文章目錄
- 可視化數據的分布
- 繪制單變量分布
- 繪制雙變量分布
- 繪制成對的雙變量分布
- 用分類數據繪圖
- 類別散點圖
- 通過stripplot()函數畫散點圖
- swarmplot()函數
- 類別內的數據分布
- 繪制箱型圖
- 繪制提琴圖
- 類別內的統計估計
- 繪制條形圖
- 繪制點圖
可視化數據的分布
繪制單變量分布
一般采用最簡單的直方圖描述單變量的分布情況。Seaborn中提供了displot()函數。
distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None,
hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,
color=None, vertical=False, norm_hist=False, axlabel=None,
label=None, ax=None)
上述函數中常用的參數含義如下:
- a:表示要觀察的數據,可以是Sries、一維數組或列表
- bins:用于控制條形的數量
- hist:接收布爾類型,表示是否繪制(標注)直方圖
- kde:接收布爾類型,表示是否繪制高斯核密度估計曲線
- rug:接收布爾類型,表示是否在支持的軸的方向上繪制rugplot
通過distplot()函數繪制直方圖:
import seaborn as sns
import numpy as npsns.set() # 顯式調用set()獲取默認繪圖
np.random.seed(0) # 確定隨機數生成器的種子
arr = np.random.randn(100) # 生成隨機數組
