指針和引用之間的區別
- 指針是一個新的變量,指向一個變量的地址。可以通過這個地址來修改另一個變量;引用是變量的別名,對引用的操作就是對變量本身的操作。
int a = 996;
int *p = &a;//p是指針,&在此是求地址運算
int &q = a;//q是引用,&在此是表示作用
- 指針可以有很多級,但是引用只有一級
- 傳參的時候,使用指針需要解引用才可以對參數進行修改;函數使用引用作為參數,直接懟參數進行修改
- 32位操作系統中,指針一般是4個字節,引用的大小取決于被引用對象的大小
- 指針可以為空,但是引用不可以為空
- 指針定義的時候可以不用初始化,但是引用必須得進行初始化
- 指針初始化之后可以再次改變,但是引用不可以
- 自增的含義不一樣:指針是指向變量之后的內存;引用是對變量本身進行自增操作
- C++中指針和引用的區別
函數傳遞的過程中,什么時候使用指針?什么時候使用引用?
- 需要返還函數內的局部變量的時候需要使用指針。但是使用指針需要開辟內存空間,用完之后需要對內存空間進行釋放,否則會導致內存的泄露。但是返還局部變量的引用是沒有任何意義
- 對于棧的大小比較敏感的時候(比如使用遞歸)的時候使用引用。使用引用不需要創建臨時變量,開銷較小
- 類對象作為函數傳遞的時候使用引用,這是C++標準對象傳遞的方式
- 函數傳參的三種方式
補充:函數值傳遞不改變變量的數值,如果想要改變變量的數值,需要返回值,使用變量接收函數返回的數值;或者使用指針和引用作為函數的參數,都可以在函數內改變變量的數值,不需要通過返回值的方式進行改變;
- 如果想要使用引用傳遞的方式提升性能,但是不想改變某個變量的數值,可以將相應的輸入參數定義為一個常量;使用const進行修飾
- 指針傳遞:指針傳遞本質上也是數值傳遞,但是傳入的是地址,指針傳遞的外部實參的地址,當被調用函數的形參數值發生改變的時候,自然外部實參數值也會發生改變
堆和棧的區別
- 使用new方式開辟的內存空間將存儲于堆區,需要程序猿手動管理,進行內存的分配,對象的構造和釋放;棧是編譯器自動管理的內存區域,存放函數的參數和局部變量
- 考慮到堆會有頻繁的內存分配和釋放,會導致內存碎片
- 棧的內存空間向下,地址越來越小;堆的內存空間向上,地址越來越大
- 棧的空間較小,一般是2M左右,使用堆存儲的數據會很大
- 堆分配的是不連續的空間,但是棧分配的是連續的地址空間
- 棧是系統自動配置,速度很快,堆一般速度比較慢
- 堆(heap)和棧(Stack)的區別是什么?為什么平時都把堆棧放在一起講?
- 什么是堆?什么是棧
堆快還是棧快
- 棧快
- 操作系統底層對棧提供了支持。會分配專門的存儲器存放棧的地址,棧的入棧出棧操作也十分簡單,并且有專門的指令執行
- 堆的操作是由C和C++函數庫提供的,分配內存的時候需要使用算法尋找合適大小的內存,并且獲取堆的內存需要兩次訪問,第一個訪問指針,第二次根據指針存儲的地址訪問內存,因此堆的速度比較慢
new和delete是如何實現的?new和delete的異同處
- new的時候,首先調用malloc為對象分配內存空間,然后調用對象的構造函數;delete會調用對象的析構函數,然后使用free進行對象的回收
- new和malloc都會進行內存空間的分配,但是new還會調用對象的構造函數進行初始化
- malloc需要給定空間的大小,new只需要對象的名字
既然有了malloc和delete為什么還要使用new和delete?
- 他們都是用于申請內存和回收內存的
- 對于非進本數據類型對象進行操作的時候,在其生命周期內,涉及到對象的構造和析構。malloc和free是庫函數,是已經編譯的代碼,所以不能將構造函數和析構函數強加給malloc和free函數
- new和delete屬于操作符,可以重載
- malloc和free屬于函數,可以重寫
- new和delete返回的是 某種數據類型的指針,malloc和free返回的是void指針
C和C++的區別
- C是面向過程的語言,C++是面向對象的語言,C++具有封裝、多態和繼承等特性;封裝隱藏了函數內部的實現,使得代碼模塊化;(繼承通過子類繼承父類的方法和屬性,實現了代碼的重用;多態是“一個接口,多個實現”,通過重寫父類的虛函數,實現接口的重用)
- C和C++內存管理的方式不一樣,C使用malloc/free,C++還使用new/delete
- C++存在函數的重載、引用、類、流操作符、操作符重載、異常處理、模板、標準庫STL和Boost等概念,C無
-
關鍵字的細微差別
(1)struct:在C語言中struct定義的變量中不能有函數,而在C++中可以有函數。 (2)malloc :malloc函數的返回值為void*,在C語言中可以賦值給任意類型的指針,在C++中必須強制類型轉換,否則報錯。 (3)struct和class:class是對struct的擴展,struct默認的訪問權限是public,而class默認的訪問權限是private。
-
區別
- C是面向過程的語言,C++是面向對象的語言;面向對象的比如:類、對象、繼承、封裝、多態(重載和復寫)
- C++有強大的設計模式:比如單例、工廠和觀察者模式
- 內存管理:C使用malloc和free實現堆內存空間的釋放;C++使用new和delete實現堆內存的釋放(new對象的創建,調用構造函數;delete調用析構函數和實現內存的釋放;堆本質上是鏈表,操作系統,實現內存的分配和回收,首個頂點存儲分配的內存的長度)
- 強制類型轉換:C的強制類型轉換使用()小括號里面加類型進行類型強轉的,而C++有四種自己的類型強轉方式,分別是const_cast,static_cast,reinterpret_cast和dynamic_cast
- C和C++的輸出方式是不一樣的:C使用printf/scanf,和C++的cout/cin的對別,前面一組是C的庫函數,后面是ostream和istream類型的對象。
- C++還支持帶有默認值的函數,函數的重載,inline內聯函數,這些C語言都不支持,當然還有const這個關鍵字,C和C++也是有區別的,但是這都是目前最常用的C89標準的C內容,在C99標準里面,C語言借鑒了C++的const和inline關鍵字,這兩方面就和C++一樣了。
- 由于C++多了一個類,因此和C語言的作用域比起來,就多了一個類作用域,此外,C++還支持namespace名字空間,可以讓用戶自己定義新的名字空間作用域出來,避免全局的名字沖突問題。
- C++不僅支持指針,還支持更安全的引用,不過在匯編代碼上,指針和引用的操作是一樣的;C++的智能指針,比如shared_ptr和unique_ptr
- 在C++中,struct關鍵字不僅可以用來定義結構體,它也可以用來定義類(至于C++中struct和class的區別,請大家自行翻閱資料)
