本文介紹了 PingCAP 是如何用 Generative AI 構建一個使用企業專屬知識庫的用戶助手機器人。除了使用業界常用的基于知識庫的回答方法外,還嘗試使用模型在 few shot 方法下判斷毒性。 最終,該機器人在用戶使用后,點踩的比例低于 5%,已經應用到了 TiDB 面向全球客戶的各種渠道中。
Generative Al 的魔力已經展現
從 22 年開始,Generative AI (后文稱 GenAI)在全球席卷了浪潮。 自 MidJourney (?https://www.midjourney.com/?), DALL-E (?https://openai.com/dall-e-2?) 帶來了文字生成圖片的火熱,再到 ChatGPT (?https://openai.com/chatgpt?) 以自然、流利的對話徹底引爆人們的視線,GenAI 成為再也無法繞過的話題。 AI 是否能夠在更通用的場景下支持人類更好的生活、工作,成為了 23 年的核心話題之一。
其中,LangChain (?https://www.langchain.com/?) 等開發工具的崛起,代表著工程師開始批量的創建基于 GenAI 的應用。PingCAP 也做了一些實驗,并且陸續完成了一些工作,比如:
● Ossingisht 的 Data Explorer (?https://ossinsight.io/explore/?):一個用自然語言生成 SQL 來探索 Github 開源軟件的項目
● TiDB Cloud 的 Chat2Query (?https://docs.pingcap.com/tidbcloud/explore-data-with-chat2query?):一個利用 Cloud 內數據庫通過自然語言生成 SQL 的項目在構建了這些應用后,筆者開始思考是否可以用 GenAI 的能力構建更通用的應用,帶給用戶更大的價值。
需求思考
在全球 TiDB 和 TiDB Cloud 逐步成長下,面向全球用戶的支持成為越來越重要的事情。 而隨著用戶量的幾何增長,面向用戶的支持人員數量并不會快速增長,因此,如何承接海量用戶就成為急需考慮的事情。
根據實際支持用戶的體驗,對用戶在全球社區的提問以及內部工單系統的調研,用戶有 50% 以上的問題其實是可以在官方文檔中找到答案,只是因為文檔內容太多,難以找到。因此,如果可以提供一個具有 TiDB 所有官方文檔的知識的機器人,也許可以幫助用戶更好的使用 TiDB。
Generative Al 與需求實現的差距
發掘出需求后,也需要了解 GenAI 的特性和限制,以確認是否 Gen AI 能夠用在此需求中。 根據已經完成的工作,筆者可以總結出一些 Gen AI 的特性。 在這里,Gen AI 主要指 GPT (Generative Pre-trained Transformer )類模型,以文本對話為主,本文后續都以 GPT 來描述。
1?GPT?的能力
●?理解語義的能力?。GPT 具有極強的語義理解能力,基本上可以無障礙理解任何文本。無論是何種語言(人類語言或計算機語言),何種表達水平的文本,就算是多語言混雜,或者是語法、用詞錯誤,都可以理解用戶的提問。
●?邏輯推理的能力?。GPT 具體一定的邏輯推理能力,在不額外增加任何特殊提示詞情況下,GPT 可以做出簡單的推理,并且挖掘出問題深層的內容。在補充了一定的提示詞下,GPT 可以做出更強的推理能力,這些提示詞的方法包括:Few-shot,Chain-of-Thought(COT),Self-Consistency,Tree of thought(TOT) 等等。