ax = sns.distplot(arr, bins=10) # 繪制直方圖
輸出結果:
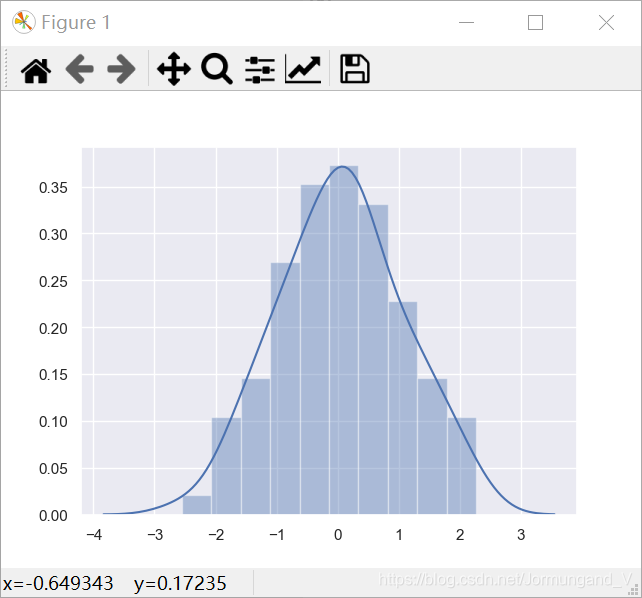
由圖可得,直方圖共有10個條柱,每個條柱的顏色為藍色,并且擁有核密度估計曲線。核密度估計是在概率論中用來估計未知的密度函數,屬于非參數檢驗方法之一,可以比較直觀地看出數據樣本本身的分布特征。
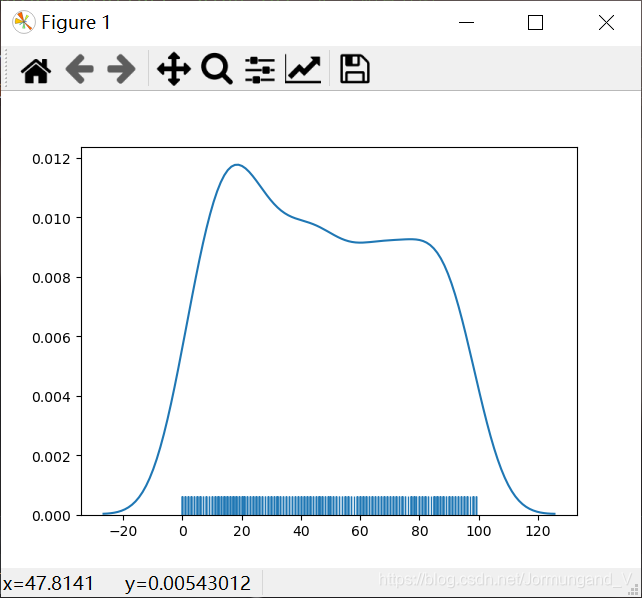
如果想要僅擁有核密度估計曲線,設置相關參數即可:
arr_random = np.random.randint(0, 100, 500) # 繪制包含500個位于[0, 100)之間的隨機整數數組
sns. distplot(arr_random, hist=False, rug=True) # 繪制核密度估計曲線
輸出結果:
繪制一條核密度估計曲線,并且在x軸的上方生成了觀測數值的小細條。
注意:如果希望Seaborn用Matplotlib的默認樣式,之前可以通過從Seaborn庫中導入apionly模塊解決這個問題,但是從2017年7月起這個方法已經被棄用了。因此,現在導入Seaborn時,需要顯式地調用set()或set_style()、set_context()和set_palette()中的一個或多個函數,以獲取Seaborn或者Matplotlib默認的繪圖樣式。
擬合并繪制核密度估計曲線還可以使用kedeplot()函數
繪制雙變量分布
兩個變量的二元分布可視化可以顯示兩個變量之間的雙變量關系以及每個變量在單獨坐標軸上的單變量分布。