- 注意事項
- malloc開辟內存只有一種方式,而new有四種分別是普通的new(內存開辟失敗拋出bad_alloc異常), nothrow版本的new,const new以及定位new。
- 如果問到malloc,還有可能問你memcpy等,realloc函數能不能在C++中使用,絕對不能,因為這些函數進行的都是內存值拷貝(也就是對象的淺拷貝),會發生淺拷貝這個嚴重的問題!多個指針指向了同一片內存區域,但是單獨釋放一個指針指向的內存空間對于內存釋放沒有什么用,造成了數據的泄露
delete和delete[]的區別
- delete和delete[]的區別
- delete只會調用一次析構函數,但是delete[]會調用每個成員的析構函數
- 使用new分配的內存使用delete進行釋放,使用new[]分配的內存使用delete[]進行釋放
int *a = new int[10];delete a;delete[] a;- 對于簡單的類型,使用new分配后的不管是數組還是非數組形式的內存空間使用delete和delete[]兩種方式都可以;原因在于,分配簡單的數據類型,內存的大小是確定的,進行對象析構的時候也不會調用析構函數;直接通過指針就可以獲得實際分配的內存空間,哪怕是數組內存空間(分配的過程中,系統會記錄分配內存大小的信息,將其存儲于結構體的CrtMemBlockHeader中)
- 針對類class,二者表現出具體的差異;
class A{
private:char* m_cBuffer;int m_nLen;public:A(){m_cBuffer = new char[m_nLen];}~A(){delete[] m_cBuffer;}
};int main(){A *a = new A[10];delete a;
}
- ?使用 delete a;僅僅釋放了a指針指向的全部內存空間,也就是只調用了a[0]對象的析構函數,剩余的a[1]到a[9]這些內存空間不能釋放,造成了數據的泄露
- delete[] a;//調用使用類對象的析構函數,釋放用戶自己分配的內存空間,釋放了a指向的全部內存的空間
C++、java的聯系和區別
- C++和java都是面向對象的編程語言,C++是編譯成可執行文件直接運行的,Java是編譯之后在JAVA虛擬機上運行的,因此Java具備很好地跨平臺的特性,但是執行的效率不是很高
- C++內存由操作員手動管理,Java的內存管理是由Java虛擬機來完成的,使用的是標記回收的方式
- C++具備指針和引用類型,但是Java只有引用
- Java和C++都具備構造函數,但是C++存在析構函數,JAVA不具備
- 區別 參考鏈接
struct和class的區別
- 類中的成員 struct默認采用public繼承方式,class默認采用private方式
- struct繼承默認采用 public繼承,class默認采用private繼承
- class 可以作為模板,但是struct不可以
補充
- C++繼承了C語言的struct,并對其進行了補充。struct可以包含1,成員函數;2,struct可以實現繼承;3,struct可以實現多態
define和const的聯系和區別(編譯階段、安全性和內存占用)
- 聯系:都是定義常量的一種方法
- 區別
- define定義的常量沒有類型,只是進行簡單的替換,可能存在多個拷貝,占用的空間很大;
- const定義的變量是有類型的,存儲于靜態存儲區,只有一個拷貝,占用的空間很小
- deifne定義的變量在預編譯階段進行替換,const在編譯階段確定他的數值
- define不會進行類型的安全檢查,但是const會進行類型的安全檢查,安全性更高
- const可以定義函數,但是define不可以
- const可以進行調試,但是define不可以進一步進行調試,因為define在預編譯階段就已經發生了替換
- const不支持重定義,但是define可以,使用#undef取消某個符號的定義,重新進行定義
- define可以避免頭文件的重復引用
- C++中define和const的區別
C++中const的用法
- const修飾類的成員變量的時候,表示常量不可以修改
- const修飾的成員函數,表示函數不會修改類中的數據成員,不會調用其他非const的成員函數
- const int *a和int*const a 的區別詳解???????
const修飾基本的數據類型
- const修飾一般常量和數組 const int a=10;等價于int const a = 10;int和const的位置隨便替換;對于基本數據類型,修飾符const和類型說明符號可以互換位置,其結果也是一致的,只要不改變這些常量的數值即可
- const修飾指針變量*和引用變量&:*返回的地址指向的變量,&返回變量的實際地址
- const位于*的左側,則const修飾的是指針所指向的變量,即指針指向的是常量;這種情況不允許對內容進行修改操作,比如 *a=3;但是a可以指向別的變量
- const位于*的右側,則const修飾的是指針本身,即指針本身是常量;指針指向的內容不是常量,*a=4是可以的,但是a=別的變量是不允許的
- const int* const a=4;//常量數據常量指針,a和*a都不可以更改
const應用到函數中
- 作為參數的const修飾符:則在函數體中,不可以對傳遞進來的指針的內容進行改變,保護了原指針指向的內容;
- 作為函數返回數值的const修飾符,一般用于二目操作符重載函數并且產生新對象的時候
***C++11不允許在類聲明中初始化static非const類型的數據成員
- 對于static const類型的成員變量都支持定義的時候初始化
- 對于static 非const類型的成員變量,不支持在定義的時候初始化
- 對于const非static類型的成員變量要求在構造函數初始化的列表中初始化
- 對于非const非static類型的成員變量,允許定義的時候進行初始化
- 對于static非const成員變量,在類的定義之后進行初始化,使用int 類名::b=5;的方式
類中定義常量
- 使用枚舉類型
- 使用static
- 使用const
常量對象只可以調用常量函數,別的成員函數都不可以調用
使用const的建議
- 能用const一定要用
- 避免賦值操作錯誤,比如對const變量進行賦值
- 在參數中使用const應該使用引用或者指針,而不是一般的對象實例
- const在函數中的三種用法,參數、返回值、函數
- 不要將返回數值的類型輕易確定為const
- 除了重載操作符,一般不要將返回數值的類型定位對某個對象的const引用?