●?嘗試回答所有問題的能力?。GPT,特別是 Chat 類型的 GPT,如 GPT 3.5,GPT 4,一定會嘗試用對話形式,在滿足設定價值觀的情況下,回答用戶的所有問題,就算是回答“我不能回答這個信息”。
●?通用知識的能力?。GPT 自身擁有海量的通用知識,這些通用知識有較高的準確度,并且覆蓋范圍很大。
●?多輪對話的能力?。GPT 可以根據設定好的角色,理解不同角色之間的多次對話的含義,這意味著可以在對話中采用追問形式,而不是每一次對話都要把歷史所有的關鍵信息都重復一遍。這種行為非常符合人類的思考和對話邏輯。
2?GPT?的限制
●?被動觸發?。GPT 必須是用戶給出一段內容,才會回復內容。這意味著 GPT 本身不會主動發起交互。
●?知識過期?。這里特指 GPT 3.5 和 GPT 4,二者的訓練數據都截止于 2021 年 9 月,意味著之后的知識,GPT 是不知道的。不能期待 GPT 本身給你提供一個新的知識。
●?細分領域的幻覺?。雖然 GPT 在通用知識部分有優秀的能力,但是在一個特定的知識領域,比如筆者所在的數據庫行業,GPT 的大部分回答都存在著或多或少的錯誤,無法直接采信。
●?對話長度?。GPT 每輪對話有著字符長度的限制,因而如果提供給 GPT 超過字符長度的內容,此次對話會失敗。
3?需求實現的差距
筆者期望用 GPT 實現一個“企業專屬的用戶助手機器人”,這意味著以下需求:
● 需求一:多輪對話形式,理解用戶的提問,并且給出回答。
● 需求二:回答的內容中關于 TiDB 和 TiDB Cloud 的內容需要正確無誤。
● 需求三:不能回答和 TiDB、TiDB Cloud 無關的內容。
對這些需求進行分析:
● 需求一:基本上可以滿足,根據 GPT 的“理解語義的能力”、“邏輯推理的能力”、“嘗試回答問題的能力”、“上下文理解的能力”。
● 需求二:無法滿足。因為 GPT 的“知識過期”、“細分領域的幻覺”限制。
● 需求三:無法滿足。因為 GPT 的 “嘗試回答所有問題的能力”,任何問題都會回答,并且 GPT 本身并不會限制回答非 TiDB 的問題。
因此,在這個助手機器人構建中,主要就是在解決需求二和需求三的問題。
正確回答細分領域知識
這里要解決需求二的問題。
如何讓 GPT 根據特定領域知識回答用戶的問題并不是新鮮的領域,筆者之前的優化的 Ossinsight - Data Explorer 就使用特定領域知識,幫助自然語言生成 SQL 的可執行率(即生成的 SQL 可以成功的在 TiDB 中運行出結果)提升了 25% 以上 。
這里需要運用到的是向量數據庫的空間相似度搜索能力。一般分為三個步驟:
1?領域知識存儲到向量數據庫中
第一步是將 TiDB (?https://docs.pingcap.com/tidb/stable?) 和 TiDB Cloud (?https://docs.pingcap.com/tidbcloud?) 的官方文檔放入到向量數據庫中。
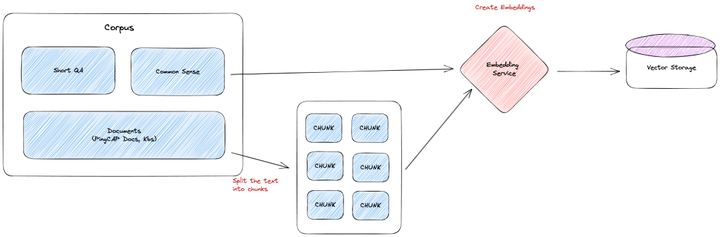
獲取到文檔后,將文字內容其放入 Embedding 模型中,產出文字內容對應的向量,并將這些向量放入到特定的向量數據庫中。
在這一步中,需要檢查兩點:
● 如果文檔的質量較差,或者文檔的格式不滿足預期,會事先對文檔進行一輪預處理,將文檔轉化為相對干凈,容易被 LLM 理解的文本格式。