jointplot(x, y, data=None, kind=“scatter”, stat_func=None,
color=None, height=6, ratio=5, space=.2,
dropna=True, xlim=None, ylim=None,
joint_kws=None, marginal_kws=None, annot_kws=None, **kwargs)
上述函數中常用參數的含義如下:
- kind:表示繪制圖形的類型
- stat_func:用于計算有關關系的統計量并標注圖
- size:用于設置圖的大小(正方形)
- ratio:表示中心圖與側邊圖的比例。該參數的值越大,則中心圖的占比會越大。
- space:用于設置中心圖與側邊圖的間隔大小。
- xlim,ylim:表示x、y軸的范圍。
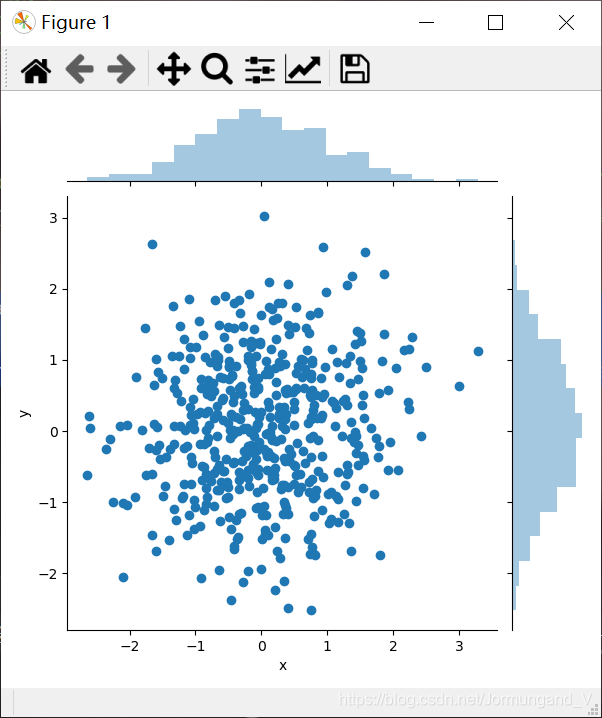
繪制散點圖:
dataframe_obj = pd.DataFrame({"x": np.random.randn(500),"y": np.random.randn(500)}) # 創建DataFrame對象
sns.jointplot(x="x", y='y', data=dataframe_obj) # 繪制散點圖
輸出結果:
x軸的名稱為“x”,y軸的名稱為“y”,兩軸的數據均為500個隨機數。可以看到的是散點圖的上方和右側增加了直方圖,便于觀察x和y軸數據的整體分布情況,并且它們的均值都是0。
繪制二維直方圖:
dataframe_obj = pd.DataFrame({"x": np.random.randn(500),"y": np.random.randn(500)}) # 創建DataFrame對象