- C++ const的用法詳解
C++中的static用法和意義
- C++中的static
- static是靜態的,用來修飾變量、類成員和函數
- 變量:被static修飾的變量就是靜態變量,他的聲明周期會持續到程序的結束。被static修飾的變量會存儲在靜態存儲區域。局部靜態變量的作用域在函數體中,全局靜態變量的作用域在這個文件中
- 函數:被static修飾的函數是靜態函數,靜態函數只能在本文件中使用,不可以被其他文件調用,也不會和其他文件中的同名函數相互沖突
- 類:在類中,被static修飾的成員變量就是類的靜態成員,這個靜態成員會被類的多個對象公用;被static修飾的函數也屬于靜態成員,不是屬于某個對象的,訪問這個靜態函數,不需要引用對象的名字,而是通過引用類名來訪問。
- 靜態成員要訪問非靜態成員時,通過對象來引用。局部靜態變量在函數調用結束之后也不會被回收,會一直保存在內存中,如果這個函數被再次調用,他存儲的數值是上次調用結束后存儲的數值
- 注意static和const的區別:const強調數值不會被修改,而static強調數值的唯一性拷貝,對所有類的對象都共用
- 面向對象的static:類中的靜態變量,聲明為static的變量只會被初始化一次,因為它在單獨的靜態存儲區域內分配了空間,因此類中靜態變量由對象共享。但是對于不同的對象,不能有相同靜態變量的多個副本,因此靜態變量不可以使用構造函數進行初始化。
- 類中的靜態成員變量必須在類內聲明,在類外定義(被const 修飾的除外)
class Apple{
public:static int i;//類內聲明Apple(){};
};int Apple::i = 10;//類外定義class Apple{
public://被const修飾的static變量直接在類內被初始化const static int i=10;//類內聲明Apple(){};
};
- 類內的靜態成員函數:靜態成員函數不需要依賴于類的靜態對象,可以使用對象和. 來調用靜態成員函數。但是建議使用類名和范圍解析運算符調用靜態成員。
- 靜態成員函數只可以訪問靜態數據成員 和 其他靜態成員函數,無法訪問類的非靜態成員函數和非靜態的成員變量
- 靜態類:和變量一樣,靜態類的聲明周期持續到程序的結束。在main函數結束之后才會調用靜態類的析構函數
class Apple{
public://被const修飾的static變量直接在類內被初始化const static int i=10;//類內聲明Apple(){};static void find(){std::cout << "靜態成員函數" <<std::endl;}
};int main(){Apple::find();return 0;
}計算幾個類的大小?
class A{};
int main(){std::cout << sizeof (A)<<std::endl;A a;std::cout << sizeof (a)<< std::endl;return 0;
}
- 空類的大小是1,在C++中占用一個字節,這是為了讓對象的實例能夠相互區別,
- 具體來講 空類同樣可以被實例化,并且每個實例在內存中都占用獨一無二的地址
- 因此編譯器會給空類隱含加上一個字節,這樣空類實例化之后就會擁有獨一無二的地址
- 當該空白類作為基類的時候,該類的大小就會被優化為0.? 測試不是
- 子類的大小就是子類本身的大小,這就是所謂的空白基類的最優化
- 空類的實例大小就是類的大小,所以sizeof(a)=1字節,如果a是指針,那么sizeof(a)的大小就是指針的大小,即4字節;32位操作系統就是4字節,64位操作系統就是8字節
class A{virtual int Fun(){};
};
int main(){std::cout << sizeof (A)<<std::endl;//32為機器輸出為4,64位機器輸出為8A a;std::cout << sizeof (a)<< std::endl;//32為機器輸出為4,64位機器輸出為8return 0;
}因為虛函數的類對象都有一個虛函數表指針 _vptr,其大小是4字節class A{static int a;
};
int main(){std::cout << sizeof (A)<<std::endl;//輸出為1A a;std::cout << sizeof (a)<< std::endl;//輸出為1return 0;
}靜態存儲成員存放在靜態存儲區域,不占據類的大小,普通函數也不占用類的大小class A{int a;
};
int main(){std::cout << sizeof (A)<<std::endl;//輸出為4A a;std::cout << sizeof (a)<< std::endl;//輸出為4return 0;
}STL介紹 (內存管理、allocator、函數、實現機理、多線程)
- STL從廣義上講涉及到了三類,算法、容器和迭代器
- 容器就是數據的存放方式,包括序列式容器list、vector等,關聯式容器map和set和非關聯容器
- 迭代器就是不暴露容器的內部結構的條件下對容器實現遍歷和操作
STL中hash的表現
- STL中unordered_map底層調用哈希表實現的。記錄的鍵是哈希的數值,通過比對元素的哈希數值確定元素的數值是否存在
- 采用開鏈法解決哈希沖突,當桶的大小超過8的時候,就自動轉換為紅黑樹進行組織
解決哈希沖突的方式
- 線性探查:當該元素的哈希值對應的桶不可以存放數據的時候,循環往后一一查找,直到找到一個空桶為止,在查找的時候如果該元素的哈希值對應的桶不匹配的啥時候,就一一往后查找,直到找到數據一致的元素,或者查找的元素不存在
- 二次探測:該元素哈希值對應的桶不能存放數據的時候,就往后尋找1^2,2^2,3^2,4^2......i^2個位置
- 雙散列函數法:當使用第一個散列函數計算得到存儲位置與對應存儲的桶發生沖突的時候,再次調用第二個散列函數進行哈希,作為步長
- 開鏈法:在每一個桶內維護一個鏈表,由元素哈希數值尋找到這個桶,然后將元素插入到對應的鏈表中,STL就是使用hash_table這種實現方式
- 建立公共溢出區,當發生沖突的時候,將所有出現沖突的區域,放在公共溢出區
STL 中unordered_map和map的區別
- unordered_map底層使用哈希實現的,占用內存比較多,查詢的速度較快,是常數時間的復雜度。內部是無序的,需要實現==操作符號
- map底層是采用紅黑樹實現的,插入刪除時間復雜度是O(logn),他的內部是有序的,因次需要實現比較操作符號<
- C++STL標準模板庫簡介