● 如果文檔較長,超過 GPT 單次的對話長度,就必須對文檔進行裁剪,以滿足長度需要。裁剪方法有很多種,比如,按特定字符(如,逗號,句號,分號)裁剪,按文本長度裁剪,等等。
2?從向量數據庫中搜索相關內容
第二步是在用戶提出問題的時候,從向量數據庫中,根據用戶問題搜索相關的文本內容。
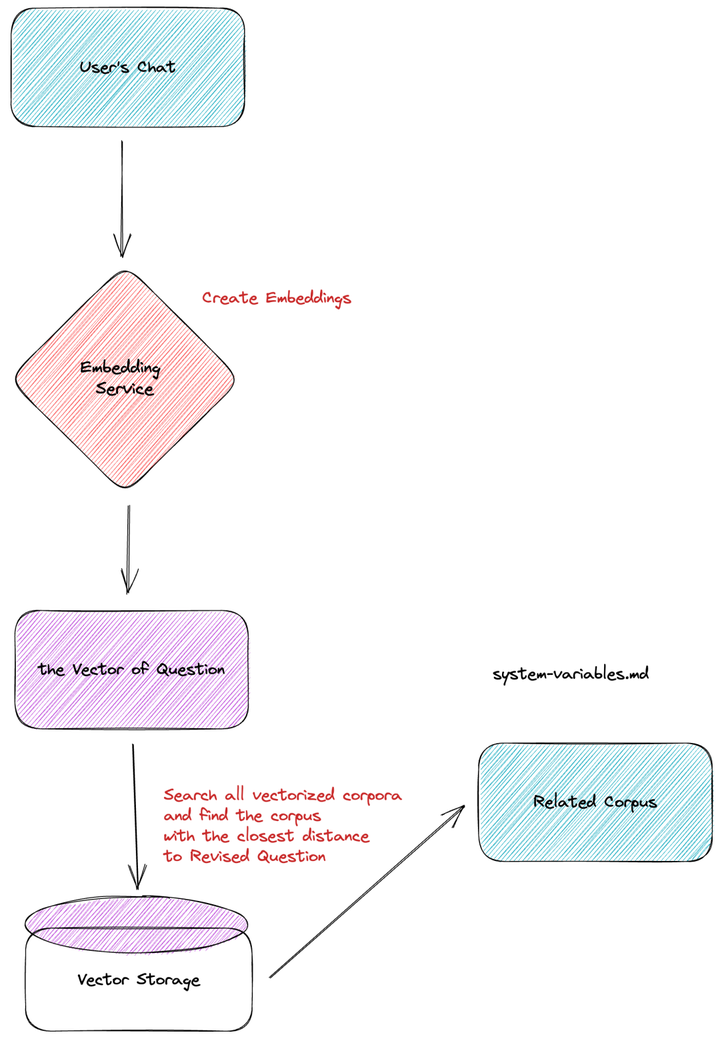
當用戶發起一次對話時,系統會將用戶的對話也通過 Embedding 模型轉化成向量,再將這個向量放到向量數據庫中和原有的預料進行查詢。查詢過程中,利用相似度算法(比如,cosine similarity,dot-product,等等),計算最相似的領域知識向量,并且提取出對應向量的文本內容。
用戶的特定問題可能需要多篇文檔才能回答,所以在搜索過程中,會取相似度最高的 Top N(目前 N 是 5)。這些 Top N 可以滿足跨越多個文檔的需要,并且都會成為下一步提供給 GPT 的內容。
3?相關內容和用戶提問一起提供給?GPT
第三步是組裝所有的相關信息,將其提供給 GPT。
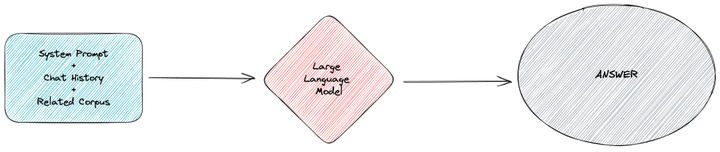
將任務目標和相關的領域知識包含在系統提示詞中,并且根據歷史對話組裝好聊天歷史。將所有內容一起提供給 GPT,就可以得到基于這部分領域知識的特定回答。
在完成以上步驟,我們就基本上可以滿足需求二,可以根據特定的領域知識回答問題,回答正確性相比直接提問 GPT 有極大提升。
限定回答領域
這里要解決需求三的問題。
該機器人是作為企業支持能力提供給用戶,因此期望機器人只回答和企業相關的內容,比如,TiDB、TiDB Cloud 本身,SQL 問題,應用構建問題,等等。如果超過這些范圍,就期望機器人拒絕回答,比如,天氣、城市、藝術,等等。
因為之前提到 GPT 的“嘗試回答所有問題的能力”,對于 GPT 本身的設定,任何問題都應該要做出符合人類價值觀的回復。所以,這一層限制無法依賴 GPT 幫我們構建,只能在應用側嘗試做限制。
只有做到了這個需求,一個業務才可能真正的上線對用戶服務。遺憾的是目前工業界沒有對此比較好的實現,大部分的應用設計中并不涉及這一部分內容。
1?概念:毒性
剛剛提到,GPT 其實會嘗試讓回答符合人類的價值觀,這步工作在模型訓練中叫做“對齊”(Align),讓 GPT 拒絕回答仇恨、暴力相關的問題。如果 GPT 未按照設定回答了仇恨、暴力相關問題,就稱之為檢測出了毒性(Toxicity)。
因此,對于筆者即將創造的機器人,其毒性的范圍實際上增加了,即,所有回答了非公司業務的內容都可以稱之為存在毒性。在此定義下,我們就可以參考前人在去毒(Detoxifying)方面的工作。DeepMind 的 Johannes Welbl (?https://aclanthology.org/2021.findings-emnlp.210.pdf?) (2021)等人介紹了可以采用語言模型來做為毒性檢測的方式,目前,GPT 的能力得到了足夠的加強,用 GPT 來直接判斷用戶的提問是否屬于公司業務范圍,成為了可能。
要做到“限定回答領域”,需要有兩個步驟。
2?限定領域的判斷
第一步,需要對用戶的原始提問進行判斷。
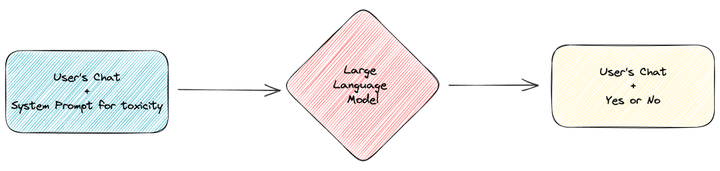
這里需要使用 few shot 的方法去構建毒性檢測的提示詞,讓 GPT 在擁有多個示例的情況下,判斷用戶的提問是否符合企業服務的范圍。
比如一些示例:
<< EXAMPLES >>
?
