前言
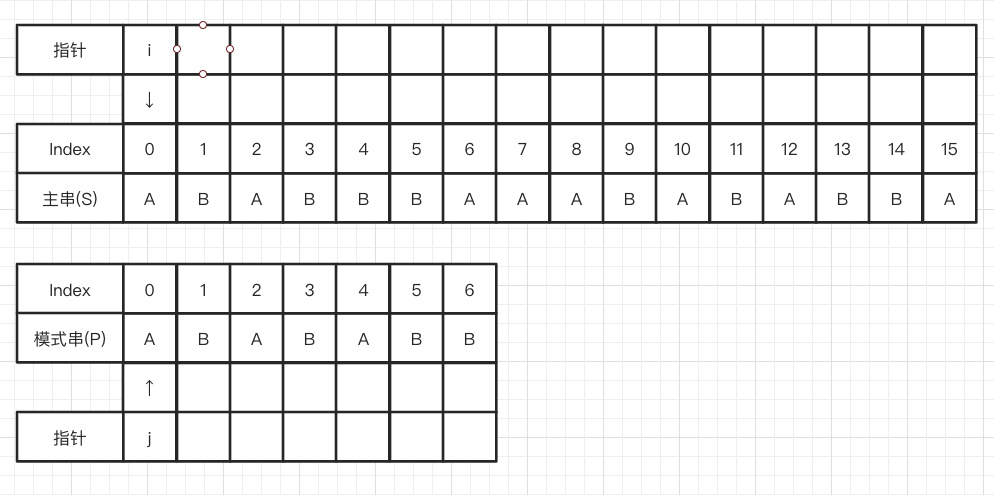
文章的一開頭,還是要強調下字符串匹配的思路
- 將
模式串和主串進行比較
- 從前往后比較
- 從后往前比較
2. 匹配時,比較主串和模式串的下一個位置
3. 失配時,
- 在
模式串中尋找一個合適的位置- 如果找到,從這個位置開始與
主串當前失配位置進行比較 - 如果未找到,從
模式串的頭部與主串失配位置的下一個位置進行比較
- 如果找到,從這個位置開始與
- 在
主串中找到一個合適的位置,重新與模式串進行比較
前面的 BF 和 KMP 算法,都是屬于規規矩矩從前向后的操作,后者僅在尋找模式串的合適位置上進行了優化,而 BM 算法的操作就顯得騷了很多,它的優化點在于: 1. 從后往前比較 2. 失配時,尋找的是主串中合適的位置
算法介紹與分析
關于算法的介紹和分析,網上有很多解釋,這里推薦一下阮一峰的字符串匹配的Boyer-Moore算法,很清楚的講解了整個優化的思路,可以先看完理解了再往下看,因為下面主要介紹一下壞字符規則和好后綴規則需要的數據結構的手工求法以及代碼實現。
壞字符規則
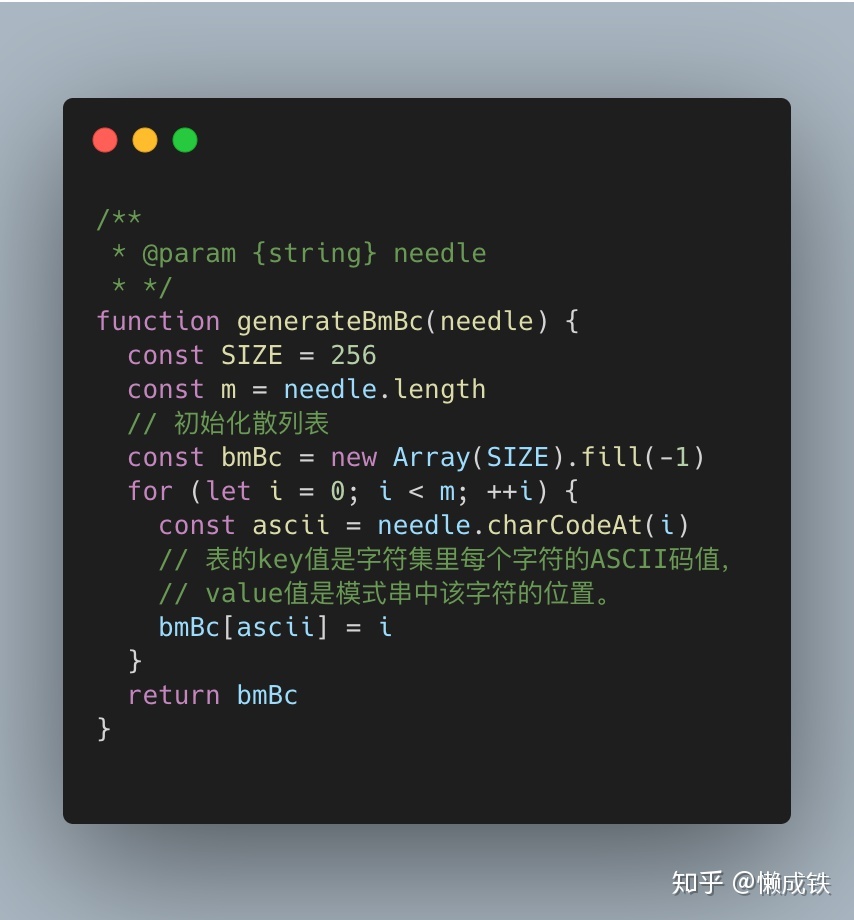
運用壞字符規則,在算法里主要體現在生成一張散列表,表的key值是字符集里每個字符的ASCII碼值,value值是模式串中該字符的位置,舉個栗子:
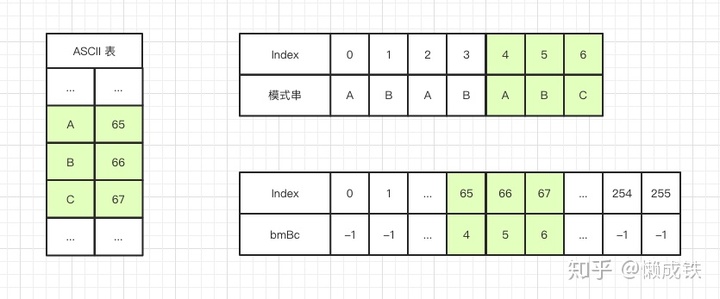
假設字符串的字符集不是很大,用長度為256的數組來存儲,并且初值賦值為-1。數組的下標對應字符的 ASCII 碼值,數組中存儲這個字符在模式串中出現的位置。這里要特別說明一點,如果壞字符在模式串里多處出現,選擇最靠后的那個,因為這樣不會讓模式串滑動過多,導致本來可能匹配的情況被滑動略過。
好后綴規則
好后綴規則體現在如何求出 suffix 和 prefix 兩個數組以及移動規則。
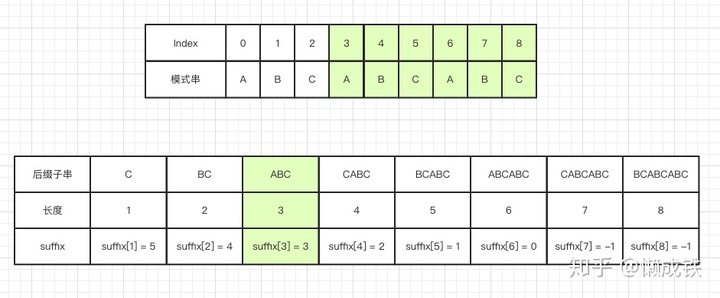
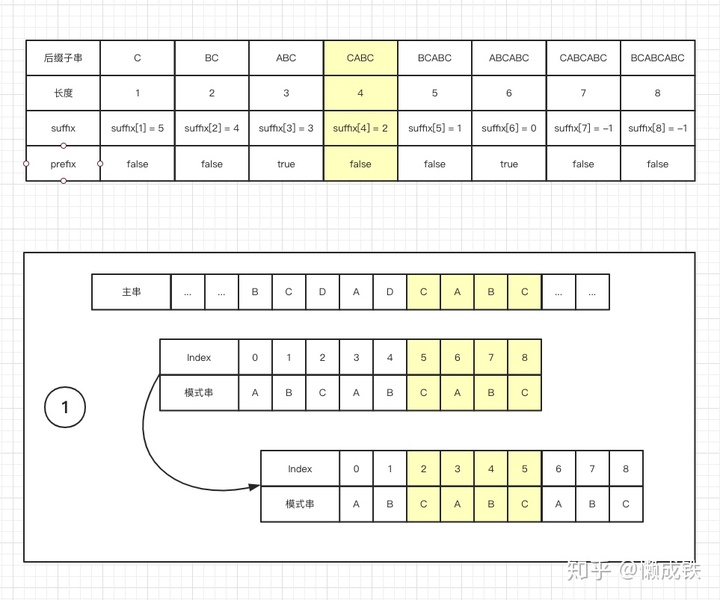
suffix 數組
key值表示的是后綴子串的長度,value值表示的是在模式串中跟好后綴 S 相匹配的最后一個子串 S' 的首字母在模式串中的key值,如下圖:
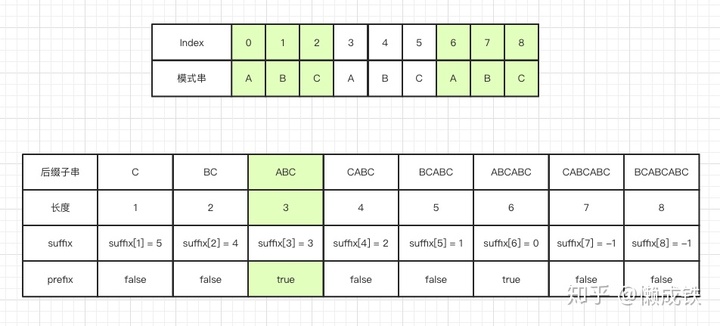
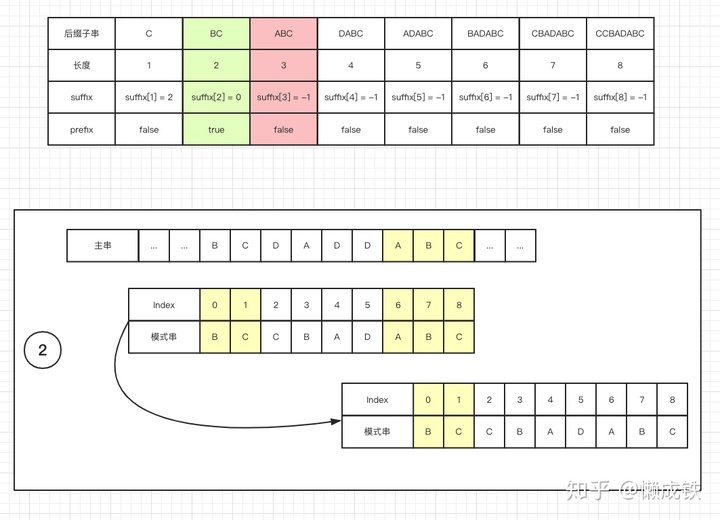
prefix 數組
同樣的,key值表示的是后綴子串的長度,而value值表示的是模式串中,是否有和該長度下后綴子串相同的前綴子串,是的話為 true,否則為 false,如下圖:
移動規則
移動規則總結如下
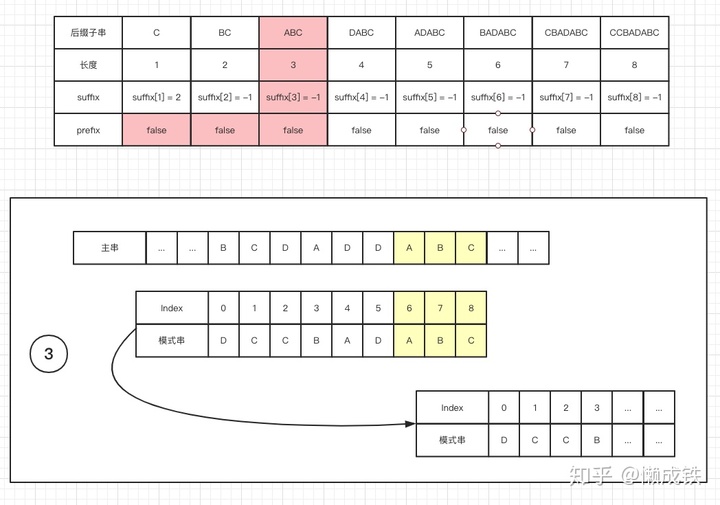
- 在
模式串中尋找跟好后綴 S 相匹配的最后一個子串 S' - 如果找到,將
模式串移動到使得 S' 和主串對齊的位置 - 如果找不到,再尋找
模式串的前綴子串中是否有和好后綴 S的后綴子串匹配的位置,滑動模式串以對齊。 - 如果仍然找不到,則將
模式串移動至主串與模式串末尾對齊的下一個位置
下圖分別對應三種情況:
代碼實現
整體邏輯框架
參考字符串匹配的思路
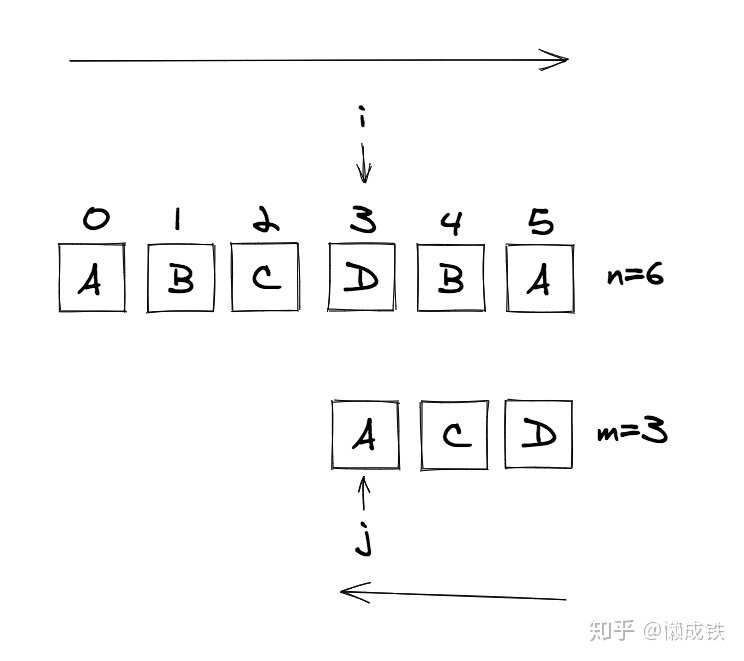
- 仍然需要進行
主串和模式串的字符對比,所以需要兩個指針i,j分別指向主串和模式串,記錄位置 需要一個循環來重復進行匹配操作,此時思考終止條件:i指向主串每次匹配的合適位置,從前往后掃描;j指向模式串的尾部,從后往前掃描。考慮極端情況:主串和模式串對比完,仍然無法匹配。此時,i的位置一定小于等于主串長度n與模式串長度m的差值。具體可看下圖。
- 每次
模式串從后往前與主串進行匹配,這也需要一個內層循環來驅動指針j如果匹配,只需要繼續移動匹配位置即可 - 如果失配,分別根據
壞字符規則和好后綴規則計算出i需要移動的位置,選擇兩個值當中最大的,重新計算i的值,重復進行匹配。
根據以上分析可以寫出整個的邏輯框架代碼:
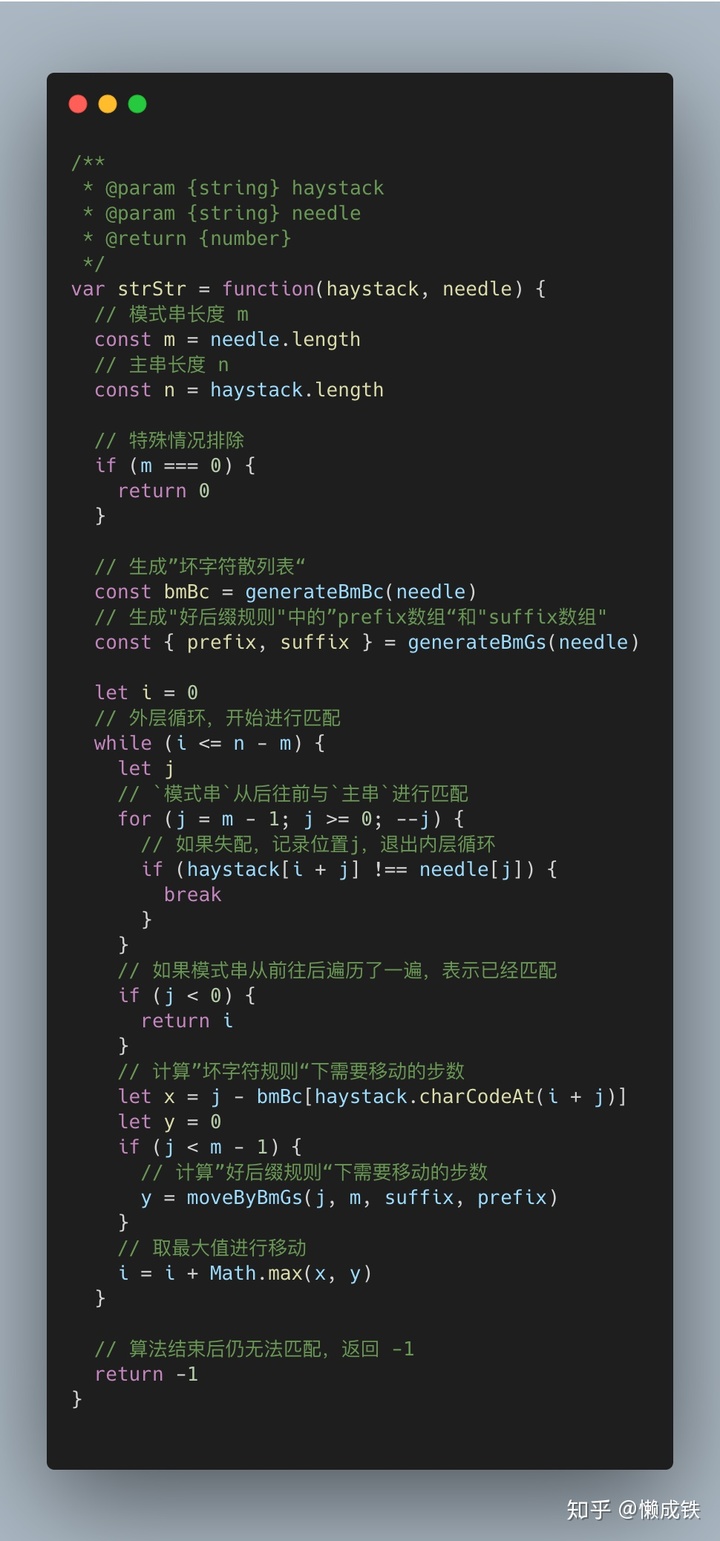
框架寫好后,接下來就是完善三個輔助函數即可
求壞字符散列表
這個就沒有什么可以多說的了,只要參考上面分析的,一步一步寫出代即可:
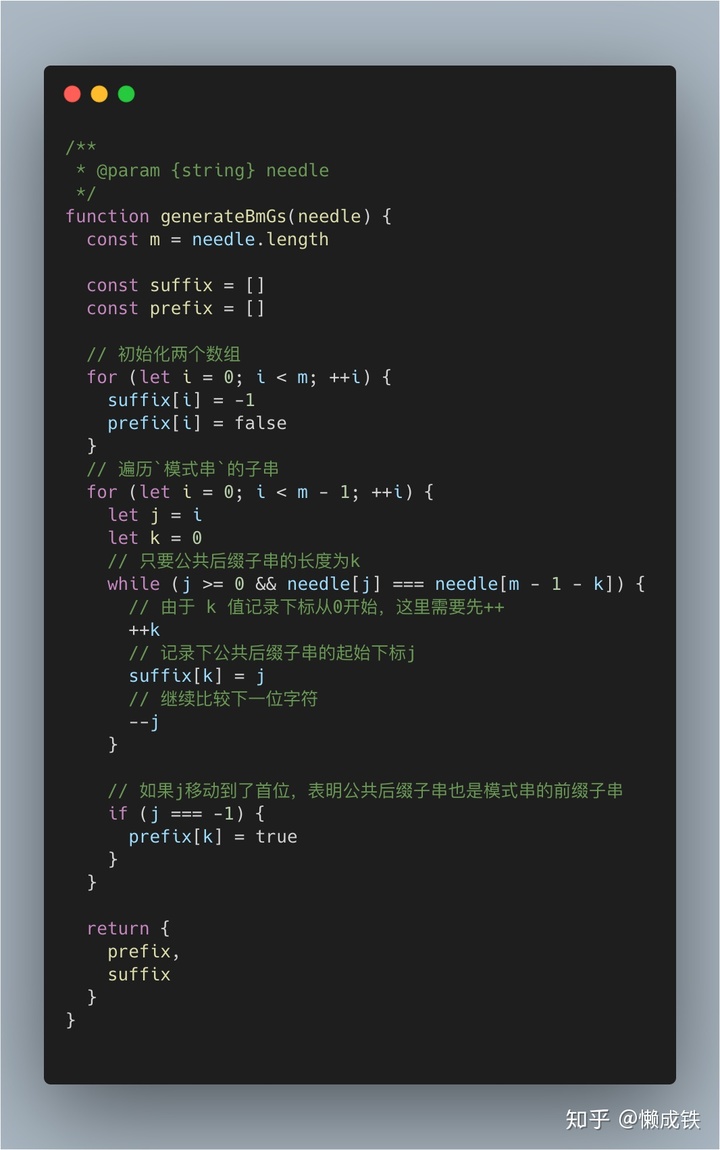
求好后綴記錄數組 suffix 和 prefix
拿下標從 0 到 i 的子串(i 可以是 0 到 m-2)與整個模式串,求公共后綴子串。如果公共后綴子串的長度是 k,那就記錄 suffix[k]=j(j 表示公共后綴子串的起始下標)。如果 j 等于 0,也就是說,公共后綴子串也是模式串的前綴子串,就記錄 prefix[k]=true。可以自己動下手,模擬下代碼的運行,尤其注意中k值的運用,很巧妙。
求好后綴移動步數
根據上面此步的算法分析,也可以寫出:

總結
總的來說,BM算法另辟蹊徑,通過從后往前的匹配的思路,加上壞字符規則和好后綴規則來優化移動的步數,從而提高算法的匹配效率。
后記
“字符串匹配算法”是“重學數據結構與算法”系列筆記:
- 字符串匹配算法(一)——BF算法
- 字符串匹配算法(二)——KMP算法
- 字符串匹配算法(三)——BM算法
- 字符串匹配算法(四)——Sunday算法

(轉載))



韓順平jsp購物車源代碼(包含數據庫))











)