std::map<int,std::string>m1;//map的三種插入方式m1.insert(make_pair(10,"abc"));//方式1m1[9] = 'cdc';//方式2m1.insert(std::pair<int,std::string>(13,"chy"));//方式3//map使用insert方式插入元素數值,只能插入的是不存在的主鍵m1.insert({8,"kkk"});C++vector的實現
- STL中的vector是封裝了動態數組的順序容器。不過與動態數組不同的是,vector可以根據需要自動擴充容器的大小。具體的策略是每次容量不夠使用的時候,重新申請一塊大小為原來大小的兩倍的內存,將原容器的元素拷貝到新的容器,并釋放原先空間,返回新空間的指針。這也是為什么容器在擴容之后,與其相關的指針、引用和迭代器都會失效
- 在原來空間不夠存儲新數值的時候,每次調用push_back方法會重新分配新的空間從而滿足新的數據的添加操作,如果頻繁的進行內存的分配,會導致性能的損耗
- 三個指針:first指向的是容器對象的起始字節位置;last指向的是最后一個元素的末尾字節;end指針指向的是vector容器所占用的內存空間的末尾字節;使用last和first,描述容器中已經使用的內存空間;last和end描述容器空閑的內存空間;first和end描述容器的容量
- 頻繁的調用 push_back()會使得程序花費很多時間在vector上,這種情況可以使用list鏈表或者提前申請內存空間
C++list和vector的區別
- vector擁有一段連續的內存空間,內存不夠會進行內存的拷貝,時間復雜度是O(n)
- list 基于雙向鏈表實現的,因此內存空間不連續,只能通過指針訪問數據,因此list查詢元素需要遍歷整個鏈表,時間復雜度是o(n),但是鏈表具備高速的插入和刪除的特性
- vector擁有連續的內存空間,可以很好地支持隨機存取,因此,vector::iterator支持+、+=、<等操作符號;list內存空間可以是不連續的,因此不支持隨機訪問,因此不會支持+、+=、<等操作符號
- vector和list的iterator都實現了++運算符號
- vector適用于隨機訪問,list適用于插入和刪除,不關心訪問
C++中重載和重寫的區別
- overload 重載一般用于同一個類內部,函數的名字相同,但是函數的參數列表不同(參數的類型和數量),具體的內部實現機制不一樣,返回數值是可以不一樣的,但是這個不是區分重載函數的標志
- override覆蓋一般用于子類和父類之間,函數的名字相同,參數的列表相同,只有方法體不相同的實現方法。子類中的同名方法屏蔽了父類的方法的現象稱為隱藏;子類改寫父類中的virtual方法
- overwrite重寫:一般用于子類和父類之間,函數的名字相同,參數的列表相同,只有方法體不相同的實現方法。子類中的同名方法屏蔽了父類的方法的現象稱為隱藏;和override類似,但是父類中的方法不是虛函數;和overload類似,只是范圍不同,是父類和子類之間
- C++overlode override overwrite的詳細解釋
C++內存管理
- C++內存分為堆、棧、全局/靜態存儲區域、常量存儲區域和代碼區
- 棧:執行的函數的時候,函數內局部變量的存儲單元都可以在棧上創建,函數執行結束,這些存儲單元會被釋放;棧內存分配運算內置于處理器的指令集,效率很高,但是分配的內存容量有限
- 堆:使用new分配的內存區域,編譯器不負責次對象的釋放,由程序員自己寫析構函數,一般一個new對應一個delete。如果程序員沒有對其進行釋放,程序結束之后,操作系統會自動回收
- 全局靜態存儲區域,內存在程序編譯的時候就已經分配好,這個內存區域的生命周期持續到程序的終止,主要存放靜態數據(局部static變量、全局static變量、全局變量和常量)
- 常量存儲區域,比較特殊的存儲區域,存放的是常量字符串,不允許修改
- 代碼區:存放程序的二進制代碼
- C++內存空間:靜態存儲區域、堆、棧、文字常量區、程序代碼區
介紹面向對象的三大特性,并且舉例說明
- 面向對象的三大特性是封裝、繼承和多態
- 封裝:隱藏了類的實現細節和成員的數據,實現了代碼的模塊化,如類里面的private和public
- 繼承:子類可以復用父類的成員和方法,實現了代碼的重用
- 多態:“一個接口,多個實現”,通過父類調用子類的成員,實現了接口的重用,如父類的指針指向了子類的對象
多態的實現
- 多態包含編譯時多態和運行時多態,編譯時多態體現在函數的重載和模板上,運行時多態體現在虛函數上
- 虛函數:在基類的函數前面加上virtual關鍵字,在派生類中重寫該函數,運行的時候根據對象的實際實際類型來調用相應的函數。如果對象的類型是派生類,就使用派生類的函數;如果對象的類型是基類,就使用基類的函數
- 面向對象的三個基本特征
C++虛函數相關(虛函數表,虛函數指針)虛函數的實現原理(重要)
- C++虛函數的實現是多態機制。他是通過虛函數表來實現的,虛函數表是每個類中存放虛函數地址的指針數組,類的實例在調用函數時會在虛函數表中尋找函數的地址進行調用,如果子類覆蓋了父類的函數,則子類的虛函數表會指向子類實現的函數地址,否則指向的是父類的函數地址。一個類的所有實例都共享同一張虛函數表
- 多重繼承的情況下,越是祖先的父類的虛函數更靠前,多繼承的情況下,越是靠近子類名稱的類的的虛函數在虛函數表中約靠前
- C++虛函數表剖析
- C++多態虛函數表詳解
編譯器如何處理虛函數表
- 編譯器處理虛函數的方式:如果類的里邊具有虛函數,就將虛函數的地址記錄在類的虛函數表中。派生類在繼承基類的時候,如果有重寫基類的虛函數,就將虛函數表中的相應的虛函數指針設置為派生類的函數地址,否則指向基類的函數地址。
- 為每個類的實例增加一個虛表指針(vptr),虛表指針指向類的虛函數。實例在調用虛函數的時候通過虛函數表指針找到類中的虛函數表,找到對應的函數進行調用
- 虛函數的作用及其底層的實現機制
基類的析構函數一般寫成虛函數的原因
- 首先析構函數可以為虛函數。當析構一個指向子類的父類指針時,編譯器可以根據虛函數表尋找子類的虛構函數進行調用,從而正確釋放子類對象的資源
- 如果析構函數不被聲明為虛函數,則編譯器實施靜態綁定,在刪除指向子類的父類指針的時候,只會調用父類的析構函數,就會導致子類對象析構不完全從而造成內存的泄露
構造函數為什么不定義成虛函數
- 因為創建一個對象需要確定對象的類型,而虛函數是運行的時候確定其類型的。構造一個對象時,由于對象還未創建成功,編譯器不能確定對象的實際類型,是類的本身還是派生類等等
- 虛函數的調用需要虛函數表指針,而這個指針存放在對象的內存空間;如果構造函數聲明為虛函數,由于對象還未創建,還沒有內存空間,更沒有虛函數表地址來調用構造函數了
構造函數或者析構函數調用虛函數會怎么樣?