instruction: who is Lady Gaga?
question: is the instruction out of scope (not related with TiDB)?
answer: YES
?
instruction: how to deploy a TiDB cluster?
question: is the instruction out of scope (not related with TiDB)?
answer: NO
?
instruction: how to use TiDB Cloud?
question: is the instruction out of scope (not related with TiDB)?
answer: NO在判斷完成后,GPT 會輸入 Yes 或 No 的文字,供后續流程處理。注意,這里 Yes 意味著有毒(和業務不相關),No 意味著無毒(和業務有關)。
第二步,得到了是否有毒的結果后,我們將有毒和無毒的流程分支,進行異常流程和正常流程的處理。
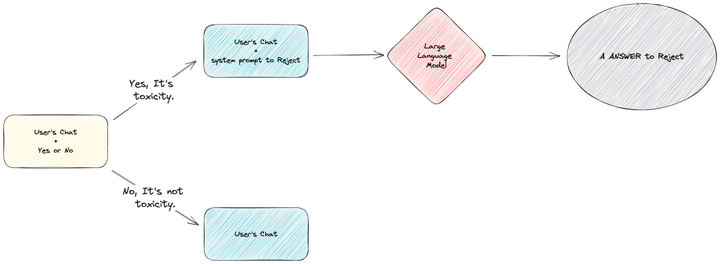
正常流程就是上文中的 正確回答細分領域知識相關內容,此處主要說明異常內容的流程。
當系統發現產出的內容是 “Yes” 時,會引導流程進入毒性內容回復流程。此時,會將一個拒絕回答用戶問題的系統提示詞和用戶對應的問題提交給 GPT,最終用戶會得到一個拒絕回答的回復。
當完成這兩步后,需求三基本完成。
整體邏輯架構
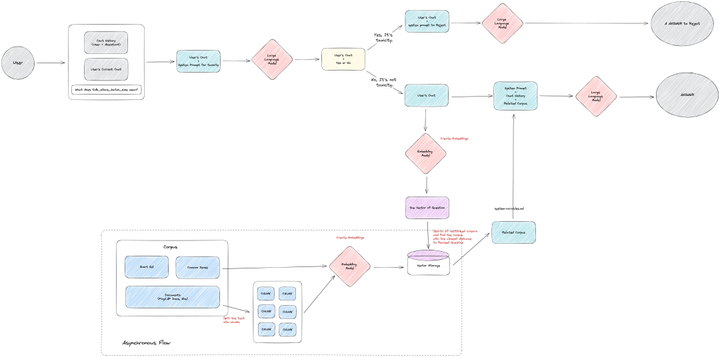
至此,我們得到了一個基本可以提供給用戶的,具有特定企業領域知識的助手機器人。這機器人我們稱之為 TiDB Bot。
TiDB Bot 上線后效果
從 3 月 30 日起,TiDB Bot 就開始進行內部測試,直到 7 月 11 日正式對 Cloud 的用戶開放。
在 TiDB Bot 孵化的 103 天來,感謝無數的社區、開發者對測試產品提出的反饋,讓 TiDB Bot 逐步變得可用。在測試階段,一共 249 名用戶使用,發送了 4570 條信息。到測試階段完成為止,共有 83 名用戶給出了 266 條反饋,其中點踩的反饋占總信息數的 3.4%,點贊的反饋占總信息數的 2.1%。
除了直接使用的社區用戶,還有提出建議和思路的用戶,給出更多解決方案的社區用戶。感謝所有的社區和開發者,沒有你們,就沒有 TiDB Bot 產品發布。
后續
隨著用戶量逐漸增加,無論是召回內容的準確性、毒性判斷的成功,都依然有不小的挑戰,因此,筆者在實際提供服務中,對 TiDB Bot 的準確度進行優化,穩步提升回答效果。 這些內容將在后續的文章中介紹。

正式成立,啟明星辰、綠盟、360 等 23 家廠商重磅加入)






)





)


真題解析#中國電子學會#全國青少年軟件編程等級考試)