sns.jointplot(kind='hex', data=dataframe_obj, x='x', y='y') # 繪制二維直方圖
輸出結果:
從六邊形顏色的深淺,可以觀察到數據密集的程度,圖形的上方和右側依然給出了直方圖。
注意: 繪制二維直方圖時最好是用白色背景以便觀察六邊形顏色深淺。
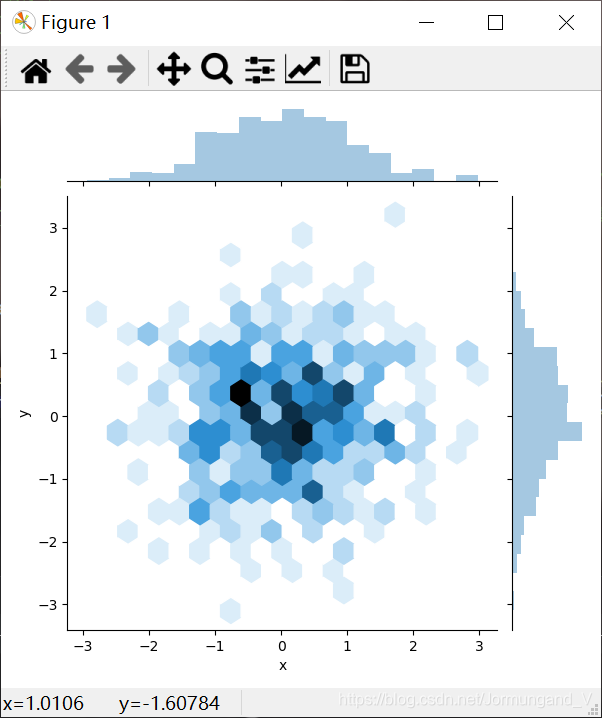
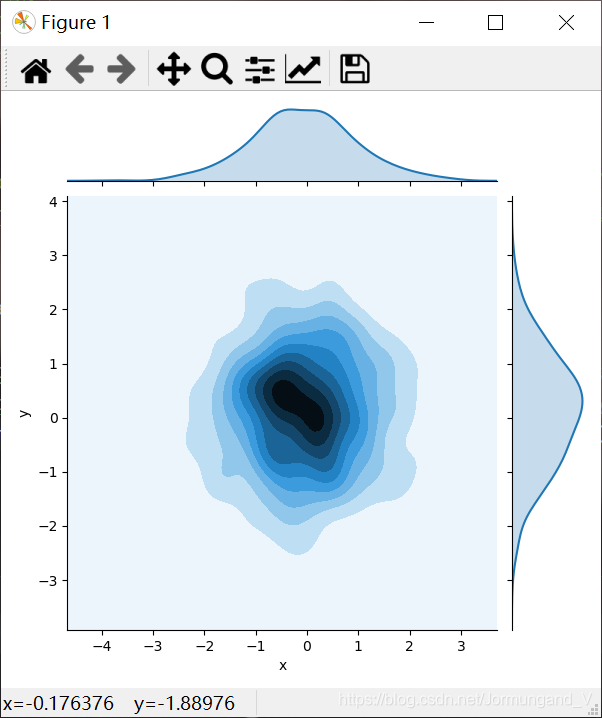
繪制核密度估計圖形:
利用核密度估計同樣可以查看二元分布,Seaborn中用等高線圖來表示。
sns.jointplot(kind='kde', x='x', y='y', data=dataframe_obj) # 繪制核密度估計圖形
輸出結果:
繪制了核密度的等高線圖,通過觀察等高線的顏色深淺,可以看出哪個范圍的數值分布的最多,哪個范圍的數值分布的最少。同樣的,在圖形的上方和右側給出了核密度曲線圖。
繪制成對的雙變量分布
要想在數據集中繪制成對的雙變量分布,則可以使用pairplot()函數實現,該函數會創建一個坐標軸矩陣,并顯示DataFrame對象中每對變量的關系。該函數亦可繪制每個變量在對角軸上的單變量分布。
代碼如下:
通過load_dataset()函數加載了seaborn中內置的數據集,根據tips數據集繪制多個雙變量分布。【如無法正確運行,則在這里下載zip文件,然后在電腦中,使用搜索功能找到seaborn-data文件夾,將zip文件解壓到文件夾中,具體步驟如下圖:】