- 構造函數調用虛函數,因為當前對象還未構造完成,調用虛函數指向的是基類的函數的實現方式
- 在析構函數中使用虛函數,調用的是子類的函數的實現方式
純虛函數
- 純虛函數是只是聲明但是沒有定義實現的虛函數,是對子類的約束,是接口的繼承
- 包含純虛函數的類是一個抽象的類,不能被實例化,只有實現了純虛函數的子類才可以生成對象
- 使用場景:當這個類本身產生實例沒有意義的時候,將這個類的函數實現為純虛函數。比如動物可以派生出老虎、兔子等,但是實例化一個動物的對象沒有任何的意義。并且可以規定派生出的子類必須重寫某些函數的時候可以寫成純虛函數
靜態綁定和動態綁定的介紹
- C++中靜態綁定和動態綁定的介紹
- 靜態綁定也就是將該對象相關的屬性或者函數綁定為他的靜態類型,也就是他聲明的類型,在編譯階段就確定。在調用的時候編譯器會尋找它聲明的類型進行訪問
- 動態綁定是將該對象的屬性或者函數綁定為它的動態類型,具體的屬性或者函數是在運行期間確定的,通常通過函數實現動態綁定
- 如果刪除 C中的func函數,在main函數中調用p_c->func(),考慮到派生類里面沒有這個函數,就會到基類中進行調用
class B : public A{
public:void func(){std::cout << "B::func()" << std::endl;}
};
class C : public A{
public:void func(){std::cout << "C::func()" << std::endl;}
};
int main(){C* p_c = new C(); //p_c 的靜態類型和動態類型都是 C*B* p_b = new B(); //p_b 的靜態類型和動態類型都是 B*A* p_a = p_c; //p_a 的靜態類型是它聲明的類型 A*,但是動態類型是p_a所指向的對象p_c的類型 C*p_a = p_b; //p_a 的動態類型是可以修改的,現在他的動態類型是B*,但是其靜態類型仍然是聲明的時候使用的 A*C* p_c_1 = nullptr;//p_c_1的靜態類型是他聲明的類型C*,沒有動態類型,因為它指向了nullptrp_a->func(); //A::func() p_a的靜態類型是A*,不管指向的是哪個子類,都是直接調用的 A::func()p_b->func(); //B::func() p_b的靜態類型和動態類型都是B*,因此調用 B::func()p_c_1->func(); //C::func() 雖然是空指針,但是他的類型在編譯階段就確定了,和空指針空不空沒有任何關系return 0;
}
- 使用virtual函數修飾class A中的函數func()
class A{
public:virtual void func(){std::cout << "A::func()" << std::endl;}
};class B : public A{
public:void func(){std::cout << "B::func()" << std::endl;}
};
class C : public A{
public:void func(){std::cout << "C::func()" << std::endl;}
};
int main(){C* p_c = new C(); //p_c 的靜態類型和動態類型都是 C*B* p_b = new B(); //p_b 的靜態類型和動態類型都是 B*A* p_a = p_c; //p_a 的靜態類型是它聲明的類型 A*,但是動態類型是p_a所指向的對象p_c的類型 C*p_a = p_b; //p_a 的動態類型是可以修改的,現在他的動態類型是B*,但是其靜態類型仍然是聲明的時候使用的 A*BC* p_c_1 = nullptr;//p_c_1的靜態類型是他聲明的類型C*,沒有動態類型,因為它指向了nullptrp_a->func(); //B::func() p_a的靜態類型是A*,因為有了virtual虛函數的特性,p_a的動態屬性指向的是B*,因此先在B中查找,找到后直接調用的 B::func()p_b->func(); //B::func() p_b的靜態類型和動態類型都是B*,因此調用 B::func()p_c_1->func(); //C::func() 空指針異常,因為func是virtual虛函數,因此對func的調用只能等到運行期才可以確定,然后發現是空指針return 0;
}- 如果基類的函數不是virtual虛函數,派生類對象對其的調用都按照其靜態類型來處理,早已在編譯期就確定了
- 如果是虛函數,調用需要等到運行時根據其指向的對象的類型才可以確定,雖然相較于靜態綁定損失了性能,但是卻可以實現多態特性
- 注意:參見Effective C++第三版 條款 37:不要重新定義一個繼承而來的virtual函數的缺省參數數值,因為缺省參數值是靜態綁定的(為了執行的效率),但是virtual是動態綁定的 例子
class A{
public:virtual void func(int i = 1){std::cout << "A::func()\t" << i << std::endl;}
};class B : public A{
public:virtual void func(int i = 2){std::cout << "B::func()\t" << i << std::endl;}
};
int main(){B* p_b = new B();A* p_a = p_b;p_b->func(); //B::func() 2 正確p_a->func(); //B::func() 1 錯誤 調用子類的函數,但是卻使用的是基類中的參數的默認數值return 0;
