模擬實現string類不是為了造一個更好的輪子,而是更加理解string類,從而來掌握string類的使用
string類的接口設計繁多,故而不會全部涵蓋到,但是核心的會模擬實現?
庫中string類是封裝在std的命名空間中的,所以在模擬實現中我們也可以用命名空間來封裝
string類的實現可以在.h頭文件中,.cpp文件中再來實際操作string類對象
完整的代碼實現:
namespace djx
{class string{public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin()const{return _str;}const_iterator end()const{return _str + _size;}string(const char* str = ""):_size(strlen(str)),_capacity(_size){_str = new char[_capacity + 1];strcpy(_str, str);}//傳統寫法/*string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}*/void swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//現代寫法string(const string& s):_str(nullptr),_size(0),_capacity(0){string tmp(s._str);swap(tmp);}//傳統寫法/* string& operator=(const string& s){if (this != &s){char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;_size = s._size;_capacity = s._capacity;}return *this;}*///現代寫法1/*string& operator=(const string& s){if (this != &s){string tmp(s);swap(tmp);}return *this;}*///現代寫法2string& operator=(string s){swap(s);return *this;}~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}const char* c_str()const{return _str;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}const char& operator[](size_t pos)const{assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = ch;_size++;_str[_size] = '\0';}void append(const char* s){size_t len = strlen(s);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str+_size, s);_size += len;}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* s){append(s);return *this;}/*void insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}int end = _size;while (end >=(int) pos){_str[end + 1] = _str[end];end--;}_str[pos] = ch;_size++;}*/void insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}size_t end = _size+1;while (end >pos){_str[end] = _str[end-1];end--;}_str[pos] = ch;_size++;}void insert(size_t pos, const char* s){assert(pos <= _size);size_t len = strlen(s);if (_size + len > _capacity){reserve(_size + len);}int end = _size;while (end >=(int) pos){_str[end + len] = _str[end];end--;}strncpy(_str + pos, s, len);_size += len;}void erase(size_t pos, size_t len = npos){assert(pos < _size);if (len == npos || pos + len >= _size){_str[pos] = '\0';_size = pos;}else{size_t begin = pos + len;while (begin <= _size){_str[begin - len] = _str[begin];begin++;}_size -= len;}}bool operator<(const string& s)const{return strcmp(_str, s._str) < 0;}bool operator==(const string& s)const{return strcmp(_str, s._str) == 0;}bool operator<=(const string& s)const{return *this < s || *this == s;}bool operator>(const string& s)const{return !(*this <= s);}bool operator>=(const string& s)const{return !(*this < s);}bool operator!=(const string& s)const{return !