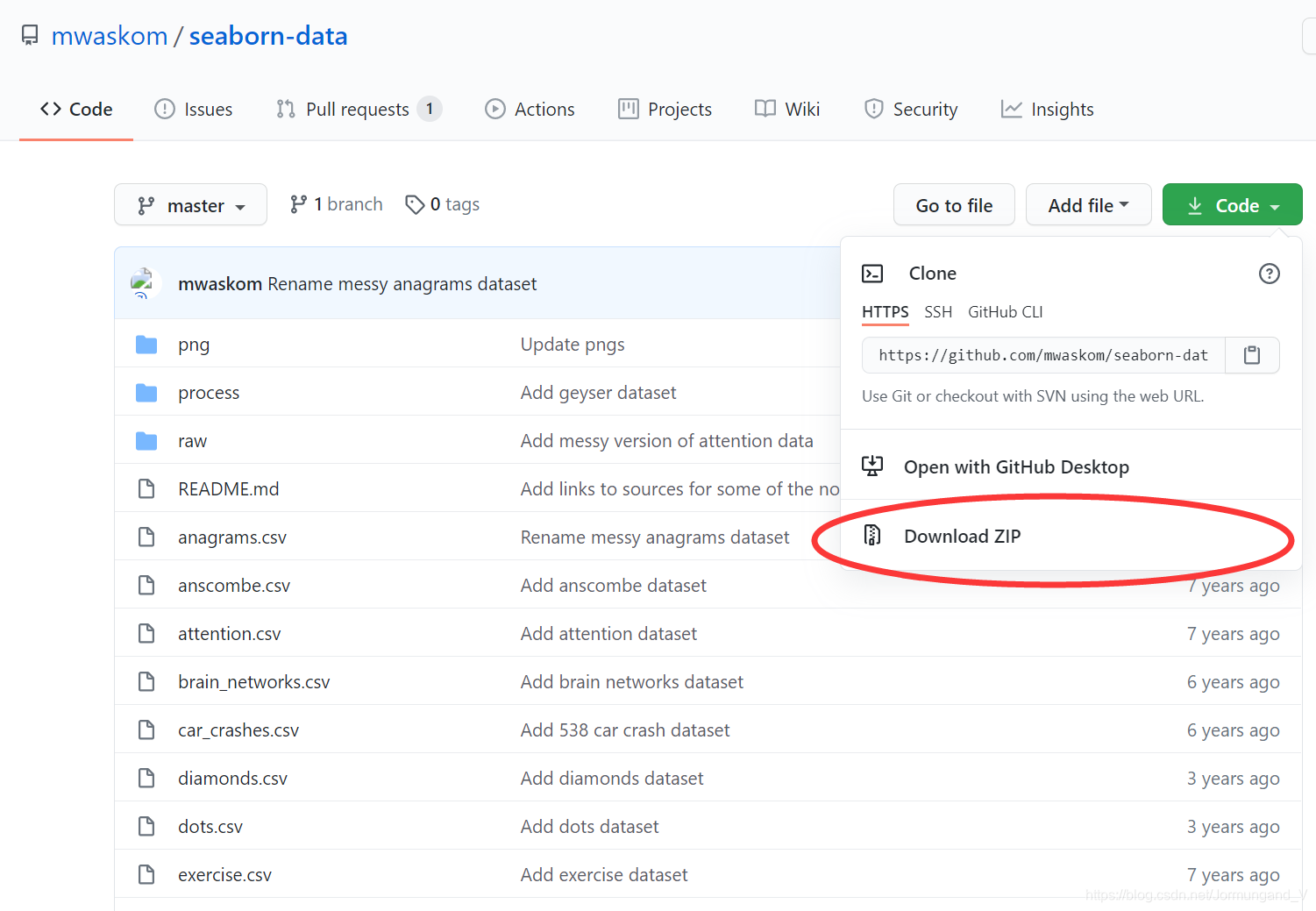
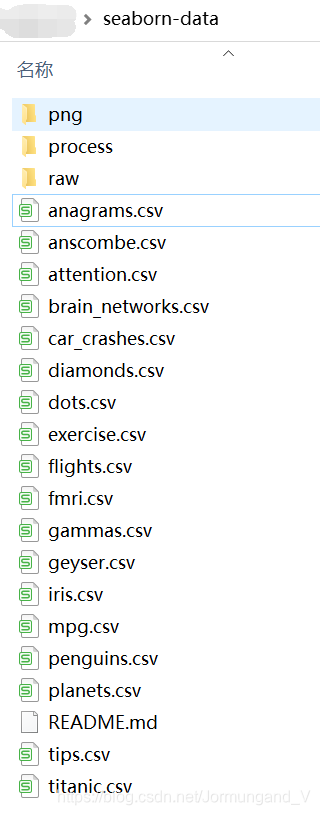
dataset = sns.load_dataset("tips") # 加載seaborn中的數據集
sns.pairplot(dataset) # 繪制多個成對的雙變量分布
輸出結果:
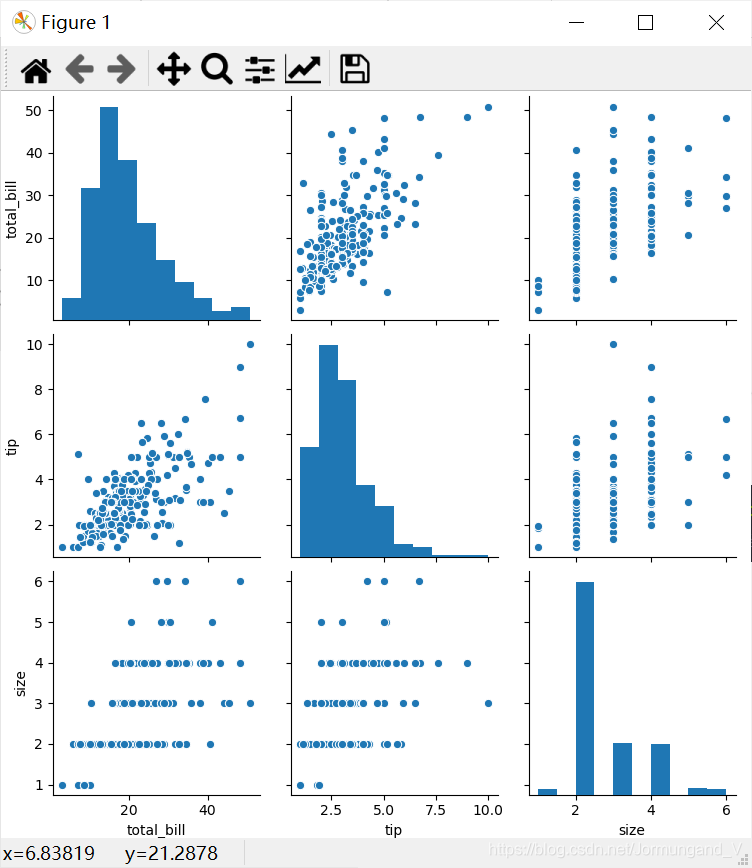
用分類數據繪圖
類別散點圖
stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
jitter=True, dodge=False, orient=None, color=None, palette=None,
size=5, edgecolor=“gray”, linewidth=0, ax=None, **kwargs)
上述函數中常用參數如下:
- x,y,hue:用于繪制長葛市數據的輸入。
- data:用于繪制的數據集。如果x和y不存在,則它將作為寬格式,否則將作為長格式。
- order,hue_order:用于繪制分類的級別。
- jitteer:表示抖動的程度(僅沿類別軸)。當很多數據點重疊時,可以指定抖動的數量,或者設為True使用默認值。
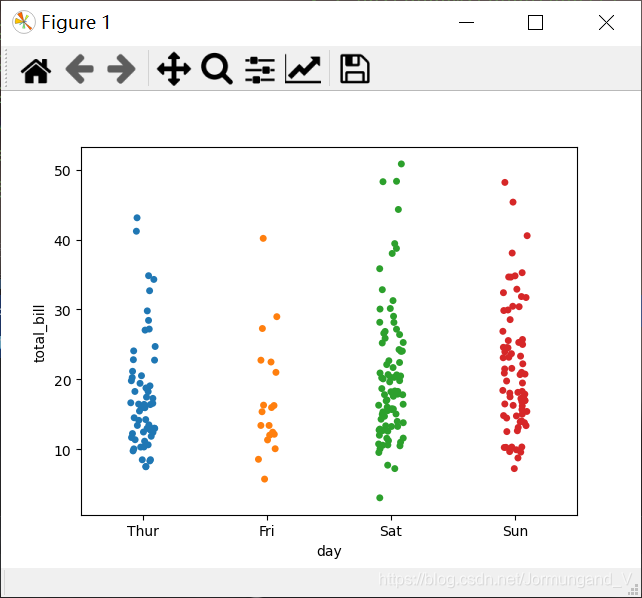
通過stripplot()函數畫散點圖
代碼如下:
tips = sns.load_dataset("tips")
sns.stripplot(x='day', y='total_bill', data=tips)
輸出結果:
從圖中可以看出,圖標橫坐標時分類的數據,而且一些數據點會互相重疊,不易于觀察。可以在調用stripplot()函數時傳入jitter參數,以調整橫坐標的位置。
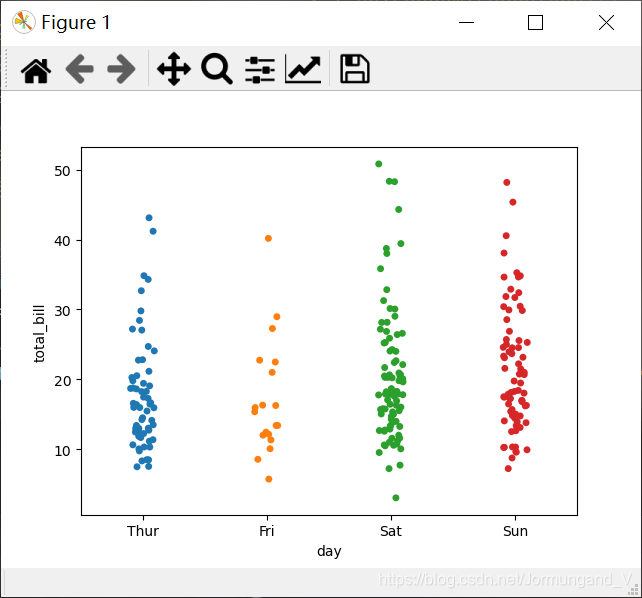
改變橫坐標的位置:
tips = sns.load_dataset("tips")
sns.stripplot(x='day', y='total_bill', data=tips, jitter=True)
輸出結果:
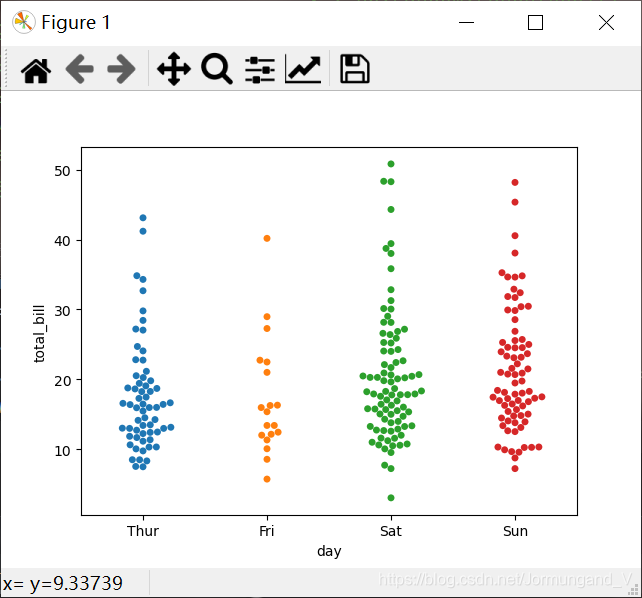
swarmplot()函數
亦可使用swarmplot()函數繪制散點圖,該函數的好處是所有的數據點都不會重疊,可以很清晰地觀察到數據的分布情況。
代碼如下:
tips = sns.load_dataset("tips")
sns.swarmplot(x='day', y='total_bill', data=tips)
輸出結果:
類別內的數據分布
由于散點圖查看各個分類中的數據分布不夠直觀,故可利用下列兩種圖形查看:
- 箱型圖:直觀地查看數據的四分位分布(1/4分位,中位數,3/4分位以及四分位距)
- 提琴圖:箱型圖與核密度圖地的結合,可以展示任意位置的密度,可以很直觀地看到哪些位置的密度較高
繪制箱型圖
boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
orient=None, color=None, palette=None, saturation=.75,
width=.8, dodge=True, fliersize=5, linewidth=None,