}深拷貝和淺拷貝的區別(需要說明深拷貝的安全性)
- 淺拷貝就是將對象的指針進行簡單的復制,原對象和副本指向的是相同的資源
- 深拷貝是新開辟一塊內存空間,將對象的資源復制到新的空間中,并且返還該空間的地址
- 深拷貝可以避免重復的釋放和寫沖突。如果對采用淺拷貝的對象進行釋放之后,對原對象的的釋放會導致內存的泄露或者程序的崩潰
 ?補充
?補充
- 深拷貝和淺拷貝的區別和原理
- 深拷貝和淺拷貝的區別 簡單易懂版本
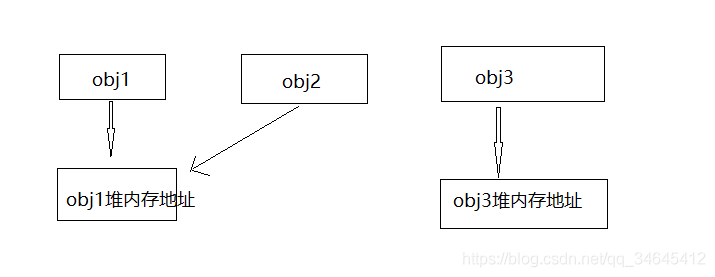
- 淺拷貝:obj2新建了一個對象,但是obj2對象復制的是obj1的指針,也就是堆內存的地址,不是復制對象的本身,因此obj1和obj2共用內存地址;淺拷貝只是數據對象之間的簡單的賦值,比如a.size = b.size,a.data = b.data
- 如果對象中沒有其他的資源(堆、文件、系統資源等)則深拷貝和淺拷貝沒有任何的區別
- 深拷貝:obj3是對obj1的深拷貝,他們不共享內存;當拷貝對象中有對其他資源比如堆、文件、?系統等的引用的時候(引用可以是指針或者引用)時,對象需要另外開辟一段新的資源,而不是單純的賦值
class A{
public:A(int _size):size(_size){data = new int[size]; //假設其中有一段動態分配的內存}A(){}int get_val(){return *data;}~A(){delete[] data;data = nullptr;//析構的時候釋放資源}
private:int size;int* data;
};int main(){A a(5);A b(a);//b=a;std::cout << b.get_val() << std::endl;return 0;
}
- A中的復制構造函數是由編譯器生成的,所以A b(a)執行的是一個淺拷貝,淺拷貝只是對象數據之間的簡單賦值?比如a.size = b.size,a.data = b.data
- 這里b的data指針和a的data指針指向的是同一塊內存空間,b析構的時候會將data指向的內存地址進行釋放,a析構的時候會將已經釋放過的內存再次釋放,這就會導致內存的泄露或者程序的崩潰

class A{
public:A(int _size):size(_size){data = new int[size]; //假設其中有一段動態分配的內存}A(){}int get_val(){return *data;}int *get_val_add(){return data;}A(const A& _A):size(_A.size){data = new int[size];//深拷貝}~A(){delete[] data;data = nullptr;//析構的時候釋放資源}
private:int size;int* data;
};int main(){A a(5);A b(a);//b=a;std::cout << b.get_val() << std::endl;return 0;
}
- 手動書寫 拷貝構造函數,為其分配一段新的內存空間,不會出現內存的泄露問題?
對象復用的了解?零拷貝的了解
- 對象的復用指的是設計模式,對象可以采用不同的設計模式從而達到復用的目的,最常見的就是繼承和組合模式了
- 零拷貝就是指進行操作的時候,避免cpu從一處存儲拷貝到另外一處存儲。在linux環境下,可以減少數據在內核空間和用戶空間來回拷貝,比如使用mmap()替代read調用
- 程序調用mmap(),磁盤上的數據通過DMA拷貝到內存緩沖區,接著操作系統會把這段內存緩沖區和應用程序共享,這樣就不需要將內核緩沖區的內容拷貝到用戶的空間。應用程序再次調用write(),操作系統直接將內存緩沖區的內容拷貝到socket緩沖區中,這一切發生在內核態,最后,socket緩沖區再把數據發送到網卡
C++的構造函數
- 構造函數的全面解析
- 默認構造函數、重載構造函數和拷貝構造函數
- 默認構造函數是黨類沒有實現自己的構造函數的時候,編譯器默認提供的一個構造函數
- 重載構造函數也被稱為一般的構造函數,一個類可以擁有多個重載構造函數,但是需要參數的類型或者參數的個數不相同。可以在重載構造函數中定義類的初始化的方式
- 拷貝構造函數是發生在對象復制的時候調用的;使用舊的對象初始化新的對象,如果程序員自己沒有寫,會進行自我創建
什么情況下會調用拷貝構造函數?三種情況
- 對象使用值傳遞的方式傳入函數的參數 void func(Dog dog){}
- 對象以值的方式從函數進行返回 Dog func(){ Dog d;return d;}
- 對象需要通過另外一個對象進行初始化Dog b; Dog a(b);
- 拷貝構造函數詳解
結構體內存對齊的方式和為什么要實現內存對齊
- 因為結構體成員可以有不同的數據類型,所占的大小也是不一樣的。考慮到CPU是按照數據塊的方式讀取數據的,采用內存對齊的方式就可以使得CPU一次將所需要的數據讀取進來
- 為什么進行內存對齊,以及對齊的規則
對齊的規則
- 第一個成員在與結構體變量偏移量為0的地址
- 其他成員變量需要對齊到某個數字(對齊數)的整數倍的地址處
- 對齊數等于編譯器默認的一個對齊數 與 結構體成員大小中的較小值
- linux默認使用4
- vs中默認數值為8,結構體的總大小為最大對齊數的整數倍(每個變量除了第一個成員都有一個對齊數)
內存泄漏的定義?如何檢測和避免?
