關于 PyFlink 的博客我們曾介紹過?PyFlink 的功能開發,比如,如何使用各種算子(Join/Window/AGG etc.),如何使用各種 Connector(Kafka, CSV, Socket etc.),還有一些實際的案例。這些都停留在開發階段,一旦開發完成,我們就面臨激動人心的時刻,那就是將我們精心設計開發的作業進行部署,那么問題來了,你知道怎樣部署 PyFlink 的作業嗎?
本文將為大家全面介紹部署 PyFlink 作業的各種模式。
組件棧回顧
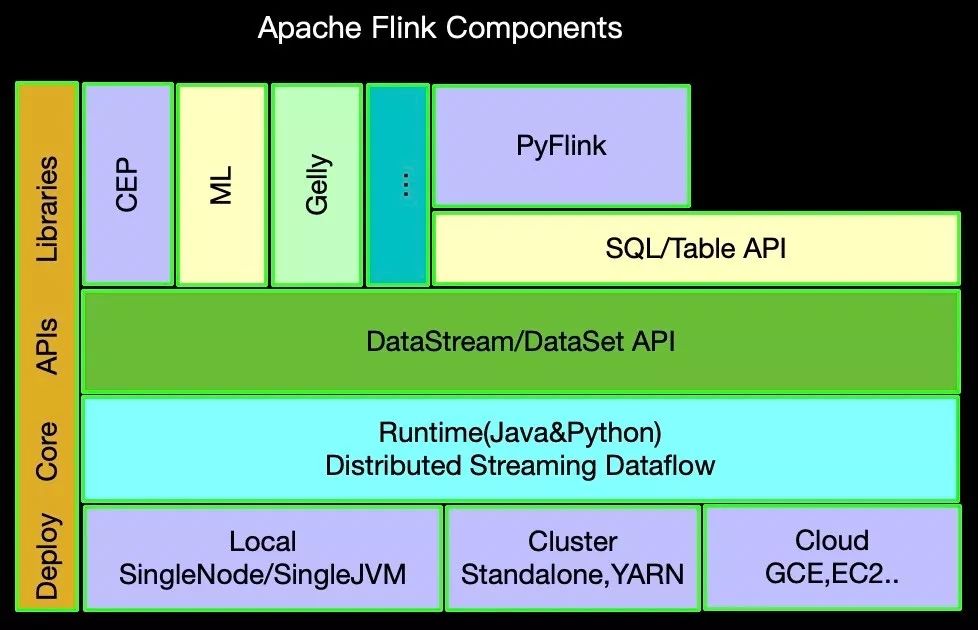
上面的組件棧除了 PyFlink 是第一次添加上去,其他部分大家應該非常熟悉了。目前 PyFlink 基于 Java 的 Table API 之上,同時在 Runtime 層面有 Python 的算子和執行容器。那么我們聚焦重點,看最底層的 Deploy 部分,上圖我們分成了三種部署模式,Local/Cluster/Cloud,其中 Local 模式還有 2 種不同方式,一是 SingleJVM,也即是 MiniCluster, 前面博客里面運行示例所使用的就是 MiniCluster。二是 SingleNode,也就是雖然是集群模式,但是所有角色都在一臺機器上。下面我們簡單介紹一下上面這幾種部署模式的區別:
Local-SingleJVM 模式:該模式大多是開發測試階段使用的方式,所有角色TM,JM 等都在同一個 JVM 里面。
Local-SingleNode 模式:意在所有角色都運行在同一臺機器,直白一點就是從運行的架構上看,這種模式雖然是分布式的,但集群節點只有 1 個,該模式大多是測試和 IoT 設備上進行部署使用。
Cluster 模式:也就是我們經常用于投產的分布式部署方式,上圖根據對資源管理的方式不同又分為了多種,如:Standalone 是 Flink 自身進行資源管理,YARN,顧名思義就是利用資源管理框架 Yarn 來負責 Flink運行資源的分配,還有結合 Kubernetes 等等。
Cloud 模式:該部署模式是結合其他云平臺進行部署。
接下來我們看看 PyFlink 的作業可以進行怎樣的模式部署?
環境依賴
JDK 1.8+ (1.8.0_211)
Maven 3.x (3.2.5)
Scala 2.11+ (2.12.0)
Python 3.5+ (3.7.6)
Git 2.20+ (2.20.1)
源碼構建及安裝
在 Apache Flink 1.10 發布之后,我們除了源碼構建之外,還支持直接利用 pip install 安裝 PyFlink。那么現在我們還是以源碼構建的方式進行今天的介紹。
下載源碼
git clone https://github.com/apache/flink.git簽出 release-1.10 分支(1.10 版本是 PyFlink 的第二個版本)
git fetch origin release-1.10git checkout -b release-1.10 origin/release-1.10構建編譯
mvn clean package -DskipTests如果一起順利,你會最終看到如下信息:
......[INFO] flink-walkthrough-table-scala ...................... SUCCESS [ 0.070 s][INFO] flink-walkthrough-datastream-java .................. SUCCESS [ 0.081 s][INFO] flink-walkthrough-datastream-scala ................. SUCCESS [ 0.067 s][INFO] ------------------------------------------------------------------------[INFO] BUILD SUCCESS[INFO] ------------------------------------------------------------------------[INFO] Total time: 16:22 min[INFO] Finished at: 2019-12-31T10:37:21+08:00[INFO]?------------------------------------------------------------------------構建 PyFlink 發布包
上面我們構建了 Java 的發布包,接下來我們構建 PyFlink 的發布包,如下:
cd flink-Python; Python setup.py sdist最終輸出如下信息,證明是成功的:
copying pyflink/util/exceptions.py -> apache-flink-1.10.dev0/pyflink/utilcopying pyflink/util/utils.py -> apache-flink-1.10.dev0/pyflink/utilWriting apache-flink-1.10.dev0/setup.cfgcreating distCreating tar archiveremoving 'apache-flink-1.10.dev0' (and everything under it)在 dist 目錄的 apache-flink-1.10.dev0.tar.gz 就是我們可以用于 pip install 的 PyFlink 包。
安裝 PyFlink
上面我們構建了 PyFlink 的發布包,接下來我們利用 pip 進行安裝,檢測是否之前已經安裝過 PyFlink,如下命令:
pip3 list|grep flink...flink 1.0 pyflink-demo-connector 0.1上面信息說明我本機已經安裝過 PyFlink,我們要先刪除,如下:
pip3 uninstall flink刪除以前的安裝之后,我們再安裝新的如下:
pip3 install dist/*.tar.gz...Successfully built apache-flinkInstalling collected packages: apache-flinkSuccessfully?installed?apache-flink-1.10.dev0我們再用 list 命令檢查一遍:
pip3 list|grep flink...apache-flink 1.10.dev0pyflink-demo-connector????????0.1其中 pyflink-demo-connector 是我以前做實驗時候的安裝,對本篇沒有影響。
安裝 Apache Beam 依賴
我們需要使用 Python3.5+ 版本,檢驗一下 Python 版本,如下:
jincheng.sunjc$ Python --versionPython 3.7.6我本機是 Python 3.7.6,現在我們需要安裝 Apache Beam,如下:
python -m pip install apache-beam==2.15.0...Installing collected packages: apache-beamSuccessfully installed apache-beam-2.15.0如果順利的出現上面信息,說明 Apache-beam 已經安裝成功。
PyFlink 示例作業
接下來我們開發一個簡單的 PyFlink 作業,源碼如下:
import loggingimport osimport shutilimport sysimport tempfilefrom pyflink.table import BatchTableEnvironment, EnvironmentSettingsfrom pyflink.table.descriptors import FileSystem, OldCsv, Schemafrom pyflink.table.types import DataTypesfrom pyflink.table.udf import udfdef word_count(): environment_settings = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build() t_env = BatchTableEnvironment.create(environment_settings=environment_settings) # register Results table in table environment tmp_dir = tempfile.gettempdir() result_path = tmp_dir + '/result' if os.path.exists(result_path): try: if os.path.isfile(result_path): os.remove(result_path) else: shutil.rmtree(result_path) except OSError as e: logging.error("Error removing directory: %s - %s.", e.filename, e.strerror) logging.info("Results directory: %s", result_path) # we should set the Python verison here if `Python` not point t_env.get_config().set_python_executable("python3") t_env.connect(FileSystem().path(result_path)) \ .with_format(OldCsv() .field_delimiter(',') .field("city", DataTypes.STRING()) .field("sales_volume", DataTypes.BIGINT()) .field("sales", DataTypes.BIGINT())) \ .with_schema(Schema() .field("city", DataTypes.STRING()) .field("sales_volume", DataTypes.BIGINT()) .field("sales", DataTypes.BIGINT())) \ .register_table_sink("Results") @udf(input_types=DataTypes.STRING(), result_type=DataTypes.ARRAY(DataTypes.STRING())) def split(input_str: str): return input_str.split(",") @udf(input_types=[DataTypes.ARRAY(DataTypes.STRING()), DataTypes.INT()], result_type=DataTypes.STRING()) def get(arr, index): return arr[index] t_env.register_function("split", split) t_env.register_function("get", get) t_env.get_config().get_configuration().set_string("parallelism.default", "1") data = [("iPhone 11,30,5499,Beijing", ), ("iPhone 11 Pro,20,8699,Guangzhou", ), ("MacBook Pro,10,9999,Beijing", ), ("AirPods Pro,50,1999,Beijing", ), ("MacBook Pro,10,11499,Shanghai", ), ("iPhone 11,30,5999,Shanghai", ), ("iPhone 11 Pro,20,9999,Shenzhen", ), ("MacBook Pro,10,13899,Hangzhou", ), ("iPhone 11,10,6799,Beijing", ), ("MacBook Pro,10,18999,Beijing", ), ("iPhone 11 Pro,10,11799,Shenzhen", ), ("MacBook Pro,10,22199,Shanghai", ), ("AirPods Pro,40,1999,Shanghai", )] t_env.from_elements(data, ["line"]) \ .select("split(line) as str_array") \ .select("get(str_array, 3) as city, " "get(str_array, 1).cast(LONG) as count, " "get(str_array, 2).cast(LONG) as unit_price") \ .select("city, count, count * unit_price as total_price") \ .group_by("city") \ .select("city, " "sum(count) as sales_volume, " "sum(total_price) as sales") \ .insert_into("Results") t_env.execute("word_count")if __name__ == '__main__': logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count()接下來我們就介紹如何用不同部署模式運行 PyFlink 作業!
Local-SingleJVM 模式部署
該模式多用于開發測試階段,簡單的利用 Python pyflink_job.py 命令,PyFlink 就會默認啟動一個 Local-SingleJVM 的 Flink 環境來執行作業,如下:
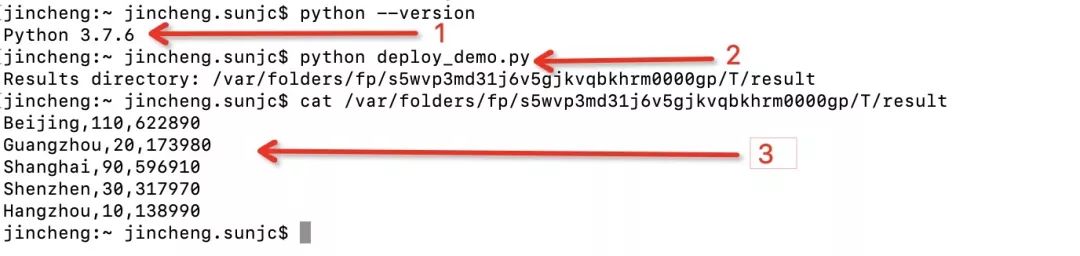
首先確認你 Python 是 3.5+,然后執行上面的 PyFlink 作業 Python deploy_demo.py,結果寫入到本地文件,然后 cat 計算結果,如果出現如圖所示的結果,則說明準備工作已經就緒。
這里運行時 SingleJVM,在運行這個 job 時候大家可以查看 java 進程:
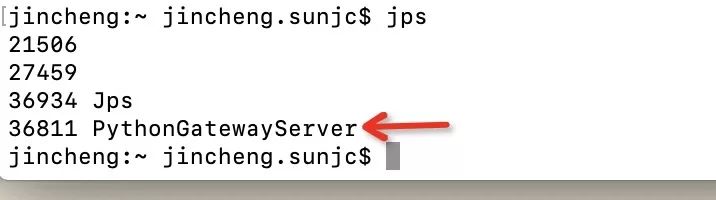
我們發現只有一個 JVM 進程,里面包含了所有 Flink 所需角色。
Local-SingleNode 模式部署
這種模式一般用在單機環境中進行部署,如 IoT 設備中,我們從 0 開始進行該模式的部署操作。我們進入到 flink/build-target 目錄,執行如下命令(個人愛好,我把端口改成了 8888):
jincheng:build-target jincheng.sunjc$ bin/start-cluster.sh ...Starting cluster.Starting standalonesession daemon on host jincheng.local.查看一下 Flink 的進程:
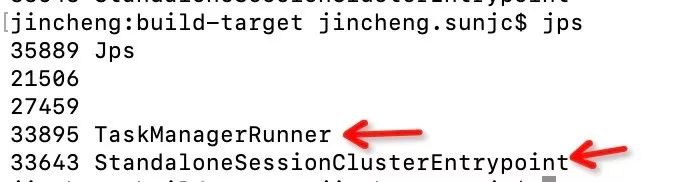
我們發現有 TM 和 JM 兩個進程,雖然在一臺機器(Local)但是也是一個集群的架構。
上面信息證明已經啟動完成,我們可以查看 web 界面:http://localhost:8888/(我個人愛好端口是 8888,默認是 8080), 如下:
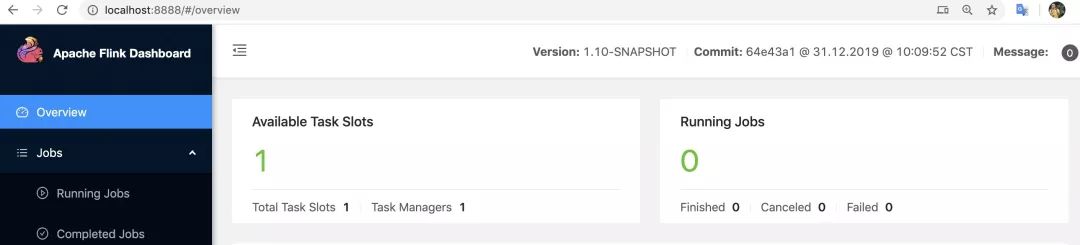
目前集群環境已經準備完成,我們看如果將作業部署到集群中,一條簡單的命令,如下:
bin/flink run -m localhost:8888 -py ~/deploy_demo.py這里如果你不更改端口可以不添加 -m 選項。如果一切順利,你會得到如下輸出:
jincheng:build-target jincheng.sunjc$ bin/flink run -m localhost:8888 -py ~/deploy_demo.py Results directory: /var/folders/fp/s5wvp3md31j6v5gjkvqbkhrm0000gp/T/resultJob has been submitted with JobID 3ae7fb8fa0d1867daa8d65fd87ed3bc6Program execution finishedJob with JobID 3ae7fb8fa0d1867daa8d65fd87ed3bc6 has finished.Job Runtime: 5389 ms其中 /var/folders/fp/s5wvp3md31j6v5gjkvqbkhrm0000gp/T/result 目錄是計算結果目錄,我們可以產看一下,如下:
jincheng:build-target jincheng.sunjc$ cat /var/folders/fp/s5wvp3md31j6v5gjkvqbkhrm0000gp/T/resultBeijing,110,622890Guangzhou,20,173980Shanghai,90,596910Shenzhen,30,317970Hangzhou,10,138990同時我們也可以在 WebUI 上面進行查看,在完成的 job 列表中,顯示如下:
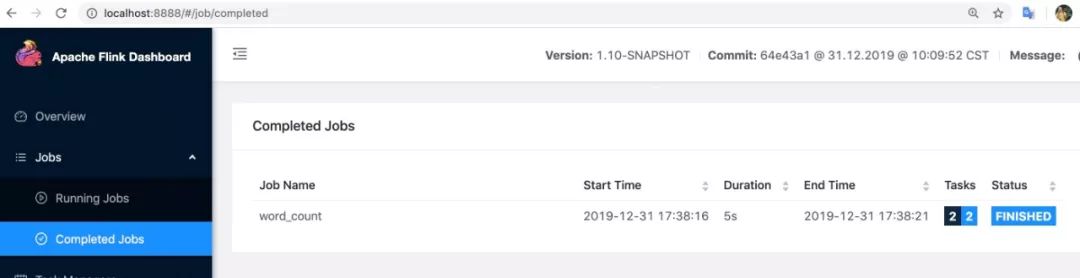
到此,我們完成了在 Local 模式,其實也是只有一個節點的 Standalone 模式下完成 PyFlink 的部署。
最后我們為了繼續下面的操作,請停止集群:
jincheng:build-target jincheng.sunjc$ bin/stop-cluster.shStopping taskexecutor daemon (pid: 45714) on host jincheng.local.Stopping?standalonesession?daemon?(pid:?45459)?on?host?jincheng.local.Cluster YARN 模式部署
這個模式部署,我們需要一個 YARN 環境,我們一切從簡,以單機部署的方式準備 YARN 環境,然后再與 Flink 進行集成。
準備 YARN 環境安裝 Hadoop
我本機是 mac 系統,所以我偷懶一下直接用 brew 進行安裝:
jincheng:bin jincheng.sunjc$ brew install HadoopUpdating Homebrew...==> Auto-updated Homebrew!Updated 2 taps (homebrew/core and homebrew/cask).==> Updated FormulaePython ? doxygen minio ntopng typescriptcertbot libngspice mitmproxy ooniprobedoitlive minimal-racket ngspice openimageio==> Downloading https://www.apache.org/dyn/closer.cgi?path=hadoop/common/hadoop-==> Downloading from http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/######################################################################## 100.0%???/usr/local/Cellar/Hadoop/3.2.1:?22,397?files,?815.6MB,?built?in?5?minutes?12?seconds完成之后,檢驗一下 Hadoop 版本:
jincheng:bin jincheng.sunjc$ hadoop versionHadoop 3.2.1超級順利,Hadoop 被安裝到了 /usr/local/Cellar/hadoop/3.2.1/ 目錄下,brew 還是很能提高生產力啊~
配置免登(SSH)
Mac 系統自帶了 ssh,我們可以簡單配置一下即可,我們先打開遠程登錄。?系統偏好設置?->?共享?中,左邊勾選遠程登錄,右邊選擇僅這些用戶(選擇所有用戶更寬松),并添加當前用戶。
jincheng:bin jincheng.sunjc$ whoamijincheng.sunjc我當前用戶是 jincheng.sunjc。配置圖如下:
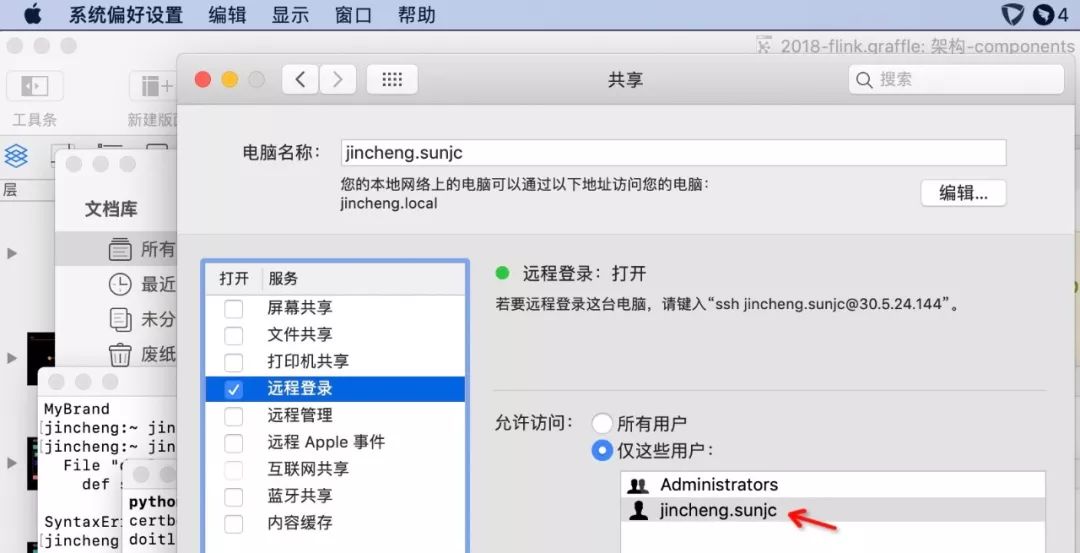
然后生產證書,如下操作:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsaGenerating public/private rsa key pair./Users/jincheng.sunjc/.ssh/id_rsa already exists.Overwrite (y/n)? yYour identification has been saved in /Users/jincheng.sunjc/.ssh/id_rsa.Your public key has been saved in /Users/jincheng.sunjc/.ssh/id_rsa.pub.The key fingerprint is:SHA256:IkjKkOjfMx1fxWlwtQYg8hThph7Xlm9kPutAYFmQR0A jincheng.sunjc@jincheng.localThe key's randomart image is:+---[RSA 2048]----+| ..EB=.o.. ||.. =.+.+ o .||+ . B. = o ||+o . + o + . ||.o. . .+S. * o || . ..o.= + = || . + o . . = || o o o || .o |+----[SHA256]-----+接下來將公鑰追加到如下文件,并修改文件權限:
jincheng.sunjc$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysjincheng.sunjc$ chmod 0600 ~/.ssh/authorized_keys利用 ssh localhost 驗證,看到 Last login: 字樣為 ssh 成功:
jincheng:~ jincheng.sunjc$ ssh localhostPassword:Last?login:?Tue?Dec?31?18:26:48?2019?from?::1設置環境變量
設置 JAVA_HOME,HADOOP_HOME 和 HADOOP_CONF_DIR,vi ~/.bashrc:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Homeexport HADOOP_HOME=/usr/local/Cellar/hadoop/3.2.1/libexecexport HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoopNOTE: 后續操作要確保的 terminal 環境變量是生效哦, 如果不生效可以執行 source ~/.bashrc。:)
修改配置
1) 修改 core-site.xml
<configuration> <property> <name>hadoop.tmp.dirname> <value>/tmpvalue> property> <property> <name>fs.defaultFSname> <value>hdfs://localhost:9000value> property>configuration>2) 修改 hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dirname> <value>/tmp/hadoop/namevalue> property> <property> <name>dfs.datanode.data.dirname> <value>/tmp/hadoop/datavalue> property> configuration>3) 修改 yarn-site.xml
配置 YARN 作為資源管理框架:
<configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.nodemanager.env-whitelistname> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue> property>configuration>簡單的配置已經完成,我們執行一下簡單命令啟動環境:
格式化文檔系統