whis=1.5, ax=None, **kwargs)
上述函數常用參數如下:
- orient:表示數據垂直或水平顯示,取值為“v”|“h”
- palette:用于設置不同級別色相的顏色變量。
- saturation:用于設置數據顯示的顏色飽和度。
代碼如下:
tips = sns.load_dataset("tips")
sns.boxplot(x='day', y='total_bill', data=tips)
輸出結果:
x軸的名稱為day,刻度范圍是Thur ~ Sun(周四至周日),y軸的名稱為total_bill,刻度范圍為10 ~ 50左右。
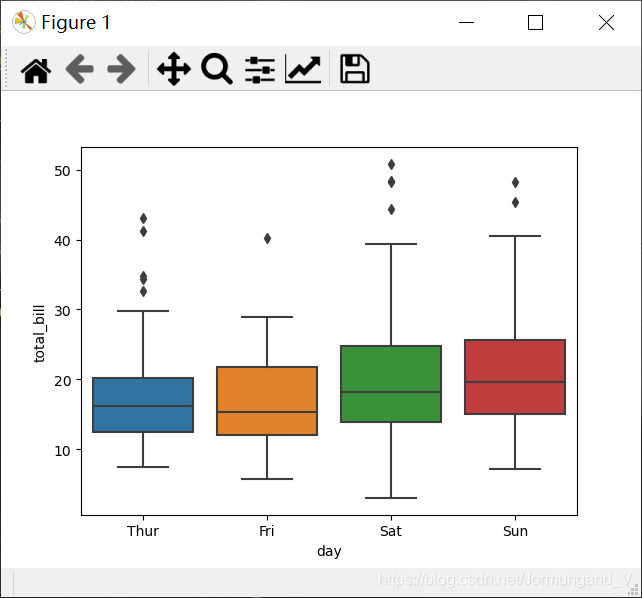
從圖中可以看出,Thur列、Fri列中大部分數據都小于30,但Thur列有5個異常值大于30、Fri列中有1個異常值大于40;Sat列中有3個大于40的異常值;Sun列中有兩個大于40的異常值。
繪制提琴圖
violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
bw=“scott”, cut=2, scale=“area”, scale_hue=True, gridsize=100,
width=.8, inner=“box”, split=False, dodge=True, orient=None,
linewidth=None, color=None, palette=None, saturation=.75,
ax=None, **kwargs)
代碼如下:
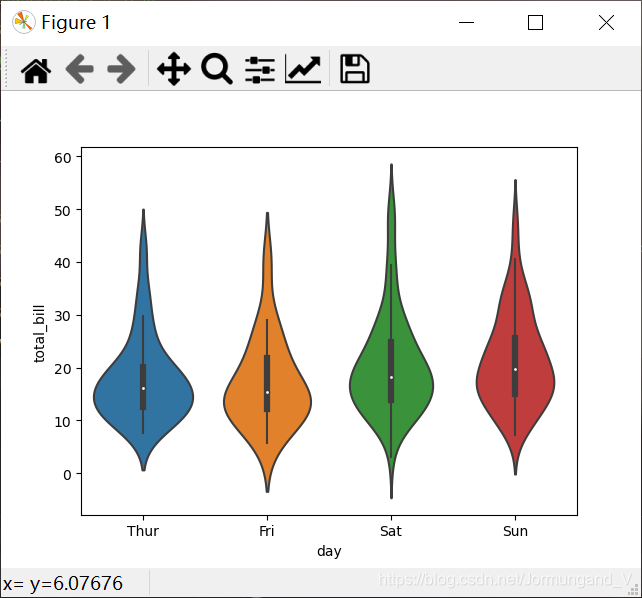