(*this == s);}void resize(size_t n,char ch='\0'){if (n <= _size){_str[n] = '\0';_size = n;}else{reserve(n);while (_size < n){_str[_size] = ch;_size++;}_str[_size] = '\0';}}size_t find(char ch, size_t pos = 0){for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}return npos;//沒有找到}size_t find(const char* s, size_t pos=0){const char* p = strstr(_str+pos, s);if (p){return p - _str;}else{return npos;}}string substr(size_t pos, size_t len = npos){string s;size_t end = pos + len;if (len == npos || pos + len >= _size){len = _size - pos;end = _size;}s.reserve(len);for (size_t i = pos; i < end; i++){s += _str[i];}return s;}size_t size()const{return _size;}size_t capacity()const{return _capacity;}void clear(){_str[0] = '\0';_size = 0;}private:char* _str;size_t _size;size_t _capacity;public:const static size_t npos;//const static size_t npos=-1;//特例//const static double npos = 1.1; // 不支持};const size_t string::npos = -1;ostream& operator<<(ostream& out, const string& s){for (auto e : s){out << e;}return out;}istream& operator>>(istream& in, string& s){s.clear();char buff[129];size_t i = 0;char ch;ch = in.get();while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 128){buff[i] = '\0';s += buff;i = 0;}ch = in.get();}if (i != 0){buff[i] = '\0';s += buff;}return in;}
}
?
構造函數和析構函數:
namespace djx
{class string{public:string(const char* str = "")//構造函數:_size(strlen(str))//在對象中的成員都要走初始化列表(成員們定義的地方),_capacity(_size){_str = new char[_capacity + 1];//多開一個空間給'\0'strcpy(_str, str);}~string()//析構函數{delete[] _str;//釋放空間+調用對象的析構函數(用于清理申請的資源)_str = nullptr;_size = _capacity = 0;}const char* c_str()const//返回c格式的字符串,加const用以修飾this指針,讓const對象可以調用,非const對象也是可以調用的{return _str;}private:char* _str;//指向存儲字符串的空間size_t _size;//有效字符的個數size_t _capacity;//存儲有效字符的容量};
}測試:
string類的對象可以重載流插入,流提取運算符,但現在我們還沒有實現,又想查看string類中字符串的內容,可以用c_str 得到_str
void test1()
{djx::string s("hello");cout << s.c_str() << endl;djx::string s2;cout << s2.c_str() << endl;
}

構造函數:
1 庫中string實現:對于無參的string,初始化為空字符串,對于有參的string,則初始化為參數內容
所以可以給構造函數缺省參數,缺省值是"",注意不能是" " 因為空格也是有效字符,也沒必要是"\0",因為常量字符串自動會帶有一個'\0'
2 _size 和_capacity是不算'\0'的大小的,它只是一個標識字符,因為c語言需要'\0'作為字符串的結束標志,c++不能拋棄c,所以'\0'被保留下來了
? ?實際在開空間時也是需要為'\0'預留一個空間的
string的三種遍歷方式:
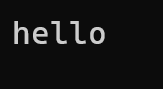
operator[]重載:
#include<assert.h>
namespace djx
{class string{public:string(const char* str = ""):_size(strlen(str)),_capacity(_size){_str = new char[_capacity + 1];strcpy(_str, str);}~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}const char* c_str()const{return _str;}char& operator[](size_t pos)//非const對象調用,返回引用,可讀可寫{assert(pos < _size);return _str[pos];}const char& operator[](size_t pos)const//const對象調用,只讀不可寫{assert(pos < _size);return _str[pos];}size_t size()const//const對象可以調用,非const對象也可以調用{return _size;}size_t capacity()const{return _capacity;}private:char* _str;size_t _size;size_t _capacity;};
}
測試:
void test2()
{djx::string s("hello");for (size_t i = 0; i < s.size(); i++){cout << s[i];}cout << endl;
}
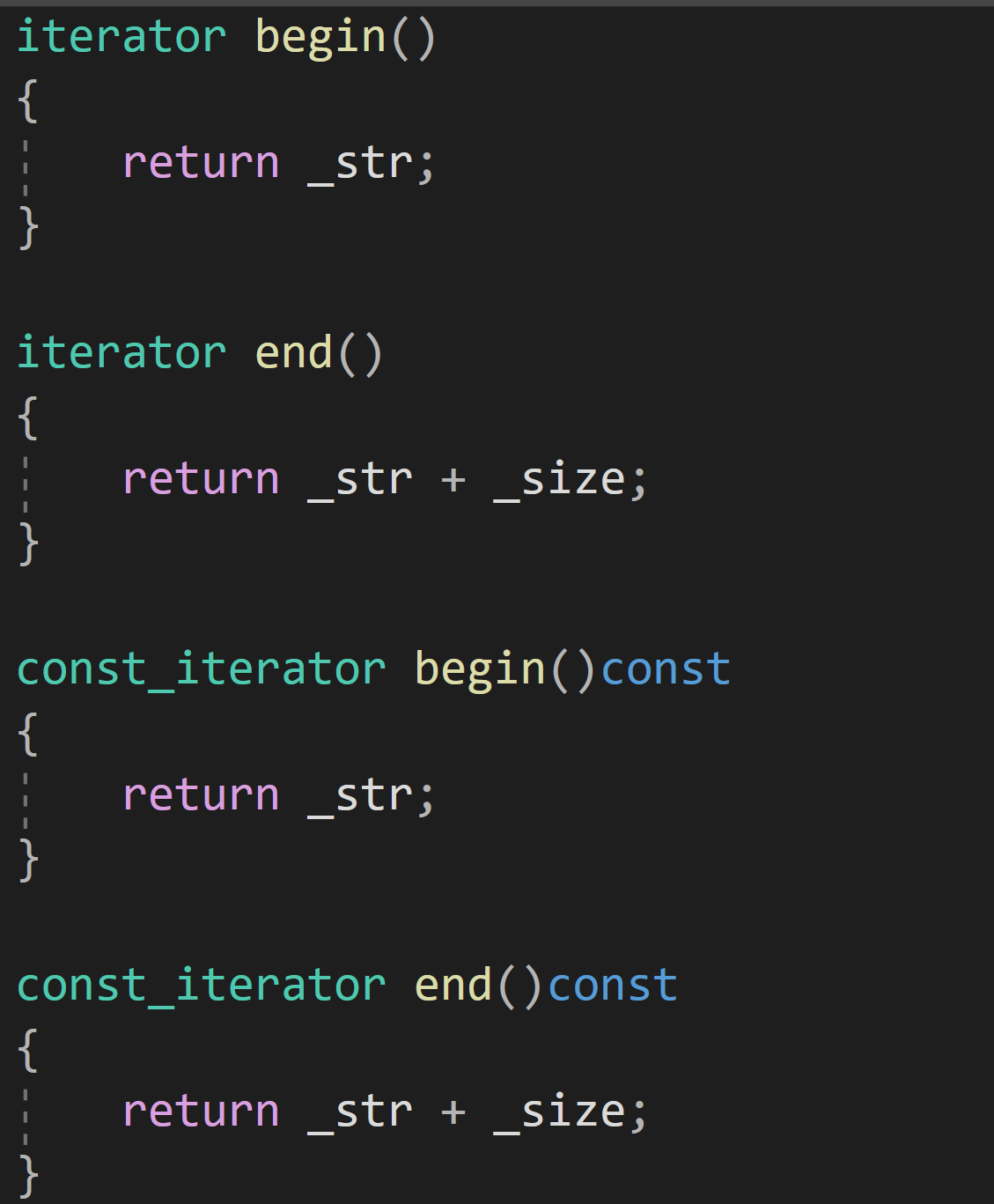
?迭代器:
string類的迭代器可以看作是指針,因為它完美契合指針的行為
namespace djx
{class string{public:typedef char* iterator;//非const對象的迭代器typedef const char* const_iterator;//const對象的迭代器iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin()const{return _str;}const_iterator end()const{return _str + _size;}string(const char* str = ""):_size(strlen(str)),_capacity(_size){_str = new char[_capacity + 1];strcpy(_str, str);}~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}const char* c_str()const{return _str;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}const char& operator[](size_t pos)const{assert(pos < _size);return _str[pos];}size_t size()const{return _size;}size_t capacity()const{return _capacity;}private:char* _str;size_t _size;size_t _capacity;};
}
測試:
void test3()
{djx::string s("hello");cout << s.c_str() <<endl;djx::string::iterator it = s.begin();while (it != s.end()){(*it)++;//寫cout << *it;//讀it++;}cout << endl;
}
?范圍for:
范圍for的底層原理是迭代器,所以有了迭代器就可以使用范圍for
測試:
void test4()
{djx::string s("hello");cout << s.c_str() << endl;for (auto &e : s)//不加引用就是只讀{e++;//寫cout << e;//讀}cout << endl;
}
插入和刪除操作:
push_back:
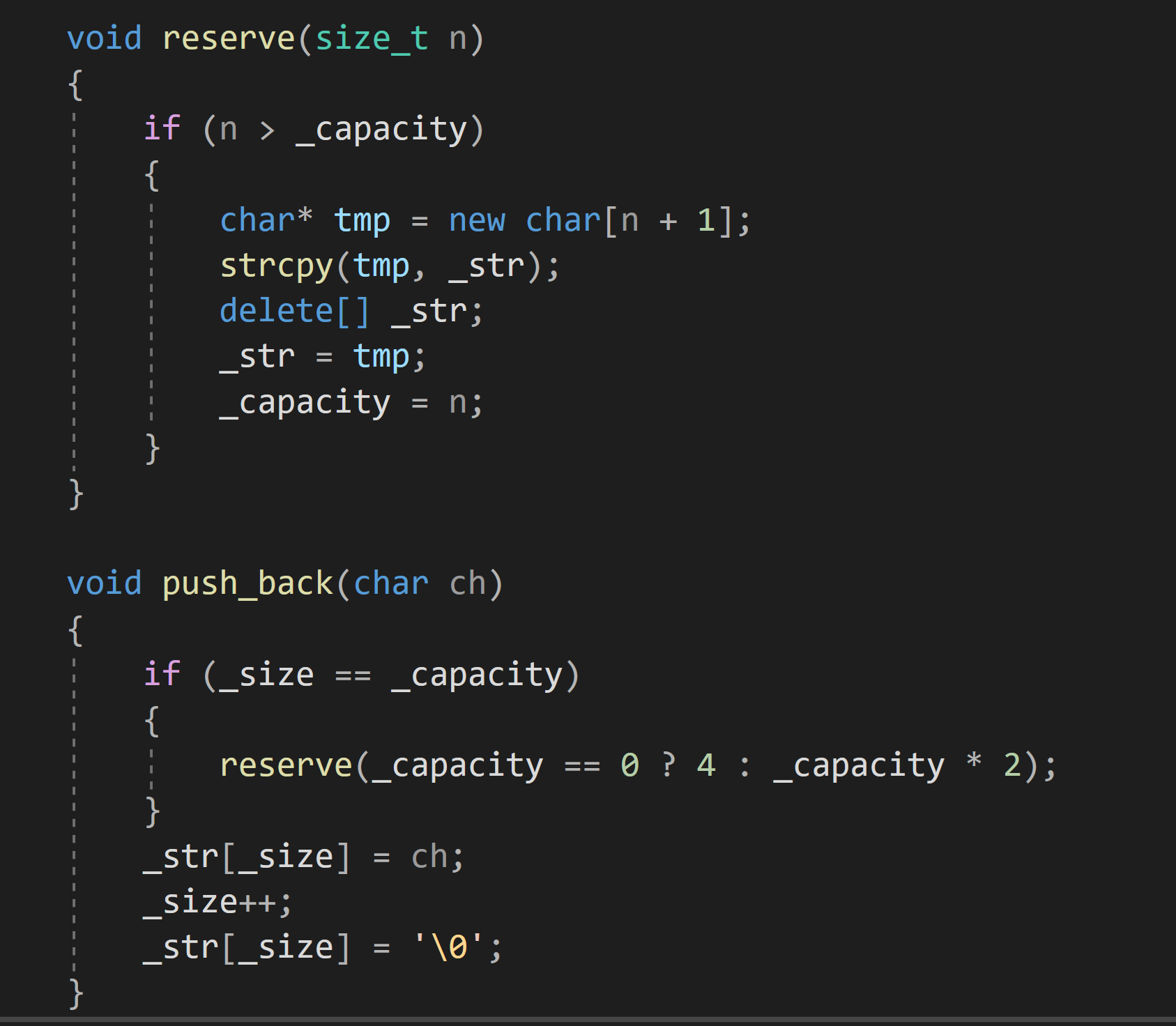
?尾插一個字符,插入之前需要檢查是否需要擴容,擴容擴至原來的2倍
注意:_size==_capacity 可能是第一次插入,雙方都是0,那么2*_capacity就是0,所以如果是第一次插入的擴容,可以擴4個空間
擴容可以使用reserve:
1 開n個空間,實際上reserve要開n+1個空間,因為要存'\0'
2 拷貝數據到新空間
3 釋放舊空間
4 指向新空間
append:

?插入之前要檢查是否需要擴容:原有效字符個數+要插入的有效字符個數>_capacity則擴容
operator+=:

目前階段的完整代碼:
#include<assert.h>
namespace djx
{class string{public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin()const{return _str;}const_iterator end()const{return _str + _size;}string(const char* str = ""):_size(strlen(str)),_capacity(_size){_str = new char[_capacity + 1];strcpy(_str, str);}~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}const char* c_str()const{return _str;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}const char& operator[](size_t pos)const{assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = ch;_size++;_str[_size] = '\0';}void append(const char* s){size_t len = strlen(s);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str+_size, s);_size += len;}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* s){append(s);return *this;}size_t size()const{return _size;}size_t capacity()const{return _capacity;}private:char* _str;size_t _size;size_t _capacity;};
}
測試:
?
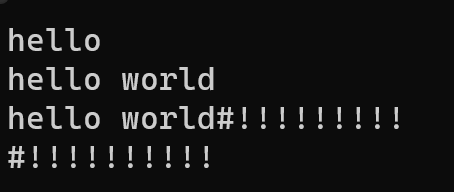
void test5()
{djx::string s("hello");cout << s.c_str() << endl;s.push_back(' ');s.append("world");cout << s.c_str() << endl;s += '#';s += "!!!!!!!!!";cout << s.c_str() << endl;djx::string s2;s2 += '#';s2 += "!!!!!!!!!!";cout << s2.c_str() << endl;
}
insert:
?插入一個字符,版本1: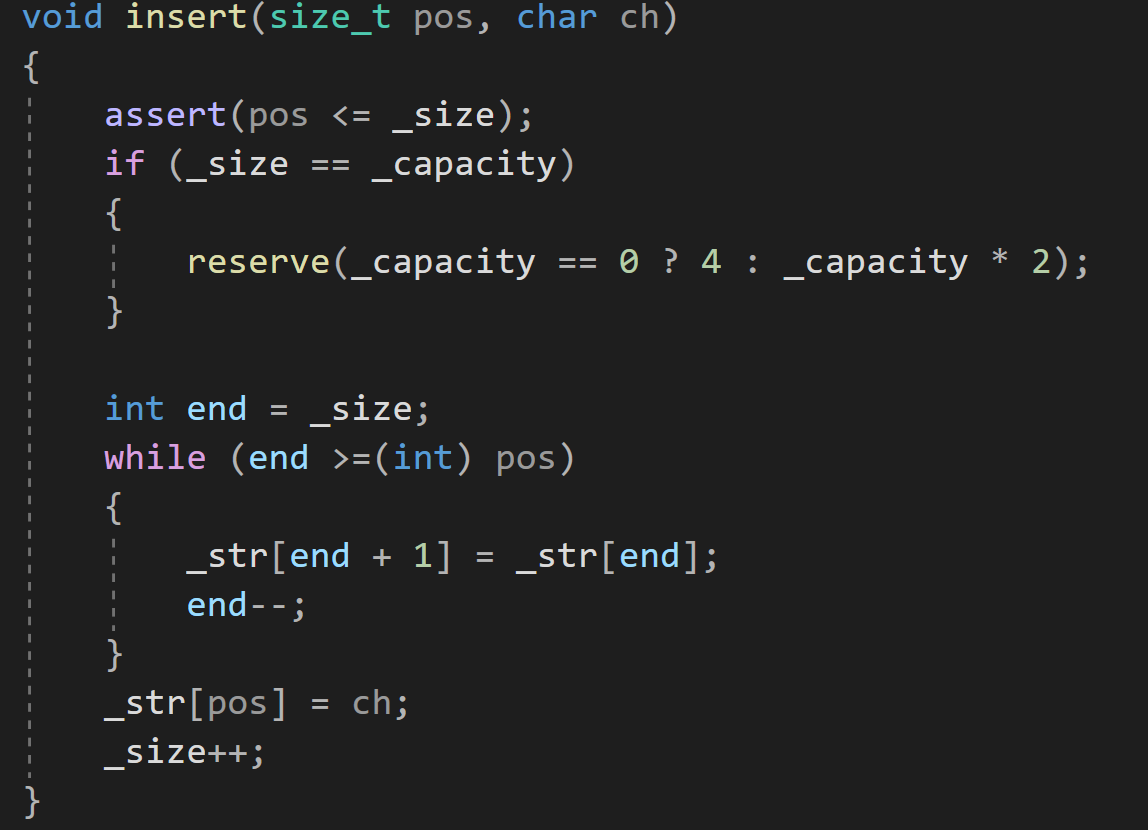
在pos位置插入一個字符,就需要從'\0'開始直到pos位置,將這些位置上的數據全部向后挪動一位
不要忘記把'\0'一并移走?
注意:如果是頭插,pos==0,且end是size_t類型,那么循環的結束條件是end<pos
即end<0,但由于end是size_t類型是不會<0的,讓end寫成int類型,那么end可以達到-1,為避開隱式類型轉換,將end由int提升為size_t,所以pos也要強制為int類型,這樣當pos為0時,end可以達到-1,-1<0結束循環?
?版本2:

?版本1利用強轉來解決循環條件的結束問題,版本2不強轉:
將end作為最后一個要挪動的數據的最終位置,end==pos+1的位置時,pos位置上的值已經挪到pos+1上了,當end==pos位置時,結束循環
插入常量字符串:
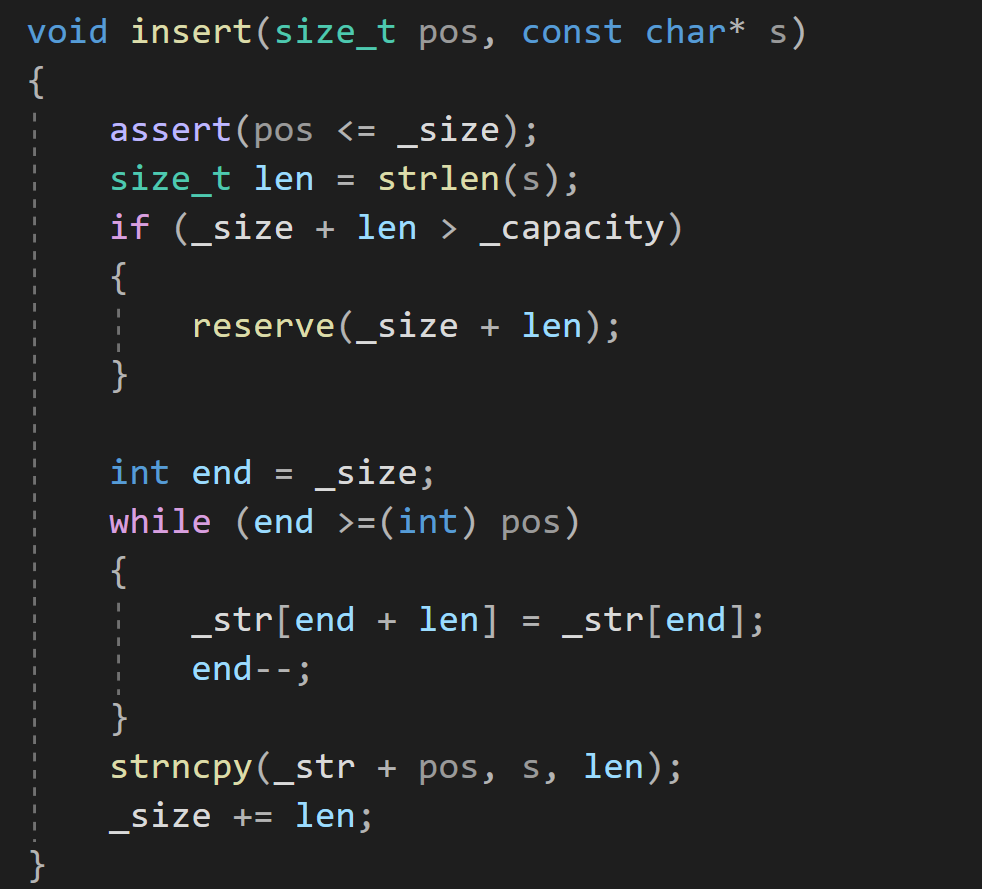
?可以尾插,所以pos可以是_size
1 檢查原有效字符個數+要插入的有效字符格式是否>_capacity,大于則擴容
2 從'\0'位置開始,一直到pos位置上的數據,將它們全部向后挪動len步
3 將常量字符串拷貝到_str+pos的位置,只要拷貝len個,不要使用strcpy全部拷貝,因為會拷貝到'\0'
erase:
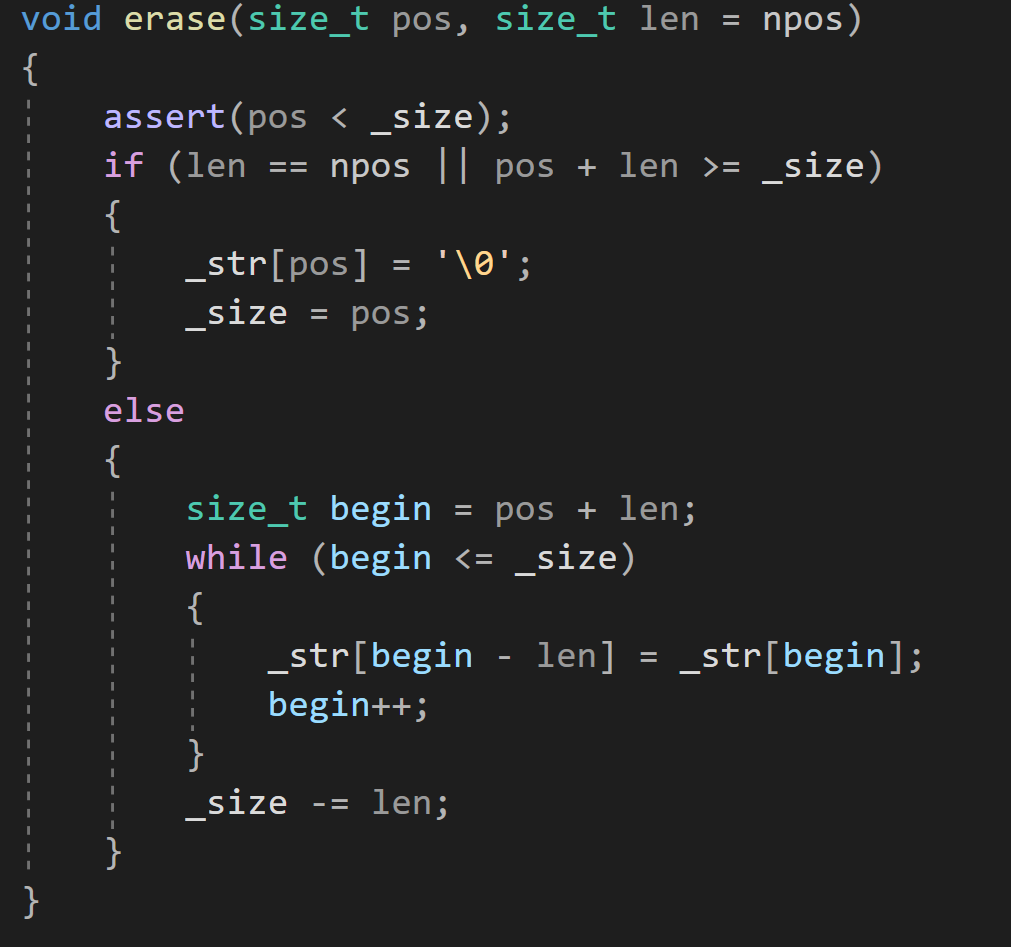
有兩種情況:
一:從pos位置開始,有多少刪多少
1 當沒有給len傳參時,len使用缺省值npos,(size_t類型的-1,很大的數字,但是一個字符串不會有那么大,所以npos通常可以理解為有多少要多少),即從pos位置開始全部刪除
2? 傳參給len,但若pos+len>=_size (pos+len是要刪除的最后一個數據的下一個位置),也是從pos位置開始全部刪除
方法:在pos位置給'\0'
二:從pos位置開始,刪除len個字符?
pos+len是合法的,那么從pos+len位置開始一直到'\0',要將它們全部向前移動len步,覆蓋效果
不要忘記移動'\0'
?len給一個缺省值npos(const修飾的靜態變量,值為-1)

?靜態成員變量不在對象中,不走初始化列表,在類外定義,給初始值-1
但是 const修飾的靜態整型成員變量是一個特例,可以在聲明的地方給缺省值
其實在常規情況下,成員變量聲明的地方給缺省值,就代表它們在走初始化列表的時候可以被初始化
流插入和流提取重載:
流插入:
ostream& operator<<(ostream& out, const string& s){for (auto e : s){out << e;}return out;}會有cout<<s<<s2的情況,所以有ostream類型的返回值?,out出了作用域還在所以可以用傳引用返回提高效率
流提取:
void clear(){_str[0] = '\0';_size = 0;} istream& operator>>(istream& in, string& s){s.clear();//在向string類的對象輸入內容時,要情況原有的所有數據char buff[129];size_t i = 0;char ch;ch = in.get();while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 128){buff[i] = '\0';s += buff;i = 0;//從頭再來}ch = in.get();}if (i != 0)//可能字符串的長度沒有達到128個{buff[i] = '\0';s += buff;}return in;}會有cin>>s>>s2的情況,所以有istream類型的返回值
在輸入的字符串很長的情況下,若是提取一個字符便+=到string類的對象中,難免會有多次擴容,
若以為了提高效率,可以開一個能存儲129個字符的buff數組,提取的字符先存儲到buff數組中
當有了128個字符時,加入'\0',再將buff數組中的所有字符以字符串的形式一并+=到string類的對象中?
buff數組就像一個蓄水池,水滿了就全部拿走,然后再接著蓄水,滿了再全部拿走
注意:cin和scanf一樣,不能提取到空格或者'\n',scanf中用getchar可以提取任意字符,那在cin中,有get可以提取任意字符
測試:
void test6()
{djx::string s("hello world");cout << s.c_str() << endl;//沒有重載流插入運算符之前,打印string類對象的內容s.insert(5, '%');cout << s.c_str() << endl;s.insert(s.size(), '%');cout << s.c_str() << endl;s.insert(0, '%');cout << s.c_str() << endl;djx::string s2("hello world");s2.insert(5, "abc");cout << s2 << endl;//重載流插入運算符之后,打印string類對象的內容s2.insert(0, "xxx");cout << s2 << endl;s2.erase(0, 3);cout << s2 << endl;s2.erase(5, 100);cout << s2 << endl;s2.erase(2);cout << s2 << endl;}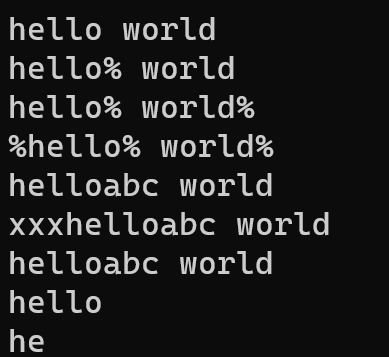
void test7()
{djx::string s("hello world");cout << s << endl;cin >> s;cout << s << endl;
}?
?
?目前為止的完整代碼:
#include<assert.h>
namespace djx
{class string{public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin()const{return _str;}const_iterator end()const{return _str + _size;}string(const char* str = ""):_size(strlen(str)),_capacity(_size){_str = new char[_capacity + 1];strcpy(_str, str);}~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}const char* c_str()const{return _str;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}const char& operator[](size_t pos)const{assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = ch;_size++;_str[_size] = '\0';}void append(const char* s){size_t len = strlen(s);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str+_size, s);_size += len;}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* s){append(s);return *this;}/*void insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}int end = _size;while (end >=(int) pos){_str[end + 1] = _str[end];end--;}_str[pos] = ch;_size++;}*/void insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}size_t end = _size+1;while (end >pos){_str[end] = _str[end-1];end--;}_str[pos] = ch;_size++;}void insert(size_t pos, const char* s){assert(pos <= _size);size_t len = strlen(s);if (_size + len > _capacity){reserve(_size + len);}int end = _size;while (end >=(int) pos){_str[end + len] = _str[end];end--;}strncpy(_str + pos, s, len);_size += len;}void erase(size_t pos, size_t len = npos){assert(pos < _size);if (len == npos || pos + len >= _size){_str[pos] = '\0';_size = pos;}else{size_t begin = pos + len;while (begin <= _size){_str[begin - len] = _str[begin];begin++;}_size -= len;}}size_t size()const{return _size;}size_t capacity()const{return _capacity;}void clear(){_str[0] = '\0';_size = 0;}private:char* _str;size_t _size;size_t _capacity;public:const static size_t npos;//const static size_t npos=-1;//特例//const static double npos = 1.1; // 不支持};const size_t string::npos = -1;ostream& operator<<(ostream& out, const string& s){for (auto e : s){out << e;}return out;}istream& operator>>(istream& in, string& s){s.clear();char buff[129];size_t i = 0;char ch;ch = in.get();while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 128){buff[i] = '\0';s += buff;i = 0;}ch = in.get();}if (i != 0){buff[i] = '\0';s += buff;}return in;}
}關系運算符重載:
bool operator<(const string& s)const{return strcmp(_str, s._str) < 0;}bool operator==(const string& s)const{return strcmp(_str, s._str) == 0;}bool operator<=(const string& s)const{return *this < s || *this == s;}bool operator>(const string& s)const{return !(*this <= s);}bool operator>=(const string& s)const{return !(*this < s);}bool operator!=(const string& s)const{return !(*this == s);}resize:
void resize(size_t n,char ch='\0'){if (n <= _size)//刪除效果{_str[n] = '\0';_size = n;}else//插入效果{reserve(n);while (_size < n){_str[_size] = ch;_size++;}_str[_size] = '\0';}}
ch的缺省值給'\0',若是沒有傳參給ch,那么就用'\0'填充?
分三種情況:
n<=_size:刪除效果,保留前n個有效字符
_size<n<_capacity : 無需擴容,直接插入
n>_capacity :先擴容,再插入
測試:
void test8()
{djx::string s("hello world");cout << s<< endl;s.resize(5);cout << s << endl;s.resize(25, 'x');cout << s << endl;
}
?find:
查找一個字符:
size_t find(char ch, size_t pos = 0){for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}return npos;//沒有找到}pos為0,若沒有傳參給pos則默認從頭開始找
查找字符串:
size_t find(const char* s, size_t pos=0){const char* p = strstr(_str+pos, s);//指向匹配字符串的首字符if (p){return p - _str;}else{return npos;//找不到}}測試:
void test()
{djx::string s("hello world");size_t i = s.find("world");cout << i << endl;
} ?
?
?
substr:
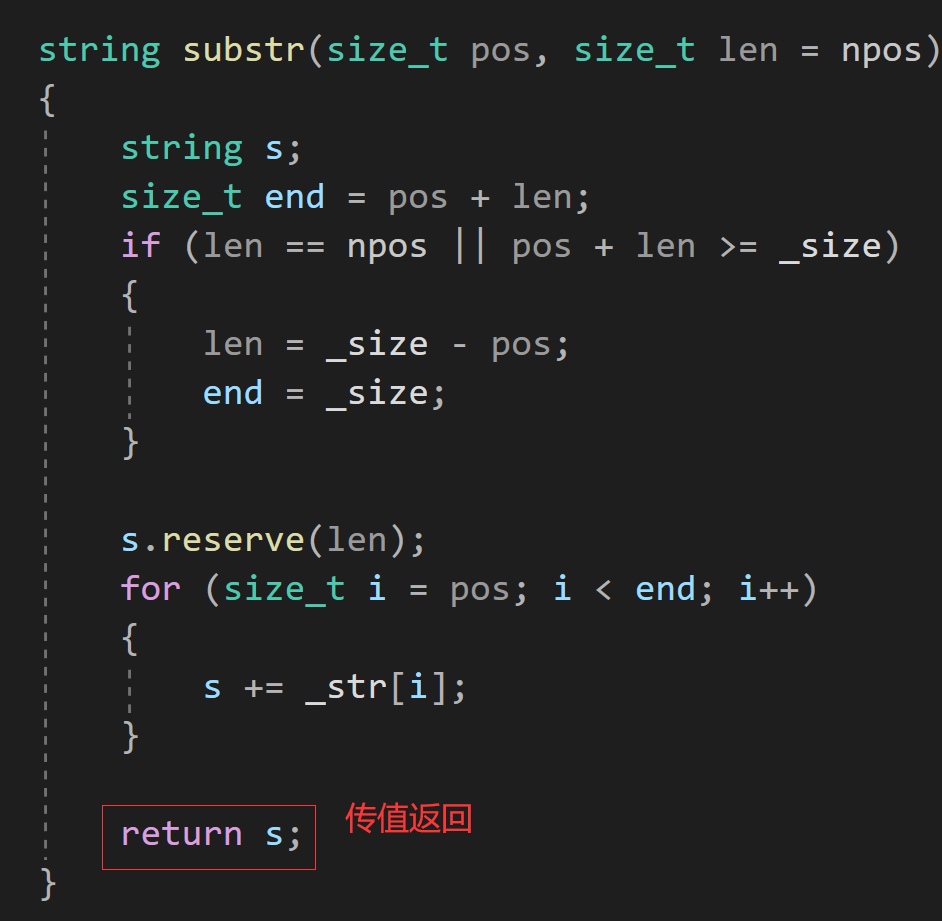
string substr(size_t pos, size_t len = npos){string s;size_t end = pos + len;if (len == npos || pos + len >= _size)//從pos位置開始有多少取多少{len = _size - pos;end = _size;}s.reserve(len);//提前開空間,避免多次擴容for (size_t i = pos; i < end; i++){s += _str[i];}return s;//傳值返回}拷貝構造:
傳統寫法和現代寫法在效率上區別不大,只是代碼簡潔性的區分
傳統寫法:
//傳統寫法string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}自己開和s一樣大的空間,拷貝數據
現代寫法:
void swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//現代寫法string(const string& s):_str(nullptr),_size(0),_capacity(0){string tmp(s._str);//調用構造函數swap(tmp);}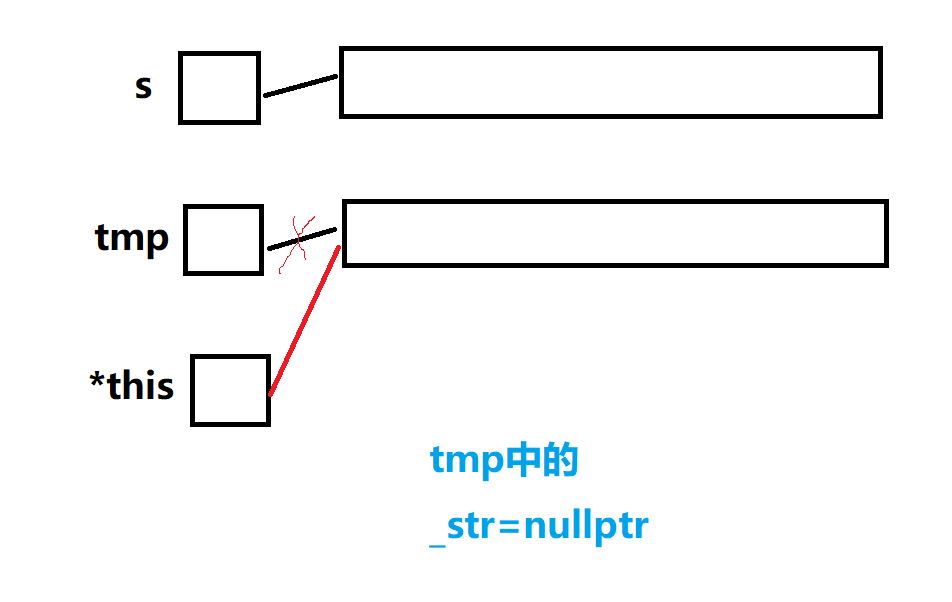 ?
?
?
讓構造函數去生成tmp,再與tmp交換
當tmp銷毀時,調用tmp的析構函數會把this指向的對象,它申請的資源給釋放掉
注意:this指向的對象中的成員變量都要走初始化列表(是它們定義的地方)
那么如果不給this指向對象的成員變量初始化,那么this指向的對象中的_str指向的是一塊隨機的空間,是野指針,不能隨意釋放這塊不屬于自己的空間
所以需要在初始胡列表的地方給this指向對象中的成員變量初始化
賦值重載:
傳統寫法:
//傳統寫法string& operator=(const string& s){if (this != &s){char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;//釋放舊空間_str = tmp;//指向新空間_size = s._size;_capacity = s._capacity;}return *this;}1 tmp指向一塊與s一模一樣的空間
2 釋放_str指向的空間
3 _str指向tmp指向的空間
現代寫法:
版本1:
//現代寫法1string& operator=(const string& s){if (this != &s){string tmp(s);//調用拷貝構造生成tmpswap(tmp);}return *this;}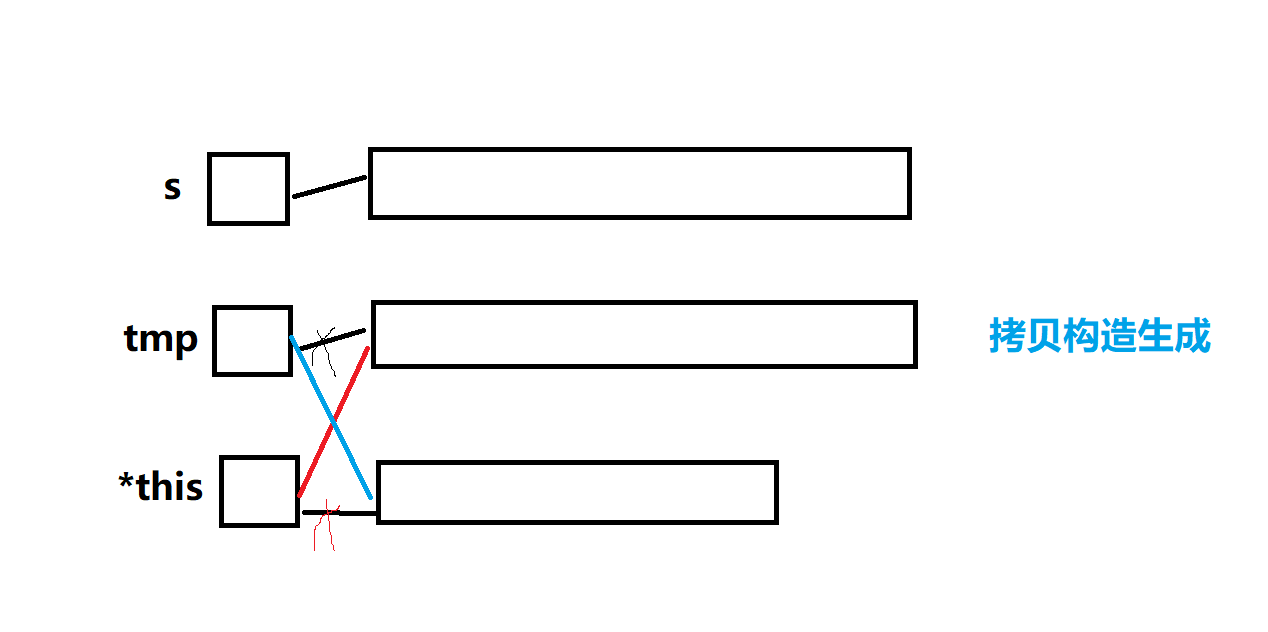
版本2:
?
//現代寫法2string& operator=(string s)//拷貝構造生成s{swap(s);return *this;}
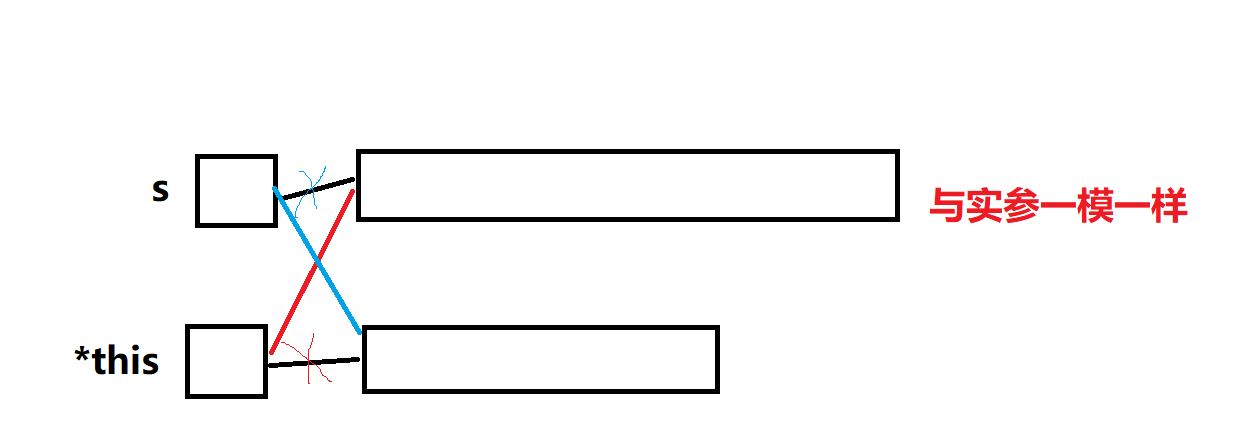
?s銷毀,會釋放原本由*this對象申請的空間
測試:
void test9()
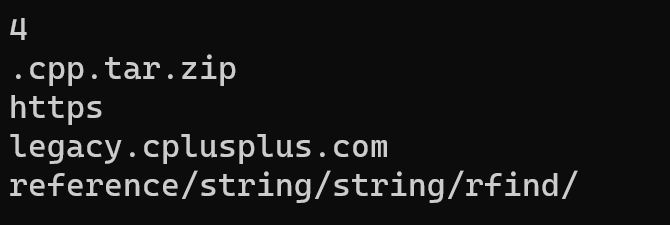
{djx::string s("test.cpp.tar.zip");size_t i = s.find('.');cout << i << endl;djx::string sub = s.substr(i);cout << sub << endl;djx::string s2("https://legacy.cplusplus.com/reference/string/string/rfind/");//分割 協議、域名、資源名djx::string sub1;djx::string sub2;djx::string sub3;size_t i1 = s2.find(':');if (i1 != djx::string::npos){sub1 = s2.substr(0, i1);}else{cout << "找不到i1" << endl;}size_t i2 = s2.find('/', i1 + 3);if (i2 != djx::string::npos){sub2 = s2.substr(i1+3, i2-(i1+3));}else{cout << "找不到i2" << endl;}sub3 = s2.substr(i2 + 1);cout << sub1 << endl;cout << sub2 << endl;cout << sub3 << endl;
}
?注意1:
 ?
?
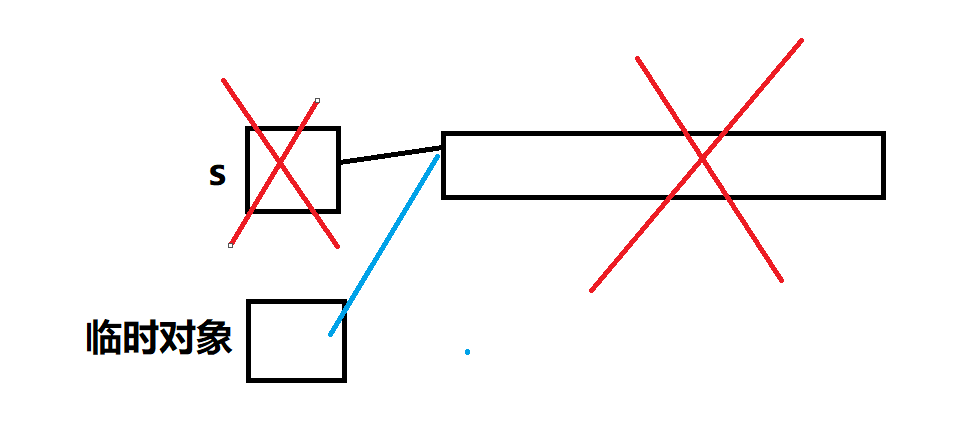
?substr是傳值返回,s對象出了作用域之后就銷毀了,會生成一個臨時對象,由s拷貝構造生成
若是我們沒有寫拷貝構造函數,編譯器默認生成的拷貝構造函數對于對象中內置類型的成員只會完成淺拷貝(值拷貝),即臨時對象和s對象管理同一塊空間,但是s出了作用域之后會調用析構函數,這塊空間會被釋放掉

?
substr返回的臨時對象再拷貝構造給sub對象,沒寫拷貝構造函數,編譯器生成的拷貝構造依然是值拷貝,那么sub對象和臨時對象管理同一塊空間,臨時對象任務完成后,銷毀,再次對已經釋放的空間進行釋放,導致程序崩潰
這里還涉及編譯器優化的問題:
substr拷貝構造生成臨時對象,再由臨時對象拷貝構造生成sub,連續的拷貝構造動作,編譯器直接一步優化為一個拷貝構造:讓s在銷毀前先拷貝構造生成sub,即使是優化了,也因為淺拷貝的問題導致程序崩潰-> sub 和s管理同一塊資源空間,s銷毀,釋放一次這塊空間,等sub銷毀時,再一次釋放這塊空間
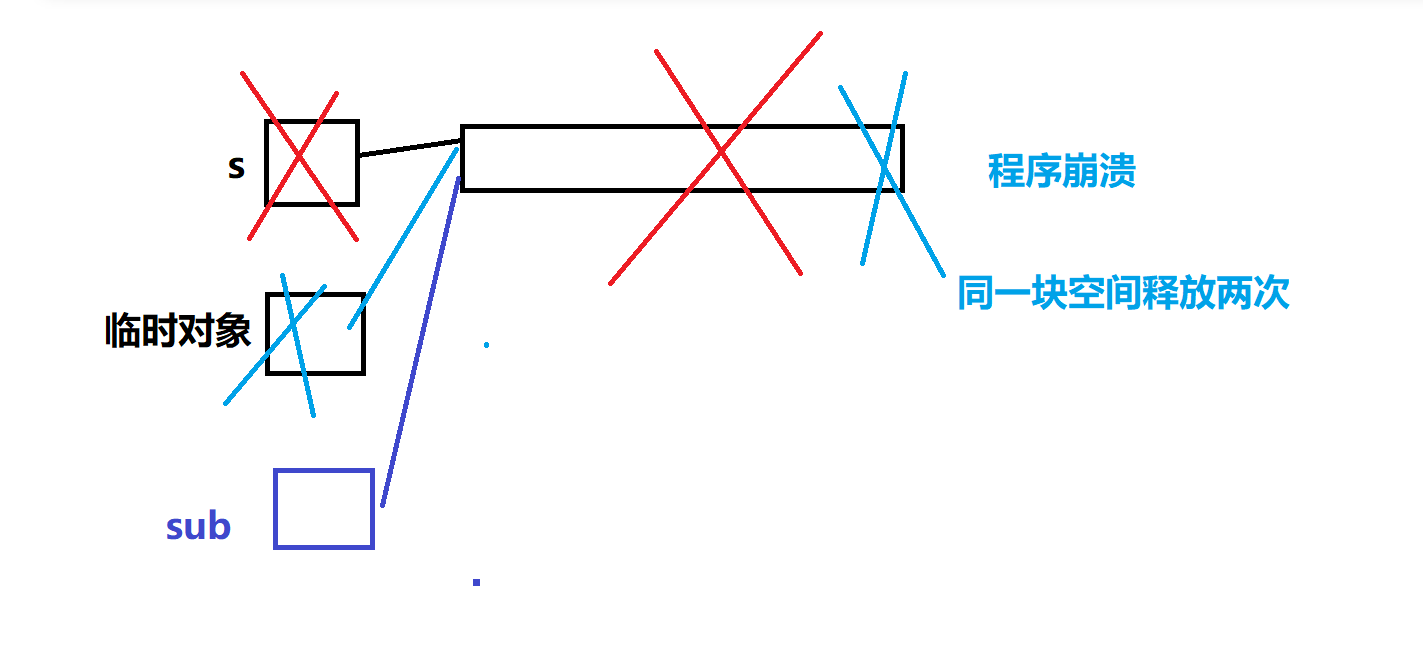
所以拷貝構造必須由我們來寫,完成深拷貝,讓每個對象有自己獨立的資源空間?
注意2 :
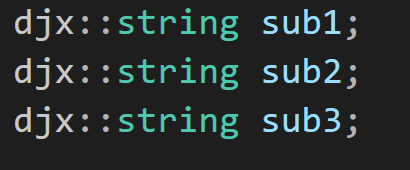
 ?
?
解決拷貝構造問題后,由原來的淺拷貝變為了深拷貝,那么substr返回的臨時對象就有和s一模一樣的獨立資源空間
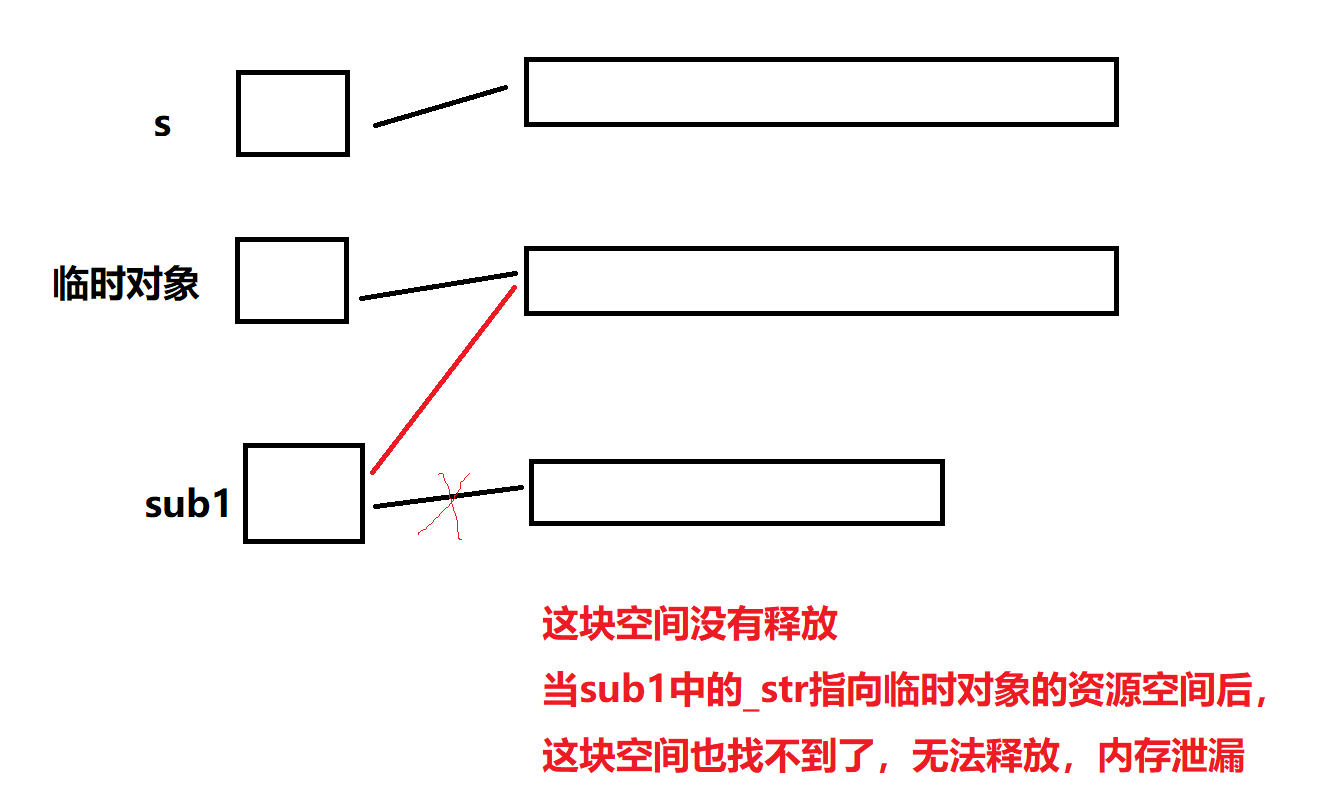
但是若是我們沒有寫賦值重載函數,那么編譯器默認生成的賦值重載函數對于對象中的內置類型的成員只會淺拷貝,即sub1和臨時對象管理同一塊空間,且sub1原來管理的資源空間丟失,導致內存泄漏,且臨時對象銷毀,對它管理的資源空間釋放一次,當sub1銷毀,又對這塊空間釋放一次,程序崩潰
?
?所以我們也要顯示寫賦值重載函數,完成深拷貝,讓每個對象有自己獨立的,與賦值對象一模一樣的資源空間,而不是和其他對象共享同一塊資源空間的管理
完結撒花~




【Go語言,Docker和新技術】)






)

)