jincheng:libexec jincheng.sunjc$ hadoop namenode -format......2019-12-31 18:58:53,260 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************SHUTDOWN_MSG: Shutting down NameNode at jincheng.local/127.0.0.1************************************************************/啟動服務
我們先啟動 hdf 再啟動 yarn,如下圖:

Okay,一切順利的話,我們會啟動 namenodes,datanodes,resourcemanager 和 nodemanagers。我們有幾個 web 界面可以查看,如下:
1)Overview 界面, http://localhost:9870?如下:
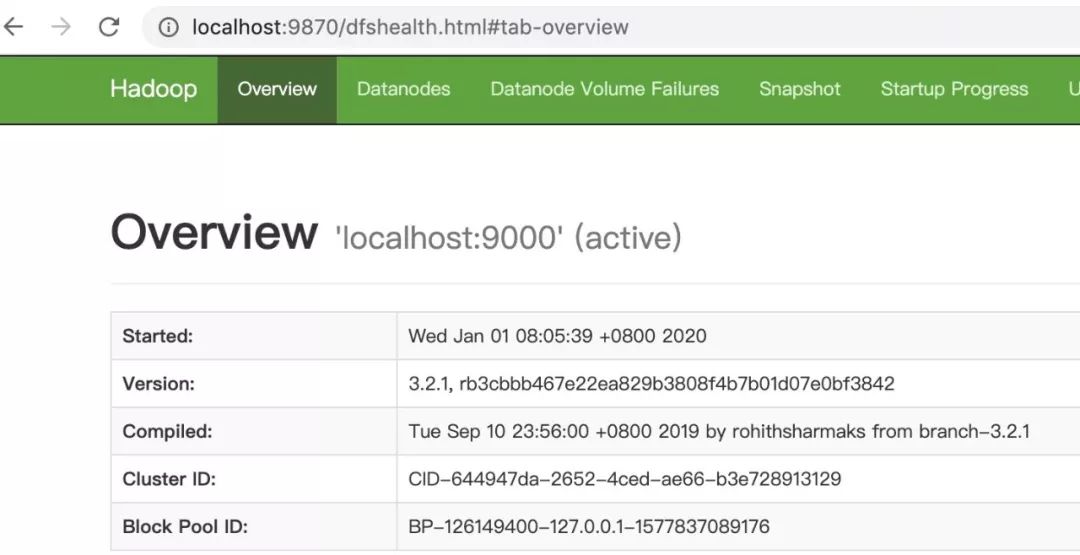
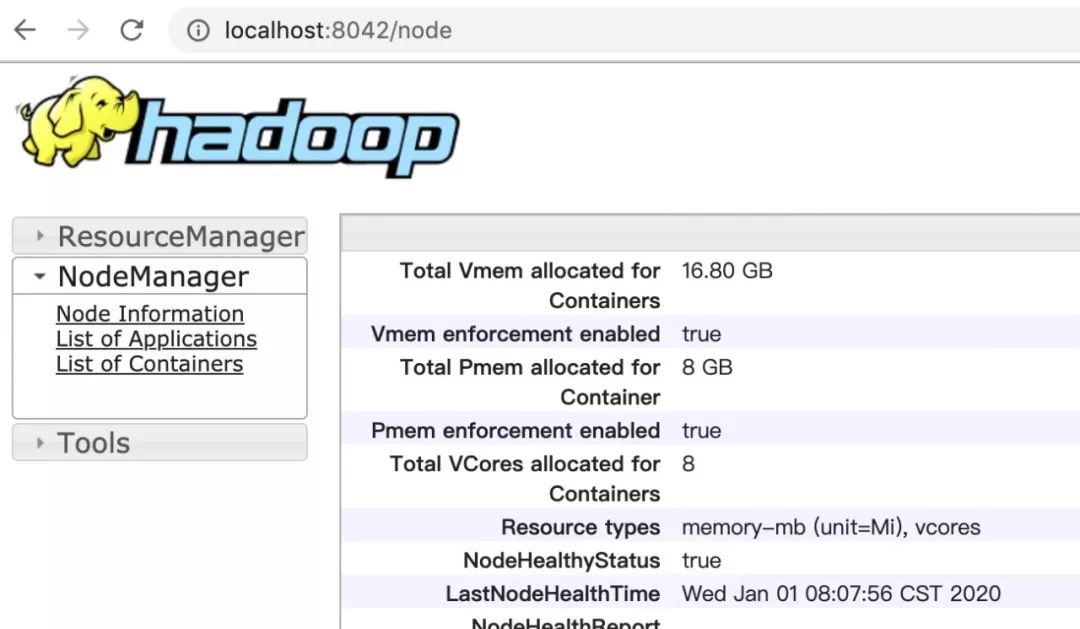
2)NodeManager 界面, http://localhost:8042,如下:
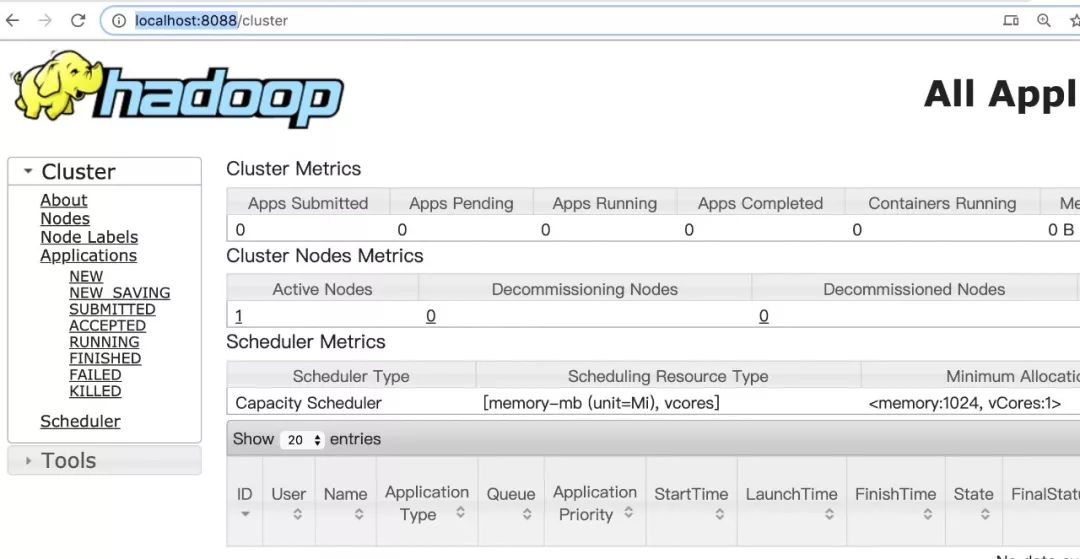
3)ResourceManager 管理界面 http://localhost:8088/,如下:
目前 YARN 的環境已經準備完成,我們接下來看如何與 Flink 進行集成。
Flink 集成 Hadoop 包切換到編譯結果目錄下 flink/build-target,并將 Haddop 的 JAR 包放到 lib 目錄。
在官網下載 Hadoop 包:
cd lib;curl https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-7.0/flink-shaded-hadoop-2-uber-2.8.3-7.0.jar > flink-shaded-hadoop-2-uber-2.8.3-7.0.jar下載后,lib 目錄下文件如下:
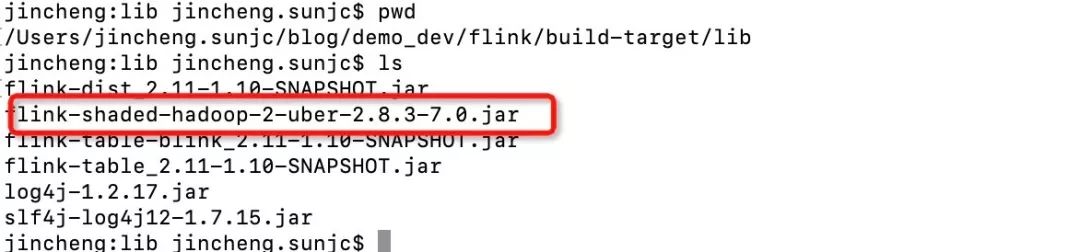
到現在為止我們可以提交 PyFlink 的作業到由 YARN 進行資源分配的集群了。但為了確保集群上有正確的 Python 環境我們最好打包一個 Python 環境到集群上面。因為大部分情況下我們無法得知 YARN 集群上的 Python 版本是否符合我們的要求(Python 3.5+,裝有 apache-beam 2.15.0),因此我們需要打包一個符合條件的 Python 環境,并隨 job 文件提交到 YARN 集群上。
打包 Python 環境再次檢查一下當前 Python 的版本是否 3.5+,如下:
jincheng:lib jincheng.sunjc$ PythonPython?3.7.6?(default,?Dec?31?2019,?09:48:30)由于這個 Python 環境是用于集群的,所以打包時的系統需要和集群一致。如果不一致,比如集群是 linux 而本機是 mac,我們需要在虛擬機或者 docker 中打包。以下列出兩種情況的示范方法,讀者根據需求選擇一種即可。
1)本地打包(集群和本機操作系統一致時)如果集群所在機器的操作系統和本地一致(都是 mac 或者都是 linux),直接通過 virtualenv 打包一個符合條件的 Python 環境:
安裝 virtualenv
使用 python -m pip install virtualenv 進行安裝如下:
jincheng:tmp jincheng.sunjc$ python -m pip install virtualenvCollecting virtualenv Downloading https://files.Pythonhosted.org/packages/05/f1/2e07e8ca50e047b9cc9ad56cf4291f4e041fa73207d000a095fe478abf84/virtualenv-16.7.9-py2.py3-none-any.whl (3.4MB) |████████████████████████████████| 3.4MB 2.0MB/s Installing collected packages: virtualenvSuccessfully installed virtualenv-16.7.9我本地環境已經成功安裝。
創建 Python 環境
用 virtualenv 以 always-copy 方式建立一個全新的 Python 環境,名字隨意,以 venv 為例,virtualenv --always-copy venv:
jincheng:tmp jincheng.sunjc$ virtualenv --always-copy venvUsing base prefix '/usr/local/Cellar/Python/3.7.6/Frameworks/Python.framework/Versions/3.7'New Python executable in /Users/jincheng.sunjc/temp/hadoop/tmp/venv/bin/Python3.7Also creating executable in /Users/jincheng.sunjc/temp/hadoop/tmp/venv/bin/PythonInstalling setuptools, pip, wheel...done.在新環境中安裝 apache-beam 2.15.0
使用 venv/bin/pip install apache-beam==2.15.0 進行安裝:
jincheng:tmp jincheng.sunjc$ venv/bin/pip install apache-beam==2.15.0Collecting apache-beam==2.15.0......Successfully?installed?apache-beam-2.15.0?avro-Python3-1.9.1?certifi-2019.11.28?chardet-3.0.4?crcmod-1.7?dill-0.2.9?docopt-0.6.2?fastavro-0.21.24?future-0.18.2?grpcio-1.26.0?hdfs-2.5.8?httplib2-0.12.0?idna-2.8?mock-2.0.0?numpy-1.18.0?oauth2client-3.0.0?pbr-5.4.4?protobuf-3.11.2?pyarrow-0.14.1?pyasn1-0.4.8?pyasn1-modules-0.2.7?pydot-1.4.1?pymongo-3.10.0?pyparsing-2.4.6?pytz-2019.3?pyyaml-3.13?requests-2.22.0?rsa-4.0?six-1.13.0?urllib3-1.25.7上面信息已經說明我們成功的在 Python 環境中安裝了 apache-beam==2.15.0。接下來我們打包 Python 環境。
打包 Python 環境
我們將 Python 打包成 zip 文件,zip -r venv.zip venv 如下:
zip -r venv.zip venv...... adding: venv/lib/Python3.7/re.py (deflated 68%) adding: venv/lib/Python3.7/struct.py (deflated 46%) adding: venv/lib/Python3.7/sre_parse.py (deflated 80%) adding: venv/lib/Python3.7/abc.py (deflated 72%) adding: venv/lib/Python3.7/_bootlocale.py (deflated 63%)查看一下 zip 大小:
jincheng:tmp jincheng.sunjc$ du -sh venv.zip 81M venv.zip這個大小實在太大了,核心問題是 Beam 的包非常大,后面我會持續在 Beam 社區提出優化建議。我們先忍一下:(。
2)Docker 中打包(比如集群為 linux,本機為 mac 時)我們選擇在 docker 中打包,可以從以下鏈接下載最新版 docker 并安裝:
https://download.docker.com/mac/stable/Docker.dmg 安裝完畢后重啟終端,執行 docker version 確認 docker 安裝成功:
jincheng:tmp jincheng.sunjc$ docker versionClient: Docker Engine - Community Version: 19.03.4 API version: 1.40 Go version: go1.12.10 Git commit: 9013bf5 Built: Thu Oct 17 23:44:48 2019 OS/Arch: darwin/amd64 Experimental: falseServer: Docker Engine - Community Engine: Version: 19.03.4 API version: 1.40 (minimum version 1.12) Go version: go1.12.10 Git commit: 9013bf5 Built: Thu Oct 17 23:50:38 2019 OS/Arch: linux/amd64 Experimental: false containerd: Version: v1.2.10 GitCommit: b34a5c8af56e510852c35414db4c1f4fa6172339 runc: Version: 1.0.0-rc8+dev GitCommit: 3e425f80a8c931f88e6d94a8c831b9d5aa481657 docker-init: Version: 0.18.0 GitCommit: fec3683啟動容器
我們啟動一個 Python 3.7 版本的容器如果是第一次啟動可能需要較長時間來拉取鏡像:docker run -it Python:3.7 /bin/bash, 如下:
jincheng:libexec jincheng.sunjc$ docker run -it Python:3.7 /bin/bashUnable to find image 'Python:3.7' locally3.7: Pulling from library/Python8f0fdd3eaac0: Pull complete d918eaefd9de: Pull complete 43bf3e3107f5: Pull complete 27622921edb2: Pull complete dcfa0aa1ae2c: Pull complete bf6840af9e70: Pull complete 167665d59281: Pull complete ffc544588c7f: Pull complete 4ebe99df65fe: Pull complete Digest: sha256:40d615d7617f0f3b54614fd228d41a891949b988ae2b452c0aaac5bee924888dStatus: Downloaded newer image for Python:3.7容器中安裝 virtualenv
我們在剛才啟動的容器中安裝 virtualenv, pip install virtualenv,如下:
root@1b48d2b526ae:/# pip install virtualenvCollecting virtualenv Downloading https://files.Pythonhosted.org/packages/05/f1/2e07e8ca50e047b9cc9ad56cf4291f4e041fa73207d000a095fe478abf84/virtualenv-16.7.9-py2.py3-none-any.whl (3.4MB) |████████████████████████████████| 3.4MB 2.0MB/s Installing collected packages: virtualenvSuccessfully installed virtualenv-16.7.9root@1b48d2b526ae:/#創建 Python 環境
以 always copy 方式建立一個全新的 Python 環境,名字隨意,以 venv 為例,virtualenv --always-copy venv, 如下:
root@1b48d2b526ae:/# virtualenv --always-copy venvUsing base prefix '/usr/local'New Python executable in /venv/bin/PythonInstalling setuptools, pip, wheel...done.root@1b48d2b526ae:/#安裝 Apache Beam
在新的 Python 環境中安裝 apache-beam 2.15.0,venv/bin/pip install apache-beam==2.15.0,如下:
root@1b48d2b526ae:/# venv/bin/pip install apache-beam==2.15.0Collecting apache-beam==2.15.0......Successfully?installed?apache-beam-2.15.0?avro-Python3-1.9.1?certifi-2019.11.28?chardet-3.0.4?crcmod-1.7?dill-0.2.9?docopt-0.6.2?fastavro-0.21.24?future-0.18.2?grpcio-1.26.0?hdfs-2.5.8?httplib2-0.12.0?idna-2.8?mock-2.0.0?numpy-1.18.0?oauth2client-3.0.0?pbr-5.4.4?protobuf-3.11.2?pyarrow-0.14.1?pyasn1-0.4.8?pyasn1-modules-0.2.7?pydot-1.4.1?pymongo-3.10.0?pyparsing-2.4.6?pytz-2019.3?pyyaml-3.13?requests-2.22.0?rsa-4.0?six-1.13.0?urllib3-1.25.7查看 docker 中的 Python 環境
用 exit 命令退出容器,用 docker ps - a 找到 docker 容器的 id,用于拷貝文件,如下:
root@1b48d2b526ae:/# exitexitjincheng:libexec jincheng.sunjc$ docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES1b48d2b526ae????????Python:3.7??????????"/bin/bash"?????????7?minutes?ago???????Exited?(0)?8?seconds?ago???????????????????????elated_visvesvaraya由于剛剛結束,一般來說是列表中的第一條,可以根據容器的鏡像名 Python:3.7 來分辨。我們記下最左邊的容器 ID。如上是 1b48d2b526ae。
打包 Python 環境
從將容器中的 Python 環境拷貝出來,我們切換到 flink/build-target 目錄下,拷貝? docker cp 1b48d2b526ae:/venv ./ 并打包 zip -r venv.zip venv。
最終 flink/build-target 錄下生成 venv.zip。
終于到部署作業的環節了:), Flink on YARN 支持兩種模式,per-job 和 session。per-job 模式在提交 job 時會為每個 job 單獨起一個 Flink 集群,session 模式先在 Yarn 上起一個 Flink 集群,之后提交 job 都提交到這個 Flink 集群。
Pre-Job 模式部署作業
執行以下命令,以 Pre-Job 模式部署 PyFlink 作業:
bin/flink run -m yarn-cluster -pyarch venv.zip -pyexec venv.zip/venv/bin/Python -py deploy_demo.py,如下:
jincheng:build-target jincheng.sunjc$ bin/flink run -m yarn-cluster -pyarch venv.zip -pyexec venv.zip/venv/bin/Python -py deploy_demo.py2020-01-02 13:04:52,889 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/Users/jincheng.sunjc/blog/demo_dev/flink/flink-dist/target/flink-1.10-SNAPSHOT-bin/flink-1.10-SNAPSHOT/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.2020-01-02 13:04:52,889 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/Users/jincheng.sunjc/blog/demo_dev/flink/flink-dist/target/flink-1.10-SNAPSHOT-bin/flink-1.10-SNAPSHOT/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.Results directory: /var/folders/fp/s5wvp3md31j6v5gjkvqbkhrm0000gp/T/result2020-01-02 13:04:55,945 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at /0.0.0.0:80322020-01-02 13:04:56,049 INFO org.apache.flink.yarn.YarnClusterDescriptor - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2020-01-02 13:05:01,153 WARN org.apache.flink.yarn.YarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.2020-01-02 13:05:01,177 INFO org.apache.flink.yarn.YarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=1}2020-01-02 13:05:01,294 WARN org.apache.flink.yarn.YarnClusterDescriptor - The file system scheme is 'file'. This indicates that the specified Hadoop configuration path is wrong and the system is using the default Hadoop configuration values.The Flink YARN client needs to store its files in a distributed file system2020-01-02 13:05:02,600 INFO org.apache.flink.yarn.YarnClusterDescriptor - Submitting application master application_1577936885434_00042020-01-02 13:05:02,971 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1577936885434_00042020-01-02 13:05:02,972 INFO org.apache.flink.yarn.YarnClusterDescriptor - Waiting for the cluster to be allocated2020-01-02 13:05:02,975 INFO org.apache.flink.yarn.YarnClusterDescriptor - Deploying cluster, current state ACCEPTED2020-01-02 13:05:23,138 INFO org.apache.flink.yarn.YarnClusterDescriptor - YARN application has been deployed successfully.2020-01-02 13:05:23,140 INFO org.apache.flink.yarn.YarnClusterDescriptor - Found Web Interface localhost:61616 of application 'application_1577936885434_0004'.Job has been submitted with JobID a41d82194a500809fd715da8f29894a0Program execution finishedJob with JobID a41d82194a500809fd715da8f29894a0 has finished.Job Runtime: 35576 ms上面信息已經顯示運行完成,在 Web 界面可以看到作業狀態:
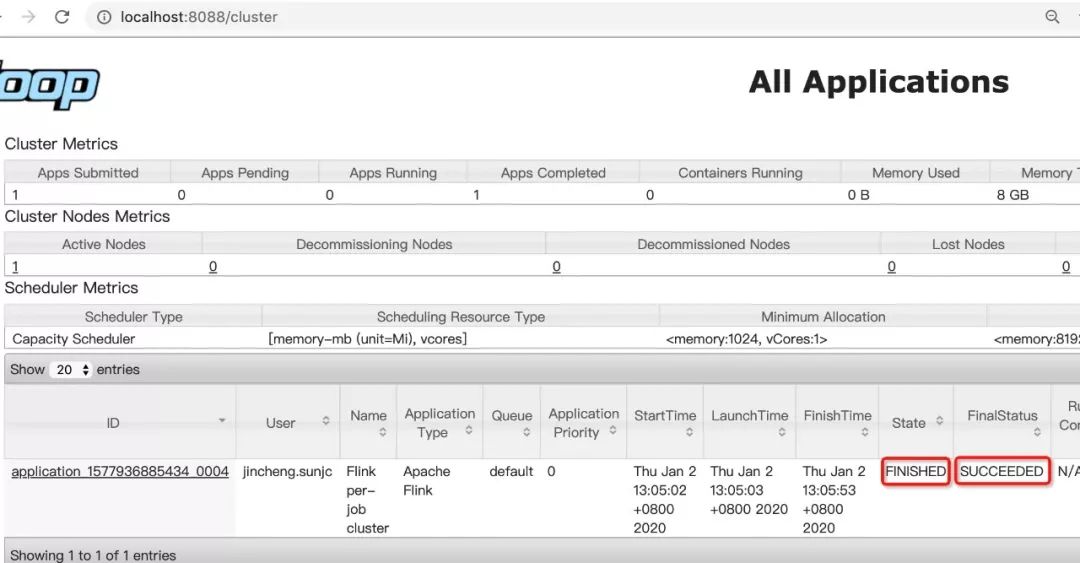
我們再檢驗一下計算結果:
cat/var/folders/fp/s5wvp3md31j6v5gjkvqbkhrm0000gp/T/result:

到這里,我們以 Pre-Job 的方式成功部署了 PyFlink 的作業!相比提交到本地 Standalone 集群,多了三個參數,我們簡單說明如下:
| 參數 | 說明 |
-m yarn-cluster | 以 Per-Job 模式部署到 yarn 集群 |
-pyarch venv.zip | 將當前目錄下的 venv.zip 上傳到 yarn 集群 |
-pyexec venv.zip/venv/bin/Python | 指定 venv.zip 中的 Python 解釋器來執行 Python UDF,路徑需要和 zip 包內部結構一致。 |
Session 模式部署作業
以 Session 模式部署作業也非常簡單,我們實際操作一下:
jincheng:build-target jincheng.sunjc$ bin/yarn-session.sh 2020-01-02 13:58:53,049 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, localhost2020-01-02 13:58:53,050 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 61232020-01-02 13:58:53,050 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m2020-01-02 13:58:53,050 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.memory.process.size, 1024m2020-01-02 13:58:53,050 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 12020-01-02 13:58:53,050 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 12020-01-02 13:58:53,051 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.execution.failover-strategy, region2020-01-02 13:58:53,413 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2020-01-02 13:58:53,476 INFO org.apache.flink.runtime.security.modules.HadoopModule - Hadoop user set to jincheng.sunjc (auth:SIMPLE)2020-01-02 13:58:53,509 INFO org.apache.flink.runtime.security.modules.JaasModule - Jaas file will be created as /var/folders/fp/s5wvp3md31j6v5gjkvqbkhrm0000gp/T/jaas-3848984206030141476.conf.2020-01-02 13:58:53,521 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/Users/jincheng.sunjc/blog/demo_dev/flink/flink-dist/target/flink-1.10-SNAPSHOT-bin/flink-1.10-SNAPSHOT/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.2020-01-02 13:58:53,562 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at /0.0.0.0:80322020-01-02 13:58:58,803 WARN org.apache.flink.yarn.YarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.2020-01-02 13:58:58,824 INFO org.apache.flink.yarn.YarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=1}2020-01-02 13:59:03,975 WARN org.apache.flink.yarn.YarnClusterDescriptor - The file system scheme is 'file'. This indicates that the specified Hadoop configuration path is wrong and the system is using the default Hadoop configuration values.The Flink YARN client needs to store its files in a distributed file system2020-01-02 13:59:04,779 INFO org.apache.flink.yarn.YarnClusterDescriptor - Submitting application master application_1577936885434_00052020-01-02 13:59:04,799 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1577936885434_00052020-01-02 13:59:04,799 INFO org.apache.flink.yarn.YarnClusterDescriptor - Waiting for the cluster to be allocated2020-01-02 13:59:04,801 INFO org.apache.flink.yarn.YarnClusterDescriptor - Deploying cluster, current state ACCEPTED2020-01-02 13:59:24,711 INFO org.apache.flink.yarn.YarnClusterDescriptor - YARN application has been deployed successfully.2020-01-02 13:59:24,713 INFO org.apache.flink.yarn.YarnClusterDescriptor - Found Web Interface localhost:62247 of application 'application_1577936885434_0005'.JobManager Web Interface: http://localhost:62247執行成功后不會返回,但會啟動一個 JoBManager Web,地址如上http://localhost:62247,可復制到瀏覽器查看:
我們可以修改 conf/flink-conf.yaml 中的配置參數。如果要更改某些內容,請參考官方文檔。接下來我們提交作業,首先按組合鍵 Ctrl+Z 將 yarn-session.sh 進程切換到后臺,并執行 bg 指令讓其在后臺繼續執行, 然后執行以下命令,即可向 Session 模式的 Flink 集群提交 job bin/flink run -m yarn-cluster -pyarch venv.zip -pyexec venv.zip/venv/bin/Python -py deploy_demo.py:
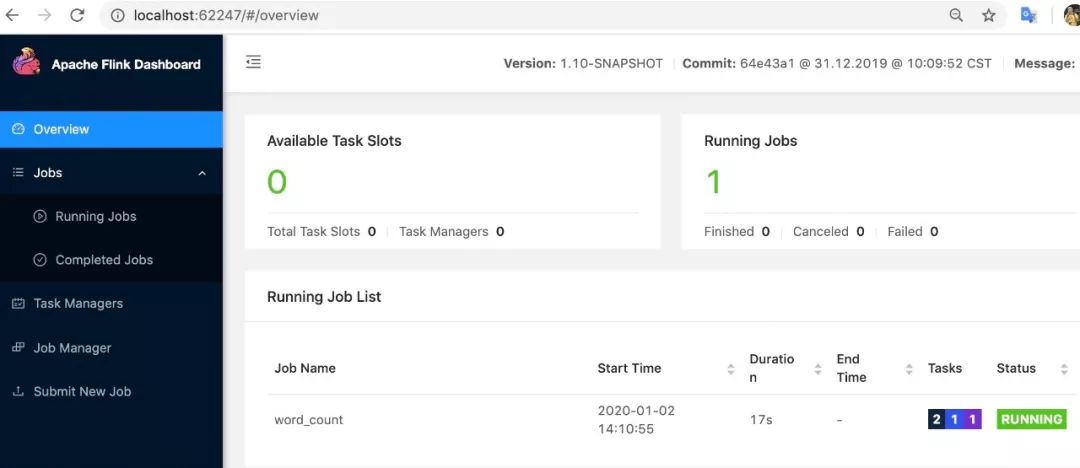
jincheng:build-target jincheng.sunjc$ bin/flink run -pyarch venv.zip -pyexec venv.zip/venv/bin/Python -py deploy_demo.py2020-01-02 14:10:48,285 INFO org.apache.flink.yarn.YarnClusterDescriptor - Found Web Interface localhost:62247 of application 'application_1577936885434_0005'.Job has been submitted with JobID bea33b7aa07c0f62153ab5f6e134b6bfProgram execution finishedJob with JobID bea33b7aa07c0f62153ab5f6e134b6bf has finished.Job Runtime: 34405 ms如果在打印 finished 之前查看之前的 web 頁面,我們會發現 Session 集群會有一個正確運行的作業,如下:
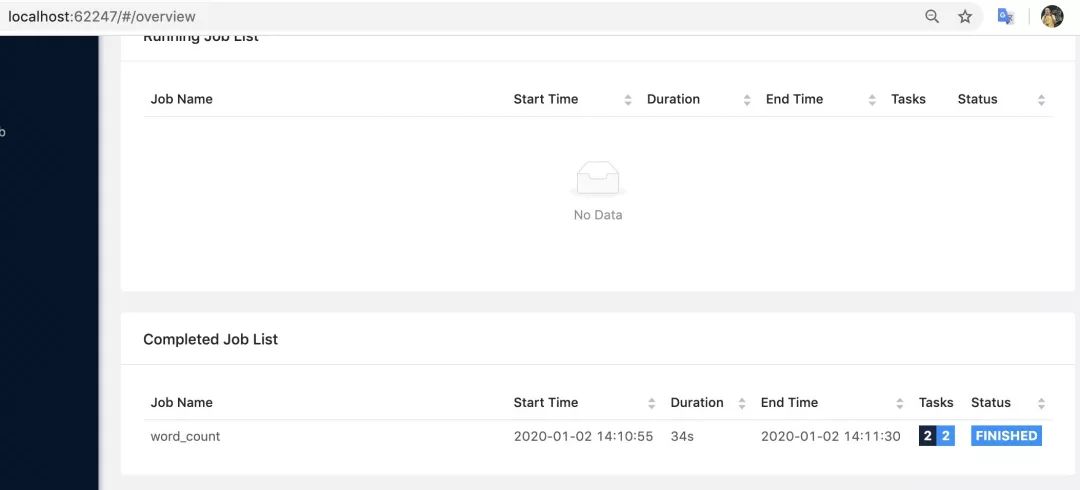
如果已經運行完成,那么我們應該會看到狀態也變成結束:
相比 per job 模式提交,少了”-m”參數。因為之前已經啟動了 yarn-session.sh,所以 Flink 默認會向 yarn-session.sh 啟動的集群上提交 job。執行完畢后,別忘了關閉 yarn-session.sh(session 模式):先將 yarn-session.sh 調到前臺,執行 fg,然后在再按 Ctrl+C 結束進程或者執行 stop,結束時 YARN 上的集群也會被關閉。
Docker 模式部署
我們還可以將 Flink Python job 打包成 docker 鏡像,然后使用 docker-compose 或者 Kubernetes 部署執行,由于現在的 docker 鏡像打包工具并沒有完美支持運行 Python UDF,因此我們需要往里面添加一些額外的文件。首先是一個僅包含PythonDriver 類的 jar 包. 我們在 build-target 目錄下執行如下命令:
jincheng:build-target jincheng.sunjc$ mkdir tempjincheng:build-target jincheng.sunjc$ cd tempjincheng:temp jincheng.sunjc$ unzip ../opt/flink-Python_2.11-1.10-SNAPSHOT.jar org/apache/flink/client/Python/PythonDriver.classArchive: ../opt/flink-Python_2.11-1.10-SNAPSHOT.jar inflating: org/apache/flink/client/Python/PythonDriver.class解壓之后,我們再進行壓縮打包:
jincheng:temp jincheng.sunjc$ zip Python-driver.jar org/apache/flink/client/Python/PythonDriver.class adding: org/apache/flink/client/Python/PythonDriver.class (deflated 56%)
我們得到 Python-driver.jar。然后下載一個 pyArrow 的安裝文件(我準備了一個大家下載直接使用即可 pyarrow-0.12.0a0-cp36-cp36m-linux_x86_64.whl。執行以下命令構建 Docker 鏡像,需要作為 artifacts 引入的文件有作業文件,Python-driver 的 jar 包和 pyarrow 安裝文件,./build.sh --job-artifacts ~/deploy_demo.py,Python-driver.jar,pyarrow-0.12.0a0-cp36-cp36m-linux_x86_64.whl --with-Python3 --from-local-dist(進入 flink/flink-container/docker 目錄)。
jincheng:docker jincheng.sunjc$ ./build.sh --job-artifacts ~/deploy_demo.py,Python-driver.jar,pyarrow-0.12.0a0-cp36-cp36m-linux_x86_64.whl --with-Python3 --from-local-distUsing flink dist: ../../flink-dist/target/flink-*-bina .a ./flink-1.10-SNAPSHOTa ./flink-1.10-SNAPSHOT/temp......Removing intermediate container a0558bbcbdd1 ---> 00ecda6117b7Successfully built 00ecda6117b7Successfully tagged flink-job:latest構建 Docker 鏡像需要較長時間,請耐心等待。構建完畢之后,可以輸入 docker images 命令在鏡像列表中找到構建結果 docker images:

然后我們在構建好的鏡像基礎上安裝好 Python udf 所需依賴,并刪除過程中產生的臨時文件:
啟動 docker 容器
docker run -it --user root --entrypoint /bin/bash --name flink-job-container flink-job安裝一些依賴
apk add --no-cache g++ Python3-dev musl-dev安裝 PyArrow
python -m pip3 install /opt/artifacts/pyarrow-0.12.0a0-cp36-cp36m-linux_x86_64.whl安裝 Apache Beam
python -m pip3 install apache-beam==2.15.0刪除臨時文件
rm -rf /root/.cache/pip
執行完如上命令我可以執行 exit 退出容器了,然后把這個容器提交為新的 flink-job 鏡像 docker commit -c 'CMD ["--help"]' -c "USER flink" -c 'ENTRYPOINT ["/docker-entrypoint.sh"]' flink-job-container flink-job:latest:
jincheng:docker jincheng.sunjc$ docker commit -c 'CMD ["--help"]' -c "USER flink" -c 'ENTRYPOINT ["/docker-entrypoint.sh"]' flink-job-container flink-job:latest sha256:0740a635e2b0342ddf776f33692df263ebf0437d6373f156821f4dd044ad648b到這里包含 Python UDF 作業的 Docker 鏡像就制作好了,這個 Docker 鏡像既可以以 docker-compose 使用,也可以結合 Kubernetes 中使用。
我們以使用 docker-compose 執行為例,mac 版 docker 自帶 docker-compose,用戶可以直接使用,在 flink/flink-container/docker 目錄下,使用以下命令啟動作業,FLINK_JOB=org.apache.flink.client.Python.PythonDriver FLINK_JOB_ARGUMENTS="-py /opt/artifacts/deploy_demo.py" docker-compose up:
jincheng:docker jincheng.sunjc$ FLINK_JOB=org.apache.flink.client.Python.PythonDriver FLINK_JOB_ARGUMENTS="-py /opt/artifacts/deploy_demo.py" docker-compose upWARNING: The SAVEPOINT_OPTIONS variable is not set. Defaulting to a blank string.Recreating docker_job-cluster_1 ... doneStarting docker_taskmanager_1 ... doneAttaching to docker_taskmanager_1, docker_job-cluster_1taskmanager_1 | Starting the task-managerjob-cluster_1 | Starting the job-cluster......job-cluster_1 | 2020-01-02 08:35:03,796 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Terminating cluster entrypoint process StandaloneJobClusterEntryPoint with exit code 0.docker_job-cluster_1 exited with code 0在 log 中出現“docker_job-cluster_1 exited with code 0”表示 job 已執行成功,JobManager 已經退出。TaskManager 還需要較長的時間等待超時后才會退出,我們可以直接按快捷鍵 Ctrl+C 提前退出。
查看執行結果,可以從 TaskManager 的容器中將結果文件拷貝出來查看,執行 docker cp docker_taskmanager_1:/tmp/result ./; cat result。

Okay, 到這里本篇要與大家分享的內容已經接近尾聲了,如果你期間也很順利的成功了,可以 Cheers 了:)
小結
本篇核心向大家分享了如何以多種方式部署 PyFlink 作業。期望在 PyFlink 1.10 發布之后,大家能有一個順利快速體驗的快感!作者博客原文在開篇說道部分,為大家分享了老子倡導大家的 “致虛極,守靜篤。萬物并作,吾以觀其復”的大道,同時也給大家帶來了 2020 的祝福,祝福大家 “2020 安!”點擊「閱讀原文」即可查看~
作者介紹:
孫金城(金竹),ASF Member,Committer & PMC Member at @Apache Flink,And Staff Engineer at @Alibaba。自 2015 年以來一直專注于大數據計算領域,并持續貢獻于Apache Flink 社區。2011 年加入阿里巴巴集團,目前就職于阿里巴巴計算平臺事業部,負責 Apache Flink Python API(PyFlink) 的整體架構開發工作。關注 Ververica,獲取更多 Flink 技術干貨
 你也「在看」嗎??
你也「在看」嗎??



![mysql not in 轉化_[轉]mysql里not in語句怎么寫 | 學步園](http://pic.xiahunao.cn/mysql not in 轉化_[轉]mysql里not in語句怎么寫 | 學步園)

)
![如何判斷輸入的是字符還是數字_[Leetgo]判斷字符串是否為數字](http://pic.xiahunao.cn/如何判斷輸入的是字符還是數字_[Leetgo]判斷字符串是否為數字)


)