- 動態分配的內存空間,使用完畢之后沒有進行釋放,導致一直占用該內存,就是內存的泄露
造成內存的泄露的原因
- 類的構造函數和析構函數中的new和delete字段沒有配套使用
- 釋放對象數組的時候使用的是delete,沒有使用delete[],但是這個對象數組必須是用戶自己構建的對象,不是基本的數據類型,如果是基本的數據類型,使用delete和delete[]的含義是一樣的
- 沒有將基類的析構函數定義為虛函數,當基類指針指向的是子類對象的時候,如果基類的析構函數不是virtual,就會調用的是父類的析構函數,而不是子類的析構函數,造成子類的資源美譽被正確的釋放,從而造成內存的泄露
- 沒有正確的清除嵌套的對象的指針
避免的方法
- malloc/free 需要配套使用
- 使用智能指針
- 將基類的析構函數設置為虛函數
C++智能指針
- 智能指針是對指針進行了簡單的 =包裝,可以像普通指針一樣進行使用,同時可以實現自行的釋放,避免了用戶使用的時候忘記釋放指針指向的內存地址造成的內存泄露問題
- unique_ptr 使用unique_ptr指向的對象,不能對其進行賦值和拷貝,保證了同一個對象同一個時間只能有一個智能指針指向
- shared_ptr? 使用多個指針指向同一個對象,當這個對象的所有智能指針都被銷毀的時候就會自動進行回收。內部使用計數機制進行維護
- weak_ptr 為了協助shared_ptr出現的,他不能訪問對象,只能觀測shared_ptr的引用計數,防止出現死鎖
調試程序的方法
- 設置斷電進行調試
- 打印log進行調試
- 打印中間結果進行調試
遇到coredump如何調試
- coredump是由于異常或者bug在運行的時候異常退出或者終止,在一定的條件下生成一個叫做core的文件,這個core文件會記錄程序運行時候的內存、寄存器的狀態、內存指針和函數的堆棧信息等等。對這個文件進行分析可以得到程序異常的時候對應的堆棧的調用信息
- gdb調試coredump問題
- ulimit -a查看core file size大小是否為0,如果是表明即使產生coredump問題也不會生成core文件,使用ulimit -c unlimited方式設置core文件的大小沒有限制后,再次執行錯誤程序,默認會在當前文件夾下面產生一個名字為 core的文件
- 需要注意編譯代碼的時候需要加上-g參數,例如 g++ coredumpTest.cpp -g -o coredumpTest
- 使用gdb進行代碼的調試 gdb [可執行文件名] [core文件名]
- 在gdb函數內部使用 bt 或者 where命令就可以查看 出現錯誤原因時的堆棧信息
inline關鍵字和宏定義之間的區別是什么
- inline的含義是內聯的意思,可以定義比較小的函數。考慮到函數的頻繁調用需要占用很多的棧空間,進行入棧操作也需要耗費計算資源,因此可以使用inline關鍵字修飾頻繁調用的小函數。編譯器會在編譯階段將inline修飾的代碼嵌入到所有調用的語句塊中
區別
- 內聯函數是在編譯的時候展開,而宏是在預編譯階段時展開
- 編譯的時候,內聯函數直接嵌入到目標代碼中,而宏是一個簡單的簡單的文本替換
- 內聯函數可以進行諸如類型的安全檢查、語句是否正確等編譯功能,宏不具備這樣的功能
- 宏不是函數,而inline是函數
- 宏在定義的時候要小心處理宏參數,一般用括號括起來,否則會出現二義性,內聯函數不會出現二義性
- inline可以不展開,但是宏一定是需要展開的,因為inline對于編譯器來講只是一個建議,編譯器可以選擇忽略該建議,不對函數進行展開
- 宏定義在形式上類似于一個函數,但是在使用它的時候僅僅進行預處理器符號表中的簡單的替換,因此他不能有效的進行參數的檢測,也不能享受C++編譯器嚴格的類型檢查的好處,另外他的返回數值也不能被強制轉換為合適的類型,存在一系列的隱患和局限性
模板的用法和使用的場景
- 使用template<typename T>關鍵字進行聲明,接下來就可以進行模板函數和模板類的編寫
- 編譯器會對函數模板進行兩次編譯:在聲明的地方對模板代碼本身進行編譯,這次編譯只會進行一個語法的檢查,并不會生成具體的代碼。
- 在運行時對代碼進行參數替換后再進行變異,生成具體的函數的代碼
成員初始化列表的概念,為什么使用成員初始化列表會快一些(性能修飾)
- 成員初始化列表就是在類或者結構體的構造函數中,在參數列表列表的后面以冒號開頭,逗號分隔進行的一系列的初始化字段
class A{
public:A(const int& input_id,std::string& input_name):id(input_id),name(input_name){};
private:int id;std::string name;
};- 因為使用成員初始化列表進行初始化的話,會直接使用傳入的參數的拷貝構造函數進行初始化,省去了一次執行傳入參數的默認構造函數的過程,否則會調用一次傳入參數的默認的構造哈數
- 一般針對 類類型,使用內置基本的數據類型,差異不是很明顯,因為減少一次調用默認構造函數的過程,直接使用拷貝構造函數,省去了調用默認構造函數的過程
- 成員初始化列表
三種情況必須使用成員初始化列表進行初始化
- 常量成員的初始化,因為常量成員只能初始化但是不可以賦值
- 引用類型
- 沒有默認構造函數的對象必須使用 成員初始化列表的方式進行初始化。因為直接使用拷貝構造,跳過了 默認構造函數這一步
C++11 的新特性
- 自動類型推導auto:auto的自動類型推導用于從初始化表達式里面推導出變量的數據類型。通過auto的類型推導,大大簡化編程工作
- nullptr:nullptr是為了解決先前C++中NULL的二義性問題而提出的一種新的數據類型,因為實際上NULL表示的是0,而nullptr表示的是void*類型的
- lambda表達式,類似于javascript的中的閉包,用于創建并定義匿名的函數對象,從而簡化編程的工作。lambda的表達式語法如下:[函數對象參數](操作符重載函數的參數)mutable或exception聲明->返回數值的類型{函數體}
- thread 和 mutex類
- 智能指針 shared_ptr? unique_ptr
- C++ 11的新特性
C++函數調用的慣例 (C++函數調用的押棧的過程)
函數調用的過程
- 從棧的空間分配存儲空間
- 從實參的存儲空間復制數值到形參棧的空間
- 進行計算
- 形參在函數調用之前都是沒有分配存儲空間的,在函數調用結束之后,形參彈出棧的空間,清除形參的空間;
- 數組作為參數的函數調用方式是地址傳遞,形參和實參都指向的是相同的內存空間,調用完成之后,形參指針被銷毀,但是指向的內存空間不會被釋放,也不會被銷毀
- 當函數有多個返回數值的時候,不能使用普通的return的方式實現,需要通過傳回地址的形式進行,即地址/指針傳遞。
C++的四種強制類型轉換
- 四種強制的類型轉換,static_cast、dynamic_cast、const_cast和reinterpret_cast
- static_cast 用于各種隱式轉換,具體的講就是各種的基本數據類型之間的轉換,比如將int轉換成char,float轉換成int;以及將派生類(子類)的指針轉換成基類的指針(父類的指針)
- 特性和要點
- 沒有運行時候的類型檢查,所以是具備一定的安全隱患的