tips = sns.load_dataset("tips")
sns.violinplot(x='day', y='total_bill', data=tips)
輸出結果:
由圖可得,Thur列中位于5 ~ 25之間的數值較多,Fri列中位于5 ~ 30之間的數值較多,Sat列中位于5 ~ 35之間的數值較多,Sun列中位于5 ~ 40之間的數值較多。
類別內的統計估計
想要集中查看每個分類的集中趨勢可以使用條形圖和點圖進行展示。
- barplot()函數:繪制條形圖
- pointplot()函數:繪制點圖。
繪制條形圖
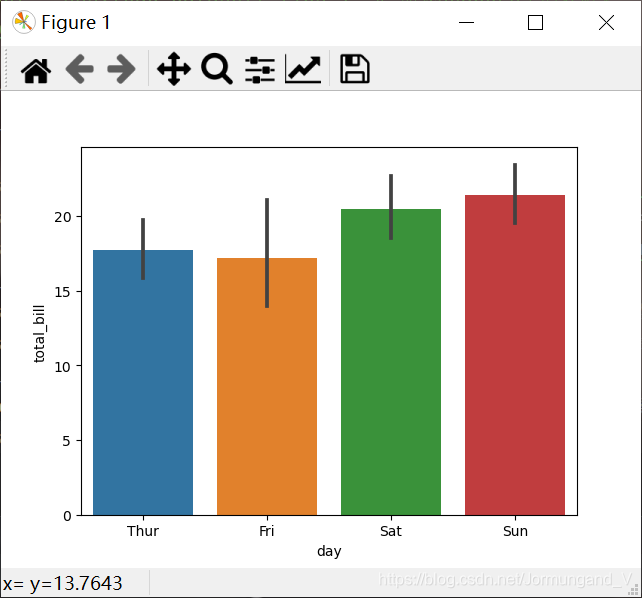
默認情況下, barplot()函數會在整個數據集上使用均值進行估計。若每個類別中有多個類別時(使用了hue參數),則條形圖可以使用引導來計算估計的置信區間(樣本統計量構造的總體參數的估計區間),并使用誤差條來表示置信區間。
代碼如下:
tips = sns.load_dataset("tips")
sns.barplot(x='day', y='total_bill', data=tips) # 繪制條形圖
輸出結果:
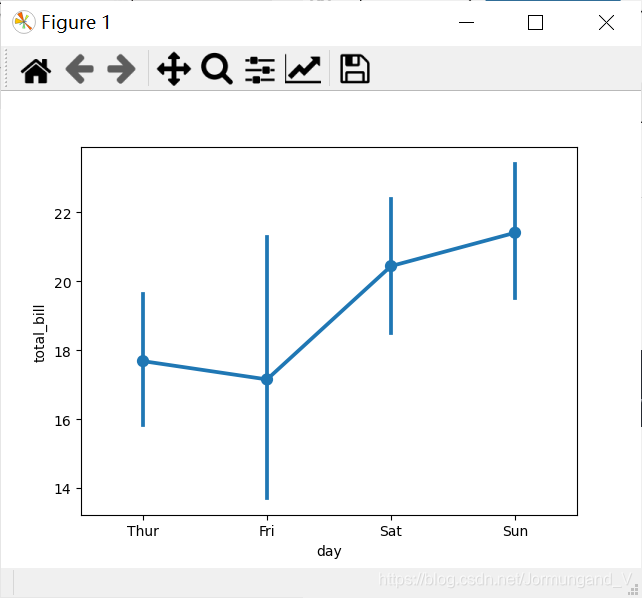
繪制點圖
該函數會用高度估計值對數據進行描述,而不是顯示完整的條形,只繪制點估計和置信區間。
代碼如下:
tips = sns.load_dataset("tips")
sns.pointplot(x='day', y='total_bill', data=tips) # 繪制點圖
輸出結果: