塊的對應的邏輯信息
- 請求分頁的工作原理:1,大致的流程一致,但是頁表記錄的信息不一樣。因為按照需求,需要將文件切片動態的植入換出,這就需要記錄哪些頁面已經在內存中,頁面執行的次數等信息,因此引出了(置換算法),動態將需要的頁面放入內存中,替代先前的使用過的,不需要的頁面
- 基本分頁頁表 記錄了每一塊的邏輯地址和物理地址的對應關系;但是 對請求分頁頁表而言,有的時候找不到,這個塊還沒有裝載到內存中,需要將這個塊替換到內存中分配的駐留集里面來使用。
- 相較于基本分頁,請求分頁對邏輯地址和物理地址的對應關系雖然也需要通過頁表,但是并不簡簡單單,期間多了mmu,虛擬地址到物理地址翻譯

助留集 和 工作集是一個意思
- 二者是一個概念,就是操作系統給單個進程分配的幾個物理框所裝的頁面的集合
- 每次程序運行的時候需要將程序從磁盤拷貝到內存,根據生存時間的不同分為主程序頁面 (常駐內存的頁面)? 和? 子程序頁面
- 比如 主程序界面作為一個界面UI,這個常駐內存,除非程序退出或者異常退出;而不同的功能就是子程序,需要的時候調入內存執行,使用完之后調出內存
- 駐留集的大小:不能過大,如果過大,退化為基本頁表,浪費內存;如果過小,置換頁面發生頻繁,運行程序的時候會很卡;要適中,相對的概念
三種策略? 分配助留集的大小的策略
- 固定分配局部置換:計劃經濟策略,非常死板,計劃趕不上變化,程序是變化的;局部是指按照需求,所需的只可以替換自己事先分配好的頁面
- 可變分配全局替換:低級的市場經濟策略,盲目擴大生產,產業泡沫;如果程序需要更大的內存空間,會進一步動態增加駐留集的大小,但是會導致裝入程序的數量下降,先前分配給程序的駐留集不會減少;
- 可變分配局部替換:高級的市場經濟策略,抽肥補瘦,動態調整,十分靈活;減少缺頁率。每個程序所需要的駐留集的大小是動態調整的
- 缺頁率 :當分配的物理塊(駐留集)一定的時候,調入和調出的頻率是成正比
- 可變分配局部替換在n1 n2之間動態變化,協調缺頁率和物理塊數量之間的關系

頁表改進 和 缺頁中斷
- 基本分頁是將程序所有的內容拷貝到內存中;請求分頁是按照需要將需要的裝入內存,動態裝載調出
- 請求分頁頁表 具體列(字段)如下
- 頁號 0 - n
- 物理塊號?
- 狀態位 有效位,標志是否在內存中,否則缺頁中斷,并且進入阻塞狀態;如果物理塊有數據,但是狀態為0,表示并沒有被裝入,狀態位控制物理塊是否有效;有效的位數要小于駐留集的大小;如果產生缺頁中斷,利用調度算法從磁盤將需要的頁拷貝到內存
- 外存地址 磁盤塊號,如果需要的頁不在內存,需要從磁盤塊導入頁
- 為置換算法提供參考使用的參數 訪問字段(統計使用,區分程序是長期使用還是短期使用,執行次數越少的越容易被調出)、修改位(對于變量的數值修改需要從內存改回磁盤)、使用位(clock算法使用)等
- 如果需要的頁不在內存中 就會產生缺頁中斷,然后從磁盤里面取頁面到內存中,替換
頁面調度時機
- 程序開始運行的時候,使用預調頁策略(局部性原理),程序員指定的,main函數,操作系統底層將其作為程序的入口
- 程序的運行過程中 修改請求頁表相關信息
- 程序運行中,發生缺頁時,比如程序啟用不同的功能;調入一頁頁面,請求調頁策略,(頁面置換算法),使用硬件中斷,中斷處理程序,啟用頁面置換算法,將新的頁面替換舊的頁面
置換算法
OPT頁面置換算法 最佳? 向未來看
- 算法思想:淘汰以后永不訪問 或者 將來最長時間不再訪問的頁面
- 算法特點:不可以預測未來,因此這個算法不能實現
- 推斷出? ?缺頁中斷次數 / 頁面置換次數? ?
- 缺頁次數 -? 頁面置換? =? 工作集(駐留集)
- 理想化,很難實現,因此其余算法是不可能超過他的
- 發生缺頁中斷的時候 除了剛開始沒有數據,剩余的都會發生頁面置換
- 下面的例子 發生了9次缺頁中斷

FIFO頁面置換算法
- 算法思想:淘汰先調入的頁面,隊列實現?
- 算法特點:簡單、性能差、且有belady異常
- 推斷出 缺頁中斷次數/頁面置換次數
- 15次中斷 15-3 = 12次 頁面置換

LRU算法 最近未使用算法? 向歷史看
- 算法思想:淘汰最近未使用的頁面 (使用過去來預測未來)
- 算法特點:性能優異,接近最佳置換算法,需要硬件棧的支持,開銷極大
- 推斷出?缺頁中斷次數 / 頁面置換次數

CLOCK算法 又叫NRU(Not recently used)
- 算法思想:通過鐘表掃描法,淘汰最近未使用的頁面(頁表增加一個使用位)首次裝入置1;再次訪問置1;掃描時將1變為0
- 算法特點:由于最近未使用和最久未使用的思想接近,因此CLOCK 算法和LRU算法性能很接近
- 推斷出?缺頁中斷次數 / 頁面置換次數
- 但是CLOCK算法性能更高,不需要硬件,而LRU算法需要硬件棧的支持

改進CLOCK算法
- 算法思想:通過鐘表掃描法,淘汰最近未使用的頁面中未修改頁面
- (u,m) use modify
- (0,0) 未使用未修改
- (0,1) 未使用已修改
- (1,0) 已使用未修改
- (1,1) 已使用已修改
- 算法特點:相比CLOCK算法,減少了頁面回寫磁盤的概率,從而省卻了回寫的時間 (I/O時間)
- 對變量的數值修改會導致內存和磁盤數據的不一致,因此要根據修改的內容更改磁盤數據;先淘汰未使用的,就減少更新數據所帶來的IO操作
- 算法步驟:1,按照鐘表掃描法,尋找(0,0)用于替換,找不到就進行第二步;2,重新執行鐘表掃描算法,尋找(0,1)用于替換,在掃描中,將(1,0)改為(0,0),(1,1)改為(0,1),找不到回到第1步
- 注意事項:第1步只查不修改;第二步邊查邊修改
- 改進CLOCK算法更加細膩
從何處調入頁面,調出的頁面存放在哪里?
- 臨時存放程序的副本 -> 磁盤必須要有一塊對換區(swap)
- 可修改程序 ->? 變量 (已修改 / 未修改);可修改程序如果已經修改,回寫磁盤,寫到對換區里面的程序副本里面
- 不可修改程序 常量
- 如果對換區很大的時候,每次運行的時候,將程序拷貝到對換區,程序運行的時候,是將對換區里面的程序拷貝到內存
- 對換區大小問題(運行程序,將程序從文件夾拷貝一份到磁盤的對換區,然后從兌換區拷貝程序到內存區)
- 對換區足夠大,從磁盤的對換區將數據文件拷貝到內存
- 對換區不夠大,對換區只裝入可修改程序,不裝入不修改程序,不可修改程序從程序安裝文件夾讀取
- unix 方式:讀取文件都是從程序安裝文件里面,但是回調的時候,無論是可修改程序還是不可修改程序都寫到對換區里面;然后第二次以后就會從對換區進行數據交互
- 1,從何處調入頁面?從磁盤的對換區將數據文件拷貝到內存
- 2,調出的頁面存放在哪里?將修改的內容回寫到對換區,不可修改程序不會回寫到文件夾
- 不對源文件進行操作,防止不同用戶之間的數據干擾
- 程序安裝目錄是原件,對換區拷貝的是程序的副本

虛擬內存的大小
- 虛擬內存 小于等于 邏輯地址支持的最大空間(軟件限制) 軟件支持的容量很大,不需要考慮,一般硬件限制就是虛擬內存可以支持的最大內存
- 磁盤裝載大程序的一部分 + 內存裝載大程序的一部分,合起來使大程序在小內存內運行,通過對換區,實現數據的交互
- 64位OS -> 2^32 * 4GB
- 32位OS -> 4GB
- 虛擬內存 小于等于 (內存卡 + 磁盤)硬件限制
- 用小內存運行大程序
- 考題形式:在一臺實現了虛擬內存技術的計算機里面,最大支持運行多大的軟件
- 游戲由程序、數據、模型(人物)、過渡動畫等組成
抖動現象
- 發生時間:如果駐留集不夠大的話,置換頁面時就可能會產生抖動現象(對換區 和 內存區 之間交換數據),又叫顛簸
- 特點:1,頻率高;2,來來回回
虛擬地址和物理地址之間的翻譯
CPU執行一條指令的過程
- 通過地址翻譯,由虛擬地址得到物理地址(先查快表,再查頁表)
- 通過物理地址,將指令讀到CPU內的寄存器(ALU)里面執行
- 頁表 :頁號、物理塊號、有效位 三個最關鍵
- 快表查詢:直接映射(Hash查找)、全相聯映射、組相聯映射
- 全相聯映射:快表和頁表一樣,查詢的時候需要從頭查到尾
- 因為?全相聯映射 內部存儲的條目是無序的,查詢比較浪費時間,因此改進為組相聯映射
- 2路組相聯映射,是指將先前的兩個條目組合在一起,形成一組,相較于先前的全相聯映射多了組索引、TLB索引,他倆是通過 頁號 進行分解得到的。
- 虛擬地址(邏輯地址結構):將先前全相聯映射中的頁號p化為TLB標記和組索引、業內偏移w不變;
- 如果是8條目2路組相聯,分成四組,將頁號的后兩位(00,01,10,11表示組號)作為組索引,剩余的作為TLB,在組索引唯一的條件下,TLB是唯一的標識
- 只有地位作為組索引,高位仍然滿足遞增序列,且唯一



虛擬內存-虛擬地址到物理地址的翻譯 例題
系統滿足如下條件,
- 有一個TLB與一個datacahe
- 存儲器以字節為單位進行編址 ;以字節為單位進行編址,一行8bit作為一個地址,一行作為0;兩個字節為單位進行編址,將先前的兩行編為0;全字,四個字節編址
- 虛擬地址14位
- 物理地址12位
- 頁面大小64B
- TLB四路組相聯,共16個條目
- data cache是物理地址,直接映射,行大小為4字節,總共16組
- 請翻譯虛擬地址
- 0x03d4 ;
- 0x00f1 ;
- 0x0229;
- 有快表,先到快表里面查詢,將虛擬地址按照快表的格式進行切分


?

基本分段管理
- 基本分頁是將程序所有文件以4kb作為一個切塊,存儲在磁盤的一段空間;基本分段是按照功能或者模塊將相關聯的代碼作為一個整體,分散存儲在磁盤中
- 分段的好處:程序多開時可以共享數據;分段可以實現程序多開,或者多個程序公用一個程序段
- 比如qq程序開了兩個,登錄不同的qq號,但是有些功能是共享的,比如網絡,因此將網絡的代碼進行復用
如何進行程序分段
- 按照程序(進程)自然段進行劃分,這個流程是由編譯器決定的
- 段長:每段段長都可能不一樣,和程序本身的結構相關
- 分頁有頁表,記錄程序轉入到內存的位置,那么分段也應該有段表,功能一致,記錄
- 頁表:記錄程序的哪一頁被記錄到內存中的哪一塊
- 段表:記錄程序的哪一段被記錄到內存中的哪一塊

段表
- 基本分段的段表,每個進程都有自己的段表
- 段號、段長、內存起始地址(因為段長不一樣,不可以向頁表一樣,使用物理塊號(等分),因為每一塊大小都是4kb,因此可以通過 物理塊號 * 4kb 計算得到物理地址)
- 通過段表 共享數據
- 分頁存儲管理通過查詢快表和頁表,將邏輯地址翻譯為物理地址,從而cpu可以到具體的位置執行指令
物理地址、邏輯地址和段表之間的關系
- 段號、段內偏移
- 段內偏移w:由于每一個程序段的大小不一樣,以最大的作為段內偏移
- 到段表查詢,得到物理的起始地址b,則物理地址等于b + w

- 低16位表示段內偏移 請翻譯邏輯地址 0x000301F4

分段地址變換機構
- 計算機步驟
- 1,根據邏輯地址的前幾位得到段號,如果段號大于段表存儲的最大長度(段表長度),則產生越界中斷,否則合法
- 2,如果合法 通過起始位置 + 段號 * 段表項長度 =? 段表項地址? ?得到段表項地址b
- 3,通過 E=b+w? 段表項地址 + 段內偏移 = 物理地址
- cpu執行一條指令 需要訪問幾次內存?兩次? 1,地址翻譯,需要查詢段表,得到物理地址;2,通過物理地址到內存讀取cpu指令到cpu內部執行

分頁和分段的地址空間維度
- 分頁的地址空間是一維的,因為只要給定頁面大小這一個參數就可以劃分邏輯地址的結構,比如每個大小都是4kb,(4kb = 2^12B)因此業內偏移是12位,頁號占了20位
- 分段的地址空間是二維的,不可以通過段長計算段號和段內偏移的位數,因為每段的長度都不一樣,因此需要給出這兩個參數
基本段頁式管理(綜合段式 和 頁式)
引入段頁式原因
- 頁式存儲管理:通過程序與內存的切成小塊,分散和分配內存,減少內存碎片,提高內存利用率。機器的角度
- 段式存儲管理:通過將程序先按照自然段(模塊)進行分段,達到通用段可以共享的目的。從人類的角度出發
- 段頁式存儲管理:先將程序按照自然段進行分段,再將每個自然段切成等大的頁。從而匯聚兩者的優勢
如何分段和如何分頁
- 先分段 再分頁
- 分段,由編譯器完成,將自然段進行分段
- 分頁,將分號的段按照4kb進行切分,每4kb作為一個頁,不足4kb的碎片,會出現不足一頁的情況 ,這樣的內部碎片很小且很少
- 因為分成段的數量就很少,而且僅僅在最后的時候會產生碎片,因此碎片很小且很少

段表和頁表
- 段表和頁表配合使用之后,先前的段表記錄段號、段長和段起始地址變成了,段號、段長(頁表長度)和頁表起始地址
- 因為對每個段進行分頁,因此每個段都有自己的頁表起始地址
- 只有一個段表,段表中的每個段表項都有自己對應的頁表
- 還實現不了邏輯地址和物理地址的轉換,需要更進一步操作

物理地址、邏輯地址、段表、頁表之間的關系
- 頁號p 業內偏移w : 分頁的邏輯結構? -> 查詢頁表? 得到物理地址?物理塊號b b|w
- 段號s 段內偏移w :?分段的邏輯結構? -> 查詢段表??得到物理地址?物理塊號b b+w
- 段號s 頁號p 業內偏移w : 段頁式邏輯結構 ->? 先查段表再查頁表(因為先分段再分頁)
段頁式地址變換機構
- 將邏輯地址變換成物理地址
- 1,取出段號S和段號表存儲的段號比較,如果大于等于最大段表長度,則報越界中斷錯誤;如果小于等于段表長度,查詢頁表;通過起始地址 + 段號 *? 段表項長度 計算得到頁表
- 頁表的計算方式一樣,得到物理塊號
- 物理塊號b 和 段內偏移w 得到物理地址 b|w
- cpu執行一條指令需要執行幾次內存?一共需要三次
- 1,地址翻譯,需要查詢段表,查詢頁表,得到物理地址;兩次
- 2,通過物理地址到內存讀取cpu指令到cpu內部執行? ?一次

 ?
?



