- 在派生類的指針轉換成基類指針時不會出現任何問題,但是將基類指針轉換成派生類指針的時候會出現安全性的問題
- static_cast不能轉換const? volatile等屬性
- dynamic_cast 用于動態類型的轉換。具體的講,就是基類指針到派生類指針,或者派生類指針到基類指針之間的轉換。dynamic_cast可以提供運行時候的類型檢查,只用于含有虛函數的類。
- 如果dynamic_cast不能轉換,則返還NULL
- const_cast: 用于去除const屬性,使其const屬性失效,可以對其數據進行修改。還可以volatile屬性的轉換
- reinterpret_cast 幾乎什么都可以進行轉換,用于任意的指針之間的轉換,引用之間的轉換,指針和足夠大的int型之間的轉換,整數到指針的轉換等。但是不具備安全性
string的底層的實現
- string繼承自basic_string,本質上是對char*進行的封裝,封裝的string包含了char*數組、容量,長度等特性。
- string可以進行動態的內存擴展,在每次擴展的時候另外申請一塊先前兩倍大的空間,然后進行字符串的拷貝操作,并添加新增的內容
一個函數或者可執行文件的生成過程或者編譯過程是怎樣的
- 預處理:對預處理命令進行替換等預處理操作
- 編譯:代碼優化和生成匯編代碼
- 匯編:將匯編代碼轉換成機器代碼
- 鏈接:將目標文件彼此鏈接起來
set、map和vector的插入復雜度
- set、map的插入復雜度是紅黑樹的插入復雜度,O(logn)
- unordered_map和unordered_set的插入時間復雜度是常數,O(N)
- vector的插入復雜度是O(N),最壞的情況就是從頭部插入,需要移動其他所有的元素,如果存儲的空間不足,需要進行內存的開辟和拷貝復制
定義和聲明的區別
- 聲明是告訴編譯器變量的類型和名字,但是并不會為變量分配內存空間
- 定義就是對這個變量和函數進行內存的分配和初始化。需要分配空間,同一個變量可以被聲明很多次,但是只能被定義一次
typedef和define的區別
- #definde是預處理的命令,在預處理階段執行簡單的替換,不做正確性的檢查
- typedef是編譯時處理的,他是在自己的作用域內給已經存在的類型起一個別名
被free回收的內存是立即返回給操作系統嗎
- 不是的,被free回收的內存首先被pt malloc使用雙鏈表保存起來,當用戶進行下一次申請內存的時候,會嘗試從這些內存中找到合適的內存空間進行返回。
- 這樣就避免了頻繁的系統調用,占用太多的系統資源。
- 同時ptmalloc也會嘗試對小塊內存進行合并,避免產生過多的內存碎片
- 參考鏈接
引用作為函數的參數以及返回數值的好處
- 在函數內部可以對此參數進行修改
- 提高函數的調用和運行的效率(沒有了傳值和生成副本的時間和空間的損耗)
- 如果函數的實質是形參,不過這個形參的作用域只是在函數的內部也就是形參和實參是兩個不同的東西,如果想要形參代替實參肯定需要一個數值的傳遞。函數調用的時候,數值的傳遞是通過”形參=實參“來對形參進行賦值從而達到傳值的目的,產生一個實參的副本。即使函數的內部對參數進行修改,針對的也是形參,也就是拷貝的副本,實參不會發生任何的改變,函數一旦執行結束,形參生命周期也被宣告終結,做出修改一樣沒有對任何變量產生影響
- 使用引用最大的好處是內存中不產生返回數值的副本
- 但是需要有以下方面的限制
- 1,不能返回局部變量的引用。因為函數結束之后局部變量的內存地址就會被銷毀
- 2,不可以返回函數內部new分配的內存的引用,雖然不存在局部變量的被動銷毀的問題,但是返回函數內部new分配的內存的引用,會出現別的問題。比如,函數返回的引用只是作為一個臨時變量出現但是沒有被賦予一個實際的變量,那么這個引用所指向的內存空間(new分配)就無法進行釋放,造成內存的泄露
- 3,可以返回類成員的引用,但是最好是const。因為如果其他對象可以獲得該屬性的非常量的引用,對這個屬性的單純的賦值就會導致業務規則的完整性的破壞
友元函數和友元類
- 友元提供了不同類的成員函數、類的成員函數和一般函數之間的數據共享的機制
- 通過友元,一個不同的函數或者一個類的=中的成員函數可以訪問類中的私有成員和保護成員
- 友元的正確使用可以提高程序的運行效率,但是友元會破壞了類的封裝和數據的隱藏性,導致程序可維護性變差
- 友元函數是定義在類外的普通函數,不屬于任何類,但是可以訪問其他類的私有和保護成員,但是需要在類的定義中聲明所有可以訪問他的友元函數,就是表明誰是我的朋友
class A{
public:friend void set_show(int x,A &a);//這個函數是友元函數的聲明
private:int data;
};void set_show(int x,A &a){a.data = x;std::cout << a.data << std::endl;
}int main(){A a;set_show(1,a);return 0;
}
- 友元類
- 友元類的所有成員函數都是另外一個類的友元函數,都可以訪問另外一個類中的隱藏信息(包括私有成員和保護成員)
- 但是需要在另外一個類里面進行對應的聲明
class A{
public:friend class B;//這個是友元類的聲明
private:int data;
};class B{
public:void set_show(int x,A &a){a.data = x;std::cout << a.data << std::endl;}
};int main(){A a;B b;b.set_show(1,a);return 0;
}
使用友元類的注意事項
- 友元關系是不能被繼承的
- 友元關系是單向的,不具備交換性。如果類B是類A的友元,但是類A不一定是類B的友元,需要看在類中是否有對應的聲明
- 友元關系不具備傳遞性,需要看類中是否有對應的聲明。就像朋友關系不可以傳遞一樣
說一下volatile關鍵字的作用
- volatile翻譯是脆弱的意思,表明用其修飾的變量十分容易被改變,所有編譯器不會對其進行優化(CPU的優化是將變量的數值存放到CPU寄存器而不是內存),進而提供穩定的訪問。每次讀取volatile變量的時候系統總是會從內存中讀取這個變量,并將其數值立刻保存
STL中sort()算法是用什么實現的?stable_sort()呢?
- sort()使用的是快速排序和插入排序相互結合的方式實現的
- stable_sort使用的是歸并排序
vector的迭代器會失效嗎?什么情況下迭代器會失效
- 會失效
- vector插入的時候,如果先前分配的空間不足,會申請新的空間并將原來的元素移動到新的內存,這個時候指向先前的地址的迭代器就會失效,first和end迭代器都會失效
- vector插入的時候,end迭代器肯定失效
- vector刪除的時候,被刪除的元素以及刪除元素之后元素迭代器會失效
為什么C++沒有實現垃圾回收機制
- 實現垃圾回收機制需要帶來額外的空間和時間的開銷,你需要開辟一定的空間來保存指針和引用的計數、以及對他們的標價mark。然后需要開辟一個線程在空閑的時候進行free操作
- 垃圾回收機制會使得C++不適合很多底層的操作





...)








)




